Хватит неправильно использовать выпадающие списки
4 мин
Перевод
Формы состоят из самых разных элементов интерфейса. Если вы не знаете, как правильно с ними обращаться, вы можете сильно усложнить заполнение форм. Чаще всего ошибаются, применяя выпадающие списки (select menu).
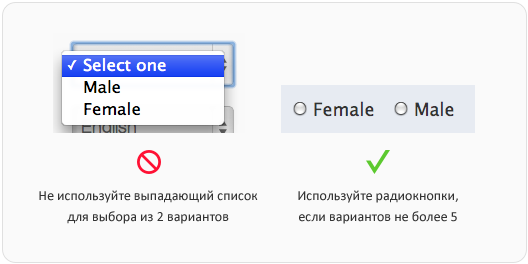
Иногда можно встретить выпадающие списки с 2 вариантами, иногда — с более чем 20. В обоих случаях это неправильно. Если у пользователя есть менее 5 вариантов выбора, следует использовать радиокнопки. Так выбор будет проще и быстрее, потому что пользователю нужно лишь взглянуть на варианты и один раз кликнуть. С выпадающим списком ему нужно нажать на него, найти подходящий вариант и кликнуть снова. Также другие варианты не видны, пока вы не нажмёте на выпадающий список. Если их меньше 5, лучше наглядно показать их в форме в виде радиокнопок — пользователи смогут быстро их просмотреть.
Когда использовать
Иногда можно встретить выпадающие списки с 2 вариантами, иногда — с более чем 20. В обоих случаях это неправильно. Если у пользователя есть менее 5 вариантов выбора, следует использовать радиокнопки. Так выбор будет проще и быстрее, потому что пользователю нужно лишь взглянуть на варианты и один раз кликнуть. С выпадающим списком ему нужно нажать на него, найти подходящий вариант и кликнуть снова. Также другие варианты не видны, пока вы не нажмёте на выпадающий список. Если их меньше 5, лучше наглядно показать их в форме в виде радиокнопок — пользователи смогут быстро их просмотреть.



 От переводчика: Это третья статья из
От переводчика: Это третья статья из  От переводчика: Это первая статья из
От переводчика: Это первая статья из  Существуют разные способы «монетизировать» проект. Но у них есть одна общая составляющая ― то, как деньги переходят из кошелька пользователя на счет организации. Сегодня мы расскажем о том, как организован прием платежей в Badoo и что можно встретить на рынке платежных шлюзов. Сразу предупреждаем, что в статье вы не найдете конкретных цифр по обороту средств компании, но все остальное будет не менее интересно.
Существуют разные способы «монетизировать» проект. Но у них есть одна общая составляющая ― то, как деньги переходят из кошелька пользователя на счет организации. Сегодня мы расскажем о том, как организован прием платежей в Badoo и что можно встретить на рынке платежных шлюзов. Сразу предупреждаем, что в статье вы не найдете конкретных цифр по обороту средств компании, но все остальное будет не менее интересно.