В предыдущей статье мы говорили о прогнозировании временных рядов. Логичным продолжением будет статья о выявлении аномалий.
Выявление аномалий используется в таких областях как:
Так, в 2010 году Иранские центрифуги были атакованы вирусом Stuxnet, который задал неоптимальный режим работы оборудования и вывел из строя часть оборудования за счет ускоренного износа.
Если бы на оборудовании использовались алгоритмы поиска аномалий, ситуации выхода из строя можно было избежать.

Поиск аномалий в работе оборудования используется не только в атомной промышленности, но и в металлургии, и работе авиационных турбин. И в других областях, где использование предиктивной диагностики дешевле возможных потерь при непрогнозируемой поломке.
Если с карты, которой вы пользуетесь в Подольске, снимают деньги в Албании, возможно, транзакции следует дополнительно проверить.
Если часть клиентов демонстрирует аномальное поведение, возможно, есть проблема, о которой вы не знаете.
Если продажи в магазине FMCG понизились ниже границы доверительного интервала прогноза, стоит найти причину происходящего.
Подходит, когда в обучающем наборе данные подчиняются нормальному распределению, а в тестовом содержат аномалии.
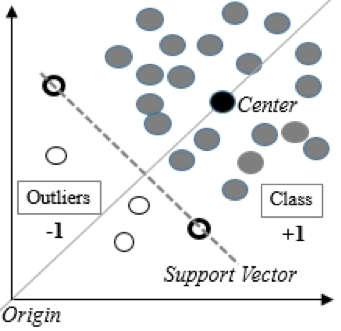
Одноклассовый метод опорных векторов строит нелинейную поверхность вокруг начала координат. Возможно задать границу отсечения, какие данные считать аномальными.
Исходя из опыта нашей команды DATA4, One-Class SVM самый часто используемый алгоритм для решения задачи поиска аномалий.
При «случайном» способе построения деревьев выбросы будут попадать в листья на ранних этапах (на небольшой глубине дерева), т.е. выбросы проще «изолировать». Выделение аномальных значений происходит на первых итерациях работы алгоритма.

Используется, когда данные нормально распределены. Чем ближе измерение к хвосту смеси распределений, тем более аномально значение.
К данному классу можно отнести и другие статистические методы.


Изображение с сайта dyakonov.org
К методам относятся такие алгоритмы, как k ближайших соседей, k-го ближайшего соседа, ABOD (angle-based outlier detection) или LOF (local outlier factor).
Подходят, если расстояние между значениями в признаках равнозначны либо нормированы (чтобы не измерять удава в попугаях).
Алгоритм k ближайших соседей предполагает, что нормальные значения расположены в определенной области многомерного пространства, а расстояние до аномалий будет больше, чем до разделяющей гиперплоскости.

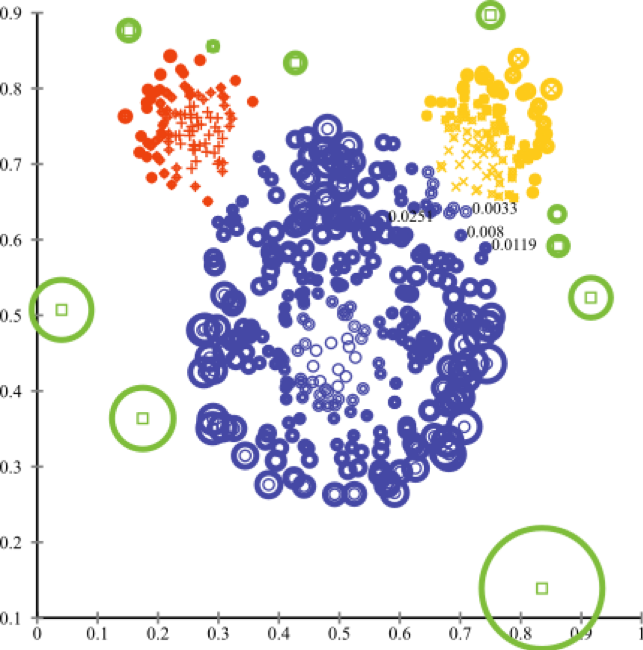
Суть кластерных методов заключается в том, что если значение удалено от центров кластеров более чем на определенную величину, значение можно считать аномальным.
Главное, использовать алгоритм, правильно кластеризующие данные, что зависит от конкретной задачи.
Подходит, где выделяются направления наибольшего изменения дисперсии.
Идея заключается в том, что если значение выбивается из доверительного интервала предсказания, значение считается аномальным. Для предсказания временного ряда используются такие алгоритмы, как тройное сглаживание, S(ARIMA), бустинг и т.д.
Про алгоритмы прогнозирования временного ряда говорилось в предыдущей статье.

Если данные позволяют, используем алгоритмы начиная от линейной регрессии и заканчивая рекуррентными сетями. Замерим разницу между предсказанием и фактическим значением, и сделаем вывод, насколько данные выбиваются из нормы. Важно, чтобы алгоритм обладал достаточной обобщающей способностью, и обучающая выборка не содержала аномальных значений.
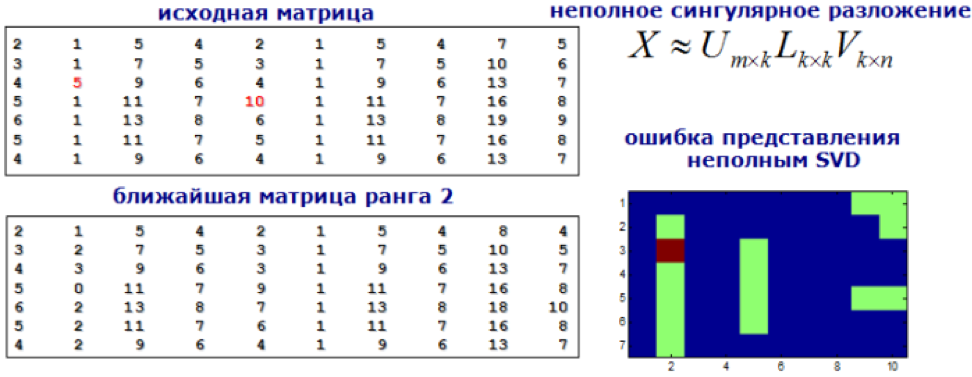
Подойдем к задаче поиска аномалий как к задаче поиска рекомендаций. Разложим нашу матрицу признаков с помощью SVD или факторизационных машин, и значения в новой матрице, существенно отличающиеся от исходных, примем аномальными.
Изображение с сайта dyakonov.org
В этой статье мы рассмотрели основные подходы к обнаружению аномалий.
Поиск аномалий во многом можно назвать искусством. Нет идеального алгоритма или подхода, применение которого решает все задачи. Чаще используется комплекс методов для решения конкретного кейса. Поиск аномалий осуществляется с помощью одноклассового метода опорных векторов, изолирующего леса, метрических и кластерных методов, а также с использованием главных компонент и прогнозирования временных рядов.
Если вы знаете другие методы, напишите про них в комментарии к статье.
Применение
Выявление аномалий используется в таких областях как:
1) Предсказание поломок оборудования
Так, в 2010 году Иранские центрифуги были атакованы вирусом Stuxnet, который задал неоптимальный режим работы оборудования и вывел из строя часть оборудования за счет ускоренного износа.
Если бы на оборудовании использовались алгоритмы поиска аномалий, ситуации выхода из строя можно было избежать.
Поиск аномалий в работе оборудования используется не только в атомной промышленности, но и в металлургии, и работе авиационных турбин. И в других областях, где использование предиктивной диагностики дешевле возможных потерь при непрогнозируемой поломке.
2) Предсказание мошеннических действий
Если с карты, которой вы пользуетесь в Подольске, снимают деньги в Албании, возможно, транзакции следует дополнительно проверить.
3) Выявление аномальных потребительских паттернов
Если часть клиентов демонстрирует аномальное поведение, возможно, есть проблема, о которой вы не знаете.
4) Выявление аномального спроса и нагрузки
Если продажи в магазине FMCG понизились ниже границы доверительного интервала прогноза, стоит найти причину происходящего.
Подходы к выявлению аномалий
1) Метод опорных векторов с одним классом One-Class SVM
Подходит, когда в обучающем наборе данные подчиняются нормальному распределению, а в тестовом содержат аномалии.
Одноклассовый метод опорных векторов строит нелинейную поверхность вокруг начала координат. Возможно задать границу отсечения, какие данные считать аномальными.
Исходя из опыта нашей команды DATA4, One-Class SVM самый часто используемый алгоритм для решения задачи поиска аномалий.
2) Метод изолирующего леса – isolate forest
При «случайном» способе построения деревьев выбросы будут попадать в листья на ранних этапах (на небольшой глубине дерева), т.е. выбросы проще «изолировать». Выделение аномальных значений происходит на первых итерациях работы алгоритма.
3) Elliptic envelope и статистические методы
Используется, когда данные нормально распределены. Чем ближе измерение к хвосту смеси распределений, тем более аномально значение.
К данному классу можно отнести и другие статистические методы.
Изображение с сайта dyakonov.org
4) Метрические методы
К методам относятся такие алгоритмы, как k ближайших соседей, k-го ближайшего соседа, ABOD (angle-based outlier detection) или LOF (local outlier factor).
Подходят, если расстояние между значениями в признаках равнозначны либо нормированы (чтобы не измерять удава в попугаях).
Алгоритм k ближайших соседей предполагает, что нормальные значения расположены в определенной области многомерного пространства, а расстояние до аномалий будет больше, чем до разделяющей гиперплоскости.
5) Кластерные методы
Суть кластерных методов заключается в том, что если значение удалено от центров кластеров более чем на определенную величину, значение можно считать аномальным.
Главное, использовать алгоритм, правильно кластеризующие данные, что зависит от конкретной задачи.
6) Метод главных компонент
Подходит, где выделяются направления наибольшего изменения дисперсии.
7) Алгоритмы на основе прогнозирования временных рядов
Идея заключается в том, что если значение выбивается из доверительного интервала предсказания, значение считается аномальным. Для предсказания временного ряда используются такие алгоритмы, как тройное сглаживание, S(ARIMA), бустинг и т.д.
Про алгоритмы прогнозирования временного ряда говорилось в предыдущей статье.
8) Обучение с учителем (регрессия, классификация)
Если данные позволяют, используем алгоритмы начиная от линейной регрессии и заканчивая рекуррентными сетями. Замерим разницу между предсказанием и фактическим значением, и сделаем вывод, насколько данные выбиваются из нормы. Важно, чтобы алгоритм обладал достаточной обобщающей способностью, и обучающая выборка не содержала аномальных значений.
9) Модельные тесты
Подойдем к задаче поиска аномалий как к задаче поиска рекомендаций. Разложим нашу матрицу признаков с помощью SVD или факторизационных машин, и значения в новой матрице, существенно отличающиеся от исходных, примем аномальными.
Изображение с сайта dyakonov.org
Заключение
В этой статье мы рассмотрели основные подходы к обнаружению аномалий.
Поиск аномалий во многом можно назвать искусством. Нет идеального алгоритма или подхода, применение которого решает все задачи. Чаще используется комплекс методов для решения конкретного кейса. Поиск аномалий осуществляется с помощью одноклассового метода опорных векторов, изолирующего леса, метрических и кластерных методов, а также с использованием главных компонент и прогнозирования временных рядов.
Если вы знаете другие методы, напишите про них в комментарии к статье.

