Здравствуйте, в данной статье я постараюсь разобрать основные шаги и методы решения соревнований на Kaggle на примере решения обучающего соревнования от DeepLearningSchool МФТИ по предсказанию оттока пользователей.
Работа с данными
Предобработка
Итак, для начала давайте загрузим наш датасет и посмотрим на 5 случайных строк в нем.
ClientPeriod | MonthlySpending | TotalSpent | Sex | IsSeniorCitizen | HasPartner | HasChild | HasPhoneService | HasMultiplePhoneNumbers | HasInternetService | HasOnlineSecurityService | HasOnlineBackup | HasDeviceProtection | HasTechSupportAccess | HasOnlineTV | HasMovieSubscription | HasContractPhone | IsBillingPaperless | PaymentMethod | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4650 | 66 | 20.35 | 1359.5 | Male | 0 | Yes | Yes | Yes | No | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | One year | Yes | Electronic check | 0 |
29 | 25 | 89.70 | 2187.55 | Female | 1 | No | No | Yes | Yes | Fiber optic | No | Yes | No | No | No | Yes | Month-to-month | Yes | Electronic check | 1 |
1688 | 36 | 76.35 | 2606.35 | Female | 0 | No | No | Yes | No | DSL | Yes | Yes | Yes | Yes | Yes | No | One year | Yes | Mailed check | 0 |
2946 | 20 | 19.60 | 356.15 | Male | 0 | No | No | Yes | No | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | Month-to-month | Yes | Credit card (automatic) | 0 |
4865 | 13 | 98.00 | 1237.85 | Male | 1 | Yes | No | Yes | No | Fiber optic | No | Yes | Yes | No | Yes | Yes | Month-to-month | Yes | Electronic check | 1 |
Как видим, у нас есть 20 колонок, в которых записана информация о пользователях. Нам нужно понять, какие пользователи чаще всего уходят к другому оператору, а какие остаются. Для начала на будущее разметим колонки, часть из них нам нужно обозначить как категориальные(текстовые), а часть - как числовые. Колонку Churn обозначим как цель наших предсказаний.
num_cols = [ "ClientPeriod", "MonthlySpending", "TotalSpent", ] cat_cols = [ "Sex", "IsSeniorCitizen", "HasPartner", "HasChild", "HasPhoneService", "HasMultiplePhoneNumbers", "HasInternetService", "HasOnlineSecurityService", "HasOnlineBackup", "HasDeviceProtection", "HasTechSupportAccess", "HasOnlineTV", "HasMovieSubscription", "HasContractPhone", "IsBillingPaperless", "PaymentMethod", ] target = 'Churn'
Затем давайте проверим, есть ли повторяющиеся записи
print(f"Duplicated rows: {data.duplicated(keep=False).sum()}") print(f"Duplicated rows without target: {data.drop(target, axis=1).duplicated(keep=False).sum()}")
Duplicated rows: 28
Duplicated rows without target: 41
Видим, что у нас 28 одинаковый строк, если учитывать целевую Chern и 41 одинаковая строка, если не учитывать. Это значит, что у нас есть некоторое количество одинаковых записей с разным результатом. Такие строчки вредны для моделей, поскольку не дают четкого разделения классов, поэтому мы их удаляем.
data[data.drop(target, axis=1).duplicated(keep=False)].sort_values(by=[*data.columns])
Далее нам нужно посмотреть, есть ли пропущенные значения в датасете. В нашем случае кроме NaN на месте пропусков был еще и пробел: " ". Давайте найдем, где именно они были
data.replace(" ", np.nan, inplace=True) X_test.replace(" ", np.nan, inplace=True) pd.DataFrame(data.isna().sum(), columns=["NaN Count"]) \ .sort_values("NaN Count") \ .plot(kind="barh", legend=False, figsize=(12, 8));

Получаем 9 NaN в столбце TotalSpent. Рассмотрим этих клиентов подробнее.
ClientPeriod | MonthlySpending | TotalSpent | Sex | IsSeniorCitizen | HasPartner | HasChild | HasPhoneService | HasMultiplePhoneNumbers | HasInternetService | HasOnlineSecurityService | HasOnlineBackup | HasDeviceProtection | HasTechSupportAccess | HasOnlineTV | HasMovieSubscription | HasContractPhone | IsBillingPaperless | PaymentMethod | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1157 | 11 | 94.20 | 999.9 | Female | 0 | No | No | Yes | No | Fiber optic | No | Yes | Yes | Yes | No | Yes | Month-to-month | Yes | Electronic check | 0 |
1048 | 0 | 25.75 | NaN | Male | 0 | Yes | Yes | Yes | Yes | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | Two year | No | Mailed check | 0 |
1707 | 0 | 73.35 | NaN | Female | 0 | Yes | Yes | Yes | Yes | DSL | No | Yes | Yes | Yes | Yes | No | Two year | No | Mailed check | 0 |
2543 | 0 | 19.70 | NaN | Male | 0 | Yes | Yes | Yes | No | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | One year | Yes | Mailed check | 0 |
3078 | 0 | 80.85 | NaN | Female | 0 | Yes | Yes | Yes | No | DSL | Yes | Yes | Yes | No | Yes | Yes | Two year | No | Mailed check | 0 |
3697 | 0 | 20.00 | NaN | Female | 0 | Yes | Yes | Yes | No | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | Two year | No | Mailed check | 0 |
4002 | 0 | 61.90 | NaN | Male | 0 | No | Yes | Yes | Yes | DSL | Yes | Yes | No | Yes | No | No | Two year | Yes | Bank transfer (automatic) | 0 |
4326 | 0 | 25.35 | NaN | Male | 0 | Yes | Yes | Yes | Yes | No | No internet service | No internet service | No internet service | No internet service | No internet service | No internet service | Two year | No | Mailed check | 0 |
4551 | 0 | 52.55 | NaN | Female | 0 | Yes | Yes | No | No phone service | DSL | Yes | No | Yes | Yes | Yes | No | Two year | Yes | Bank transfer (automatic) | 0 |
4598 | 0 | 56.05 | NaN | Female | 0 | Yes | Yes | No | No phone service | DSL | Yes | Yes | Yes | Yes | Yes | No | Two year | No | Credit card (automatic) | 0 |
Очевидно, это новые клиенты, которые еще не внесли первый платеж. Заполним их нулями.
data["TotalSpent"] = data.TotalSpent.fillna(0).astype(float) X_test["TotalSpent"] = X_test.TotalSpent.fillna(0).astype(float)
Затем давайте посмотрим, как у нас распределены данные
fig, axes = plt.subplots(5, 4, figsize=(25, 20)) for ax, col in zip(axes.flatten(), data.columns): ax.set_title(col) if col in cat_cols or col == target: ax.pie(data[col].value_counts(), autopct="%1.1f%%", labels=data[col].value_counts().index) else: data[col].plot(kind="hist", ec="black", ax=ax)
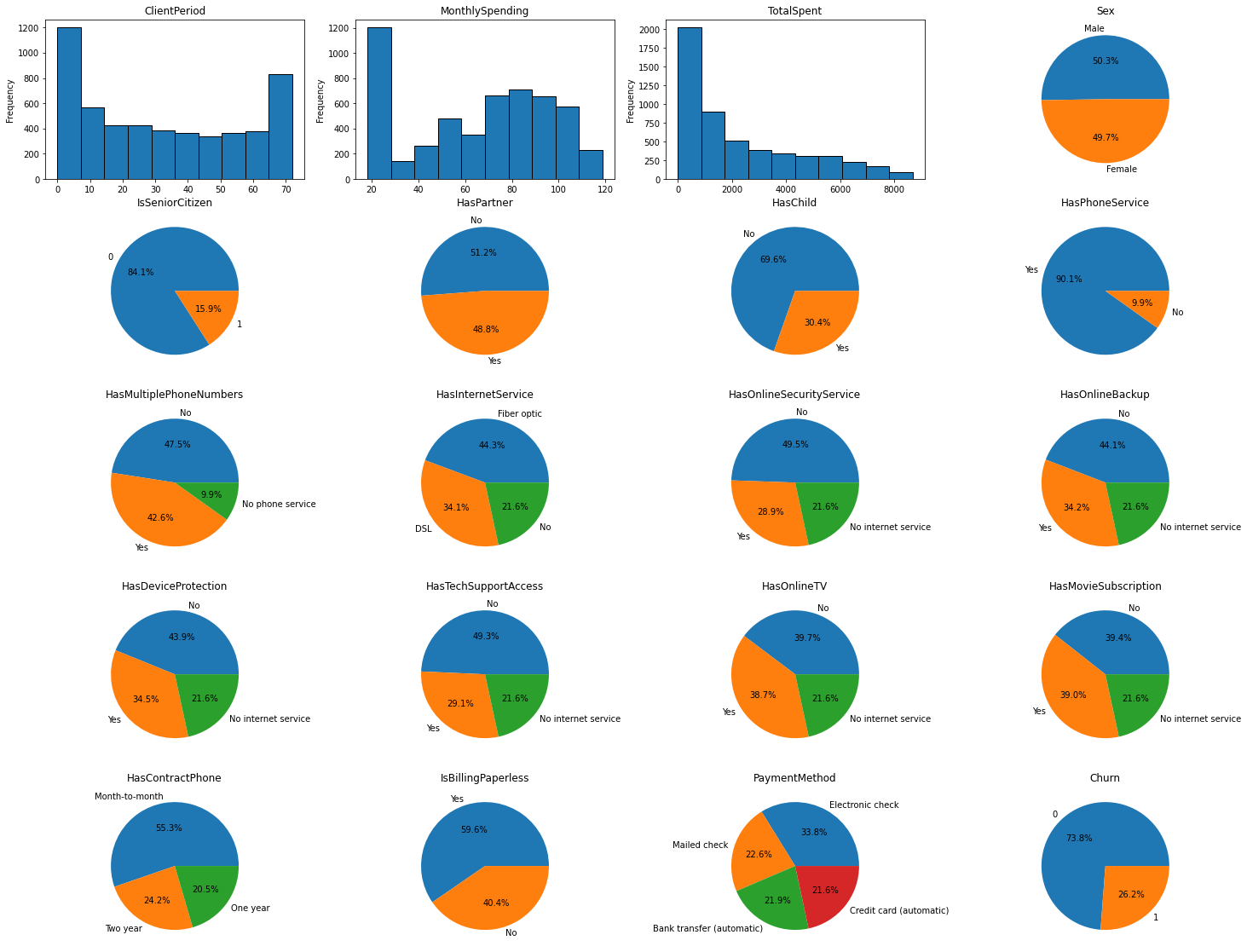
На графике Churn в правом нижнем углу видно, что класс 1 представлен четвертью данных. Это означает, что люди в три раза чаще остаются, чем уходят. Многие столбцы имеют значения «No internet service» и «No Phone service». Поскольку у нас уже есть функции «HasPhoneService» и «HasInternetService» эта информация избыточна. Мы можем объединить их с опцией «No».
Давайте поищем закономерности в данных
Между Churn и PaymentMethod
tmp = data.groupby("PaymentMethod", as_index=False).agg({"Churn": ["sum", "count"]}) tmp["Churn (%)"] = 100 * tmp["Churn", "sum"] / tmp["Churn", "count"] tmp.sort_values("Churn (%)").reset_index(drop=True)
PaymentMethod | Churn | Churn (%) | ||
|---|---|---|---|---|
sum | count | |||
0 | Credit card (automatic) | 165 | 1143 | 14.435696 |
1 | Bank transfer (automatic) | 195 | 1159 | 16.824849 |
2 | Mailed check | 230 | 1194 | 19.262982 |
3 | Electronic check | 794 | 1786 | 44.456887 |
Видим, что разница между электронным чеком и другими способами оплаты гораздо больше, чем между автоматическим и неавтоматическим.
Между Churn и HasContractPhone
tmp = data.groupby("HasContractPhone", as_index=False).agg({"Churn": ["sum", "count"]}) tmp["Churn (%)"] = 100 * tmp["Churn", "sum"] / tmp["Churn", "count"] tmp.sort_values("Churn (%)").reset_index(drop=True)
HasContractPhone | Churn | Churn (%) | ||
|---|---|---|---|---|
sum | count | |||
0 | Two year | 33 | 1280 | 2.578125 |
1 | One year | 120 | 1082 | 11.090573 |
2 | Month-to-month | 1231 | 2920 | 42.157534 |
Иначе говоря, люди редко разрывают долгосрочные телефонные контракты
Между Churn и HasInternetService
tmp = data.groupby("HasInternetService", as_index=False).agg({"Churn": ["sum", "count"]}) tmp["Churn (%)"] = 100 * tmp["Churn", "sum"] / tmp["Churn", "count"] tmp.sort_values("Churn (%)").reset_index(drop=True)
HasInternetService | Churn | Churn (%) | ||
|---|---|---|---|---|
sum | count | |||
0 | No | 82 | 1141 | 7.186678 |
1 | DSL | 342 | 1800 | 19.000000 |
2 | Fiber optic | 960 | 2341 | 41.008116 |
Люди с Fiber optic чаще недовольны услугами провайдера, чем остальные
Между Churn и СlientPeriod
sns.catplot(data=data, x="ClientPeriod", hue="Churn", kind="count", height=8, aspect=20/8) plt.xticks(rotation=45);

Видно, что новые пользователи часто уходят после первого месяца пользования, а постоянные клиенты остаются верны привычкам.
Преобразуем категориальные признаки в тип int согласно наблюдениям. Т.е. значения «No internet service» и «No phone service» получают 0, так же, как и «No». Значения в «PaymentMethod» и «HadContractPhone» будут пронумерованы в соответствии с их корреляцией с Chern. Двоичным значениям будут присвоены 0 и 1.
patterns = { "No": 0, "No internet service": 0, "No phone service": 0, "Yes": 1, "Male": 0, "Female": 1, "DSL": 1, "Fiber optic": 2, "Month-to-month": 0, "One year": 1, "Two year": 2, "Credit card (automatic)": 0, "Bank transfer (automatic)": 1, "Mailed check": 2, "Electronic check": 3, } X_train = data.replace(patterns).drop(target, axis=1) y_train = data[target] X_test = X_test.replace(patterns)
Теперь мы можем построить тепловую корреляционную матрицу
sns.heatmap(data=pd.concat([X_train, y_train], axis=1).corr(), annot=True, cmap="coolwarm", center=0, ax=plt.subplots(figsize=(15,10))[1]);

Наконец, давайте визуализируем данные после уменьшения их размерности с помощью PCA.
pca = PCA(n_components=2) pca.fit(X_train_std) x0, x1 = pca.components_ sns.set(font_scale=1.5) y = data["Churn"].map({0: False, 1: True}) fig = sns.pairplot(data=pd.concat([pd.DataFrame(data=X_train_std @ np.stack([x0, x1]).T, columns=["PC1", "PC2"]), y], axis=1), x_vars="PC1", y_vars="PC2", hue="Churn", markers=('^', 's'), palette=["blue", "red"], plot_kws={'s': 100, 'alpha': 0.5}, height=6) fig.set(title="Customer churn visialization (PCA)") fig.axes[0][0].axhline(y=0, color='black', lw=3, alpha=0.1) fig.axes[0][0].axvline(x=0, color='black', lw=3, alpha=0.1);
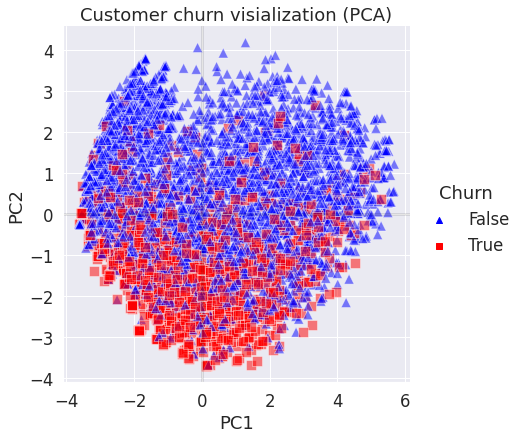
Мы видим, что возможно грубо разделить классы прямой линией. Так что старая добрая логистическая регрессия, вероятно, подойдет. Давайте проверим его и сравним результаты с другими алгоритмами.
Обучение моделей
Логистическая регрессия
Для того чтобы какая-либо модель давала наилучший результат, необходимо правильно подобрать параметры модели. Обычно для этого используют GridSearchCV, который автоматически перебирает варианты параметров в некотором диапазоне.
PARAMS = { "model__C": np.arange(0.001, 100, 0.001)#ставим диапазон от 0.001 до 100 с шагом 0.001 } clf = Pipeline(steps=[ ("scaler", StandardScaler()), ("model", LogisticRegression(penalty="l1", solver="saga", max_iter=1000, random_state=42)), ]) grid_search = GridSearchCV( estimator=clf, param_grid=PARAMS, scoring="roc_auc", n_jobs=-1, cv=10, refit=True, ) logreg = grid_search.fit(X_train, y_train)
Затем мы можем посмотреть лучшие параметры для данной модели и использовать их в дальнейшем
print(f"best score: {logreg.best_score_}") print(f"best params: {logreg.best_params_}")
best score: 0.8451031617037706
best params: {'model__C': 1.734}
Неплохой результат для прямой линии :) , давайте же посмотрим, что нам ответит Kaggle!

Мдаааа, для этого соревнования явно недостаточно, давайте попробуем другие модели.
KNN
KNN - это метод классификации, который основан на принципе поиска ближайших соседей, его часто применяют в различных задачах машинного обучения. Посмотрим, как он справится с задачей.
numeric_transformer = Pipeline(steps=[ ("scaler", StandardScaler()) ]) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, num_cols),#делим на числовые ("cat", OneHotEncoder(handle_unknown='ignore'), cat_cols)#и категориальные, которые преобразуем в числовые через OneHotEncoder ] ) PARAMS = {#параметры для grid search "model__n_neighbors": range(1, 100), "model__metric": ["cityblock", "cosine", "euclidean", "l1", "l2", "manhattan", "nan_euclidean"], } clf = Pipeline(steps=[ ("preproc", preprocessor),#наши разделенные данные ("model", KNeighborsClassifier()), ]) grid_search = GridSearchCV( estimator=clf, param_grid=PARAMS, scoring="roc_auc", n_jobs=-1, cv=10, refit=True, ) knn = grid_search.fit(X_train, y_train)
и смотрим на лучшие
print(f"best score: {knn.best_score_}") print(f"best params: {knn.best_params_}")
best score: 0.8347721646087625
best params: {'model__metric': 'manhattan', 'model__n_neighbors': 44}
Результат похуже, чем у логистической регрессии, посмотрим, что скажет Kaggle

Да, себя мы не превзошли, но ничего, модель может нам пригодиться при использовании Stacking в будущем.
Random Forest
Случайный лес уже представляет из себя серьезный алгоритм машинного обучения, при котором множество деревьев решений строятся на разных частях данных и их прогнозы объединяются в один окончательный прогноз.
PARAMS = { "min_samples_split": range(2, 200), "min_samples_leaf": range(1, 200), } clf = RandomForestClassifier(n_estimators=200, random_state=42) grid_search = GridSearchCV(clf, PARAMS, scoring="roc_auc", cv=5) rf = grid_search.fit(X_train, y_train);
Код получился совсем небольшой, по традиции смотрим на лучшие параметры
print(f"Best score: {rf.best_score_}") print(f"Best params: {rf.best_params_}")
Best score: 0.8433171488881694
Best params: {'min_samples_leaf': 18, 'min_samples_split': 9}
Странно, на трейновых данных мы логистическую регрессию не превзошли

А вот на Kaggle результат стал гораздо лучше! Мы даже преодолели порог 0.85!
CatBoost
Самой сильной моделью на сегодня будет модель градиентного бустинга catboost. Модели градиентного бустинга всегда можно встретить на соревнованиях, зачастую все именно ими и ограничивается. Однако чтобы catboost показывал отличный результат, необходимо потратить тучу времени на подбор его гиперпараметров (поскольку обучаться catboost будет уже гораздо дольше остальных моделей). У модели для этого есть свой отдельный метод grid_search.
catboost = CatBoostClassifier( cat_features=cat_cols, logging_level="Silent", eval_metric="AUC:hints=skip_train~false", grow_policy="Lossguide", metric_period=1000, random_seed=0, ) PARAMS = { "n_estimators": [5, 10, 20, 30, 40, 50, 70, 100, 150, 200, 250, 300, 500, 1000], "learning_rate": [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.02, 0.04, 0.05, 0.1, 0.2, 0.3, 0.5], "max_depth": np.arange(4, 20, 1), "l2_leaf_reg": np.arange(0.1, 1, 0.05), "subsample": [3, 5, 7, 10], "random_strength": [1, 2, 5, 10, 20, 50, 100], "min_data_in_leaf": np.arange(10, 1001, 10), } catboost.grid_search(PARAMS, X_train, y_train, cv=5, plot=True, refit=True)
И также смотрим на лучшие из них
print("Best score:", end=' ') pprint(catboost.best_score_) best_params = catboost.get_params() for f in ("cat_features", "logging_level", "eval_metric"): best_params.pop(f) print("Best params:", end=' ') pprint(best_params)
Best score: {'learn': {'AUC': 0.8542032782485164, 'Logloss': 0.39144271235447}}
Best params: {'depth': 4, 'grow_policy': 'Lossguide', 'iterations': 250, 'l2_leaf_reg': 10, 'learning_rate': 0.05, 'metric_period': 1000, 'min_data_in_leaf': 100, 'random_seed': 0, 'random_strength': 5, 'subsample': 0.6}
Результат даже лучше, чем у Random Forest! Посмотрим что скажет Kaggle

Stacking
Как говорил Павел Плесков (гранд мастер Kaggle) если вы научитесь пользоваться стейкингом, будете выигрывать любые соревнования. Суть метода заключается в том, что мы объединяем результаты работы нескольких моделей вместе, улучшая наш общий результат.
meta = CatBoostClassifier( logging_level='Silent', eval_metric="AUC:hints=skip_train~false", metric_period=1000, random_seed=0, grow_policy="Depthwise", l2_leaf_reg=1, learning_rate=0.08, max_depth=10, min_data_in_leaf=10, n_estimators=10, random_strength=11, subsample=0.1, ) stacking = StackingClassifier( estimators=[ ("logreg", logreg), ("knn", knn), ("rf", rf), ("catboost", catboost), ], final_estimator=meta, n_jobs=-1, ) stacking.fit(X_train, y_train)
Ну и, наконец, финальный результат. Барабанная дробь...

Супер! Отличный результат! Лидерборд доступен по ссылке.

