Пролог
По сети сейчас гуляет видео — как автопилот Теслы видит дорогу.
У меня давно чесались руки транслировать видео, обогащенное детектором, да и в реальном времени.

Проблема в том, что транслировать видео я хочу с Raspberry, а производительность нейросетевого детектора на ней оставляет желать лучшего.
Intel Neural Computer Stick
Я рассматривал разные варианты решения.
В прошлой статье экспериментировал с Intel Neural Computer Stick. Железка мощная, но требует своего формата сети.
Несмотря на то, что Интел предоставляет конвертеры для основных фреймворков, здесь есть ряд подводных камней.
Например, формат нужной сети может быть несовместим, а если совместим, то какие-то слои могут не поддерживаться на девайсе, а если поддерживаются, то в процессе конвертации могут происходить ошибки, в результате которых на выходе получаем какие-то странные вещи.
В общем, если хочется какую-то произвольную нейросеть, то с NCS может не получиться. Поэтому, я решил попробовать решить проблему через самые массовые и доступные инструменты.
Облако
Очевидная альтернатива локально-хардварному решению — пойти в облако.
Готовых вариантов — глаза разбегаются.
Все лидеры:
… И десятки менее известных.
Выбрать среди этого многообразия совсем не просто.
И я решил не выбирать, а завернуть старую добрую рабочую схему на OpenCV в докер и запустить его в облаке.
Преимущество такого подхода в гибкости и контроле — можно поменять нейросеть, хостинг, сервер — в общем, любой каприз.
Сервер
Начнем с локального прототипа.
Традиционно я использую Flask для REST API, OpenCV и MobileSSD сеть.
Поставив на докер текущие версии, обнаружил что OpenCV 4.1.2 не работает с Mobile SSD v1_coco_2018_01_28, и пришлось откатиться на проверенную 11_06_2017.
На старте сервиса загружаем имена классов и сеть:
def init(): tf_labels.initLabels(dnn_conf.DNN_LABELS_PATH) return cv.dnn.readNetFromTensorflow(dnn_conf.DNN_PATH, dnn_conf.DNN_TXT_PATH)
На локальном докере (на не самом молодом лаптопе) это занимает 0.3 секунды, на Raspberry — 3.5.
Запускаем расчет:
def inference(img): net.setInput(cv.dnn.blobFromImage(img, 1.0/127.5, (300, 300), (127.5, 127.5, 127.5), swapRB=True, crop=False)) return net.forward()
Докер — 0.2 сек, Raspberry — 1.7.
Превращаем тензорный выхлоп в читабельный json:
def build_detection(data, thr, rows, cols): ret = [] for detection in data[0,0,:,:]: score = float(detection[2]) if score > thr: cls = int(detection[1]) a = {"class" : cls, "name" : tf_labels.getLabel(cls), "score" : score} a["x"] = int(detection[3] * cols) a["y"] = int(detection[4] * rows) a["w"] = int(detection[5] * cols ) - a["x"] a["h"] = int(detection[6] * rows) - a["y"] ret.append(a) return ret
Дальше экспортируем эту операцию через Flask(на входе картинка, на выходе — результаты детектора в json).
Альтернативный вариант, в котором больше работы перекладывается на сервер: он сам обводит найденные объекты и возвращает готовую картинку.
Такой вариант хорош там, где мы не хотим тянуть opencv на сервер.
Докер
Собираем образ.
Код причесан и выложен на Гитхаб, докер возьмет его напрямую оттуда.
В качестве платформы возьмем тот же Debian Stretch, что и на Raspberry — не будем уходить от проверенного техстека.
Надо поставить flask, protobuf, requests, opencv_python, скачать Mobile SSD, код сервера с Гитхаба и запустить сервер.
FROM python:3.7-stretch RUN pip3 install flask RUN pip3 install protobuf RUN pip3 install requests RUN pip3 install opencv_python ADD http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_11_06_2017.tar.gz / RUN tar -xvf /ssd_mobilenet_v1_coco_11_06_2017.tar.gz ADD https://github.com/tprlab/docker-detect/archive/master.zip / RUN unzip /master.zip EXPOSE 80 CMD ["python3", "/docker-detect-master/detect-app/app.py"]
Простой клиент для детектора на основе requests.
Публикация на Docker Hub
Реестры докера плодятся со скоростью не меньшей, чем облачные детекторы.
Чтобы не заморачиваться, мы консервативно пойдем через ДокерХаб.
- Регистрируемся
- Авторизуемся:
docker login
- Придумаем содержательное имя:
docker tag opencv-detect tprlab/opencv-detect-ssd
- Загружаем образ на сервер:
docker push tprlab/opencv-detect-ssd
Запускаем в облаке
Выбор, где запустить контейнер, тоже весьма широк.
Все большие игроки (Гугл, Микрософт, Амазон) предлагают микроинстанс бесплатно в первый год.
Поэксперементировав с Microsoft Azure и Google Cloud, остановился на последнем — потому, что быстрее взлетело.
Не стал писать здесь инструкцию, так как эта часть очень специфичная для выбранного провайдера.
Попробовал разные варианты железа,
Низкие уровни (shared и выделенные) — 0.4 — 0.5 секунды.
Машины помощнее — 0.25 — 0.3.
Что ж, в даже в худшем случае выигрыш в три раза, можно попробовать.
Видео
Запускаем простой OpenCV видеостример на Raspberry, детектируя через Google Cloud.
Для эксперимента был использован видеофайл, когда-то снятый на случайном перекрестке.
def handle_frame(frame): return detect.detect_draw_img(frame) def generate(): while True: rc, frame = vs.read() outFrame = handle_frame(frame) if outFrame is None: (rc, outFrame) = cv.imencode(".jpg", frame) yield(b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n' + bytearray(outFrame) + b'\r\n') @app.route("/stream") def video_feed(): return Response(generate(), mimetype = "multipart/x-mixed-replace; boundary=frame")
С детектором получается не более трех кадров в секунду, все идет очень медленно.
Если в GCloud взять мощную машину, можно детектить 4-5 кадров в секунду, но разница глазом практически незаметна, все равно медленно.

Облако и транспортные расходы здесь не причем, на обычном железе детектор и работает с такой скоростью.
Neural Computer Stick
Не удержался и прогнал бенчмарк на NCS.
Скорость детектора была чуть медленнее 0.1 секунды, в любом случае в 2-3 раза быстрее облака на слабой машине, т.е 8-9 кадров в секунду.
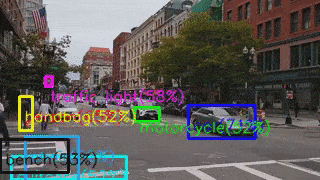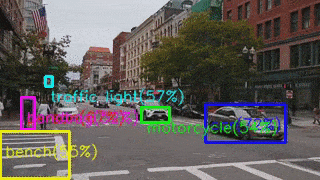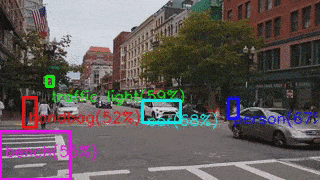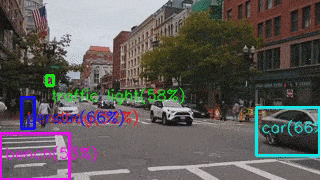
Разница в результатах объясняется тем, что на NCS запускался Mobile SSD версии 2018_01_28.
P.S. Кроме того, эксперименты показали, что достаточно мощная десктопная машина с I7 процессором показывает чуть лучшие результаты и на ней оказалось возможно выжать 10 кадров в секунду.
Кластер
Эксперимент пошел дальше и я поставил детектор на пяти узлах в Google Kubernetes.
Сами по себе поды были слабые и каждый из них не мог обработать больше 2х кадров в секунду.
Но если запустить кластер на N узлов и разбирать кадры в N потоков — то при достаточном количестве узлов (5) можно добиться желанных 10 кадров в секунду.
def generate(): while True: rc, frame = vs.read() if frame is not None: future = executor.submit(handle_frame, (frame.copy())) Q.append(future) keep_polling = len(Q) > 0 while(keep_polling): top = Q[0] if top.done(): outFrame = top.result() Q.popleft() if outFrame: yield(b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n' + bytearray(outFrame) + b'\r\n') keep_polling = len(Q) > 0 else: keep_polling = len(Q) >= M
Вот что получилось:

Немного не так резво как с NCS, но бодрее чем в один поток.
Выигрыш, конечно, не линеен — выстреливают накладки на синхронизацию и глубокое копирование картинок opencv.
Заключение
В целом, эксперимент позволяет сделать вывод, что, если постараться, можно выкрутиться с простым облаком.
Но мощный десктоп или локальная железка позволяют добиться лучших результатов, причем без всяких ухищрений.

