Здравствуйте, уважаемые посетители Хабра!
В этой статье речь пойдёт о связном списке, многопоточности и С++. Сразу отмечу, что были все шансы положить эту работу «на полочку» и использовать в небольшом количестве личных проектов. Вместо этого я всё-таки решил выложить её на суд общественности – вдруг это действительно покажется кому-нибудь полезным или интересным. Более того, если окажется, что кто-нибудь когда-нибудь уже успел сделать что-нибудь подобное, укажите мне эти материалы, пожалуйста. Однако сколько я ни пытался гуглить на эту тему, все попытки были безуспешны.
Также отмечу, что речь пойдёт не о классическом связном списке, а о моём творческом переосмыслении использования этой структуры данных в многопоточном окружении. Я рассматривал сценарий неупорядоченного интенсивного многопоточного обращения к списку. Это означает, что любой поток в любой момент независимо от других может получить доступ к списку и произвести требуемые операции. Если он только добавляет или изменяет элементы, это ещё полбеды. Если же он ещё и удаляет элементы, могут возникнуть различные интересные особенности.
Этот проект, которым я занимался на правах хобби и саморазвития, по ряду причин растянулся на весьма длительный срок. Кроме того, по мере работы над ним я интенсивно учился: проект начинался без знания и понимания STL и проектировался соответственно, используя только внутренние средства собственно языка С++. Однако потом я весьма серьёзно его модифицировал с учётом STL и даже под STL. Что у меня из этого получилось, судить вам, уважаемые читатели.
Для наиболее полного понимания описываемого здесь материала вам потребуется познакомиться со следующими книгами:
Линейный список – известная структура данных, применяемая ещё со времён языка С и ранее. Его элемент представляет собой некоторый объект в памяти, имеющий связи с одним или двумя соседними аналогичными элементами – здесь приведён пример для двусвязного списка:
Соответственно, сам список – это некоторая (под)программа, которая выполняет манипуляции с этими элементами. Как правило, известен указатель на начало и, опционально, на конец списка: этого достаточно, чтобы, начиная с первого элемента, пройти по всем его элементам вплоть до конца.
По сути, я описываю уже хорошо изученную и известную всем информацию: это был ликбез для тех, кто совсем не в курсе. За подробностями, например, можно обратиться сюда:
Линейный список (Википедия)
В библиотеке STL есть такой замечательный контейнер std::list (двусвязный список), а также его близнец – std::forward_list (односвязный список). То есть если вам не интересно, как список устроен и функционирует внутри, а вы хотите им просто пользоваться для своих задач, предложенные контейнеры – ваш вариант.
Но есть одно но…
Повторюсь, что когда я начинал разбирать эту тему, я собирался всё сделать, полагаясь только на внутренние средства С++ без какой-либо поддержки STL. Ценность того, что получилось бы, была бы ниже, если бы я всё-таки решил рассказать об этом здесь. Но с другой стороны, я был совершенно свободен от каких-либо концепций или ограничений библиотеки, а потому был не связан ничем и искал подходы непредвзято и независимо.
Раньше, в далёкие-далёкие времена, подавляющее большинство компьютеров были одноядерными и однопроцессорными. Линейный список был относительно простой и прозрачной структурой данных, и работа с ним не вызывала особых затруднений. Сейчас же даже смартфоны стали многоядерными. В условиях многопоточности даже такая простейшая структура, как связный список, серьёзно усложняется. Обеспечение корректной работы в многопоточном режиме вообще серьёзно усложняет любую программу, это известный факт.
Возьмём некий абстрактный сценарий интенсивной работы со списком различными потоками: каждый из них в совершенно произвольный момент времени может добавлять, удалять, изменять элементы, и т.д. С одной стороны, работа со списком в этом случае должна быть прежде всего безопасной: если произойдут какие-либо нарушения данных и неопределённое поведение программы, это будет совершенно неподходящее решение. С другой стороны, очень хотелось бы, чтобы работа с ним была как можно более быстродействующей.
Для решения первой проблемы список, очевидно, придётся как-то блокировать, а также синхронизировать доступ к нему. Вторую проблему – производительность – пока отложим.
В этой статье рассматривается только блокировка всего списка потоком для осуществления монопольного доступа потока к нему. Другие варианты казались сомнительными, например, по следующим соображениям. Предположим, у нас двухсвязный список, и мы решили удалить элемент из него. Для этого надо заблокировать сам узел, а также предыдущий и последующий.
В это самое время перед началом операции другой поток удаляет как раз, например, предшествующий узел. Мы блокируем удаляемый и останавливаемся в ожидании освобождения предыдущего узла, заблокированного другим потоком. А он блокируется на ожидании последующего для него, т.е. нашего удаляемого узла. Всё, вот и взаимная блокировка. Так что этот способ не является надёжным.
Если ваши потоки не хранят какие-либо указатели (или итераторы) на конкретные узлы, то задача предельно упрощается. Фактически, можно обойтись только средствами STL. Поток блокирует список, обращается к какому-либо элементу в нём (например, с начала, с конца или посредством поиска в нём по каким-либо критериям), обрабатывает или удаляет этот элемент, добавляет какие-либо новые, не сохраняя ссылки на них, а затем завершает работу со списком. Всё это – монопольно заблокировав доступ к списку в одном потоке, единолично владея им на время требуемых операций. В этом случае совершенно логично использовать std::list и средства блокировки библиотеки. При всём при этом следует учесть, что пока ваш поток выполняет всю требуемую работу, другие потоки остановятся в ожидании, т.е. работа со списком будет осуществляться в однопоточном режиме.
Я же рассматривал другой, более сложный сценарий, когда поток хранит указатель или итератор на нужный ему элемент. Например, ваша программа работает над какими-то сложными вычислениями, взяв исходные данные из элемента списка, а затем, после обработки, обновляет его значение, добавив туда результаты вычислений. При этом другие потоки также имеют доступ к этому же списку. Я не делал каких-либо предположений о характере приложения: другой поток может легко удалить по каким-то причинам именно этот элемент. Или перенести его в другое место. Таким образом, работа со списком становится проблематичной не только по обычным соображениям многопоточности и синхронизации.
В чём фундаментальное отличие списка от, скажем, массива? В распределённом расположении элементов списка. Все элементы массива расположены в единой области памяти. Даже если вы храните указатель на какой-либо его элемент, вы точно уверены, что обращение по его адресу будет корректным (разумеется, если массив не был перемещён в памяти в другое место с расширением его размера, например). Если нужный вам элемент удалили или переместили в другом потоке, вы просто обратитесь по прежнему адресу, поймёте по каким-либо признакам, что нужного вам элемента здесь нет, затем попробуете поискать его и т.д. Разумеется, программа должна заранее поддерживать такую возможность. Но, в любом случае, её работа останется корректной, пока вы находитесь в корректных пределах памяти.
Совсем другая ситуация – в случае списка (а также в случае дерева, графа – любой структуры данных с распределёнными элементами). Если элемент по вашему указателю удалили в другом потоке, вы об этом даже не узнаете, и при попытке обращения по его адресу получите нарушение доступа (в лучшем случае). Даже если он не будет фактически удалён из памяти (например, в случае использования интеллектуальных указателей), он будет удалён из списка, т.е. не будет являться его частью. Вы об этом также не узнаете. Корректная работа со списком нарушается.
При этом интенсивная многопоточная работа со списком создаёт совершенно фантастические сценарии. Вы можете даже быть уверены, что с вашим элементом и указателем на него всё нормально – вплоть до обращения к какой-либо функции списка для работы с ним.
Пример. Пусть есть часть списка, и в некоторую функцию-метод списка передаётся указатель на узел, который обозначим как (#), в то время как узлы, связанные с ним, будем обозначать относительными по отношению к нему номерами. На момент вызова функции известно, что этот элемент существует и указатель на него корректен, то есть состояние списка в этой области такое:

Пусть теперь узел (#) передаётся как параметр в некоторую функцию списка. Эта функция, как водится, блокируется в ожидании доступа к нему. Пока она ждала, до неё поработали три потока, удалившие узел (#) вместе с прилежащими к нему так, что получилось:

Затем ещё 5 потоков вставили ещё 5 элементов в список, начиная с (-2). Обозначим новые элементы как (nN), где N — относительный среди этих пяти номер, начиная с нуля:

Тут наконец получает время наш поток, который вызывали с (#). Вопрос такой: что ему делать в этом случае, ведь (#) уже давно нет?
Ответ: всё сильно зависит от операции, а также от сценария использования списка. Однако, поскольку мы рассматриваем самый общий случай без каких-либо ограничений, можно сделать некоторые общие предположения.
Если это операция удаления, то достаточно просто проверить, присутствует ли заданный элемент в списке. Если нет, то его уже удалили, и больше ничего делать не нужно. Если да, то удалить. Аналогично — для операции чтения/изменения содержимого узла: если узел удалён, то читать/изменять уже нечего. А вот самые большие проблемы возникают при операциях вставки нового узла, а также при перемещении к следующему/предыдущему. С одной стороны, указанного узла уже нет, и можно вернуть неудачу. С другой — узел должен быть вставлен, и такая ситуация может возникнуть в любой момент.
Поскольку приоритетом (для общего случая) всё же безопасность и надёжность, а только потом быстродействие, то, очевидно, когда поток наконец получил время работы внутри функции, то придётся устанавливать факт присутствия элемента в списке: а он вообще есть там ещё или уже нет? Это решает одну проблему: по крайней мере, мы не нарушим работу всего списка в случае отсутствия запрошенного узла там и избежим ошибок доступа к памяти в связи с этим. Но не решает проблему вставки и переходов: непонятно, куда теперь вставлять новый узел и переходить от уже удалённого.
Решение проблемы существования элемента будет подробно рассматриваться далее. Вопрос же, что делать, когда мы обнаружили, что элемента уже нет, а он очень нужен, выходит за рамки этой статьи, поскольку это целиком зависит от алгоритма работы использующей список программы. Разумеется, она должна предусматривать такие сценарии и соответствующие реакции на них: например, если элемента нет, то перейти к началу списка или выполнить какую-нибудь другую операцию. Главное, что нужно обеспечить в этой ситуации – это корректную и безопасную работу списка, а также уведомление о подобных ситуациях.
Самый простой и прямолинейный подход – это проверка присутствия элемента в списке посредством последовательного прохода по нему в поиске заданного элемента. Т.е. просто ищется данный элемент. Если он в списке есть, мы работаем с ним. Если же нет, то, в зависимости от функции, выходим с успехом или неудачей, и пусть вызывающая программа принимает решение, что делать в этой ситуации. Главное, что работа со списком в любом случае будет корректной.
Этот способ безопасен и вполне работоспособен, но, особенно для списков большого размера, приводит к катастрофическому падению производительности. Фактически, работа со списком оказывается однопоточной: список блокируется на время поиска заданного элемента в нём, и другие потоки не могут получить к нему доступ. Во-вторых, резко повышаются накладные расходы – в каждой операции со списком приходится проверять, есть ли нужный на момент операции элемент, и огромная доля времени уходит не на полезную работу, а на проверку наличия элемента. Тем не менее, этот простой незамысловатый подход вполне годится для списков малого объёма и не слишком интенсивных операций с ним, а также в качестве первого приближения к решению проблемы существования элемента.
Но что делать, если у нас список с большим количеством элементов, а работа с ним весьма интенсивная: множество потоков постоянно добавляют, изменяют и удаляют элементы из него? Есть ли способ как-нибудь ускорить его работу?
Есть известный факт, что увеличение используемой программой памяти может увеличить скорость работы программы. Например, программа интенсивно использует результаты каких-то вычислений. Вместо того, чтобы каждый раз выполнять их заново, можно всё вычислить заранее и сохранить их результаты в какой-нибудь таблице или массиве. Затем программа просто обращается в нужную ячейку таблицы и сразу получает нужное значение, что существенно ускоряет её работу.
Именно этот подход я и использовал в случае списка. Создадим битовый массив. Добавим в служебную информацию каждого его элемента, помимо обязательного указателя на следующий и, опционально, предыдущий элементы ещё два новых поля: первый – это его уникальный номер в пределах этого списка, а второй – это указатель на сам список. Теперь, когда элемент создаётся, ему присваивается уникальный номер, и в битовом массиве по соответствующему индексу устанавливает единица. Когда элемент удаляется, этот бит обнуляется. Номер создаваемого элемента постоянно увеличивается при каждом создании нового элемента – уже использованные обнулённые биты не используются повторно.
Теперь, когда требуется проверить наличие заданного элемента, вместо линейного поиска его во всём списке просто происходит обращение к битовому массиву по индексу этого элемента в нём, и факт его наличия сразу устанавливается, причём за константное время, не зависящее от размера списка.
Этот способ позволяет достичь максимального быстродействия, однако он имеет свои серьёзные недостатки. Первый – придётся выделить память под весь массив сразу, часть бит которого может вообще не понадобиться за время работы программы, но эту память можно было бы использовать на другие нужды. Эту проблему и способ сгладить перерасход памяти рассмотрим чуть ниже.
Второй недостаток серьёзнее и интереснее – каждый новый элемент списка создаётся по монотонно возрастающему номеру. Это означает, что рано или поздно свободные биты массива будут исчерпаны.
В этот момент, к сожалению, придётся остановиться, заблокировать список и начать его обслуживать. Т.е. сжать биты этого массива, удалив все нулевые биты от промежуточных ранее удалённых элементов списка, оставив только биты для реально существующих в данный момент элементов, сместив все эти биты к началу массива. Придётся опять пройти по всему списку, причём в однопоточном режиме, переписав все индексы для каждого элемента. Очевидная выгода этого по сравнению с предыдущим подходом в том, что в данном случае это будет выполняться всего один раз за длительный период времени. Далее список может продолжать работу как прежде в предельно быстродействующем режиме.
Разумеется, я не имею ввиду, что в список узлы только добавлялись, т.к. в этом случае все биты массива будут единичными. Я рассматриваю сценарий, когда элементы интенсивно и произвольно удаляются и добавляются. Т.е. общее количество элементов списка с начала его работы может измениться незначительно. Естественно, вопрос выбора объёма массива зависит от характера работы программы. Также всегда можно создать новый массив большего объёма, если размера текущего не хватает.
Можно поступить и по-другому: при создании элемента искать первый нулевой бит с начала битового массива. Это оптимизирует расход памяти, но приведёт к падению производительности: теперь опять каждый раз при создании нового элемента придётся выполнять дополнительную работу – просматривать массив в поисках свободного бита. Но по сравнению с проверкой наличия элемента прямым просмотром списка выигрыш налицо: мы будем просматривать массив рядом расположенных элементов, причём каждый элемент такого массива содержит множество бит, т.е. мы обрабатываем множество узлов списка за раз (64 бита для современных систем или даже 128/256/512 в случае использования SSE/AVX). Ищем первое слово, не равное слову со всеми единичными битам, далее ищем первый нулевой бит в этом слове. Фактически, этот метод – промежуточный по быстродействию между предыдущим и методом прямого просмотра.
Допустим, мы предполагаем длительную и интенсивную работу со списком, выделив для него огромный массив бит. Но так получилось, что фактически программа работала иначе: обращалась к списку редко, выполняла другие операции, которым тоже требуется память. В результате получаем почти неиспользованный массив бит огромного объёма и проблемы с памятью в других частях программы. Сплошные неудобства!
Linux, насколько я могу судить, автоматически решает эту проблему (хотя опытные разработчики-линуксоиды пусть меня поправят, если что). Вы выделяете память под массив, но фактически система эту память массиву не передаёт до тех пор, пока она реально не понадобится. Происходит оптимизация использования памяти. Windows такого делать не позволяет. Вернее, позволяет, но это придётся делать своими руками.
Для тех, кто совсем не в курсе, поясню: вашему приложению (точнее, соответствующему ему процессу), система выделяет виртуальное адресное пространство большого объема – вплоть до 8 Тб для 64-разрядной Windows. Физической памяти в системе может быть намного меньше – 8 или 16 Гб на данный момент для массовых компьютеров. Операционная система отображает адреса вашего виртуального пространства процесса на адреса физической памяти, делая это прозрачным образом без вашего прямого участия. Естественно, большая часть свободной виртуальной памяти процесса оказывается обычно незанятой. Так вот, когда вы просите Windows выделить память обычными средствами, она эту память одновременно выделяет как в вашем виртуальном пространстве, так в физической памяти. Если вы выделите битовый массив большого объёма, вы рискуете сразу занять всю доступную память на вашей машине без гарантии, что эта память вообще может понадобиться.
Однако можно поступить и по-другому: разметить огромный участок памяти в виртуальном пространстве процесса, но передавать ему физическую только тогда, когда она реально нужна. Сделать это можно посредством структурной обработки исключений в Windows, за подробностями прошу обратиться в книге Рихтер Д., Назар К. – «Windows via C/C++, Программирование на языке Visual C++».
Это было бы только идеей и теорией, если бы я не реализовал все эти идеи на практике, причём не в виде простенькой экспериментальной программы: я делал её максимально тщательно как для production, намереваясь использовать в своих реальных проектах, поэтому именно в таком виде вам её и представляю. Подумал, что было бы несправедливо и слишком эгоистично применять сделанное в своём ограниченном количестве проектов, если это может оказаться полезным или хотя бы просто интересным широкому кругу разработчиков. С другой стороны, создатели библиотеки Boost и других более специализированных библиотек предлагают свои работы всем желающим абсолютно бесплатно. Почему я не могу поступить таким же образом?
Я разделил список на два логических уровня. Первый уровень – это список, каждый элемент которого не содержит никаких полезных данных, а содержит только служебную информацию: указатели на соседние элементы, а также, опционально, те два дополнительных поля для ускорения проверки наличия элемента в списке. Однако уже на этом уровне возможно выполнять все базовые операции над списком: добавление и удаление элементов, разбиение и объединение списков и т.д. Фактически, я сконцентрировался прежде всего на этом уровне.
Второй уровень – это добавление фактических данных к элементу списка, а также добавление новых операций в список для работы с этими данными. Всё это обеспечивается в С++ путём наследования. Но о деталях пойдёт речь ниже.
Такое разбиение реализации на два уровня имело свой смысл: зачем учитывать наличие конкретных данных, если целый ряд операций никак не зависит от этих данных? Для любых данных элементов списка всё равно придётся удалять их и добавлять новые в список, а также выполнять другие типичные операции.
Начинал я с предельно простой и незамысловатой концепции, взятой ещё из приведённой в начале статьи конструкции из языка С. Как внутри, так и вне списка применяются внутренние указатели C/С++. Разница была лишь в том, что добавление данных, как было указано выше, отложено на более поздний срок.
Пусть есть элемент списка без данных, содержащий лишь указатель (или указатели) на соседний/-ие элемент(ы). Тогда соответствующий код для него схематично можно представить так:
Элемент для односвязного списка содержит внутри себя указатель на следующий элемент, и только. Класс списка параметризуется типом этого элемента, подразумевая, что этот тип будет изменён на стадии добавления данных. Он содержит внутри себя указатели на первый и последний элементы. Поскольку я исходно нацеливал этот проект только для Windows, то также включена критическая секция типа SRWLock для блокировки списка. Далее определяются конструкторы, деструктор, а также все необходимые функции для работы со списком.
Данная реализация содержит сразу две проблемы.
Первая – открытый доступ к содержимому служебной информации элемента. Это означает, что, получив доступ к какому-либо узлу, т.е. имея указатель на этот узел, мы можем непосредственно обратиться к последующему или предыдущему элементу.
Однако при многопоточной работе со списком это недопустимо.
Это недопустимо главным образом потому, что этот переход осуществляется в обход блокировки и, следовательно, защиты списка. В самом деле, предположим, имея указатель на некоторый элемент pCurr, мы сохранили значение на следующий относительно него элемент в указателе pNext следующим образом: pNext = pCurr->pNext. После этого выполняем некоторую длительную операцию над данным узлом pCurr. В это же время другие потоки удалили следующие относительно pCurr элементы списка. Закончив работу с pCurr, текущий поток переходит к следующему элементу, используя старое значение, сохранённое в локальной pNext, и получает ошибку доступа либо неопределённое поведение, поскольку элемента по адресу локального pNext уже не существует, и нужно обращаться к обновлённому значению pCurr->pNext, если текущий элемент по адресу pCurr, в свою очередь, тоже вообще ещё существует.
Из этого примера можно сделать два вывода для предотвращения этой ситуации:
Именно поэтому для реализации вывода из первого пункта следует запретить доступ к указателям на смежные элементы извне:
Вторая проблема несколько деликатнее. Чтобы понять её, следует структуру классов описать более подробно. Класс списка определён как шаблонный и работает не с элементами типа ListElement_OneLinked, а с типом ListElement, передаваемым в качестве параметра шаблона. Это сделано для того, чтобы иметь возможность создавать внутри класса новые узлы с данными. Для того, чтобы делать это, нужно знать точный тип создаваемого узла. Точный тип узла списка пока ещё не известен: он будет определён позже вместе с данными. Функция создания элемента выделяет память для него, инициализирует указатели, а затем возвращает указатель на созданный элемент в вызывающую функцию. Так в вызывающей функции производного класса можно будет провести инициализацию других, специфичных для этого класса и доопределённых позже свойств элемента. Иными словами, точное определение типа узла списка оставлено на будущее, и для того, чтобы список корректно функционировал, важно лишь, чтобы его элементы содержали указатель pNext, остальное пока не имеет значения.
Таким образом, на базе ListElement_OneLinked впоследствии путём наследования будет создан новый класс для элемента с конкретными данными и передан классу List_OneLinked через параметр шаблона. Одновременно на базе List_OneLinked будет создан новый производный класс, доопределяющий операции с этими новыми данными.
Однако даже такой вариант не является совсем корректным. В ранних версиях класса списка несколько раз применялась операция явного преобразования типа reinterpret_cast<ListElement *>(...). Дело в том, что шаблонный класс работает с типом-параметром шаблона ListElement, который является производным от ListElement_OneLinked/ListElement_TwoLinked. А в функциях класса создаются переменные в выражениях типа:
ListElement *pNext = pCurr->pNext;
Причём pCurr->pNext здесь — это указатель на ListElement_OneLinked/ListElement_TwoLinked, как члены базовых классов.
Выход: либо объявлять переменную, указывая явный базовый тип ListElement_OneLinked/ListElement_TwoLinked, либо приводить её к производному типу явно.
На самом деле даже явное определение базового типа не является корректным, например, в функции удаления (очистки) списка:
Если изменить тип указателей:
то это будет означать, что будут удалены операцией
только базовые части каждого узла списка, что неправильно. Либо, как вариант, придётся уже указатель pCurr приводить к его производному типу:
Таким образом, в любом случае от явного преобразования reinterpret_cast при такой структуре классов не избавиться, что не является лучшим решением (точнее, что совсем нехорошо на самом деле).
По этой причине, чтобы избавиться от таких вот явных преобразований, было решено изменить базовый класс для элемента (для двусвязного списка – аналогично):
Кратко это можно охарактеризовать так: базовый элемент списка содержит указатель на другой элемент, но тип этого указателя ещё пока не известен, потому как передаётся параметром шаблона (точное определение этого типа оставлено на будущее). Иными словами: на данном этапе тип узла списка (т.е. каким он будет в итоге) ещё не определён, он будет определён позже. Но сейчас мы сохраняем указатель на элемент будущего, пока ещё не известного, типа. Итоговый тип узла списка передаётся сюда как параметр шаблона.
Теперь не потребуется никаких преобразований, поскольку везде – и в классе списка, и в классе для узлов – используются указатели одного типа ListElement. ListElement здесь и в классе списка – это итоговый класс для элемента с конкретными данными.
Это означает, что теперь класс списка стал максимально абстрагированным от конкретного его содержимого: известно лишь, что его узлы содержат указатели на другие такие узлы, и, пользуясь этой информацией, в классе списка выполняются все базовые операции над ними с соответствующей многопоточной блокировкой.
Первая версия была предельно простой и незамысловатой и не выходила за описанные выше рамки. Использовались внутренние указатели С++, память для элементов выделялась посредством операции new и удалялась с помощью delete, список блокировался на содержащейся в нём критической секции. О средствах библиотеки STL я не знал и не подозревал, а также о том, на какой уровень они выводят программирование на С++.
Уже на этом этапе я на практике столкнулся с описанной ранее проблемой существования элемента и понял, что простой блокировки списка недостаточно. Я перемещался по списку с помощью соответствующих функций со всеми мерами предосторожности, список корректно блокировался, но программа всё равно успешно падала с разной периодичностью. Именно тогда я выяснил, что наличие элемента придётся проверять, что привело к изменению логики ключевых функций.
Приведу в пример функцию добавления элемента после заданного:
Видно, что прежде чем создать новый элемент, она проверяет, присутствует ли в списке заданный элемент, вызывая функцию FindElement(…):
Изначально проект нацеливался строго на Windows. Но в какой-то момент я подумал, почему бы не добавить ему гибкости? Почему только Windows? Ведь список реализовывался по сути на чистом С++, от Windows у него было только одно: критическая секция SRWLock. К тому моменту я уже познакомился с концепцией классов стратегий. Об этом вы можете подробно почитать в книге Александреску А. – «Современное проектирование на С++». В ней описаны многие необычные и потрясающие вещи, которые могут быть полезны даже сейчас несмотря на то, что книге уже 12 лет.
Одна из них – это классы стратегий. Классы стратегий, по сути, – это и есть изменений поведения класса посредством шаблонов, о чём упоминал Б. Страуструп в своей известной книге. Только в книге Александреску эта тема широко раскрывается.
Предположим, ваш класс выполняет одно какое-то строго определённое действие. Вы можете вынести определение этого действия за пределы класса, создать на основе этого действия отдельный класс и передать его в ваш исходный класс в качестве параметра шаблона. Это усложняет код, его чтение и понимание, но зато существенно добавляет вашему классу гибкости: чтобы заменить данное конкретное действие каким-то другим, аналогичным, вам достаточно просто будет написать другую подобную стратегию и передать её вашему классу в качестве параметра шаблона. Всю остальную работу сделает за вас компилятор.
Применяя это к описываемому списку, я вынес блокировку через SRWLock в отдельную стратегию, а затем написал несколько других стратегий: через обычную критическую секцию Windows, через мьютексы С++ STL и т.д. Потом можно будет добавить чисто специфичные для Linux методы. Таким образом, класс стал подходящим не только для Windows, но я всегда могу очень быстро перенастроить его обратно для Windows оптимальным образом, просто указав нужную стратегию.
Примерно к этому моменту я также серьёзно взялся изучать STL и в числе первых средств этой библиотеки познакомился с интеллектуальными указателями. А затем подумал: почему я не могу добавить поддержку интеллектуальных указателей в свой список? Тогда я вынес тип указателя, а также создание и удаление данных элемента списка в отдельную стратегию:
Аналогичная стратегия для интеллектуальных указателей:
Стратегия памяти принимает три параметра: тип объекта Type, а также распределитель и удалитель памяти. На основании типа объекта стратегия создаёт тип указателя на этот тип – либо Type *, либо std::shared_ptr, в зависимости от стратегии, а также предлагает соответствующие функции создания и удаления объекта. Эти функции, если говорить о распределителях и удалителях по умолчанию, создают объект либо через операцию new Type, либо через функцию std::make_shared(…). Всё это работает благодаря тому, что разыменование указателя происходит одинаково как для встроенного указателя С++, так и для интеллектуального std::shared_ptr. Конечно, в случае двусвязного списка и интеллектуальных указателей, чтобы избежать неприятной особенности зацикливания указателей, для указателей на предыдущий элемент используется std::weak_ptr, и во время компиляции для двусвязного списка в зависимости от выбранной стратегии памяти выбирается, как его разыменовывать (это – новая особенность С++17):
Таким образом, теперь список не создаёт самостоятельно свои элементы: он перенаправляет вызов соответствующей стратегии.
Разумеется, и решение проблемы существования элемента я вынес в отдельную стратегию: если списку требуется проверить наличие какого-то его элемента, он просто переадресует вызов соответствующей стратегии. Самый первый, незамысловатый и топорный подход стал стратегией прямого поиска DirectSearch. Далее я разработал ещё две стратегии на основе двух описанных ранее подходов с битовым массивом в порядке их описания: SearchByIndex_BitArray и SearchByIndex_BitArray2. Для Windows для возможности постепенного занимания памяти битовым массивом по мере его заполнения также добавил ещё две стратегии:
SearchByIndex_BitArray_MemoryOnRequestLocal и SearchByIndex_BitArray2_MemoryOnRequestLocal.
Как было отмечено ранее, для работы этих продвинутых стратегии требуется, чтобы элемент списка содержал в себе индекс в битовом массиве и указатель на базовый класс списка (об этом см. ниже), т.е. был определён следующим образом:
При подробном рассмотрении оказалось, во взаимоотношениях стратегии памяти со стратегиями проверки наличия элемента присутствует подводный камень.
Предположим, вы используете интеллектуальные указатели в качестве стратегии памяти, а также стратегию с использованием битового массива для ускоренной проверки наличия элемента в списке. Вы удаляете элемент, стратегия памяти сбрасывает его указатель. При этом этот элемент фактически не удаляется из памяти, поскольку у вас в вашей вызывающей программе есть другой интеллектуальный указатель на него. В дальнейшем вы обращаетесь к списку с этим элементом, и он совершенно корректно делает проверку, обращаясь к его данным – индексу в битовом массиве и указателю на список. Элемент фактически удаляется из памяти только тогда, когда больше не осталось нигде никаких ссылок на него.
Совсем не то происходит в случае использования встроенных указателей С++. В этом случае стратегия памяти действительно удалит этот элемент из памяти с помощью операции delete. В дальнейшем вы, как и в предыдущем случае, обратитесь к списку с этим элементом, и он попытается обратиться к элементу по этому адресу в целях считать индекс битового массива и указатель на список. А этого делать нельзя: элемент ведь уже удалён из памяти! В лучшем случае вы получите нарушение доступа, в худшем – неопределённое поведение, когда библиотека С++, библиотека времени выполнения или просто операционная система запишет туда совершенно произвольное значение, которые считает список и попытается установить по ним факт присутствия элемента в списке.
Таким образом, получается, что внутренние указатели совместимы только со стратегией прямой проверки DirectSearch, а интеллектуальные указатели в данном случае предлагают не только присущую им безопасность, но и увеличение производительности: ведь только с их использованием можно применять битовые массивы, которые существенно увеличивают работу списка в многопоточном режиме!
Чтобы гарантировать соответствие и исключить несовместимые конфигурации стратегий, я включил в каждый класс списка следующую проверку:
Она сравнивает переданные в список классы стратегий и, в случае их несовместимости, останавливает компиляцию с соответствующим выводом сообщения об ошибке.
Исходно обработка ошибок списка осуществлялась только посредством исключений. Но как-то на каком-то уже не помню форуме я вычитал, что исключения замедляют программу, и для максимальной производительности следует использовать традиционный возврат ошибок. Так и сделал, создав два новых класса на основе исходных, только переписав их под возврат ошибок.
Реализация описанных выше стратегий проверки наличия элементов выявила одну важную проблему. Элемент списка, как мы помним, содержит помимо уникального в данном списке номера ещё также указатель на этот список: ведь у нас может быть в программе два и более списков, каждый из которых содержит собственный битовый массив флагов наличия элемента. Как убедиться, что данный элемент принадлежит именно данному списку, а не другому? Только посредством хранения указателя на весь список внутри каждого элемента.
Проблема в том, что теперь за счёт добавления разнообразных стратегий в наш класс списка мы существенно усложнили его тип. Допустим, у нас есть два разных списка с одинаковым типом элемента и одинаковой стратегий памяти, но с разными стратегиями блокировки и проверки наличия элементов в них. Для компилятора это будут два разных типа списков. Указатель на какой тип хранить в элементе? Причём класс для элемента заранее не знает, какая именно стратегия будет применяться, он должен учесть их все.
Вспомним также, что и стратегия блокировки, и стратегия проверки наличия элемента, и даже связность (односвязный или двусвязный) списка относятся только к характеру поведения самого списка, но никак не относятся к хранимым им данным. А ведь нас как конечных пользователей этого класса интересуют именно данные! Так что, с одной стороны, использовав классы стратегий, мы добавили себе гибкости, а с другой – усложнили себе жизнь и добавили проблем.
Можно ли всё-таки как-нибудь сделать так, чтобы и волки были сыты, и овцы целы?
Можно. Можно вывести указатели на данные из класса (т.е из типа) списка. Помимо указанных прежде двух уровней организации списка появился ещё один – нулевой:
Теперь, т.к. реальные классы списков наследуются от него, если мы хотим обратиться к данным списка вне зависимости от его реального типа, нам следует обратиться к его базовому классу ListBase. Получаем доступ к началу и концу списка, а затем работаем с его данными как хотим. Конкретный тип списка, а также комбинация используемых в нём стратегий значения не имеет.
Уже вовсю плотно работая с STL в реальном проекте (не моём :) ), а также продолжая изучать его в книгах, я обратил внимание на цикл for по коллекции. Ведь этот цикл – не просто часть STL, он стал уже внутренней частью языка. Я подумал, что тоже могу добавить поддержку его в свой проект.
Для этого необходимо добавить поддержку итераторов, абстрагируясь от конкретного способа работы с указателями и переходу по списку.
Пример итератора:
Теперь стало возможным написать следующим образом:
leValue имеет тип указателя на элемент списка.
Первоначально я внёс поддержку итераторов только в списки с поддержкой исключений.
Причина была проста: поскольку код внутри цикла недоступен, то корректно обработать ошибки не представляется возможным. Остаётся только обрабатывать исключения, обернув цикл в блок try. Вообще, ходить по списку таким образом, когда с ним интенсивно работают другие потоки, является не лучшей идеей: лучше заблокировать список самостоятельно, а затем спокойно пройти по нему в однопоточном режиме. Но всё-таки если зачем-то требуется сделать именно так, как в примере выше, то теперь и для этого есть возможность.
На самом деле я изначально планировал (и до сих планирую) сделать не только многопоточный список, но также ещё и дерево. Для некоторых своих нужд. Граф тоже можно, но во-первых, он мне не был нужен, а во-вторых, граф – штука сложная и с весьма нетривиальными алгоритмами, а мне не хотелось погружаться в это без особой нужды.
В первоначальном варианте стратегия проверки наличия элемента была ориентирована только на список, и её функции принимали указатель на элемент и указатель на базовый класс списка (ListBase *). Впоследствии я подумал: но ведь в случае дерева придётся делать ровно то же самое! Делать отдельную, но по сути точно такую же стратегию?
Решение было простое: абстрагироваться от списка. Это означало, что теперь на вход будут поступать не указатели на элементы, а итераторы. А функции станут шаблонными, чтобы принимать указатели на контейнер любого подходящего типа.
Так что теперь исходная функция, например, регистрации списка в битовом массиве
Превратилась в функцию регистрации контейнера:
Переход по списку по указателям трансформировался в переход по абстрактному контейнеру посредством итераторов. Теперь для дерева достаточно будет реализовать свои итераторы, и его поддержка данными стратегиями будет уже обеспечена.
Это потребовало вернуть итераторы в списки без исключений, но сделать их недоступными извне и предназначенными только для внутреннего использования.
Достаточно интенсивно поработав с STL, а также набирая, запуская и изучая учебные программы из книг, я обратил внимание на простоту работы с контейнерами STL.
Например, обратите внимание на следующий код:
Я создаю вектор, передав ему нужный мне тип int, и всё! Контейнер сразу готов к работе, если мне не нужно изменить какие-то дополнительные параметры, заданные по умолчанию, что чаще всего не происходит! У меня же, исходя из трёхуровневой организации списка, в каждом случае пришлось бы сначала создавать новый класс для элемента, а затем – писать класс для списка с данными, реализуя специфичные для итогового списка операции. Представляете, сколько работы! А если вам понадобится создать другой список для других данных, придётся проделывать всё заново или, на крайний случай, копировать предыдущий код, слегка его изменяя. Это уже напоминает ту самую возню с языком С и Windows API, где для каждого элементарного действия приходится заполнять все нужные данные для структуры, а затем вызывать нужную функцию. И либо постоянно держать всё это в голове, либо также постоянно читать MSDN, изучая аргументы каждой новой функции! Рутинно и страшно неудобно!
Я стал искать способы, как получить возможность создавать свой список по аналогии с контейнерами STL, чтобы не пришлось каждый раз заново выполнять одну и ту же рутинную работу: создавать отдельный класс для любого нового элемента, а затем – отдельный класс списка по работе с элементами этого типа. Так появился адаптер для списка с данными данных.
Адаптер для списка с данными – это класс, в параметрах шаблона которого вы передаете сразу нужный вам тип данных, а не элемента. Тип элемента, который я назвал составным типом элемента, на основе этих данных он создаёт самостоятельно:
Отдельным моментом стоит упомянуть доступ к данным элемента. Тип элемента содержит операцию «*»:
Это значит, что если есть указатель на элемент pElement, то чтобы получить доступ к хранящимся в нём данным, его необходимо разыменовывать дважды:
Один раз – чтобы получить доступ к объекту типа ListElementCompound_OneLinked по его указателю: ListElementCompound_OneLinked& le = *pCurrElement, а второй раз – чтобы получить доступ к данным через операцию ‘*’: ElementData& li = *le.
Это выглядит весьма странно и нетипично, но предполагается, что вы будете работать не через указатели (для этого и так уже был готовый исходный вариант), а через итераторы.
Далее, создавая список на основе адаптера, вы указываете нужные вам стратегии, как это было ранее. Адаптер на основе всех ваших параметров автоматически создаёт нужные типы и передаёт их базовому внутреннему списку, от которого наследуется. Общее определение класса:
Специализация для списка с исключениями:
Выглядит весьма громоздко, многоэтажно и страшненько. Я знаю. Но зато это определение автоматически делает всё, что нужно, без непосредственного участия собирающегося использовать его программиста. С помощью std::conditional_t и std::is_same_v производится сравнение переданной вами стратегии проверки наличия элемента со стратегий прямого поиска и, в зависимости от результата, выбирается соответствующий тип составного элемента списка: с наличием индекса в битовом массиве и указателя на список или же без. Это позволит сэкономить вам память за счёт ненужных дополнительных данных внутри каждого узла, если вы используете стратегию прямого поиска.
Внутри класса лишь реализованы специфичные для него итераторы, а также необходимые по аналогии с STL функции push_back()/push_front(), переадресующие вызовы в базовый многопоточный список. Можно добавить и другие функции позже, чтобы список стал совсем похожим на STL'овский. Но при этом он будет со всеми необходимыми защитами и опциями по увеличению производительности в многопоточной среде.
Работа с адаптером для данных стала выглядеть так. Создание объектов списка:
Если вас устраивают все стратегии и параметры по умолчанию, то создание списка становится совсем кратким:
Как видите, внешне совершенно никакой разницы по сравнению с STL’вским за исключением того, что название класса списка другое.
Теперь работать с ним можно как по старинке, через функции базового класса:
Здесь последовательно в конец списка добавляются числа от 0 до 3. Чтобы дойти до аргумента, передаваемого в конструктор создаваемого типа при его создании, приходится явно проставлять значения первых трёх аргументов.
Да, здесь возникает определённое неудобство в явно указании типа, но это – следствие попытки опять обратиться в список через прежнюю функцию по работе с указателями. Если добавить в адаптер функцию back(), которая вернёт итератор, то при работе через него не будет такой проблемы:
После подстройки итераторов под требования STL:
становится возможным использовать список в алгоритмах библиотеки:
Разумеется, придётся организовывать перехват и обработку исключений: все примеры выше приведены для работы в одном потоке в целях тестирования совместимости с STL.
Применение алгоритмов STL делает возможным интересный момент: можно использовать сразу несколько алгоритмов одновременно, запуская их в нескольких потоках параллельно. Это невозможно сделать обычными средствами (например, используя std::list и средства блокировки), не имея доступ к внутреннему содержимому класса списка. Можно было только блокировать весь список целиком на время работы всего алгоритма. Конечно, это ускорит работу для выполняющего алгоритм потока, но сделает список недоступным для других потоков. Правда, если применять ту же «тонкую» блокировку SRWLock, можно выполнять над списком несколько алгоритмов одновременно, если они этот список не модифицируют. Но первый же поток на запись встанет в ожидании завершения операции чтения списка всеми же остальными потоками.
Предлагаемый же вариант списка позволяет организовать работу с ним более гибко. Например, вы можете организовать работу со списком так, чтобы выполнять немодифицирующие алгоритмы в первой половине списка несколькими потоками одновременно, в то время как ряд других потоков могут что-нибудь добавлять или изменять во второй половине списка. Тот факт, что список блокируется на время одной операции, а не всего алгоритма, позволит «просачиваться» операциям записи через последовательность операций чтения списка, что сделает работу с ним более гибкой, производительной и эффективной.
Первоначально списки были в варианте только с исключениями. Затем я добавил новые – без исключений с возвратом ошибок, а старые переименовал с добавлением буквы “E”в названии класса: List_OneLinked_E и List_TwoLinked_E. Это потребовало везде указывать по четыре объявления класса списка.
Затем я решил, что это неудобно по многим причинам. Зачем нам два совершенно разных класса, если это один и тот же список просто с поддержкой исключений или же без? Я объединил оба списка каждого типа в единый класс с дополнительным булевым параметром, а конкретная их реализация с исключениями и без – это две специализации единственного класса для указанного булева параметра.
Шаблонная операция объединения списков ранее работала только со списками одного типа. Она объединяла либо только односвязные списки, либо только двусвязные.
Однако, если вдуматься, то ведь совершенно неважно, списки какого типа участвуют в операции: односвязные или двусвязные. Также неважны их стратегии блокировки, какая у них стратегия проверки существования элементов, а также то, поддерживают ли они обработку исключений или нет. Всё это относится только к организации списка, но не к данным, содержащимся в нём. Важно, чтобы совпадали только тип данных и стратегия памяти для элементов. Соответственно, теперь, после объединения списков с булевым параметром относительно исключений, операция на вход принимает списки любого типа со всеми вариантами их параметров:
Теперь в качестве результирующего типа списка компилятором выбирается, в зависимости от установки внешнего параметра ce_bGetMinLinksList, список либо с минимальной, либо с максимальной связностью и, в зависимости от этого решения, используются соответствующие его параметры:
На основании выбранных параметров создаётся список результата:
Затем у этого списка указатели настраиваются на начало первого и конец второго списка:
Далее прежние списки очищаются, и производится выход из функции.
Слабым местом этой функции является двойная блокировка списков с потенциальной взаимной блокировкой:
Можно ввести некоторую функцию для одновременной блокировки двух списков за единую атомарную операцию типа std::lock(mutex1, mutex2), однако не все стратегии блокировки поддерживают одновременную блокировку двух объектов синхронизации, как std::lock(…).
Кроме того, у двух списков могут быть разные стратегии блокировки. Решение этой проблемы (если оно вообще существует) оставлено на будущее.
Компиляция проверялась через проект ListDataAdapterTest, изначально написанный на чистом C++ без специфичных для Windows особенностей, на Linux Ubuntu 16.04 LTS, компилятор g++ 8.2.0. Большинство незначительных нюансов было легко исправить, и проект успешно скомпилировался, а вывод программы совпал с аналогичным выводом под Windows. Однако это – в том случае, если закомментировать строку объединения списков через операцию «+»:
Если её оставить как есть, то возникнет ошибка компиляции в описанной выше операции «+» так, как если бы она не была объявлена привилегированной в классе составного элемента списка. Аналогичная ошибка в классе стратегии прямой проверки наличия элемента DirectSearch. В Visual C++ здесь всё нормально, однако эти же ошибки появляются, если в классе составного элемента и в классе списка закомментировать объявление операции объединения списков и DirectSearch как привилегированных. Такое впечатление, что g++ просто пропускает эти объявления и жалуется на закрытые/защищённые члены соответствующих классов.
(В g++ версии 9 (Ubuntu 20.04) те же ошибки.)
Почему пропускаются объявления привилегированности и как это исправить, так и не разобрался. Я не силён в особенностях компилятора GCC. Оставил этот момент также на будущее.
За исключением этого нюанса, других серьёзных ошибок компиляции нет.
Уважаемые читатели, полноценный проект под лицензией LGPL 3.0 я опубликовал на GitHub по адресу:
github.com/SkyCloud555/ListMT
Это – одно решение, состоящее из нескольких тестовых проектов. Основной же код многопоточного списка, в силу его реализации через шаблоны, располагается в нескольких заголовочных файлах:
Кроме финального проекта я также добавил три старые версии в папке «Old versions», чтобы можно было кратко оценить, как изменялся проект по мере развития.
Основной проект с названием List представляет собой программу с интерфейсом под Windows, хардкорно реализованным через Windows API (я по-другому пока не умею). В этой программе вы выбираете тип списка (односвязный или двухсвязный), а также указываете начальное количество элементов и желаемое количество потоков. Элементы списка содержат единственное 64-битное значение. После создания списка программа в каждом потоке в цикле выполняет переход по списку вперёд или назад на случайное количество элементов, а затем добавление или удаление элемента. Никакой реальной полезной работы посредством этого списка не выполняется, и вся энергия уходит на обогрев атмосферы, но это и не нужно: нам необходимо лишь оценить работоспособность и производительность списка в интенсивном многопоточном окружении. Мерой производительности выступает количество итераций описанного выше цикла в секунду, выполненных всеми потоками.
Настройка списка производится посредством указания соответствующих стратегий в коде программы и последующей перекомпиляции. Все стратегии для главной программы указываются в основном модуле ListMain.cpp, стратегия памяти же выбирается в ListDataExample.h.
Вообще говоря, с экспериментами я несколько схалтурил. Честно признаюсь. Главным образом потому, что там в ряде случаев у списка существенно изменяется количество элементов. Для чистоты эксперимента для измерения производительности следовало бы поставить тест таким образом, чтобы количество элементов в среднем не менялось за исследуемый период либо менялось крайне несущественно. Только при таких условиях справедливо было бы оценивать значение производительности на основании среднего значения. Если кому-нибудь это интересно, предлагаю заняться организацией таких экспериментов самостоятельно.
Я не стал исправлять исходную организацию тестов из следующих соображений.Прежде всего, мне было просто лень. Во-первых, на мой взгляд, никому не интересны точные количественные значения производительности с вычисленной погрешностью: важно оценить работу и производительность списка качественно. Во-вторых, это позволяет оценить изменение производительности списка с ростом его объёма, что тоже довольно важная и интересная информация. По этим причинам я не стал изменять исходные эксперименты. В-третьих, над всеми вариантами списка выполняет один и тот же код теста, что в этом смысле ставит их в одинаковые условия: тот факт, что они при этом ведут себя по-разному, и позволяет судить о качестве изменений.
Чтобы включить замер производительности, установить флаг ce_bPerformanceMeasure в модуле ListMain.cpp на значение true. Программа создаст файл «PerformanceMeasure.txt» с парами «количество элементов – число циклов/сек», разделённых символом «:».
Разумеется, я не стал проводить тесты для всех возможных конфигураций списка, потому что их очень много. Я сосредоточился только на ключевых.
Тестирование проводилось на моей порядком уже устаревшей, но до сих пор весьма бодрой конфигурации Intel Core i7-3930K, DDR3-1333, 4-канальный контроллер памяти. Компиляция проводилась посредством Visual Studio 2019 для режима Release x64, операционная система Windows 7 x64. Я не стал играться с количеством потоков, так что во всех тестах всегда использовались максимально доступные в данной системе 12 потоков. Список всегда создавался с 10000 случайными по значению элементами, за исключением последнего теста.
Использование встроенных указателей, как я упоминал ранее, позволяет применять только стратегию прямого поиска для проверки наличия элемента в списке. Соответственно, чтобы сравнение был корректным, и для интеллектуальных указателей будет применяться в этом тесте только эта стратегия.
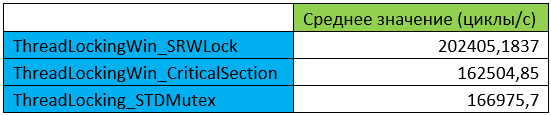
В качестве стратегии блокировки выбрана критическая секция с «тонкой» блокировкой как наиболее производительная в Windows (см. ниже): ThreadLockingWin_SRWLock. Обработка ошибок осуществляется путём возврата кода ошибок, т.е. вариант без исключений.

На этом графике показано количество циклов, произведённых суммарно всеми потоками за секунду, в зависимости от продолжительности теста (в секундах). Очевидно, что производительность непостоянна ввиду случайного характера обращений потоков к списку.
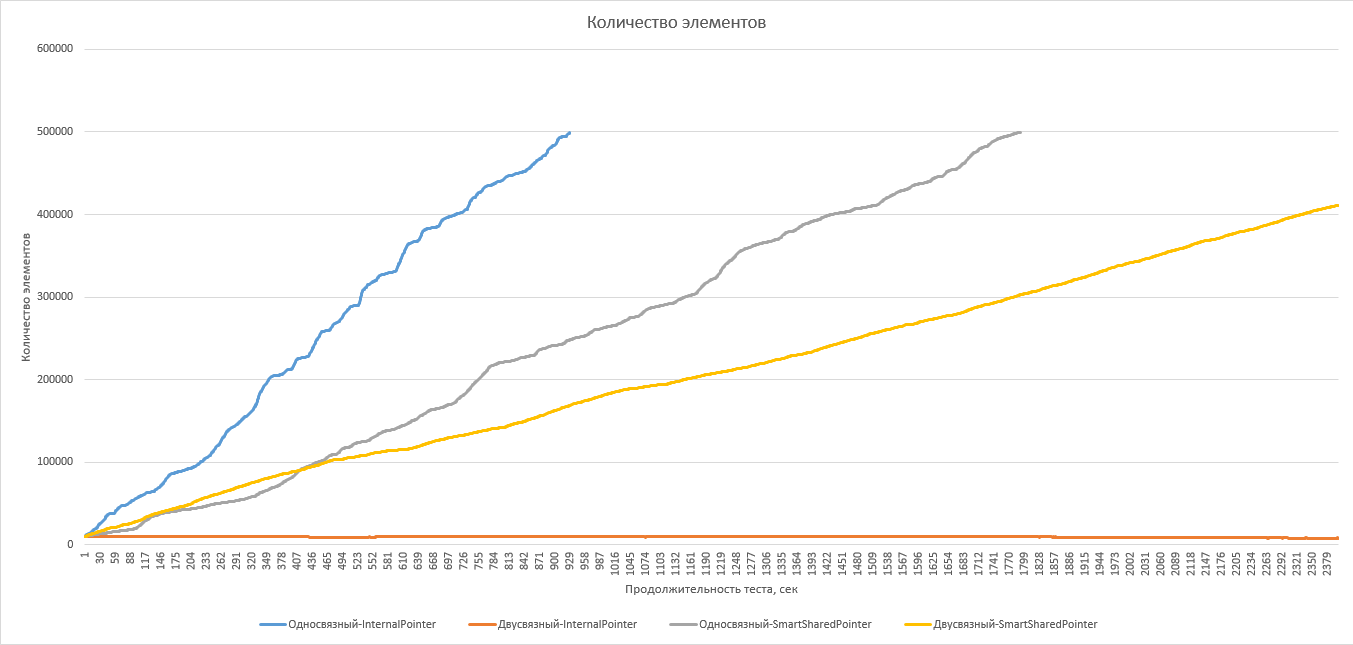
Второй график показывает, как изменяется количество элементов списка во время теста. Каких-либо глубокомысленных утверждений по поводу этого графика делать не буду, за исключением очевидного: ясно, что они работают несколько по-разному, и связность списка вместе со стратегией памяти оказывают своё влияние. Двусвязный список с внутренними указателями – единственный из всех, который неожиданным образом не изменяется в среднем в размерах за всё время теста.
Усреднённая производительность (циклы/с) за измеряемый период:
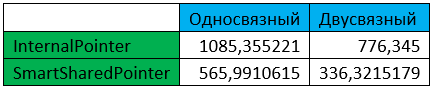
По крайней мере, можно утверждать, что вариант списка с интеллектуальными указателями работает медленнее варианта со встроенными указателями, чего и следовало ожидать. В обоих случаях каким-то образом получается, что односвязный работает быстрее двусвязного, что в очередной раз показывает, что в многопоточном режиме многие привычные вещи могут измениться.
Самым интересным является тестирование по стратегиям проверки наличия элемента. В качестве стратегии памяти указаны, естественно, интеллектуальные указатели по описанным ранее причинам. Остальное всё то же самое: блокировка посредством ThreadLockingWin_SRWLock и обработка ошибок путём возврата кода ошибки.
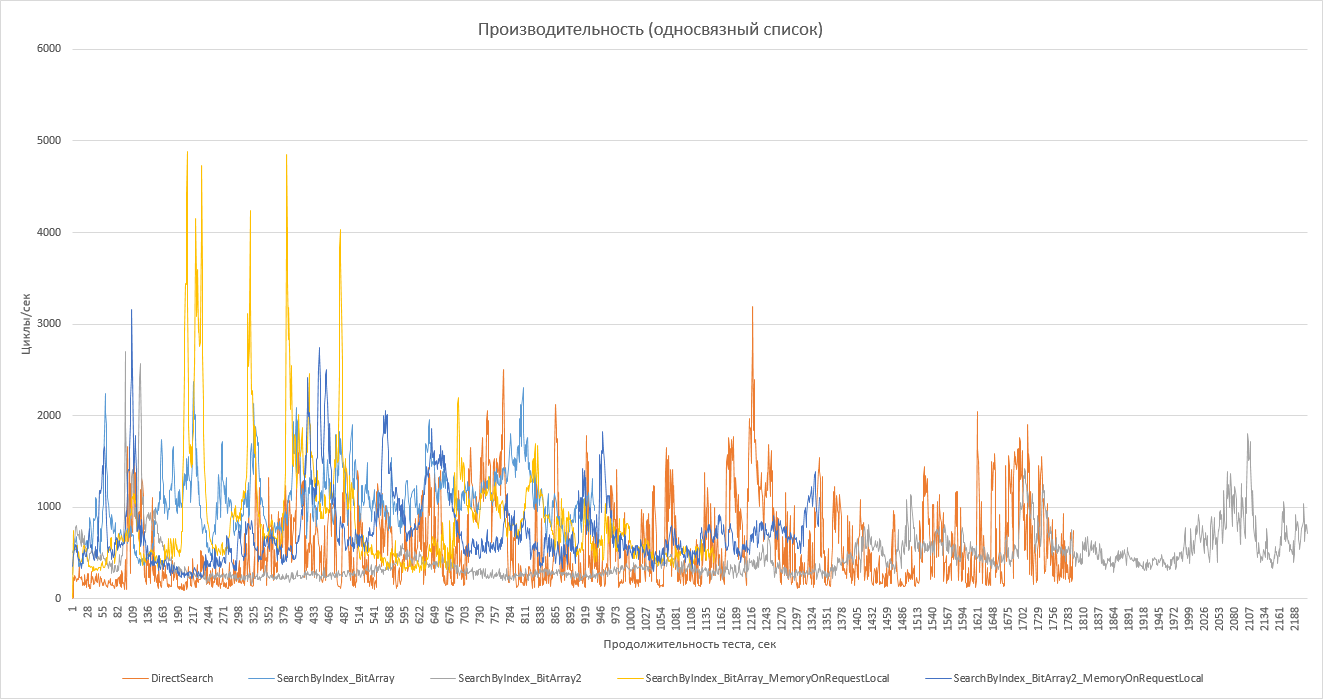
Можно сказать определённо, что все стратегии работают примерно одинаково. Это и понятно: в односвязном списке при удалении его элемента приходится каждый раз просматривать список до элемента, который указывает на удаляемый. Это сводит на нет все усилия по оптимизации доступа к списку и ускорению проверки наличия элемента в нём. Следовательно, односвязный список – не лучший выбор для интенсивной неупорядоченной многопоточной работы с ним.
График по количеству элементов приводить не буду: там нет ничего интересного. Отмечу лишь, что теперь увеличивается число элементов у всех списков.
Совершенно иная ситуация возникает для двусвязного списка. Чтобы графики выглядели красиво, я даже исключил стратегию прямого просмотра списка DirectSearch из него, поскольку по результатам она явно «выпадает» из числа остальных. Кроме того, я увеличил предельное количество элементов в 4 раза, достигнув которое, тест останавливается.
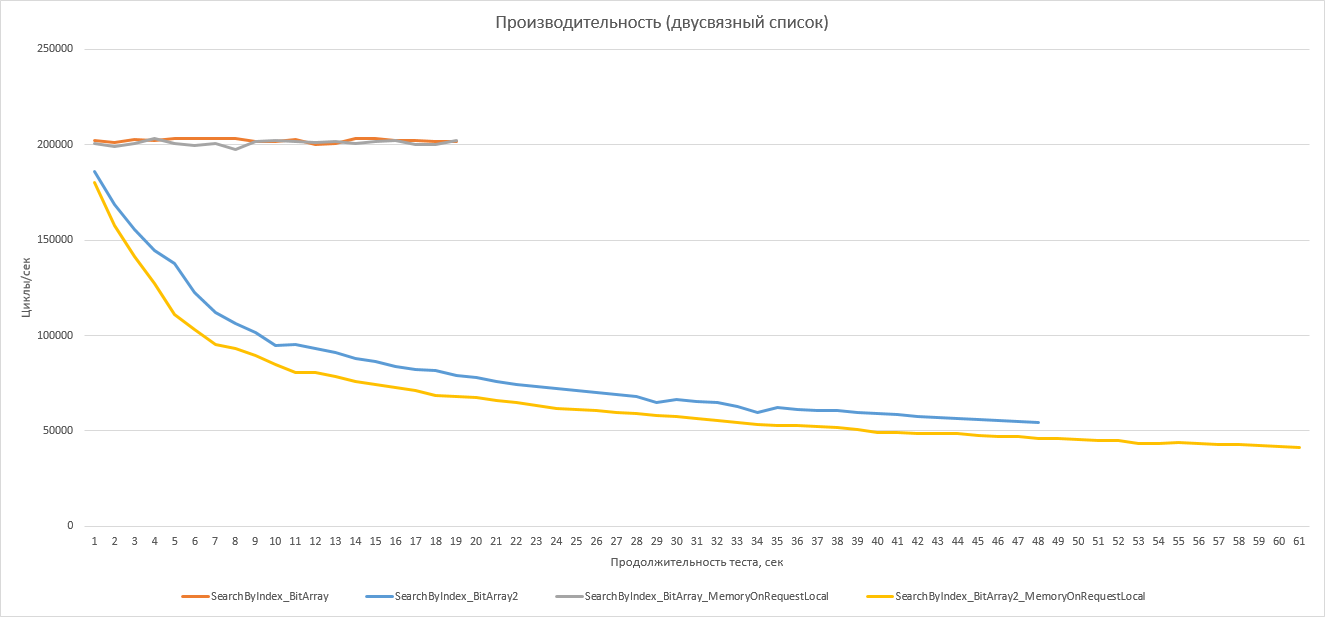
Прежде всего, производительность обращений к списку (равно как и загрузка процессора при этом, став 99-100%) очень резко и существенно возросла! Во-вторых, пара стратегий с последовательным заполнением бит массива имеют примерно одинаковую не меняющуюся в течение теста производительность. Скорость работы же второй пары стратегий нелинейно уменьшается. Почему это так, станет понятно из графика для количества узлов списка.

Списки с первой парой стратегий растут в количестве элементов, причём линейно. Вторая же пара даёт существенно нелинейный рост, причём большее число элементов имеет список, тем медленнее он увеличивается. Это понятно, т.к. с ростом числа элементов при создании нового приходится в среднем просматривать большее количество бит массива в поисках свободного. Первая же пара стратегий не занимается этим, она использует новый бит для каждого нового элемента. Таким образом, список с такой стратегией имеет максимальную производительность доступа и ближе всего к классическому списку: и создание, и удаление элементов производится за константное время, не зависящее от количества элементов. Однако при этом он предоставляет некоторые гарантии целостности и безопасности в многопоточном окружении, пусть и ценой определённых затрат памяти.
Список же со второй парой стратегий, конечно, заметно медленнее. Тем не менее, он всё равно существенно быстрее вариантов с прямой проверкой. Так что действительно можно рекомендовать его в качестве некоторого промежуточного по производительности, но более оптимального по расходам памяти.
На самом деле списки со стратегией прямого поиска также будут работать медленнее при увеличении количества элементов в них: большее количество элементов придётся просматривать каждый раз. Просто за время теста список не успевает увеличиться настолько, чтобы это стало заметно несмотря на хаотичные колебания производительности.

Усреднённые значения производительности показывают, что стратегии с битовым массивом при последовательном его заполнении позволили увеличить производительность обращений к списку примерно в 200 раз, т.е. на 2 порядка, по сравнению со стратегиями прямого поиска. Это – весьма радикальное изменение. Производительность же вариантов с оптимальным по памяти заполнением бит, как было отмечено выше, конечно, заметно медленнее, но всё равно гораздо быстрее вариантов с прямой проверкой.
Стоит отметить также, что использование механизма передачи памяти по запросу несколько замедляет обращения к списку. Не слишком чтобы критично, но эффект присутствует и заметен, особенно – в варианте с экономным использованием памяти (жёлтая линия на графиках).
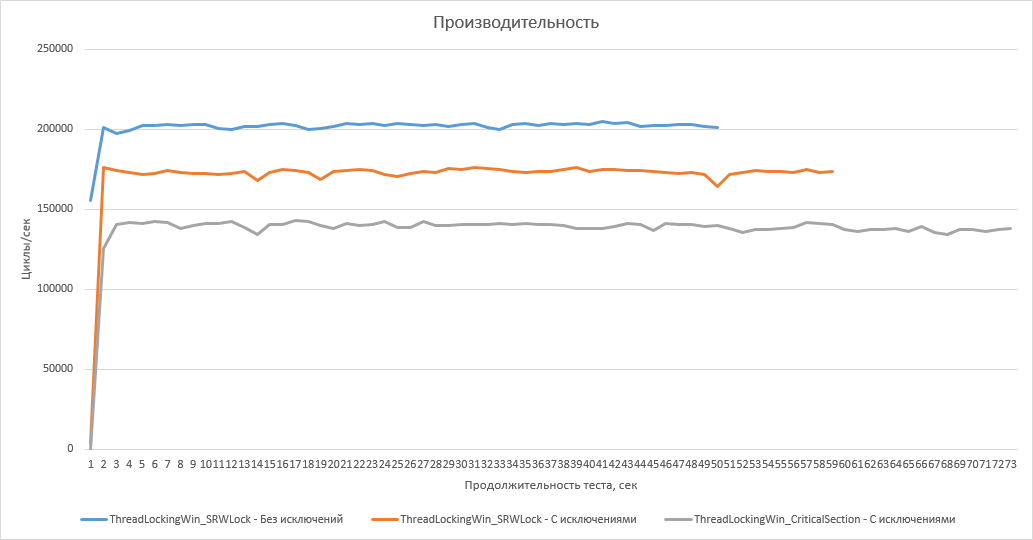
Рассмотрим теперь, как будет изменяться производительность списка при выборе различных стратегий блокировки. Я использовал три типа блокировок: «тонкая» блокировка SRWLock, обычная критическая секция Windows и мьютекс STL. По остальным же настройкам использовалась самая быстрая версия списка: двухсвязный, интеллектуальные указатели, стратегия проверки наличия элемента – SearchByIndex_BitArray, вариант без исключений.

Как и следовало ожидать, «тонкая» блокировка увеличивает производительность почти на 25%.
Скорость работы с критической секцией Windows и мьютексом STL примерно одинакова.
Чтобы оценить влияние исключений на производительность, я провёл три теста. В первых двух использовался двусвязный список, интеллектуальные указатели, стратегия проверки наличия элемента – SearchByIndex_BitArray, критическая секция SRWLock. Для последнего теста использовалось всё то же самое, только блокировка была заменена на обычную критическую секцию для сравнения.

Видно, что поддержка исключений способна действительно снизить скорость работы, особенно если использовать более «грубый» вариант блокировки. Однако следует помнить, что в этом случае будет недоступна поддержка STL и циклов for по коллекции.
Это был для меня весьма масштабный эксперимент. Имею ввиду вовсе не тесты выше, а весь проект целиком. Не ожидал сам, что он настолько затянется. Тем не менее я выполнил его целиком от и до в той мере, в которой планировал. Разумеется, в конечном итоге это всё равно не итоговый вариант, а лишь некоторый рабочий прототип, реализация описанных в начале статьи идей.
По результатам тестов ясно, что под Windows самым быстрым оказался двусвязный список с интеллектуальными указателями, стратегией проверки наличия элемента SearchByIndex_BitArray, критической секцией SRWLock и без исключений. В такой конфигурации список обеспечивает максимальную производительность при интенсивных хаотичных обращениях к нему из различных потоков и по поведению ближе всего к классическому списку с гарантиями безопасности в многопоточном режиме. Вариант с более экономным расходом памяти тоже весьма производителен (по сравнению с прямой проверкой DirectSearch), но всё же заметно медленнее, чем предыдущая, и его производительность падает с увеличением количества элементов.
Если вы думаете, что буду здесь агитировать за то, какую классную штуку я сделал и как здорово её использовать, то нет: на самом деле я начну с того, что буду вас отговаривать. В самом деле:
Недостатки проекта:
Надеюсь, это было интересно. Новичкам может быть полезно, т.к. всё рассматривается от простого к сложному. Профессионалов же попрошу сказать, насколько, на ваш взгляд, описанные здесь идеи применимы на практике в реальных проектах? Случался ли в вашей деятельности случай, когда по смыслу вам требовался список или дерево, а не другой контейнер, но он становился узким местом в вашей программе из-за описанных здесь проблем? Либо приходилось сильно изменять или усложнять программу. Если встречались с этим ранее, то как вы это решали?
Разумеется, по сути этот проект – лишь реализация моего собственного взгляда на решение этой проблемы. Вполне вероятно, что найдётся какой-нибудь вариант получше. Повторю мысль из начала, что я делал это изначально для себя и не планировал выкладывать на всеобщее обозрение. Но всё-таки я сделал это по описанным там же причинам, так что буду рад конструктивной критике.
P.S. При внимательном рассмотрении кода вы можете наткнуться на такую конструкцию:
Сия чёрная магия заслуживает отдельной статьи. Правда, это ещё менее практическая вещь, чем описываемый здесь многопоточный список, но она имеет свои любопытные особенности. Может быть, как-нибудь попозже я тоже об этом напишу.
В этой статье речь пойдёт о связном списке, многопоточности и С++. Сразу отмечу, что были все шансы положить эту работу «на полочку» и использовать в небольшом количестве личных проектов. Вместо этого я всё-таки решил выложить её на суд общественности – вдруг это действительно покажется кому-нибудь полезным или интересным. Более того, если окажется, что кто-нибудь когда-нибудь уже успел сделать что-нибудь подобное, укажите мне эти материалы, пожалуйста. Однако сколько я ни пытался гуглить на эту тему, все попытки были безуспешны.
Также отмечу, что речь пойдёт не о классическом связном списке, а о моём творческом переосмыслении использования этой структуры данных в многопоточном окружении. Я рассматривал сценарий неупорядоченного интенсивного многопоточного обращения к списку. Это означает, что любой поток в любой момент независимо от других может получить доступ к списку и произвести требуемые операции. Если он только добавляет или изменяет элементы, это ещё полбеды. Если же он ещё и удаляет элементы, могут возникнуть различные интересные особенности.
Этот проект, которым я занимался на правах хобби и саморазвития, по ряду причин растянулся на весьма длительный срок. Кроме того, по мере работы над ним я интенсивно учился: проект начинался без знания и понимания STL и проектировался соответственно, используя только внутренние средства собственно языка С++. Однако потом я весьма серьёзно его модифицировал с учётом STL и даже под STL. Что у меня из этого получилось, судить вам, уважаемые читатели.
Для наиболее полного понимания описываемого здесь материала вам потребуется познакомиться со следующими книгами:
- Александреску А. – «Современное проектирование на С++».
- Рихтер Д., Назар К. – «Windows via C/C++, Программирование на языке Visual C++».
- Джосаттис Н. – «Стандартная библиотека С++. Справочное руководство. Второе издание» или аналогичная книга по STL.
Линейный список
Линейный список – известная структура данных, применяемая ещё со времён языка С и ранее. Его элемент представляет собой некоторый объект в памяти, имеющий связи с одним или двумя соседними аналогичными элементами – здесь приведён пример для двусвязного списка:
struct ListItem
{
<… некоторые данные …>
List *pNext;
List *pPrev;
};Соответственно, сам список – это некоторая (под)программа, которая выполняет манипуляции с этими элементами. Как правило, известен указатель на начало и, опционально, на конец списка: этого достаточно, чтобы, начиная с первого элемента, пройти по всем его элементам вплоть до конца.
По сути, я описываю уже хорошо изученную и известную всем информацию: это был ликбез для тех, кто совсем не в курсе. За подробностями, например, можно обратиться сюда:
Линейный список (Википедия)
В библиотеке STL есть такой замечательный контейнер std::list (двусвязный список), а также его близнец – std::forward_list (односвязный список). То есть если вам не интересно, как список устроен и функционирует внутри, а вы хотите им просто пользоваться для своих задач, предложенные контейнеры – ваш вариант.
Но есть одно но…
Проблемы многопоточности
Повторюсь, что когда я начинал разбирать эту тему, я собирался всё сделать, полагаясь только на внутренние средства С++ без какой-либо поддержки STL. Ценность того, что получилось бы, была бы ниже, если бы я всё-таки решил рассказать об этом здесь. Но с другой стороны, я был совершенно свободен от каких-либо концепций или ограничений библиотеки, а потому был не связан ничем и искал подходы непредвзято и независимо.
Раньше, в далёкие-далёкие времена, подавляющее большинство компьютеров были одноядерными и однопроцессорными. Линейный список был относительно простой и прозрачной структурой данных, и работа с ним не вызывала особых затруднений. Сейчас же даже смартфоны стали многоядерными. В условиях многопоточности даже такая простейшая структура, как связный список, серьёзно усложняется. Обеспечение корректной работы в многопоточном режиме вообще серьёзно усложняет любую программу, это известный факт.
Возьмём некий абстрактный сценарий интенсивной работы со списком различными потоками: каждый из них в совершенно произвольный момент времени может добавлять, удалять, изменять элементы, и т.д. С одной стороны, работа со списком в этом случае должна быть прежде всего безопасной: если произойдут какие-либо нарушения данных и неопределённое поведение программы, это будет совершенно неподходящее решение. С другой стороны, очень хотелось бы, чтобы работа с ним была как можно более быстродействующей.
Для решения первой проблемы список, очевидно, придётся как-то блокировать, а также синхронизировать доступ к нему. Вторую проблему – производительность – пока отложим.
В этой статье рассматривается только блокировка всего списка потоком для осуществления монопольного доступа потока к нему. Другие варианты казались сомнительными, например, по следующим соображениям. Предположим, у нас двухсвязный список, и мы решили удалить элемент из него. Для этого надо заблокировать сам узел, а также предыдущий и последующий.
В это самое время перед началом операции другой поток удаляет как раз, например, предшествующий узел. Мы блокируем удаляемый и останавливаемся в ожидании освобождения предыдущего узла, заблокированного другим потоком. А он блокируется на ожидании последующего для него, т.е. нашего удаляемого узла. Всё, вот и взаимная блокировка. Так что этот способ не является надёжным.
Если ваши потоки не хранят какие-либо указатели (или итераторы) на конкретные узлы, то задача предельно упрощается. Фактически, можно обойтись только средствами STL. Поток блокирует список, обращается к какому-либо элементу в нём (например, с начала, с конца или посредством поиска в нём по каким-либо критериям), обрабатывает или удаляет этот элемент, добавляет какие-либо новые, не сохраняя ссылки на них, а затем завершает работу со списком. Всё это – монопольно заблокировав доступ к списку в одном потоке, единолично владея им на время требуемых операций. В этом случае совершенно логично использовать std::list и средства блокировки библиотеки. При всём при этом следует учесть, что пока ваш поток выполняет всю требуемую работу, другие потоки остановятся в ожидании, т.е. работа со списком будет осуществляться в однопоточном режиме.
Я же рассматривал другой, более сложный сценарий, когда поток хранит указатель или итератор на нужный ему элемент. Например, ваша программа работает над какими-то сложными вычислениями, взяв исходные данные из элемента списка, а затем, после обработки, обновляет его значение, добавив туда результаты вычислений. При этом другие потоки также имеют доступ к этому же списку. Я не делал каких-либо предположений о характере приложения: другой поток может легко удалить по каким-то причинам именно этот элемент. Или перенести его в другое место. Таким образом, работа со списком становится проблематичной не только по обычным соображениям многопоточности и синхронизации.
Проблема существования элемента
В чём фундаментальное отличие списка от, скажем, массива? В распределённом расположении элементов списка. Все элементы массива расположены в единой области памяти. Даже если вы храните указатель на какой-либо его элемент, вы точно уверены, что обращение по его адресу будет корректным (разумеется, если массив не был перемещён в памяти в другое место с расширением его размера, например). Если нужный вам элемент удалили или переместили в другом потоке, вы просто обратитесь по прежнему адресу, поймёте по каким-либо признакам, что нужного вам элемента здесь нет, затем попробуете поискать его и т.д. Разумеется, программа должна заранее поддерживать такую возможность. Но, в любом случае, её работа останется корректной, пока вы находитесь в корректных пределах памяти.
Совсем другая ситуация – в случае списка (а также в случае дерева, графа – любой структуры данных с распределёнными элементами). Если элемент по вашему указателю удалили в другом потоке, вы об этом даже не узнаете, и при попытке обращения по его адресу получите нарушение доступа (в лучшем случае). Даже если он не будет фактически удалён из памяти (например, в случае использования интеллектуальных указателей), он будет удалён из списка, т.е. не будет являться его частью. Вы об этом также не узнаете. Корректная работа со списком нарушается.
При этом интенсивная многопоточная работа со списком создаёт совершенно фантастические сценарии. Вы можете даже быть уверены, что с вашим элементом и указателем на него всё нормально – вплоть до обращения к какой-либо функции списка для работы с ним.
Пример. Пусть есть часть списка, и в некоторую функцию-метод списка передаётся указатель на узел, который обозначим как (#), в то время как узлы, связанные с ним, будем обозначать относительными по отношению к нему номерами. На момент вызова функции известно, что этот элемент существует и указатель на него корректен, то есть состояние списка в этой области такое:
Пусть теперь узел (#) передаётся как параметр в некоторую функцию списка. Эта функция, как водится, блокируется в ожидании доступа к нему. Пока она ждала, до неё поработали три потока, удалившие узел (#) вместе с прилежащими к нему так, что получилось:
Затем ещё 5 потоков вставили ещё 5 элементов в список, начиная с (-2). Обозначим новые элементы как (nN), где N — относительный среди этих пяти номер, начиная с нуля:
Тут наконец получает время наш поток, который вызывали с (#). Вопрос такой: что ему делать в этом случае, ведь (#) уже давно нет?
Ответ: всё сильно зависит от операции, а также от сценария использования списка. Однако, поскольку мы рассматриваем самый общий случай без каких-либо ограничений, можно сделать некоторые общие предположения.
Если это операция удаления, то достаточно просто проверить, присутствует ли заданный элемент в списке. Если нет, то его уже удалили, и больше ничего делать не нужно. Если да, то удалить. Аналогично — для операции чтения/изменения содержимого узла: если узел удалён, то читать/изменять уже нечего. А вот самые большие проблемы возникают при операциях вставки нового узла, а также при перемещении к следующему/предыдущему. С одной стороны, указанного узла уже нет, и можно вернуть неудачу. С другой — узел должен быть вставлен, и такая ситуация может возникнуть в любой момент.
Поскольку приоритетом (для общего случая) всё же безопасность и надёжность, а только потом быстродействие, то, очевидно, когда поток наконец получил время работы внутри функции, то придётся устанавливать факт присутствия элемента в списке: а он вообще есть там ещё или уже нет? Это решает одну проблему: по крайней мере, мы не нарушим работу всего списка в случае отсутствия запрошенного узла там и избежим ошибок доступа к памяти в связи с этим. Но не решает проблему вставки и переходов: непонятно, куда теперь вставлять новый узел и переходить от уже удалённого.
Решение проблемы существования элемента будет подробно рассматриваться далее. Вопрос же, что делать, когда мы обнаружили, что элемента уже нет, а он очень нужен, выходит за рамки этой статьи, поскольку это целиком зависит от алгоритма работы использующей список программы. Разумеется, она должна предусматривать такие сценарии и соответствующие реакции на них: например, если элемента нет, то перейти к началу списка или выполнить какую-нибудь другую операцию. Главное, что нужно обеспечить в этой ситуации – это корректную и безопасную работу списка, а также уведомление о подобных ситуациях.
Прямой поиск элемента
Самый простой и прямолинейный подход – это проверка присутствия элемента в списке посредством последовательного прохода по нему в поиске заданного элемента. Т.е. просто ищется данный элемент. Если он в списке есть, мы работаем с ним. Если же нет, то, в зависимости от функции, выходим с успехом или неудачей, и пусть вызывающая программа принимает решение, что делать в этой ситуации. Главное, что работа со списком в любом случае будет корректной.
Этот способ безопасен и вполне работоспособен, но, особенно для списков большого размера, приводит к катастрофическому падению производительности. Фактически, работа со списком оказывается однопоточной: список блокируется на время поиска заданного элемента в нём, и другие потоки не могут получить к нему доступ. Во-вторых, резко повышаются накладные расходы – в каждой операции со списком приходится проверять, есть ли нужный на момент операции элемент, и огромная доля времени уходит не на полезную работу, а на проверку наличия элемента. Тем не менее, этот простой незамысловатый подход вполне годится для списков малого объёма и не слишком интенсивных операций с ним, а также в качестве первого приближения к решению проблемы существования элемента.
Но что делать, если у нас список с большим количеством элементов, а работа с ним весьма интенсивная: множество потоков постоянно добавляют, изменяют и удаляют элементы из него? Есть ли способ как-нибудь ускорить его работу?
Память или быстродействие
Есть известный факт, что увеличение используемой программой памяти может увеличить скорость работы программы. Например, программа интенсивно использует результаты каких-то вычислений. Вместо того, чтобы каждый раз выполнять их заново, можно всё вычислить заранее и сохранить их результаты в какой-нибудь таблице или массиве. Затем программа просто обращается в нужную ячейку таблицы и сразу получает нужное значение, что существенно ускоряет её работу.
Именно этот подход я и использовал в случае списка. Создадим битовый массив. Добавим в служебную информацию каждого его элемента, помимо обязательного указателя на следующий и, опционально, предыдущий элементы ещё два новых поля: первый – это его уникальный номер в пределах этого списка, а второй – это указатель на сам список. Теперь, когда элемент создаётся, ему присваивается уникальный номер, и в битовом массиве по соответствующему индексу устанавливает единица. Когда элемент удаляется, этот бит обнуляется. Номер создаваемого элемента постоянно увеличивается при каждом создании нового элемента – уже использованные обнулённые биты не используются повторно.
Теперь, когда требуется проверить наличие заданного элемента, вместо линейного поиска его во всём списке просто происходит обращение к битовому массиву по индексу этого элемента в нём, и факт его наличия сразу устанавливается, причём за константное время, не зависящее от размера списка.
Этот способ позволяет достичь максимального быстродействия, однако он имеет свои серьёзные недостатки. Первый – придётся выделить память под весь массив сразу, часть бит которого может вообще не понадобиться за время работы программы, но эту память можно было бы использовать на другие нужды. Эту проблему и способ сгладить перерасход памяти рассмотрим чуть ниже.
Второй недостаток серьёзнее и интереснее – каждый новый элемент списка создаётся по монотонно возрастающему номеру. Это означает, что рано или поздно свободные биты массива будут исчерпаны.
В этот момент, к сожалению, придётся остановиться, заблокировать список и начать его обслуживать. Т.е. сжать биты этого массива, удалив все нулевые биты от промежуточных ранее удалённых элементов списка, оставив только биты для реально существующих в данный момент элементов, сместив все эти биты к началу массива. Придётся опять пройти по всему списку, причём в однопоточном режиме, переписав все индексы для каждого элемента. Очевидная выгода этого по сравнению с предыдущим подходом в том, что в данном случае это будет выполняться всего один раз за длительный период времени. Далее список может продолжать работу как прежде в предельно быстродействующем режиме.
Разумеется, я не имею ввиду, что в список узлы только добавлялись, т.к. в этом случае все биты массива будут единичными. Я рассматриваю сценарий, когда элементы интенсивно и произвольно удаляются и добавляются. Т.е. общее количество элементов списка с начала его работы может измениться незначительно. Естественно, вопрос выбора объёма массива зависит от характера работы программы. Также всегда можно создать новый массив большего объёма, если размера текущего не хватает.
Использование нулевых бит от уже удалённых прежде элементов
Можно поступить и по-другому: при создании элемента искать первый нулевой бит с начала битового массива. Это оптимизирует расход памяти, но приведёт к падению производительности: теперь опять каждый раз при создании нового элемента придётся выполнять дополнительную работу – просматривать массив в поисках свободного бита. Но по сравнению с проверкой наличия элемента прямым просмотром списка выигрыш налицо: мы будем просматривать массив рядом расположенных элементов, причём каждый элемент такого массива содержит множество бит, т.е. мы обрабатываем множество узлов списка за раз (64 бита для современных систем или даже 128/256/512 в случае использования SSE/AVX). Ищем первое слово, не равное слову со всеми единичными битам, далее ищем первый нулевой бит в этом слове. Фактически, этот метод – промежуточный по быстродействию между предыдущим и методом прямого просмотра.
Оптимизация расхода памяти для незанятых бит массива
Допустим, мы предполагаем длительную и интенсивную работу со списком, выделив для него огромный массив бит. Но так получилось, что фактически программа работала иначе: обращалась к списку редко, выполняла другие операции, которым тоже требуется память. В результате получаем почти неиспользованный массив бит огромного объёма и проблемы с памятью в других частях программы. Сплошные неудобства!
Linux, насколько я могу судить, автоматически решает эту проблему (хотя опытные разработчики-линуксоиды пусть меня поправят, если что). Вы выделяете память под массив, но фактически система эту память массиву не передаёт до тех пор, пока она реально не понадобится. Происходит оптимизация использования памяти. Windows такого делать не позволяет. Вернее, позволяет, но это придётся делать своими руками.
Для тех, кто совсем не в курсе, поясню: вашему приложению (точнее, соответствующему ему процессу), система выделяет виртуальное адресное пространство большого объема – вплоть до 8 Тб для 64-разрядной Windows. Физической памяти в системе может быть намного меньше – 8 или 16 Гб на данный момент для массовых компьютеров. Операционная система отображает адреса вашего виртуального пространства процесса на адреса физической памяти, делая это прозрачным образом без вашего прямого участия. Естественно, большая часть свободной виртуальной памяти процесса оказывается обычно незанятой. Так вот, когда вы просите Windows выделить память обычными средствами, она эту память одновременно выделяет как в вашем виртуальном пространстве, так в физической памяти. Если вы выделите битовый массив большого объёма, вы рискуете сразу занять всю доступную память на вашей машине без гарантии, что эта память вообще может понадобиться.
Однако можно поступить и по-другому: разметить огромный участок памяти в виртуальном пространстве процесса, но передавать ему физическую только тогда, когда она реально нужна. Сделать это можно посредством структурной обработки исключений в Windows, за подробностями прошу обратиться в книге Рихтер Д., Назар К. – «Windows via C/C++, Программирование на языке Visual C++».
Реализация
Это было бы только идеей и теорией, если бы я не реализовал все эти идеи на практике, причём не в виде простенькой экспериментальной программы: я делал её максимально тщательно как для production, намереваясь использовать в своих реальных проектах, поэтому именно в таком виде вам её и представляю. Подумал, что было бы несправедливо и слишком эгоистично применять сделанное в своём ограниченном количестве проектов, если это может оказаться полезным или хотя бы просто интересным широкому кругу разработчиков. С другой стороны, создатели библиотеки Boost и других более специализированных библиотек предлагают свои работы всем желающим абсолютно бесплатно. Почему я не могу поступить таким же образом?
Абстракция – список без данных
Я разделил список на два логических уровня. Первый уровень – это список, каждый элемент которого не содержит никаких полезных данных, а содержит только служебную информацию: указатели на соседние элементы, а также, опционально, те два дополнительных поля для ускорения проверки наличия элемента в списке. Однако уже на этом уровне возможно выполнять все базовые операции над списком: добавление и удаление элементов, разбиение и объединение списков и т.д. Фактически, я сконцентрировался прежде всего на этом уровне.
Второй уровень – это добавление фактических данных к элементу списка, а также добавление новых операций в список для работы с этими данными. Всё это обеспечивается в С++ путём наследования. Но о деталях пойдёт речь ниже.
Такое разбиение реализации на два уровня имело свой смысл: зачем учитывать наличие конкретных данных, если целый ряд операций никак не зависит от этих данных? Для любых данных элементов списка всё равно придётся удалять их и добавлять новые в список, а также выполнять другие типичные операции.
Начинал я с предельно простой и незамысловатой концепции, взятой ещё из приведённой в начале статьи конструкции из языка С. Как внутри, так и вне списка применяются внутренние указатели C/С++. Разница была лишь в том, что добавление данных, как было указано выше, отложено на более поздний срок.
Пусть есть элемент списка без данных, содержащий лишь указатель (или указатели) на соседний/-ие элемент(ы). Тогда соответствующий код для него схематично можно представить так:
template<class ListElement> class List_OneLinked; //односвязный список
//узлы списка
struct ListElement_OneLinked //узел односвязного списка (без данных)
{
ListElement_OneLinked *pNext; //указатель на следующий элемент списка
};
//классы списков
template<class ListElement> class List_OneLinked //односвязный список
{
//свойства
//указатели на узлы списка
ListElement *pFirst = nullptr; //указатель на первый узел
ListElement *pLast = nullptr; //указатель на последний узел
SRWLOCK csSRW = { 0 }; //структура для критической секции блокировки
<…m-функции (методы) класса>
};Элемент для односвязного списка содержит внутри себя указатель на следующий элемент, и только. Класс списка параметризуется типом этого элемента, подразумевая, что этот тип будет изменён на стадии добавления данных. Он содержит внутри себя указатели на первый и последний элементы. Поскольку я исходно нацеливал этот проект только для Windows, то также включена критическая секция типа SRWLock для блокировки списка. Далее определяются конструкторы, деструктор, а также все необходимые функции для работы со списком.
Данная реализация содержит сразу две проблемы.
Первая – открытый доступ к содержимому служебной информации элемента. Это означает, что, получив доступ к какому-либо узлу, т.е. имея указатель на этот узел, мы можем непосредственно обратиться к последующему или предыдущему элементу.
Однако при многопоточной работе со списком это недопустимо.
Это недопустимо главным образом потому, что этот переход осуществляется в обход блокировки и, следовательно, защиты списка. В самом деле, предположим, имея указатель на некоторый элемент pCurr, мы сохранили значение на следующий относительно него элемент в указателе pNext следующим образом: pNext = pCurr->pNext. После этого выполняем некоторую длительную операцию над данным узлом pCurr. В это же время другие потоки удалили следующие относительно pCurr элементы списка. Закончив работу с pCurr, текущий поток переходит к следующему элементу, используя старое значение, сохранённое в локальной pNext, и получает ошибку доступа либо неопределённое поведение, поскольку элемента по адресу локального pNext уже не существует, и нужно обращаться к обновлённому значению pCurr->pNext, если текущий элемент по адресу pCurr, в свою очередь, тоже вообще ещё существует.
Из этого примера можно сделать два вывода для предотвращения этой ситуации:
- извне списка осуществлять переход к следующему/предыдущему узлу и вообще осуществлять любую работу с элементами списка только через функции (методы) класса списка, производящие блокировку списка и делающими доступ к списку безопасным;
- получать доступ к элементам по возможности непосредственно перед обращением к ним (например, получать указатель на следующий элемент pNext = list.GetNext(pCurr) не заранее, а непосредственно перед тем, как появится необходимость в переходе к следующему узлу).
Именно поэтому для реализации вывода из первого пункта следует запретить доступ к указателям на смежные элементы извне:
class ListElement_OneLinked //узел односвязного списка (без данных)
{
ListElement_OneLinked *pNext; //указатель на следующий элемент списка
friend List_OneLinked; //объявляем класс односвязного списка привилегированным для обеспечения доступа из него
};Вторая проблема несколько деликатнее. Чтобы понять её, следует структуру классов описать более подробно. Класс списка определён как шаблонный и работает не с элементами типа ListElement_OneLinked, а с типом ListElement, передаваемым в качестве параметра шаблона. Это сделано для того, чтобы иметь возможность создавать внутри класса новые узлы с данными. Для того, чтобы делать это, нужно знать точный тип создаваемого узла. Точный тип узла списка пока ещё не известен: он будет определён позже вместе с данными. Функция создания элемента выделяет память для него, инициализирует указатели, а затем возвращает указатель на созданный элемент в вызывающую функцию. Так в вызывающей функции производного класса можно будет провести инициализацию других, специфичных для этого класса и доопределённых позже свойств элемента. Иными словами, точное определение типа узла списка оставлено на будущее, и для того, чтобы список корректно функционировал, важно лишь, чтобы его элементы содержали указатель pNext, остальное пока не имеет значения.
Таким образом, на базе ListElement_OneLinked впоследствии путём наследования будет создан новый класс для элемента с конкретными данными и передан классу List_OneLinked через параметр шаблона. Одновременно на базе List_OneLinked будет создан новый производный класс, доопределяющий операции с этими новыми данными.
Однако даже такой вариант не является совсем корректным. В ранних версиях класса списка несколько раз применялась операция явного преобразования типа reinterpret_cast<ListElement *>(...). Дело в том, что шаблонный класс работает с типом-параметром шаблона ListElement, который является производным от ListElement_OneLinked/ListElement_TwoLinked. А в функциях класса создаются переменные в выражениях типа:
ListElement *pNext = pCurr->pNext;
Причём pCurr->pNext здесь — это указатель на ListElement_OneLinked/ListElement_TwoLinked, как члены базовых классов.
Выход: либо объявлять переменную, указывая явный базовый тип ListElement_OneLinked/ListElement_TwoLinked, либо приводить её к производному типу явно.
На самом деле даже явное определение базового типа не является корректным, например, в функции удаления (очистки) списка:
//удаляем все элементы списка
ListElement *pCurr = pFirst;
ListElement *pNext = nullptr;
while (pCurr != nullptr)
{
pNext = reinterpret_cast<ListElement *>(pCurr->pNext);
delete pCurr;
pCurr = pNext;
}Если изменить тип указателей:
ListElement_OneLinked *pCurr = pFirst;
ListElement_OneLinked *pNext = nullptr;то это будет означать, что будут удалены операцией
delete pCurr;только базовые части каждого узла списка, что неправильно. Либо, как вариант, придётся уже указатель pCurr приводить к его производному типу:
delete reinterpret_cast<ListElement *>(pCurr);Таким образом, в любом случае от явного преобразования reinterpret_cast при такой структуре классов не избавиться, что не является лучшим решением (точнее, что совсем нехорошо на самом деле).
По этой причине, чтобы избавиться от таких вот явных преобразований, было решено изменить базовый класс для элемента (для двусвязного списка – аналогично):
template<class ListElement> class ListElement_OneLinked //узел односвязного списка (без данных)
{
ListElement *pNext; //указатель на следующий элемент списка
friend List_OneLinked<ListElement>; //объявляем класс односвязного списка привилегированным для обеспечения доступа из него
};Кратко это можно охарактеризовать так: базовый элемент списка содержит указатель на другой элемент, но тип этого указателя ещё пока не известен, потому как передаётся параметром шаблона (точное определение этого типа оставлено на будущее). Иными словами: на данном этапе тип узла списка (т.е. каким он будет в итоге) ещё не определён, он будет определён позже. Но сейчас мы сохраняем указатель на элемент будущего, пока ещё не известного, типа. Итоговый тип узла списка передаётся сюда как параметр шаблона.
Теперь не потребуется никаких преобразований, поскольку везде – и в классе списка, и в классе для узлов – используются указатели одного типа ListElement. ListElement здесь и в классе списка – это итоговый класс для элемента с конкретными данными.
Это означает, что теперь класс списка стал максимально абстрагированным от конкретного его содержимого: известно лишь, что его узлы содержат указатели на другие такие узлы, и, пользуясь этой информацией, в классе списка выполняются все базовые операции над ними с соответствующей многопоточной блокировкой.
Решение проблемы существования элемента – простой поиск (версия 01.03.2018)
Первая версия была предельно простой и незамысловатой и не выходила за описанные выше рамки. Использовались внутренние указатели С++, память для элементов выделялась посредством операции new и удалялась с помощью delete, список блокировался на содержащейся в нём критической секции. О средствах библиотеки STL я не знал и не подозревал, а также о том, на какой уровень они выводят программирование на С++.
Уже на этом этапе я на практике столкнулся с описанной ранее проблемой существования элемента и понял, что простой блокировки списка недостаточно. Я перемещался по списку с помощью соответствующих функций со всеми мерами предосторожности, список корректно блокировался, но программа всё равно успешно падала с разной периодичностью. Именно тогда я выяснил, что наличие элемента придётся проверять, что привело к изменению логики ключевых функций.
Приведу в пример функцию добавления элемента после заданного:
ListElement* AddAfter(ListElement* const pElem, bool bProtected = false) throw (FailElemCreation, Nullptr, NotPartOfList)
{
if (!pElem)
throw Nullptr(); //генерация исключения об ошибочном параметре (нулевой указатель)
//блокируем список на время операции
if (!bProtected)
LockListExclusive();
//проверяем, является ли переданный элемент частью списка
if (!FindElement(pElem, true))
{
if (!bProtected)
UnlockListExclusive();
throw NotPartOfList(); //генерация исключения - переданный элемент не является частью списка
}
ListElement *pCurr = new ListElement;
if (!pCurr)
{
if (!bProtected)
UnlockListExclusive();
throw FailElemCreation(); //генерация исключения о неудаче выделения памяти для узла списка
}
//проверяем, является ли это первым элементом списка
if (pFirst == nullptr)
{
pFirst = pLast = pCurr;
pCurr->pNext = nullptr;
}
else
{
//устанавливаем указатель в текущем элементе списка на только что созданный
ListElement *pNext = pElem->pNext;
pElem->pNext = pCurr;
pCurr->pNext = pNext;
//проверяем, является ли текущий элемент последним
if (pElem == pLast)
pLast = pCurr;
}
//разблокируем список
if (!bProtected)
UnlockListExclusive();
return pCurr;
}Видно, что прежде чем создать новый элемент, она проверяет, присутствует ли в списке заданный элемент, вызывая функцию FindElement(…):
bool FindElement(ListElement* const pElem, bool bProtected = false) const throw (Nullptr)
{
if (!pElem)
throw Nullptr(); //генерация исключения об ошибочном параметре (нулевой указатель)
if (!bProtected)
LockListShared(); //блокируем список на время операции
ListElement *pCurr = pFirst;
bool bResult = false;
while (pCurr != nullptr)
{
if (pCurr == pElem)
{
bResult = true;
break;
}
pCurr = pCurr->pNext;
}
if (!bProtected)
UnlockListShared(); //разблокируем список
return bResult;
}Дальнейшее усложнение классов многопоточного списка – классы стратегий (версии 18.02.2019, 27.11.2019)
Изначально проект нацеливался строго на Windows. Но в какой-то момент я подумал, почему бы не добавить ему гибкости? Почему только Windows? Ведь список реализовывался по сути на чистом С++, от Windows у него было только одно: критическая секция SRWLock. К тому моменту я уже познакомился с концепцией классов стратегий. Об этом вы можете подробно почитать в книге Александреску А. – «Современное проектирование на С++». В ней описаны многие необычные и потрясающие вещи, которые могут быть полезны даже сейчас несмотря на то, что книге уже 12 лет.
Одна из них – это классы стратегий. Классы стратегий, по сути, – это и есть изменений поведения класса посредством шаблонов, о чём упоминал Б. Страуструп в своей известной книге. Только в книге Александреску эта тема широко раскрывается.
Предположим, ваш класс выполняет одно какое-то строго определённое действие. Вы можете вынести определение этого действия за пределы класса, создать на основе этого действия отдельный класс и передать его в ваш исходный класс в качестве параметра шаблона. Это усложняет код, его чтение и понимание, но зато существенно добавляет вашему классу гибкости: чтобы заменить данное конкретное действие каким-то другим, аналогичным, вам достаточно просто будет написать другую подобную стратегию и передать её вашему классу в качестве параметра шаблона. Всю остальную работу сделает за вас компилятор.
Стратегия блокировки
Применяя это к описываемому списку, я вынес блокировку через SRWLock в отдельную стратегию, а затем написал несколько других стратегий: через обычную критическую секцию Windows, через мьютексы С++ STL и т.д. Потом можно будет добавить чисто специфичные для Linux методы. Таким образом, класс стал подходящим не только для Windows, но я всегда могу очень быстро перенастроить его обратно для Windows оптимальным образом, просто указав нужную стратегию.
//блокировка посредством критической секции SRWLock
//так как критическую секцию типа SRWLock как-либо удалять не нужно, то деструктор классу не требуется (конструктор также не требуется из инициализации члена
//класса прямо в классе: С++11)
class ThreadLockingWin_SRWLock //блокировка посредством критической секции SRWLock
{
mutable SRWLOCK csSRW = { 0 }; //структура для критической секции типа SRWLock
public:
ThreadLockingWin_SRWLock(bool bInitialize = true)
{
//конструктор; bInitialize - флаг того, что требуется инициализация критической секции
if(bInitialize)
InitializeSRWLock(&csSRW); //инициализируем критическую секцию SRWLock
}
//функции управления блокировкой
void LockExclusive(void) const noexcept //выполняет блокировку ресурса для изменения
{
AcquireSRWLockExclusive(&csSRW);
}
void UnlockExclusive(void) const noexcept //выполняет разблокировку ресурса после изменения
{
ReleaseSRWLockExclusive(&csSRW);
}
void LockShared(void) const noexcept //выполняет блокировку ресурса для чтения
{
AcquireSRWLockShared(&csSRW);
}
void UnlockShared(void) const noexcept //выполняет разблокировку ресурса после чтения
{
ReleaseSRWLockShared(&csSRW);
}
void Lock(void) const noexcept //выполняет блокировку ресурса
{
AcquireSRWLockExclusive(&csSRW);
}
void Unlock(void) const noexcept //выполняет разблокировку ресурса
{
ReleaseSRWLockExclusive(&csSRW);
}
};Стратегия работы с памятью
Примерно к этому моменту я также серьёзно взялся изучать STL и в числе первых средств этой библиотеки познакомился с интеллектуальными указателями. А затем подумал: почему я не могу добавить поддержку интеллектуальных указателей в свой список? Тогда я вынес тип указателя, а также создание и удаление данных элемента списка в отдельную стратегию:
//стратегия работы с памятью при помощи встроенных указателей C/С++
//выделитель памяти по умолчанию
template<class Type> class DefaultAllocator_InternalPointer
{
public:
template<class... ArgTypes> static Type* Create(ArgTypes... Args) noexcept //выполняет выделение памяти для объекта
{
return new Type(Args...);
}
};
template<class Type> class DefaultAllocator_InternalPointer<Type[]> //частичная специализация для массивов
{
public:
static Type* Create(size_t size) noexcept //выполняет выделение памяти для массива
{
if (size != 0)
return new Type[size];
else
return nullptr;
}
};
//удалитель по умолчанию
template<class Type> class DefaultDeleter_InternalPointer
{
public:
void operator()(Type* ptr) noexcept //для того, чтобы можно было использовать в удалителях классов типа unique_ptr
{
Delete(ptr);
}
static void Delete(Type *ptr) noexcept //выполняет удаление объекта из памяти
{
if(ptr)
delete ptr;
}
};
template<class Type> class DefaultDeleter_InternalPointer<Type[]> //частичная специализация для массивов
{
public:
void operator()(Type* ptr) noexcept //для того, чтобы можно было использовать в удалителях классов типа unique_ptr
{
Delete(ptr);
}
static void Delete(Type *ptr) noexcept //выполняет удаление массива из памяти
{
if(ptr)
delete[] ptr;
}
};
//тип объекта, для которого создаётся указатель, передаётся в параметре Type шаблона
//Deleter и Allocator - это удалители и выделители памяти для объектов типа Type
template<class Type, class _Deleter = DefaultDeleter_InternalPointer<Type>, class _Allocator = DefaultAllocator_InternalPointer<Type>> class InternalPointer
{
public:
//объявления типов
using ptrType = Type * ; //тип указателя на тип объекта
using Allocator = _Allocator; //выделитель памяти
using Deleter = _Deleter; //удалитель
using shared_ptrType = ptrType; //для поддержки интеллектуальных указателей
using weak_ptrType = ptrType; //для поддержки интеллектуальных указателей
//функции
template<class... ArgTypes> static ptrType Create(ArgTypes... Args) noexcept
{
//функция создаёт объект и возвращает указатель на него
//на вход: Args - аргументы-параметры для конструктора объекта типа Type
//на выход: указатель на созданный объект типа Type
return Allocator::Create(Args...); //создаём объект с помощью переданного выделителя памяти
}
static void Delete(ptrType& pObject) noexcept
{
//удаляет объект из памяти, устанавливая указатель на него в нулевое значение
//на вход: pObject - ссылка на указатель объекта для удаления, DeleterFunc - указатель на функцию-удалитель
if (pObject)
{
Deleter::Delete(pObject); //удаляем объект с помощью переданного удалителя
pObject = nullptr;
}
}
static ptrType MakePointer(Type& obj) noexcept
{
//возвращает указатель заданного типа на существующий объект
//на выход: указатель на объект типа Type
return &obj;
}
};Аналогичная стратегия для интеллектуальных указателей:
//стратегия работы с памятью при помощи интеллектуальных указателей shared_ptr/weak_ptr С++
//выделитель памяти по умолчанию
template<class Type> class DefaultAllocator_SmartSharedPointer
{
public:
template<class... ArgTypes> static std::shared_ptr<Type> Create(ArgTypes... Args) noexcept //выполняет выделение памяти для объекта
{
return std::make_shared<Type>(Args...);
}
};
template<class Type> class DefaultAllocator_SmartSharedPointer<Type[]> //частичная специализация для массивов
{
public:
static std::shared_ptr<Type> Create(size_t size) noexcept //выполняет выделение памяти для массива
{
if (size != 0)
return std::make_shared<Type[]>(size);
else
return nullptr;
}
};
//удалитель по умолчанию
template<class Type> class DefaultDeleter_SmartSharedPointer
{
public:
void operator()(std::shared_ptr<Type>* ptr) noexcept //для того, чтобы можно было использовать в удалителях классов типа unique_ptr
{
Delete(*ptr);
}
static void Delete(std::shared_ptr<Type>& ptr) noexcept //выполняет удаление объекта из памяти
{
ptr = nullptr; //сбрасываем указатель, что приводит к удалению объекта, если нет других объектов
}
};
template<class Type> class DefaultDeleter_SmartSharedPointer<Type[]> //частичная специализация для массивов
{
public:
void operator()(std::shared_ptr<Type>* ptr) noexcept //для того, чтобы можно было использовать в удалителях классов типа unique_ptr
{
Delete(*ptr);
}
static void Delete(std::shared_ptr<Type>& ptr) noexcept //выполняет удаление массива из памяти
{
ptr = nullptr; //сбрасываем указатель, что приводит к удалению объекта, если нет других объектов
}
};
//тип объекта, для которого создаётся указатель, передаётся в параметре Type шаблона
//Deleter и Allocator - это удалители и выделители памяти для объектов типа Type
template<class Type, class _Deleter = DefaultDeleter_SmartSharedPointer<Type>, class _Allocator = DefaultAllocator_SmartSharedPointer<Type>> class SmartSharedPointer
{
public:
//объявления типов
using ptrType = std::shared_ptr<Type>; //тип указателя на тип объекта
using Allocator = _Allocator; //выделитель памяти
using Deleter = _Deleter; //удалитель
using shared_ptrType = ptrType; //указатель для совместного владения
using weak_ptrType = std::weak_ptr<Type>; //слабый указатель
//функции
template<class... ArgTypes> static ptrType Create(ArgTypes... Args) noexcept
{
//функция создаёт объект и возвращает указатель на него
return Allocator::Create(Args...); //создаём объект с помощью переданного выделителя памяти
}
static void Delete(ptrType& pObject) noexcept
{
//устанавливаем указатель на объект в нулевое значение; если это - последний указатель, которым владеет этот объект, то объект будет удалён
//из памяти
Deleter::Delete(pObject); //удаляем объект с помощью переданного удалителя
}
static ptrType MakePointer(Type& obj) noexcept
{
//возвращает указатель заданного типа на существующий объект
//на выход: указатель на объект типа Type
return std::shared_ptr<Type>(&obj);
}
};Стратегия памяти принимает три параметра: тип объекта Type, а также распределитель и удалитель памяти. На основании типа объекта стратегия создаёт тип указателя на этот тип – либо Type *, либо std::shared_ptr, в зависимости от стратегии, а также предлагает соответствующие функции создания и удаления объекта. Эти функции, если говорить о распределителях и удалителях по умолчанию, создают объект либо через операцию new Type, либо через функцию std::make_shared(…). Всё это работает благодаря тому, что разыменование указателя происходит одинаково как для встроенного указателя С++, так и для интеллектуального std::shared_ptr. Конечно, в случае двусвязного списка и интеллектуальных указателей, чтобы избежать неприятной особенности зацикливания указателей, для указателей на предыдущий элемент используется std::weak_ptr, и во время компиляции для двусвязного списка в зависимости от выбранной стратегии памяти выбирается, как его разыменовывать (это – новая особенность С++17):
//если тип pPrev является weak_ptr, то обращаться к нему можно только после преобразования в shared_ptr с помощью функции lock()
if constexpr (std::is_same_v<typename ListElement::MemoryPolicy, SmartSharedPointer<ListElement>>) //C++17: if constexpr
pFirst->pPrev.lock() = nullptr;
else
pFirst->pPrev = nullptr;Таким образом, теперь список не создаёт самостоятельно свои элементы: он перенаправляет вызов соответствующей стратегии.
Стратегия проверки наличия элемента
Разумеется, и решение проблемы существования элемента я вынес в отдельную стратегию: если списку требуется проверить наличие какого-то его элемента, он просто переадресует вызов соответствующей стратегии. Самый первый, незамысловатый и топорный подход стал стратегией прямого поиска DirectSearch. Далее я разработал ещё две стратегии на основе двух описанных ранее подходов с битовым массивом в порядке их описания: SearchByIndex_BitArray и SearchByIndex_BitArray2. Для Windows для возможности постепенного занимания памяти битовым массивом по мере его заполнения также добавил ещё две стратегии:
SearchByIndex_BitArray_MemoryOnRequestLocal и SearchByIndex_BitArray2_MemoryOnRequestLocal.
Как было отмечено ранее, для работы этих продвинутых стратегии требуется, чтобы элемент списка содержал в себе индекс в битовом массиве и указатель на базовый класс списка (об этом см. ниже), т.е. был определён следующим образом:
//элементы списка с информацией для быстрой проверки присутствия элемента в списке
template<class ListElement, template<class> class _MemoryPolicy> class ListElement_OneLinked_CP //узел односвязного списка (без данных)
{
public:
using MemoryPolicy = _MemoryPolicy<ListElement>; //сохраняем используемую стратегию работы с памятью внутри класса элемента
private:
typename MemoryPolicy::ptrType pNext; //указатель на следующий элемент списка
unsigned long long ullElementIndex; //индекс элемента среди всех созданных в списке
ListBase<ListElement> *pList; //указатель на список-владелец элемента
//объявляем шаблонный класс односвязного списка привилегированным для обеспечения доступа из него; класс объявляется привилегированным ВЕСЬ, независимо от конкретных
template<class ListElement, class LockingPolicy, template<class> class CheckingPresenceElementPolicy> friend class List_OneLinked;
//объявляем шаблонную функцию операции "+" привилегированной
template<class ListElement, class LockingPolicy, template<class> class CheckingPresenceElementPolicy> friend List_OneLinked<ListElement, LockingPolicy, CheckingPresenceElementPolicy> operator+<ListElement, LockingPolicy, CheckingPresenceElementPolicy>(List_OneLinked<ListElement, LockingPolicy, CheckingPresenceElementPolicy>&, List_OneLinked<ListElement, LockingPolicy, CheckingPresenceElementPolicy>&) noexcept; //объявляем операцию объединения списков привилегированной
//объявляем классы стратегий поиска и проверки элемента списка привилегированными
template<class ListElement> friend class DirectSearch;
template<class ListElement> friend class SearchByIndex_BitArray;
template<class ListElement> friend class SearchByIndex_BitArray2;
};Соотношение стратегии памяти со стратегиями проверки наличия элемента
При подробном рассмотрении оказалось, во взаимоотношениях стратегии памяти со стратегиями проверки наличия элемента присутствует подводный камень.
Предположим, вы используете интеллектуальные указатели в качестве стратегии памяти, а также стратегию с использованием битового массива для ускоренной проверки наличия элемента в списке. Вы удаляете элемент, стратегия памяти сбрасывает его указатель. При этом этот элемент фактически не удаляется из памяти, поскольку у вас в вашей вызывающей программе есть другой интеллектуальный указатель на него. В дальнейшем вы обращаетесь к списку с этим элементом, и он совершенно корректно делает проверку, обращаясь к его данным – индексу в битовом массиве и указателю на список. Элемент фактически удаляется из памяти только тогда, когда больше не осталось нигде никаких ссылок на него.
Совсем не то происходит в случае использования встроенных указателей С++. В этом случае стратегия памяти действительно удалит этот элемент из памяти с помощью операции delete. В дальнейшем вы, как и в предыдущем случае, обратитесь к списку с этим элементом, и он попытается обратиться к элементу по этому адресу в целях считать индекс битового массива и указатель на список. А этого делать нельзя: элемент ведь уже удалён из памяти! В лучшем случае вы получите нарушение доступа, в худшем – неопределённое поведение, когда библиотека С++, библиотека времени выполнения или просто операционная система запишет туда совершенно произвольное значение, которые считает список и попытается установить по ним факт присутствия элемента в списке.
Таким образом, получается, что внутренние указатели совместимы только со стратегией прямой проверки DirectSearch, а интеллектуальные указатели в данном случае предлагают не только присущую им безопасность, но и увеличение производительности: ведь только с их использованием можно применять битовые массивы, которые существенно увеличивают работу списка в многопоточном режиме!
Чтобы гарантировать соответствие и исключить несовместимые конфигурации стратегий, я включил в каждый класс списка следующую проверку:
//проверка, что внутренний указатель С++ (Type *) может использоваться только со стратегией проверки элемента прямого поиска (DirectSearch)
static_assert(!(std::is_same_v<typename ListElement::MemoryPolicy, InternalPointer<ListElement>> == true && std::is_same_v<CheckingPresenceElementPolicy<ListElement, false>, DirectSearch<ListElement, false>> == false), "Internal C++ pointer memory policy can be used only with DirectSearch policy.");Она сравнивает переданные в список классы стратегий и, в случае их несовместимости, останавливает компиляцию с соответствующим выводом сообщения об ошибке.
Исключения или возврат ошибок
Исходно обработка ошибок списка осуществлялась только посредством исключений. Но как-то на каком-то уже не помню форуме я вычитал, что исключения замедляют программу, и для максимальной производительности следует использовать традиционный возврат ошибок. Так и сделал, создав два новых класса на основе исходных, только переписав их под возврат ошибок.
Базовый класс списка
Реализация описанных выше стратегий проверки наличия элементов выявила одну важную проблему. Элемент списка, как мы помним, содержит помимо уникального в данном списке номера ещё также указатель на этот список: ведь у нас может быть в программе два и более списков, каждый из которых содержит собственный битовый массив флагов наличия элемента. Как убедиться, что данный элемент принадлежит именно данному списку, а не другому? Только посредством хранения указателя на весь список внутри каждого элемента.
Проблема в том, что теперь за счёт добавления разнообразных стратегий в наш класс списка мы существенно усложнили его тип. Допустим, у нас есть два разных списка с одинаковым типом элемента и одинаковой стратегий памяти, но с разными стратегиями блокировки и проверки наличия элементов в них. Для компилятора это будут два разных типа списков. Указатель на какой тип хранить в элементе? Причём класс для элемента заранее не знает, какая именно стратегия будет применяться, он должен учесть их все.
Вспомним также, что и стратегия блокировки, и стратегия проверки наличия элемента, и даже связность (односвязный или двусвязный) списка относятся только к характеру поведения самого списка, но никак не относятся к хранимым им данным. А ведь нас как конечных пользователей этого класса интересуют именно данные! Так что, с одной стороны, использовав классы стратегий, мы добавили себе гибкости, а с другой – усложнили себе жизнь и добавили проблем.
Можно ли всё-таки как-нибудь сделать так, чтобы и волки были сыты, и овцы целы?
Можно. Можно вывести указатели на данные из класса (т.е из типа) списка. Помимо указанных прежде двух уровней организации списка появился ещё один – нулевой:
//базовый класс списка
template<class ListElement> class ListBase
{
using ptrListElement = typename ListElement::MemoryPolicy::ptrType; //извлекаем тип указателя из класса элемента списка и переданной ему стратегии работы с памятью
protected:
//указатели на узлы списка
ptrListElement pFirst{ nullptr };
ptrListElement pLast{ nullptr };
};Теперь, т.к. реальные классы списков наследуются от него, если мы хотим обратиться к данным списка вне зависимости от его реального типа, нам следует обратиться к его базовому классу ListBase. Получаем доступ к началу и концу списка, а затем работаем с его данными как хотим. Конкретный тип списка, а также комбинация используемых в нём стратегий значения не имеет.
Итераторы
Уже вовсю плотно работая с STL в реальном проекте (не моём :) ), а также продолжая изучать его в книгах, я обратил внимание на цикл for по коллекции. Ведь этот цикл – не просто часть STL, он стал уже внутренней частью языка. Я подумал, что тоже могу добавить поддержку его в свой проект.
Для этого необходимо добавить поддержку итераторов, абстрагируясь от конкретного способа работы с указателями и переходу по списку.
Пример итератора:
class ListIterator //класс итератора для перебора элементов
{
ptrListElement pCurrElement{ nullptr }; //текущий элемент, на который указывает итератор
const List_OneLinked<ListElement, LockingPolicy, CheckingPresenceElementPolicy, false>* pList = nullptr; //указатель на список, которому принадлежит данный элемент
bool bProtected = true; //флаг того, что список блокирован извне итератора
public:
ListIterator() {}
ListIterator(ptrListElement pElem, const List_OneLinked<ListElement, LockingPolicy, CheckingPresenceElementPolicy, false>* pList, bool bProtected = true)
noexcept : pCurrElement(pElem), pList(pList), bProtected(bProtected) {}
ListIterator(const ListIterator& li) noexcept : pCurrElement(li.pCurrElement), pList(li.pList) {}
ptrListElement& operator*()
{
if (!bProtected)
{
pList->LockListShared(); //блокируем список на время операции
if (!pList->FindElement(pCurrElement, nullptr, true))
{
if (!bProtected)
pList->UnlockListShared();
throw ListErrors::NotPartOfList(); //генерация исключения - переданный элемент не является частью списка
}
}
ptrListElement& pli = pCurrElement;
if (!bProtected)
pList->UnlockListShared(); //разблокируем список после операции
return pli;
}
operator bool() noexcept { return pCurrElement != nullptr; }
operator ptrListElement() noexcept { return pCurrElement; }
void operator++() //префиксный инкремент: ++it
{
if (!bProtected)
{
pList->LockListShared(); //блокируем список на время операции
if (!pList->FindElement(pCurrElement, nullptr, true))
{
if (!bProtected)
pList->UnlockListShared();
throw ListErrors::NotPartOfList(); //генерация исключения - переданный элемент не является частью списка
}
}
pCurrElement = pCurrElement->pNext;
if (!bProtected)
pList->UnlockListShared(); //разблокируем список после операции
}
ListIterator operator++(int) noexcept //постфиксный инкремент: it++
{
ListIterator itPrev = *this;
if (!bProtected)
{
pList->LockListShared(); //блокируем список на время операции
if (!pList->FindElement(pCurrElement, nullptr, true))
{
if (!bProtected)
pList->UnlockListShared();
throw ListErrors::NotPartOfList(); //генерация исключения - переданный элемент не является частью списка
}
}
pCurrElement = pCurrElement->pNext;
if (!bProtected)
pList->UnlockListShared(); //разблокируем список после операции
return itPrev;
}
bool operator==(const ListIterator li)
{
if (!bProtected)
pList->LockListShared(); //блокируем список на время операции
bool bResult = (pCurrElement == li.pCurrElement && pList == li.pList);
if (!bProtected)
pList->UnlockListShared(); //разблокируем список после операции
return bResult;
}
bool operator!=(const ListIterator li)
{
if (!bProtected)
pList->LockListShared(); //блокируем список на время операции
bool bResult = false;
if (pList == nullptr || li.pList == nullptr)
bResult = !(pCurrElement == li.pCurrElement);
else
bResult = !(pCurrElement == li.pCurrElement && pList == li.pList);
if (!bProtected)
pList->UnlockListShared(); //разблокируем список после операции
return bResult;
}
};Для того, чтобы список был доступен в операторе for по коллекции, в него необходимо добавить также функции begin() и end():
ListIterator begin(bool bProtected = false) noexcept
{
if(!bProtected)
LockListShared(); //блокируем список на время операции
ListIterator lit(ListBase<ListElement>::pFirst, this);
if (!bProtected)
UnlockListShared(); //разблокируем список
return lit;
}
ListIterator end() noexcept
{
return ListIterator();
}Теперь стало возможным написать следующим образом:
using List = ListData<List_TwoLinked<ListElement, ThreadLockingWin_SRWLock, SearchByIndex_BitArray, true>, true>;
List list;
try
{
for(auto& leValue : list)
_tprintf_s(TEXT("%I64u\n"), leValue->u64Value);
}
catch(…)
{
…
}leValue имеет тип указателя на элемент списка.
Первоначально я внёс поддержку итераторов только в списки с поддержкой исключений.
Причина была проста: поскольку код внутри цикла недоступен, то корректно обработать ошибки не представляется возможным. Остаётся только обрабатывать исключения, обернув цикл в блок try. Вообще, ходить по списку таким образом, когда с ним интенсивно работают другие потоки, является не лучшей идеей: лучше заблокировать список самостоятельно, а затем спокойно пройти по нему в однопоточном режиме. Но всё-таки если зачем-то требуется сделать именно так, как в примере выше, то теперь и для этого есть возможность.
Обобщение стратегии проверки наличия элемента на произвольный контейнер; итераторы для списков без исключений
На самом деле я изначально планировал (и до сих планирую) сделать не только многопоточный список, но также ещё и дерево. Для некоторых своих нужд. Граф тоже можно, но во-первых, он мне не был нужен, а во-вторых, граф – штука сложная и с весьма нетривиальными алгоритмами, а мне не хотелось погружаться в это без особой нужды.
В первоначальном варианте стратегия проверки наличия элемента была ориентирована только на список, и её функции принимали указатель на элемент и указатель на базовый класс списка (ListBase *). Впоследствии я подумал: но ведь в случае дерева придётся делать ровно то же самое! Делать отдельную, но по сути точно такую же стратегию?
Решение было простое: абстрагироваться от списка. Это означало, что теперь на вход будут поступать не указатели на элементы, а итераторы. А функции станут шаблонными, чтобы принимать указатели на контейнер любого подходящего типа.
Так что теперь исходная функция, например, регистрации списка в битовом массиве
void RegisterList(const ListBase<ListElement>* const pList, ptrListElement const pStart, ptrListElement const pEnd = nullptr) noexcept
{
//регистрирует элементы списка, присоединённые к данному
//на вход: pList - указатель на список, которым нужно обновить соответствующие данные в элементах, pStart - начальный обновляемый элемент,
//pEnd - конечный обновляемый элемент
if (pElementPresentFlags)
{
ptrListElement pCurr = pStart;
unsigned long long ullQWordIdx = 0; //индекс учетверённого слова внутри массива
unsigned long long ullBitIndex = 0; //индекс бита внутри учетверённого слова
while (pCurr != pEnd && pCurr != nullptr)
{
if (ullCurrentElementIndex == ullNumElementsMax)
UpdateFlagsArray(pList->pFirst);
pCurr->ullElementIndex = ullCurrentElementIndex;
pCurr->pList = const_cast<ListBase<ListElement> *>(pList);
ullQWordIdx = ullCurrentElementIndex / ce_ullNumBitsInWord; //индекс учетверённого слова внутри массива
ullBitIndex = ullCurrentElementIndex % ce_ullNumBitsInWord; //индекс бита внутри учетверённого слова
pElementPresentFlags[ullQWordIdx] |= 1ULL << ullBitIndex; //устанавливаем бит
ullCurrentElementIndex++;
ullNumElements++;
pCurr = pCurr->pNext;
}
}
}Превратилась в функцию регистрации контейнера:
template<class Container, class Iterator> void RegisterContainer(Container* const pContainer, Iterator itStart, Iterator itEnd = Iterator{})
{
//регистрирует элементы контейнера, присоединённые к данному
//на вход: pContainer - указатель на контейнер, которым нужно обновить соответствующие данные в элементах; itStart - начальный итератор обновляемого
//элемента, itEnd - конечный итератор обновляемого элемента
if (pElementPresentFlags)
{
unsigned long long ullQWordIdx = 0; //индекс учетверённого слова внутри массива
unsigned long long ullBitIndex = 0; //индекс бита внутри учетверённого слова
for (auto it = itStart; it != itEnd; ++it)
{
ptrElementType& pCurr = *it;
if (ullCurrentElementIndex == ullNumElementsMax)
UpdateFlagsArray(pContainer);
pCurr->ullElementIndex = ullCurrentElementIndex;
pCurr->pContainer = pContainer;
ullQWordIdx = ullCurrentElementIndex / ce_ullNumBitsInWord; //индекс учетверённого слова внутри массива
ullBitIndex = ullCurrentElementIndex % ce_ullNumBitsInWord; //индекс бита внутри учетверённого слова
pElementPresentFlags[ullQWordIdx] |= 1ULL << ullBitIndex; //устанавливаем бит
ullCurrentElementIndex++;
ullNumElements++;
}
}
}Переход по списку по указателям трансформировался в переход по абстрактному контейнеру посредством итераторов. Теперь для дерева достаточно будет реализовать свои итераторы, и его поддержка данными стратегиями будет уже обеспечена.
Это потребовало вернуть итераторы в списки без исключений, но сделать их недоступными извне и предназначенными только для внутреннего использования.
Адаптер для данных
Достаточно интенсивно поработав с STL, а также набирая, запуская и изучая учебные программы из книг, я обратил внимание на простоту работы с контейнерами STL.
Например, обратите внимание на следующий код:
std::vector<int> v = { 0, 1, 2, 3, 4, 5 };
for (auto& i : v)
i = 1;Я создаю вектор, передав ему нужный мне тип int, и всё! Контейнер сразу готов к работе, если мне не нужно изменить какие-то дополнительные параметры, заданные по умолчанию, что чаще всего не происходит! У меня же, исходя из трёхуровневой организации списка, в каждом случае пришлось бы сначала создавать новый класс для элемента, а затем – писать класс для списка с данными, реализуя специфичные для итогового списка операции. Представляете, сколько работы! А если вам понадобится создать другой список для других данных, придётся проделывать всё заново или, на крайний случай, копировать предыдущий код, слегка его изменяя. Это уже напоминает ту самую возню с языком С и Windows API, где для каждого элементарного действия приходится заполнять все нужные данные для структуры, а затем вызывать нужную функцию. И либо постоянно держать всё это в голове, либо также постоянно читать MSDN, изучая аргументы каждой новой функции! Рутинно и страшно неудобно!
Я стал искать способы, как получить возможность создавать свой список по аналогии с контейнерами STL, чтобы не пришлось каждый раз заново выполнять одну и ту же рутинную работу: создавать отдельный класс для любого нового элемента, а затем – отдельный класс списка по работе с элементами этого типа. Так появился адаптер для списка с данными данных.
Адаптер для списка с данными – это класс, в параметрах шаблона которого вы передаете сразу нужный вам тип данных, а не элемента. Тип элемента, который я назвал составным типом элемента, на основе этих данных он создаёт самостоятельно:
template<class ElementData, template<class> class _MemoryPolicy> class ListElementCompound_OneLinked_CP
{
ElementData ed; //данные
public:
using ListElement = ListElementCompound_OneLinked_CP<ElementData, _MemoryPolicy>;
using MemoryPolicy = _MemoryPolicy<ListElement>; //сохраняем используемую стратегию работы с памятью внутри класса элемента
template<class... Args> ListElementCompound_OneLinked_CP(Args... args) : ed(args...) {}
ListElementCompound_OneLinked_CP(const ElementData& ed) : ed(ed) {}
ElementData& operator*()
{
return ed;
}
operator ElementData()
{
return ed;
}
private:
typename MemoryPolicy::ptrType pNext = nullptr; //указатель на следующий элемент списка
unsigned long long ullElementIndex = 0; //индекс элемента среди всех созданных в списке
ListBase<ListElement>* pContainer = nullptr; //указатель на список-владелец элемента
...
};Отдельным моментом стоит упомянуть доступ к данным элемента. Тип элемента содержит операцию «*»:
ElementData& operator*()
{
return ed;
}Это значит, что если есть указатель на элемент pElement, то чтобы получить доступ к хранящимся в нём данным, его необходимо разыменовывать дважды:
ElementData& li = **pCurrElement;Один раз – чтобы получить доступ к объекту типа ListElementCompound_OneLinked по его указателю: ListElementCompound_OneLinked& le = *pCurrElement, а второй раз – чтобы получить доступ к данным через операцию ‘*’: ElementData& li = *le.
Это выглядит весьма странно и нетипично, но предполагается, что вы будете работать не через указатели (для этого и так уже был готовый исходный вариант), а через итераторы.
Далее, создавая список на основе адаптера, вы указываете нужные вам стратегии, как это было ранее. Адаптер на основе всех ваших параметров автоматически создаёт нужные типы и передаёт их базовому внутреннему списку, от которого наследуется. Общее определение класса:
template<class ElementData, template<class> class _MemoryPolicy = SmartSharedPointer, class LockingPolicy = ThreadLocking_STDMutex, template<class, bool> class CheckingPresenceElementPolicy = DirectSearch, bool bExceptions = true> class List_OneLinked_DataAdapter;Специализация для списка с исключениями:
template<class ElementData, template<class> class _MemoryPolicy, class LockingPolicy, template<class, bool> class CheckingPresenceElementPolicy>
class List_OneLinked_DataAdapter<ElementData, _MemoryPolicy, LockingPolicy, CheckingPresenceElementPolicy, true> :
public List_OneLinked<std::conditional_t<std::is_same_v<CheckingPresenceElementPolicy<ListElementCompound_OneLinked_CP<ElementData, _MemoryPolicy>, true>, DirectSearch<ListElementCompound_OneLinked_CP<ElementData, _MemoryPolicy>, true>>, ListElementCompound_OneLinked<ElementData, _MemoryPolicy>, ListElementCompound_OneLinked_CP<ElementData, _MemoryPolicy>>, LockingPolicy, CheckingPresenceElementPolicy, true>
{
…
}Выглядит весьма громоздко, многоэтажно и страшненько. Я знаю. Но зато это определение автоматически делает всё, что нужно, без непосредственного участия собирающегося использовать его программиста. С помощью std::conditional_t и std::is_same_v производится сравнение переданной вами стратегии проверки наличия элемента со стратегий прямого поиска и, в зависимости от результата, выбирается соответствующий тип составного элемента списка: с наличием индекса в битовом массиве и указателя на список или же без. Это позволит сэкономить вам память за счёт ненужных дополнительных данных внутри каждого узла, если вы используете стратегию прямого поиска.
Внутри класса лишь реализованы специфичные для него итераторы, а также необходимые по аналогии с STL функции push_back()/push_front(), переадресующие вызовы в базовый многопоточный список. Можно добавить и другие функции позже, чтобы список стал совсем похожим на STL'овский. Но при этом он будет со всеми необходимыми защитами и опциями по увеличению производительности в многопоточной среде.
Работа с адаптером для данных стала выглядеть так. Создание объектов списка:
List_TwoLinked_DataAdapter<double, SmartSharedPointer, ThreadLockingWin_SRWLock, DirectSearch, false> list00;
List_TwoLinked_DataAdapter<double, SmartSharedPointer, ThreadLockingWin_SRWLock, DirectSearch, false> list00;Если вас устраивают все стратегии и параметры по умолчанию, то создание списка становится совсем кратким:
List_TwoLinked_DataAdapter<double> list1;Как видите, внешне совершенно никакой разницы по сравнению с STL’вским за исключением того, что название класса списка другое.
Теперь работать с ним можно как по старинке, через функции базового класса:
list0.AddLast(nullptr, false, false, 0);
list0.AddLast(nullptr, false, false, 1);
list0.AddLast(nullptr, false, false, 2);
list0.AddLast(nullptr, false, false, 3);Здесь последовательно в конец списка добавляются числа от 0 до 3. Чтобы дойти до аргумента, передаваемого в конструктор создаваемого типа при его создании, приходится явно проставлять значения первых трёх аргументов.
int x = *list0.GetLast(); //тип приходится указывать явно, иначе через auto будет выведен тип ListElementCompound_TwoLinked_CP<...>
cout << "x = " << x << endl << endl;Да, здесь возникает определённое неудобство в явно указании типа, но это – следствие попытки опять обратиться в список через прежнюю функцию по работе с указателями. Если добавить в адаптер функцию back(), которая вернёт итератор, то при работе через него не будет такой проблемы:
auto x = *list0.back();После подстройки итераторов под требования STL:
//определения типов для STL
using iterator_category = std::forward_iterator_tag;
using value_type = const ElementData;
using difference_type = std::ptrdiff_t;
using pointer = const typename List::ptrListElement;
using reference = const ElementData&;становится возможным использовать список в алгоритмах библиотеки:
unsigned int i = 0;
for (auto& dElem : list1)
cout << i++ << ": " << dElem << endl;
transform(list1.begin(), list1.end(), list1.begin(), [](double& dElem1)
{
return dElem1 * dElem1;
});
vector<double> v(list1.cbegin(), list1.cend());
…
copy(v.begin(), v.end(), list1.begin());Разумеется, придётся организовывать перехват и обработку исключений: все примеры выше приведены для работы в одном потоке в целях тестирования совместимости с STL.
Применение алгоритмов STL делает возможным интересный момент: можно использовать сразу несколько алгоритмов одновременно, запуская их в нескольких потоках параллельно. Это невозможно сделать обычными средствами (например, используя std::list и средства блокировки), не имея доступ к внутреннему содержимому класса списка. Можно было только блокировать весь список целиком на время работы всего алгоритма. Конечно, это ускорит работу для выполняющего алгоритм потока, но сделает список недоступным для других потоков. Правда, если применять ту же «тонкую» блокировку SRWLock, можно выполнять над списком несколько алгоритмов одновременно, если они этот список не модифицируют. Но первый же поток на запись встанет в ожидании завершения операции чтения списка всеми же остальными потоками.
Предлагаемый же вариант списка позволяет организовать работу с ним более гибко. Например, вы можете организовать работу со списком так, чтобы выполнять немодифицирующие алгоритмы в первой половине списка несколькими потоками одновременно, в то время как ряд других потоков могут что-нибудь добавлять или изменять во второй половине списка. Тот факт, что список блокируется на время одной операции, а не всего алгоритма, позволит «просачиваться» операциям записи через последовательность операций чтения списка, что сделает работу с ним более гибкой, производительной и эффективной.
Объединение двух вариантов классов списков с поддержкой исключений и без в один с булевым параметром
Первоначально списки были в варианте только с исключениями. Затем я добавил новые – без исключений с возвратом ошибок, а старые переименовал с добавлением буквы “E”в названии класса: List_OneLinked_E и List_TwoLinked_E. Это потребовало везде указывать по четыре объявления класса списка.
Затем я решил, что это неудобно по многим причинам. Зачем нам два совершенно разных класса, если это один и тот же список просто с поддержкой исключений или же без? Я объединил оба списка каждого типа в единый класс с дополнительным булевым параметром, а конкретная их реализация с исключениями и без – это две специализации единственного класса для указанного булева параметра.
Шаблонная операция объединения списков
Шаблонная операция объединения списков ранее работала только со списками одного типа. Она объединяла либо только односвязные списки, либо только двусвязные.
Однако, если вдуматься, то ведь совершенно неважно, списки какого типа участвуют в операции: односвязные или двусвязные. Также неважны их стратегии блокировки, какая у них стратегия проверки существования элементов, а также то, поддерживают ли они обработку исключений или нет. Всё это относится только к организации списка, но не к данным, содержащимся в нём. Важно, чтобы совпадали только тип данных и стратегия памяти для элементов. Соответственно, теперь, после объединения списков с булевым параметром относительно исключений, операция на вход принимает списки любого типа со всеми вариантами их параметров:
template<class ListElement, class LockingPolicy1, class LockingPolicy2, template<class, bool> class CheckingPresenceElementPolicy1,
template<class, bool> class CheckingPresenceElementPolicy2, bool bExceptions1, bool bExceptions2,
template<class, class, template<class, bool> class, bool> class ListType1, template<class, class, template<class, bool> class, bool> class ListType2>
auto operator+(ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>& list1, ListType2<ListElement, LockingPolicy2, CheckingPresenceElementPolicy2, bExceptions2>& list2) noexcept;Теперь в качестве результирующего типа списка компилятором выбирается, в зависимости от установки внешнего параметра ce_bGetMinLinksList, список либо с минимальной, либо с максимальной связностью и, в зависимости от этого решения, используются соответствующие его параметры:
constexpr unsigned int ce_uiMinLinksNumber = std::min(ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>::GetLinksNumber(),
ListType2<ListElement, LockingPolicy2, CheckingPresenceElementPolicy2, bExceptions2>::GetLinksNumber());
constexpr unsigned int ce_uiMaxLinksNumber = std::max(ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>::GetLinksNumber(),
ListType2<ListElement, LockingPolicy2, CheckingPresenceElementPolicy2, bExceptions2>::GetLinksNumber());
using ListTypeResultMinLinks = std::conditional_t<ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>::GetLinksNumber() == ce_uiMinLinksNumber, ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>, ListType2<ListElement, LockingPolicy2, CheckingPresenceElementPolicy2, bExceptions2>>;
using ListTypeResultMaxLinks = std::conditional_t<ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>::GetLinksNumber() == ce_uiMaxLinksNumber, ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>, ListType2<ListElement, LockingPolicy2, CheckingPresenceElementPolicy2, bExceptions2>>;
using ListTypeResult = std::conditional_t<ce_bGetMinLinksList, ListTypeResultMinLinks, ListTypeResultMaxLinks>;
...
constexpr bool bExceptionsResultMinLinks = ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>::GetLinksNumber() == ce_uiMinLinksNumber ? bExceptions1 : bExceptions2;
constexpr bool bExceptionsResultMaxLinks = ListType1<ListElement, LockingPolicy1, CheckingPresenceElementPolicy1, bExceptions1>::GetLinksNumber() == ce_uiMaxLinksNumber ? bExceptions1 : bExceptions2;
constexpr bool bExceptionsResult = ce_bGetMinLinksList ? bExceptionsResultMinLinks : bExceptionsResultMaxLinks;На основании выбранных параметров создаётся список результата:
ListTypeResult list(list1.GetNumElementsMax_SearchElementPolicy(true) + list2.GetNumElementsMax_SearchElementPolicy(true), false);Затем у этого списка указатели настраиваются на начало первого и конец второго списка:
//устанавливаем указатели, объединяющие списки (один или оба из них могут оказаться пустыми, поэтому нужны проверки)
if (list1.GetFirst(true))
list.ListBase<ListElement>::pFirst = list1.GetFirst(true);
else
list.ListBase<ListElement>::pFirst = list2.GetFirst(true);
if (list1.GetLast(true))
list1.GetLast(true)->pNext = list2.GetFirst(true);
if (list2.GetLast(true))
list.ListBase<ListElement>::pLast = list2.GetLast(true);
else
list.ListBase<ListElement>::pLast = list1.GetLast(true);
//регистрируем элементы списка в соответствующей стратегии поиска элемента
list.CheckingPresenceElementPolicyResult::RegisterContainer(&list, typename ListTypeResult::iterator{ list.ListBase<ListElement>::pFirst, &list });Далее прежние списки очищаются, и производится выход из функции.
Слабым местом этой функции является двойная блокировка списков с потенциальной взаимной блокировкой:
//блокируем списки: здесь - потенциальная взаимная блокировка; нужен способ заблокировать оба списка одновременно за единую атомарную операцию типа std::lock(mutex1, mutex2)
list1.LockListExclusive();
list2.LockListExclusive();Можно ввести некоторую функцию для одновременной блокировки двух списков за единую атомарную операцию типа std::lock(mutex1, mutex2), однако не все стратегии блокировки поддерживают одновременную блокировку двух объектов синхронизации, как std::lock(…).
Кроме того, у двух списков могут быть разные стратегии блокировки. Решение этой проблемы (если оно вообще существует) оставлено на будущее.
Компиляция под Linux
Компиляция проверялась через проект ListDataAdapterTest, изначально написанный на чистом C++ без специфичных для Windows особенностей, на Linux Ubuntu 16.04 LTS, компилятор g++ 8.2.0. Большинство незначительных нюансов было легко исправить, и проект успешно скомпилировался, а вывод программы совпал с аналогичным выводом под Windows. Однако это – в том случае, если закомментировать строку объединения списков через операцию «+»:
auto list3 = list00 + list1;Если её оставить как есть, то возникнет ошибка компиляции в описанной выше операции «+» так, как если бы она не была объявлена привилегированной в классе составного элемента списка. Аналогичная ошибка в классе стратегии прямой проверки наличия элемента DirectSearch. В Visual C++ здесь всё нормально, однако эти же ошибки появляются, если в классе составного элемента и в классе списка закомментировать объявление операции объединения списков и DirectSearch как привилегированных. Такое впечатление, что g++ просто пропускает эти объявления и жалуется на закрытые/защищённые члены соответствующих классов.
(В g++ версии 9 (Ubuntu 20.04) те же ошибки.)
Почему пропускаются объявления привилегированности и как это исправить, так и не разобрался. Я не силён в особенностях компилятора GCC. Оставил этот момент также на будущее.
За исключением этого нюанса, других серьёзных ошибок компиляции нет.
Описание структуры заголовочных файлов
Уважаемые читатели, полноценный проект под лицензией LGPL 3.0 я опубликовал на GitHub по адресу:
github.com/SkyCloud555/ListMT
Это – одно решение, состоящее из нескольких тестовых проектов. Основной же код многопоточного списка, в силу его реализации через шаблоны, располагается в нескольких заголовочных файлах:
- List.h – базовый класс списка без данных, реализующий все базовые операции со списком, возможные без определения конкретных данных, а также подобные STL адаптеры для данных.
- ListE.h – версии списка с поддержкой исключений.
- ListElement.h – определение базовых классов для элемента списка.
- ListErrors.h – определение кодов и классов ошибок для исключений.
- Помимо перечисленных основных файлов также реализованы следующие:
- MemoryPolicy.h – стратегии работы с памятью;
- ThreadLocking.h – стратегии блокировки.
- SearchContainerElement.h – стратегии проверки наличия элемента в списке, абстрактно описанные для любого контейнера с итераторами.
Кроме финального проекта я также добавил три старые версии в папке «Old versions», чтобы можно было кратко оценить, как изменялся проект по мере развития.
Тестирование
Основной проект с названием List представляет собой программу с интерфейсом под Windows, хардкорно реализованным через Windows API (я по-другому пока не умею). В этой программе вы выбираете тип списка (односвязный или двухсвязный), а также указываете начальное количество элементов и желаемое количество потоков. Элементы списка содержат единственное 64-битное значение. После создания списка программа в каждом потоке в цикле выполняет переход по списку вперёд или назад на случайное количество элементов, а затем добавление или удаление элемента. Никакой реальной полезной работы посредством этого списка не выполняется, и вся энергия уходит на обогрев атмосферы, но это и не нужно: нам необходимо лишь оценить работоспособность и производительность списка в интенсивном многопоточном окружении. Мерой производительности выступает количество итераций описанного выше цикла в секунду, выполненных всеми потоками.
Настройка списка производится посредством указания соответствующих стратегий в коде программы и последующей перекомпиляции. Все стратегии для главной программы указываются в основном модуле ListMain.cpp, стратегия памяти же выбирается в ListDataExample.h.
Вообще говоря, с экспериментами я несколько схалтурил. Честно признаюсь. Главным образом потому, что там в ряде случаев у списка существенно изменяется количество элементов. Для чистоты эксперимента для измерения производительности следовало бы поставить тест таким образом, чтобы количество элементов в среднем не менялось за исследуемый период либо менялось крайне несущественно. Только при таких условиях справедливо было бы оценивать значение производительности на основании среднего значения. Если кому-нибудь это интересно, предлагаю заняться организацией таких экспериментов самостоятельно.
Я не стал исправлять исходную организацию тестов из следующих соображений.
Чтобы включить замер производительности, установить флаг ce_bPerformanceMeasure в модуле ListMain.cpp на значение true. Программа создаст файл «PerformanceMeasure.txt» с парами «количество элементов – число циклов/сек», разделённых символом «:».
Результаты измерений производительности
Разумеется, я не стал проводить тесты для всех возможных конфигураций списка, потому что их очень много. Я сосредоточился только на ключевых.
Тестирование проводилось на моей порядком уже устаревшей, но до сих пор весьма бодрой конфигурации Intel Core i7-3930K, DDR3-1333, 4-канальный контроллер памяти. Компиляция проводилась посредством Visual Studio 2019 для режима Release x64, операционная система Windows 7 x64. Я не стал играться с количеством потоков, так что во всех тестах всегда использовались максимально доступные в данной системе 12 потоков. Список всегда создавался с 10000 случайными по значению элементами, за исключением последнего теста.
Тестирование по стратегиям памяти
Использование встроенных указателей, как я упоминал ранее, позволяет применять только стратегию прямого поиска для проверки наличия элемента в списке. Соответственно, чтобы сравнение был корректным, и для интеллектуальных указателей будет применяться в этом тесте только эта стратегия.
В качестве стратегии блокировки выбрана критическая секция с «тонкой» блокировкой как наиболее производительная в Windows (см. ниже): ThreadLockingWin_SRWLock. Обработка ошибок осуществляется путём возврата кода ошибок, т.е. вариант без исключений.
На этом графике показано количество циклов, произведённых суммарно всеми потоками за секунду, в зависимости от продолжительности теста (в секундах). Очевидно, что производительность непостоянна ввиду случайного характера обращений потоков к списку.
Второй график показывает, как изменяется количество элементов списка во время теста. Каких-либо глубокомысленных утверждений по поводу этого графика делать не буду, за исключением очевидного: ясно, что они работают несколько по-разному, и связность списка вместе со стратегией памяти оказывают своё влияние. Двусвязный список с внутренними указателями – единственный из всех, который неожиданным образом не изменяется в среднем в размерах за всё время теста.
Усреднённая производительность (циклы/с) за измеряемый период:
По крайней мере, можно утверждать, что вариант списка с интеллектуальными указателями работает медленнее варианта со встроенными указателями, чего и следовало ожидать. В обоих случаях каким-то образом получается, что односвязный работает быстрее двусвязного, что в очередной раз показывает, что в многопоточном режиме многие привычные вещи могут измениться.
Тестирование по стратегиям проверки наличия элемента
Самым интересным является тестирование по стратегиям проверки наличия элемента. В качестве стратегии памяти указаны, естественно, интеллектуальные указатели по описанным ранее причинам. Остальное всё то же самое: блокировка посредством ThreadLockingWin_SRWLock и обработка ошибок путём возврата кода ошибки.
Можно сказать определённо, что все стратегии работают примерно одинаково. Это и понятно: в односвязном списке при удалении его элемента приходится каждый раз просматривать список до элемента, который указывает на удаляемый. Это сводит на нет все усилия по оптимизации доступа к списку и ускорению проверки наличия элемента в нём. Следовательно, односвязный список – не лучший выбор для интенсивной неупорядоченной многопоточной работы с ним.
График по количеству элементов приводить не буду: там нет ничего интересного. Отмечу лишь, что теперь увеличивается число элементов у всех списков.
Совершенно иная ситуация возникает для двусвязного списка. Чтобы графики выглядели красиво, я даже исключил стратегию прямого просмотра списка DirectSearch из него, поскольку по результатам она явно «выпадает» из числа остальных. Кроме того, я увеличил предельное количество элементов в 4 раза, достигнув которое, тест останавливается.
Прежде всего, производительность обращений к списку (равно как и загрузка процессора при этом, став 99-100%) очень резко и существенно возросла! Во-вторых, пара стратегий с последовательным заполнением бит массива имеют примерно одинаковую не меняющуюся в течение теста производительность. Скорость работы же второй пары стратегий нелинейно уменьшается. Почему это так, станет понятно из графика для количества узлов списка.
Списки с первой парой стратегий растут в количестве элементов, причём линейно. Вторая же пара даёт существенно нелинейный рост, причём большее число элементов имеет список, тем медленнее он увеличивается. Это понятно, т.к. с ростом числа элементов при создании нового приходится в среднем просматривать большее количество бит массива в поисках свободного. Первая же пара стратегий не занимается этим, она использует новый бит для каждого нового элемента. Таким образом, список с такой стратегией имеет максимальную производительность доступа и ближе всего к классическому списку: и создание, и удаление элементов производится за константное время, не зависящее от количества элементов. Однако при этом он предоставляет некоторые гарантии целостности и безопасности в многопоточном окружении, пусть и ценой определённых затрат памяти.
Список же со второй парой стратегий, конечно, заметно медленнее. Тем не менее, он всё равно существенно быстрее вариантов с прямой проверкой. Так что действительно можно рекомендовать его в качестве некоторого промежуточного по производительности, но более оптимального по расходам памяти.
На самом деле списки со стратегией прямого поиска также будут работать медленнее при увеличении количества элементов в них: большее количество элементов придётся просматривать каждый раз. Просто за время теста список не успевает увеличиться настолько, чтобы это стало заметно несмотря на хаотичные колебания производительности.
Усреднённые значения производительности показывают, что стратегии с битовым массивом при последовательном его заполнении позволили увеличить производительность обращений к списку примерно в 200 раз, т.е. на 2 порядка, по сравнению со стратегиями прямого поиска. Это – весьма радикальное изменение. Производительность же вариантов с оптимальным по памяти заполнением бит, как было отмечено выше, конечно, заметно медленнее, но всё равно гораздо быстрее вариантов с прямой проверкой.
Стоит отметить также, что использование механизма передачи памяти по запросу несколько замедляет обращения к списку. Не слишком чтобы критично, но эффект присутствует и заметен, особенно – в варианте с экономным использованием памяти (жёлтая линия на графиках).
Тестирование по стратегиям блокировки
Рассмотрим теперь, как будет изменяться производительность списка при выборе различных стратегий блокировки. Я использовал три типа блокировок: «тонкая» блокировка SRWLock, обычная критическая секция Windows и мьютекс STL. По остальным же настройкам использовалась самая быстрая версия списка: двухсвязный, интеллектуальные указатели, стратегия проверки наличия элемента – SearchByIndex_BitArray, вариант без исключений.
Как и следовало ожидать, «тонкая» блокировка увеличивает производительность почти на 25%.
Скорость работы с критической секцией Windows и мьютексом STL примерно одинакова.
Исключения
Чтобы оценить влияние исключений на производительность, я провёл три теста. В первых двух использовался двусвязный список, интеллектуальные указатели, стратегия проверки наличия элемента – SearchByIndex_BitArray, критическая секция SRWLock. Для последнего теста использовалось всё то же самое, только блокировка была заменена на обычную критическую секцию для сравнения.
Видно, что поддержка исключений способна действительно снизить скорость работы, особенно если использовать более «грубый» вариант блокировки. Однако следует помнить, что в этом случае будет недоступна поддержка STL и циклов for по коллекции.
Выводы
Это был для меня весьма масштабный эксперимент. Имею ввиду вовсе не тесты выше, а весь проект целиком. Не ожидал сам, что он настолько затянется. Тем не менее я выполнил его целиком от и до в той мере, в которой планировал. Разумеется, в конечном итоге это всё равно не итоговый вариант, а лишь некоторый рабочий прототип, реализация описанных в начале статьи идей.
По результатам тестов ясно, что под Windows самым быстрым оказался двусвязный список с интеллектуальными указателями, стратегией проверки наличия элемента SearchByIndex_BitArray, критической секцией SRWLock и без исключений. В такой конфигурации список обеспечивает максимальную производительность при интенсивных хаотичных обращениях к нему из различных потоков и по поведению ближе всего к классическому списку с гарантиями безопасности в многопоточном режиме. Вариант с более экономным расходом памяти тоже весьма производителен (по сравнению с прямой проверкой DirectSearch), но всё же заметно медленнее, чем предыдущая, и его производительность падает с увеличением количества элементов.
Если вы думаете, что буду здесь агитировать за то, какую классную штуку я сделал и как здорово её использовать, то нет: на самом деле я начну с того, что буду вас отговаривать. В самом деле:
- Подумайте, не возможно ли использовать контейнер с другим расположением элементов: например, массив. Он не имеет таких проблем, как список.
- Если вы не храните никаких указателей или итераторов на конкретные элементы, то вполне допустимо использовать стандартный std::list и любые средства блокировки. Блокируйте список целиком и работайте с ним любым образом в одном потоке. Если список небольшого размера, а тем более если обращения к нему нечастые, то он не станет узким местом в производительности вашей программы. Используйте проверенные и стандартные средства там, где это возможно
, а не поделки левых программистов. Вы же не хотите,если у вас серьёзный бизнес,чтобы программа упала в самый неожиданный момент, а заказчики остались недовольны. - По возможности, упорядочивайте доступ к данным. Это справедливо и для предложенного здесь проекта: многопоточный список не знает, что делать, если окажется, что нужного элемента нет, так как он был удалён в другом потоке. Всё, что он сможет – это сообщить об этом в вызывающую программу, потому что только она может знать, как решить эту проблему.
- Любой предложенный здесь односвязный список либо даже двусвязный со стратегий прямой проверки наличия элемента ничем не лучше, чем стандартный с дополнительной внешней блокировкой. На самом деле, с точки зрения производительности он даже хуже, потому что ради гарантий безопасности выполняет колоссальную дополнительную работу по просмотру списка при каждой операции.
- Если вам важна производительность, обращение к списку частое, а он сам большого размера, вам следует использовать любую подходящую стратегию проверки наличия элемента через битовый массив. Размеры массива, а также прочие стратегии выбирайте исходя из условий и желаемых потребностей вашей программы. Однако при всём при этом это не гарантирует гладкую и безоблачную работу со списком. Например, список остановится с ошибкой, если один поток считывает значения из него, а другой – удаляет элементы вокруг считываемых значений. Таких сценариев следует избегать. Всё, что гарантируется – это целостность списка при максимальном уровне быстродействия доступа к нему. Вся ответственность за сценарий использования, а также что делать в случае ошибочных ситуаций, лежит целиком на вас. А также все возможные проблемы по расходу памяти на битовый массив, принудительную остановку на время его обслуживания и т.д. Однако, при выполнении всех мер предосторожности и наличии обработки ошибочных ситуаций, это позволяет организовать гибкую и производительную работу со списком из разных потоков, например, как в описанном выше случае, когда в его первой половине выполняется считывание или добавление данных, а во второй: изменение или удаление. Разбиение обращения на отдельные защищаемые операции вместо одной блокировки на время единственного длительного действия в одном потоке позволяет увеличить эффективность работы со списком.
- Стратегии с передачей памяти битовому массиву по требованию также хотя бы частично приближают многопоточный список к классическому: по крайней мере, до полного заполнения массива памяти будет занято ровно столько, сколько фактически требуется. Однако это влечёт за собой снижение производительности.
Недостатки проекта:
- Отмеченная ранее возможность взаимной блокировки в операции объединения списков.
- Все блокировки и разблокировки внутри классов делаются вручную, в стиле языка С. Знаю, что это некрасиво и нехорошо: лучше создавать объект, осуществляющий блокировку посредством механизма RAII: блокировка при создании объекта и автоматическая разблокировка при его уничтожении. Я взялся было переделывать на такой лад, но поскольку этих блокировок там уйма, я в какой-то момент остановился, махнул рукой и вернул всё как было. Если сделаю дерево, там сделаю сразу как надо. Ну, либо если пойму, что переделать это в списке всё-таки необходимо.
- Стратегии проверки наличия элемента не предусматривают создание нового битового массива, если старый полностью заполнен. Они лишь выбрасывают соответствующее исключение.
Надеюсь, это было интересно. Новичкам может быть полезно, т.к. всё рассматривается от простого к сложному. Профессионалов же попрошу сказать, насколько, на ваш взгляд, описанные здесь идеи применимы на практике в реальных проектах? Случался ли в вашей деятельности случай, когда по смыслу вам требовался список или дерево, а не другой контейнер, но он становился узким местом в вашей программе из-за описанных здесь проблем? Либо приходилось сильно изменять или усложнять программу. Если встречались с этим ранее, то как вы это решали?
Разумеется, по сути этот проект – лишь реализация моего собственного взгляда на решение этой проблемы. Вполне вероятно, что найдётся какой-нибудь вариант получше. Повторю мысль из начала, что я делал это изначально для себя и не планировал выкладывать на всеобщее обозрение. Но всё-таки я сделал это по описанным там же причинам, так что буду рад конструктивной критике.
P.S. При внимательном рассмотрении кода вы можете наткнуться на такую конструкцию:
//многократное наследование (допускает передачу последней структуры или класса в самый базовый)
class thisclass {}; //класс-пустышка, используемый для аргумента по умолчанию в классе, производном от ListElementData_OneLinked/ListElementData_TwoLinked
//элементы односвязного списка
template<class DerivedListElement = thisclass> class ListElementData_OneLinked1 : public ListElement_OneLinked<std::conditional_t<std::is_same<DerivedListElement, thisclass>::value, ListElementData_OneLinked1<>, DerivedListElement>, MemoryPolicy>
{
unsigned __int64 u64Value = 0; //некое значение узла
template<class List, bool bExceptions> friend class ListData; //объявляем шаблонный класс списка с данными привилегированным для обеспечения доступа из него
public:
ListElementData_OneLinked1(unsigned __int64 u64Value = 0) : u64Value(u64Value) {} //конструктор
};
template<class DerivedListElement = thisclass> class ListElementData_OneLinked2 : public ListElementData_OneLinked1<std::conditional_t<std::is_same<DerivedListElement, thisclass>::value, ListElementData_OneLinked2<>, DerivedListElement>>
{
using ListElementBase = ListElementData_OneLinked1<std::conditional_t<std::is_same<DerivedListElement, thisclass>::value, ListElementData_OneLinked2<>, DerivedListElement>>;
unsigned char ucSomeData[1024 - sizeof(decltype(ListElementBase::u64Value))]; //имитируем некоторые данные для заполнения памяти
template<class List, bool bExceptions> friend class ListData; //объявляем шаблонный класс списка с данными привилегированным для обеспечения доступа из него
public:
ListElementData_OneLinked2(unsigned __int64 u64Value = 0) : ListElementBase(u64Value) {} //конструктор
};Сия чёрная магия заслуживает отдельной статьи. Правда, это ещё менее практическая вещь, чем описываемый здесь многопоточный список, но она имеет свои любопытные особенности. Может быть, как-нибудь попозже я тоже об этом напишу.
