

Недавно закончилось соревнование по машинному обучению Dstl Satellite Imagery Feature Detection в котором приняло участие аж трое сотрудников Avito. Я хочу поделиться опытом участия от своего лица и рассказать о решении.
Описание задачи
Задача заключалась в разработке алгоритма сегментации объектов на спутниковых снимках.
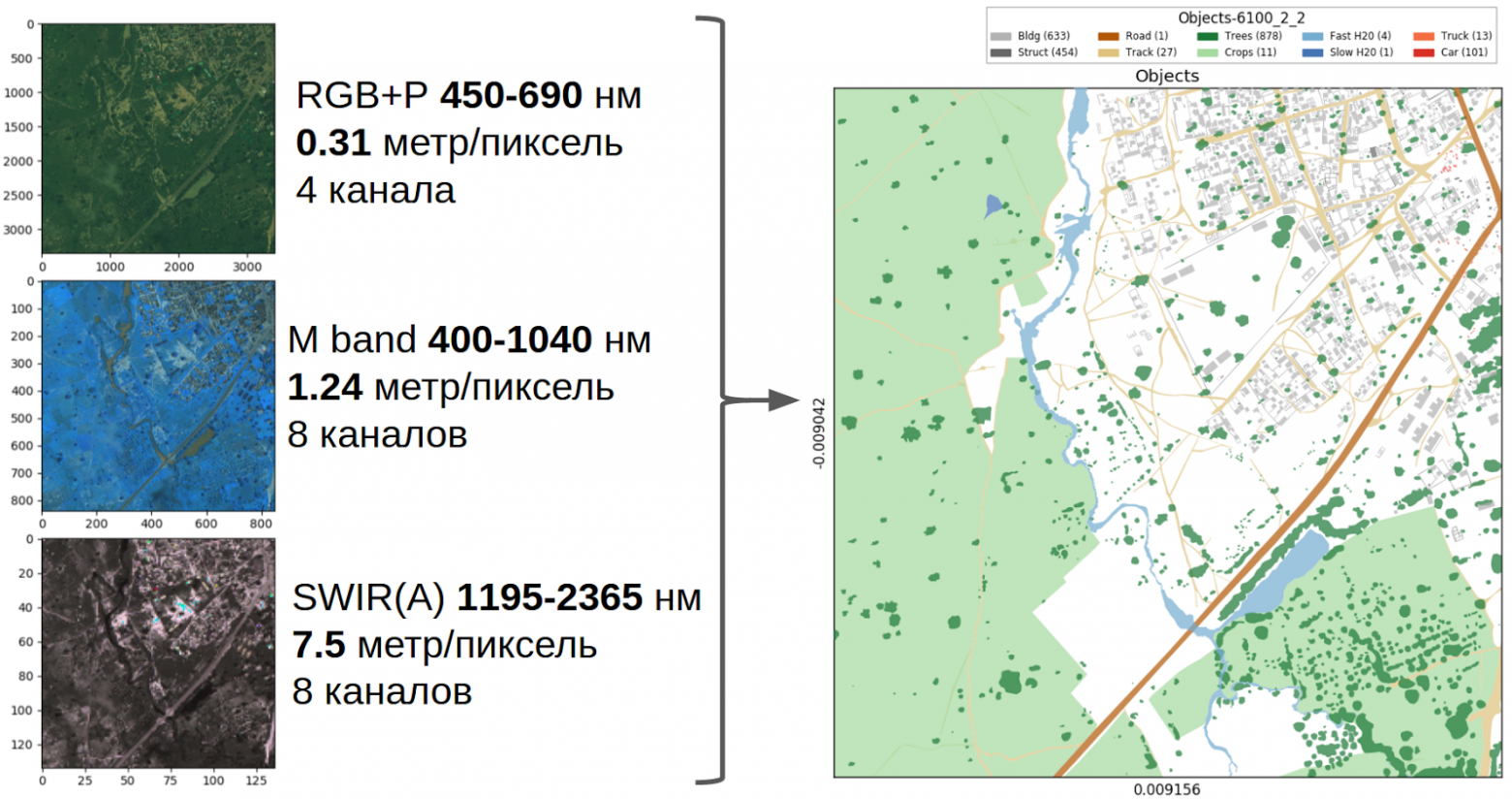
Даны мультиспектральные снимки, сделанные в разных диапазонах длин волн. Снимки также отличаются разрешением и из-за особенностей съемки некоторые каналы немного смещены относительно друг друга.
Предсказывать нужно объекты 10 классов:
Class 1: Строения (просто строения, ничего примечательного)
Class 2: Структуры (заборы, которые даже на самых больших снимках имеют ширину в несколько пикселей)
Class 3: Дороги (асфальтовые дороги и шоссе)
Class 4: Грунтовые дороги
Class 5: Деревья (могут расти как одиночно, так и группами)
Class 6: Поля (отличаются тем, что на них что-то выращивают)
Class 7: Быстрая вода (реки, фрагменты моря, крупные водоемы)
Class 8: Медленная вода (озера, пересыхающие реки)
Class 9: Большой транспорт (грузовики, автобусы)
Class 10: Небольшой транспорт (автомобили и мотоциклы).
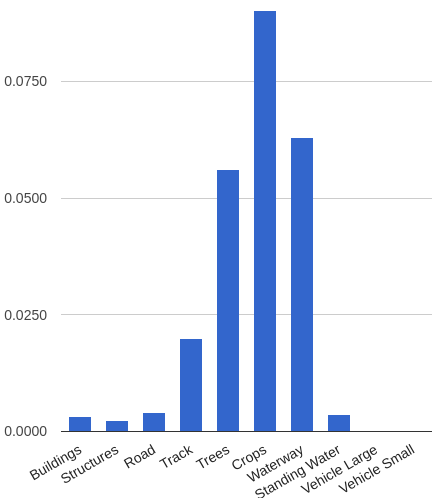
Метрика — усредненный по всем классам индекс Джаккарда (Average Jaccard Index), который определяется как отношение площади пересечения к площади объединения. В данном случае пересечение и объединение относятся к маскам классов. При этом каждый класс вносил одинаковый вклад в общую метрику, но площади каждого класса сильно отличались. На гистограмме показана доля площади каждого класса относительно всей площади. Для класса 6 (поля) доля площади составляла 0.6, а для двух последних классов 0.0001.
Отдельно стоит отметить количество данных. Нам были выданы 25 размеченных областей. В то время как в тесте их было 425. Из них public leaderboard строился по 19%, а private по оставшимся 81%. Как водится public служил по сути для того, чтобы проверить свое решение и сравнить результат с другими участниками. А финальный рейтинг составлялся только по private части. Однако мне было очевидно, что раз в public’e 81 снимок, то эта проверка куда надежней, чем любая моя локальная валидация по 25 снимкам, и если я получал расхождение между метрикой на локальной проверке и лидербордом, то доверял лидерборду. Как же я ошибался… Но об этом ближе к концу.
Лирическое отступление
В конкурсе было довольно мало участников и я прекрасно понимаю почему, ведь я сам долгое время не мог решиться на участие, потому что в организации была масса проблем. Во-первых, орги выдали маски не в виде картинок, а в виде полигонов в csv файле и нужно было самому сконвертить их в нужный размер. Во-вторых, каждый раз предсказывать 425 картинок теста — это долго. В-третьих, нужно было отправлять организаторам не маски в виде пикселей, как это обычно выдает алгоритм, а такой же csv-файл с полигонами, как из обучающей выборки. И каждая стадия влияет на конечную метрику, а раз речь идет о конкурсе, то придется вылизывать каждую процедуру. Но я все-таки решился по трем причинам:
- коллега по работе Дмитрий Цыбулевский уже участвовал и рассказывал, что конкурс интересный, позволяет попробовать много трюков и поэкспериментировать с архитектурой нейросетей (ну и даже решать проблемы с конвертацией масок это интереснее, чем просто обучать xgboost поверх обфусцированных фичей);
- также Владимир Игловиков в ODS Slack’e агрессивно агитировал участвовать и аргументировал это тем, что тут будет борьба за что-то осмысленное, а не за 4-й знак после запятой в метрике (как же он ошибался...);
- ну и в итоге окончательное решение я принял, когда Константин Лопухин выложил скрипт, который решал последнюю проблему с конвертацией масок в полигоны.
Baseline
Прежде чем кидаться клонировать репозитории со State of the Art решениями по сегментации, я решил сделать простое решение, которое мог бы непрерывно улучшать. На мой взгляд, это хорошая практика не только для почти любого конкурса, но и вообще для любой задачи по машинному обучению.
Соответственно, я выбрал скрипты, выложенные на форуме, и собрал из них следующий пайплайн:
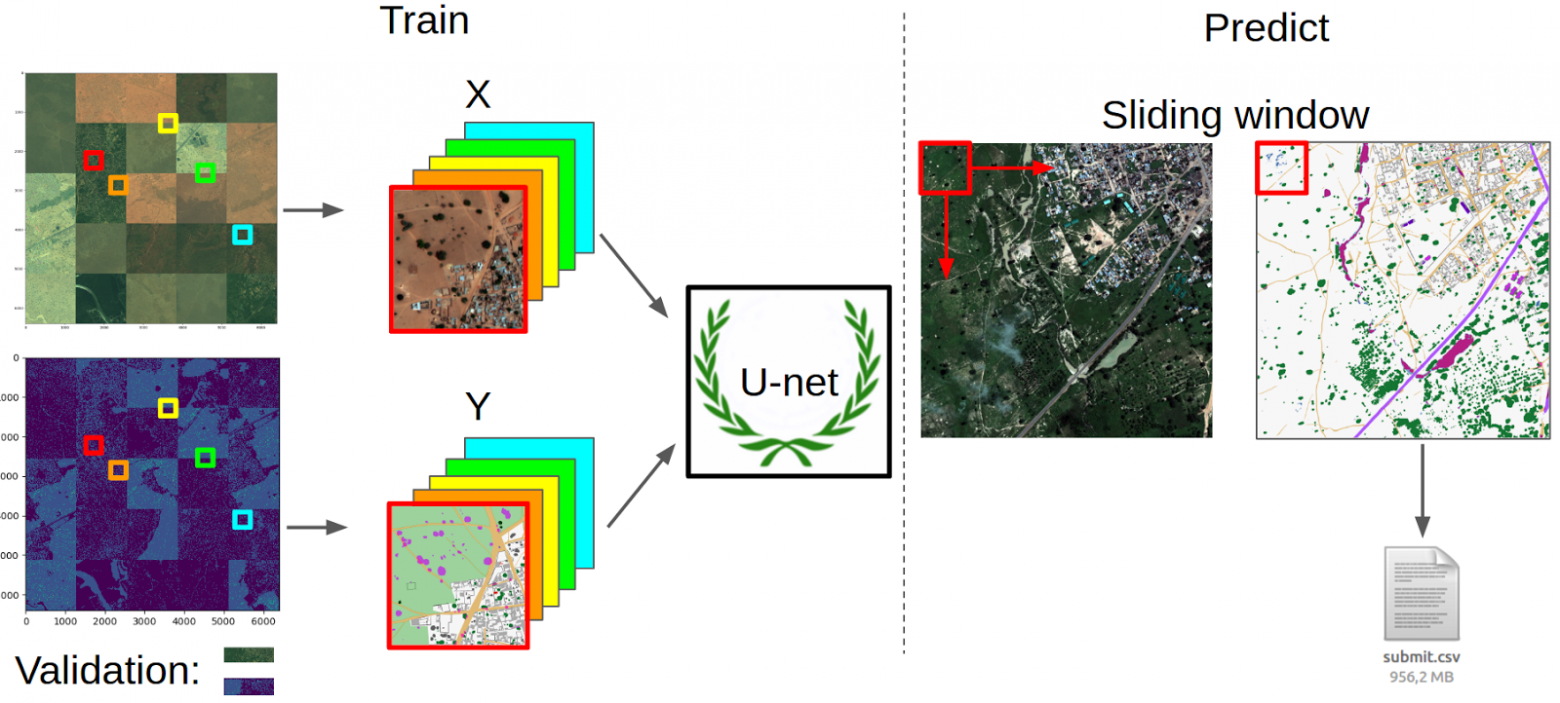
Предпроцессинг и подготовка данных
Я взял все изображения из M-бэнда, отмасштабировал их к одному размеру для удобства (при этом рейсайз был не больше 1%) и собрал из них большую мозаику 5х5. Тоже самое сделал с масками. Затем из одинаковых для изображения и маски рандомных мест я вырезал кропы размером под вход и выход сети (128 х 128 пикселей), формируя тем самым очередь для обучения. Однако брались не все сэмплы, а только те, у которых доля площади маски класса от общей площади была выше порога. Пороги я подобрал для каждого класса руками так, чтобы сэмплирование происходило более-менее равномерно. Затем изображения в каждой очереди приводились к диапазону (-1, 1). Также для валидации я вырезал небольшую полоску из картинки, в которой содержались все классы и заменил ее копией соседнего куска картинки в трейне.
Обучение нейросети
В качестве нейросети я выбрал U-net. Эта нейросеть по структуре похожая на обычный энкодер-декодер, но с пробросами фичей из энкодер-части в декодер на соответствующих по размеру стадиях.
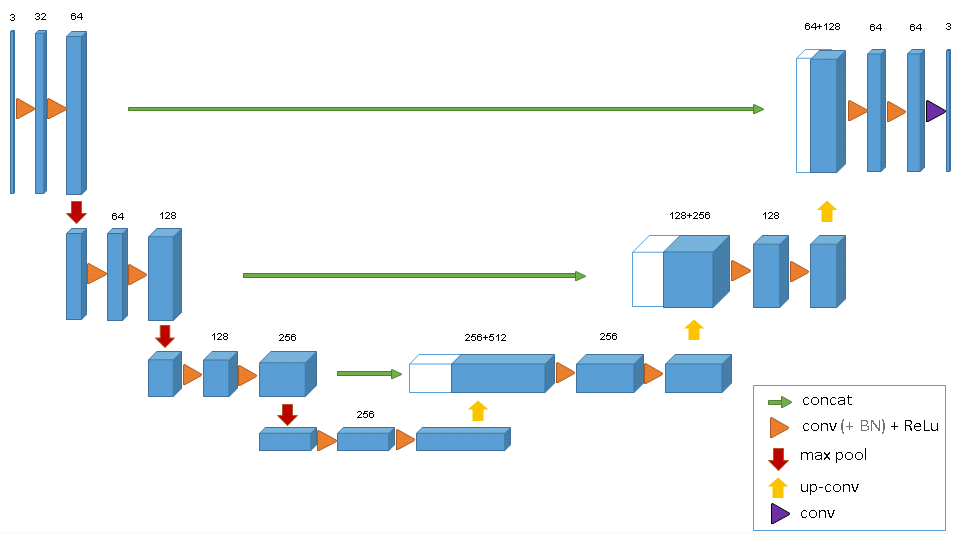
U-net себя хорошо показал в другом конкурсе на кэггле с сегментацией нервов. К тому же я нашел код с ней для Keras’a. В качестве функции потерь использовалось приближение целевой метрики. Оптимайзер был взят Adam, потому что как правило у меня получались с ним неплохие результаты в задачах, когда непонятно, по какому критерию уменьшать Learning rate.
Предсказания
Чтобы предсказать маску, я использовал обычное скользящее окно. Т.е. каждая картинка из теста нарезается на патчи, они предсказываются и затем собираются обратно. По построению нейросеть выдает вероятности того, что в конкретном пикселе находится каждый класс. Соответственно, чтобы получить бинарную маску, нужно подобрать порог, что я сделал исходя из максимальной метрики на локальной валидации. Предсказав маски, я воспользовался скриптом Кости и получил свой сабмит.
В итоге кэггл его даже принял. Я решил, что это успех и побежал оформлять свой код в виде kernel. На тот момент никто не выложил полный pipeline от начала и до конца, поэтому скрипт был принят очень позитивно. И потом в течение нескольких дней я видел, как на лидерборде появляются новые люди с примерно моим скором. Ну и кернел набрал больше всех голосов и комментов в этом соревновании.

Однако радость моя был недолгой. У меня был объективно низкий скор, и я не мог понять причину. Ее нашел Расим Ахунзянов. Я зачем-то после того, как приводил все изображения к диапазону (0, 1), переводил float’ы в int’ы. Этот факт отметили в комментариях к скрипту и с того момента любой желающий мог получить работающую версию скрипта.
Однако я не стал исправлять баг в коде. Во-первых это поучительно — читать хотя бы комментарии, а еще лучше разбираться в коде, а не запускать бездумно полотно на 4 страницы. Во-вторых, даже с багом код прекрасно выполнял свою функцию, а именно: привлечение новых участников. В-третьих, даже с багом он все еще вписывался в концепцию простого решения, которое можно непрерывно улучшать.
Примером успешного использования скрипта является результат Миши Каменщикова. В Avito он занимается рекомендациями и я решил подсадить его на DL, продав ему этот конкурс. Миша исправил баги, за выходные обучил свою модель с небольшими доработками и воспользовался другим публичным скриптом для воды. Это позволило ему финишировать на 46 месте и получить первую серебряную медаль.
Мое решение
Вообще говоря, мое решение не сильно отличалось от Baseline в плане общего похода, однако я внес ряд существенных улучшений.
- Conv + ReLu → Conv + BN + ReLu.
В ванильном U-net не использовался слой батч нормализации. Я его добавил. И так делали почти все участники. У всех он улучшал сходимость.
- Аугментации: поворот на произвольный угол, вертикальный и горизонтальный флип. Очевидная вещь, без которой сейчас не обходится обучений картиночных нейросетей.
- Hard Negative mining.
Тут стоит остановиться поподробнее. Я отказался от сэмплирования патчей с долей маски класса выше порога и решил брать все сэмплы. Но после обучения нейросети на наборе сэмплов, я предсказывал маски на нем. И для каждого класса выбирал топ 100 сэмплов, где присутствует маска класса и где метрика наихудшая. И затем добавлял эти сэмплы в следующую итерацию. Тем самым я убивал двух зайцев: Теперь в каждой эпохе были сэмплы каждого класса и в каждой эпохе были «сложные» сэмплы. Я не проводил прямого сравнения, но по ощущениям сеть сходилась намного быстрее.
С такими улучшениями я обучил еще две сети, которые вошли в финальный ансамбль. Но лучшая, на мой взгляд, находка состояла в сети с тремя входами:
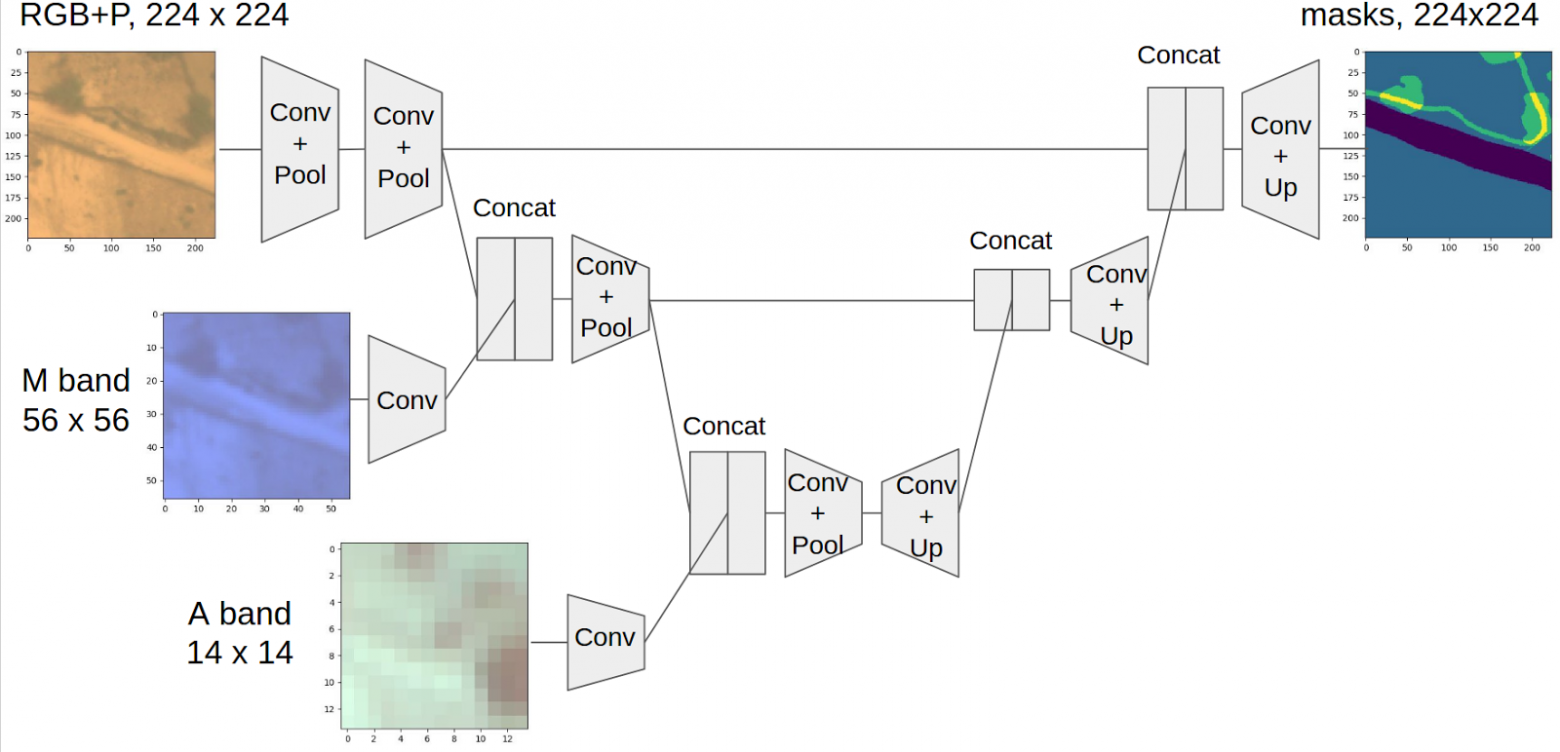
Эта концепция родилась в процессе обсуждения с Дмитрием Цыбулевским. Проблема с картинками в этом конкурсе в том, что разные каналы имеют сильно разное разрешение и если хочется использовать всю информацию, то нужно приводить все к одному размеру. Но если уменьшать, то теряется разрешение и такие классы как рукотворные структуры вовсе исчезнут. Ну а если приводить все к самому большому размеру, то нужно увеличивать, скажем, А-бэнд в 20 раз, что выглядит крайне неразумно. С другой стороны изображение при прохождении через нейросеть после каждого слоя с пуллингом становится эффективно меньшего размера.
Соответственно, родилась идея добавлять новые картинки по мере уменьшения размера основного бранча энкодер-части U-net. Для этого на первый выход подавались RGB и P-бэнды в размере 224х224, после двух пуллингов к основному бранчу конкатинировался вход с М-бэндом и затем еще через два пуллинга А-бэнд. При этом, на всех бэндах была одинаковая физическая область. Для этого все-таки пришлось в 1.5 раза увеличить самый маленький канал, но это приемлемо. Каждый канал конкатинировался после слоя свертки. Это было сделано, чтобы не конкатенировать представление сетки и сырые картинки как фичи разной природы. В этом плане я получил справедливую критику, что этого все равно не достаточно, ведь картинка в основном бранче прошла куда больше слоев сверток, чем картинка с второго и тем более третьего входа. И, скорее всего, это правда, и архитектура с большим числов сверток для каждого последующего входа будет работать лучше, но я не занимался такого рода оптимизацией гиперпараметров. Полная схема
Особенности обучения
Как правило, процесс обучения глубоких сверточных нейросетей для распознавания изображения довольно понятная вещь. Особенно после того как были разработаны и выложены веса State of the Art архитектуры с Imagenet. Однако в этой задаче не выходило просто взять и обучить нейросеть так, чтобы она гладенько залетела в глобальный минимум. Во-первых, долгое время в ODS Slack’e никто не мог предложить надежную схему локальной валидации, которая бы давала однозначное соответствие с лидербордом и в конце мы узнали почему. Во-вторых, сеть довольно сильно шатало от эпохи к эпохе и порой соседние эпохи для одной архитектуры по качеству предсказаний отличались сильнее, чем предсказания другой нейросети.
Если построить лог обучения на локальной валидации, то он выглядит так:
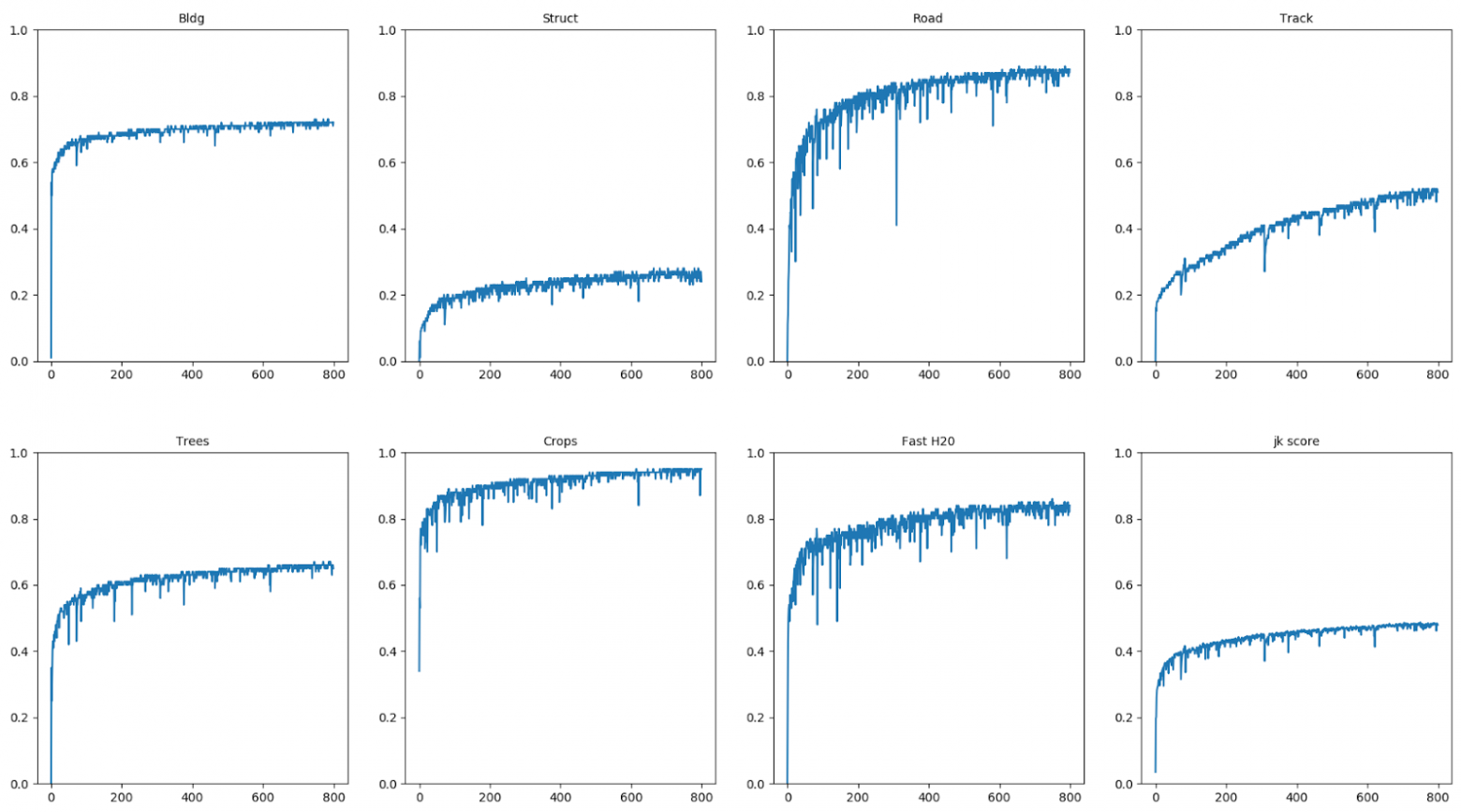
На графиках джаккард для первых 7 классов и справа снизу средняя метрика по всем классам. Видно, что разные классы обучаются за разное количество итераций даже с выравниванием сэмплов, поскольку все равно площади одних классов больше других. Также видны провалы и шатание. Мне интересно было узнать, что же происходит с предсказаниями, и я для каждой эпохи визуализировал их для валидации. Из этих предсказаний Роман Соловьев собрал прекрасный ролик:
В ролике показано как меняются предсказания каждого класса от эпохи к эпохе. Цветами отмечено: синий — маска класса (False Negative), зеленое — неправильные предсказания (False Positive), голубое — правильные предсказания (пересечение маски и предсказаний) (True Positive). Мне лично очень нравятся моменты, когда сеть сначала предсказывает что-то нерелевантное, а потом уточняет свои предсказания, как, например, с классами быстрой воды и шоссейных дорог. Также на всех классах видно шатание в предсказаниях. Еще можно заметить артефакты, связанные с тем, что вся маска предсказывается скользящим окном. Ну и главный вывод, который я для себя сделал, — визуальный анализ результатов решает.
Поэтому я сделал такую штуку.

Это мозаика из полосок изображений из теста, которые мне показались сложными по той или иной причине. Я потратил целый вечер, чтобы поаутировать в картинки теста и предсказания, поэтому такие цвета. Например, самая левая часть содержит дома и карьер, который часто давал ложные срабатывания на дома и воду. Затем идет кусок моря с водой такого оттенка, которого не было в обучающей выборки. Дальше идет кусок большой реки с рябью на воде, соответственно таких больших рек и ряби тоже не было. Также я выбрал сложные участки шоссе, которые плохо определялись.
И дальше я на каждой эпохе помимо трейн пула (для сложных примеров) и валидации предсказывал еще этот кусок теста. Далее я выбирал лучшие эпохи визуально, а затем проверял их на лидерборде и если они давали профит, то усреднял их предсказания, чтобы стабилизировать решение. Трюк с усреднением тоже давал прирост, но проверить много эпох таким образом мне не удалось.
Финальный пайплайн до объединения с Романом выглядит так:
Но затем мне написал Роман и предложил объединиться. Мне показалось, что это крайне разумно, ведь мы оба использовали Keras с Theano в качестве бэкэнда и прямое объединение наших результатов с лучшими классами давал топ2 результат даже без усреднения или объединения предсказаний по отдельным классам. Про свое решение, я надеюсь, Роман напишет отдельный пост.
Послесловие
Про данные. Каково же было мое удивление и удивление всех участников ODS Slack’a, когда уже после окончания конкурса орги сообщили, что на самом деле они разметили только 32 снимка из теста. Остальные были просто фейком. Ну и соответственно public это 6 снимков, а private 26. Именно из-за этого можно считать, что конкурс имел в какой-то степени характер лотереи. Ну и это также объясняет, частые расхождения локальной валидации и паблика, ведь часто они были сопоставимы по размеру.
Про организаторов. По описанию конкурс должен был закончиться 7го марта в 3 ночи по Москве. Этого момента лично я ждал намного больше, чем любого нового года. И вы можете представить уровень пригара участников ODS Slack'a, когда результаты не опубликовали, а на форуме появилось сообщение, что мы все молодцы и результаты будут через неделю. Мол, связано с тем, что заказчики готовят пресс-релиз. Через неделю появился пресс-релиз в котором сообщалось, что данные уже анализируются (ага, конечно, ведь решение никто еще не отправил). И еще Dstl так понравился формат соревнований, что они решили запилить свой кэггл с беспилотниками и topic modelling. На этой площадке уже запущены два конкурса, но не спешите натирать радиаторы видеокарт и импортировать xgboost'ы. На призы в этом конкурсе могут претендовать только граждане стран, у которых индекс коррупции выше 37 (Transparency International's Corruption Perceptions Index 2014). Соответственно, граждане Замбии и Буркина-Фасо могут участвовать, а россияне — нет. У любых соревнований есть своя изюминка, и, похоже, Dstl её нашли — это пригар.
Про общий опыт участия. Несмотря на то, что я убил кучу времени на этот конкурс, он мне определенно понравился и я получил массу профита даже без приза. Это и опыт работы с сегментацией изображения, куча трюков для обучения нейросетей, не стоит также забывать про новые знакомства с людьми, которые также увлекаются участием в конкурсах. Компания Avito в скором времени проведёт свой конкурс, который будет посвящен рекомендательным системам. Призываю всех принять участие в нем!
Запись с тренировки:
Презентация доклада здесь.
UPD:
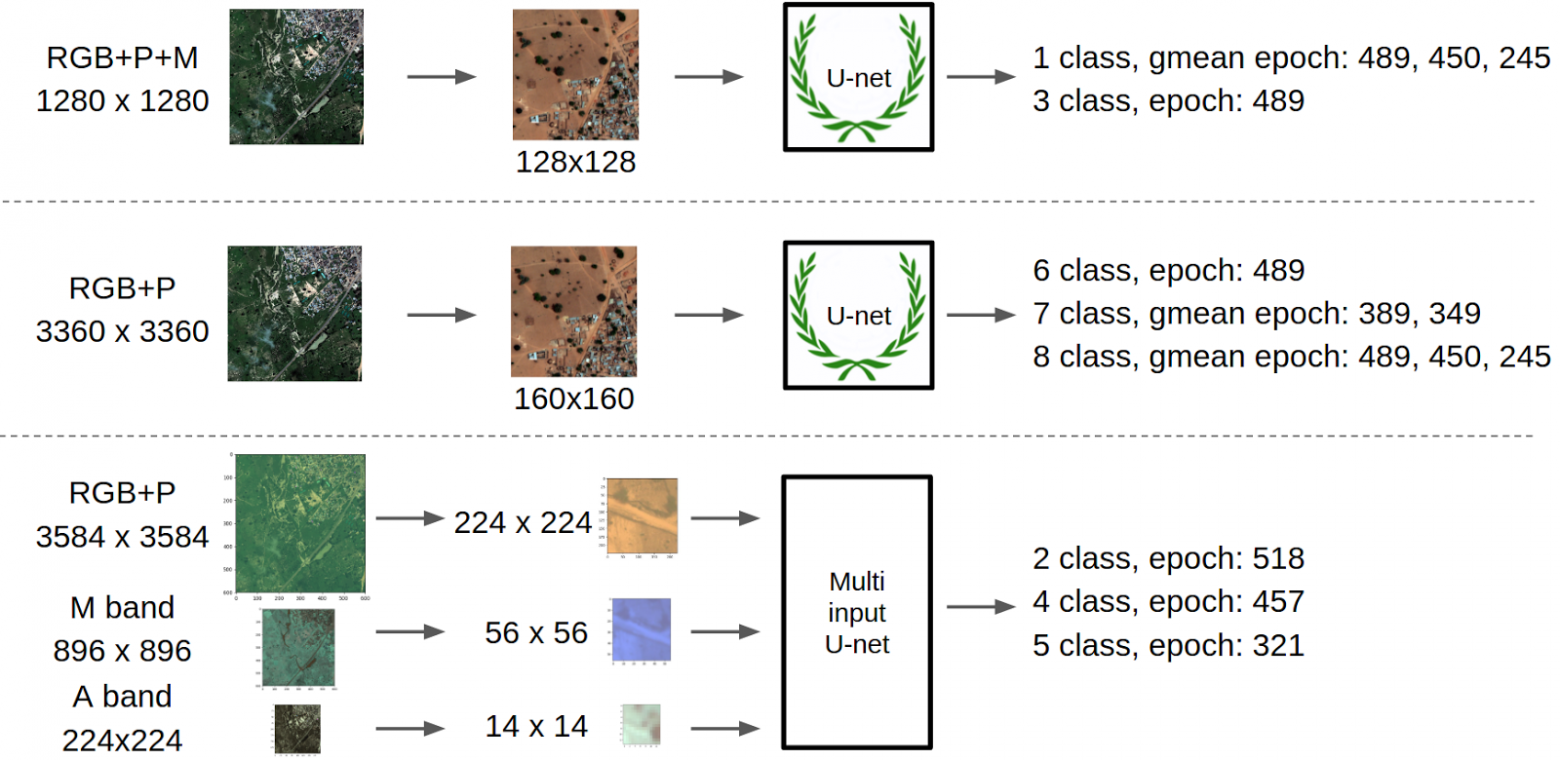
В ожидании поста от Романа, решил сделать картинку с нашим общим пайплайном:

UPD2:
Пост Владимира о том же соревновании

{kind=link}