 Привет, Хаброжители! Глубокое обучение с подкреплением (глубокое RL) сочетает в себе два подхода к машинному обучению. В ходе такого обучения виртуальные агенты учатся решать последовательные задачи о принятии решений. За последнее десятилетие было много неординарных достижений в этой области — от однопользовательских и многопользовательских игр, таких как го и видеоигры Atari и Dota 2, до робототехники. Эта книга — введение в глубокое обучение с подкреплением, уникально комбинирующее теорию и практику. Авторы начинают повествование с базовых сведений, затем подробно объясняют теорию алгоритмов глубокого RL, демонстрируют их реализации на примере программной библиотеки SLM Lab и напоследок описывают практические аспекты использования глубокого RL. Руководство идеально подойдет как для студентов, изучающих компьютерные науки, так и для разработчиков программного обеспечения, которые знакомы с основными принципами машинного обучения и знают Python.
Привет, Хаброжители! Глубокое обучение с подкреплением (глубокое RL) сочетает в себе два подхода к машинному обучению. В ходе такого обучения виртуальные агенты учатся решать последовательные задачи о принятии решений. За последнее десятилетие было много неординарных достижений в этой области — от однопользовательских и многопользовательских игр, таких как го и видеоигры Atari и Dota 2, до робототехники. Эта книга — введение в глубокое обучение с подкреплением, уникально комбинирующее теорию и практику. Авторы начинают повествование с базовых сведений, затем подробно объясняют теорию алгоритмов глубокого RL, демонстрируют их реализации на примере программной библиотеки SLM Lab и напоследок описывают практические аспекты использования глубокого RL. Руководство идеально подойдет как для студентов, изучающих компьютерные науки, так и для разработчиков программного обеспечения, которые знакомы с основными принципами машинного обучения и знают Python. Hogwild!
В SLM Lab асинхронная параллелизация реализована с помощью алгоритма Hogwild! — безблокировочного метода параллелизации стохастического градиентного спуска [93]. В Hogwild! глобальная сеть не блокируется во время обновления параметров. При его реализации применяются также общая глобальная сеть без запаздывания и локальное вычисление градиентов.
Прежде чем перейти к разбору кода, стоит уделить некоторое время рассмотрению принципа работы алгоритма Hogwild!..
С параллельным обновлением параметров при отсутствии блокировки связана проблема перезаписи, которая вызывает разрушительные конфликты. Однако этот эффект можно свести к минимуму, если допустить, что задача оптимизации разреженная. То есть для данной параметризированной нейронной сетью функции при обновлении параметров будет, как правило, преобразован лишь малый их поднабор. В этом случае обновления редко будут вступать в противоречие, и перезапись перестанет происходить постоянно. Если исходить из данного допущения о разреженности, то параметры, преобразованные при множестве одновременных обновлений, являются непересекающимися в вероятностном смысле. Следовательно, стратегия безблокировочного параллелизма эффективна. Она жертвует небольшим количеством конфликтов в пользу повышения скорости обучения.
Можно сравнить обе схемы, чтобы увидеть, как разреженность применяется для распараллеливания обновлений параметров, которые иначе были бы последовательными. Пусть θi — параметр сети на i-й итерации. Последовательное обновление может быть записано в следующем виде:

где ui → i + 1 — обновление, такое что θi + 1 = θi + ui → i + 1. Тогда согласно допущению о разреженности небольшая группа из w обновлений uj → j + 1… uj + w – 1 → j + w содержит весьма малое количество пересекающихся элементов. И последовательные обновления могут быть сжаты до параллельного обновления, которое w действующих сетей порождают независимо друг от друга, чтобы получить uj → j + 1… uj → j + w.
Для приведенных далее заданных w обновлений, производимых последовательно и параллельно,

полученные в обоих случаях параметры на w-х итерациях точно или приблизительно равны
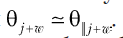
Следовательно, параллелизация с помощью w действующих сетей может быть быстрой аппроксимацией, близкой к последовательному выполнению обновлений. Поскольку в обоих случаях мы решаем одну и ту же задачу оптимизации, они должны давать одинаковые или почти одинаковые результаты.
При использовании Hogwild! нужно учитывать, что чем больше действующих сетей, тем выше вероятность конфликтов при обновлении параметров. Разреженность возникает лишь при небольшом количестве параллельных операций. Если конфликты возникают слишком часто, это допущение неприменимо.
Насколько оправданно допущение о разреженности применительно к RL? К несчастью, этот вопрос недостаточно изучен. Как бы то ни было, этот подход был реализован Мнихом и др. в статье об А3С. Успешность применения данного подхода предполагает несколько возможных объяснений. Во-первых, вполне вероятно, что в задачах, при решении которых он использовался, обновления параметров часто были разреженными. Во-вторых, для компенсации шума, внесенного конфликтующими обновлениями, могли быть проведены дополнительные этапы обучения. В-третьих, одновременные обновления параметров могли происходить редко, например, по той причине, что этапы обновления некоторых действующих сетей были разнесены между собой. В-четвертых, согласно исследованиям методов сжатия нейронных сетей [30, 41, 90] предполагается, что во время их обучения множество параметров необязательны либо излишни. Если конфликты возникнут при обновлении этих параметров, то вряд ли это повлияет на производительность в целом. Полученные результаты могут объясняться совокупностью всех факторов. Эффективность Hogwild! в глубоком RL остается интересной открытой проблемой.
В листинге 8.1 приведена минимальная реализация Hogwild!, примененного к типичному процессу обучения нейронной сети. Основная логика связана с созданием сети и размещением ее в общей памяти перед передачей в действующие сети для обновлений. Такая простота реализации возможна благодаря превосходной интеграции PyTorch с многопроцессорной обработкой данных.
Листинг 8.1. Пример минимальной реализации Hogwild!
1 # Пример минимальной реализации Hogwild! 2 import torch 3 import torch.multiprocessing as mp 4 5 # примеры сети, оптимизатора и функции потерь из PyTorch 6 net = Net() 7 optimizer = torch.optim.SGD(net.parameters(), lr=0.001) 8 loss_fn = torch.nn.F.smooth_l1_loss 9 10 def train(net): 11 # создание data_loader, optimizer, loss_fn 12 net.train() 13 for x, y_target in data_loader: 14 optimizer.zero_grad() # удалить все ранее накопленные градиенты 15 # autograd начинает накапливать следующие градиенты 16 y_pred = net(x) # прямой проход 17 loss = loss_fn(y_pred, y_target) # расчет функции потерь 18 loss.backward() # обратное распространение 19 optimizer.step() # обновление весов сети 20 21 def hogwild(net, num_cpus): 22 net.share_memory() # это заставляет все действующие сети ➥ использовать общую память 23 workers = [] 24 for _rank in range(num_cpus): 25 w = mp.Process(target=train, args=(net, )) 26 w.start() 27 workers.append(w) 28 for w in workers: 29 w.join() 30 31 if __name__ == '__main__': 32 net = Net() 33 hogwild(net, num_cpus=4)
Обучение агента А3С
Если к алгоритму актора-критика с любой функцией преимущества применена параллелизация с помощью асинхронного метода, то он называется А3С [87]. Ко всем реализованным в SLM Lab алгоритмам можно применить параллелизацию путем простого добавления флага в файл spec. В листинге 8.2 это продемонстрировано на примере модифицированной спецификации для актора-критика из главы 6. Полный файл есть в SLM Lab в slm_lab/spec/benchmark/a3c/a3c_nstep_pong.json.
Листинг 8.2. Файл spec для А3С для игры Pong из Atari
1 # slm_lab/spec/benchmark/a3c/a3c_nstep_pong.json 2 3 { 4 "a3c_nstep_pong": { 5 "agent": [{ 6 "name": "A3C", 7 "algorithm": { 8 "name": "ActorCritic", 9 "action_pdtype": "default", 10 "action_policy": "default", 11 "explore_var_spec": null, 12 "gamma": 0.99, 13 "lam": null, 14 "num_step_returns": 5, 15 "entropy_coef_spec": { 16 "name": "no_decay", 17 "start_val": 0.01, 18 "end_val": 0.01, 19 "start_step": 0, 20 "end_step": 0 21 }, 22 "val_loss_coef": 0.5, 23 "training_frequency": 5 24 }, 25 "memory": { 26 "name": "OnPolicyBatchReplay", 27 }, 28 "net": { 29 "type": "ConvNet", 30 "shared": true, 31 "conv_hid_layers": [ 32 [32, 8, 4, 0, 1], 33 [64, 4, 2, 0, 1], 34 [32, 3, 1, 0, 1] 35 ], 36 "fc_hid_layers": [512], 37 "hid_layers_activation": "relu", 38 "init_fn": "orthogonal_", 39 "normalize": true, 40 "batch_norm": false, 41 "clip_grad_val": 0.5, 42 "use_same_optim": false, 43 "loss_spec": { 44 "name": "MSELoss" 45 }, 46 "actor_optim_spec": { 47 "name": "GlobalAdam", 48 "lr": 1e-4 49 }, 50 "critic_optim_spec": { 51 "name": "GlobalAdam", 52 "lr": 1e-4 53 }, 54 "lr_scheduler_spec": null, 55 "gpu": false 56 } 57 }], 58 "env": [{ 59 "name": "PongNoFrameskip-v4", 60 "frame_op": "concat", 61 "frame_op_len": 4, 62 "reward_scale": "sign", 63 "num_envs": 8, 64 "max_t": null, 65 "max_frame": 1e7 66 }], 67 "body": { 68 "product": "outer", 69 "num": 1 70 }, 71 "meta": { 72 "distributed": "synced", 73 "log_frequency": 10000, 74 "eval_frequency": 10000, 75 "max_session": 16, 76 "max_trial": 1 77 } 78 } 79 }
В листинге 8.2 устанавливаются спецификация метаданных «distributed»: «synced» (строка 72) и количество действующих сетей max_session, равное 16 (строка 75). Оптимизатор изменен на версию GlobalAdam (строка 47), которая больше подходит для Hogwild!.. Также меняем количество сред num_envs на 8 (строка 63). Нужно отметить, что если количество сред больше 1, алгоритм станет гибридным с объединением синхронных (векторизация среды) и асинхронных (Hogwild!) методов. Тогда количество действующих сетей составит num_envs · max_session. С концептуальной точки зрения их можно рассматривать как иерархию в Hogwild! действующих сетей, каждая из которых порождает несколько синхронных действующих сетей.
Для обучения агента А3С с оценкой преимущества по отдаче за n шагов с помощью SLM Lab запустите в терминале команды из листинга 8.3.
Листинг 8.3. Обучение агента А3С
1 conda activate lab 2 python run_lab.py slm_lab/spec/benchmark/a3c/a3c_nstep_pong.json ➥ a3c_nstep_pong train
Как обычно, будет запущено испытание Trial для получения графиков, показанных на рис. 8.1. Однако обратите внимание на то, что теперь сессии исполняют роль асинхронных действующих сетей. При запуске на ЦПУ испытание должно занять лишь несколько часов, хотя для этого потребуется машина по крайней мере с 16 ядрами.

Резюме
В этой главе обсуждались два широко применяемых метода параллелизации: синхронная и асинхронная. Было показано, что они могут быть реализованы с помощью векторизации среды и алгоритма Hogwild! соответственно.
Двумя преимуществами параллелизации являются ускорение обучения и повышение разнообразия данных. Последнее играет основную роль в повышении устойчивости и улучшении обучения алгоритмов градиента стратегии. Фактически от этого зависит успех или неудача обучения.
Чтобы выбрать, какой из методов параллелизации применить, нужно рассмотреть такие их факторы, как простота реализации, вычислительная сложность и масштаб задачи.
Синхронные методы (то есть векторизация среды) зачастую простые, и их легче реализовать, чем асинхронные методы, особенно если параллелизация используется только при сборе данных. Порождение данных, как правило, менее затратно, в связи с чем для одного и того же количества кадров потребуется меньше ресурсов. Поэтому лучше масштабировать до умеренного количества действующих сетей, например менее 100. Однако этап синхронизации становится сдерживающим фактором при дальнейшем масштабировании. В этом случае асинхронные методы могут оказаться значительно более быстрыми.
Необходимость в параллелизации возникает далеко не всегда. Основное правило: попробуйте понять, достаточно ли проста задача для того, чтобы решить ее без параллелизации, прежде чем тратить на последнюю время и ресурсы. Необходимость параллелизации обусловлена применяемым алгоритмом. Алгоритмы обучения по отложенному опыту, такие как DQN, зачастую достигают наибольшей производительности без параллелизации из-за того, что память прецедентов уже предоставляет разнообразные данные. Даже если на обучение уходит очень много времени, агенты по-прежнему могут эффективно учиться. Но для того, чтобы алгоритмы обучения по актуальному опыту, такие как метод актора-критика, могли обучаться на разнообразных данных, часто необходима параллелизация.
Сравнительный анализ алгоритмов
В этой книге были введены три основные характеристики алгоритмов. Во-первых, выбираем мы алгоритм обучения по актуальному опыту или по отложенному? Во-вторых, к каким типам пространств параметров его можно применить? И в-третьих, какие функции он настраивает?
REINFORCE, SARSA, A2C и PPO — алгоритмы обучения по актуальному опыту, тогда как DQN и двойная DQN с PER — по отложенному. SARSA, DQN и двойная DQN с PER — основанные на полезности алгоритмы, которые настраивают аппроксимацию функции Qπ. Следовательно, они применимы только к средам с дискретными пространствами действий.
REINFORCE — это в чистом виде основанный на стратегии алгоритм, поэтому он настраивает только стратегию π. A2C и РРО — гибридные методы, настраивающие стратегию π и функцию Vπ. REINFORCE, А2С и РРО применимы к средам как с дискретным, так и с непрерывным пространством действий. Характеристики всех алгоритмов сведены в табл. 9.1.

Обсуждавшиеся нами алгоритмы образуют два семейства, как показано на рис. 9.1. В каждом семействе есть базовый алгоритм, который расширяют все остальные. Первое семейство — основанные на полезности алгоритмы SARSA, DQN и двойная DQN с PER. В этом семействе SARSA — базовый алгоритм. DQN можно рассматривать как расширение SARSA с более высокой эффективностью выборки, так как в нем применяется обучение по отложенному опыту. PER и двойная DQN — это расширения DQN, которые повышают эффективность выборки и устойчивость обучения.
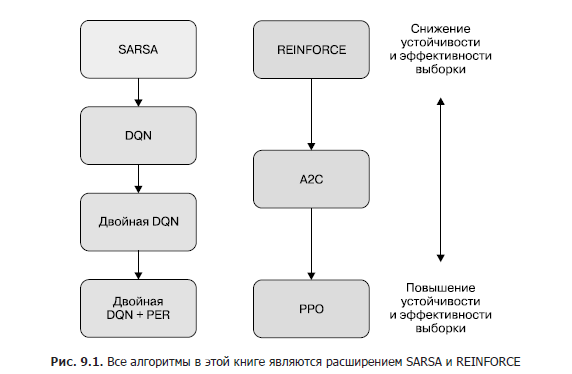
Второе семейство состоит из основанных на стратегии и комбинированных алгоритмов REINFORCE, A2C и PPO. REINFORCE — базовый алгоритм в этом семействе. А2С — расширение REINFORCE с заменой оценки отдачи по методу Монте-Карло на настройку функции полезности. РРО расширяет А2С за счет преобразования целевой функции во избежание резкого падения производительности и для повышения эффективности выборки.
Из всех обсуждавшихся в книге алгоритмов наиболее производительными являются РРО и двойная DQN с PER. В своих семействах эти алгоритмы, как правило, наиболее устойчивые и эффективные с точки зрения качества выборки. Поэтому, приступая к работе над новой задачей, начинать лучше с них.
Принимая решение, что использовать: двойную DQN с PER или PPO, нужно рассмотреть два важных фактора — пространство действий среды и затратность порождения траекторий. Агент РРО может обучаться в средах с любым типом пространства действий, тогда как двойная DQN с PER ограничена дискретными действиями. Тем не менее двойная DQN с PER может обучаться с повторным использованием данных, порожденных при обучении по отложенному опыту с помощью любых других методов. Это становится преимуществом, когда сбор данных затратен с точки зрения ресурсов или времени, например, если нужно накапливать данные из реального мира. В отличие от него РРО — алгоритм обучения по актуальному опыту, поэтому он может обучаться только на данных, порожденных его собственной стратегией.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Python

