Возможно вы сталкивались с задачей параллельных вычислений над pandas датафреймами. Решить эту проблему можно как силами нативного Python, так и с помощью замечательной библиотеки — pandarallel. В этой статье я покажу, как эта библиотека позволяет обрабатывать ваши данные с использованием всех доступных мощностей.
Библиотека позволит вам не думать о числе потоков, создании процессов и предоставит интерактивный интерфейс для мониторинга прогресса.
Установка
pip install pandas jupyter pandarallel requests tqdm
Как видите, я также устанавливаю tqdm. С его помощью я наглядно продемонстрирую разницу в скорости выполнения кода при последовательном и параллельном подходе.
Настройка
import pandas as pd import requests from tqdm import tqdm tqdm.pandas() from pandarallel import pandarallel pandarallel.initialize(progress_bar=True)
С полным списком настроек вы можете ознакомиться в документации pandarallel.
Создаем датафрейм
Для экспериментов создадим простой датафрейм — 100 строк, 1 колонка.
df = pd.DataFrame( [i for i in range(100)], columns=["sample_column"] )

Пример задачи, подходящей для распараллеливания
Как мы знаем, решение не всех задач можно распараллелить. Простой пример подходящей задачи — вызов какого-нибудь внешнего источника, например API или базы данных. В функции ниже я вызываю API, который возвращает мне одно случайное слово. Моя цель — добавить в датафрейм колонку со словами, полученными из этого API.
def function_to_apply(i): r = requests.get(f'https://random-word-api.herokuapp.com/word').json() return r[0]
Классический способ решения задачи
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
Для людей, который не знакомы с библиотекой tqdm, поясню — функция progress_apply действует аналогично привычному apply. И, вдобавок к этому, мы получаем интерактивный progress bar.

Такое "наивное" решение задачи заняло 35 секунд.
Параллельный способ решения задачи
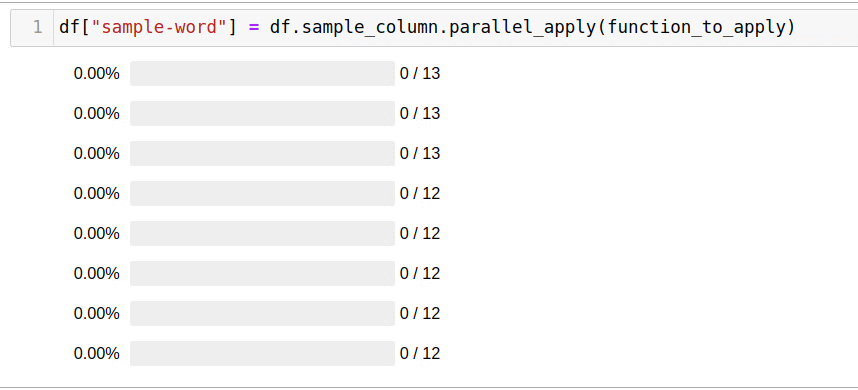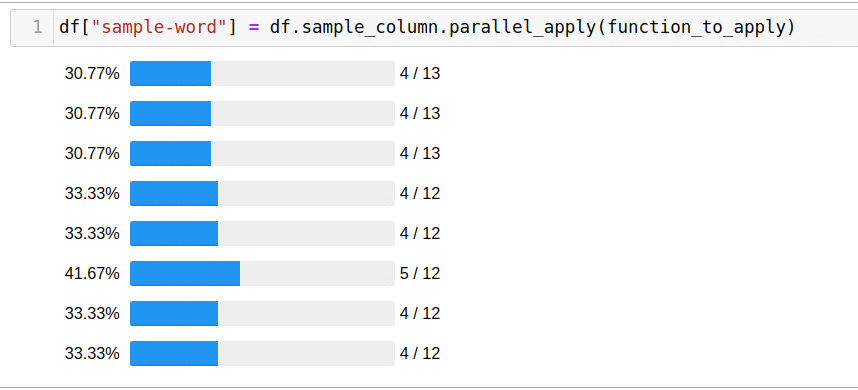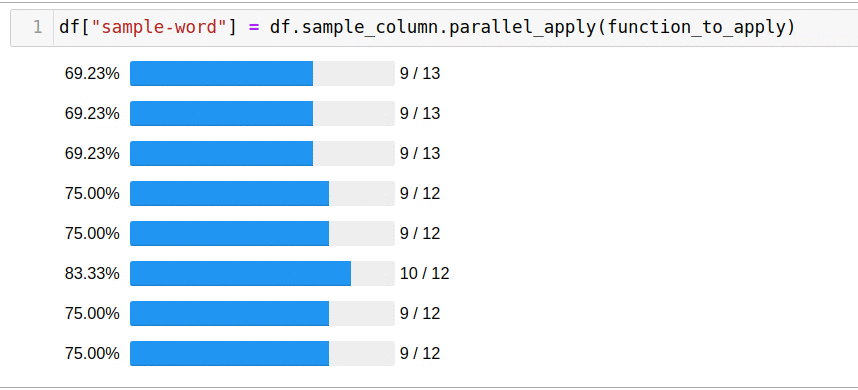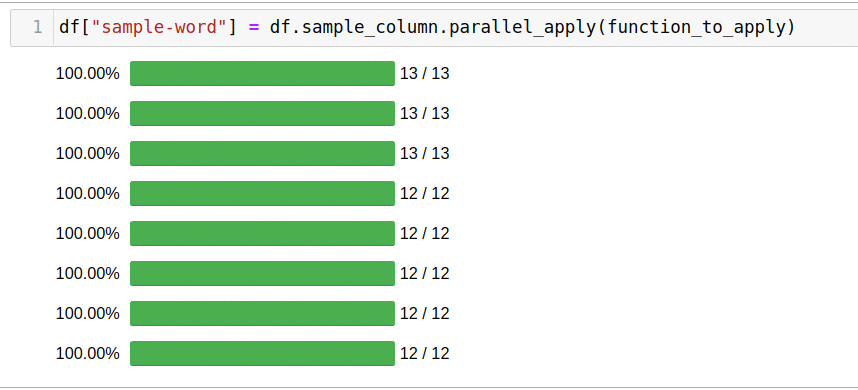
Для использования всех доступных ядер, достаточно использовать функцию parallel_apply:
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
Такое решение заняло всего 5 секунд.
Прочие сценарии
Полный список pandas функций, поддерживаемых pandarallel, приведен в Github проекта.

Спасибо за внимание! Если статья вам понравилась — подписывайтесь на мой Телеграм канал или Твиттер.

