Статья об одном неудачном решении, которое распространено при переходе на микросервисы. Несмотря на то, что Microsoft и другие компании в своих руководствах рассматривают возможность создавать Entity Services, есть все основания считать его антипаттерном. Далее мы поговорим о том, что такое Entity Service и какими свойствами он обладает для конечной системы в целом.
Entity Service - что это такое? И как возникает идея о его создании?
Все слышали, что разбиение монолита на микросервисы дает много плюсов. Повышается гибкость, простота, масштабируемость, отказоустойчивость и т.п. Однако можно услышать и критику микросервисного подхода за сложность обеспечения консистентности данных, ведь невозможно расшарить транзакцию между несколькими микросервисами - они общаются по http. Да и сама система в целом становится сложной - куда проще убрать http вызовы и объединить все обратно в монолит с обычными вызовами из кода.
Это наводит на мысль, что не достаточно просто разбить монолит на несколько составных частей. Нужно сделать это правильно. Типичный монолит работает с базой данных и содержит несколько экземпляров для повышения производительности и отказоустойчивости.
Предположим, что наш монолит представляет собой интернет магазин. В нем есть список товаров, можно зарегистрироваться как пользователь, оформить заказ, оплатить его и оформить доставку. Появляется идея распилить монолит на микросервисы. Внутри кода монолита уже есть сущности - заказ, товар, пользователь, доставка и т.п. Выделить их в виде отдельных микросервисов проще всего. Достаточно заменить вызовы в коде на вызовы по http, скопировать код сущности в новый сервис, сделать API фасад и т.д. В итоге получим сервис заказов, пользователей, товаров, доставки и т.д.
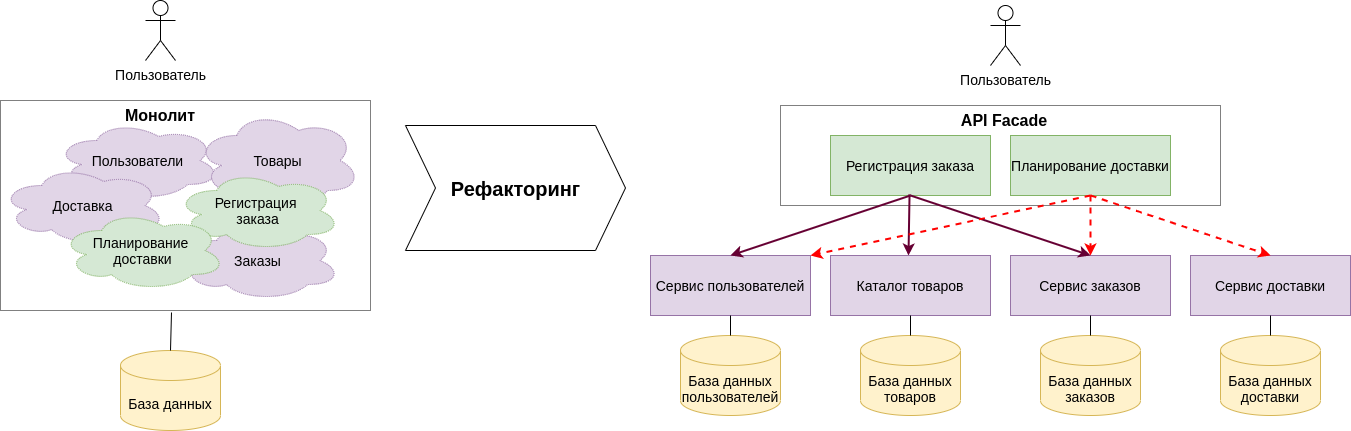
На рисунке регистрация заказа и планирование доставки остались внутри фасада, но они могут быть вынесены в отдельные сервисы - в рамках нашего примера это не самое главное.
Такие сервисы называют одним термином - Entity Service. Это сервисы, которые содержат только CRUD операции для одной сущности и ничего более.
Сразу видно, что у обоих операций (регистрация заказа и планирование доставки) происхоит как минимум по три вызова entity сервисов. И по мере добавления нового функционала ситуация будет только ухудшаться. В итоге у каждого из таких сервисов будет большое число входящих связей.
Все это ведет к следующим недостаткам:
При реализации нового функционала вы можете сломать уже существующий. Допустим, вы меняете метод обновления заказа и удаляете оттуда один из параметров (либо добавляете). В вашем сценарии все хорошо, но в других может быть и нет.
Отказоустойчивость не очень высокая. Если падает все тот же сервис заказов - не работают все сценарии, в которых он участвует. А мы с вами уже видели, что участвует он почти везде. Все таки отказоустойчивость лучше, чем у монолита - сценарии, где заказ не участвует - будут работать.
Сложность отладки. Если сравнивать с монолитом, то все стало хуже. Теперь код находится в разных процессах и нужны инструменты вроде Jaeger Jaeger: open source, end-to-end distributed tracing.
Дополнительные накладные расходы по производительности. Вызов удаленного метода дороже, чем внутри одного процесса.
Несмотря на все это в документации по микросервисам от Microsoft рассказывается как сделать такой сервис: Creating a simple data-driven CRUD microservice
Как избавиться от Entity Service?
Для рассмотрения решения по рефакторингу entity service удобно рассмотреть другой пример. Допустим у нас есть интернет ресурс в котором авторы могут публиковать свои статьи (вроде блога или Хабр). Есть следующие возможности:
автор может предложить к публикации статью;
сайт проверяет уникальность иллюстраций, не встречаются ли эти картинки где либо еще;
сайт проверяет уникальность текста, учитывает семантику текста. Если он написан синонимами, но о том же - отсеиваем;
модератор сайта может вносить правки в статью (изменять форматирование заглавной иллюстрации, править текст ссылки);
модератор публикует финальную версию;
посетители сайта могут видеть список публикаций по категориям.
Реализация с Entity Service может быть такая:

Автор с помощью API автора публикации загружает статью на сайт, который вызывает Сервис публикаций и создает там новую сущность. Далее вызывается Сервис проверки уникальности текста, Сервис оценки иллюстраций - все они обновляют сущность публикации в одноименном сервисе. Вполне возможно, что у этой сущности проставляется признак ее допуска к модерированию. После этого уже модератор через Сервис модерирования опять же работает с сущностью из Сервиса публикаций. На схеме выше оставлены не все связи, чтобы не загромождать ее лишними деталями.
Есть как минимум два способа избавиться от entity service. В первом случае мы обращаем внимание на поведение, а не на сущности и данные. Таким образом, мы пытаемся представить сам бизнес-процесс, где каждый из шагов в нем - отдельный сервис:
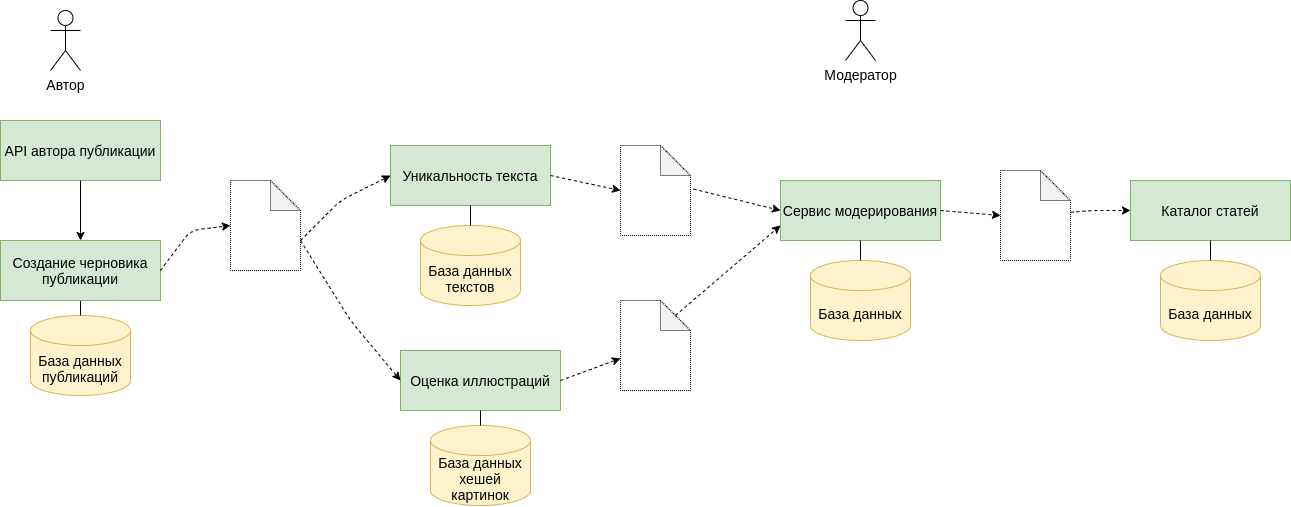
Аналогично предыдущим рисункам здесь каждый кубик - отдельный сервис. Только сама публикация не хранится в каком-то одном хранилище. По мере прохождения бизнес-процесса по его стадиям в эти микросервисы отправляется вся необходимая информация по этой публикации. Каждый из сервисов забирает только то, что ему нужно непосредственно для работы. Например, при оценке иллюстраций нам интересны ссылки на картинки. Далее сервис считает для каждой картинки хеш и по базе данных хешей сравнивает с другими иллюстрациями. Сама по себе эта база данных, кроме сервиса оценки иллюстраций, больше никому не интересна, интерес представляют пометки для иллюстраций в исходной публикации. Дубликат или нет. Именно такой информацией наша изначальная публикация обогащается и идет дальше.
Проверка уникальности текста похожа на проверку уникальности иллюстраций по структуре своей работы. Только алгоритм и его база данных совсем другие. Итого, в сервисе модерирования оказываются уже публикации, прошедшие все проверки и подготовленные для рассмотрения модератором. Модератор может делать правки, может оставлять заметки, что-то исправлять - информация об этом точно также может оставаться в самом сервисе модерирования. Использоваться как история. Однако в итоге на выходе мы получаем уже опубликованную статью.
Пример сильно упрощен, но мне думается, основную идею он хорошо отображает. В целом он использует один из принципов функционального программирования - неизменность (immutability). Мы не храним какое-то состояние в одном месте, а по мере работы генерируем новую информацию. Из плюсов такой реализации:
Каждый сервис получается маленьким и не содержит много кода.
Структура сервисов приближена к реальному бизнес-процессу.
Не возникает проблем с конкурентным доступом к одним и тем же данным в ходе выполнения бизнес-процесса.
Потенциально выше производительность, т.к. у каждого сервиса есть своя копия данных.
Проще реализовать согласованность в конечном счете (eventual consistency).
Проще производить горизонтальное масштабирование. Например, если один из микросервисов очень ресурсоемкий.
Недостатки тоже есть:
Потенциально сетевой трафик больше.
Нужно больше места на диске.
Если вы еще не используете такой подход - есть подсказка. Вместо существительных в названии сервисов должны быть глаголы. Тогда сервисы будут в большей степени ориентированы на поведение, нежели на данные.
Еще один вариант, на который имеет смысл обратить внимание - это выделение микросервисов по поддоменам. Pattern: Decompose by subdomain По ссылке выше есть еще варианты разбиения на микросервисы, но именно два вышеупомянутых имеет смысл рассмотреть в первую очередь.
Оба варианта отлично сочетаются - вы вполне можете их совместить. Главное избежать всех недостатков Entity Service.
Доводилось ли вам сталкиваться с данным антипаттерном в своей практике? Как бы вы предложили рефакторить системы, где он уже есть? Задавайте вопросы, высказывайте свои мысли в комментариях. Интересно ваше мнение!

