
Пишете музыку, но внезапно настиг творческий кризис? Или вам хочется получить треки уровня royalty-free, потыкав несколько слайдеров в Colab ноутбуке? Вы не готовы получать PhD в нейронных сетях и разбираться с теорией музыки, а попробовать себя в роли нейросетевого музыканта очень уж хочется?
Команда Sber AI спешит к вам с радостной новостью: совершенно безвозмездно мы выкатили NLP-модель синтеза музыки, обученную на тысячах часов музыки из открытых источников. Вам не придется платить за аренду GPU сервера с картой V100 для синтеза через Jukebox - наша модель порадует вас бесплатными треками в риалтайме даже в простом Google Colab.
А ещё вы узнаете, как связаны трансформеры и шедевры классической музыки. Но обо всем по порядку.
Ссылка на репозиторий - можно загрузить демку и сгенерировать музыку
Что не так с имеющимися моделями?
С чего начинается путь падавана нейросетевой музыки? Разумеется, пишем в google “neural network music generator” и видим следующее:

OpenAI мы доверяем, ведь благодаря им мы имеем DALL-E, CLIP и GPT-3, превзошедшие многие другие модели и подходы. Начнем с MuseNet (ведь он выше в поиске, а значит годнее). Прослушаем несколько любезно предоставленных примеров для повышения мотивации:
Но вот незадача - у MuseNet есть только заранее сгенерированные треки, нет доступа к коду и возможности поимпровизировать, заточив музыку под себя.
Пробуем вторую модель - Jukebox. Вот тут мы уже можем наложить свои руки на код и адаптировать музыку под свои нужды. С ней мы можем выбрать жанр, стиль исполнителя и даже добавить вокал, получив что-то наподобие:
Ваша мотивация повысилась? Открываем демонстрационный ноутбук на Google Colab, запускаем все ячейки подряд и вожделенно ожидаем музыкального шедевра…
Однако вместо него ноутбук перезагружается и ставит нас перед фактом:

Но мы готовы немного потанцевать с бубном, взять урезанную модель и сократить длину трека. В таком случае спустя несколько часов мы получим наше творение (упс, сорри, очень скверный звук):
Стоп, а почему так много шума? Всё потому, что надо произвести дополнительный шаг апсемплинга со слоёв меньшего разрешения.
К нашему сожалению, генерация музыки на колабе с урезанной моделью заняла у нас больше времени, чем продолжительность бесплатных инстансов Colab:

Неужели синтез музыки - удел счастливчиков со свободным сервером? Разберёмся в том, почему у нас не хватает памяти и времени.
«Я волна» VS «Набор нот»
Всё дело в том, что Jukebox синтезирует музыку в волновом формате. А это ни много ни мало, а 44100 точек данных в одной секунде трека студийной записи. Выглядит это следующим образом:
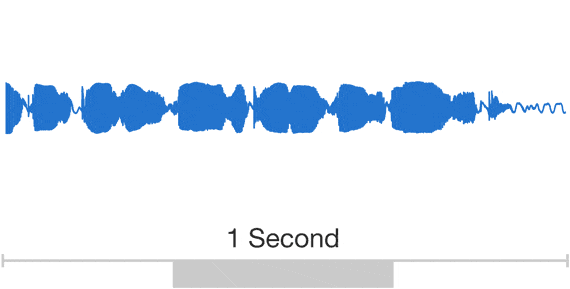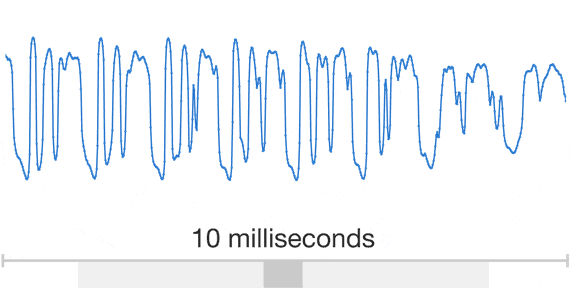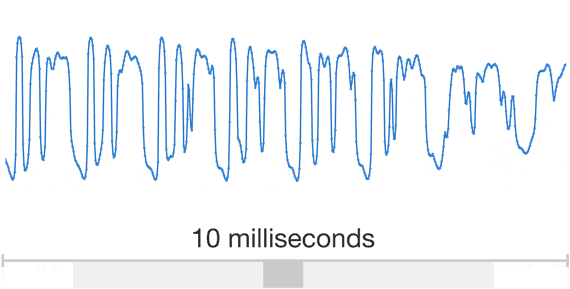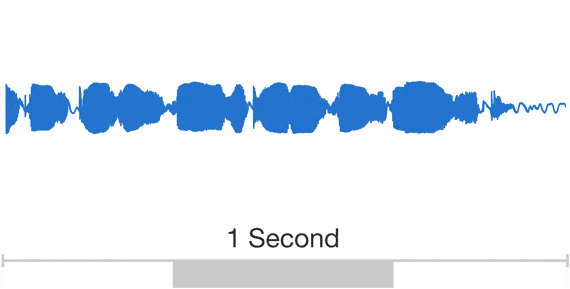
Односекундные треки мало кому интересны, для начала попробуем хотя бы получить 30-секундную студийную запись. Итого 1 323 000 значений амплитуд в одной записи с частотой семплирования 44100. Для сравнения: RGB-изображение разрешением 512x512 имеет всего 786 432 значений - почти в два раза меньше. И тут уже многие эксперты по Computer Vision скажут вам, что это перебор (кроме разве что тех, кто поднимает super resolution, высокоточную сегментацию или детекцию). И с такими проблемами мы сталкиваемся на инференсе. А представляете, какие ресурсы нужны для обучения такой модели?
В итоге имеем фундаментальную проблему - слишком много данных нужно сгенерировать. Самый простой способ обойти это ограничение - поменять сам формат данных. Музыку же можно представить в виде последовательности нот, и мы получим так называемый MIDI файл. После этого он загружается в секвенсор, выдающий нам музыкальный трек в волновом формате.
На первый взгляд может показаться, что от смены формата ничего радикально не поменялось. На самом же деле даже с самым базовым MIDI мы сильно сокращаем запись. Мы на практике получали треки продолжительностью до 2.5 минут используя всего 2048 нот. Разница в генерации 2048 и 1 323 000 значений очень ощутима, не правда ли? Плюс перед нами открылся огромный творческий простор для того, чтобы придумать оптимальный способ кодирования данных.
Эксперименты с кодированием в борьбе за длину трека
Осторожнее! Мы ступили на земли NLP, как только решили кодировать свои данные. Но не стоит пугаться, ведь принцип тут простой - придумать такой алфавит из нот, чтобы трек на новом энкодинге занимал меньшее число значений. При этом делать всё слишком сжатым нежелательно - можем потерять важную информацию. По нашему опыту сложилось впечатление, что рецепт синтеза символьной музыки - это 60% энкодинга, 30% сбора и чистки данных и 10% обучения модели.
Поэтому все, кто работает в этой области только и думают о том, как бы предложить что-нибудь свое. Мы, однако, для пилотной версии модели решили не запариваться и взяли самый простой, родной event-based MIDI энкодинг из статьи Music Transformer.
MIDI ЭНКОДИНГ
В MIDI каждая нота имеет 3 основных характеристики: высота, длительность и громкость. По вертикальной оси задается высота ноты, по горизонтальной - длительность. Отдельно вынесены громкости для каждой ноты (на рисунке ниже - вертикальные столбцы под каждой нотой, чем выше столбец - тем громче нота). Для каждого инструмента создаётся своя дорожка с последовательностями нот. Из таких дорожек состоит midi файл.

Суть event-based MIDI энкодинга в том, что мы отслеживаем нажатия и отпускания клавиш, учитывая силу нажатия. Так, MIDI преобразуется в последовательность событий нажатия, отпускания клавиши (по 128 токенов), установки громкости (32 токена) и шага по времени (100 токенов).

Углубляться в способы кодирования можно очень долго, и это выйдет за рамки вводной статьи, так что оставим это в качестве материала на будущее.
Что делать с энкодингом?
Энкодинг есть, а что с ним делать? Правильно - с материнской заботой скармливаем его какой-нибудь NLP-модели. И учим-учим-учим. В нашем случае под руку подвернулась архитектура Music Transformer от Magenta. Поздравляем, теперь вам открылась тайна связи антропоморфных роботов-машин и игры на фортепиано.
Из интересных особенностей - тут вместо стандартного Self-Attention прикручен более прокачанный Relative Attention. По заверениям авторов, он сильно улучшает качество и позволяет модели воспроизводить и повторять музыкальные фразы. Мы в этом убедились, теперь ваш черёд.
RELATIVE ATTENTION
Что же такое Relative Positional Self-Attention, и с чем его едят? Тут в отличие от дефолтного Self-Attention, учитывается относительное положение каждой пары токенов, а не абсолютное. Это сильно помогает модели обрабатывать музыкальную информацию, так как в музыке часто встречаются повторения музыкальных фраз или повторения с небольшими изменениями.

Механизм skew введён авторами оригинальной статьи как версия оптимизированного варианта Relative Attention, уменьшив, тем самым, затраты по памяти с O(L^2 D) до O(LD) (L - длина последовательности, D - hidden size). Подробнее можно почитать в оригинальной статье или на medium.
 с моделями без него (средняя и нижняя строка).")
На MIDI представлении мы уже видим повторяющиеся паттерны в виде повторяющихся гор и всяческих лесенок. Без него модели снизу пытаются получить что-то подобное, но даже если у них в начале получается, то под конец они предпочитают зажать клавиши и не отпускать до самого конца. Особенно это заметно на средней модели. Нижняя же вообще не склонна к повтору музыкальных фраз. Так что Relative attention - настоящая палочка-выручалочка в задаче синтеза символьной музыки.
Как приручить трансформер?
Использованная архитектура Music Transformer на самом деле в некотором смысле неконтролируема. Вы можете часами генерировать музыку, ожидая вам трек ожидаемого вами жанра. И он может оказаться неприемлемого качества. Мы решили, что это бессмысленно и постарались сымитировать механизм генерации Jukebox. Для этого в начало генерируемой последовательности мы подаем специальный код, отвечающий за жанр. Через него модель понимает какое подмножество треков от неё хотят получить и генерирует в этом стиле.
Сейчас мы смогли создать модель на четыре жанра: classic, pop, jazz, ambient. Но это не предел и в перспективе никто не мешает из метаинформации о треках достать исполнителей и большее число жанров, расширить их список, позволив генерировать в их стиле.
А еще в отличие от Jukebox мы можем при желании контролировать каждый шаг генерации. Если этого не делать - существует риск того, что модель начнёт циклически повторять какую-то музыкальную фразу. В секвенсоре это, конечно, выглядит прикольно, но на слух приедается уже после второго повторения.
Для этого мы добавляем штрафы за частую генерацию с повторами. Также у нас есть температурный скейлинг, позволяющий балансировать между моделью, зажатой в рамках и моделью-импровизатором. Ну и конечно же beam search, использующийся во многих NLP-задачах генерации текста.
НЮАНСЫ
Стандартный способ генерации основан на случайном сэмплировании по распределению вероятностей, полученному из модели. Генерация происходит авторегрессионно, то есть за один шаг генерируется один токен с учётом всех предыдущих. Каждый новый токен добавляется к последовательности уже сгенерированных токенов, и вся последовательность подаётся на вход для генерации следующего.
Но такая случайная генерация - очень неконтролируемый процесс и может приводить к плохим случаям, т.к. всегда существует маленькая вероятность сгенерировать что-то неподходящее. К примеру, начать повторять две-три ноты по кругу, сродни тому как происходит в языковых моделях клавиатурных ассистентов. Поэтому мы используем методы, контролирующие процесс генерации:
● top-k - ограничение набора по верхней границе. Сэмплирование происходит из набора k наиболее вероятных токенов.
● at_least_k - ограничение набора по нижней границе. Сэмплирование будет гарантированно происходить как минимум из at_least_k наиболее вероятных токенов.
● top-p - ограничение набора по кумулятивной сумме вероятностей. Упрощенно набор токенов для генерации создаётся так: итеративно добавляем наиболее вероятные токены в набор, и считаем их суммарную вероятность (всех токенов в наборе). Добавляем в набор до тех пор, пока суммарная вероятность не станет больше topp. (отметим, что сумма вероятностей по всему распределению = 1, поэтому значения topp, обычно выбираются в пределах 0.90-0.99). top-p хорошо комбинируется с at_least_k, т.к. из-за ограничения по top-p слишком уверенная модель может прийти к тому, что будет выбирать только из одного токена, тогда сэмплирования не будет. Это часто приводит к бесконечному зацикливанию композиции на одной музыкальной фразе. at_least_k помогает решить эту проблему.
● temperature - влияет на само распределение вероятностей, делая его более либо менее равновероятным. Тем самым регулируется разнообразие генерации.
При t=1.0 ничего не изменит (дефолтное значение).
При t<1.0 - равновероятность уменьшается. Это аналогично увеличению уверенности модели, она будет склонна генерировать наиболее вероятные токены (при t→0 сэмплирование превратится в выбор по argmax - то есть в выбор одного самого вероятного токена).
При t>1.0, наоборот, распределение будет приближаться к равновероятному, при t>>1.0 происходит абсолютно случайная генерация - шум.

● Мы разработали метод Repetition Penalty (RP), который помогает избавиться от проблемы зацикливания на одной музыкальной фразе и в целом позволяет генерировать более разнообразные композиции. rp_penalty и rp_restore_speed - эти параметры отвечают за штрафование модели за частое повторение нот или фрагментов. Суть метода в том, что мы отслеживаем все нажатия нот, каждое нажатие уменьшает вероятность этой же ноты на следующем шаге генерации на число rp_penalty. Если нажатие всё равно происходит, то вероятность снова понижается, и т.д. Если нажатие не происходит, то вероятность этой ноты восстанавливается с каждым следующим шагом генерации За скорость восстановления отвечает параметр rp_restore_speed. Это число, обратное кол-ву секунд, за которое произойдет полное восстановление - с 0 до 1. Чем больше значение, тем менее заметно влияние RP.
Где можно приобщиться?

Сейчас мы предоставляем доступ к коду модели, обучения и генерации в нашем репозитории. Там же можно найти предобученные веса для экспериментов с подбором параметров генерации. Пытливые умы и знакомые с PyTorch смогут разобраться с кодом, подгрузить веса и сгенерировать всё, что душе угодно.
Пока мы готовили демо-ноутбук на свет появилась картинка с «рыбов продаёте?» и теперь с его наличием она уже не актуальна. Но выбрасывать жалко, поэтому она занимает почетное место в заключении. Ну а напоследок можете оценить результаты генерации нашей модели:
Один из самых длинных треков. В жанре ambient, т.к. в нём музыка спокойная и расход токенов на генерацию меньше. Благодаря этому удаётся растянуть 2048 токенов на 2 минуты.
Еще один ambient. Звучит энергичнее чем предыдущий, оттого и длина меньше.
Интересный спокойный душевный джазовый трек. Модель довольно смело раскидывается красивыми джазовыми аккордами в нужных местах и в нужное время, не скупясь, при этом, на импровизацию, и, сохраняя общую спокойную идею трека.
Более динамичный современный джаз. Напоминает лёгкое джазовое музыкальное оформление в кафе.
Интересная классическая композиция. Здесь модель хорошо подчеркнула динамику трека - на контрасте чередуются то громкие и смелые, то тихие фрагменты, что характерно для классической музыки.
Жанр pop. Интересна тенденция модели к запоминанию основной ведущей партии в поп треках. Поп сам по себе склонен к частым повторениям простых мелодий и аккомпанемента, поэтому модель это успешно усвоила.
Как видим лучше получаются жанры Jazz(в нем проще всего импровизировать) и Ambient(в нем треки простые)
Максим Елисеев,
Александр Маркелов,
Иван Базанов
SberAI
