
В настоящее время уже сложно найти крупную компанию, которая не использовала бы возможности накопления и использования больших данных. Меня зовут Никита Сурков и я работаю в проекте ценообразования "Пятёрочки" X5 Group. Проект является ярким примером использования больших данных, так как "Пятёрочка" — это 18000 магазинов по всей стране. Чтобы построить систему ценообразования в такой сети, требуется обработка миллиардов строк информации из чеков, данных по остаткам, себестоимостей и многих других показателей. Для всего этого преимущественно используется PySpark, как один из популярных инструментов для работы с распределёнными системами. В данной статье будет представлен один из методов написания кода на PySpark таким образом, чтобы он был более читаем, легко тестируем и поддерживаем. Сразу оговорюсь, что не представляю здесь единственное правильное решение, но оно доказало свою жизнеспособность на примере того проекта, в котором я работал.

Отправная точка
Перед тем, как перейти к конкретике, хочу немного рассказать про историю проекта, который натолкнул меня на мысли о проработке архитектуры написания кода. Большинство проектов начинаются с идеи, разрастающейся до MVP в достаточно короткие сроки. На стадии MVP основная задача продукта – показать то, что он работает и может приносить деньги. Если он этого не может, он дальше не живёт, а если может, то из него уже хотят получить готовое решение с минимальными затратами и максимальными темпами. Проблема тут заключается в том, что при создании MVP в код продукта вряд ли закладывались все заделы на будущее масштабирование и стабильную работу. В силу этого, большиство модернизаций, требуемых хотя бы для стадильной работы, может не укладываться в концепцию начального решения и дописывается <<как придётся>>. В общем, даже если в MVP изначально закладывалась какая-то архитектура, то она скорее не выдержит наплыва доработок и код превращается в что-то вроде наушников, которые пролежали в кармане на протяжении последнего месяца: вроде, ты и пытался сложить их аккуратненько, но доставая их, концы найти весьма затруднительно. Проблема усугубляется тем, что люди, которые этот код писали, ещё более-менее в нём ориентируются, но вот для вновь прибывших сотрудников (а это не редкость при расширении проекта) погружение в такой код занимает неоправданно много времени.
Вот приблизительно на первой стадии раскатки MVP я и подключился в проект со всей его витиеватой логикой. Здесь я пропущу рассказ о моей боли, которую я испытывал при попытках составить последовательность логических операций формирования одной таблички, кусочки которой я кропотливо собирал по 7 файлам кода из различных директорий. Скажу лишь, что именно это и подтолкнуло меня к созданию такой архитектуры, которая позволила облегчить жизнь тем, кто будет после. Надеюсь, облегчит кому-нибудь ещё. Вперёд к светлому будущему!
Проблемы MVP
Прежде чем решать проблему, нужно её определить. Поэтому для начала я хотел бы обозначить основные моменты, которые были самыми критичными на мой взгляд.
Документация. Здесь речь идёт даже не о банальных правилах расставления комментариев и описаний функций. Они, конечно, важны, намого проще разобраться в коде, если там есть хоть какие-то пояснения, но есть и другая проблема. Наш продукт, например, находится в постоянном контакте с бизнесом. Логика его работы должна быть этому бизнесу понятна и где-то зафиксирована. При этом, естественно, в источнике, доступном бизнесу, она должна поддерживаться в актуальном состоянии. Даже если аккуратно описать все функции на понятном человеку языке, сгенерировать какой-нибудь pydoc или sphinx, то вряд ли вы порадуете менеджеров, если дадите им это почитать. Есть другой путь – написать менеджерам отдельное описание логики проекта. Но в таком случае при любом изменении логики (а они происходили постоянно), придётся поменять описание внутри кода, поменять описание функции, а затем ещё и переписать документацию для бизнеса. Вывод – хочется иметь такую документацию, которая была бы понятна и людям, работающим с кодом и бизнесу. А ещё неплохо бы тратить на неё не больше времени, чем на написание кода.
Нелинейность кода. С одной стороны код типа
fun(fun1(fun2…))очень плохо воспринимается, а ситуации, когда он прямо таки необходим в ETL-процессах встречаются крайне редко. С другой стороны, возвращаемся к вопросу документации и объяснения этой логики. Чем больше вложенности, тем сложнее восстановить логику в один связный текст.Недекомпозированность кода. Работа датафреймами в pyspark ни в коем разе не останавливает полёт фантазии. Если у вас достаточно запала, то написание функции можно не останавливать никогда.
df = select.join.withColumn.withColumn.groupby.agg.select.withColumnRenamed...и дальше, дальше пока не оставят силы. Можно отдохнуть. А на следующий деньdf_new = df.select.join.withColumn.... В общем, если без шуток, то я натыкался на файлы в несколько тысяч строк вот такого кода, в котором уже на 500 строчке забываешь, с чего, собственно, всё начиналось. Ещё одной большой проблемой длинного спарковского кода лично для меня является то, что очень быстро перестаёшь осознавать, какие вообще колонки есть в том или ином датафрейме.Сложность тестирования. В основном, функции содержали обращения к таблицам базы внутри себя. В таких условиях очень тяжело их хоть как-то тестировать, так как тесты на больших таблицах занимают очень много времени, а при отсутствии доступа к базе вообще невозможны, а хотелось бы. Можно, конечно, собрать свою локальную песочницу и записать все тестовые таблицы туда. Но тесты частенько помогают понять логику кода, и хотелось бы иметь тестовые таблички всегда под рукой.
Теперь, когда основные проблемы обозначены, можем перейти к примерам их решения. Далее я не хотел бы уделять много времени скучному разбору кода базовых классов, на которых строилось моё решение. Больше внимания я уделю основным концепциям с примерами использования, а сам код вы всегда сможете найти в репозитории.
Структура проекта
Проекты разные, задачи разные, структуры разные. Говорить, что какая-то структура является универсальной смысла не имеет. В этом разделе просто будет приведён пример структуры, которая хорошо прижилась в нашем проекте, и в контексте которой я буду дальше вести повествование. Возьмём только минимально необходимое:
example_project: |--utils | |--description_builder.py |--modules | |--__init__.py | |--module_base.py | |--config_base.py | |--module1 | |--__init__.py | |--config.py | |--module.py | |--runner.py |--config.yml |--config_sources.yml
На самом верхнем уровне у нас лежат конфиги проекта. У нас было всего 2 файла, поэтому в корне они никому не мешались (config.yml, config_sources.yml). Если их больше, то, конечно, можно уместить их в отдельную директорию. Дальше директория со скриптами-утилитами (utils) и, собственно, дерево всех модулей проекта (modules).
Модули проекта — его логические части. Здесь изображена структура модулей одного уровня вложенности, потому что я устал рисовать для простоты восприятия, но уровней может быть и больше. Главное — чтобы они были логически связаны. В каждом модуле лежит файл с конфигом этого модуля (config.py), файл в котором содержатся все вычисления (module.py) и скрипт для запуска (runner.py), в котором должно быть минимум кода. Файлы module_base.py и config_base.py содержат базовые классы, речь о которых пойдёт далее. Да, хранить базовые классы именно так -- не самое удачное решение, но оно работает, никого не беспокоит, поэтому пусть полежат здесь.
Пример с такой структурой можно наблюдать в разделе example_project репозитория.
Теперь, когда мы разобрались с основой структуры, можем переходить, собственно, к самому решению, которое, на мой взгляд, сделало жизнь в проекте намного проще.
Конфиги проекта
Начнём с конфигураций проекта. В большинстве случаев конфиги делятся на два типа:
статические, которые иногда меняются, но всё-таки крайне редко
динамические, которые может понадобиться менять чуть ли ни при каждом отдельном запуске скрипта. Обычно они же и передаются в качестве параметров в скриптах запуска
Начнём со статических конфигов. Обычно это словарь, полученный при чтении yaml, json или подобного файла, где задана конфигурация проекта. В нашем случае это два yaml-файла. config.yml — файл, содержащий параметры, общие для всего проекта. В нашем проекте это были сопоставления городов и макрорегионов. config_sources.yml — файл, содержащий список витрин, которые используются в проекте. Источники могут быть внешними (считаются другими продуктами) и внутренними (считаются внутри проекта). Также, под проект может быть выделено несколько баз (для прода, теста, бэкапов и т.д.) и всю эту информацию нужно как-то хранить. В своём проекте мы пришли к следующей схеме описания таблиц:
# Внешние источники titanic_tbl: 'edw_db.titanic_table' # справочник товаров (ссылка) # базы данных продукта db_backups: test: 'product_test_db' # база, в куторую сохраняются бэкапы расчётов prod: 'product_prod_db' # база, в куторую сохраняются расчёты # Бэкапы backups: # витрины продукта, слепок которых делается в тестовую базу product_table_1: # алиас таблицы table_name: table_name_in_database # имя таблицы в базе partitionedby: ['date', 'city'] # партиции
Сначала идёт перечисление внешних источников, которые мы только считываем. Затем список баз данных продукта, в нашем случае это продовая и тестовая базы. Затем идёт описание таблиц, расчёт которых производится в проекте. Здесь полезной дополнительной информацией будет список колонок, по которым производится партиционирование таблицы при записи.
Если говорить о динамических конфигах, то у нас они всегда передавались через bash в качестве аргументов. В силу этого, каждый скрипт запуска начинается с добавления параметров в argparse, причём обычно, всё это полотно задаётся кописастом из загрузчика ранее написанного модуля. Во избежании копипаста, такие параметры тоже хотелось бы хранить в нашем конфиге.
Ну и наконец, во время работы скриптов может понадобиться передавать некоторую информацию из функции в функцию. Конфиг, скорее всего будет тем объектом, который передаётся в каждую функцию и передавать параметры через него достаточно удобно.
Итого, конфиг в проекте будет объектом класса, в котором существуют 4 атрибута:
cfg— для статических конфигов изconfig.yml(считывается при инициализации объекта класса)cfg_sources— для хранения информации по базам данных изconfig_sources.yml(считывается при инициализации объекта класса)parameters— параметры, получающие данные при помощиargparse. Описание параметров, которые используются повсеместно (таких как, например, TEST -- флаг использования тестовой базы, или дата расчёта), можно задавать в__init__()базового классаtmp— дополнительные данные, которые могут быть добавлены в конфиг в процессе вычислений
А также несколько полезных функций:
getitem,setitem— для того, чтобы к классу можно было обращаться, как к словарюprint_description— для выведения описания всех конфигурацийadd_parameter,parse_arguments— для добавления параметров и парсинга их значений из bashget_table_link— функция, выдающая полный путь к таблице по её алиасу
В конфиг можно также накидать и других функций, результат которых зависит от статических или динамических параметров, и которые используются повсеместно в проекте. Например, функцию, которая возвращает дату расчёта в нужном формате очень упрощает жизнь.
Ниже пример использования конфига для получения ссылки на таблицу product_table_1 из описания выше. В конфиге по умолчанию, добавлен параметр TEST, который определяет базу данных проекта для проведения вычислений. Также продемонстрировано, как работать с параметрами и временными значениями конфига.
from modules.config_base import ConfigBase # Пример вывода ссылки на таблицу config = ConfigBase() print(f"For test parameter '{config['TEST']}' table link is '{config.get_table_link('product_table_1')}'") config.update_config({'TEST': True}) print(f"For test parameter '{config['TEST']}' table link is '{config.get_table_link('product_table_1')}'") # Добавление параметров config.add_parameter("validateAS", '--vas', type=int, required=False, default=0, help="""Валидировать ли вычисления шага AnotherStep""" ) config['tmp_parameter'] = None config.print_description()
For test parameter 'False' table link is 'product_prod_db.table_name_in_database' For test parameter 'True' table link is 'product_test_db.table_name_in_database' --------------------------------------------------- global_config contains: config_parameter_1 : 12 config_parameter_2 : subparam1 : param subparam2 : noparam --------------------------------------------------- --------------------------------------------------- sources_config contains: titanic_tbl : edw_db.titanic_table db_backups : test : product_test_db prod : product_prod_db backups : product_table_1 : table_name : table_name_in_database partitionedby : ['date', 'city'] --------------------------------------------------- --------------------------------------------------- parameters contain: TEST : True calc_date : 10.09.2021 logging_level : 10 validateAS : 0 --------------------------------------------------- --------------------------------------------------- temporary data contains: tmp_parameter : None ---------------------------------------------------
Даже такая простая функция, как возвращение пути к таблице по её алиасу, может существенно сократить количество однотипного кода в проекте. На функцию печати содержания конфига тоже рекомендую потратить время, это экономит много времени в дальнейшем, когда модулей в проекте становится больше, чем один.
В заключении следует оговорить, что же тогда содержится в файлах config.py каждого отдельного модуля? В этих файлах происходит инициализация объекта базового класса ConfigBase и добавление в этот объект параметров, имеющих отношение к модулю (функция add_parameter()).
Нужно больше кода?
Шаблон базового класса находится в библиотеке репозитория
Пример адаптации конфига под конкретный проект находится в файле config_base.py проекта example_project
Пример дополнения конфига для конкретного модуля также лежит в соответствующем файле
Файлы config.yml и config_sources.yml, о которых шла речь, также можно найти в примере репозитория.
Линеаризация структуры
Иметь хороший конфиг, конечно, приятно, но глобальных проблем это не решает. Основной из них, на мой взгляд, является нелинейность написания кода. Для решения такого рода проблемы мне очень приглянулась идеология pipeline'ов, которые используются, например, в pandas для построения алгоритмов обработки данных с последующим обучением моделек. В общем, каждый ETL процесс проекта мне хотелось видеть в виде последовательности шагов, выполняющихся один за другим. В моей терминологии я определил следующие два основных понятия:
Pipeline — ETL процесс, состоящий из последовательного выполнения шагов, принимающий на вход таблицы из БД, результатом выполнения которого является новая таблица в БД (можно несколько, но желательно небольшое количество, иначе получается много намешанной логики)
Step — Шаг вычислений, на вход принимает
spark.DataFrameили обращается к базам напрямую. На выходе одна или несколько таблиц (в виде тех жеspark.DataFrame), которые будут использоваться в дальнейших вычислениях
Под каждый из этих пунктов был написан свой базовый класс, основные концепции которых я и попытаюсь продемонстрировать далее.
Step
Пойдём от малого к большому и начнём с описания требований к шагу вычислений. Объём -- шаг не должен быть большим. Обычно, мы ориентировались на 100-150 строк спаркокода. Такое количество приемлемо, чтобы не потерять цепочку повествования даже при весьма заковыристой логике. Помимо этого, в каждом шаге хотелось бы иметь описание структур входных и выходных таблиц и в процессе вычислений сверять данные с этой структурой. Получаем следующие требования к объекту Step:
Так как мы целимся на нормальную документацию, каждый класс-шаг должен иметь качественное описание логики его вычислений, эквивалентом которой будут являться 100-150 строк кода
Должен иметь атрибуты, в которых хранятся описания схем входных и выходных таблиц
Если у нас есть описания таблиц, то пусть он проверяет вход на соответствие описанию перед началом вычислений
Должен иметь функцию, в которой, собственно, и будут производиться все основные вычисления
Должен иметь функцию
.run(), которая будет возвращать список датафреймов, являющихся результатами вычислений.
Далее рассмотрим пример написания кода в такой парадигме. Для этого воспользуемся данными пассажиров Титаника из соревнования на kaggle. Пусть задача нашего шага будет простейшей: Заполним отсутствующие данные возраста на средний возраст людей, купивших билеты соответствующего такого же класса.
In [3]:
# Загрузим данные тренировочного датасета df = pd.read_csv('./example_project/data/train.csv') df['Cabin'] = df['Cabin'].fillna('') df['Embarked'] = df['Embarked'].fillna('') spark_df =spark.createDataFrame(df) df.head(3)
Out[3]:
PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | S | |
1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | S |
# Импортируем базовый класс шага from modules.module_base import StepBase # Создание класса вычислений class Processing(StepBase): """ Предобработка данных датасета "Титаник" С данными из датасета "Титаник" производятся следующие операции: * Для каждого класса билетов вычисляется средний возраст пассажиров, купивших билет * Если возраст пассажира не указан, то он заменяется средним возрастом пассажиров, купивших билет такого же класса (с округлением до целого) """ source_tables = { # словарь описаний источников 'input_table_1': { # имя, по которому можно будет обращаться к таблице при описании вычислений 'link': 'titanic_tbl', # ссылка на таблицу (можно алиасом из config_sources, как здесь), # 'argument' если таблица не из БД 'description': 'Данные пассажиров титаника', # описание таблицы 'columns': [ # список колонок ('Survived', 'bigint', 'survived', 'int'), # имя, тип колонки в таблице, новое имя, новый тип ('Pclass', 'bigint', 'ticket_class', 'int'), ('Sex', 'string', 'sex', None), ('Age', 'double', 'age', None), ] } } output_tables = { 'out_table_1': { 'link': None, # ссылка на таблицу (можно алиасом из config_sources), для дальнейшего сохранения 'description': 'Обработанные данные пассажиров титаника', 'columns': [ ('survived', 'int'), # имя и тип колонки в выхоной таблице таблице ('sex', 'string'), ('age', 'double'), ] } } def _calculations(self): "Вычисления класса, на выходе словарь в соответствии с self.output_tables" w = Window.partitionBy('ticket_class') df = ( self.tables['input_table_1'] .withColumn('avg_age', F.mean('age').over(w)) .withColumn('age', F.when(F.col('age').isNull(), F.round(F.col('avg_age'), 0)).otherwise(F.col('age'))) ) return {'out_table_1': df} # Инициализация объекта класса argument_tables = {'input_table_1': spark_df} # Словарь с таблицами-аргументами step = Processing(spark, config, argument_tables, test=True, logger=logger) # Запуск вычислений result = step.run() result['out_table_1'].limit(5).show()
+--------+------------+------+----+------------------+ |survived|ticket_class| sex| age| avg_age| +--------+------------+------+----+------------------+ | 1| 1|female|38.0|38.233440860215055| | 1| 1|female|35.0|38.233440860215055| | 0| 1| male|54.0|38.233440860215055| | 1| 1|female|58.0|38.233440860215055| | 1| 1| male|28.0|38.233440860215055| +--------+------------+------+----+------------------+
При этом на стадии инициализации объекта класса осуществляются:
проверки на соответствие названий и типов колонок входных таблиц описанию, заданному в
source_tablesселект, переименование и изменение типов колонок входных таблиц таким образом, чтобы они соответствовали новым названиям и типам
source_tablesскладирование таблиц в переменную класса
self.tables
На стадии запуска вычислений осуществляется выполнение функции _calculations() с последующей проверкой на то, что результат её вычислений соотносится с описанием output_tables. При этом отмечу, что в таблице могут присутствовать колонки и не входящие в описание, их корректность никак не проверяется.
На первый взгляд, такой подход кажется избыточно сложным. В данном примере написание простейшей операции потребовало значительных затрат. Но когда дело касается более замысловатой логики, он себя более чем оправдывает:
делает погружение в такой код много более приятным
проверки на соответствие типов входных таблиц описанию ни раз спасали, как при дебаге нового кода, так и при рефакторинге старого
сильно сокращает количество строк кода с
.withColumnRenamedиcast.
Последний пунт можно назвать несколько спорным, ведь переименовывание колонок и смена типизации нужны не всегда, а писать по 4 параметра в описании каждой колонки придётся везде. Тем не менее, начинать каждую новую функцию с .withColumnRenamed и cast мне нравится ещё меньше.
Также хочется отдельно обговорить параметр test при инициализации шага. Как видно в описании класса, ссылка на входную таблицу была задана алиасом из конфига. В этом случае, если бы мы просто инициализировали шаг, то он бы начал стучаться в базу для того, чтобы получить схему таблицы и сравнить её с описанием. Но для тестирования нам бы хотелось просто передавать шагу на вход нужную нам таблицу. Для этого и вводится параметр test, который говорит шагу, что все источники переданы ему в качестве аргументов и в базы ломиться ему не нужно.
Более подробно пример кода базового класса можно найти в файле step_base.py библиотеки. В целом, хотелось бы отметить, что основную часть кода составляет логика проверок на соответствие таблиц описанию. Если проверки не осуществлять, то код можно уложить в пару десятков строк.
Pipeline
С модулем Pipeline дела обстоят много проще. Основной принцип его действия:
создаём пустой словарь с таблицами
resultначинаем последовательно запускать шаги, передавая каждому шагу на вход
resultи обогащаяresultрезультатом выполнения текущего шагапосле всех вычислений выбираем из
resultте таблицы, которые указаны в описании
Для демонстрации написания кода пайплайна можно написать ещё один шаг. Пусть в новом шаге, из таблицы предыдущего шага вычисляются следующие статистики пола человека на Титанике:
процент выживаемости
средний возраст
Я вынесу описание кода класса за скобки, на код можно будет посмотреть в репозитории и перейдём к примеру:
# Импортируем тот самый шаг и класс базового пайплайна from modules.some_module.module import CalcStats from modules.module_base import PipelineBase # Определяем пайплайн class Pipeline(PipelineBase): """ Пайплайн расчёта характеристик пассажиров титаника Расчёт характеристик соответствующих каждому полу пассажиров титаника: * процент выживаемости * средний возраст """ step_sequence = [ Processing, CalcStats ] output_tables = { # Аналогично описанию в Step 'out_table_2': { 'link': None, 'description': 'Финальная таблица', 'columns': [ ('sex', 'string'), ('avg_age', 'double'), ('survival_percentage', 'double') ] } } # Инициализация пайплайна pipeline = Pipeline(spark, config, test_arguments=argument_tables, logger=logger) # Запуск вычислений result = pipeline.run() result['out_table_2'].show()
+------+------------------+-------------------+ | sex| avg_age|survival_percentage| +------+------------------+-------------------+ |female|27.828025477707005| 74.2| | male|30.047088388214902| 18.89| +------+------------------+-------------------+
При инициализации пайплайн сначала пробегается последовательно по всем шагам и проверяет возможность вычислений исходя из описаний входных-выходных таблиц каждого шага. Коротко говоря, проверяет, соответствует ли схема выходной таблицы шага "1" схеме входной таблицы шага "2", если шаг "2" пользуется результатом вычислений шага "1". Для этого не требуется даже инициализация объектов каждого шага. Если со схемами всё в порядке, то начинаются последовательные вычисления в соответствии с основными принципами, которые были представлены в начале раздела.
Важным моментом здесь является то, что в логику Pipeline закладывалось то, что он работает только с базами данных и не принимает ничего на вход. Но для теста это не удобно, поэтому нужно было предусмотреть подачу ему на вход <> таблиц test_arguments. Если эти аргументы переданы, то при инициализации Pipeline будет запускать все свои шаги с параметром test=True и доступ к базам не потребуется.
Описание класса Pipeline следует хранить в файле module.py для каждого конкретного модуля. Описание всех шагов может не уложиться в этот файл, поэтому можно растаскать их по другим файлам, но описание именно пайплайна лучше хранить для каждого модуля в файле с одинаковым названием. Далее будет показано почему это особенно удобно.
Нужно больше кода?
Шаблон для описания работы пайплайна также можно найти в библиотеке. В шаблоне пайплайна, так же как и в шаблоне шага, большую часть кода занимают вспомогательные функции проверок. Также в шаблон добавлены функции записи в базу, которые позволили сократить ещё тонну кода в проекте.
Подтягивание базовых классов в проект происходит в файле module_base.py. В этом файле можно изменить или добавить каких-либо функций относительно шаблона, которые будут полезны именно вам. В примере не происходит ничего, кроме перетягивания шаблонов в проект.
Вкусненькое
Что же мы получаем, при использовании такой структуры?
Во-первых, использование качественного конфига позволяет иметь все необходимые параметры под рукой, так как он является обязательным аргументом при инициализации классов типа PipelineBase и передаётся во все его шаги.
Во-вторых, при таком подходе сильно сокращается количество строк в файле
run.py, который является криптом запуска модуля. Обычно, после всех импортов он выглядит как-то так (Пример раннера, запускающего описанный ранее пайплайн можно посмотреть в репозитории):
if __name__ == '__main__': config.parse_arguments() config.tune_logger(LOGGER) spark = load_spark() try: pipeline = module.Pipeline(spark, config, logger=LOGGER) result = pipeline.run() pipeline.save_result_to_hive(save_mode='append') finally: spark.stop()
В-третьих, на своём опыте заметил, что написание кода в концепции StepBase мотивирует людей к написанию функций разумного размера. Функции величиной в пару строк писать не хочется, потому что больше времени потратишь на описание входных-выходных таблиц. Функции величиной в 500-1000 строк тоже нет большого желания писать, так как придётся описывать их логику понятным для неподготовленного читателя языком в описании класса. Таким образом получается, что средний пайплайн в нашем проекте состоял из 5-7 шагов с величиной каждого шага 100-200 строк кода. Погружаться в логику работы модулей при таких обстоятельствах стало не только возможно, но и достаточно приятно.
В-четвёртых, как мы уже успели убедиться, тестирование каждого шага является достаточно простым делом. Все таблицы, которые используются для вычислений достаточно просто передать на вход и не нужно ломать себе голову над тем, как вынести все инициализации
spark.table()из тела функции. Ещё больше примеров тестирования основных шаблонов можно найти здесь.
Но это ещё не всё. Одним из самых приятных моментов, что при таком подходе очень просто собирать описание работы пайплайнов! У нас для этого есть всё:
описание каждого шага на понятном языке (насколько это возможно)
описание входов и выходов каждого шага
краткое описание алгоритма в целом (его цели, время запуска и т.п. лучше как раз и указывать в описании класса Pipeline)
описание выходных таблиц пайплайна
Код генерации описания содержится в функции get_pipeline_description базового класса пайплайна. Также можно собрать и визуализировать граф вычислений средствами graphviz (функция get_pipeline_graph).
Для разобранного нами примера описание будет выглядеть следующим образом:
Пайплайн расчёта характеристик пассажиров титаника
Расчёт характеристик соответствующих каждому полу пассажиров титаника:
процент выживаемости
средний возраст
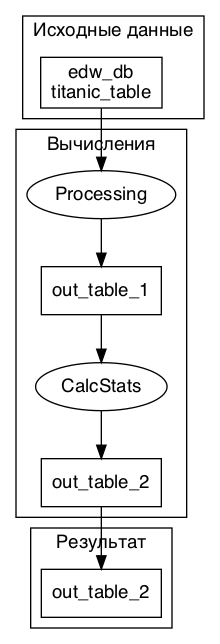
Модуль состоит из последовательного выполнения следующих шагов:
Processing (Предобработка данных датасета "Титаник"):
С данными из датасета "Титаник" производятся следующие операции:
Для каждого класса билетов вычисляется средний возраст пассажиров, купивших билет
Если возраст пассажира не указан, то он заменяется средним возрастом пассажиров, купивших билет такого же класса (с округлением до целого)
Исходные таблицы:
input_table_1 (edw_db.titanic_table) (Данные пассажиров титаника)
Выходные таблицы:
out_table_1 (Обработанные данные пассажиров титаника)
CalcStats (Вычисление статистик по пассажирам Титаника):
Данные таблицы
out_table_1группируются по полу пассажира и вычисляются следующие статистики:процент выживаемости
средний возраст
Исходные таблицы:
out_table_1 (Результат вычислений шага Processing) (Обработанные данные пассажиров титаника)
Выходные таблицы:
out_table_2 (Статистики пассажиров титаника)
Результатом выполнения алгоритма являются следующие таблицы:
out_table_2 (Результат вычислений шага CalcStats) (Финальная таблица):
Название колонки | Формат |
sex | string |
avg_age | double |
survival_percentage | double |
Более того, если придерживаться структуры в проекте, то не составит большого труда написать функцию, которая будет пробегаться по всем модулям проекта, строить для них документацию с картинкой графа вычислений и записывать её в README.md модуля. В корневой README она же может вставлять оглавления со ссылками на частные ридмишки модулей. Пример такой функции можно посмотреть здесь.
Затем, запуск такой функции можно делегировать git CI и вообще забыть о том, что описание модулей нужно править где-то помимо кода проекта. Получаем качественное описание алгоритмов (с картинками, чтобы было нескучно читать), на поддержание которой в актуальном состоянии требуется минимум усилий. Профит!
Итого
В данной статье у меня не было цели подробно разобрать концепцию пайплайнов при написании кода на спарке со всеми тонкостями её реализации. Код всегда можно посмотреть в репозитории, ссылки на отдельные куски кода, которые позволяли реализовать тот или иной функционал также своевременно поставлялись. Целью являлось просто привести основные принципы, которые позволяют:
писать код понятным и последовательным образом
сократить время погружения в проект новых сотрудников
писать тесты без боли
составлять понятную обычным людям документацию и легко поддерживать её в актуальном состоянии
Не претендую на то, что такое решение является единственно верным, но как мне, так и моим коллегам работать в такой парадигме оказалось приятно. Надеюсь, поможет это и кому-нибудь ещё.
Хотелось бы поблагодарить команду ценообразования "Пятёрочки" X5 за поддержку и энтузиазм в реализации данного функционала. Отдельно хочу поблагодарить лидера этой команды Антона Денисова за открытость новому и поддержку, как в реализации функционала, так и в написании этой статьи.
