(Хабр-Статья представляет собой авторский перевод доклада, представленного автором на Scheme Workshop 2020, проводившегося в рамках Международной Конференции по Функциональному Программированию, 28 августа 2020 года)
Эта статья -- своего рода "отчёт" по самому большому проекту, который я сделал в своей жизни по собственной инициативе. Я сделал полное и всеобъемлющее решение всех задач из одной из самых извесных книг по программированию в мире "Структура и Интерпретация Компьютерных Программ" (Structure and Interpretation of Computer Programs -- SICP), за авторством Абельсона, Сассмана и Сассман.
В ходе выполнения проекте автор собрал довольно много данных о том, как решалось это задание в частности, и придумал несколько эвристик, помогающих выполнять проекты вообще, а именно:
Измерил полную трудоёмкость SICP (729 часов, 19 минут (больше 8 месяцев работы), распределённых по 292 учебным сессиям)
Сколько компьютерных языков потребовалось выучить (6)
Сколько программ потребовалось использовать (9)
В какой степени требовалась внешняя помощь.
В этой статье предлагается:
Практичный, поддерживаемый программно, протокол для решения любого вида домашней работы в электронном виде.
Несколько предложений по улучшению процесса преподавания любого вида технических навыков.
Несколько улучшений для процесса преподавания любых навыков в принципе.
Решебник доступен онлайн (в виде исходного кода, а также скомпилированного pdf):
В практическом смысле, результаты этой статьи (в частности, данные в приложении) могут быть востребованы прямо сейчас в качестве:
Точечной оценки трудоёмкости набора задач SICP.
Раздаточный материал для студентов-первокурсников, служащий повышению мотивации к учёбе.
Набора данных для изучения поведенческих паттернов характерных для взрослых, занимающихся самообразованием.
"Практически готового" протокола для выполнения любого представимого в виде дерева подзадач курсового задания, допускающего применение данного решения при трудоустройстве в качестве портфолио.
"Практически готового" и "почти удобного" протокола для измерения трудоёмкости любого набора задач, представимого в цифровом виде.
Данный отчёт подготовлен таким образом, чтобы анализ данных, произведенный по результатами измерения времени, был воспроизводим на машинах, поддерживающих org-mode.
(См приложение: "Код для анализа данных на Emacs Lisp" в английской версии доклада.)
Введение
Учебники программирования не часто сами становятся предметом изучения. Их задача -- обучать, а не быть изучаемыми. С другой стороны, преподавателям часто требуется разрабатывать курсы для своих учебных заведений, и им требуется на что-то опираться. Чаще всего, в качестве начального курса программирования выбирается изучение синтаксиса какого-нибудь одного языка программирования, выбранного случайно или согласно веяниям моды.
Однако, были попытки сделать дизайн вводного курса в программирование более систематическим. "Структура и Интерпретация Компьютерных Программ" была написана в результате одной из таких попыток. SICP был революционным уже в годы написания первого издания, и можно сказать, что остаётся революционным до сих пор. Через двадцать лет после выхода первого издания, практическая применимость книги была проанализирована Маттиасом Феллейсеном в статье "Stucture and Interpretation of Computer Science Curriculum". (См библиграфию) В ней рассматриваются плюсы и минусы курса, целенаправленно разработанного по всем правилам педагогического подхода. В ней же он предлагает то, что по его мнению, является "вторым поколением", продолжающим развитие этого "педагогического подхода". (См "How To Design Programs" Felleisen 2018)
Оставляя в стороне дидактическое качестве курса (автор сам не преподаватель), в этом отчёте рассматривается другая, намного реже анализируемая сторона обучения программированию (и вообще любому предмету) -- трудоёмкость. Сколько именно времени, рабочих часов, требуется для того, чтобы успешно завершить какой-либо курс?
Этот проект в каком-то смысле является продолжением предыдущего, во время которого автор сего текста учил уравнения математической физики традиционным методом, при помощи бумаги и карандаша, и механического таймера. Тот проект был плохо формализован, и на него невозможно сослаться. Однако, даже грубые измерения настолько тривиальным инструментом как таймер, выявили колоссальную разницу между тем, что заявляется в качестве трудоёмкости курса его создателями, и тем, что получается на самом деле.
Автор сего текста решил методически продолжить свой предыдущий опыт, и разработать процедуру, позволяющую контролируемым и не мешающим основной задаче способом измерять трудоёмкость. Программирование предоставлялось здесь очевидным местом для "входа в область". Компьютерные навыки, как кажется интуитивно, и измеряться должны проще всего.
Решебник был структурирован, разбит на части, оснащён программной системой для решения задач, и написан автором сего текста в полном объёме. Тем самым, декларируемая цель была достигнута, а трудоёмкость измерена.
Данные по измерениям находятся в общем доступе. (Прим. к русскому переводу: поскольку данные очень объёмны, в русском переводе они отсутствуют. Предлагается обратиться к английской версии.) Читателям, занимающимся преподаванием профессионально, предлагается в будущем разрабатывать курсы с учётом результатов, полученных в этой работе.
Если подходить к вопросу более широко, автор предлагает в целом осуществить переоценку процесса преподавания в специализированных институтах, и сформировать новую парадигму, основанную на эмпирических исследованиях. Необходимо точно понимать, что именно, в каком объёме, где и когда осуществляет каждая сторона, участвующая в образовательном процессе. Это необходимо, в частности, для того, чтобы понимать, где у системы слабые места и бутылочные горлышки, и для применения оптимизационных процедур. В программировании данный подход называется "профайлингом".
Подход к решению
Автор считает, что хороший решебник должен удовлетворять следующим принципам:
Быть полным.
Представлять собой достаточно реалистичную модель процесса решения задач, как будто бы если она осуществлялась целевой аудиторией курса: студентами начальных курсов высшего учебного заведения с небольшим опытом программирования, скорее всего, полученного в школе.
Быть полностью цифровым, написанным в цифровом субстрате изначально.
Быть измеримым.
В следующем параграфе рассмотрим подробнее, что имеется в виду.
Что имеется в виду под полнотой?
Что значит "решить все задачи курса"?
Автор этих строк считает, что полнота освоения материала -- необходимое условие прохождения любого курса обучения чему-либо.
Но как выразить на бытовом языке, что вообще такое "пройти курс" или "выучить предмет"?
Как можно, например, формализовать для проверки утверждением "я знаю математический анализ"?
Или, подходя в вопросу проще, что именно позволяет студенту, нормально освоившему материал, сказать "я выучил всё, что должен был выучить в рамках университетского курса математического анализа"?
Конечно, неплохо было бы провести исследование мнений всех заинтересованных сторон: учителей, учеников, работодателей, политиков, и абстрактных представителей "общества в целом", что для них значит фраза "знаю предмет хорошо".
Ниже представлены потенциальные ответы на этот вопрос, как они придуманы автором этого текста:
Сдать устный экзамен.
Сдать письменный экзамен.
Пройти процедуру защиты проекта перед советом (научным, диссертационным).
Успешно выполнить требуемое количество задач в рамках системы непрерывной оценки. (Примерно так, как это делается в начальной школе.)
Решить "большое домашнее задание". (Как это принято в МФТИ.)
Посетить определённое количество учебных сессий (лекций или семинаров).
Прочесть определённое количество учебного материала.
Всё вышеперечисленное, в некой комбинации, может быть объявлено "достаточным" для признания курса "освоенным", то есть перед нами задача из класса "goal attainment". (См: Gembicki 1975) Такие задачи, однако, всё равно решаются путём сведения многих целей к некоторой обобщённой "единой" цели.
Если посмотреть на задачу построения такой цели отстранённым взглядом (на жаргоне такая позиция иногда называется "точкой зрения марсианина", (см Э.Берн "Люди, которые играют в игры"), то покажется возможным свести все вышеперечисленные критерии к единому "выполнение большого домашнего задания". Грубо говоря, посещение лекции тоже можно в каком-то смысле считать "решаемой задачей из задачника". "Выполнение большого домашнего задания", в свою очередь, крайне трудно свести к другим видам целей, без потери внутренней структуры. Таковая внутренняя структура представляет собой древовидный список задач/подзадач, часть из которых искусственные. "Искусственные" задачи -- это как раз задачи вида "сходить на лекцию".
Если подходить к процессу обучения более прагматично, то самостоятельное выполнение больших домашних заданий -- это наиболее реалистичный способ обучения для взрослых людей, трудоустроенных на полную ставку, и не имеющих достаточно свободного времени для посещения очных занятий.
Выбор книги, посвящённой программированию, которая обязана своей известностью включённому в неё задачнику даже более, чем основному тексту, был довольно естественным.
Однако, нельзя сказать, что "решить все задачки из книжки" -- это достаточное условие для того, чтобы утверждать, что "материал освоен".
Поскольку автор хотел "сделать", а не "отделаться", то есть выучить предмет, а не просто решить задачки, то в изначальный план включал в себя придумывание новых задачек, для покрытия тех мест курса, для которых штатные задачи отсутствуют.
Эта часть плана не удалась, в первую очередь потому, что предъявить разбивку имеющегося курса по времени выполнения в какой-то момент показалось автору сего текста более важным. Тем не менее, при применении текущего подхода к другим курсам, с возможно более низким качеством составленных авторами задач, такую необходимость стоит иметь в виду.
Автор, однако, перерисовал несколько иллюстраций из книги, а именно те, которые не требовались для выполнения задач из задачника.
Сделано это было для того, чтобы получить ощущение, что автор (играющий роль студента) может при необходимости написать аналогичную книжку "из головы" и "по имеющимся материалам". Перерисовка осуществлялась для иллюстраций, покрывающих материал, по мнению автора, недостаточно представленный в задачах. Эти дополнительные иллюстрации не заняли слишком большого количества времени, и не повлияли на полную оценку трудоёмкости по порядку величины.
Качественная имитация университетского опыта
Одним из главных критических замечаний к настоящему проекту, может звучать следующим образом: В большинстве университетов (если не во всех) вообще-то, не требуется прорешать прямо уж все задачи из задачника, чтобы завершить курс успешно. Зачастую это верно, и в особенности в математических курсах. (Задачники по математике обычно включают в несколько раз больше задач, чем требуется для покрытия материала курса "в один слой".) Автор, однако, не считает, что таковая критика применима к задачнику из SICP. Задачи покрывают материал курса с минимальным пересечением, и автор (как указывалось выше), даже рассматривал возможность добавить собственных задач.
Другим важным критически замечанием является утверждение, что самостоятельное изучение предмета вообще принципиально не может качественно симулировать университетский опыт, ибо семинары и презентации являются его неотъемлимой частью. Предполагается, что методы решения задач приготовляются семинаристами согласованно с индивидуальными паттернами поведения студентов, и подаются в персонализированной манере.
Это валидное возражение. С другой стороны, несмотря на валидность, оно несколько идеализирует ситуацию в университетской среде. Семинаристы зачастую рекрутируются из имеющегося "пула", чаще всего, аспирантов, и не имеют ни необходимых знаний, ни педагогической подготовки. В таких случаях, настоящий отчёт может служить реперной точкой уже для семинаристов, для оценки времени, необходимого для подготовки к семинарам.
Более того, зачастую студенты не посещают большую часть занятий, либо из-за чрезмерной уверенности в себе, либо из-за конфликтов в расписании. Для таковых студентов настоящий отчёт также является возможной оценкой времени, необходимого для самостоятельной работы.
Более того, имеющиеся данные подсказывают, что для студентов в верхней квартили успеваемости, корреляция посещаемости с оценкой невелика. (См St_Clair 1999 A case agains compulsory class attendance policies in higher education и Kooker 1975 Changes in grade distributions associated with changes in class attendance policies)
Для студентов же, которые занятия посещают, настоящий отчёт может быть выдан в качестве рекомендованного чтения на первом занятии, для стимуляции посещения занятий.
Более того, самостоятельное выполнение курса не противоречит записи семинаров на видео и предоставления этих видео студентам для последующего ознакомления.
Недостаток интерактивности в записанных видео может бы скомпенсирован большим количеством материала, накапливаемым за годы проведения семинаров разными людьми для разных групп.
Мета-когнитивные упражнения
Мы часто недооцениваем степень неравенства в отношениях между учителем и учеником. Учитель не просто лучше знает предмет обучения -- это нормально -- но ещё и зачастую играет определяющую роль в том, как и когда студент будет учиться. (Автор не исключил бы, хотя это и требует дополнительного исследования, что курсы, преподаваемые по понедельникам, осваиваются лучше курсов, преподаваемых по пятницам.)
Часто преподаватели игнорируют этот факт, и рассматривают себя исключительно как источник знаний, или, что ещё хуже, только как экзаменаторов.
Следовательно, стоит рассматривать весь эффект, который оказывает учитель на ученика, целиком.
На практике, чаще всего у ученика нет иного выбора, кроме как доверять учителю вы выборе упражнений.
Ученик также склонен выбирать такие же инструменты для выполнения задачи, как и те, что выбираются учителем.
Основная мысль этого абзаца в том, что преподавание -- это не просто процесс передачи данных.
Это еще и процесс передачи метаданных, и развития метакогнитивных навыков. (См Ku 2010 Metacognitive strategies that enhance critical thinking).
Следовательно, передача метакогнитивных навыков, хотя она и является важной составляющей частью обучения, и выполняет важную роль в обучении студента "думать", заслуживает отдельного рассмотрения при написании курсов.
Примерами метакогнитивных упражнений являются:
Предъявление материала не согласно "естественному порядку", таким образом, чтобы более ранние (по порядовому номеру) задачи были неразрешимы без предварительного разрешения задач, более поздних по номеру или номеру главы.
Сознательная неполнота изложения материала.
Немногословность изложения, отсутствие предварительно заложенного дублирования материала во имя повторения пройденного.
Отсутствие готового предложения программного обеспечения, поддерживающего излагаемый материал.
Отсутствие оценки сложности или трудоёмкости для предлагаемых задач.
Демонстративно неравномерное распределение сложности задач.
Дополнительным вызовом гладкости и непрерывности процесса обучения является отсутствие поддержки среди людей занимающихся тем же самым делом.
Учебные заведения предпринимают попытки стимулировать взаимопомощь среди студентов, но насколько эти попытки успешны, не очень понятно.
Помогают ли в самом деле студенты друг другу в искусственно созданных группах поддержки и в учебных группах вообще?
Естественно, общение в учебных группах не ограничивается общением по теме предмета обучения.
До какой степени "непрофильное" общение влияет на учеников? Может, быть, оно более отвлекает от учёбы, нежели помогает учиться?
Способы поддержки важнее для взрослых, которые учатся самостоятельно, поскольку даже искусственных групп поддержки, созданных по разнарядке университетскими чиновниками, у них нет, как нет никакой регулярной учебной поддержки вообще.
Здесь надо заметить, что платформа, на которой осуществляется поддержка -- платформа для групповых чатов, или список рассылки, -- это важный социальный фактор, каким бы он не казался не имеющим отношения к предмету обучения.
Это не значит, что учитель должен создать группу поддержки обучения в той социальной сети, которая является модной на момент проведения курса.
Это значит, что вопрос о методе осуществления поддержки должен рассматриваться внимательно в каждом конкретном случае.
Личный опыт автора был таков:
IRC-канал irc:irc.freenode.org/#scheme был основным местом для задавания вопросов в режиме реального времени. Канал #emacs также был очень полезен.
http://StackOverflow.com использовался для задавания вопросов асинхронно.
The Scheme Community Wiki активно использовалась как дополнительный учебный материал.
Автор также напрямую посылал сообщения по электронной почте многим участникам сообщества Scheme.
Автор нашёл некоторое количество ошибок в документах, созданных в рамках процесса по работе с сообществом Scheme.
Автор задавал вопросы в списке рассылки Chibi-Scheme.
Автор получил некоторое количество помощи на Slack-чате Open Data Science.
Автор получил некоторую помощь от членов сообщества Closed-Circles.
Автор получил помощь от сообщества rulinux@conference.jabber.ru.
Автор получил помощь от членов Shanghai Linux User Group.
Автор получил помощь от участников онлайн-сообщества "научный форум" http://www.dxdy.ru.
Автор получил помощь от группы в Telegram, посвящённой изучению Haskell.
Следует заметить, что среди вышеперечисленных средств поддержки, только Open Data Science и группа, посвящённая Haskell, хостятся на "модных" платформах.
Взаимодействие с сообществом приведено в настоящем отчёте в подглаве "метакогнитивные упражнения", потому что навык поиска людей, которые могут тебе помочь, без сомнения, является метакогнитивным навыком, и более того, одним из самых сложных для преподания.
Более того, даже если знающие люди находятся, и могут дать ответы на вопросы студент, они, в большинстве ситуаций, совершенно не обязаны это делать. Таким образом, автор считает, что навык общения с некооперирующимися людьми должен рассматриваться на лекциях специально.
Повторяя главную мысль предыдущего абзаца: человеческие сообщества состоят из грубых людей. Естественно, нельзя заставить людей терпеть грубость, но нельзя также и заставить людей быть вежливыми.
Метакогнитивный навык извлечения ценных знаний из кооперативных, но грубых людей, также очень важен, и так же редко преподаётся.
Автор также считает важным довести до студентов и учителей следующую мысль: ни мода, ни популярность, лёгкая доступность, реклама, или социальная приемлемость, не являются важными факторами при выборе медиа для группы поддержки.
К сожалению, технологические преимущества, современность или удобство, также не являются важными факторами при выборе медиа. Важным является наличие информации, и наличие людей, способных помочь с задачами, решаемыми в рамках курса.
Помощь и поддержка, требуемые проектом по написанию решебника для SICP в цифрах:
Email-цепочек в списках рассылки, посвящённых компиляторам и интерпретаторам Scheme: 28.
Email-цепочек в списках рассылок, посвящённые IDE, текстовым редакторам и сообщениям об ошибках в них: 16.
Email-цепочек, посвящённых форматированию и оформлению: 20.
Email-цепочек, посвящённых непосредственно задачнику: 3.
Цепочек, посвящённых документации и ошибкам не в ней (а также отчётам о битых ссылках): 16.
Сообщений в IRC: 2394 сообщений, написанных автором на профильном канале.
Проектов, восстановленных на Software Forges (таких как Github), из архивов исходных авторов: 2.
В силу закрытости, идиосинкратичности, и нестандартизированности иных средств общения, таких как Slack, статистика по иным каналам общения не собиралась, но общение в них не было очень объёмным.
Перерисованные иллюстрации
Несколько иллюстраций из SICP были перерисованы с помощью языков программирования или генерации изображений.
Как было упомянуто выше, перерисовывались те иллюстрации, которые, как кажется, человек, освоивший курс, должен уметь рисовать для анализа своей ежедневной рабочей деятельности.
Также иллюстрации перерисовывались для покрытия тем, недостаточно покрытых задачами основного набора.
Список иллюстраций:
1.1 Древовидное изображение формулы, включая значение всех под-комбинаций.
1.2 Разбиение программы, вычисляющей квадратный корень, на процедуры.
1.3 Линейный рекуррентный процесс.
2.2 Box-and-pointer представление ~(cons 1 2)~.
2.8 Решение задачи о восьми ферзях.
3.32 Процедура интегрирования, представленная как система обработки сигналов.
3.36 RLC схема.
5.1 Пути распространения данных в регистровой машине.
5.2 Контроллер для машины, вычисляющей НОД.
Моделирование поведения, "вроливание" и выбор инструментов
Биография автора сего текста
Перед началом выполнения настоящего проекта, у автора уже была степень кандидата наук в Информатике, хотя и не в промышленном программировании.
Без сомнения, у автора было преимущество перед первокурсником.
Тем не менее, в значительно степени, опыт представляется релевантным, поскольку до момента начала выполнения задач, автор никогда не пользовался функциональными языками программирования, и редакторами программного кода более совершенными, чем Notepad++. Другим важным отличием от типичного первокурсника было то, что автор уже умел печатать десятью пальцами (так называемым, слепым десятипальцевым методом). Этот навык преподаётся в средних школах в США, однако всё ещё не является обязательным в большей части мира.
Замечание: данные, представленные в данном отчёте в большой степени зависят от навыка скоропечати слепым методом, и скорее всего, итоговая трудоёмкость для студентов, не владеющих методом слепой печати, окажется в константу раз выше. При отсутствии у студентов навыка скоропечати, измерения из данного отчёта невозможно брать за основу при оценке сложности разрабатываемого курса, а выбор инструментов может показаться странным.
Цель, которую автор поставил перед собой, была в какой-то степени противоречива, так как "модельный" студент, поведения которого автор старался придерживаться, не существует. Таковое поведение заключается в:
Выполнении всех упражнений честно, не обращая внимания на то, сколько времени они потребуют.
Не жульничать при выполнении упражнений (однако, консультироваться с решениями других студентов не запрещалось в той степени, в которой это не было прямым списыванием). Использовать инструменты, которые могли бы быть доступны студенту в 1987 году, хотя, возможно в современных версиях.
По возможности, следовать методологии "Свободного программного обеспечения, Программного обепечения с открытым кодом, и Unix-way", в формулировке широко известных организаций.
Попытаться подготовить "решение задач" в формате, потенциально применимом для "сдачи" в университете.
Первые три принципа не требовали больших сознательных усилий для соблюдения, последний же потребовал некоторой аккуратности выполнения и выбора инструментов.
Интересно, что личный опыт автора в университетском программировании большей частью был посвящён отладке процедур ввода-вывода.
На втором месте по трудозатратности была задача написания тестов.
Собственно решение программистских задач было только на третьем месте по трудоёмкости.
Широко известно утверждение, что SICP был целенаправленно разработан в качестве вводного курса. Автор предположил, что значительная часть программы будет посвящена первым двум задачам, указанным выше.
Выяснилось, что это не так.
Вместо того, чтобы решать эти две задачи, SICP игнорирует их, взамен предлагая очень жёсткий формат входных данных, в тоже время способный описать большую часть входящих данных.
Несмотря на то, что SICP совершенно не предполагался быть решённым в формате, в котором его решил автор, то есть в виде "весь решебник -- один файл, в котором входные данные, код, решающий задачу, и выходные данные включены в виде блоков интерактивной электронной тетради", (так называемый notebook-формат), тот факт, что SICP ограничивает возможные структуры, подаваемые на вход интерпретатора, сильно упрощает решение в вышеуказанном формате.
Противоречивость модели "идеального студента" выражается в необходимости сочетать две модели поведения, характерные для студентов. Одна представляет собой "ленивого" студента, который работал бы в той степени, в которой это необходимо, для того, чтобы "сделать курс", и не более того. Эта модель отвечает за то, чтобы затратить на проект минимально возможное время, и за то, чтобы выбрать такие инструменты, которые сделают процесс "сдачи задания" минимально времязатратным. Другая же модель отвечала "трудолюбивому" студенту, который был бы счастлив изучить материал настолько глубоко, насколько это возможно, и возможно, никогда курс не закончить, "потерявшись" в какой-нибудь наиболее интересной задаче, и должна была отвечать за качество работы, и за выбор наиболее "правильных" инструментов.
Таковые две модели студенческой мотивации в каком-то смысле отвечают концепции "Theory X and theory Y", предложенными McGregor ([[cite:mcgregor:1960:theory_x_and_theory_y]]).
Попытаемся представить себе "идеального студента", смесь двух вышеуказанных моделей, и попробуем принимать решения так же, как это делал бы он.
Неформально говоря, попробуем вести себя как "Я выучу все инструменты, которые потребуются для того, чтобы сделать работу, в том объёме, который потребуется, но не более того".
(Существуют намного более качественные модели поведения студентов, многие с применением математического моделирования (например Hlosta 2018 Modelling student online behaviour in a virtual learning environment), однако данная простая модель казалась достаточной при выполнении данного проекта.
Выбор инструментов
Конечный набор инструментов, применявшийся при выполнении проекта, следующий:
Chibi-Scheme :: реализация языка Scheme
srfi-159 :: инструмент для pretty-printing
srfi-27 :: библиотека случайных чисел
srfi-18 :: библиотека для работы с потоками
(chibi time) :: библиотека для работы с временем и датой
(chibi ast) :: (строго говоря, не требующаяся для решения) библиотека для работы с абстрактным синтаксическим деревом языка и экспансии макросов
(chibi process) :: использовался только для вызова ImageMagick
GNU Emacs :: в качестве IDE
org-mode :: в качестве основного носителя рабочих данных и в качестве основного инструмента для управления проектом
f90-mode :: как IDE для низкоуровнего языка
geiser :: расширение для Emacs для работы с Scheme, оказался неготовым к серьёзному применению, однако, оказался также полезен для выполнения небольших кусков кода
magit :: как графический инструмен для git
gfortran :: как низкоуровневый язык
PlantUML :: как язык рисования диаграмм первого выбора
TikZ + luaLaTeX :: как язык рисования диаграмм "второго выбора"
Graphviz :: как язык рисования диаграмм "третьего выбора"
ImageMagick :: как основной бэкэнд для написания реализации графической библиотеки
git :: как инструмент для контроля версий
GNU diff, bash, grep :: как инструменты для работы с текстом
(Список инструментов, который потребовалось освоить для решения SICP)
Chibi-Scheme была, по сути, единственной реализацией Scheme, поддерживающей самый свежий стандарт языка, r7rs-large (Red Edition), так что выбор был очевиден.
Выбор становится ещё более очевиден, если представить себя на месте студента, не желающего вдаваться в особенности тех школ мысли, которые привели к созданию огромного разнообразия различных реализаций Scheme, не до конца совместимых со стандартом.
Несколько библиотек, три из который стандартизированы, а три нет, потребовались для полного решения всех задач.
Невозможно решить все упражнения из задачника, пользуясь только стандартным языком Scheme.
Даже Scheme, вместе со всеми возможными расширениями языка, всё ещё недостаточно.
За пределами стандартных инструментов, потребовалась одна нестандартная библиотека, (chibi process), послужившая мостом к графическому интерфейсу.
git не часто преподаётся в школах.
Причиной тому может послужить то, что учителя могут не хотеть заниматься тем, что им самим кажется тривиальным, или, тем более, жизненно необходимым ("вы же не можете заниматься программированием без системы контроля версий?"), или перегрузка иными задачами.
Однако, практика показывает, что очень часто студенты ухитряются выпуститься из института, защитив диплом, и так и не выучив основных концепций управления версиями документов, что значительно тормозит рабочий процесс впоследствии.
Git был выбран в связи с тем, что это самая широко используемая система контроля версий.
ImageMagick оказалась самым простым способом создания изображений, состоящих их простых прямых линий.
Не существует стандартного способа связать приложения на Scheme с приложениями, написанными на других языках.
Согласно принципу минимального выхода за пределы курса, ImageMagick был выбран, как требующий одной-единственной нестандартной процедуры.
Более того, эта процедура, (простой синхронный вызов другой программы), вероятно вообще самый простой примитив для кооперации программ из когда-либо изобретённых.
Практически все операционные системы поддерживают запуск одними программами других программ.
PlantUML -- это реализация международного стандарта визуализации программ.
Её синтаксис незамысловат и хорошо документирован.
Интерфейс PlantUML-Emacs существует и относительно надёжен.
Текстовое представление воплощает в себе дух хакерства, и сильно упрощает контроль версий.
UML практически полностью доминирует на рынке визуализации программ, и практически любая университетская программа включает его, до какой-то степени.
Соответственно, автору показалось очень естественным решать те диаграммные задачи из SICP, которые допускали представление в виде UML, в PlantUML.
Применение Graphviz также являлось попыткой использовать (на этот раз уже другой) индустриальный стандарт для решения тех графических задач, которые не допускали решения в виде UML.
Язык ~dot~ хорошо разбирается машинным способом, и даже менее зависит от контекста, чем UML. Однако, на практике он оказался менее удобным.
TikZ -- это практически единственный язык рисования общего назначений.
В тех задачах, в которых общность модели изображений была шире, чем позволяют нарисовать UML и Graphviz, автор использовал TikZ.
Довольно естественным выбором было бы рисовать требуемые изображения при помощи инструмента с графическим интерфейсом, такого как Inkscape или Adobe Illustrator.
Однако, одна из проблем с изображениями, создаваемыми при помощи таких инструментов состоит в том, что они плохо обрабатываются системами контроля версий.
Вторая проблема заключается в том, что автору хотелось сохранить все результаты курса в одном цифровом артефакте (грубо говоря, в одном файле). Упаковка решения в один файл уменьшает путаницу, вызываемую большим количеством версий одного кода, делает поиск в коде намного более простой задачей, а также упрощает презентацию решения потенциальному экзаменатору.
gfortran, он же GNU Fortran, был выбран в качестве низкоуровнего языка для решения последних двух задач в задачнике.
Причины выбрать такой не самый популярный язык были следующими:
Автор уже знал язык Си, то есть имел преимущество перед гипотетическим "студентом-первокурсником".
Фортран достаточно низкоуровневый для решения низкоуровневых задач из SICP.
Существует свободная реализация Фортрана.
Фортран 90 уже существовал во время выпуска второго издания SICP.
GNU Unix Utilities автор изначально не планировал использовать, однако~diff~ оказался очень полезным для иллюстрации разницы между двумя кусками кода в Главе 5. Они также оказались полезными в качестве "клея", для соединения разных программ в единую систему.
GNU Emacs де факто является самой популярной IDE среди пользователей Scheme, это IDE используемая основателями Free Software Foundation, среди которых и авторы SICP, и, вероятно, использовался в качестве текстого редактора для написания SICP, также с большой вероятностью может быть выбран студентом-первокурсником из-за его ассоциации с "хакерской" субкультурой.
Это, вероятно, не очевидный выбор, поскольку на протяжении многих лет одной из самых популярных сред разработки среди первокурсников являлась Microsoft Visual Studio.
Другим возможным выбором был бы Dr. Racket, в который библиотеки, необходимые для прохождения SICP включены в поставку по-умолчанию.
Однако, для любителей Lisp, и для продвинутых студентов, Emacs всё ещё является популярным выбором, и поддержка Lisp в нём хороша, хотя для Scheme и не так хороша, как можно было бы подумать.
Наличие org-mode оказало решающее влияние на выбор Emacs, и она заслуживает отдельной подглавы.
Говоря неформально, выбор платформы Emacs в качестве главной операционной среды для работы на ЭВМ, оказался настолько важным, что полностью преобразил вообще всю парадигму в которой автор этого отчёта работает с вычислительными устройствами.
Кривая обучения для Emacs, без сомнения, очень крута.
Как было описано выше, одним из главных достижений этого отчёта является публикация данных, "профилирующих" выполнение задачника по временным ресурсам. В подолжении статьи будет рассказано, как именно данные собирались, при помощи механизмов учёта времени, встроенных в org-mode. Собранные данные включены в настящий отчёт в приложении, и не включают время, затраченное на изучение Emacs или org-mode. Однако, некоторое количество (менее надёжных) данных было собрано всё равно.
Прочтение руководства пользователя Emacs Liso потребовало 10 учебных сессий общей трудоёмкостью в 32 часа 40 минут.
Изучение Emacs в дополнение к прочтению руководства потребовало 59 часов 14 минут.
Org-mode как универсальный носитель документов, поддерживающий парадигму reproducible research.
Org-mode помогла автору разрешать зависимости между упражнениями.
Одно из мета-когнитивных упражений SICP -- это высокая степень зависимости упражнений друг от друга.
Например, упражнения из Главы 5 требуют наличия исходного кода, написанного в ходе решения задач Главы 1.
В современных учебных заведениях стандартной практикой является разделяемого кода между упражнениями при помощи операций "копировать" и "вставить".
Однако, в более поздние упражнения из задачника SICP, потребовали бы копирования десятков фрагментов кода, написанных в предыдущих главах.
Простое копирование привело бы к немедленному раздуванию файлов с решениями в несколько раз, и сделало бы поиск по файлу очень сложным. Более того, оно бы сильно усложнило пропагацию исправлений ошибок в более раннем коде, найденных во время решения задач из более поздних глав.
Люди, знакомые с работой Дональда Кнута могут узнать в org-mode идеи, впервые предложенные им в реализации системы WEB, в частности, программой web2c.
Другой крайне популярной WEB-образной системой является Jupyter Notebook, уже упоминавшаяся выше. (См Jupyter)
Org-mode помогает упаковать целый решебник в один файл.
Представим ситуацию, в которой студенту требуется отослать решение задач преподавателю на проверку.
Каждый дополнительный файл, который студент посылает -- потенциальный источник ошибок.
Даже если правильно и детально именовать файлы согласно их функции, что требует определённой мыслительной дисциплины, от преподавателя всё равно будет требоваться вникнуть в детали сборки проекта, которые станут бесполезными ровно в тот момент, когда он подпишет сдачу задания.
Ситуация выглядит ещё хуже, когда от преподавателя требуется не только оценить работу студента, но и протестировать, что часто случается с программистскими курсами.
Org-mode файлы могут быть экспортированы в форматы, которые удобны для применения в отдалённом будущем.
Представим иную ситуацию: применение студентом решённого задания для улучшения собственных перспектив трудоустройства.
Эта задача хорошо известна в области искусств. Студенты художественных и журналистских специальностей начинают собирать портфолио часто ещё до поступления в ВУЗ.
Однако студентам технических специальностей важность наличия портфолио ясна ещё не в полной мере.
Один из самых частых вопросов, который задаётся на собеседовании при трудоустройстве: "покажите нам, что вы уже сделали примечательного".
Наличие портфолио, в форме, которая легко предъявима на собеседовании, может быть невероятно полезной собеседуемому.
С высокой вероятностью, у потенциального работодателя не будет ни оборудования, ни желания запускать код вчерашнего студента.
Даже у студента самого, скорее всего, уже не будет в наличии отлаженной программной системы, в которой писался код на начальных курсах.
Следовательно, студенческая работа должна архивироваться в "переносимом" формате, и быть настолько устойчивой к эффектам течения времени и эволюции вычислительных систем, насколько это возможно.
Естественным образом, самый переносимый и устойчивый к влиянию времени формат -- это простая белая бумага.
В идеале, работа, после визирования преподавателем, должна быть форматируема в виде печатаемого отчёта.
Относительно небольшой объём работы (в сравнении с полной трудоёмкостью SICP), позволяющий конвертировать программный код в пригодный для печати отчёт, должен служить эмоциональным стимулом для студента проделать этот небольшой объём работы и получить элемент портфолио.
Естественно, "бумага" -- это не очень удобный формат для работы в 21 веке.
Однако, существует относительно удобное к нему приближение, формат PDF.
Таким образом, "исходный код" решения должен быть сравнительно легко и без повреждений экспортироваться в PDF.
Org-mode позволяет таковую конвертацию через PDF преобразователь, при помощи типографского пакета LaTeX.
У org-mode практически неограниченная применимость.
В частности, этот отчёт написан в org-mode.
Основными положительными сторонами применения org-mode для форматирования решебника можно считать интерактивность выполнения кода и лёгкость экспорта в печатные форматы. Однако, для данного отчёта ключевой возмжностью оказалась подсистема учёта времени с минимальными трудозатратами.
Как именно данные были собраны, описано в следующей подглаве. Также приведена статистическая выжимка этих данных, которую, однако, ни в коем случае нельзя считать всеобъемлющей.
Разные виды задач
Задачи из SICP можно грубо разделить на следующие классы:
Задачи, решаемые на Scheme, без ввода.
Задачи, решаемые на Scheme с вводом, который, возможно, является выводом других программ.
Задачи, решаемые на Scheme с графическим выводом.
Задачи, решаемые на "языке низкого уровня по выбору студента".
Математические задачи.
Задачи, требующие рисования диаграмм, подчиняющихся какому-либо стандарту технических иллюстраций.
Нестандартные упражнения, требующие рисования.
Эссе.
Примечательно, что совершенно отсутствуют задачи по анализу данных.
В этой подглаве будет рассмотрено, как эти классы задач разрешимы модели "единого документа".
Эссе представляют собой самый простой класс. Студент может писать соответсвующее эссе прямо под заголовком, соответствующим решаемой задаче.
Org-mode предоставляет минимальные возможности для форматирования текста, которых, однако, достаточно для реализации всех потребностей SICP.
Математические задачи требуют наличия системы TeX на машине студента, и используют возможности org-mode по встраиванию математических формул прямо в текст. Автору не потребовалось практически никаких вычислений с карандашом и бумагой для решения математических упражнений SICP.
Упражнения, решаемые на Scheme, то есть, большая часть задач, форматируются в качестве babel-блоков, вывод которых внедряется непосредственно под те блоки, в которых написан код, и обновляется по мере решения.
Упражнения, решаемые на Scheme с вводом требуют несколько больше работы для корректной организации. Не всегда очевидно, когда ввод является абстрактным простым текстом, и когда он должен быть проинтерпретирован как исполняемый код.
В итоге оказалось, что возможно представить код в качестве либо блоков "example", либо "code" с отключённым автоматическим выполнением, и указать их в качестве входных блоков при помощи директивы :stdin. Таким образом, и условия тестов, и результаты тестов оказалось возможным включить непосредственно в документ.
Упражнения, решаемые на языке низкого уровня, требовали оборачивания низкоуровнего кода в babel-блоки, и комбинирования этих блоков в единый файл при помощи блока типа shell.
В этом месте в решебник пришлось привнести зависимость от средств операционной системы. Однако, GNU Unix Utilities достаточно широко распространены, чтобы не считать это ограничение чрезмерным.
Задачи по программированию, с графическим выводом, оказались самой нетривиальной частью системы.
В итоге, автору пришлось написать специализированную библиотеку для Chibi-Scheme, использующую функционал ImageMagick.
Org-mode предоставляет специальные средства для вставки изображений прямо в файл. Решения задач таким образом выглядели как программы, генерирующие графические файлы, и подставляющие ссылки на эти файлы в тело документа для отображения средствами Emacs.
Упражнения, решаемые с помощью стандартных диаграмм, представляют собой часть проблемы, которая крайне широко распространения, но часто плохо понимается, быть может, потому, что люди, решающие её, происходят обычно не из программистского сообщества.
Есть несколько стандартный соглашений по технической визуализации и созданию иллюстраций и диаграмм, включая UML, ArchiMate, SDL и другие.
Когда иллюстрация, требуемая для решения задачи из SICP, допускала стандартизированное представление, автор старался предоставить таковое представление.
Для генерации диаграмм чаще всего использовался инструмент PlantUML, поддерживающий большое количество видов диаграмм, и с отличной поддержкой UML.
Система, org-plantuml, позволяющая связать её с Emacs, позволяла решать диаграммные задачи в такой же манере, как и программистские задачи -- при помощи babel-блоков.
Нестандартные диаграммные упражнения, самыми частыми из которых были упражнения, требующие изобразить диаграммы окружений (в каком-то смысле, интерфейс отладчика), оказались намного технически нетривиальными.
Когда заранее известная абстрактная модель (язык диаграмм) отсутствовал, диаграмму приходилось реализовывать "с нуля".
Для этого самым подходящим оказался язык TikZ.
Его применение потребовало больших временных затрат для прочтения руководства, и определённых уровень квалификации при работе с TeX.
Анализ трудоёмкости, профилирование эффективности, и графики
В этой подглаве мы рассмотрим как именно рабочий процесс был организован, и также покажем, некоторую аггрегированную статистику трудозатрат.
Детали рабочего процесса и профилирование
Задачи выполнялись в следующей манере:
В начале работы, дерево заголовков, соответствующее дереву глав/параграфов книги было приготовлено в org-mode.
Большая часть заголовков -- это TODO-заголовки. (За исключением небольшого количества заголовков, соответствующих параграфам без задач.)
TODO-заголовок -- это специальный вид заголовка в org-mode, экспортирующий своё состояние (завершено/не завершено) в простую базу данных, что позволяет мониторить долю выполненных задач в документе, главе, подглаве.
Промежуточные уровни (главы) не являются TODO-заголовками, однако, они содержат индикаторы, позволяющие узнать долю выполненных задач.
Самый верхний уровень дерева, таким образом, соответствует степени завершённости всего проекта.
Ниже представлен фрагмент дерева, в качестве примера:
* SICP [385/404] ** Chapter 1: Building abstractions ... [57/61] *** DONE Exercise 1.1 Interpreter result CLOSED: [2019-08-20 Tue 14:23]... *** DONE Exercise 1.2 Prefix form CLOSED: [2019-08-20 Tue 14:25] #+begin_src scheme :exports both :results value (/ (+ 5 4 (- 2 (- 3 (+ 6 (/ 4 5))))) (* 3 (- 6 2) (- 2 7))) #+end_src #+RESULTS: : -37/150 ...
Когда работа очевидно разделена на подзадачи, и для каждой единицы разбивки очевидна степень её завершённости, это создаёт в студенте ощущение контроля над выполняемым процессом.
Степень завершённости всего проекта, доступная в любой момент, создаёт важный эмоциональный стимул, ощущение приближения к желаемой цели с каждым решённым упражнением.
Требуются дополнительные исследования того, насколько это эмоциональный эффект устойчив, и насколько он зависит от неравномерной сложности задач, или от полной трудоёмкости задачника.
Есть, однако, исследования, которые утверждают, что наличие даже очень грубых KPI положительно сказывается на вероятности завершения проекта. (См: VanWormer 2008)
Согласно опыту автора, неравномерное распределение сложности по задачам нижнего уровня -- это огромный демотивирующий фактор.
С другой стороны, задачи, встречаемые в реальной жизни, не являются равномерно сложными, а значит возможность справляться с таковыми задачами являтся важным метакогнитивным навыком. Умение разделять большие задачи на малые, быть может, не в том, виде, который предлагается книгой или преподавателем, может являться одним из способов управления такими видами сложности. Следы такого подхода можно видеть в PDF решения, сделанном автором.
Проблемы решались практически последовательно.
Работа над следующей задачей начиналась в тот же момент, когда работа над текущей заканчивалась.
Из более чем 350 упражнений, только 13 были решены вне линейного порядка. (См подглаву [[* Задачи, решённые не по порядку и иные измерения]]) Последовательность решения задач важна для качественного профилирования времени, поскольку полным временем, отвечающим одной задаче, признавалась сумма продолжительностей учебных сессий между завершением предыдущей задачи и завершением текущей. Строгое соответствие последовательности решения задач последовательности из книги не требуется, однако в случае, когда задача откладывается на будущее, требуется удалить из базы сессий те сессии, соответствующие этой задаче, которые уже были проведены. Иными словами, задачи можно решать непоследовательно, но нельзя перемешивать сессии двух и более задач.
В этом отчёте "неудачные" подходы к задачам игнорируются. Это игнорирование не оказало сильного влияния на профайлинг, потому что неудачные подходы были очень короткими.
Необходимость последовательного решение -- это самая слабая точка настоящего отчёта. Обычно студенту трудно найти в себе мотивацию для последовательной работы. SICP требует строгой последовательности для некоторых подмножеств задач, зависящих друг от друга, однако, это "покрытие зависимостями" не всеобъемлюще.
В качестве самого простого способа справиться с нелинейностью при применении данного протокола к другим задачникам, автор может только предложить такой же подход -- выбрасывать неудачные сессии за базы данных. Это кажется всё-таки не самым большим ограничением, потому что зачастую довольно несложно понять, является ли задача "крайне трудной". Учебную сессию, на которую пришлась "очень трудная" задача, можно искусственно укоротить.
Автор прочитал всю книгу перед тем как начать проект по решению. Соответственно, время, затраченное на решение, не было учтено в оценке полного времени решения задач. Дело в том, что когда автор подошёл к прохождению курса с точки зрения решения задач, простое чтение текста оказалось практически бесполезным, и текст выглядел так, как будто он совершенно новый.
Автор приложил сознательные усилия для того, чтобы учебная сессия не закрывалась в тот же момент, когда и задача объявлялась решённой.
Причина этому -- применение хорошо известных трюков (См: Adler 1929 Some Factors Operating at the Moment of Resumption of Interrupted Tasks):
Когда что-то не доделано, вернуться к выполнению проекта проще, чем если выполнение было приостановлено в момент завершения чётко выделенной фазы.
Само прочтение условия задачи уже заставляет читателя начать решать задачу в бессознательном.
Данные представлены двумя наборами данных, тесно связанных друг с другом.
Набор данных 1: Времена завершения работы над каждыйм упражнением. (См Приложение: Данные по временам завершений решений задач) Для каждого упражнения, время его завершения было записано как временная метка org-mode, с точностью до минуты.
Набор данных 2: Учебные сессии записывались в отдельный org-mode файл в виде стандартного описания временного интервала (две временные метки):
"BEGIN_TIME -- END_TIME"
(См Приложение: Данные по учебным сессиям.)
Во время каждой учебной сессии автор старался уделять всё своё внимание выполнению проекта и не тратить время ни на что больше. Выполнение задач не ограничивается исключительно написанием кода и настройкой программной системы. Оно требует целого "пакета" действий по изучению предмета, ведущих к решению задачи. Таковые действия включают чтение и просмотр дополнительных материалов, задавание вопросов, исправление ошибок в программных инструментах, и подобные вещи, но не ограничиваются ими.
Несколько крупных ошибок в популярных программных продуктах были найдены во время написания решебника.
Эти ошибки были доложены авторам данных программных продуктов.
Некоторые ошибки были исправлены в течение короткого времени, тем самым позволив автору продолжить работу над решебником.
Для некоторых ошибок были найдены обходные пути.
Ни одна из ошибок в итоге не оказалась критической, мешающей завершить работу.
Очень удобным оказалось наличие инструмента по разрешению зависимостей.
Как было упомянуто выше, задачи из SICP используют друг друга.
Оказалось важным найти способ повторного использованя кода в рамках одного org-документа.
Возможности org-mode в части работы по принципу WEB (<<noweb>>-ссылок) оказалось достаточными для того, чтобы реализовать повторное использование всего кода, для которого это потребовалось. Noweb-ссылки -- это всего лишь способ включения блоков кода в другие блоки кода, без каких-либо преобразований. В частности, Упражнение 5.48 потребовало включения 58 различных блоков в блок, соответствующий окончательному решению. Даже копирование в данном случае не подошло бы, так как задача требовала исполнения кода, полученного в результате выполнения кода, написанного в предыдущих упражнениях. (Кодогенерация.) Как уже упоминалось, последующие упражнения помогают находить ошибки в предыдущих.
Задачи, решённые не по порядку и иные измерения
На следующей иллюстрации представлены некоторые статистические метрики, посчитанные по собранным данным.
729 часов полная трудоёмкость написания решебника.
2.184 часа в среднем на одну задачу.
0.96 потребовалось на решение медианной задачи.
94.73 часов потребовалось на решение самой сложной задачи: написания интерпретатора Scheme на языке низкого уровня.
652 учебных сессий.
1.79 учебных сессий было затрачено в среднем на одну задачу.
>78000-строк в итоговом файле с решебником. Это более 2.6 мегабайт, или 5300 страниц в PDF.
1 учебная сессия потребовалась для решения медианной задачи. Из разницы в два раза между средним значением статистик и медианным, можно сделать вывод, что самые сложные задачи требуют существенно больше времени, чем "типичные".
13 задач были решены не по порядку:
"Figure 1.1 Tree representation…"
"Exercise 1.3 Sum of squares."
"Exercise 1.9 Iterative or recursive?"
"Exercise 2.45 Split."
"Exercise 3.69 Triples."
"Exercise 2.61 Sets as ordered lists."
"Exercise 4.49 Alyssa's generator."
"Exercise 4.69 Great-grandchildren."
"Exercise 4.71 Louis' simple queries."
"Exercise 4.79 Prolog environments."
"Figure 5.1 Data paths for a Register Machine."
"Exercise 5.17 Printing labels."
"Exercise 5.40 Maintaining a compile-time environment."
Возможно, эти задачи можно считать самыми заковыристыми, хотя и не самыми сложными.
Десять самых трудоёмких задач
Exercise | Days Spent | Spans Sessions | Minutes Spent |
Exercise 2.46 ~make-vect~. | 2.578 | 5 | 535 |
Exercise 4.78 Non-deterministic queries. | 0.867 | 6 | 602 |
Exercise 3.28 Primitive or-gate. | 1.316 | 2 | 783 |
Exercise 4.79 Prolog environments. | 4.285 | 5 | 940 |
Exercise 3.9 Environment structures. | 21.030 | 10 | 1100 |
Exercise 4.77 Lazy queries. | 4.129 | 9 | 1214 |
Exercise 4.5 ~cond~ with arrow. | 12.765 | 7 | 1252 |
Exercise 5.52 Making a compiler for Scheme. | 22.975 | 13 | 2359 |
Exercise 2.92 Add, mul for different variables. | 4.556 | 11 | 2404 |
Exercise 5.51 EC-evaluator in low-level language. | 28.962 | 33 | 5684 |
Не противоречит бытовой интуиции тот факт, что написание интерпретатора Scheme на низкоуровневом языке (Exercise 5.51) оказалось самым трудоёмким.
В конце концов, оно потребовало изучения совсем нового языка с нуля.
В данном проекте этим низкоуровневым языком оказался Fortran 2018.
Изучение Фортрана оказалось довольно незамысловатым, хотя и требующим времени процессом.
Exercise 5.52, компилятор Scheme, подразумевало наличие уже решённого упражнения 5.51, потому что библиотека времени выполнения в этих упражнениях применялась общая. Скомпилированный EC-evaluator оказалсь одной (очень длинной) Fortran-функцией.
Exercise 2.29 доказывает, что даже при отсутствии в вашем языке программирования мутации (изменения значения переменной), можно сделать очень сложные задачи.
У этой задачи есть комментарий от авторов SICP: "Эта задача непростая."
И в самом деле, решение потребовало написания более 800 строк кода, разработки алгоритма нормализации символьных выражений с нуля, и потребовало написания 28 тестов.
Это просто очень большая задача.
Exercise 4.5 -- это задача, в которой наличие семинариста помогло бы больше всего.
Сама задача довольно простая.
Трудоёмкость происходит из-за того, что для того, чтобы проверить, что решение корректно, требуется собрать полностью рабочий интерпретатор Scheme.
То есть, упражнение предполагает прочтение всей главы 4, и сборку интерпретатора из фрагментов.
Более того, оно требует большого количества работы со списками, что само по себе непросто, если пользоваться только функциями, про которые рассказывается в SICP.
Exercise 4.77 требует большого количества модификаций наработанной кодовой базы, в разных местах. Пожалуй, это упражнение более всего нацеленное на преподавание "архитектуры ПО", за исключением, может быть, переписывания алгоритма раскручивания вычислений (backtracking) из Пролога.
Такого вида код очень трудно реализовать инкрементально и сложно проверить его работоспособность практически до самого завершения.
Более того, это упражнение требует модификации структуры данных самого нижнего уровня, и соответственно, пропагации изменения на все уровни абстракции выше.
Exercise 4.79, по существую, является плохо определённой задачей.
Автор считает её завершённой, однако задание сформулировано настолько размыто, что трудно определить, что именно точно требуется. Следовательно данная задача может потребить произвольное количество времени.
Exercise 3.9 предполагало реализацию библиотеки для построения диаграмм окружений.
Казалось бы, задача тривиальна, и должна решаться снимком экрана отладочной программы.
Однако, стандарт Scheme не предполагает никакого отладочного интерфейса.
Функционал для поддержки отладки кода отличается от реализации к реализации, и большинство не имеет никакой визуальной составляющей.
Существует библиотека EnvDraw (и её ответвления), но автор не нашёл лёгкого способа экспорта результатов её работы.
Оказалось проще реализовать построение диаграмм в TikZ и встроенных LaTeX-блоках.
Время, потраченное на Exercise 3.28 по большей части израсходовалось на сборку системы моделирования цифровых схем из фрагментов. Время, потраченное на решение самой задачи, было сравнительно невелико.
То же самое можно сказать про Exercise 2.46, большая часть времени из которого была потрачена на написание моста между интерпретатором и графической системой. Само упражнение довольно простое.
Суммируя, самые трудные в книге упражнения -- это те, которые требуют от студента:
реализовать тот функционал, который книга использует так, как будто он имеется в наличии, но стандарт его не поддерживает.
собрать разрозненные фрагменты кода в работающую программу.
решить задачи по темам, не покрытым материалом из книги.
Все вместе, десять самых сложных задач требуют 280 часов, что больше трети всего затраченного времени.
Позадачная разбивка трудоёмкости

Вышеуказанный график, пожалуй, лучше всего иллюстрирует распределение трудоёмкости задачника. Ожидаемо, несколько последних по порядковому номеру задач оказались самыми сложными. Вторая часть курса оказалась более трудоёмкой, чем первая.
Дни, затраченные на задачи
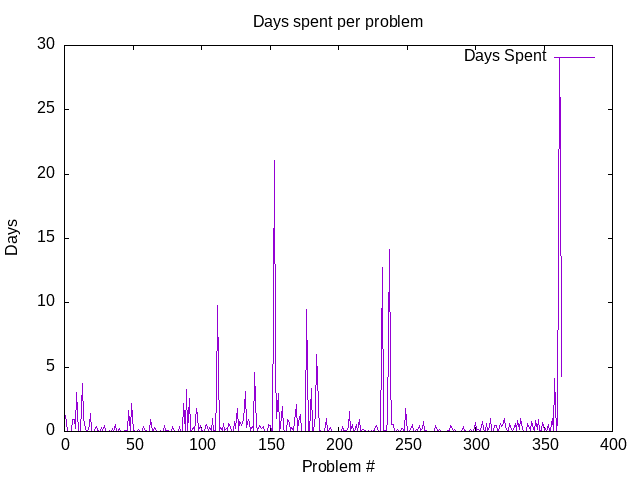
На этом графике можно видеть, какое количество дней (на оси ординат), задача под номером Х (ось абсцисс), была загружена в мозг автора. Простыми словами, сколько дней потребовалось на решение "задачи номер Х".
Эта метрика менее репрезентативна, чем "трудоёмкость задачи Х в часах", на предыдущем графике. Она, однако может служить в качестве способа побуждения студентов к дальнейшей работе, в случаях, когда штурм задачи не приносит быстрых результатов. Естественным образом, большинство задач (но не все), решаемы за одну сессию, или один день.
Второй пик в распределении, вероятно отвечает за общую усталость и потребность в отдыхе, и не связан со сложностью самой задачи. Соответствующий пик на графике часов менее заметен.
Учебных сессий на задачу
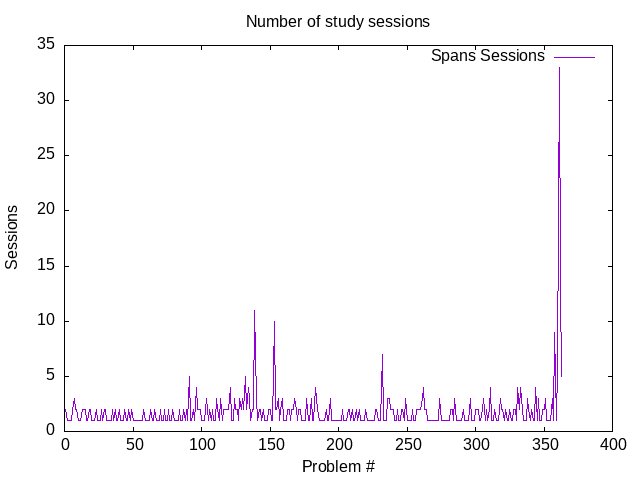
"Учебная сессия" -- это период высокой концентрации внимания, во время которого ученик активно пытается решить задачу, написать код или эссе. На данном графике отложена зависимость количества затраченных сессий от номера задачи, вне зависимости от длинны сессии.
Почему этот график имеет смысл? Когда ученик уходит на отдых, или каникулы, задача остаётся загруженной в мозг. Таким образом, периодические "штурмы", или учебные сессии могут быть полезными для поставки рабочих данных в бессознательное.
Во время отдыха, должен наблюдаться пик на графике "дней потраченных на задачу", но не "сессий, потраченных на задачу". Этот эффект, собственно, виден на втором пике на графике "дней, затраченных на задачу", и, соответственно, его пару на графике "сессий, затраченных на задачу". Его пара значительно короче.
Гистограмма сложности (линейная)

На линейной гистограмме отложено количество задач, требующих "размер корзины" часов на решение. Логично, что большинство задач разрешимы за один-три часа.
Гистограмма сложности (логарифмическая)
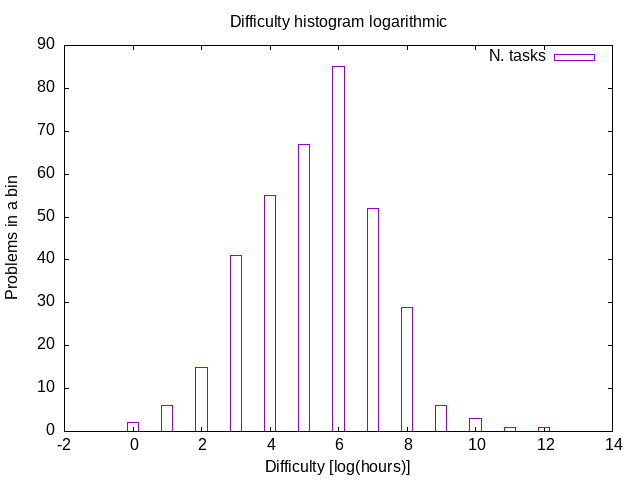
На логарифмической гистограмме отложено количество задач, требующих e^"размер корзины" часов на решение.
Интересно, что в логарифмическом масштабе наблюдается "купол", одномодального распределения.
Трудно понять, почему именно такая форма у графика.
Есть, однако, эмпирические результаты, показывающие, что такое лог-нормальное распределение сложности вообще характерно для задачников в целом. (См Crow 2018 Lognormal Distributions: Theory and Applications)
Заключение и возможные направления работы в будущем
Заключение
Как следует непосредственно из введения, этот отчёт представляет собой точечную оценку трудоёмкости задачника по программированию университетского уровня.
Насколько автору известно, это первый случай такого детального анализа университетского задачника.
Как было отмечено в параграфе "Задачи решённые не по порядку и другие измерения", полная трудоёмкость задачника составляет 729 часов. Попросту -- это очень много. Если считать, что в стандартном рабочем дне 8 часов, то полное решение требует 91 день, или 14 недель, или три с половиной месяца.
В предисловии ко второму изданию, авторы утверждают, что урезанная версия курса (с выброшенной главой, посвящённой логическому программированию, главой, посвящённой регистровым машинам, и большинству тем, посвящённых компиляции), может быть проведена за один семестр.
Это утверждение не противоречит данным, полученным во время подготовки данного отчёта. (Если предполагать работу в течение полного дня.)
Тем не менее, скорее всего преподаватели не будут включать вообще все задачи в "большое домашнее задание" по курсу, а будут делать какую-то подвыборку из задачника. Автор надеется, что этот отчёт может им в этом помочь, при оценке сложности.
С другой стороны, автор рекомендовал бы рассмотреть возможность организации двухсеместрового курса. Если убрать самые сложные задачи (те, что рассмотрены в параграфе "Десять самых трудоёмких задач", курс может быть вмещён в два 300-часовых односеместровых модуля. Триста часов на один курс в одном семестре -- это совпадает с похожими наблюдениями, сделанными автором в отношении курса уравнений математической физики, преподаваемого в Московском Физико-Техническом Институте.
Ещё одной частью курса, требующей отдельного внимания, является время, затрачиваемое преподавателями на проверку заданий, на оценку студентов и на написание фидбека.
Логично предположить, что проверка решений и написание фидбека должны занимать по порядку величины то же самое время, что и решение самого задачника, потому что каждую решённую задачу потребуется также проверить. Для простоты можно предположить, что проверка в десять раз проще решения, значит для полного курса она потребует 72 часа на работу одного студента.
Можно предположить, что в одной учебной группе 5 студентов (обычно больше, но для простоты посчитаем, что 5).
Значит, время, затрачиваемое на оценку будет 72*5=360 часов, или 45 полных рабочих дней.
Маловероятно, чтобы один преподаватель мог найти столько времени в семестре, или даже в двух. С другой стороны, если допустить возможность найма людей, в чьи должностные обязанности входила бы помощь семинаристам в проверке работ, проблема становится более реалистичной.
Ещё одним практическим приложением данного отчёта может быть его применение в качестве довода, которые профессора могли бы применить для обоснования потребности в найме дополнительного учебного персонала перед администрациями университетов.
Дальнейшая работа
Широкомасштабной оценки сложности (особенно с применением вычислительных инструментов) университетских предметов не проводится.
Данный отчёт является первым настолько подробным сложностным анализом университетского курса.
(Конечно, SICP успешно полностью решался в прошлом, однако без детальной оценки трудозатрат. Различные подходы к решению, разной степени завершённости, можно найти на Software Forges, таких как SourceForge.)
Одним из естественных продолжений данного направления исследования было бы применение этого же подхода к другим задачникам и другим предметным областям.
С другой стороны, данный отчёт представляет собой лишь точечную оценку, и тем самым крайне несостоятелен статистически. Его можно было бы качественно улучшить, организовав применение текущего протокола к тому же самому задачнику (SICP), разными людьми, вероятно, студентами целой группы или целого потока в высшем учебном заведении.
Представление детального описания протокола, а также описаний системы программной поддержки решения, автор считает важным достижением данного отчёта.
Преподавателям, преподающим такой или похожие курсы в высших учебных заведения, предлагается продемонстрировать настоящий отчёт своим студентом и предложить оформить решение по аналогии с описанным методом.
Другим направлением исследований может быть предложение модели разработки курсов за пределами предметов, преподаваемых в рамках SICP.
Достаточно ожидаемо, что студенты отказываются принимать участие в курсах, которые им кажутся чрезмерно сложными.
Иными словами вполне понятно, когда студент чувствует отчаяние от отсутствия прогресса в течение слишком долгого времени, и выбирает другой курс.
Было бы интересно измерить, какой уровень сложности является "чрезмерным" для каких студентов, и с чем это связано.
Не исключено, что "моменты отсечения" можно уловить, если измерять внутреннюю мотивацию каким-то образом (пока непонятно, каким), или правильно подбирать внешнюю мотивацию (правильно выбирать KPI, поощрения и штрафы, или применять какие-то иные средства).
Было бы интересно сравнить успешность завершения курса среди студентов, которые следуют протоколу, описанному в настоящем отчёте, с таковой у студентов, от него отказавшихся.
Возможно, такой эксперимент мог бы реализовать "тест самоопределения" по Deci and Ryan. (См Ryan 2017 Self-Determination Theory)
Ещё одним направлением исследования может быть разработка и формализация форматов подготовки "больших домашних задания", упрощающая сбор похожих данных по другим предметам.
Неформальный обзор
В этой подглаве предлагаются субъективные ощущения автора от завершённого проекта.
Автору проект показался интересным.
С другой стороны, автор ни на секунду не готов поверить, что найдётся статистически значимое количество студентов-первокурсников, способных его повторить.
Крайне маловероятно, что живой человек сможет посвятить семьсот часов решению задач по одному предмету, пусть даже этот предмет разбит на два семестра. Также следует учитывать, что с момента выхода SICP прошло 25 лет, и технологии программирования сделали огромный шаг вперёд. Даже если найти такого целеустремлённого студента, у него скорее всего будут в семестре иные курсы, а также ему будет требоваться время для посещения лекций и семинаров.
С другой стороны, автор не может найти среди 353 упражнений ни одного лишнего. Более того, по некоторым темам автору пришлось самому добавить несколько упражнений.
Каждая задача раскрывает какую-то важную концепцию, и стимулирует студента мыслить глубже.
Курс можно было бы расширить в сторону более широкого обзора систем сборки мусора и иного управления памятью.
Основной сборщик cons-памяти описан хотя и сухо, но в деталях достаточных для его реализации. Другие же компоненты модели памяти не описаны никак. Ничего не сказано об эффективных механизмах хранения чисел, строк и иных объектов.
Очень мало внимания посвящено описанию эвристик, полезных при решении задач разработки ПО.
Эвристики, вероятно, нельзя назвать фундаментальным знанием, но трудно переоценить их полезность для профессионального программиста.
Последние два упражнения занимают две трети всего времени, требуемого для завершения проекта.
Оказалось крайне неожиданным увидеть в самом конце задачи, которые требуется решать на языке, отличном от Scheme, применяющемся для большинства упражнений.
Пожалуй, самый большой недостаток -- это отсутствие какого-либо заключения и предложений возможных путей продолжения образования, например, в области строгой типизации, моделирования физических систем, или обработки данных.
Книга предлагает обширный список литературы, и теоретически, работу можно продолжить путём прохода по ссылкам оттуда.
Автору, однако, хотелось бы видеть более заключение более нарративного формата, включая высокоуровневый обзор всей области искусственного интеллекта.
Неформальные рекомендации
Автор хотел бы позволить себе смелость дать несколько технических рекомендаций разработчикам ВУЗовских программ обучения. Эти рекомендации менее фундаментальны, однако автору кажутся сильно упрощающими жизнь.
Уделить отдельное внимание преподаванию ТеХа в своих курсах, и не просто ТеХа как программы, а всей инфраструктуры типографики и компьютерной графики. Мы живём в электронном мире, и логично создавать контент университетского уровня в формате, родном для электронных медиа.
Эта область знаний часто оставляется студентам в качестве "внеклассного чтения", однако опыт автора показывает, что степень проникновения ТеХ всё ещё слишком мала. Крайне мало студентов, да и профессионалов, применяют ТеХ эффективно, и почти никто не пишет своих стилевых файлов. Автору потребовалось более 50 часов на то, чтобы обновить навыки \TeX{} для написания диссертации, при том, что ещё до этого автор уже использовал ТеХ в институтские годы. ТеХ дожен преподаваться на первом курсе.Учите студентов слепому десятипальцевому методу печати. Это может показаться избыточным в тех частях Земли, где слепой метод печати входит в школьную программу, однако в большей части мира это всё ещё не так.
Научите студентов читать руководства к ПО. В последние 30 лет наблюдается тенденция к написанию "дружелюбного" ПО, которое либо не требует освоения, либо имеет руководства, встроенные в интерфейс. Часто, прочтение руководства не требуется для успешного решения задачи. Однако, опыт прочтения хотя бы одного руководства от первой страницы до последней так, как будто это литературное произведение (технической литературы), -- это очень просветляющий опыт, как минимум очень полезный в деле структурирования ментальной модели навыков построения технических систем, а также крайне полезный в деле понимания, как именно авторы представляли себе применение их программного продукта. Навыкам чтения длинных текстов обычно обучают в средней школе на уроках литературы, и достаточно приятно осознавать небесполезность этих навыков после выпуска. В качестве побочного эффекта, опыт прочтения руководства может помочь студентам самим писать более грамотные и приятные для прочтения руководства.
Научите ваших студентов делать домашние задания с таймером, пусть даже не с полноценным профилировщиком, таким как org-mode. Реалистичная оценка трудоёмкости заданий очень хорошо лишает иллюзии всемогущества сильных студентов, а также помогает студентам послабее планировать свою работу.
Когда вы пишете учебное пособие, начинайте писать его с составления упражнений, и уже затем пишите текст, склеивающий эти упражнения в единую концепцию и предоставляющий навыки, необходимые для решения. Прочтение SICP без решения задач оказалось практически бесполезным для выполнения этого проекта.
Рассмотрите возможность ознакомления студентов со стандартами индустриальных диаграмм (UML, ArchiMate), в рамках своих вводных курсов программирования. Курсы, которые специально разработаны как "курсы по UML", чаще всего страдают оторванностью от реальности. (Мало кому нравится рисовать миллионную вариацию на тему UML-модели банкомата.) Вводное программирование предоставляет намного более близкую студенту предметную область, которую, соответственно, проще отрисовать.
Материалы
В данной подглаве представлен полный список материалов, использованных при написании решебника. (Это не список литературы, использованный для написания настоящего отчёта.)
Книги
Structure and Interpretation of Computer Programs 2nd Ed. (Abelson 1996)
Structure and Interpretation of Computer Programs 1st Ed. (Abelson 1985)
Modern Fortran Explained 2018. (Metcalf 2018)
Revised(^7) Report on Algorithmic Language Scheme. (Shinn 2013)
Logic Programming: A Classified Bibliography. (Balbin 1985)
Chibi-Scheme Manual.
TikZ Manual.
PlantUML Manual.
UML Weekend Crash Course. (Pender 2002)
GNU Emacs Manual.
GNU Emacs Lisp Reference Manual.
GNU Emacs Org-Mode Manual.
Debugging With GDB.
Implementations of Prolog. (Campbell 1984)
Программы
GNU Emacs.
Org-mode for Emacs.
Chibi-Scheme.
MIT/GNU Scheme. [For for portability checks].
Geiser.
GNU Debugger (GDB).
luaLaTeX/TeX Live.
TikZ/PGF.
PlantUML.
Graphviz.
Slackware Linux 14.2-current.
#+latex: \nocite{Schulte:Davison:Dye:Dominik:2011:JSSOBK:v46i03}
Статьи
Revised Report on the Propagator Model. (Radul 2011)
On Implementing Prolog In Functional Programming. (Carlsson 1984)
eu-Prolog, Reference Manual. (Kohlbecker 1984)
Литература
Harold Abelson and Gerald J. Sussman. Structure and Interpretation of Computer Programs. MIT Press, 1 edition, 1985. [ bib ] |
Harold Abelson, Gerald J. Sussman, and Julia Sussman. Structure and Interpretation of Computer Programs. MIT Press, 2 edition, 1996. [ bib ] |
Dan L. Adler and Jacob S. Kounin. Some factors operating at the moment of resumption of interrupted tasks. 7(2):255--267. [ bib | DOI | http ] |
Isaac Balbin and Koenraad Lecot. Logic Programming. Springer Netherlands, 1985. [ bib | DOI | http ] |
Eric Berne. What Do You Say After You Say Hello? Bantam Books, New York, 1973. [ bib ] |
John A. Campbell, editor. Implementations of Prolog. Ellis Horwood/Halsted Press/Wiley, 1984. [ bib ] |
Mats Carlsson. On implementing Prolog in functional programming. 2(4):347--359, 1984. [ bib | DOI | http ] |
Karen L. St. Clair. A case against compulsory class attendance policies in higher education. 23(3):171--180, 1999. [ bib | DOI | http ] |
Edwin L. Crow and Kunio Shimizu. Lognormal Distributions: Theory and Applications. Routledge, 5 2018. [ bib | DOI | http ] |
Carsten Dominik. The Org-Mode 7 Reference Manual: Organize Your Life with GNU Emacs. Network Theory, UK, 2010. with contributions by David O'Toole, Bastien Guerry, Philip Rooke, Dan Davison, Eric Schulte, and Thomas Dye. [ bib ] |
Matthias Felleisen, Robert Bruce Findler, Matthew Flatt, and Shriram Krishnamurthi. The structure and interpretation of the computer science curriculum. 14:365--378, 07 2004. [ bib | DOI ] |
Matthias Felleisen, Robert Bruce Findler, Matthew Flatt, and Shriram Krishnamurthi. How to Design Programs: an Introduction to Programming and Computing. The MIT Press, Cambridge, Massachusetts, 2018. [ bib ] |
Free Software Foundation. GNU debugger, 2020. [ bib | http ] |
Floyd W. Gembicki and Yacov Y. Haimes. Approach to performance and sensitivity multiobjective optimization: The goal attainment method. 20(6):769--771, December 1975. [ bib | DOI | http ] |
Martin Hlosta, Drahomira Herrmannova, Lucie Vachova, Jakub Kuzilek, Zdenek Zdrahal, and Annika Wolff. Modelling student online behaviour in a virtual learning environment. 2018. [ bib ] |
Eugene Kohlbecker. eu-Prolog, reference manual and report. Technical report, University of Indiana (Bloomington), Computer Science Department, 04 1984. [ bib ] |
E. W. Kooker. Changes in grade distributions associated with changes in class attendance policies. 13:56--57, 1976. [ bib ] |
Kelly Y. L. Ku and Irene T. Ho. Metacognitive strategies that enhance critical thinking. 5(3):251--267, July 2010. [ bib | DOI | http ] |
Douglas McGregor. Theory X and theory Y. 358:374, 1960. [ bib ] |
Michael Metcalf, John Reid, and Malcolm Cohen. Modern Fortran Explained. Oxford University Press, 10 2018. [ bib | DOI | http ] |
Vladimir Nikishkin. A full solution to the structure and interpretation of computer programs. [ bib | http ] |
Thomas Pender. UML Weekend Crash Course. Hungry Minds, Indianapolis, IN, 2002. [ bib ] |
PlantUML Developers. Drawing UML with plantuml. [ bib | http ] |
Project Jupyter Developers. Jupyter Notebook: a server-client application that allows editing and running notebook documents via a web browser., 2019. [ bib | http ] |
Alexey Radul and Gerald J. Sussman. Revised report on the propagator model. [ bib | http ] |
Richard M Ryan and Edward L Deci. Self-determination theory: Basic psychological needs in motivation, development, and wellness. Guilford Publications, 2017. [ bib ] |
Alex Shinn, John Cowan, Arthur A. Gleckler, et al., editors. Revised7 Report on the Algorithmic Language Scheme. 2013. [ bib | http ] |
Richard Stallman et al. Debugging with GDB, 2020. [ bib | .html ] |
Richard Stallman et al. GNU Emacs Lisp Reference Manual, 2020. [ bib | .pdf ] |
Richard Stallman et al. GNU Emacs Manual, 2020. [ bib | .pdf ] |
Jeffrey J. VanWormer, Simone A. French, Mark A. Pereira, and Ericka M. Welsh. The impact of regular self-weighing on weight management: A systematic literature review. 5(1):54, 2008. [ bib | DOI | http ] |
Patric Volkerding et al. Slackware Linux, 2019. [ bib | http ] |
Приложение: Проанализированные данные о сложности задач
Данное приложение состоит целиком из данных. Во избежание дублирования и ошибок, с ним связанных, читатели приглашаются обратиться к английской версии доклада. https://arxiv.org/abs/2101.06759
Приложение: Гистограмма трудоёмкости линейная
Данное приложение состоит целиком из данных. Во избежание дублирования и ошибок, с ним связанных, читатели приглашаются обратиться к английской версии доклада. https://arxiv.org/abs/2101.06759
Гистограмма трудоёмкости логарифмическая
Данное приложение состоит целиком из данных. Во избежание дублирования и ошибок, с ним связанных, читатели приглашаются обратиться к английской версии доклада. https://arxiv.org/abs/2101.06759
Приложение: данные по учебным сессиям
Данное приложение состоит целиком из данных. Во избежание дублирования и ошибок, с ним связанных, читатели приглашаются обратиться к английской версии доклада. https://arxiv.org/abs/2101.06759
Приложение: данные по временным меткам завершений решения задач
Данное приложение состоит целиком из данных. Во избежание дублирования и ошибок, с ним связанных, читатели приглашаются обратиться к английской версии доклада. https://arxiv.org/abs/2101.06759
Приложение: Код на Emacs Lisp для анализа данных
Данное приложение состоит целиком из данных. Во избежание дублирования и ошибок, с ним связанных, читатели приглашаются обратиться к английской версии доклада. https://arxiv.org/abs/2101.06759

