Начиная с PVS-Studio 7.14, для C и C++ анализатора появилась поддержка межмодульного анализа. В этой статье, которая будет состоять из двух частей, мы расскажем, как устроены похожие механизмы в компиляторах и раскроем некоторые технические подробности реализации в нашем статическом анализаторе.

Предисловие
Прежде чем рассматривать сам межмодульный анализ, будет полезным освежить в памяти, как устроена компиляция в мире C и C++. В этой части мы уделим особое внимание различным техническим решениям в области компоновки объектных модулей. А также посмотрим, какое применение межмодульный анализ нашёл в известных компиляторах и как он связан с оптимизациями времени связывания (LTO).
Если вы эксперт в этой области, вам скорее всего будет интереснее вторая часть статьи, в которой мы расскажем о своих решениях и проблемах, с которыми сталкивались. Кстати, автор не считает самого себя экспертом в сфере устройства компиляторов и будет рад конструктивной критике.
Фазы компиляции
Компиляция C и C++ проектов происходит в несколько этапов.
Согласно стандартам C18 (п.5.1.1.2 "Programming languages — C") и C++20 (п.5.2 "Working Draft, Standard for Programming Language C++"), определено 8 и 9 фаз трансляции соответственно.
Давайте опустим детали и рассмотрим абстрактно процесс трансляции:

Препроцессор выполняет предварительные операции над каждым компилируемым файлом перед тем, как передать его компилятору. На этом этапе происходит подстановка текста всех заголовочных файлов на место директив #include и раскрытие всех макросов. Соответствует фазам 1 – 4.
Компилятор преобразует каждый препроцессированный файл в файл с машинным кодом, специально подготовленным для компоновки в исполняемый бинарный объектный файл. Соответствует фазам 5 – 7.
Компоновщик объединяет все объектные файлы в бинарный исполняемый файл, разрешая при этом конфликты при совпадении символов. Только на этом этапе код, написанный в разных файлах, связывается в единое целое. Соответствует фазе 8 и 9 драфтов C18 и C++20 соответственно.
Как мы можем заметить, программа составляется из единиц трансляции. И каждая из них компилируется независимо от другой. Из-за этого каждая отдельная единица трансляции не имеет никакой информации о других. По этой причине все сущности (функции, классы, структуры и т. д.) в C и C++ программах имеют объявление и определение.
Рассмотрим пример:
// TU1.cpp
#include <cstdint>
int64_t abs(int64_t num)
{
return num >= 0 ? num : -num;
}
// TU2.cpp
#include <cstdint>
extern int64_t abs(int64_t num);
int main()
{
return abs(0);
}В файле TU1.cpp присутствует определение функции abs, а в файле TU2.cpp — только её объявление и использование. Компоновщик сам определяет, какая именно функция будет вызвана, если не нарушается правило единственного определения (ODR). Последнее означает ограничение: у каждого символа должно быть одно и только одно определение.
Для упрощения согласования разных единиц трансляции был придуман механизм заголовочных файлов, заключающийся в объявлении чёткого интерфейса. Впоследствии каждая единица трансляции в случае надобности будет включать заголовочный файл через директиву препроцессора #include.
Символы и их категории
Когда компилятор встречает объявление, у которого нет соответствующего определения в единице трансляции, то он вынужден оставить работу по связыванию компоновщику. И, к сожалению, при этом теряется часть оптимизаций, которые он мог бы выполнить. Этот этап выполняется уже компоновщиком и называется "оптимизациями времени связывания" (LTO). Само же связывание осуществляется по именам сущностей, то есть по идентификаторам, или символам. На этом же этапе выполняется и межмодульный анализ.
Компилятору необходимо скомпоновать различные объектные файлы в один, связав при этом все ссылки в программе. Тут нужно подробнее остановиться на последнем. Речь идёт о символах – ими в программе называются любые идентификаторы, которые в ней встречаются. Рассмотрим пример:
struct Cat // <Cat, class, external>
{
static int x; // <Cat::x, object, internal>
};
Cat::x = 0;
int foo(int arg) // <foo(int), function, external>
{
static float symbol = 3.14f; // <foo(int)::symbol, object, internal>
static char x = 2; // <foo(int)::x, object, internal>
static Cat dog { }; // <foo(int)::dog, object, internal>
return 0;
}Компилятор разделяет символы на категории. Зачем это нужно? Не все символы предназначены для использования в других единицах трансляции. При связывании необходимо эт�� учитывать. То же самое нужно учитывать и при статическом анализе. Сначала стоит определить, какую именно информацию нужно собирать для объединения между модулями.
Первая категория – linkage, или тип связывания. Определяет область видимости символа.
Если символ имеет внутренний тип связывания, то и ссылаться на него можно только в той единице трансляции, в которой он объявлен. Если в другом объектном модуле будет символ с таким же именем, это не вызовет проблем. Но компоновщик будет рассматривать их как разные.
static int x3; // internal
const int x4 = 0; // internal
void bar()
{
static int x5; // internal
}
namespace // all symbols are internal here
{
void internal(int a, int b)
{
}
}Если символ имеет внешний тип связывания, то он уникален, предназначен для использования во всех единицах трансляции программы и будет помещён в общую таблицу. В случае если компоновщик встретит больше одного определения с внешним типом связывания, то сообщит о нарушении правила единственного определения.
extern int x2; // external
void bar(); // externalЕсли символ не имеет типа связывания, то он будет виден только в той области видимости, в которой определён. Например, в блоке инструкций, имеющем свою область видимости (if, for, while и так далее).
int foo(int x1 /* no linkage */)
{
int x4; // no linkage
struct A; // no linkage
}Вторая категория – storage duration. Это свойство идентификатора, определяющее правила, в соответствии с которыми объект будет создан и разрушен.
Automatic storage duration – объект размещается в памяти в момент его определения и освобождается, когда контекст выполнения программы выходит из его области видимости.
Static storage duration определяет ресурсы, которые будут размещены в памяти в момент старта программы и освобождены при её завершении.
Объекты, созданные с thread storage duration, будут размещены в памяти каждого потока отдельно друг от друга. Это полезно при создании потокобезопасных приложений.
И, наконец, dynamic storage duration. Определяет ресурсы, размещённые в динамической памяти. Самый сложный случай для компиляторов и статических анализаторов. Такие объекты не будут уничтожены автоматически. Управление ресурсами с dynamic storage duration осуществляется через указатели. Контролировать такие ресурсы удобно с помощью упра��ляющих объектов, имеющих свой storage duration, которые обязаны освободить их вовремя (идиома RAII).
Все символы сохраняются в объектном файле в специальной секции в таблице. И тут мы подходим к объектным файлам.
Объектные файлы
Как писалось ранее, компилятор преобразует единицы трансляции в двоичные объектные файлы, организованные определённым образом. У разных платформ свои форматы объектных файлов. Давайте взглянем на структуру самых распространённых из них.

COFF – изначально использовался на UNIX системах (.o, .obj) и не поддерживал 64-битные архитектуры (потому что их в тот момент просто не было). Позже был заменён на формат ELF. С его развитием появился Portable Executable (PE), который до сих пор используется в Windows (.exe, .dll).
Mach-o – формат объектных файлов на macOS. Отличается от COFF структурой, но выполняет те же функции. Формат поддерживает хранение кода для разных архитектур. Например, в одном исполняемом файле можно хранить код как для ARM, так и для x86 процессоров.
ELF – формат объектных файлов на Unix системах. Забегая вперед, скажу, что мы вдохновлялись именно им при создании объектных семантических модулей для PVS-Studio.
У всех трёх форматов схожая структура, так что будем рассматривать общую идею разделения на секции, которая в них используется. В качестве примера рассмотрим формат ELF. Отметим, что он предназначается для хранения исполняемого кода программ. Но, так как мы рассматриваем его в свете статического анализа, не все его компоненты нам интересны.
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 688 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 1
There are 12 section headers, starting at offset 0x2b0:В заголовочной секции содержится информация, определяющая формат файла: Magic, Class, Data, Version и др. Кроме того, в нём присутствует информация о платформе, для которой сгенерирован файл.
Далее по содержанию идёт список заголовочных и программных секций.
Section Headers:
[Nr] Name Type Off Size ES Flg Lk Inf Al
[ 0] NULL 000000 000000 00 0 0 0
[ 1] .strtab STRTAB 0001b9 0000a3 00 0 0 1
[ 2] .text PROGBITS 000040 000016 00 AX 0 0 16
[ 3] .rela.text RELA 000188 000018 18 11 2 8
[ 4] .data PROGBITS 000058 000005 00 WA 0 0 4
[ 5] .bss NOBITS 00005d 000001 00 WA 0 0 1
[ 6] .comment PROGBITS 00005d 00002e 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00008b 000000 00 0 0 1
[ 8] .eh_frame X86_64_UNWIND 000090 000038 00 A 0 0 8
[ 9] .rela.eh_frame RELA 0001a0 000018 18 11 8 8
[10] .llvm_addrsig LLVM_ADDRSIG 0001b8 000001 00 E 11 0 1
[11] .symtab SYMTAB 0000c8 0000c0 18 1 6 8Секций достаточно много. Подробнее можно посмотреть в документации к ELF. В качестве примера кратко рассмотрим некоторые из них:
strtab – по большей части, тут находятся строки, ассоциированные с записями из таблицы символов (см. symbol string table);
text – содержит исполняемые инструкции программы;
data – в этой секции размещаются все проинициализированные данные, которые будут загружены при запуске программы;
bss – также хранит данные программы, но в отличие от секции '.data' не проинициализированные;
symtab – таблица символов программы.
Давайте теперь посмотрим на содержание самих секций. Так как мы рассматриваем предметную область со стороны межмодульного анализа, остановимся на таблице символов.
Symbol table '.symtab' contains 8 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS sym.cpp
2: 0000000000000004 1 OBJECT LOCAL DEFAULT 4 foo(int)::x
3: 0000000000000000 1 OBJECT LOCAL DEFAULT 5 foo(int)::dog
4: 0000000000000000 4 OBJECT LOCAL DEFAULT 4 foo(int)::symbol
5: 0000000000000000 0 SECTION LOCAL DEFAULT 2 .text
6: 0000000000000000 22 FUNC GLOBAL DEFAULT 2 foo(int)
7: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND Cat::xОна состоит из записей, имеющих определённую структуру. В каком-то смысле это простейшая база данных, удобная для многократного чтения. Причём все данные выровнены в памяти. Благодаря этому можно просто загрузить их в структуру, чтобы работать с ними дальше.
Некоторые компиляторы используют свои форматы объектных файлов для хранения там промежуточной информации. К таким можно отнести биткод LLVM (.bc), хранящий промежуточное представление LLVM IR в двоичном формате, или GCC Gimple (.wpo). Вся эта информация используется компиляторами для осуществления оптимизаций времени связывания, в которых участвует и межмодульный анализ.
Межмодульный анализ в компиляторах
Настало время перейти ближе к теме статьи. Прежде чем пытаться что-то реализовывать, будет нелишним посмотреть, как похожие задачи решались в других инструментах. Компиляторы выполняют большое количество оптимизаций кода. В их число входит удаление мертвого кода, раскрутка циклов, раскручивание хвостовой рекурсии, подстановка результатов вычислений на этапе компиляций и т. д.
Тут, например, можно почи��ать список доступных оптимизаций для GCC. Уверены, у вас займёт несколько минут простое пролистывание этого документа. Однако все преобразования выполняются в рамках конкретных единиц трансляции. Из-за этого теряется часть полезной информации и, как следствие, эффективность оптимизаций. Эту проблему и решает межмодульный анализ. Он успешно применяется в компиляторах для оптимизаций времени связывания (Link Time Optimizations). Мы уже кратко описали основную идею, как это работает, в предыдущей статье.
И первый компилятор (мой любимый) – Clang. Относится к группе компиляторов, использующих LLVM для кодогенерации. Такие компиляторы имеют модульную архитектуру. Схематически она представлена на рисунке:

Она содержит три части:
Frontend. Занимается трансляцией кода на конкретном языке (C, C++ и Objective-C в случае с Clang) в промежуточное представление. На этом этапе уже можно делать многие оптимизации, специфичные для языка;
Middle-end. Тут представлены утилиты, которые занимаются анализом или модификацией промежуточного представления. Конкретно в LLVM оно представлено в виде абстрактного ассемблера. Делать над ним оптимизации гораздо удобнее, так как набор его функциональности ограничен до минимума. Вспомните, сколько есть способов инициализации переменных в C++? В LLVM Intermediate Representation их нет (в привычном понимании). Все значения в стековой памяти хранятся в виде виртуальных регистров, работа с которыми происходит через ограниченный набор команд (load/store, арифметические операции, вызовы функций);
Backend. Занимается генерацией исполняемых модулей под конкретную архитектуру.
Такая архитектура имеет много преимуществ. Если вам нужно создать свой компилятор, который будет работать на большинстве архитектур, вам скорее всего будет достаточно написать свой frontend для LLVM. Причём из коробки у вас будут работать общие оптимизации, такие как удаление мёртвого кода, раскрутка циклов и т. д. Если вы разрабатываете новую архитектуру, то, чтобы поддержать для неё большой набор популярных компиляторов, вы можете реализовать только backend для LLVM.
Оптимизации времени связывания как раз работают на уровне промежуточного представления. Давайте посмотрим пример, как это выглядит в читаемом для человека виде:

Файл с исходным кодом simple.cpp можно преобразовать в промежуточную форму с помощью специальной команды. Для краткости результата, на рисунке я также применил большую часть оптимизаций, которые убрали весь лишний код. Речь идёт о преобразовании исходного варианта промежуточного представления в SSA форму. В ней по возможности убираются любые присвоения переменных и заменяются инициализации виртуальных регистров. Естественно, после любых преобразований теряется прямая связь с исходным кодом на C или C++. Однако, значимые для компоновщика external символы остаются. В нашем примере это функция add.
Впрочем, мы отошли от сути. Вернёмся к оптимизациям времени связывания. В документации LLVM описано 4 этапа.

Чтение файлов с объектным кодом или промежуточным представлением. Компоновщик читает объектные файлы в произвольном порядке и собирает информацию в глобальную таблицу символов.
Symbol Resolution. Компоновщик находит символы, для которых нет определения, заменяет слабые, запоминает "живые символы" и т. д. При этом ему не обязательно знать точное содержание исходных файлов с промежуточным представлением. На этом этапе важно, чтобы программа не нарушала правило единственного определения.
Оптимизация файлов с промежуточным представлением. Для каждого объектного файла компоновщик предоставляет нужные им символы, после чего оптимизатор осуществляет эквивалентные преобразования, основываясь на собранной информации. Например, на этом этапе удаляются неиспользуемые в программе функции или другой недостижимый код на основе анализа потока данных в контексте всей программы. Результатом работы этого шага является объединённый объектный файл, содержащий данные из всех единиц трансляции. Чтобы точнее понять, как именно LLVM обходит модули, нужно исследовать его исходный код, но это выходит за рамки данной статьи.
Symbol Resolution после оптимизаций. Необходимо обновить таблицу символов. На этом этапе также обнаруживаются символы, которые связаны с удалёнными на третьем этапе, после чего они тоже удаляются. Далее компоновщик продолжает работу в "обычном" режиме.
Нельзя обойти стороной GCC – коллекция компиляторов для языков C, C++, Objective-C, Fortran, Ada, Go и D. В ней также представлены оптимизации времени связывания. Однако устроены они немного по-другому.
GCC также при трансляции генерирует своё промежуточное представление, называемое GIMPLE. Однако, в отличие от LLVM, хранится оно не в виде отдельных файлов, а рядом с объектным кодом в специальной секции. Кроме того, оно больше похоже на исходный код программы, хоть и является отдельным языком со своей грамматикой. Предлагаю посмотреть на пример из документации.
Для хранения GIMPLE GCC использует формат ELF. По умолчанию они содержат только байт-код программы. Но если указать флаг -ffat-lto-objects, то GCC поместит промежуточный код в отдельную секцию рядом с готовым объектным кодом.
В режиме LTO объектные файлы, сгенерированные GCC, содержат только GIMPLE байт-код. Такие файлы называются slim и устроены так, чтобы такие утилиты, как *ar *и nm, понимали LTO секции.
В общих чертах, LTO в GCC происходит в два этапа.

Первый – writer. GCC создаёт потоковое представление всех внутренних структур данных, необходимых для оптимизации кода. Сюда входит информация о символах, типах и промежуточное представление GIMPLE для тел функций. Этот процесс называется LGEN.
Второй этап – reader. GCC второй раз проходится по объектным модулям с уже записанной в них межмодульной информацией и объединяет их в одну единицу трансляции. Этот этап называется LTRANS. Затем над готовым объектным файлом производятся оптимизации.
Такой подход хорошо работает на небольших программах. Но, так как все единицы трансляции связываются в одну вместе с промежуточной информацией, дальнейшие оптимизации выполняются в одном потоке. Кроме того, приходится загружать всю программу в память целиком (не только глобальную таблицу символов), что может стать проблемой.
Поэтому GCC поддерживает режим, называемый WHOPR, в котором связывание объектных файлов происходит по частям на основе ��рафа вызовов. Это позволяет выполнять второй этап распараллелено и не загружать всю программу в память целиком.
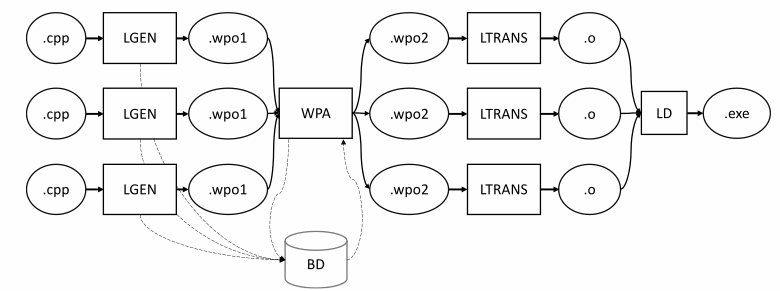
На этапе LGEN так же, как и в обычном режиме, генерируется набор файлов с промежуточным представлением GIMPLE (wpo1).
Далее на этапе WPA на основе анализа вызовов функций (Call Site) полученные файлы объединяются по группам в набор объединённых файлов (wpo2).
На этапе LTRANS выполняются локальные трансформации над каждым .wpo2 файлом, после чего компоновщик объединяет их в исполняемый файл.
При такой реализации LTO можно запускать его в параллельных потоках (за исключением этапа WPA) и не придётся загружать большие файлы в оперативную память.
Заключение
Многое в этой части статьи можно считать справочной информацией под призмой восприятия автора статьи. Как было отмечено в начале, он не эксперт в этой тематике. Именно поэтому ему кажется интересным разобраться в тонкостях работы механизмов, написанных великими умами. Большая их часть скрыта за ширмой инструментов, упрощающих разработку. И это безусловно правильно. Однако, полезно знать, что происходит под капотом машин, которые мы используем каждый день. Если вас заинтересовала эта тема, приглашаем почитать вторую часть, в которой мы применим опыт, полученный в результате исследования вышеизложенных решений.
