Задача Титаника одна из самых известных платформы Kaggle. Рано или поздно, любой начинающий специалист по данным возьмется за ее решение. Здесь я покажу на пальцах: как проверить гипотезы, найти зависимости и реализовать предсказание только на основе аналитики.
Описание задачи
Всем знакома история, связанная с этим кораблем. Посмотрели одноименную картину и имеем представление о чем пойдет речь.

На борту находилось 2200 человек, после крушения выжило ( по некоторым данным) 565=( Предполагается, что у кого-то на борту шансов выжить было больше. Может если это был мужчина, или богач из первого класса... Мы изучим различные гипотезы, проверим их с помощью математической статистики и смоделируем свой вектор предсказания выживания на судне, а потом сравним с тем, как отработают знаменитые алгоритмы.
Обработка данных
Прежде чем начать обработку, необходимо эти данные получить. Любой желающий может зарегистрироваться на Kaggle и принять участие в соревновании. Для удобства прилагаю ссылку, после регистрации нажмите кнопку "Принять участие" и скачет два файла gender_submission.csv, train.csv и test.csv. Для начала импортируем необходимые библиотеки.
import pandas as pd import numpy as np import missingno as msno import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import mannwhitneyu from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier
Чтение файлов обычно выглядит так:
df = pd.read_csv('gender_submission.csv') test = pd.read_csv('test.csv') train = pd.read_csv('train.csv')
msno.matrix(train)

msno.matrix(test)
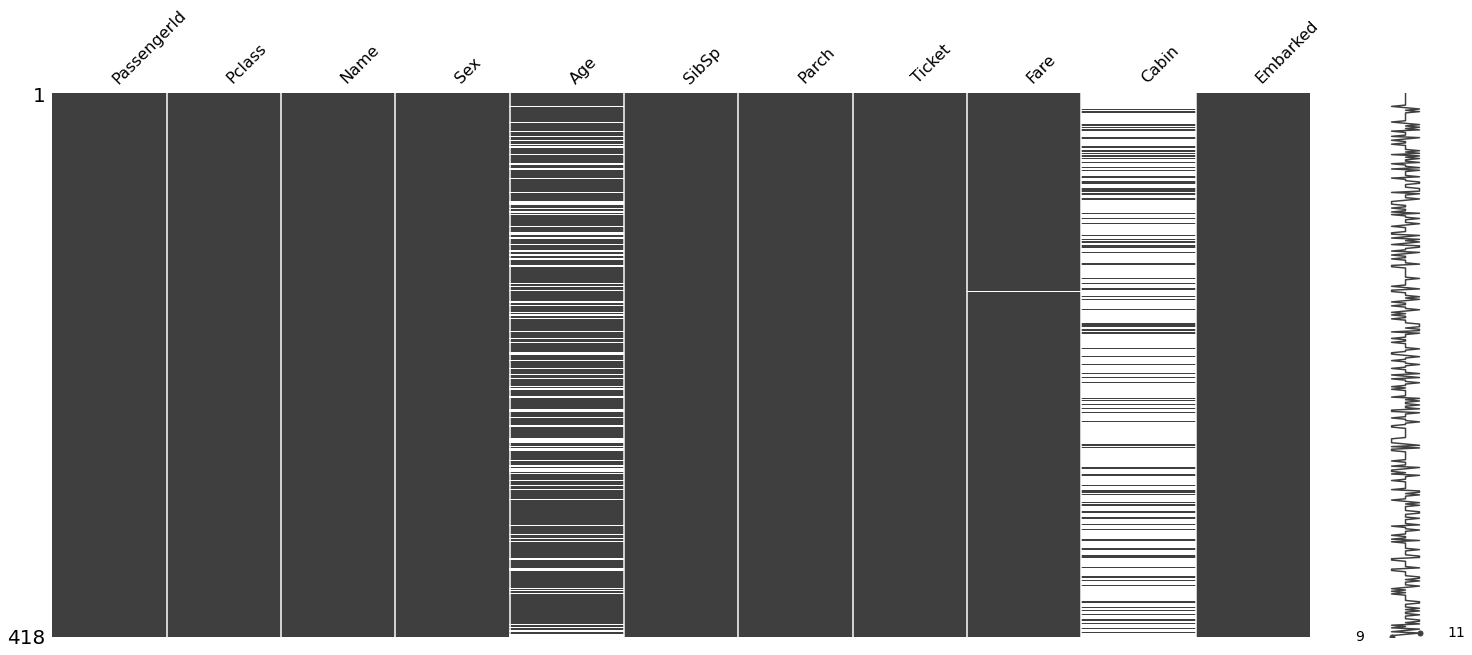
Из указанного выше следует, что в train и test содержатся несовпадающий столбцы ( их названия по оси x) в train - 891 наблюдение, в test- 418. В обоих датасетах много пропущенных значений в столбцах Age и Cabin. df содержит 418 наблюдений с номером пассажира и предсказанием Survived в котором 1- спасен, 0 нет. В нем также 418 значений выживания для пассажиров из test.
Для изучения данных соединим train и test.
y = test.merge(df,on='PassengerId', how = 'right') df = train.append(y)
Мужчины-женщины на борту
df.groupby('Sex')['PassengerId'].count()
Sex female 466 male 843
Классы билетов
df.groupby('Pclass')['PassengerId'].count()
Pclass 1 323 2 277 3 709
Описательная статистика возраста пассажиров.
df.Age.describe()
count 1046.000000 mean 29.881138 std 14.413493 min 0.170000 25% 21.000000 50% 28.000000 75% 39.000000 max 80.000000
df[train.Age==0.17]
Survived | Pclass | Sex | Age | |
|---|---|---|---|---|
354 | 1 | 3 | female | 0.17 |
Ура, малыш спасен:) Описательная статистика тарифов билетов
df.Fare.describe()
count 1308.000000 mean 33.295479 std 51.758668 min 0.000000 25% 7.895800 50% 14.454200 75% 31.275000 max 512.329200
Братьев и сестер на борту
df.SibSp.unique()
array([1, 0, 3, 4, 2, 5, 8])
df.SibSp.describe()
count 1309.000000 mean 0.498854 std 1.041658 min 0.000000 25% 0.000000 50% 0.000000 75% 1.000000 max 8.000000
Родителей- детей на борту
df.Parch.unique()
array([0, 1, 2, 5, 3, 4, 6, 9])
df.Parch.describe()
count 891.000000 mean 0.381594 std 0.806057 min 0.000000 25% 0.000000 50% 0.000000 75% 0.000000 max 6.000000
Большинство пассажиров путешествовавали в одиночку. но некоторые семьи насчитывали до 9 человек. Мужчин почти в два раза больше женщин. Интересно сравнить отличался ли возраст пасажиров в группах мужчины- женщины, была ли разница для них в тарифах билетов.
men = df[df.Sex == "male"] women = df[df.Sex == "female"]
stat, p = mannwhitneyu(men.Age, women.Age) print('Критерий значимости = %.3f' % (p)) alpha = 0.1 if p > alpha: print('Возраст не отличался') else: print('Действительно разный возраст, мужчины ', men.Age.mean(),', женщины ', women.Age.mean())
Критерий значимости = 0.001 Действительно разный возраст, мужчины 30.58 , женщины 28.68
Интересно,а на первый взгляд так и не скажешь)
stat, p = mannwhitneyu(men.Fare, women.Fare) print('Критерий значимости = %.3f' % (p)) alpha = 0.1 if p > alpha: print('Возраст не отличался') else: print('Действительно разный тариф, мужчины ', men.Fare.mean(),', женщины ', women.Fare.mean())
Критерий значимости = 0.000 Действительно разный тариф, мужчины 25.52 , женщины 44.47
А вот тариф однозначно отличается, женщинам путешествовать обходилось дороже. Посмотрим как они распределились по классам кают.
s = pd.DataFrame(df.groupby(['Sex', 'Pclass'])['PassengerId'].count(). reset_index()) f = s[s.Sex == 'female'] f['ratio'] = f.PassengerId/f.PassengerId.sum()*100 m = s[s.Sex == 'male'] m['ratio'] = m.PassengerId/m.PassengerId.sum()*100
Sex | Pclass | PassengerId | ratio | |
|---|---|---|---|---|
0 | female | 1 | 144 | 30.901288 |
1 | female | 2 | 106 | 22.746781 |
2 | female | 3 | 216 | 46.351931 |
Sex | Pclass | PassengerId | ratio | |
|---|---|---|---|---|
3 | male | 1 | 179 | 21.233689 |
4 | male | 2 | 171 | 20.284698 |
5 | male | 3 | 493 | 58.481613 |
Женщины предпочли первый клас чаще мужчин.
Заменим пропуски возраста средним значением ( так как среднее и медиана рядом)
df.Age = df.Age.fillna(df.Age.mean()) df.Age.describe()
count 1309.000000 mean 29.881138 std 12.883193 min 0.170000 25% 22.000000 50% 29.881138 75% 35.000000 max 80.000000
Стандартное отклонение изменилось на 2. В колонке кабин мало значений, удалим их. Также удалим имя, порт посадки на борт и номер билета, так как такая информация не несет предсказательной силы.
df = df.drop(labels=['Cabin','Name','Ticket','Embarked'], axis=1)
Визуализация параметра Survived
sns.catplot(data = df,y='Survived',x='Sex',col='Pclass', kind='bar', saturation=0.5)

Во всех классах женщины спаслись больше мужчин, это говорит о героизме мужчин на борту, так как мы ранее узнали, что их было значительно больше, а также наблюдаем, что пассажиров первого класса спаслось больше( проверим это далее)
sns.catplot(data = df,hue = 'Survived', x = 'Sex', kind='count', saturation=0.5)

На этом графике хорошо видно соотношение выживших мужчин и женщин после крушения. Предположим, что люди 'богатый' сегмент спасались чаще чем остальные.
sns.catplot(data = df,hue = 'Survived', x = 'Pclass', kind='count', saturation=0.5)

Подтверждаем гипотизу, большинство погибших- это пассажиры третьего класса, а наименьшее число гиблей и наибольшее выживших мы наблюдаем в первом классе. Ранее мы уже изучили, что большинство пассажиров в третьем классе- это мужчины. Можно уловить связь - вероятность погибнуть у мужчины в третьем классе больше, чем вероятность погибнуть у всех остальных пассажиров. Соотношение погибших-выживших во втором классе примерно одинаковое.
Возможно, дети выживали реже взрослых, в связи с невозможностью дееспособности.Поделим возраст на 7 перцентилей.
df.Age.hist()

Из распределения, видно, что людей 30 лет погибло больше остальных, но и среднее у нас в этом значении. Разобьем всех на 7 групп с помощью категоризации.
df['Age_cat'] = pd.qcut(df.Age,7) sns.catplot(data = df,hue = 'Survived', x = 'Age_cat', kind='count', saturation=0.5) plt.xticks(rotation=45)
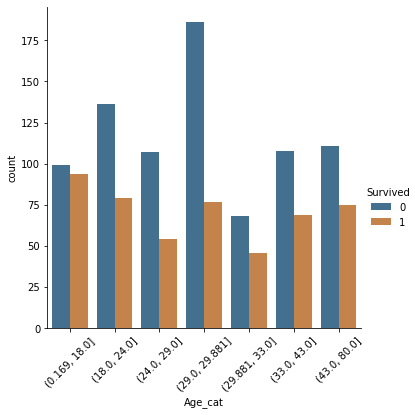
child= df[df.Age<6] sns.catplot(data = child,hue = 'Survived', x = 'Sex',kind='count', saturation=0.5)
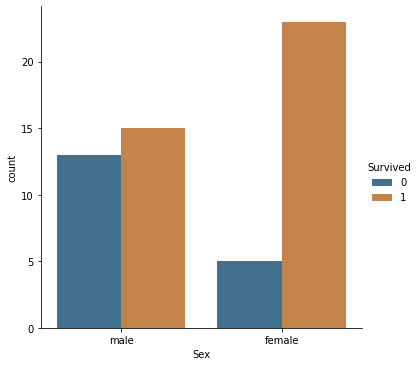
grand= df[df.Age>50] sns.catplot(data = grand,hue = 'Survived', x = 'Sex',kind='count', saturation=0.5)

В целом на корабле предпочли спасать женщин и детей в первую очередь. Зависимости от возраста наблюдается. Например, погибнуть у мужчины за 50 шансов было больше. Проверим как влиял размер сеиьи на выживаемость. Ранее на графике наблюдалось аномальное количество погибших в 29 лет, (конечно, мы меняли пропуски на среднее, и медиана находится примерно здесь)
h = df[(df.Age>=29)&(df.Age<=30)] sns.catplot(data = h,hue = 'Survived', x = 'Sex',kind='count', saturation=0.5)
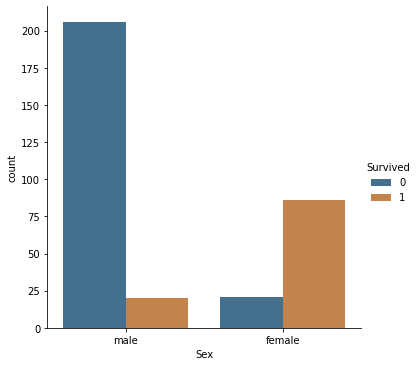
Опять же, высокий бар дали мужчины. Проверим как наличие семьи на борту повлияло на выживаемость.
df = df.drop('Age_cat', axis=1) df['family'] = df['Parch'] + df['SibSp']
Обычно мы можем добавлять новые наблюдений, с помощью арифметических операций ( как в ячейке выше). Такая переменная будет отражать на общее количество человек семьи на борту.
sns.catplot(data = df,hue = 'Survived', x = 'family', kind='count', saturation=0.5)

Мы наблюдаем некую форму графика, а это означает, что у вычисленной переменной есть хорошее влияние на выживаемость. Такую переменную необходимо оставить для увеличения предсказательной способности.
Чем меньше семья- тем больше шансов выжить.
sns.catplot(data = df,hue = 'Survived', x = 'family', col = 'Sex',kind='count', saturation=0.5)

Дополнительно можно посмотреть как размер семьи повлиял на выживаемость внутри гендерных групп.
Модель "Baseline" на основе логических выводов
df['result'] = 1 df.loc[(df.Sex == 'male')&(df.Pclass == 3), 'result'] = 0 df.loc[(df.Sex == 'male')&(df.Age > 50), 'result'] = 0 df.loc[df['family']>3, 'result'] = 0
Здесь я присвоила "смерть" всем мужчинам в третьем классе, всем мужчинам старше 50, всем семьям, в которых больше 3 человек. Теперь оценим точность.
df['errors'] = (df.Survived - df.result)**2 1 - df.errors.sum() / df.shape[0]
0.7203972498090145
Отличный результат для моделей такого типа, в 72 случаях из 100 мы правильно предсказываем событие, а это гораздо выше случайности. Попробуем добавить еще один критерий
df.loc[(df.Sex == 'male')&(df.Age >=29)&(df.Age <=39), 'result'] = 0 df['errors'] = (df.Survived - df.result)**2 1 - df.errors.sum() / df.shape[0]
0.7815126050420168
Предсказательный вектор улучшил точность до 78,9%! Тут мы предсказывали смерти, что если мы попробуем предсказать спасение?
df['alive'] = 0 df.loc[(df.Sex == 'female')&((df.Pclass == 1)& (df.Pclass == 2)), 'alive'] = 1 df.loc[df.Age < 6, 'alive'] = 1 df.loc[(df.Sex == 'female')& (df['family'] < 2), 'alive'] = 1 df.loc[(df.Sex == 'male')& (df['family'] < 2)& (df.Pclass == 1), 'alive'] = 1
df['errors_2'] = (df.Survived - df.alive)**2 1 - df.errors_2.sum() / df.shape[0]
0.7524828113063406
В коде выше мы спасли всех женщин 1-2 класса, детей младше 6 лет, женщин у кого семья меньше 2 человек и мужчин в первом классе с семьей меньше двух.
Полученная точность наглядно показывает, если хорошо познакомиться и изучить данные можно вывести гипотезы, которые помогут реализовать правило предсказания, основываясь на одних лишь логических выводах.

