Введение
Данная статья является продолжением серии статей описывающей алгоритмы лежащие в основе
Synet — фреймворка для запуска предварительно обученных нейронных сетей на CPU.
В предыдущей статье я описал методы, основанные на матричном умножении. Эти методы с минимальными усилиями позволяют достичь во многих случаях более 80% от теоретического максимума. Казалось бы, ну куда тут можно еще дальше улучшать? Оказывается можно! Существуют математически методы, которые позволяют сократить число операций, необходимых для свертки. С одним из таких методов — алгоритму свертки по методу Винограда мы и ознакомимся в настоящей статье.

Шмуэль Виноград (Shmuel Winograd) 1936.01.04 — 2019.03.25 — выдающийся израильский и американский ученый в области компьютерных наук, создатель алгоритмов быстрого матричного умножения, свертки и преобразования Фурье.
Немного математики
Хотя, в машинном обучении наиболее часто используют свертки с квадратным ядром, мы с целью упрощения изложения, вначале рассмотрим одномерный случай. Пусть у нас есть входное одномерное изображение размером
 :
:
и фильтр размером
 :
: 
тогда результатом свертки будет:

Эти выражения будет удобно переписать в матричной форме:

где использованы обозначения:

На первый взгляд, последняя замена выглядит несколько бессмысленно — операций стало явно больше. Но выражения
 и
и  нужно рассчитать только один раз. С учетом этого нам надо выполнить всего 4 операции умножения, в то время как в оригинальной формуле их необходимо сделать 6.
нужно рассчитать только один раз. С учетом этого нам надо выполнить всего 4 операции умножения, в то время как в оригинальной формуле их необходимо сделать 6.Выражение (1) перепишем еще раз:
![$F(2,3)=A^T[(G g)\odot(B^T d)] , (2)$](https://habrastorage.org/getpro/habr/formulas/762/159/29b/76215929b83b9648a01e0002144822f8.svg)
где
 обозначает поэлементное умножение, а также используются следующие обозначения:
обозначает поэлементное умножение, а также используются следующие обозначения:
Выражение (2) можно обобщить на двумерный случай:
![$F(2\times2,3\times3)=A^T\bigg[[G g G^T]\odot[B^T d B]\bigg] A. (6)$](https://habrastorage.org/getpro/habr/formulas/dc8/335/4c2/dc83354c267b105316d09699314b1758.svg)
Требуемое количество операций умножения для
 сократится с
сократится с  до
до  . Таким образом мы получаем вычислительный выигрыш в
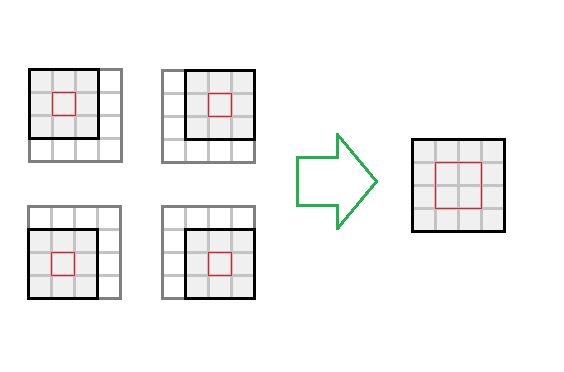
. Таким образом мы получаем вычислительный выигрыш в  раза. Если визуализировать, то по сути мы, вместо раздельного вычисления свертки для каждой точки изображения, будем вычислять его сразу для блока размером
раза. Если визуализировать, то по сути мы, вместо раздельного вычисления свертки для каждой точки изображения, будем вычислять его сразу для блока размером  :
:
В произвольном случае для свертки с окном
 и размером блока
и размером блока  количество требуемых умножений будет
количество требуемых умножений будет
а выигрыш описывается формулой:

В пределе, при достаточно больших
 и
и  для любой свертки достаточно всего 1 операции умножения на точку! К сожалению, увеличение размера блока ведет к быстрому увеличению накладных расходов на преобразование входного
для любой свертки достаточно всего 1 операции умножения на точку! К сожалению, увеличение размера блока ведет к быстрому увеличению накладных расходов на преобразование входного  и выходного
и выходного ![$A^T [...] A$](https://habrastorage.org/getpro/habr/formulas/115/d24/f33/115d24f330d2997f85718960d54e3e96.svg) изображения, так что на практике обычно не используют размер блока больше, чем
изображения, так что на практике обычно не используют размер блока больше, чем  .
.Пример реализации
Для практической реализации алгоритма Винограда хотелось бы рассмотреть простейший случай — свертку с ядром
 для блока . С целью дальнейшего упрощения изложения будем также полагать, что паддинг входного изображения отсутствует, а размеры входного и выходного изображения кратны 2.
для блока . С целью дальнейшего упрощения изложения будем также полагать, что паддинг входного изображения отсутствует, а размеры входного и выходного изображения кратны 2.Реализация свертки, основанная на матричном умножении, будет иметь вид:
float relu(float value) { return value > 0 ? return value : 0; } void gemm_nn(int M, int N, int K, float alpha, const float * A, int lda, float beta, const float * B, int ldb, float * C, int ldc) { for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) { C[i*ldc + j] = beta; for (int k = 0; k < K; ++k) C[i*ldc + j] += alpha * A[i*lda + k] * B[k*ldb + j]; } } void im2col(const float * src, int srcC, int srcH, int srcW, int kernelY, int kernelX, float * buf) { int dstH = srcH - kernelY + 1; int dstW = srcW - kernelX + 1; for (int sc = 0; sc < srcC; ++sc) for (int ky = 0; ky < kernelY; ++ky) for (int kx = 0; kx < kernelX; ++kx) for (int dy = 0; dy < dstH; ++dy) for (int dx = 0; dx < dstW; ++dx) *buf++ = src[((b * srcC + sc)*srcH + dy + ky)*srcW + dx + kx]; } void convolution(const float * src, int batch, int srcC, int srcH, int srcW, int kernelY, int kernelX, int dilationY, int dilationX, int strideY, int strideX, int padY, int padX, int padH, int padW, int group, const float * weight, const float * bias, float * dst, int dstC, float * buf) { int dstH = srcH - kernelY + 1; int dstW = srcW - kernelX + 1; int M = dstC; int N = dstH * dstW; int K = srcC * kernelY * kernelX; for (int b = 0; b < batch; ++b) { im2col(src, srcC, srcH, srcW, kernelY, kernelX, buf); gemm_nn(M, N, K, 1, weight, K, 0, buf, N, dst, N)); for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) dst[i*N+ j] = relu(dst[i*N + j] + bias[i]); src += srcC*srcH*srcW; dst += dstC*dstH*dstW; } }
Тем, кто хочет подробно понять, что здесь происходит, необходимо обратится к моей предыдущей статье. Текущая реализация получается из предыдущей, если положить:
strideY = strideX = dilationY = dilationX = group = 1, padY = padX = padH = padW = 0.
Mодифицированный алгоритм свертки
Приведу здесь еще раз формулу (6):
![$F(2\times2,3\times3)=A^T\bigg[[G g G^T]\odot[B^T d B]\bigg] A.$](https://habrastorage.org/getpro/habr/formulas/2c4/69c/e19/2c469ce19232231a84abcdad4e77ec5e.svg)
Если перейти от выходного изображения размером
к изображению произвольного размера, то нам придется разбить его на блоки размером . Для каждого такого блока из входного изображения будет образовано  значений, которые входят в 16 преобразованных входных изображений уменьшенного вдвое размера. Затем осуществляется умножение каждой из этих 16 матриц на соответсвующую матрицу преобразованных весов
значений, которые входят в 16 преобразованных входных изображений уменьшенного вдвое размера. Затем осуществляется умножение каждой из этих 16 матриц на соответсвующую матрицу преобразованных весов  . 16 получившихся в итоге матриц преобразуются к выходному изображению
. 16 получившихся в итоге матриц преобразуются к выходному изображению ![$A^T\bigg[...\bigg] A$](https://habrastorage.org/getpro/habr/formulas/3b3/98a/d9e/3b398ad9ed8da0c71523257d42e3e3cb.svg) . Ниже этот процесс нарисован на схеме:
. Ниже этот процесс нарисован на схеме:
С учетом этих замечаний алгоритм свертки примет вид:
void convolution(const float * src, int batch, int srcC, int srcH, int srcW, int kernelY, int kernelX, int dilationY, int dilationX, int strideY, int strideX, int padY, int padX, int padH, int padW, int group, const float * weight, const float * bias, float * dst, int dstC, float * buf) { const int block = 2, kernel = 3; int count = (block + kernel - 1)*(block + kernel - 1); // 16 int dstH = srcH - kernelY + 1; int dstW = srcW - kernelX + 1; int tileH = dstH / block; int tileW = dstW / block; int sizeW = srcC * dstC; int sizeS = srcC * tileH * tileW; int sizeD = dstC * tileH * tileW; int M = dstC; int N = tileH * tileW; int K = srcC; float * bufW = buf; float * bufS = bufW + sizeW*count; float * bufD = bufS + sizeS*count; set_filter(weight, sizeW, bufW); for (int b = 0; b < batch; ++b) { set_input(src, srcC, srcH, srcW, bufS, sizeS); for (int i = 0; i < count; ++i) gemm_nn(M, N, K, 1, bufW + i * sizeW, K, bufS + i * sizeS, N, 0, bufD + i * sizeD, N)); set_output(bufD, sizeD, dst, dstC, dstH, dstW); for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) dst[i*N+ j] = relu(dst[i*N + j] + bias[i]); src += srcC*srcH*srcW; dst += dstC*dstH*dstW; } }
Количество операций, которые требуются без учета преобразований входного и выходного изображения: ~srcC*dstC*dstH*dstW*count. Далее опишем алгоритмы преобразования весов, входного и выходного изображения.
Преобразование сверточных весов
Как видно из выражения (6), над весами свертки нужно выполнить следующее преобразование:
, где матрица  определена в выражении (4). Код для такого преобразования будет иметь следующий вид:
определена в выражении (4). Код для такого преобразования будет иметь следующий вид:void set_filter(const float * src, int size, float * dst) { for (int i = 0; i < size; i += 1, src += 9, dst += 1) { dst[0 * size] = src[0]; dst[1 * size] = (src[0] + src[2] + src[1])/2; dst[2 * size] = (src[0] + src[2] - src[1])/2; dst[3 * size] = src[2]; dst[4 * size] = (src[0] + src[6] + src[3])/2; dst[5 * size] = ((src[0] + src[6] + src[3]) + (src[2] + src[8] + src[5]) + (src[1] + src[7] + src[4]))/4; dst[6 * size] = ((src[0] + src[6] + src[3]) + (src[2] + src[8] + src[5]) - (src[1] + src[7] + src[4]))/4; dst[7 * size] = (src[2] + src[8] + src[5])/2; dst[8 * size] = (src[0] + src[6] - src[3])/2; dst[9 * size] = ((src[0] + src[6] - src[3]) + (src[2] + src[8] - src[5]) + (src[1] + src[7] - src[4]))/4; dst[10 * size] = ((src[0] + src[6] - src[3]) + (src[2] + src[8] - src[5]) - (src[1] + src[7] - src[4]))/4; dst[11 * size] = (src[2] + src[8] - src[5])/2; dst[12 * size] = src[6]; dst[13 * size] = (src[6] + src[8] + src[7])/2; dst[14 * size] = (src[6] + src[8] - src[7])/2; dst[15 * size] = src[8]; } }
К счастью это преобразование нужно сделать только 1 раз. Потому оно не влияет на итоговую производительность.
Преобразование входного изображения
Как видно из выражения (6), над входным изображением нужно выполнить следующее преобразование:
, где матрица  определена в выражении (3). Код для такого преобразования будет иметь следующий вид:
определена в выражении (3). Код для такого преобразования будет иметь следующий вид:void set_input(const float * src, int srcC, int srcH, int srcW, float * dst, int size) { int dstH = srcH - 2; int dstW = srcW - 2; for (int c = 0; c < srcC; ++c) { for (int row = 0; row < dstH; row += 2) { for (int col = 0; col < dstW; col += 2) { float tmp[16]; for (int r = 0; r < 4; ++r) for (int c = c; c < 4; ++c) tmp[r * 4 + c] = src[(row + r) * srcW + col + c]; dst[0 * size] = (tmp[0] - tmp[8]) - (tmp[2] - tmp[10]); dst[1 * size] = (tmp[1] - tmp[9]) + (tmp[2] - tmp[10]); dst[2 * size] = (tmp[2] - tmp[10]) - (tmp[1] - tmp[9]); dst[3 * size] = (tmp[1] - tmp[9]) - (tmp[3] - tmp[11]); dst[4 * size] = (tmp[4] + tmp[8]) - (tmp[6] + tmp[10]); dst[5 * size] = (tmp[5] + tmp[9]) + (tmp[6] + tmp[10]); dst[6 * size] = (tmp[6] + tmp[10]) - (tmp[5] + tmp[9]); dst[7 * size] = (tmp[5] + tmp[9]) - (tmp[7] + tmp[11]); dst[8 * size] = (tmp[8] - tmp[4]) - (tmp[10] - tmp[6]); dst[9 * size] = (tmp[9] - tmp[5]) + (tmp[10] - tmp[6]); dst[10 * size] = (tmp[10] - tmp[6]) - (tmp[9] - tmp[5]); dst[11 * size] = (tmp[9] - tmp[5]) - (tmp[11] - tmp[7]); dst[12 * size] = (tmp[4] - tmp[12]) - (tmp[6] - tmp[14]); dst[13 * size] = (tmp[5] - tmp[13]) + (tmp[6] - tmp[14]); dst[14 * size] = (tmp[6] - tmp[14]) - (tmp[5] - tmp[13]); dst[15 * size] = (tmp[5] - tmp[13]) - (tmp[7] - tmp[15]); dst++; } } src += srcW * srcH; } }
Количество операций, которые требуются для этого преобразования: ~srcH*srcW*srcC*count.
Преобразование выходного изображения
Как видно из выражения (6), над выходным изображением нужно выполнить следующее преобразование:
, где матрица определена в выражении (5). Код для такого преобразования будет иметь следующий вид:void set_output(const float * src, int size, float * dst, int dstC, int dstH, int dstW) { for (int c = 0; c < dstC; ++c) { for (int row = 0; row < dstH; row += 2) { for (int col = 0; col < dstW; col += 2) { float tmp[8]; tmp[0] = src[0 * size] + src[1 * size] + src[2 * size]; tmp[1] = src[1 * size] - src[2 * size] - src[3 * size]; tmp[2] = src[4 * size] + src[5 * size] + src[6 * size]; tmp[3] = src[5 * size] - src[6 * size] - src[7 * size]; tmp[4] = src[8 * size] + src[9 * size] + src[10 * size]; tmp[5] = src[9 * size] - src[10 * size] - src[11 * size]; tmp[6] = src[12 * size] + src[13 * size] + src[14 * size]; tmp[7] = src[13 * size] - src[14 * size] - src[15 * size]; dst[col + 0] = tmp[0] + tmp[2] + tmp[4]; dst[col + 1] = tmp[1] + tmp[3] + tmp[5]; dst[dstW + col + 0] = tmp[2] - tmp[4] - tmp[6]; dst[dstW + col + 1] = tmp[3] - tmp[5] - tmp[7]; src++; } dst += 2*dstW; } } }
Количество операций, которые требуются для этого преобразования: ~dstH*dstW*dstC*count.
Особенности практической реализации
В рассмотренном выше примере мы привели описание алгоритма Винограда для блока размером
. На практике чаще всего используют более продвинутый вариант алгоритма:  . В этом случае размером блока будет , а количество преобразованных матриц — 36. Вычислительный выигрыш, согласно формуле (8) будет достигать 4. Общая схема алгоритма такая же, отличаются только матрицы алгоритмов преобразования.
. В этом случае размером блока будет , а количество преобразованных матриц — 36. Вычислительный выигрыш, согласно формуле (8) будет достигать 4. Общая схема алгоритма такая же, отличаются только матрицы алгоритмов преобразования. Существует небольшой проект на Github, который позволяет рассчитать эти матрицы с коэффициентами для произвольного размера ядра свертки и размера блока.
Мы привели вариант алгоритма Винограда для формата изображения NCHW, но алгоритм может быть по похожей схеме реализован и для формата NHWC (подробнее об этих форматах изображения я рассказывал в предыдуще статье.
Не смотря на наличие дополнительных преобразований, основная вычислительная нагрузка в алгоритме Винограда (при его грамотном применении, конечно) все равно лежит на матричном умножении. К счастью, это стандартная операция и эффективно реализована во множестве библиотек.
Оптимизированные под разные платформы функции преобразования для алгоритма Винограда можно найти здесь.
Плюсы и минусы алгоритма Винограда
Сначала конечно плюсы:
- Алгоритм позволяет в несколько раз (чаще всего в 2-3 раза) ускорить вычисление свертки. Таким образом удается вычислять свертку быстрее «теоретического» предела.
- Алгоритм опирается в своей реализации на стандартный алгоритм матричного умножения.
- Он может реализован для различных форматов входных изображений: NCHW, NHWC.
- Размер буфера для хранения промежуточных значений меньше, чем требуется для алгоритма, основанного на матричном умножении.
Ну и куда же без минусов:
- Алгоритм требует отдельной реализации функций преобразования для каждого размера ядра свертки, а также для каждого размера блока. Может быть это является одной из основных причин того, что он практически везде реализован только для свертки с ядром .
- С ростом размера блока, сложность реализации функций преобразования быстро растет. Поэтому практически нет реализаций с размером блока больше чем .
- Алгоритм накладывает жесткие ограничения на параметры свертки strideY = strideY = dilationY = dilationX = group = 1. Хотя теоретически, возможна реализация алгоритма, когда эти ограничения нарушаются, на практике она мала применима по причине низкой эффективности.
- Эффективность алгоритма падает, если число входных или выходных каналов в изображении мало (это связано с затратами на конвертацию входных и выходных изображений).
- Эффективность алгоритма падает для малых размеров входных изображений (получающиеся матрицы из входного изображения имеют слишком маленькие размеры, и стандартный алгоритм матричного умножения для них становится не эффективным).
Выводы
Метод вычисления свертки, основанный на алгоритме Винограда, позволяет значительно повысить вычислительную эффективность по сравнению с методом, основанном на простом матричном умножении. К сожалению, он не универсален и достаточно сложен в реализации. Для ряда частных случаев существуют более быстрые подходы, описание которых мне хотелось бы отложить для следующих статей данной серии. Жду отзывов и замечаний от читателей. Надеюсь, вам было интересно!
P.S. Этот и другие подходы реализованы мной в Convolution Framework в рамках библиотеки Simd.
Данный фреймворк лежит в основе Synet — фреймворка для запуска предварительно обученных нейронных сетей на CPU.

