Данная статья открывает цикл, посвященный розничной торговле. Идею использования аналитики в ритейле можно изобразить в виде вот такого маркетингового круга:

Основная идея, на первый взгляд, бесполезной картинки – показать, что аналитика позволяет предсказать последствия принятия тех или иных бизнес решений, основываясь на последующем изменении покупательского спроса. И чем лучше мы понимаем спрос, агрегируя информацию из разных каналов, тем лучше мы будем предсказывать результат. Короче говоря, картинка идеального мира, и каждый идет к этому миру своим путем.
Сегодня речь пойдет об аналитике ценообразования в офлайн ритейле.
Введение
На Вики дано лаконичное определение ценообразованию. С точки зрения компании, ценообразование — еще один инструмент, который позволяет управлять спросом на товары/услуги и соответственно KPI’ми компании. Почему бы не воспользоваться достижениями цифровизации и науки о данных, чтобы помочь компании выставлять цены более эффективно.
Типичное для ритейла ценообразование товаров выглядит следующим образом:
- Товары, на которые цена ограничивается из-за государственного регулирования: табак, некоторые лекарства. В этом случае обычно не заморачиваются и ставят максимально разрешенную цену
- Товары-индикаторы для покупателя. Их жестко ценообразуют от конкурентов на основании правил вроде "наша цена = цена конкурента – 2%" (KVI, первая цена, локомотивы и пр.)
- Остальные товары (back basket), которые каждый ценообразует в меру своих возможностей. Именно о них сегодня и будет идти речь, как выставить цену на эти товары наилучшим образом. Таких остается в среднем где-то половина в выручке
Ближе к делу
Кратко весь процесс оптимизации цен можно описать следующими шагами:
- Строим модель покупательского спроса на исторических данных
- Собираем правила ценообразования от бизнеса (о них чуть ниже) и превращаем их в математические ограничения оптимизации
- Запускаем оптимизацию по заданным KPI (маржа, выручка, штуки) и получаем оптимальные цены
Выглядит не очень сложно, но тут начинаются детали

Для простоты рассмотрим процесс оптимизации цен с конца. Если первые два пункта выполнены (т.е. построены модели спроса и формализованы правила ценообразования), то третий является чисто техническим шагом (конечно, если вы знаете, какой KPI надо оптимизировать). Методов оптимизации придумано множество под разные задачи. В конце концов можно просто пробежаться по сетке цен и найти наилучшую, хоть это и не подход настоящих джедаев.
Второй пункт – это отдельная и очень сложная задача сбора правил для автоматизации ценообразования. Здесь не много аналитики-математики, а основная проблема – формализовать и согласовать правила, которые находятся в голове у нескольких десятков Николаев Сергеевичей. Благо, что есть более или менее устоявшийся набор шаблонов правил, с которого можно начать:
- Маржа не ниже/не выше N[%] или N[руб.]
- Изменение цены не более N[%] или N[руб.]
- Цена в рамках ценового кластера одинакова
- Цена в рамках линеек товаров одинакова
- Цена за единицу объема дешевле у бо’льших товаров
- Цена не может быть ниже/выше N[%], относительно конкурентов
- СТМ дешевле бренда на N[%]
- Формат цены ##.00, #9.95 (да, такие цены все еще очень любят, причем не только в России)
Ну вот и самый интересный первый пункт – построение модели покупательского спроса
Тип модели и данные
Модель должна строиться с учетом того, что ее будут использовать для дальнейшей оптимизации. Т.е. бустинги деревьев это хорошо, когда у вас небольшое число пар «товар/магазин», но попробуйте оптимизировать бустингом 10 000 000 пар «товар/магазин» за 5 часовое ночное окно (кроме того, вы видели, как ансамбли деревьев учитывают цены?).
По оси X указана цена, по оси Y предсказанный спрос
Раз пример:
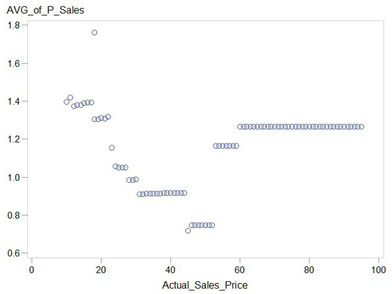
Два пример:
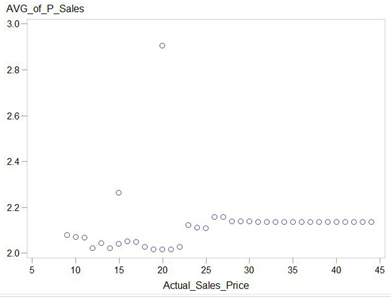
В этой области по-прежнему рулят линейные модели. Как показывает практика, хорошо настроенная линейная модель не уступает в точности бустингу среднестатистического “датасатанистаcаентиста”. Но даже если линейная регрессия чуть-чуть уступит другой модели – это не так страшно, т.к. итоговая задача – определение наилучшей цены, а не максимально точный прогноз.
Наша задача — получить модели (или модель), которые будут предсказывать спрос на каждый товар в каждом магазине. Типичные данные, которые нужны для этого – это история продаж, история остатков, история цен, история промо. Опционально можно добавлять другие данные вроде цен конкурентов, погоды, данных о лояльности или транзакционных данных. При этом обычно в нормальном состоянии есть только история продаж. Остатки могут скакать из-за списаний, воровства и просто проблем с учетом (нередки случаи, когда на остатках может находиться -0.4 банки зеленого горошка, вот и думай, что это значит). История цен и промо вообще отдельная история – их тяжело найти в глубинах ERP (а иногда их там просто нет). Конечно, возможно восстановить цены из продаж, но это соответствующим образом скажется на качестве моделирования и, конечно, не в лучшую сторону.
Небольшой оффтоп
Часто бывает трудно объяснить, что аналитика вообще может помочь в ценообразовании. Вот два типичных случая:
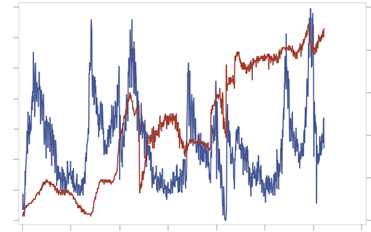
Случай 1. Синим цветом изображены продажи в [шт.] во времени, красным – цена. Вот заказчик показывает нам этот график и говорит: у нас нет классической зависимости от цены, ведь цена растет и спрос растет, цена падает и спрос падает. В конце статьи станет понятно, что делать в этом случае (и нет — это не товар Гиффена).
Здесь кроме цены необходимо учитывать дополнительные факторы. Такими факторами могут быть (не ограничиваясь):

- Собственные цены и цены конкурентов
- Промо-мероприятия
- Праздники
- Сезонность
- Тренды
- Жизненный цикл товара
- Товарные запасы
Задача, которую мы решаем — понять, как изменение цены влияет на спрос при прочих известных факторах.

Случай 2. На графике изображены продажи товара во времени. Тяжело найти зависимость от цены, если товар продается по одной штуке в неделю.
Ответ лежит на поверхности – необходимо агрегировать данные для получения полезного сигнала.
Давайте теперь по порядку подробно разберем оба этих случая.
Учет факторов и агрегирование
Чтобы модель могла учитывать внешние факторы и была оптимизируемой за разумное время, давайте использовать линейную регрессию. На тему «какую лучше всего модель использовать» написана ни одна диссертация, но на практике хорошо зарекомендовали себя две очень простые модели следующего вида:


Давайте дальше их и использовать.
При нехватке данных логично использовать агрегирование. При этом под агрегированием можно понимать следующие шаги:
- Вертикальное объединение информации (vertical information pooling) – агрегирование в классическом понимании, например, смотреть продажи товары на уровне города, а не конкретного магазина.
- Горизонтальное объединение информации (horizontal information pooling) – использование эконометрических моделей с фиксированными, случайными и смешанными эффектами с использованием панельных данных.
После того, как мы определились с моделью прогнозирования и методом агрегирования, можно приступить к декомпозиции спроса – т.е. оценивать коэффициенты регрессии на наиболее подходящем уровне товарно-географической иерархии. При этом считаем, что все уровни ниже по иерархии наследуют полученные на более верхних уровнях зависимости. Часто приходится вернуться на этап выбора модели и метода агрегирования и попробовать несколько вариантов декомпозиции.
Декомпозиция спроса состоит из следующих шагов:
- На верхних уровнях товарно-географической иерархии оцениваем сезонные, цикличные и трендовые компоненты, используя методы временных рядов.
- На средних уровнях вычитаем полученную сезонность, строим ту самую модель регрессии, о которой мы говорили выше – оцениваем влияние внешних факторов.
- На нижних уровнях вычитаем сезонность и влияние факторов. В результате у нас появляются необъясненные остатки. Назовем их локальными трендами и снова спрогнозируем временными рядами.
Итогом декомпозиции спроса является своя модель прогнозирования для каждой пары «товар-магазин».
Казалось бы, все проблемы решены, для каждой пары «товар-магазин» построили свою линейную модель, осталось наложить ограничения и отправить все в оптимизатор. На самом деле, основная сложность декомпозиции спроса заключается в построении правильной иерархии и определении оптимальных уровней построения регрессии. Для этого нам надо построить подходящие товарную и географическую иерархии. Часто принятые в компании иерархии отвечают больше управленческим задачам (например, финансовая иерархия или иерархия, привязанная к поставщикам и т.д.). Они плохо подходят для задачи моделирования спроса, поэтому надо построить свою классную иерархию.
Для построения товарной иерархии необходимо изучить, как покупатель принимает решение о покупке товаров. И, задавая себе этот вопрос, мы приходим к новому понятию – дерево принятия решений покупателем (Customer Decision Tree, CDT). Оно показывает, какие атрибуты товаров важны для покупателя, и в какой последовательности они должны быть расположены.
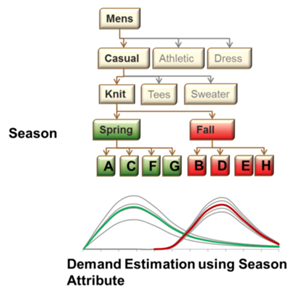
В большинстве случаев CDT строится на основании атрибутов товаров. Чем ниже уровень CDT, тем сильнее товары заменяют друг друга. Категорийные менеджеры могут оказать большую помощь в построении CDT, т.к. хорошо понимают свои категории. Есть аналитические способы построения CDT, например, анализ графа транзакций. Описание подобных методов — отдельная статья.
Каждая точка – товар,
Вес ребер характеризуется количеством транзакций, в которых оба товара были вместе
Построение географической иерархии — обычно более простая задача. Помочь здесь может кластеризация по структуре сезонности, структуре продаж категорий, по перемещениям покупателей.
Интересный кейс был в одном продуктовом ритейлере: структура спроса сильно различалась в зависимости от того, на какой стороне крупных дорог располагались магазины – в сторону области брали больше водки, пива и сигарет, в сторону центра – больше чистящих средств, детских йогуртов и корма для животных – это был стабильный паттерн потребления.
Построив отдельно CDT и географическую иерархию, комбинируем их в товарно-географическую. Таким образом мы построили новую иерархию, которая отлично подходит для моделирования спроса.
Что в итоге
В итоге мы построили новую иерархию, которая хорошо подходит для моделирования спроса, а также получили последовательность действий, которые надо сделать, чтобы построить сами модели спроса для дальнейшей оптимизации. Вот кратко порядок построения моделей:
- Оцениваем сезонность, тренд, циклические компоненты
- Агрегируем данные до уровня товарно-географической иерархии, на котором оцениваем сезонность, тренд и циклические компоненты
- Все уровни иерархий ниже наследуют полученные значения
- Агрегируем данные до уровня, на котором будем оценивать влияние внешних факторов
- Вычитаем сезонность и тренд
- Оцениваем влияние внешних факторов
- Все уровни иерархий ниже наследуют рассчитанную оценку влияния от внешних факторов
- Вычитаем полученные значения сезонности и оценки влияния внешних факторов на самом детальном уровне – товар/магазин
- Остатки сглаживаем и прогнозируем простыми методами. Восстанавливаем сезонность, праздники, влияние промо и цен.
В результате для каждого товара в каждом магазине мы получили свою формулу:

Люди из бизнеса сразу спросят, а как же учитывается взаимное влияние товаров друг на друга? Его можно учесть на этапе моделирования несколькими способами, но вот два самых популярных:
Прямой метод – учитываем цены товаров, которые оказывают наибольшее влияние друг на друга в формуле спроса:

Моделирование доли продаж – прогнозируем продажи группы и долю каждого товара внутри группы:


Далее формулы для каждой пары «товар-магазин» отправляем в оптимизатор и получаем на выходе оптимальные цены.

А как же тот пример?
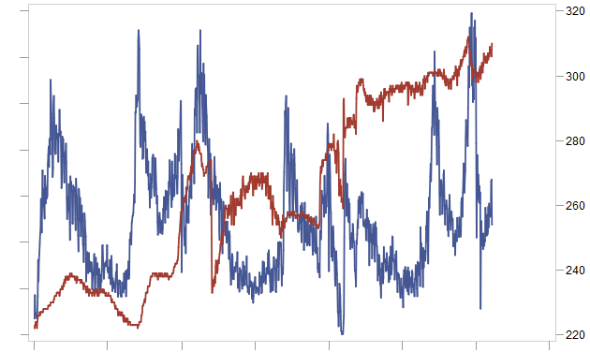
Спрос (синий) и цена (красный) во времени

Спрос (ось Y) в зависимости от цены (ось X)
Да, на первый взгляд зависимость спроса от цены действительно отсутствует, ставь максимальную цену и радуйся.
Но построив новую иерархию для прогнозирования, рассчитав сезонность на более высоком уровне, вычтем ее на уровне товаров.
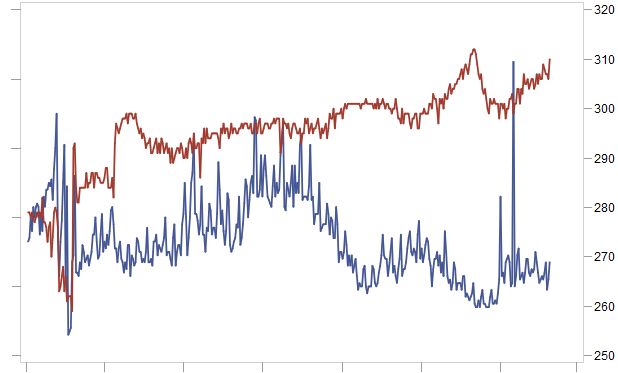
Спрос со компенсированной сезонностью (синий) и цена (красный) во времени
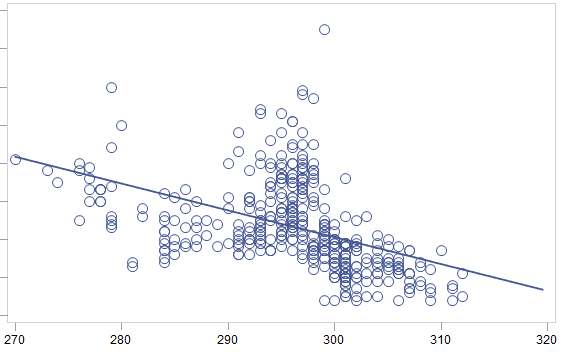
Спрос со компенсированной сезонностью (ось Y) в зависимости от цены (ось X)
Типичная зависимость спроса от цены (чем больше цена, тем меньше спрос). Т.е. в данном случае отлично видно влияние сезонности, учтя которую сразу видно, что товар является вполне эластичным.
Заключение
Оптимизировать цены не только выгодно для компании (несколько процентов маржи еще никому не мешали), но и интересно. Тут и регрессии, и оптимизация, и анализ графов, и все это в биг дата обертке — есть куда развернуться душе аналитика. Но не стоит забывать, что моделирование спроса и оптимизация цен — это лишь маленькая часть большого бизнес-процесса ценообразования и, отдельно от оставшейся части, приносит мало пользы.
Оптимизируйте процессы, оптимизируйте цены, оптимизируйте хранение данных (ведь Garbage In – Garbage Out) и получайте классные результаты.

