
Привет, Хабр!
Неделю назад вышла статья, в которой я начал разговор о том, как подготовить e-commerce проект к взрывному росту трафика и прочим прелестям масштабных акций.
С ключевыми техническими деталями мы разобрались, теперь уделим внимание административным вопросам и оптимизации процессов поддержки на время пиковых нагрузок:
- что делает сайт нестабильным и почему облако — не панацея;
- какие бизнес-параметры необходимо отслеживать, чтобы обнаружить проблему до того, как она принесет существенные убытки;
- как без хаоса маршрутизировать инцидент от события до решения и локализовать сбой.
И многое другое — прошу всех под кат!
По моему опыту, самая большая головная боль при подготовке к масштабным акциям — это сильный административный прессинг. У бизнеса, до того весьма спокойного, внезапно появляется желание, чтобы все были на стреме, сдували с сайта пылинки и прочее «не дай Бог что случится — оштрафуем». Давайте попробуем удовлетворить это в целом здравое желание. Говорить об этом будем на примере Черной Пятницы, так как это наиболее яркий пример резкого роста нагрузки на сайт.
А начнем мы с основополагающего вопроса: что именно является причиной нестабильной работы нашего сайта?
Что делает сайт нестабильным

Пришла пора заняться тем, что вы давно и регулярно откладываете. Чтобы понять, какие факторы делают сайт менее стабильным, поднимите и проанализируйте историю проблем. Только не говорите, что у вас её нет.
В вашем топе будут плюс-минус следующие причины:
- Аварии, связанные с релизами.
- Накосячили админы — чинили одно, а сломалось другое. К сожалению, такие накладки часто скрываются и не попадают в историю.
- Напортачил бизнес — криво запустили акцию, что-то удалили и т.п.
- Сломались партнерские сервисы.
- «Загрустил» софт. Чаще всего такое случается из-за пп. 1 и 2.
- Физические поломки.
- Прочие проблемы.
Конечно же, все ситуации разные, и «рейтинг» у вас может получиться немного другим. Но лидировать всё равно будут проблемы, связанные с изменениями на сайте и человеческим фактором, а также плоды их совместной любви — релизы или попытки что-то оптимизировать.
Искоренять эти проблемы так, чтобы с первой попытки вносить необходимые изменения и не ломать то, что нормально работает, — задача, о которую сломано немало копий. А времени у нас и так совсем немного, всего около четырех месяцев. К счастью, локально с этим можно справиться. Для этого нужно соблюдать парочку простых правил:
1. Работает — не трогай.
Завершить все плановые работы как можно раньше — за пару недель, за месяц. Насколько рано нужно завязать с улучшениями, подскажет ваша история инцидентов. По ней видно, как долго тянется основной хвост проблем. После этого не трогайте сайт и инфраструктуру продуктива, пока не пройдёт нагрузка.
2. Если все-таки пришлось залезть в продуктив для срочной починки — тестируйте.
Регулярно, неустанно, даже самые мелкие и незначительные изменения. Сначала в тестовой среде, в том числе под нагрузкой, а уже потом переносите на прод. И опять тестируйте и перепроверяйте ключевые параметры сайта. Работы лучше проводить ночью, когда нагрузка минимальна, ведь у вас должно быть время спасти ситуацию, если что-то пойдет не так. Хорошее тестирование — это целая наука, но даже просто разумное тестирование всё-таки лучше, чем его отсутствие. Главное — не надеяться на «авось».
Заморозка изменений на время высокой нагрузки — единственное надёжное средство.
Что делать с партнерскими сервисами, мы уже обсудили в прошлой статье. Если кратко — при любых проблемах безжалостно отключайте. Чаще всего проблемы возникают сразу у многих пользователей сервиса, и обращение в техподдержку — мера малоэффективная. Ваши письма не помогут им починиться быстрее, в такие часы IT-отделу сервиса и без них жарко.
Однако если о проблеме не сообщить и не получить номер инцидента со временем его заведения, вы, скорее всего, не сможете выставить сервису пени за нарушение SLA.
Немного о надежности

В рамках подготовки нужно поменять всё сбоящее железо и кластеризовать сервисы. Подробнее об этом — в одной из моих предыдущих статей.
Обращу ваше внимание на следующее популярное заблуждение: многим кажется, что перенос сайта со своих серверов в облако сразу же дает +100 к надежности. К сожалению, только +20.
Для повышения отказоустойчивости виртуального сервера коммерческое ��блако просто автоматизирует и ускоряет «замену» упавшего железа до считанных секунд, автоматом переподнимая виртуальную машину на одном из живых серверов. Ключевые слова — «ускоряет» и «упавшего железа». Виртуальная машина все равно при этом будет перезапущена. VMware Fault Tolerance и аналоги, позволяющие спастись от перезагрузки, как правило, не используются в коммерческой виртуализации из-за ресурсоемкости и снижения производительности защищаемых виртуальных машин. Отсюда вывод: коммерческое облако — не панацея для отказоустойчивости, его основные плюсы — гибкость и масштабируемость.
Посмотрите в истории, сколько у вас было простоев для замены или ремонта физического оборудования. После переезда в облако их количество уменьшится, и — да, жить вам станет немного проще. Не придется бежать на склад или в магазин за новым сервером. Но теперь к авариям железа добавятся приколы виртуализации.
Может случиться, что машина стала недоступна, но физический хост все равно отвечает. Облако не увидит эту проблему. Или с точностью до наоборот: хост не отвечает, а с виртуальными машинами всё хорошо. В этом случае виртуализация переподнимет их в другом месте. На запуск уйдет некоторое время, и вы опять получите простой на ровном месте. А под нагрузкой он может оказаться фатальным. Поэтому даже в облаке нужно помнить о резервировании. Кстати, предупредить провайдера виртуализации о том, какие машины резервируют друг друга — отличная идея. Иначе может случиться, что все ваши машинки окажутся на одном физическом сервере и умрут одновременно.
- При проведении нагрузочных тестов имеет смысл запланировать тестирование отказоустойчивости под нагрузкой.
Это когда прямо во время нагрузочного теста вы «роняете» ноду в кластере и смотрите, что при этом происходит. При правильно настроенных кластерах и корректно выделенных ресурсах это не должно негативно сказаться на результатах теста и вызвать ворох ошибок.
Похоже, что со всеми типовыми «барабашками» мы покончили. Перед тем, как читать дальше, я рекомендую вам освежить в памяти технические детали, описанные в предыдущей статье. Ведь если сайт технически не способен выдержать нагрузку, скорость реакции вас уже не спасет.
Теперь подумаем, как подготовиться к необычным или внезапным. Их мы по определению предотвратить не можем, так что остается засучить рукава и научиться чинить их как можно быстрее.
Этапы устранения инцидента

Рассмотрим, из чего складывается время на устранение аварии:
- Скорость обнаружения сбоя — задержка мониторинга, получение письма от пользователя и т.д.
- Время реакции на обнаруженный инцидент — кто-то должен заметить репорт и заняться им.
- Время подтверждения наличия инцидента — а был ли мальчик?
- Время на анализ инцидента и поиск путей устранения.
- Время на устранение инцидента и проблемы. Не всегда получается исправить всё с первого раза, и у этого этапа может быть несколько итераций.
Обычно обнаружением и устранением сбоев занимается служба поддержки. Если команда большая, каждый из перечисленных этапов может выполняться разными людьми. А время, как известно, деньги. В нашем случае — буквально. Черная пятница имеет фиксированную продолжительность, а конкуренты не дремлют – клиенты могут потратить всё у них. Соответственно, критически важно, чтобы каждый сотрудник знал свою зону ответственности и инциденты решались «конвейером».
Давайте рассмотрим каждый этап отдельно, определим проблемные моменты и рассмотрим способы оперативно их оптимизировать.
Все приведенные ниже советы, хинты и рекомендации — это не рецепт «красивой жизни», а конкретные вещи, которые вы успеете внедрить за ближайшие 3-4 месяца, оставшихся до Черной пятницы.
Обнаруживаем аварию
При самом неудачном раскладе о неполадках сообщает вам клиент. То есть проблема настолько серьезна, что он потратил свое время на репорт. При этом только очень преданный клиент напишет или позвонит, а простой юзер уйдет, пожав плечами.
К тому же, зачастую у клиента нет прямого доступа к IT-отделу. Поэтому он либо пишет на какую-нибудь info@business.ru, либо звонит девочкам из колл-центра. Когда информация доползет до IT, пройдет уже куча времени.
Допустим, лояльных клиентов у нас много, и каждый из них считает своим долгом написать в ТП о неполадках. Пока инцидент классифицируют как массовый, пока эскалируют и решат — пройдут часы. При этом единичные обращения могут затеряться, а почта info@business.ru иногда не разгребается неделями.
Поэтому будет очень кстати начать самостоятельное отслеживание основных бизнес-параметров. Как минимум — количества пользователей на сайте, количества совершаемых покупок и их соотношение. Эти данные позволят быстро отреагировать, если что-то пошло не так, и значительно сократят время на выявление (и решение) конкретной проблемы в работе сайта.
Нет пользователей? Надо посмотреть, куда они могли подеваться. Пользователи на сайте есть, а продаж нет? Это сигнал о проблеме, причем довольно-таки поздний. Обнаружить, что где-то случилось что-то, поможет автоматизированное сценарное тестирование. Обычно автотесты гоняют по билдам или релизам, но и для мониторинга они подходят просто замечательно. С их помощью вы сможете увидеть поломку или замедление какого-то важного бизнес-процесса глазами пользователя.
Конечно, если сценарного тестирования у вас нет, за несколько месяцев, оставшихся до Черной пятницы, весь продуктив тестами вы не покроете. Да и нагрузку они могут дать нешуточную. Но с тестами десятка основных процессов вполне можно успеть.
Также очень полезно отслеживать среднее время ответа серверов. Если оно растет, можно ожидать проблем с продажами. Такие данные должны автоматически отслеживаться системой мониторинга.
Как видите, на грамотном мониторинге можно сократить время обнаружения проблемы с часов и дней до нескольких минут, а иногда и увидеть наличие проблемы до того, как она встанет в полный рост.
Время реакции на инцидент

Мы отлично сработа��и и благодаря мониторингу мгновенно обнаружили сбой. Теперь нужно завести инцидент, присвоить приоритет, маршрутизировать и назначить ответственного за дальнейшую обработку.
Здесь важны две вещи:
- Получить уведомление о проблеме в кратчайшие сроки;
- Быть готовыми оперативно обработать уведомление.
Многие айтишники не привыкли быстро реагировать на письма даже при наличии клиента на смартфоне. Так что важные уведомления не стоит слать по email.
Используйте СМС для оповещений об авариях. Еще лучше — внедрите бота-звонильщика для самых критичных случаев. Практических реализаций таких ботов я лично не встречал, но если ресурсы позволяют, почему бы и нет? В крайнем случае, используйте WhatsApp/Viber/Jabber. Увы, Telegram на территории РФ по многим понятным причинам не может быть надежным каналом для экстренных уведомлений.
Также может пригодиться автоматическая эскалация инцидента при отсутствии подтверждения. То есть мониторинг уведомит следующего в очереди, если основной получатель уведомления не отвечает. Эта система подстрахует вас,
Теперь поговорим о том, как обеспечить оперативное реагирование на сообщения о сбое. Во-первых, кто-то должен быть наготове, чтобы отвечать за обработку оповещений. Оповещения на всю команду полезны, но только для поддержания людей в курсе событий.
Коллективная ответственность — штука ненадежная, когда требуется скорость.
Если на время акций не установить дежурство по четкому графику, вы можете столкнуться с тем, что во время форс-мажора кто-то будет спать, а у кого-то не будет доступа из дома. Кто-то вообще окажется в дороге. И по факту, некому заняться проблемой в ближайший час. Конечно, можно поставить круглосуточного оперативного дежурного, но и тут есть нюанс. Хороших спецов вы не заставите постоянно работать в смены, а значит, когда они понадобятся, всё равно придется искать их и будить. А те, кто все-таки в смены работает, наглухо выпадают из общего контекста жизни команды. Это самым фатальным образом сказывается на их эффективности по плановым задачам.
Спасет нас то, что в большинстве проектов оперативно реагировать на сообщения, разбираться, что случилось, и срочно чинить нужно около 18 часов в сутки. Обычно на период с 6-8 часов утра до 1-2 часов ночи следующего дня приходится до 90% трафика и продаж.
Чтобы избежать накладок, достаточно сдвинуть рабочий график для дежурных на форматы типа:
- 6:00-15:00 и 17:00-02:00 — дежурство «из дома»;
- 15:00-17:00 — прикрывают те, кто в офисе;
- 02:00-06:00 — мало трафика. Тем не менее, назначьте не очень крепко спящего ответственного.
Не забудьте про выходные дни. Этот вопрос можно решить таким же образом.
Если у вас дневная активность пользователей распределяется иначе, подберите похожий график, при котором в прайм-тайм сайт не останется без присмотра.
Быть дежурным — значит отвечать за обработку событий мониторинга, звонков из предыдущих линий (клиентской поддержки) и следить за системой в целом. Но пока все тихо, дежурный зан��мается своей основной работой.
Обязательно начните дежурства за несколько дней до начала нагрузки. Во-первых, это позволит лишний раз убедиться, что у всех есть все доступы. Во-вторых, смена рабочего режима — это стресс, многим понадобится «приладиться». И лучше будет, если период привыкания не совпадет с основной жарой.
Отлично, оповещения приходят, причем именно тем людям, которые должны на них реагировать. Но на время реакции дежурных очень влияет наличие лишних и необработанных оповещений, а также уведомлений, которые в принципе не предполагают никаких действий. Очень важно не оставлять необработанных оповещений. Если на регулярной основе происходит много одинаковых событий, расследуйте причину и почините. В системе мониторинга вообще не должно оставаться активных алармов.
По опыту, если что-то нельзя починить быстро или оно не требует ремонта, но все равно «моргает», лучше подавить оповещение и создать задачу на проработку. Постоянно моргающий аларм рано или поздно примелькается и перестанет привлекать внимание. Беда в том, что при возникновении реальной проблемы люди могут и перепутать лампочку, и проигнорировать действительно важное событие.
Еще крайне важна грамотная настройка и приоритизация событий в системе мониторинга. Система должна уведомлять вас именно о том, что надо починить. О конкретных сбоях или риске их возникновения. Вы же не будете чинить 100% CPU Usage? Вы будете устранять высокие задержки на WEB-сервере, потому что CPU Usage — это информация для дебага, а не проблема. Если в Черную пятницу процессор загружается на 100% при целевой нагрузке, скорости отклика и с учетом запасов — это значит, что вы все грамотно рассчитали.
Утилизацию ресурсов системы обязательно нужно контролировать, но это немного другая задача, которая важна для планирования ресурсов и выявления зон влияния аварии.
События мы настроили, теперь важно грамотно приоритизировать то, что мы будем исправлять в первую очередь. Для этого разберемся, в чем различия уровней оповещений Critical и Warning. Приведу немного утрированные, зато понятные примеры.
Critical — это когда вы едете к бабушке на метро, получаете оповещение и сходите на ближайшей станции. Достаете ноут, садитесь на скамеечку и начинаете работать — произошла остановка продаж или появились сильные потери. То есть Critical — это то, что имеет непосредственное, притом значительное влияние на пользователей.
Warning — это когда вы не уходите с работы, пока не почините. Бросать все и бежать на помощь ради варнинга не надо. Можно докурить/доесть и заняться решением. К примеру, появился явный риск возникновения критичных проблем вроде упавшего сервера из HA пары, в логи посыпались ошибки и тому подобное. Если не забивать и добросовестно чинить такие события, (а также докапываться до причин возникновения и проводить работу по их предупреждению) их будет очень мало.
Еще одна вещь, о которой часто забывают. Не бросайте на дежурства одних только админов. Обязательно привлеките разработчиков, сформировав рабочие пары на каждую смену. Это пригодится нам на следующих этапах.
Если проект функционально сложный, имеет смысл отправить на дежурство консультантов, аналитиков, тестировщиков и всех прочих, кто может быть полезен. Обеспечьте их доступность хотя бы по звонку. Специалист должен будет подтвердить проблему (или наоборот) и помочь с функциональной локализацией — когда придется поднимать человека на ремонт, это сэкономит ваше время. Подробнее этот вопрос я рассмотрю в следующем разделе.
И последний важный момент. Каждый дежурный сотрудник должен досконально знать контакты и зоны ответственности всех своих коллег по ЧП. Если он не сможет решить проблему самостоятельно и в панике начнет искать доступных спасателей, наступит хаос, из-за которого вы потеряете массу времени.
Соблюдение этих простых правил поможет избежать проблем из-за пропущенных оповещений и гарантирует: когда придет ЧП (читать и как «Черная пятница», и как «чрезвычайное происшествие»), люди смогут заняться решением проблем оперативно.
Подтверждаем наличие инцидента
Следующий шаг после получения уведомления — понять, что именно пошло не так и есть ли проблема в принципе: с ходу определить, кто прав, пользователь или система, не всегда легко. Дело в том, что одно и то же оповещение может быть по-разному интерпретировано в зависимости от угла зрения.
К примеру, типичный админ, получивший информацию о багах в поисковой системе (пропали товары), пойдет проверять поисковый сервер и читать логи. Он потратит кучу времени и убедится, что поиск исправен. Затем он полезет еще глубже в попытках понять, что же сломалось. В итоге, выяснится, что «пропавшие» товары были специально скрыты и проблемы нет, просто пользователь был не в курсе.
Или же админ впадет в ступор, а потом закроет тикет за отсутствием состава преступления. Ну а что, другие товары замечательно ищутся! А на самом деле кто-то случайно удалил из базы товары с лендинга, и вся рекламная кампания превратилась в «демотивационную».
В первом случае админ потратил время на локализацию несуществующей проблемы из-за неполноты сведений. Во втором «виноват» именно угол его зрения. Админ будет искать техническую проблему, в то время, как аналитик быстро обнаружит логическую и восстановит товары.
Решение здесь только одно — если вам пришло автоматическое оповещение, вы должны четко знать, что оно значит и как его проверять. Желательно, в виде письменной инструкции. Если речь идет о сообщениях от пользователей, в первую очередь ими должен заниматься не столько технический, сколько функциональный специалист с техническим бэкграундом. Именно он примет на себя еще одну раздражающую проблему — отлично знакомые вам путаные сообщения а-ля «у меня всё зависло», «ваш сайт не работает» и «я нажимаю, а оно не хочет».
Прежде чем разбираться дальше, нужно понять, что именно случилось у человека, и убедиться, что проблема «настоящая». Для этого в техподдержке, куда пользователь сообщает о неполадках, должны сидеть вежливые и опытные спецы. Их задача — вытянуть как можно больше сведений и понять, что, по мнению посетителя, работает не так. На основе этих сведений можно определить: это техническая проблема с сайтом или, скажем так, интерфейс оказался недостаточно интуитивным.
Локализуем сбой
Отлично, оповещение мы получили. Убедились, что проблема есть. Дальше нужно понять ее техническую суть и очертить зону ее влияния. Мы должны увидеть, что именно не работает, почему и как это исправить. На этом этапе наш главный враг — всё тот же, что и раньше: дефицит информации.
Восполнять его помогает хороший мониторинг и ведение логов. Во-первых, ключевые параметры работы системы, о которых мы говорили в первом пункте, – продажи, посетители, скорость генерации страниц, технические ошибки в ответах сервера, в виде графиков надо выводить на большой экран (чем больше, тем лучше) в комнате службы поддержки.
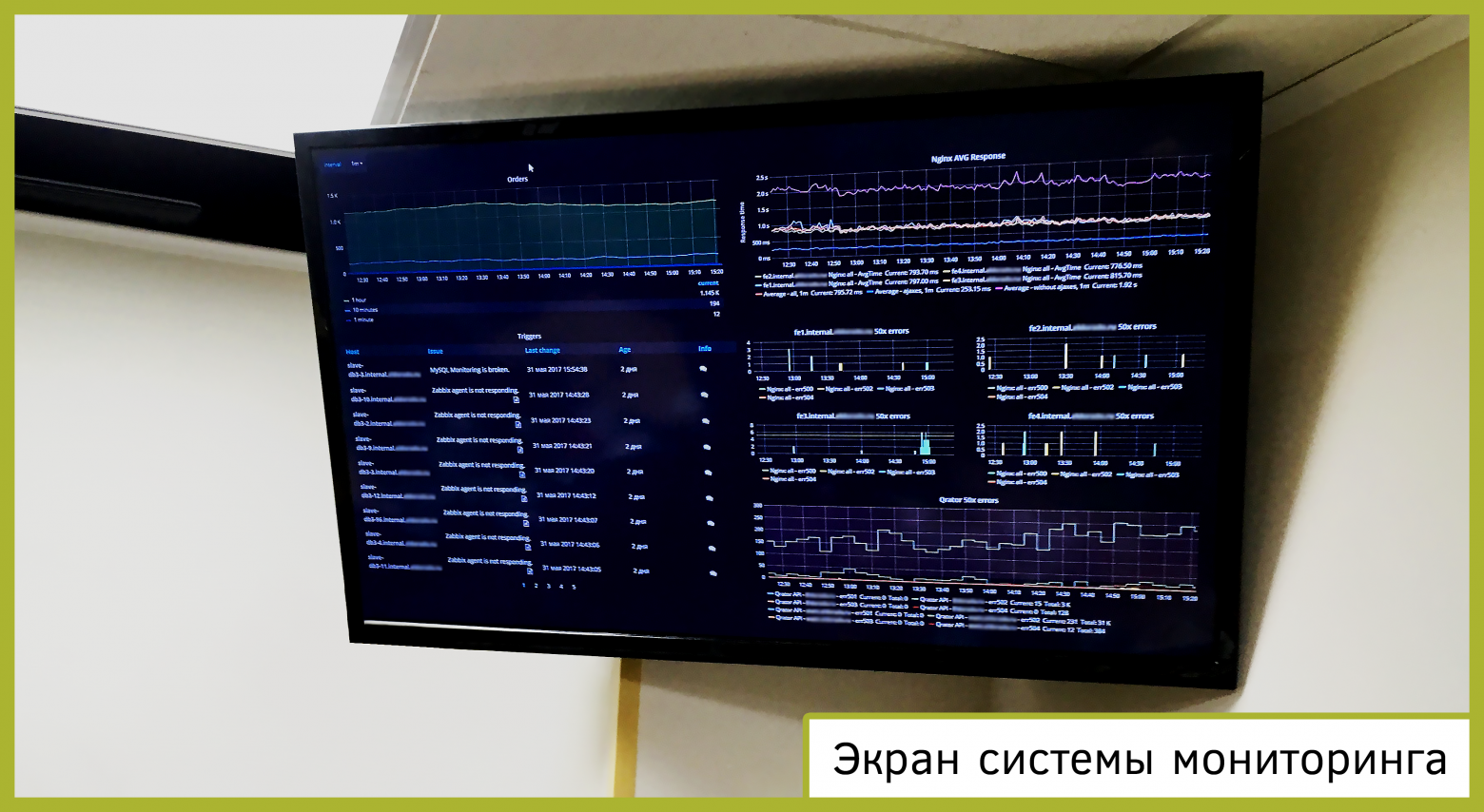
Все важные данные всегда должны быть перед глазами вашей службы поддержки. Во время ЧП или любой другой акции это позволит им быстро отреагировать на изменения показателей и предупредить проблему.
Для локализации сбоящего компонента понадобится схема сайта с данными по взаимодействию компонентов и их связям. Чтобы быстро обнаруживать проблемные точки, нужно в динамике отслеживать данные по каждому потоку взаимодействия.
Например, приложение обращается к базе данных. Значит, по каждому серверу БД и с серверной, и с клиентской стороны мы должны видеть следующее:
- Количество запросов в секунду;
- Количество ответов;
- Время формирования ответов;
- Объем передаваемых ответов;
- Технические ошибки этого взаимодействия (авторизация, коннекты и т.д.).
После локализации проблемного компонента можно идти в логи и смотреть, что же с ним, беднягой, не так. Здорово ускорить этот процесс поможет централизованный лог-коллектор. Например, на ELK.
Также, как я писал в прошлой статье, существенная экономия времени достигается за счет удобства поиска по логам кластеров и возможности проследить обработку запросов по всей цепочке.
Устраняем сбой

На этой стадии мы наконец-то чиним то, что сломалось, и разбираемся, как можно ускорить этот процесс.
Очевидно, наш лучший помощник — инструкция по устранению сбоя. К сожалению, она будет у нас только в том случае, если мы уже сталкивались с этой ситуацией ранее. Ну, и не забыли записать рабочее решение. Если инструкции нет, придется идти торным путем проб и ошибок.
Когда приходится чинить на проде что-то новенькое, необходимо взвесить безопасность работ и необходимость скорейшего вмешательства. Проверка внесенного исправления в тестовой среде, с одной стороны, снижает риски, а с другой — затягивает решение проблемы.
Я стараюсь руководствоваться следующим правилом: если я совершенно уверен, что хуже уже не будет, или воспроизвести проблему в тестовой среде нельзя, можно попытаться починить сразу на проде. Но такой метод оправдан только в том случае, если совпадают сразу 3 фактора:
- Всё лежит;
- Лекарство не затронет ценные данные;
- Есть бэкапы.
В остальных случаях стоит воспроизвести проблему в тесте и перепроверить всё до переноса на продуктив. Избежать итераций по повторному исправлению поможет качественная работа на предыдущих стадиях (осознание проблемы и ее локализация). Как правило, починить с первого раза не выходит, если мы чиним что-то, что не сломано, или чего-то не учли.
И здесь нам снова приходит на помощь нагрузочное тестирование. Мы эмулируем работу продуктива и начинаем специально его ломать. Это нужно, чтоб понять, как он работает, какое влияние на него оказывают те или иные проблемы. К тому же, это отличный способ научиться чинить приложение, а заодно — написать инструкции по его ремонту.
После этого можно будет проводить тактические учения по локализации и устранению проблем на зоне тестирования. Например, когда кто-то из ведущих специалистов что-то хитро ломает, может, даже и не в одном месте, и отправляет кого-то разбираться и чинить самостоятельно. На время. Очень полезная практика. И к работе в стрессовой ситуации приучает, и систему изучаешь, и навыки оттачиваешь, и новых инструкций рождается море.
В заключение нашего небольшого методического ликбеза, я хочу обратить ваше внимание на важность актуальных инструкций, формальных графиков и прочего нелюбимого многими бумагомарательства. Да, оно съедает львиную долю времени и сил. Но потраченное время вернется вам сторицей, когда грянет гром, и вы «по бумажке» всё почините без лишних нервов.
Эксплуатация – это SLA. А SLA – это про соблюдение таймингов как в целом, так и отдельно, на каждом этапе. Чтобы контролировать выполнение SLA и эти самые тайминги, нужно знать ограничения по времени для каждого этапа. Иначе до самого выхода за рамки вы не поймете, что где-то уже опоздали. А без фиксации алгоритмов работы и конкретных действий на каждом этапе нельзя ни оценить, ни гарантировать продолжительность этих этапов.
Творчество — это очень интересно, но совершенно непредсказуемо. Занимайтесь им для души, а наиболее удачные решения тестируйте и внедряйте, но только не во время подготовки к Черной пятнице или другой акции. Бизнес скажет вам за это спасибо.
Пока что это всё, что я хотел бы рассказать на эту тему. Буду рад, если мои советы, будучи перенесенными на реалии вашего бизнеса, позволят пережить высокую нагрузку спокойно и с комфортом.
Если вы хотите получить совет, как действовать именно в вашей ситуации, приглашаю вас на мой семинар «Черная пятница. Секреты выживания». В формате вопрос-ответ мы поговорим о подготовке сайта к росту трафика и обсудим как технические, так и организационные тонкости этого процесса.
Семинар пройдет 16 августа в Москве. Поскольку мероприятие будет довольно-таки камерным (максимум 25 человек), предварительная запись обязательна. А всех остальных я жду для дискуссии в комментах. :)

