Однажды коллега поделился размышлениями об API для распределённых вычислительных кластеров, а я в шутку ответил: «Очевидно, что идеальным API был бы простой вызов
За первые выходные сделал базовый прототип, а второй уикенд принёс демку, которая могла
На видео показано, что рендеринг на 64-ядерной VM в облаке завершается за 8 секунд (плюс 6 секунд на телефорк туда и обратно). Тот же рендеринг локально в контейнере на моём ноутбуке занимает 40 секунд:
Как возможно телепортировать процесс? Вот что должна объяснить эта статья! Основная идея заключается в том, что на низком уровне у процесса Linux всего несколько составляющих. Просто нужен способ восстановить каждую из них от донора, передать по сети и скопировать в клонированный процесс.
Вы можете подумать: «Но как реплицировать [что-то трудное, например, TCP-соединение]?» Действительно. На самом деле мы не переносим такие сложные вещи, чтобы сохранить код простым. То есть это просто забавная техническая демонстрация, которую, вероятно, не следует использовать в продакшне. Но она всё равно умеет телепортировать широкий класс, в основном, вычислительных задач!
Я реализовал код в виде библиотеки Rust, но теоретически вы можете обернуть программу в C API, а затем запустить через привязки FFI для телепортации даже питоновского процесса. Реализация составляет всего около 500 строк кода (плюс 200 строк комментариев):
Я также написал хелпер под названием
Посмотрим, как выглядит процесс в Linux (на котором работает ОС материнского хоста
Таким образом, базовую реализацию
Я не первым задумался о воссоздании процессов на другой машине. Так, очень похожие вещи делает отладчик записи и воспроизведения rr. Я отправил автору этой программы @rocallahan несколько вопросов, а он рассказал мне о системе CRIU для «горячей» миграции контейнеров между хостами. CRIU умеет передавать процесс Linux в другую систему, поддерживает восстановление всех видов файловых дескрипторов и других состояний, однако код действительно сложный и использует множество системных вызовов, которые требуют специальных сборок ядра и рутовых разрешений. По ссылке с вики-страницы CRIU я нашёл DMTCP, созданный для снапшотов распределённых заданий на суперкомпьютерах, чтобы их можно было перезапустить позже, и у этой программы код оказался проще.
Эти примеры не заставили меня отказаться от попыток реализовать собственную систему, поскольку это чрезвычайно сложные программы, которые требуют специальных раннеров и инфраструктуры, а я хотел реализовать максимально простую телепортацию процессов как вызов библиотеки. Поэтому я изучил фрагменты исходного кода
Чтобы телепортировать процесс, нужно выполнить определённую работу в исходном процессе, который вызывает
Ниже приведён упрощённый обзор обоих процессов. Если хотите детально разобраться, предлагаю прочитать исходный код. Он содержится в одном файле и плотно закомментирован, чтобы читать по порядку и разбираться, как всё работает.
Отправка процесса с помощью
Функция
Чтобы превратить целевой процесс в копию входящего процесса, нужно будет заставить процесс выполнить кучу системных вызовов на самом себе, не имея доступа к какому-либо коду, потому что мы всё удалили. Мы выполняем удалённые системные вызовы с помощью ptrace, универсального системного вызова для манипулирования и проверки других процессов:
Приём процесса в
Используя этот и уже описанные примитивы, мы можем воссоздать процесс:
Некоторые части моей реализации telefork спроектированы неидеально. Я знаю, как их исправить, но и в нынешнем виде система мне нравится, а иногда их действительно сложно исправить. Вот несколько интересных примеров:
Думаю, вы уже поняли, что при наличии правильных низкоуровневых интерфейсов можно реализовать некоторые сумасшедшие вещи, которые кому-то казались невозможными. Вот некоторые мысли, как развить основные идеи telefork. Хотя многое из перечисленного, наверное, полностью можно реализовать только на полностью новом или исправленном ядре:
Мне это действительно очень нравится, потому что здесь пример одной из моих любимых техник — нырнуть на менее известный слой абстракции, который относительно легко выполняет то, что мы считали почти невозможным. Телепортация вычислений может показаться невозможной или очень сложной. Вы могли подумать, что она потребует таких методов, как сериализация всего состояния, копирование двоичного исполняемого файла на удалённую машину и запуск его там со специальными флагами командной строки для перезагрузки состояния. Но нет, всё гораздо проще. Под вашим любимым языком программирования лежит слой абстракции, где вы можете выбрать довольно простое подмножество функций — и за выходные реализовать телепортацию большинства чистых вычислений на любом языке программирования в 500 строчках кода. Думаю, что такие погружения на другой уровень абстракции часто приводит более простым и универсальным решениям. Ещё один из моих проектов, похожих на этот, — Numderline.
На первый взгляд такие проекты кажутся экстремальными хаками, и в значительной степени так оно и есть. Они делают вещи так, как никто не ожидает, а когда ломаются, то делают это на уровне абстракции, на котором вроде как не должны работать подобные программы — например, таинственно исчезают ваши файловые дескрипторы. Но иногда вы можете правильно установить уровень абстракции и закодировать любые возможные ситуации, так что в итоге всё будет работать плавно и волшебно. Думаю, что хорошими примерами здесь являются rr (хотя telefork умудрился его засегфолтить) и облачная миграция виртуальных машин в реальном режиме времени (по сути, телефорк на уровне гипервизора).
Мне также нравится представлять эти вещи как идеи альтернативных способов работы компьютерных систем. Почему наши API для кластерных вычислений намного сложнее, чем простая программа, которая транслирует функции в кластер? Почему сетевое системное программирование намного сложнее многопоточного? Конечно, вы можете привести всевозможные веские причины, но они обычно основаны на том, насколько трудно это сделать, на примере существующих систем. А может при правильной абстракции или при достаточных усилиях всё будет работать легко и незаметно? Принципиально тут нет ничего невозможного.

telefork(), чтобы твой процесс очнулся на каждой машине кластера, возвращая значение ID инстанса». Но в итоге эта идея овладела мной. Я не мог понять, почему она такая глупая и простая, намного проще, чем любой API для удалённой работы, и почему компьютерные системы, кажется, не способны на такое. Я также вроде бы понимал, как это можно реализовать, и у меня уже было хорошее название, что является самой трудной частью любого проекта. Поэтому я приступил к работе.За первые выходные сделал базовый прототип, а второй уикенд принёс демку, которая могла
телефоркнуть процесс на гигантскую виртуальную машину в облаке, прогнать рендеринг трассировки путей на множестве ядер, а затем телефоркнуть процесс обратно. Всё это завёрнуто в простой API.На видео показано, что рендеринг на 64-ядерной VM в облаке завершается за 8 секунд (плюс 6 секунд на телефорк туда и обратно). Тот же рендеринг локально в контейнере на моём ноутбуке занимает 40 секунд:
Как возможно телепортировать процесс? Вот что должна объяснить эта статья! Основная идея заключается в том, что на низком уровне у процесса Linux всего несколько составляющих. Просто нужен способ восстановить каждую из них от донора, передать по сети и скопировать в клонированный процесс.
Вы можете подумать: «Но как реплицировать [что-то трудное, например, TCP-соединение]?» Действительно. На самом деле мы не переносим такие сложные вещи, чтобы сохранить код простым. То есть это просто забавная техническая демонстрация, которую, вероятно, не следует использовать в продакшне. Но она всё равно умеет телепортировать широкий класс, в основном, вычислительных задач!
На что это похоже
Я реализовал код в виде библиотеки Rust, но теоретически вы можете обернуть программу в C API, а затем запустить через привязки FFI для телепортации даже питоновского процесса. Реализация составляет всего около 500 строк кода (плюс 200 строк комментариев):
use telefork::{telefork, TeleforkLocation}; fn main() { let args: Vec<String> = std::env::args().collect(); let destination = args.get(1).expect("expected arg: address of teleserver"); let mut stream = std::net::TcpStream::connect(destination).unwrap(); match telefork(&mut stream).unwrap() { TeleforkLocation::Child(val) => { println!("I teleported to another computer and was passed {}!", val); } TeleforkLocation::Parent => println!("Done sending!"), }; }
Я также написал хелпер под названием
yoyo, который телефоркается на сервер, выполняет переданное замыкание, а затем телефоркается обратно. Это создает иллюзию, что можно легко запустить фрагмент кода на удалённом сервере, например, с гораздо большей вычислительной мощностью.// load the scene locally, this might require loading local scene files to memory let scene = create_scene(); let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height]; telefork::yoyo(destination, || { // do a big ray tracing job on the remote server with many cores! render_scene(&scene, width, height, &mut backbuffer); }); // write out the result to the local file system save_png_file(width, height, &backbuffer);
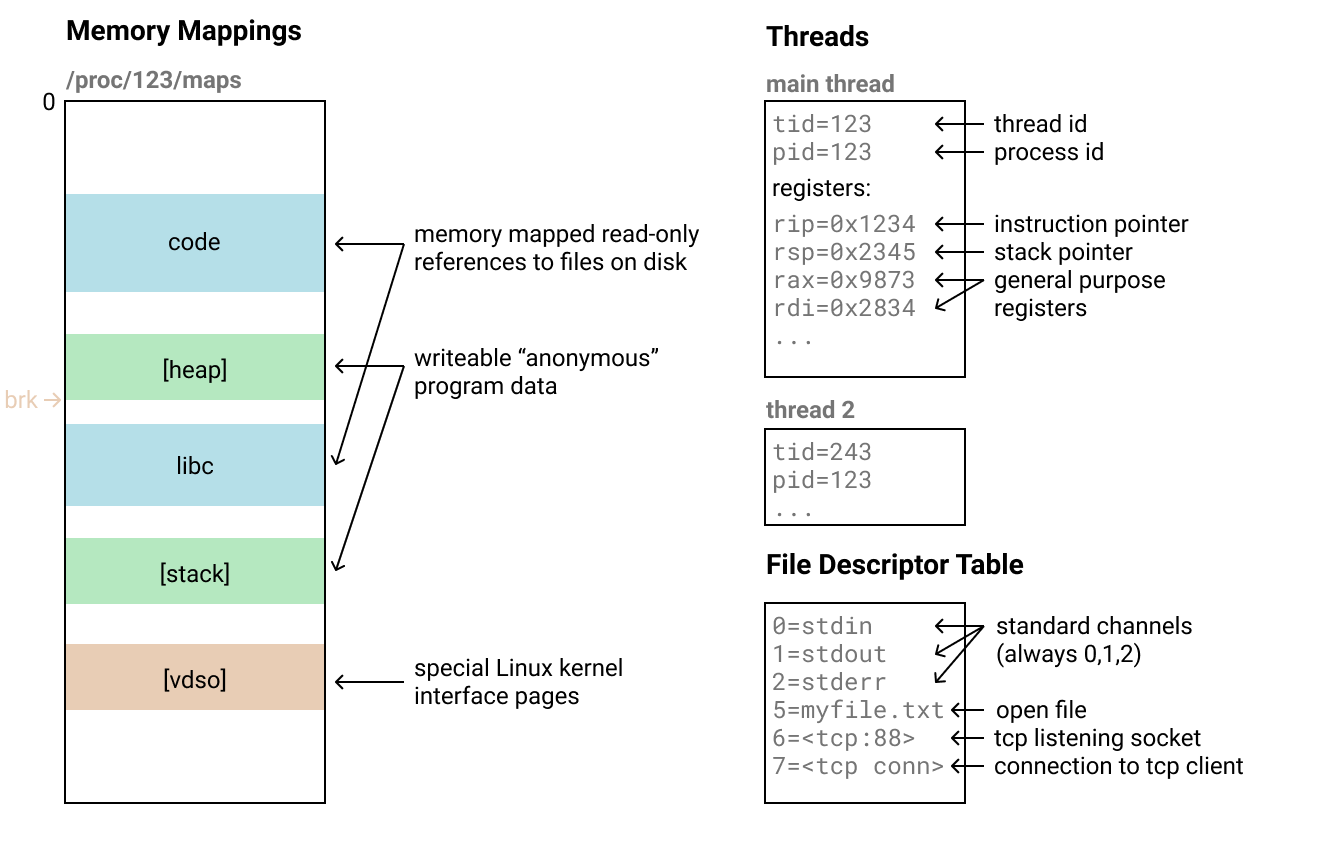
Анатомия процесса Linux
Посмотрим, как выглядит процесс в Linux (на котором работает ОС материнского хоста
telefork):- Сопоставления памяти (memory mappings): они определяют диапазоны байтов из пространства возможных адресов памяти, которые использует наша программа. Диапазоны состоят из «страниц» по 4 килобайта. Можно проверить их на наличие процесса через файл
/proc/<pid>/maps. Они содержат как весь исполняемый код нашей программы, так и данные, с которыми она работает.
- Существует несколько различных типов этих сопоставлений, но мы можем рассматривать их просто как диапазоны байтов, которые необходимо скопировать и воссоздать в том же месте (за исключением некоторых специальных).
- Потоки: у процесса может быть несколько потоков, которые выполняются одновременно в той же памяти. У них есть идентификаторы и, возможно, какое-то другое состояние, но когда они приостановлены, то в основном описываются регистрами процессора, соответствующими точке выполнения. После копирования всей памяти можно просто скопировать содержимое регистра в поток на конечном процессе, а затем возобновить его.
- Файловые дескрипторы: в операционной системе есть таблица, которая соотносит обычные целые числа со специальными ресурсами ядра. Вы можете что-то делать с конкретными ресурсами, передавая эти целые числа в системные вызовы. Существует целая куча различных типов ресурсов, на которые могут указывать эти файловые дескрипторы, и некоторые из них, например TCP-соединения, трудно клонировать.
- Я просто отказался от этой части и вообще их не обрабатываю. После переноса совпадают только дескрипторы stdin/stdout/stderr, потому что они всегда соответствуют числам 0, 1 и 2.
- Это не значит, что с дескрипторами невозможно справиться, просто потребуется дополнительная работа, о которой я расскажу позже.
- Я просто отказался от этой части и вообще их не обрабатываю. После переноса совпадают только дескрипторы stdin/stdout/stderr, потому что они всегда соответствуют числам 0, 1 и 2.
- Разное: есть некоторые другие части состояния процесса, которые различаются по сложности репликации. Но в большинстве случаев они не имеют значения, например, brk (указатель кучи). Некоторые из них можно восстановить только с помощью странных трюков или специальных системных вызовов вроде PR_SET_MM_MAP, что усложняет восстановление.
Таким образом, базовую реализацию
telefork можно сделать с помощью простого сопоставления памяти и регистров основных потоков. Этого должно хватить для простых программ, которые в основном выполняют вычисления, не взаимодействуя с ресурсами ОС, такими как файлы (в принципе, для телепортации достаточно открыть файл в системе и закрыть его перед вызовом telefork).Как телефоркнуть процесс
Я не первым задумался о воссоздании процессов на другой машине. Так, очень похожие вещи делает отладчик записи и воспроизведения rr. Я отправил автору этой программы @rocallahan несколько вопросов, а он рассказал мне о системе CRIU для «горячей» миграции контейнеров между хостами. CRIU умеет передавать процесс Linux в другую систему, поддерживает восстановление всех видов файловых дескрипторов и других состояний, однако код действительно сложный и использует множество системных вызовов, которые требуют специальных сборок ядра и рутовых разрешений. По ссылке с вики-страницы CRIU я нашёл DMTCP, созданный для снапшотов распределённых заданий на суперкомпьютерах, чтобы их можно было перезапустить позже, и у этой программы код оказался проще.
Эти примеры не заставили меня отказаться от попыток реализовать собственную систему, поскольку это чрезвычайно сложные программы, которые требуют специальных раннеров и инфраструктуры, а я хотел реализовать максимально простую телепортацию процессов как вызов библиотеки. Поэтому я изучил фрагменты исходного кода
rr, CRIU, DMTCP и некоторых примеров ptrace — и собрал собственную процедуру telefork. Мой метод работает по-своему, это мешанина различных техник.Чтобы телепортировать процесс, нужно выполнить определённую работу в исходном процессе, который вызывает
telefork, и определённую работу на стороне вызова функции, которая получает потоковый процесс на сервере и воссоздаёт его из потока (функция telepad). Они могут происходить одновременно, но всю сериализацию также можно выполнить перед загрузкой, например, сбросив её в файл, а позже загрузив.Ниже приведён упрощённый обзор обоих процессов. Если хотите детально разобраться, предлагаю прочитать исходный код. Он содержится в одном файле и плотно закомментирован, чтобы читать по порядку и разбираться, как всё работает.
Отправка процесса с помощью telefork
Функция
telefork получает поток с возможностью записи, по которому она передаёт всё состояние своего процесса.- Форк процесса в «замороженный» дочерний. Процессу может быть трудно проверить собственное состояние, так как по мере выполнения проверки изменяются стек, регистры и проч. Мы можем избежать этого с помощью обычной юниксовой команды fork с последующей остановкой дочернего процесса для инспекции.
- Проверка карт распределения памяти. Разбор
/proc/<pid>/mapsпоказывает, где находятся все сопоставления. Для этого я использовал proc_maps crate.
- Отправка информации для специальных карт ядра. По примеру механизма DMTCP, вместо копирования содержимого специальных карт ядра мы переназначаем их, и это лучше всего сделать до остальных сопоставлений, поэтому мы сначала передаём их без содержимого. Эти специальные карты, такие как
[vdso], используются для создания определённых системных вызовов, например, более быстрого получения времени.
- Цикл на других картах распределения памяти и передача их потоком в предоставленный канал. Сначала я сериализую структуру, содержащую информацию о сопоставлении, а затем перебираю страницы в ней и использую системный вызов process_vm_readv для копирования памяти из дочернего элемента в буфер, а затем записываю этот буфер в канал.
- Передача регистров. Я использую опцию
PTRACE_GETREGSдля системного вызова ptrace. Она позволяет получить все значения регистра дочернего процесса. Затем просто записываю их в сообщение по каналу.
Запуск системных вызовов в дочерний процесс
Чтобы превратить целевой процесс в копию входящего процесса, нужно будет заставить процесс выполнить кучу системных вызовов на самом себе, не имея доступа к какому-либо коду, потому что мы всё удалили. Мы выполняем удалённые системные вызовы с помощью ptrace, универсального системного вызова для манипулирования и проверки других процессов:
- Найти инструкцию syscall. Вам нужно выполнить хотя бы одну инструкцию syscall для дочернего процесса, чтобы сопоставление было в исполняемом состоянии. Некоторые предпочитают вставить её, но я вместо этого использую
process_vm_readvдля чтения первой страницы сопоставления[vdso]ядра, которое, насколько мне известно, содержит по крайней мере один syscall во всех версиях Linux, а затем ищу по байтам его смещение. Я делаю это только один раз и обновляю его, когда перемещаю сопоставление[vdso].
- Настроить регистры для выполнения системных вызовов, используя
PTRACE_SETREGS. Указатель инструкции указывает на инструкцию syscall, регистрraxхранит номер системного вызова в Linux, а аргументы хранятся в регистрахrdi, rsi, rdx, r10, r8, r9.
- Сделать один шаг с помощью параметра
PTRACE_SINGLESTEPдля выполнения команды syscall.
- Считать регистры с помощью
PTRACE_GETREGS, чтобы восстановить возвращаемое значение syscall, и посмотреть, удалось ли это сделать.
Приём процесса в telepad
Используя этот и уже описанные примитивы, мы можем воссоздать процесс:
- Форкнуть «замороженный» дочерний процесс. Аналогично отправке, но на этот раз нам нужен дочерний процесс, которым мы можем манипулировать, чтобы превратить его в клон передаваемого процесса.
- Проверить карты распределения памяти. На этот раз нам нужно знать все существующие карты распределения памяти, чтобы удалить их и освободить место для входящего процесса.
- Размонтировать существующие сопоставления. Запускаем цикл над каждым маппингом и манипулируем дочерним процессом, вызывая для него
munmap.
- Переназначить специальные сопоставления ядра. Считываем их назначения из потока и используем
mremap, чтобы переназначить их на целевые назначения.
- Запустить поток с новых сопоставлениями. Используем удалённый
mmapдля создания маппингов, а затемprocess_vm_writevдля потоковой передачи туда страниц памяти.
- Восстановить регистры. Используем
PTRACE_SETREGSдля восстановления регистров основного потока, которые были отправлены, за исключениемrax. Это значение возвращается дляraise(SIGSTOP), где остановился процесс снапшота. Перезаписываем его произвольным целым числом, которое передаётся вtelepad.
- Произвольное значение используется для того, чтобы сервер telefork мог передать файловый дескриптор TCP-соединения, в которое вошёл процесс, и мог отправить данные обратно или, в случае
yoyo, провести телепортацию обратно по тому же соединению.
- Произвольное значение используется для того, чтобы сервер telefork мог передать файловый дескриптор TCP-соединения, в которое вошёл процесс, и мог отправить данные обратно или, в случае
- Перезапустить процесс с новым содержимым, используя
PTRACE_DETACH.
Более грамотная реализация
Некоторые части моей реализации telefork спроектированы неидеально. Я знаю, как их исправить, но и в нынешнем виде система мне нравится, а иногда их действительно сложно исправить. Вот несколько интересных примеров:
- Правильная обработка общих виртуальных динамических объектов (vDSO). Я выполняю
mremapдля vDSO точно так же, как это делает DMTCP, но оказалось, что это работает только при восстановлении на точно такой же сборке ядра. Если же осуществлять копирование содержимого vDSO, то такой способ работает в разных сборках одной и той же версии. Именно так я запустил телефорк в своей демо-версии трассировки путей, поскольку процедура получения количества ядер CPU в glibc проверяет текущее время с помощью vDSO для кэширования количества. Но чтобы действительно правильно всё реализовать, нужно либо исправить все функции vDSO, чтобы просто выполнить инструкции syscall, как это делаетrr, либо исправить каждую функцию vDSO на переход к функции vDSO из процесса донора.
- Восстановление
brkи других состояний. Я попытался использовать метод из DMTCP, но он работает только в том случае, если целевойbrkбольше, чемbrkдонора. Правильный способ, который восстанавливает ещё и другие вещи, — этоPR_SET_MM_MAP, но для него нужно повышение привилегий и флаг сборки ядра.
- Восстановление локального хранилища потоков. Локальное хранилище потоков в Rust «просто работает», вероятно, потому что восстанавливаются регистры FS и GS, но, судя по всему, существует какой-то кэш
glibcдля pid и tid, который не совместим с другими типами локального хранилища потоков. Как вариант из CRIU, можно рассмотреть восстановление процесса с теми же PID и TID через нестандартное пространство имён.
- Восстановление некоторых файловых дескрипторов. Это можно сделать либо с помощью отдельных стратегий для каждого типа файлового дескриптора, например, проверяя, существует ли файл с тем же именем/содержимым в целевой системе, либо перенаправляя все операции чтения/записи в исходную систему процесса с помощью FUSE. Но это требует огромных усилий для поддержки всех типов файловых дескрипторов, таких как запуск TCP-соединений, поэтому DMTCP и CRIU просто аккуратно реализуют наиболее распространённые типы и не поддерживают остальные, такие как дескрипторы
perf_event_open.
- Обработка нескольких потоков. Обычный
fork()в Unix этого не делает, но он должен просто остановить все потоки перед потоковой передачей памяти, затем скопировать их регистры и восстановить их в потоках клонированного процесса.
Ещё более безумные идеи
Думаю, вы уже поняли, что при наличии правильных низкоуровневых интерфейсов можно реализовать некоторые сумасшедшие вещи, которые кому-то казались невозможными. Вот некоторые мысли, как развить основные идеи telefork. Хотя многое из перечисленного, наверное, полностью можно реализовать только на полностью новом или исправленном ядре:
- Кластерный телефорк. Первоначальным источником вдохновения для telefork была идея потоковой передачи процесса на все машины в вычислительном кластере. Возможно, получится реализовать даже UDP-мультикаст или одноранговые методы, чтобы ускорить распределение по всему кластеру. Вероятно, вы также захотите иметь примитивы коммуникации.
- Ленивый поток памяти. CRIU отправил патчи для ядра, чтобы добавить что-то под названием
userfaultfd. Эта функция умеет ловить ошибки страниц и более эффективно выполняет сопоставление на новые страницы, чем обработчикиSIGSEGVиmmap. Она позволит передавать новые страницы памяти только тогда, когда они доступны программе, что даёт возможность телепортировать процессы с меньшей задержкой — они начинают работать практически сразу.
- Удалённые потоки! Вы можете прозрачно заставить процесс думать, что он работает на машине с тысячью ядер. Вы можете использовать
userfaultfdплюс набор патчей для защиты от записи userfaultfd, который как раз смерджили в начале апреля, чтобы реализовать алгоритм когерентности кэша, такой как MESI, чтобы эффективно реплицировать память процесса через кластер машин. В этом случае память нужно будет передавать только тогда, когда одна машина прочитает страницу, в которую другая машина записала информацию с момента последнего чтения. Тогда потоки — это просто наборы регистров, которые можно очень дёшево распределить между машинами через регистры пулов потоков ядра. Разумно перераспределить потоки так, чтобы они работали на той же машине, что и другие потоки, с которыми они взаимодействуют. Вы даже можете запускать системные вызовы: для этого приостанавливаем выполнение syscall, переносим поток на исходную хост-машину, выполняем там syscall, а затем переносим его обратно. Примерно так работает ваш многоядерный процессор, только мы используем страницы вместо линий кэша и сеть вместо шины. Те же самые методы, как минимизация совместного использования между потоками, которые работают в параллельном программировании, будут эффективными и здесь. Я думаю, что это действительно может быть очень круто, хотя для бесперебойной работы может потребоваться дополнительная поддержка ядра. Но в итоге вы будете программировать распределённый кластер так же, как вы программируете многоядерную машину, и (с кучей оптимизационных трюков, о которых я ещё не писал) она вполне сможет сравниться с обычной распределённой системой, которую пришлось бы строить в противном случае.
Заключение
Мне это действительно очень нравится, потому что здесь пример одной из моих любимых техник — нырнуть на менее известный слой абстракции, который относительно легко выполняет то, что мы считали почти невозможным. Телепортация вычислений может показаться невозможной или очень сложной. Вы могли подумать, что она потребует таких методов, как сериализация всего состояния, копирование двоичного исполняемого файла на удалённую машину и запуск его там со специальными флагами командной строки для перезагрузки состояния. Но нет, всё гораздо проще. Под вашим любимым языком программирования лежит слой абстракции, где вы можете выбрать довольно простое подмножество функций — и за выходные реализовать телепортацию большинства чистых вычислений на любом языке программирования в 500 строчках кода. Думаю, что такие погружения на другой уровень абстракции часто приводит более простым и универсальным решениям. Ещё один из моих проектов, похожих на этот, — Numderline.
На первый взгляд такие проекты кажутся экстремальными хаками, и в значительной степени так оно и есть. Они делают вещи так, как никто не ожидает, а когда ломаются, то делают это на уровне абстракции, на котором вроде как не должны работать подобные программы — например, таинственно исчезают ваши файловые дескрипторы. Но иногда вы можете правильно установить уровень абстракции и закодировать любые возможные ситуации, так что в итоге всё будет работать плавно и волшебно. Думаю, что хорошими примерами здесь являются rr (хотя telefork умудрился его засегфолтить) и облачная миграция виртуальных машин в реальном режиме времени (по сути, телефорк на уровне гипервизора).
Мне также нравится представлять эти вещи как идеи альтернативных способов работы компьютерных систем. Почему наши API для кластерных вычислений намного сложнее, чем простая программа, которая транслирует функции в кластер? Почему сетевое системное программирование намного сложнее многопоточного? Конечно, вы можете привести всевозможные веские причины, но они обычно основаны на том, насколько трудно это сделать, на примере существующих систем. А может при правильной абстракции или при достаточных усилиях всё будет работать легко и незаметно? Принципиально тут нет ничего невозможного.

