Недавно в Dota 2 появилась возможность нарезать видео-ролики в формате .mp4 при просмотре записей матчей. Я не удержался и решил сделать простой алгоритм поиска интересных моментов aka хайлайтов. Вот что из этого получилось на примере последней карты гранд-финала The International 2021, где Collapse из Team Spirit катал PSG.LGD на своем Magnus'е.
Видео ускорено в 1.5 раза.
Под катом
Формат записей матчей в Dota 2
Парсинг реплеев
Анализ событий матча
Кластеризация методом DBSCAN
Идеи по усовершенствованию подхода
Ссылки
Формат записей матчей в Dota 2
Запись матча в Dota 2 называется Replay и представляет из себя файл <match_id>.dem с набором protobuf-событий: клики, урон, хил, сообщения в чат и так далее. Если подсунуть файл клиенту игры, то он воспроизведет все события соответствующего матча. Это замечательная фича, которая позволяет вам открыть пивко и залипнуть в годную каточку после тяжелого дня расковырять структуру реплеев.
Но мы сегодня протобафы ковырять не будем. Вместо этого воспользуемся результатами умельцев из комьюнити (ссылка на репозиторий в конце статьи).
Парсинг реплеев
Естественно умельцы не остановились на достигнутом и реализовали парсер с говорящим названием Clarity. Он написан на Java и представляет из себя набор processor'ов, обрабатывающий события разных типов.
Чтобы не возиться с настройками, поднимем контейнер в Docker. Скачаем репозиторий.
git clone https://github.com/odota/parser.git
Запустим Docker.
sudo service docker start
И выполним build-скрипт.
sudo bash parser/scripts/rebuild.sh
Под капотом скрипт создает контейнер и запускает веб-сервер на локальном порту 5600.
sudo docker build -t odota/parser . sudo docker rm -fv parser sudo docker run -d --name parser --net=host odota/parser
У нас появился парсер.Теперь нужен реплей матча. Есть несколько способов его получить.
I. Скачать через клиент игры
Вы можете скачивать реплеи через вкладку Watch в клиенте игры. Я использовалmatch_id = 6227492909.

Результат сохраняется в корневую папку игры. Пример пути на машинах под Windows.
C:\Program Files (x86)\Steam\steamapps\common\dota 2 beta\game\dota\replays\
II. Скачать с OpenDota
Есть возможность скачать реплей с сайта OpenDota (ссылка в коцне статьи). Ребята эмулируют поведение игрового клиента и вытаскивают ссылки на CDN Valve. Последний в свою очередь отдает файлы в сжатом формате, поэтому их нужно предварительно распаковывать.
bzcat replays/6227492909_1934613958.dem.bz2 > replays/6227492909.dem
Допустим мы справились с поиском .dem файла. Прогоним его через парсер.
curl localhost:5600 --data-binary "@replays/6227492909.dem" > replays/6227492909.jsonlinesines
На выходе получим JSON'ы, разделенные символами переноса строки и сохраненные в отдельный файл .jsonlines.
Анализ событий матча
Для удобства дальнейшего анализа расчехлим Python и Jupyter. Считаем файл с предыдущего шага и посчитаем количество событий.
import os import json REPLAYS_DIR = os.path.join('../replays/') dem_path = os.path.join(REPLAYS_DIR, '6227492909.jsonlines') with open(dem_path, 'r') as fin: jsonlines = [json.loads(event) for event in fin.readlines()] len(jsonlines) > 205385
40-минутный матч превратился в ~200k событий. Посмотрим на их структуру.
jsonlines[10] > {'time': -852, 'type': 'player_slot', 'key': '8', 'value': 131}
jsonlines[100212] > {'time': 1011, 'type': 'DOTA_COMBATLOG_MODIFIER_REMOVE', 'value': 0, 'attackername': 'npc_dota_badguys_tower2_top', 'targetname': 'npc_dota_hero_enchantress', 'sourcename': 'dota_unknown', 'targetsourcename': 'dota_unknown', 'attackerhero': False, 'targethero': True, 'attackerillusion': False, 'targetillusion': False, 'inflictor': 'modifier_tower_aura_bonus'}
Видим, что разные события имеют разные поля. Но все события имеют поля type — тип события и time — время в секундах с начала матча. Стоит отметить, что время может принимать отрицательные значения. Это позволяет отделять события до и после выхода крипов (00:00 по часам матча).
Посчитаем количество событий разных типов.
from collections import Counter Counter([e['type'] for e in jsonlines]) > Counter({'DOTA_COMBATLOG_GAME_STATE': 8, 'player_slot': 10, 'interval': 30580, 'draft_start': 1, 'draft_timings': 24, 'actions': 113360, 'CHAT_MESSAGE_ITEM_PURCHASE': 58, 'DOTA_COMBATLOG_GOLD': 2612, 'DOTA_COMBATLOG_MODIFIER_ADD': 7058, 'DOTA_COMBATLOG_PURCHASE': 522, 'DOTA_ABILITY_LEVEL': 406, 'DOTA_COMBATLOG_ABILITY': 1245, 'chatwheel': 22, 'DOTA_COMBATLOG_ITEM': 1658, 'chat': 10, 'DOTA_COMBATLOG_MODIFIER_REMOVE': 7021, 'pings': 482, 'obs': 34, 'DOTA_COMBATLOG_PLAYERSTATS': 225, 'DOTA_COMBATLOG_DAMAGE': 27580, 'DOTA_COMBATLOG_DEATH': 3260, ...
Я предположил, что интересными могут оказаться те моменты, когда герои наносят друг другу урон. Рассмотрим подробнее события DOTA_COMBATLOG_DAMAGE. Для начала посчитаем, сколько урона игроки нанесли друг другу.
import pandas as pd df_damage = pd.DataFrame([ e for e in jsonlines if e['type'] == 'DOTA_COMBATLOG_DAMAGE' and e['attackerhero'] and e['targethero'] ]) df_damage.groupby(['attackername', 'targetname']).agg({'value': 'sum'})

Полученные значения я сравнил с выводами на все том же сайте OpenDota и остался доволен, потому что они совпали.
Обратим внимание, что в игре используются текстовые идентификаторы персонажей, которые могут не соответствовать привычным именам. Например, герой Magnus в реплеях использует кодовое имя npc_dota_hero_magnataur.
df_damage['attackername'].unique() > array(['npc_dota_hero_ember_spirit', 'npc_dota_hero_kunkka', 'npc_dota_hero_enchantress', 'npc_dota_hero_bane', 'npc_dota_hero_tiny', 'npc_dota_hero_magnataur', 'npc_dota_hero_lycan', 'npc_dota_hero_skywrath_mage', 'npc_dota_hero_winter_wyvern', 'npc_dota_hero_terrorblade'], dtype=object)
Визуализируем таймлайн урона от игрока Collapse на Magnus по персонажам других игроков.
import matplotlib.pyplot as plt mask = df_damage['attackername'] == 'npc_dota_hero_magnataur' df_player_damage = df_damage[mask].copy() df_player_damage['ones'] = 1 fig, ax = plt.subplots(figsize=(19, 5)) plt.scatter( x=df_player_damage['time'] / 60, y=df_player_damage['ones'] ) plt.plot()

Матчи в Dota 2 можно условно разделить на 2 большие стадии: лайнинг и основная. В случае Collapse это разделение проходит по границе ~10 минут с момента выхода крипов. Герой Magnus раскрывается как раз в основной стадии за счет покупки Blink Dagger и обилия массовых драк. Поэтому отсечем события до 10 минуты, а также увеличим размер точек в зависимости от нанесенного урона.
df_player_late_damage = df_player_damage[df_player_damage['time'] > 10 * 60].copy() fig, ax = plt.subplots(figsize=(19, 5)) plt.scatter( x=df_player_late_damage['time'] / 60, y=df_player_late_damage['ones'], s=df_player_late_damage['value'] ) plt.plot()

Кластеризация методом DBSCAN
Заметим, что ощутимую часть времени персонаж не наносит урон. А значит и шансы обнаружить хайлайты в эти моменты крайне невелики. С другой стороны, события нанесения урона образуют достаточно плотные группы. Интуиция подсказывает, что эти группы и есть потенциальные клипы с хайлайтами. Все что требуется — найти начало и конец каждого клипа.
Задачу можно свести к кластеризации — методу машинного обучения без учителя, где общая идея заключается в том, чтобы разделить исходную выборку на подмножества похожих объектов — кластеры.
Алгоритмов кластеризации достаточно много, ниже иллюстрация результатов работы некоторых из них на синтетических данных.

Мы воспользуемся алгоритмом DBSCAN. Суть проста: объединить объекты, которые находятся  - окрестности друг друга. Расстояние между объектами можно считать с помощью разных метрик, но в нашем примере хватит самой привычной — Евклидовой.
- окрестности друг друга. Расстояние между объектами можно считать с помощью разных метрик, но в нашем примере хватит самой привычной — Евклидовой.

Причем мы не будем использовать абсолютное значение урона, а только время события. Т.е. для  мы просто группируем события с интервалом не более ~30 секунд.
мы просто группируем события с интервалом не более ~30 секунд.
Вторым важным параметром алгоритма является min_samples. Он определяет минимальное число объектов в кластерах. Если вокруг точки мало соседей, то ей присваивается метка -1 — выброс. В данном примере можно взять min_samples = 1 и ничего не сломается, но на практике это может привести к клипам с хайлайтами, у которых начало будет совпадать с концом.
from sklearn.cluster import DBSCAN dbscan = DBSCAN(eps=30, min_samples=2) cluster = dbscan.fit_predict(df_player_late_damage[['time', 'ones']]) df_player_late_damage['cluster'] = cluster fig, ax = plt.subplots(figsize=(19, 5)) plt.scatter( x=df_player_late_damage['time'] / 60, y=df_player_late_damage['ones'], s=df_player_late_damage['value'], c=df_player_late_damage['cluster'] )

Осталось только вспомнить, что кластеры в данном случае — временные промежутки матча. Для нарезки клипов с хайлайтами выделим начало и конец каждего кластера.
df_player_late_damage['stime'] = df_player_late_damage['time'].apply( lambda t: f'{t // 60}:{str(t % 60).zfill(2)}') df_action = df_player_late_damage.groupby('cluster').agg({'stime': ['first', 'last']}) df_action.sort_values(('stime', 'first'))
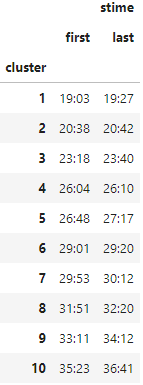
Успех! Осталось воспользоваться фичей игры и нарезать клипы. Итоговое видео вы уже видели в начале статьи.
Идеи по усовершенствованию подхода
Внимательный читатель заметит, что кластеризацию мы использовали скорее для общего развития. Можно потюнить параметры алгоритма или вовсе изменить подход для поиска временных промежутков с потенциальными хайлайтами.
Некоторые моменты получились не очень насыщенными. Как отсортировать временные промежутки по эпичности?
Подсказка: можно использовать не только события урона.Как реализовать автоматическую запись видео, чтобы не приходилось запускать клиент игры и накликивать руками?
Подсказка: существуют консольные командыdemo_goto,demo_gototick.
В следующей части мы увеличим масштаб и напишем сервис для параллельного парсинга реплеев на Celery и Flask.

