Привет, Хабр! Меня зовут Владимир Швец, я ведущий разработчик центра Smart Process в МТС Digital. Расскажу о том, как мы собрали BPM-движок, который позволяет кастомизировать бизнес-процессы без перезагрузки стенда и перезапуска приложения.
Два программиста написали движок за две недели, поэтому такой BPM-механизм – быстрое и легкое решение, назвали его Scenario Engine. Мы применили движок для гибкого создания ряда процессов в рамках проекта интеграции с внешней системой. Ниже я разберу то, как работает движок, что у него под капотом, как мы его придумали и какие выводы сделали.

Цели у нас были такие:
быстро создавать новые процессы;
менять бизнес-процессы без перезапуска приложения;
путем декомпозиции наших классов на небольшие методы и небольшие классы навести некоторый порядок в кодовой базе;
подготовиться к декомпозиции на микросервисы, так как наше решение испытывало ряд технологических проблем, связанных с ограничениями монолитной архитектуры;
уложиться в выделенные нам сроки и потратить минимум ресурсов, так как эта инициатива возникла в ходе реализации проекта интеграции с внешней системой, который имел конечные сроки.
Для решения таких задач подходит BPM. Что такое BPM? Это концепция процессного управления, рассматривающая бизнес-процессы как непрерывно адаптирующиеся к постоянным изменениям, моделируемые с использованием некоторой нотации и динамически перестраиваемые.
Среди известных на рынке решений есть Activiti и Camunda. Второе решение, насколько я знаю, – форк от первого.

У этих вариантов широкий функционал, но мы решили разработать свое решение. Изучение готовых платформ требует времени, плюс есть проблемы с кастомизацией. А еще мы подумали, что дальнейшая разработка пойдет гораздо эффективнее, если решение будет создано с нуля – так мы сможем понимать, какие у него «внутренности».
Какие технологии мы используем?
Первое — это, естественно, язык программирования Java 8. Помимо него у нас используется Spring, в качестве ORM мы применяем jOOQ, база данных – PostgreSQL. Используются также коллекции Google Guava и планировщик задач Quartz.
Концепция решения выглядит следующим образом: у нас есть некоторые процессы, каждый из которых имеет точку начала и состоит из некоторых последовательных задач.
Для примера изобразим процесс, состоящий из трех задач.
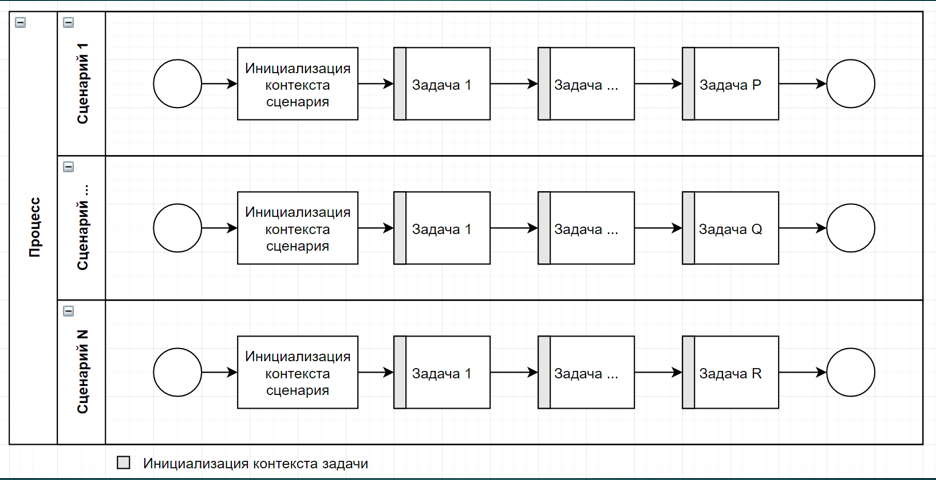
Задачи в рамках одного процесса выполняются последовательно. Также для использования всей вычислительной мощности устройств у нас есть параллельные процессы.
Теперь о том, как передаются параметры из задачи в задачу. Есть некоторая общая коллекция Params, которая является множеством параметров Param. Param – это совокупность ключа и некоторого значения. У нас есть начальная инициализация каждой задачи, в рамках которой задача получает переменные из некоторого контекста сценария. Сначала инициализируется контекст сценария, если ему это необходимо.
Далее по сценарию инициализируется контекст первой задачи. Отработав, она выдает параметры обратно в контекст сценария. Потом вторая задача, потом третья, и так далее. С другими процессами – аналогично. И, соответственно, есть еще одна группировка, которая называется процессом. Один процесс — это совокупность всех сценариев, которые выполняют какую-то общую задачу, имеют общую ценность.
Как это реализовано?
У нас есть некоторый абстрактный класс сущности, назовем его Entity. Этот класс содержит общие для всех дочерних сущностей поля и методы. От него наследуются три разных класса, имеющие разные уникальные характеристики. Eсть сущность задачи Task — атомарное элементарное действие. Есть сущность сценария Scenario — набор последовательно запускаемых задач. Eсть сущность процесса Process — совокупность параллельно отрабатывающих сценариев.

Какие свойства имеет любая сущность? Уникальный идентификатор (UUID), наименование name, контекст сontext, статус status. Статус может быть успешным или ошибочным. Статус сценария определяется статусом задач, которые в него входят. Если все задачи выполнены со статусом success, то у сценария тоже будет статус success. Пока задачи выполняются у сценария статус in progress. Если какая-то задача в ходе выполнения возвращает ошибку, то, соответственно, у сценария проставляется статус exception.
Касательно статуса процесса – тут все не так однозначно, возможны два варианта. Есть процессы, которые состоят только из сценариев, которые должны отработать успешно, чтобы процесс можно было считать выполненным. В таком случае любой сценарий, завершившийся с ошибкой, проставляет процессу статус exception. Однако, бывают и такие процессы, которые можно считать завершившимися успешно, даже если какие-то входящие в него сценарии завершились с ошибкой. В таком случае процессу может быть проставлен статус success, даже несмотря на то, что один из сценариев не завершился. Данные случаи обрабатываются отдельно.
Помимо статуса есть время начала timeStart и время завершения timeFinish работы сущности. Также любая сущность обладает сообщением message. Если какая-то задача или сценарий хотят что-то сказать более общей сущности о себе, – они могут поместить это в категорию message. Как правило, message содержит более подробное сообщение об ошибке, если задача, сценарий или процесс завершились со статусом exception.
Каждый таск имеет уникальные идентификаторы процесса и сценария, которым он принадлежит. У сценария же есть только уникальный идентификатор процесса. Помимо этого, у сценария есть список задач, из которых он состоит. Процесс же имеет множество сценариев, из которых он состоит.
Как теперь все это конфигурировать?
Задачи бывают функциональные и структурные. Из функциональных задач выделяем несколько типов: Read — смысл задачи заключается в том, чтобы считать некоторые данные в контекст задачи и потом вернуть это в контекст сценария. Второй тип задач — это Write, когда мы определенные параметры из контекста задачи, записываем в некоторую таблицу базы данных. В таком случае указывается таблица, а поля заполняемой таблицы заполняются согласно ключам параметров контекста.
Есть задачи типа Call, они нужны для вызова внешних систем. Переменные берутся из контекста задачи и из этих переменных формируется запрос во внешнюю систему. Запрос отправляется, ответ получается синхронно, и парсится в контекст задачи, откуда параметры возвращаются в контекст сценария. А есть задачи типа Calc — это преобразование данных, когда нам нужно, например, просто переложить данные из параметров с одними ключами в параметры с другими ключи и произвести какие-либо вычисления.
Структурные задачи управляют потоком выполнения, то есть сценарием. Первый тип здесь — это IfElse, задачи, которые позволяют запустить некоторый подсценарий, если какое-то значение параметра контекста равно какой-то определенной величине. Если значение равно другому числу – запускается другой подсценарий.
Есть задачи типа Map. Задача этого типа пробегает по некоторой коллекции из своего контекста и на каждый элемент этой коллекции запускает свой подсценарий. При этом она не ожидает завершения подсценария. Есть задачи типа MapReduce. Отличие от предыдущего типа заключается в том, что они ожидают завершения запущенных подсценариев и аккумулируют результаты в некоторую новую коллекцию.
И есть задачи типа Terminator — если какой-то параметр равен определенному значению, то сценарий завершаются. Причем сценарий может завершится в таком случае как со статусом success, так и со статусом exception.
Как конфигурируется наша система?
Вся конфигурация хранится в базе данных. Оттуда она считывается в статическую коллекцию Guava при запуске приложения и обновляется раз в час. Таким образом, конфигурация обновляется сама по себе, но с задержкой не более чем в один час. Однако, если нужно принудительно обновить конфигурацию, это можно сделать, вызвав определенный метод через http-контроллер.
Какие таблицы определяют конфигурацию нашего движка? Прежде всего – таблица Process. Далее – таблица Scenario. И таблица задач Task. Все эти таблицы состоят из двух колонок: идентификатор и название.

Для того, чтобы связать задачи со сценариями, есть отдельная таблица, которая так и называется Scenario_Task. В ней есть четыре колонки: идентификатор строки, идентификатор сценария, идентификатор задачи и порядковый номер задачи в сценарии. Дело в том, что задачи выполняются в рамках сценария последовательно, и каждая задача должна иметь свой порядковый номер выполнения.
Из каких сценариев состоит процесс? Есть специальная таблица Process_Scenario и она похожа на предыдущую. Разница в том, что в процессе нет порядкового номера сценария, потому что сценарии в рамках процесса запускаются параллельно, а не последовательно. Номер сценария процессу попросту не нужен.
И есть еще отдельная таблица, которая называется Context. У нее такие колонки: идентификатор строки, идентификатор сущности и наименование ключа параметра. Context нужна для того, чтобы сконфигурировать инициализацию контекста сущности. По идентификатору сущности мы находим все параметры, которые должны передаться этой сущности на вход. В общем виде все это выглядит примерно так:

Так выполняется первичная конфигурация BPM-движка. Если нужно в рамках сценария добавить некоторую задачу – мы просто делаем insert в таблицу Scenario_Task. Если в рамках процесса добавился параллельный запуск еще какого-то сценария – в таблицу Process_Scenario добавляем еще одну запись. Если в контекст какой-то задачи требуется добавить какой-то параметр – добавляем запись в таблицу Context.
Для мониторинга того, что происходит с нашей системой, используется специальное логирование. Центр механизма логирования – таблица Unit. Данная таблица состоит из трёх колонок: собственный уникальный идентификатор UUID экземпляра сущности, идентификатор сущности Entity_ID и тип сущности Type (задача, сценарий, процесс). Эта таблица связана с таблицами Process, Scenario и Task. В таблицах Process, Scenario и Task общие абстрактные сущности (задачи, сценарии и процессы), а в таблице Unit записи о конкретных экземплярах процессов, сценариев или задач.
И есть отдельная табличка с событиями Event. Она содержит следующие колонки: UUID процесса, UUID сценария, UUID задачи, статус, время начала, время завершения, сообщение и контекст. По этой таблице можно определить состояния каждой задачи, при этом у задачи будет Process_ID, Scenario_ID и Task_ID. Также можно выяснить состояние каждого сценария. У сценария будет, соответственно, Process_ID и Scenario_ID. В таблицу логируются и процессы. У процесса будет только Process_ID.
Какие результаты?
мы смогли сделать гибкий динамический движок, позволяющий создавать новые сценарии из уже существующих задач и добавлять их в процессы;
в рамках декомпозиции наших больших методов и классов на маленькие методы мы улучшили структуру нашей бизнес-логики;
после того, как мы декомпозировали наш код на набор маленьких методов, их стало проще покрыть тестами, и процент кода, покрытого тестами, сильно повысился;
появилось понимание того, как дальше декомпозировать наш монолит на микросервисы;
решение мы смогли реализовать буквально за один спринт, еще примерно один спринт понадобился на доводку механизма до ума и исправление всех возникших в процессе разработки багов.
Что дальше?
Мы решили сделать сделать сервис-оркестратор, который считывал бы конфигурацию из базы данных и, в зависимости от этой конфигурации, запускал ту или иную задачу на выполнение. А задачи вывести в отдельные микросервисы, чтобы каждый микросервис имеет свою очередь на вход и на выход. Название очередей также конфигурировать через базу данных.
Спасибо за внимание! Если у вас есть вопросы о нашем BPM-механизме или вы делаете что-то аналогичное – с удовольствием пообщаюсь с вами в комментариях к этой статье!
