
 На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.
На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.Yandex SpeechKit позволяет напрямую обращаться к тому бэкэнду, который успешно применяется в мобильных приложениях Яндекса. Мы достаточно долго развивали эту систему и сейчас правильно распознаем 94% слов в Навигаторе и Мобильных Картах, а также 84% слов в Мобильном Браузере. При этом на распознавание уходит чуть больше секунды. Это уже весьма достойное качество, и мы активно работаем над его улучшением.
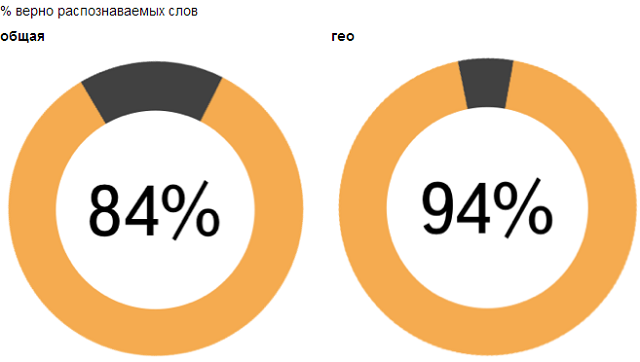
Можно утверждать, что уже в скором времени голосовые интерфейсы практически не будут отличаться по надежности от классических способов ввода. Подробный рассказ о том, как нам удалось добиться таких результатов, и как устроена наша система, под катом.
Распознавание речи — одна из самых интересных и сложных задач искусственного интеллекта. Здесь задействованы достижения весьма различных областей: от компьютерной лингвистики до цифровой обработки сигналов. Чтобы понять, как должна быть устроена машина, понимающая речь, давайте для начала разберемся, с чем мы имеем дело.
I. Основы
Звучащая речь для нас — это, прежде всего, цифровой сигнал. И если мы посмотрим на запись этого сигнала, то не увидим там ни слов, ни четко выраженных фонем — разные «речевые события» плавно перетекают друг в друга, не образуя четких границ. Одна и та же фраза, произнесенная разными людьми или в различной обстановке, на уровне сигнала будет выглядеть по-разному. Вместе с тем, люди как-то распознают речь друг друга: следовательно, существуют инварианты, согласно которым по сигналу можно восстановить, что же, собственно, было сказано. Поиск таких инвариантов — задача акустического моделирования.
Предположим, что речь человека состоит из фонем (это грубое упрощение, но в первом приближении оно верно). Определим фонему как минимальную смыслоразличительную единицу языка, то есть звук, замена которого может привести к изменению смысла слова или фразы. Возьмем небольшой участок сигнала, скажем, 25 миллисекунд. Назовем этот участок «фреймом». Какая фонема была произнесена на этом фрейме? На этот вопрос сложно ответить однозначно — многие фонемы чрезвычайно похожи друг на друга. Но если нельзя дать однозначный ответ, то можно рассуждать в терминах «вероятностей»: для данного сигнала одни фонемы более вероятны, другие менее, третьи вообще можно исключить из рассмотрения. Собственно, акустическая модель — это функция, принимающая на вход небольшой участок акустического сигнала (фрейм) и выдающая распределение вероятностей различных фонем на этом фрейме. Таким образом, акустическая модель дает нам возможность по звуку восстановить, что было произнесено — с той или иной степенью уверенности.
Еще один важный аспект акустики — вероятность перехода между различными фонемами. Из опыта мы знаем, что одни сочетания фонем произносятся легко и встречаются часто, другие сложнее для произношения и на практике используются реже. Мы можем обобщить эту информацию и учитывать ее при оценке «правдоподобности» той или иной последовательности фонем.
Теперь у нас есть все инструменты, чтобы сконструировать одну из главных «рабочих лошадок» автоматического распознавания речи — скрытую марковскую модель (HMM, Hidden Markov Model). Для этого на время представим, что мы решаем не задачу распознавания речи, а прямо противоположную — преобразование текста в речь. Допустим, мы хотим получить произношение слова «Яндекс». Пусть слово «Яндекс» состоит из набора фонем, скажем, [й][а][н][д][э][к][с]. Построим конечный автомат для слова «Яндекс», в котором каждая фонема представлена отдельным состоянием. В каждый момент времени находимся в одном из этих состояний и «произносим» характерный для этой фонемы звук (как произносится каждая из фонем, мы знаем благодаря акустической модели). Но одни фонемы длятся долго (как [а] в слове «Яндекс»), другие практически проглатываются. Здесь нам и пригодится информация о вероятности перехода между фонемами. Сгенерировав звук, соответствующий текущему состоянию, мы принимаем вероятностное решение: оставаться нам в этом же состоянии или же переходить к следующему (и, соответственно, следующей фонеме).

Более формально HMM можно представить следующим образом. Во-первых, введем понятие эмиссии. Как мы помним из предыдущего примера, каждое из состояний HMM «порождает» звук, характерный именно для этого состояния (т.е. фонемы). На каждом фрейме звук «разыгрывается» из распределения вероятностей, соответствующего данной фонеме. Во-вторых, между состояниями возможны переходы, также подчиняющиеся заранее заданным вероятностным закономерностям. К примеру, вероятность того, что фонема [а] будет «тянуться», высока, чего нельзя сказать о фонеме [д]. Матрица эмиссий и матрица переходов однозначно задают скрытую марковскую модель.
Хорошо, мы рассмотрели, как скрытая марковская модель может использоваться для порождения речи, но как применить ее к обратной задаче — распознаванию речи? На помощь приходит алгоритм Витерби. У нас есть набор наблюдаемых величин (собственно, звук) и вероятностная модель, соотносящая скрытые состояния (фонемы) и наблюдаемые величины. Алгоритм Витерби позволяет восстановить наиболее вероятную последовательность скрытых состояний.
Пусть в нашем словаре распознавания всего два слова: «Да» ([д][а]) и «Нет» ([н'][е][т]). Таким образом, у нас есть две скрытые марковские модели. Далее, пусть у нас есть запись голоса пользователя, который говорит «да» или «нет». Алгоритм Витерби позволит нам получить ответ на вопрос, какая из гипотез распознавания более вероятна.
Теперь наша задача сводится к тому, чтобы восстановить наиболее вероятную последовательность состояний скрытой марковской модели, которая «породила» (точнее, могла бы породить) предъявленную нам аудиозапись. Если пользователь говорит «да», то соответствующая последовательность состояний на 10 фреймах может быть, например, [д][д][д][д][а][а][а][а][а][а] или [д][а][а][а][а][а][а][а][а][а]. Аналогично, возможны различные варианты произношения для «нет» — например, [н'][н'][н'][е][е][е][е][т][т][т] и [н'][н'][е][е][е][е][е][е][т][т]. Теперь найдем «лучший», то есть наиболее вероятный, способ произнесения каждого слова. На каждом фрейме мы будем спрашивать нашу акустическую модель, насколько вероятно, что здесь звучит конкретная фонема (например, [д] и [а]); кроме того, мы будем учитывать вероятности переходов ([д]->[д], [д]->[а], [а]->[а]). Так мы получим наиболее вероятный способ произнесения каждого из слов-гипотез; более того, для каждого из них мы получим меру, насколько вообще вероятно, что произносилось именно это слово (можно рассматривать эту меру как длину кратчайшего пути через соответствующий граф). «Выигравшая» (то есть более вероятная) гипотеза будет возвращена как результат распознавания.
Алгоритм Витерби достаточно прост в реализации (используется динамическое программирование) и работает за время, пропорциональное произведению количества состояний HMM на число фреймов. Однако не всегда нам достаточно знать самый вероятный путь; например, при тренировке акустической модели нужна оценка вероятности каждого состояния на каждом фрейме. Для этого используется алгоритм Forward-Backward.
Однако акустическая модель — это всего лишь одна из составляющих системы. Что делать, если словарь распознавания состоит не из двух слов, как в рассмотренном выше примере, а из сотен тысяч или даже миллионов? Многие из них будут очень похожи по произношению или даже совпадать. Вместе с тем, при наличии контекста роль акустики падает: невнятно произнесенные, зашумленные или неоднозначные слова можно восстановить «по смыслу». Для учета контекста опять-таки используются вероятностные модели. К примеру, носителю русского языка понятно, что естественность (в нашем случае — вероятность) предложения «мама мыла раму» выше, чем «мама мыла циклотрон» или «мама мыла рама». То есть наличие фиксированного контекста «мама мыла ...» задает распределение вероятностей для следующего слова, которое отражает как семантику, так и морфологию. Такой тип языковых моделей называется n-gram language models (триграммы в рассмотренном выше примере); разумеется, существуют куда более сложные и мощные способы моделирования языка.
II. Что под капотом у Yandex ASR?
Теперь, когда мы представляем себе общее устройство систем распознавания речи, опишем более подробно детали технологии Яндекса — лучшей, согласно нашим данным, системы распознавания русской речи.
При рассмотрении игрушечных примеров выше мы намеренно сделали несколько упрощений и опустили ряд важных деталей. В частности, мы утверждали, что основной «строительной единицей» речи является фонема. На самом деле фонема — слишком крупная единица; чтобы адекватно смоделировать произношение одиночной фонемы, используется три отдельных состояния — начало, середина и конец фонемы. Вместе они образуют такую же HMM, как представлена выше. Кроме того, фонемы являются позиционно-зависимыми и контекстно-зависимыми: формально «одна и та же» фонема звучит существенно по-разному в зависимости от того, в какой части слова она находится и с какими фонемами соседствует. Вместе с тем, простое перечисление всех возможных вариантов контекстно-зависимых фонем вернет очень большое число сочетаний, многие из которых никогда не встречаются в реальной жизни; чтобы сделать количество рассматриваемых акустических событий разумным, близкие контекстно-зависимые фонемы объединяются на ранних этапах тренировки и рассматриваются вместе.
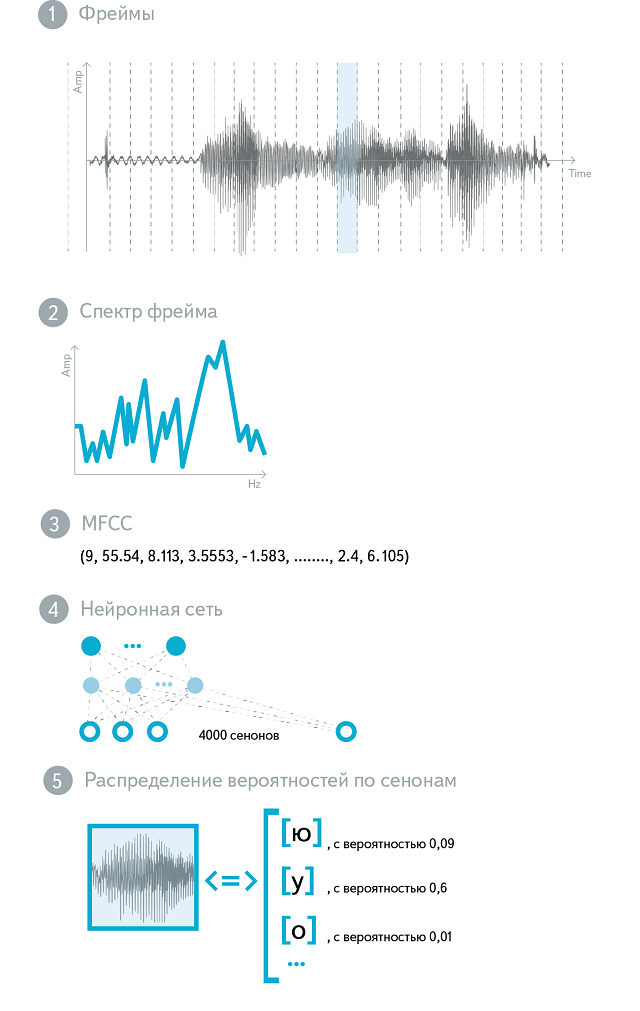
Таким образом, мы, во-первых, сделали фонемы контекстно-зависимыми, а во-вторых, разбили каждую из них на три части. Эти объекты — «части фонем» — теперь составляют наш фонетический алфавит. Их также называют сенонами. Каждое состояние нашей HMM — это сенон. В нашей модели используется 48 фонем и около 4000 сенонов.
Итак, наша акустическая модель все так же принимает на вход звук, а на выходе дает распределение вероятностей по сенонам. Теперь рассмотрим, что конкретно подается на вход. Как мы говорили, звук нарезается участками по 25 мс («фреймами»). Как правило, шаг нарезки составляет 10 мс, так что соседние фреймы частично пересекаются. Понятно, что «сырой» звук — амплитуда колебаний по времени — не самая информативная форма представления акустического сигнала. Спектр этого сигнала — уже гораздо лучше. На практике обычно используется логарифмированный и отмасштабированный спектр, что соответствует закономерностям человеческого слухового восприятия (Mel-преобразование). Полученные величины подвергаются дискретному косинусному преобразованию (DCT), и в результате получается MFCC — Mel Frequency Cepstral Coefficients. (Слово Cepstral получено перестановкой букв в Spectral, что отражает наличие дополнительного DCT). MFCC — это вектор из 13 (обычно) вещественных чисел. Они могут использоваться как вход акустической модели «в сыром виде», но чаще подвергаются множеству дополнительных преобразований.
Тренировка акустической модели — сложный и многоэтапный процесс. Для тренировки используются алгоритмы семейства Expectation-Maximization, такие, как алгоритм Баума-Велша. Суть алгоритмов такого рода — в чередовании двух шагов: на шаге Expectation имеющаяся модель используется для вычисления матожидания функции правдоподобия, на шаге Maximization параметры модели изменяются таким образом, чтобы максимизировать эту оценку. На ранних этапах тренировки используются простые акустические модели: на вход даются простые MFCC features, фонемы рассматриваются вне контекстной зависимости, для моделирования вероятности эмиссии в HMM используется смесь гауссиан с диагональными матрицами ковариаций (Diagonal GMMs — Gaussian Mixture Models). Результаты каждой предыдущей акустической модели являются стартовой точкой для тренировки более сложной модели, с более сложным входом, выходом или функцией распределения вероятности эмиссии. Существует множество способов улучшения акустической модели, однако наиболее значительный эффект имеет переход от GMM-модели к DNN (Deep Neural Network), что повышает качество распознавания практически в два раза. Нейронные сети лишены многих ограничений, характерных для гауссовых смесей, и обладают лучшей обобщающей способностью. Кроме того, акустические модели на нейронных сетях более устойчивы к шуму и обладают лучшим быстродействием.
Нейронная сеть для акустического моделирования тренируется в несколько этапов. Для инициализации нейросети используется стек из ограниченных машин Больцмана (Restricted Boltzmann Machines, RBM). RBM — это стохастическая нейросеть, которая тренируется без учителя. Хотя выученные ей веса нельзя напрямую использовать для различения между классами акустических событий, они детально отражают структуру речи. Можно относиться к RBM как к механизму извлечения признаков (feature extractor) — полученная генеративная модель оказывается отличной стартовой точкой для построения дискриминативной модели. Дискриминативная модель тренируется с использованием классического алгоритма обратного распространения ошибки, при этом применяется ряд технических приемов, улучшающих сходимость и предотвращающих переобучение (overfitting). В итоге на входе нейросети — несколько фреймов MFCC-features (центральный фрейм подлежит классификации, остальные образуют контекст), на выходе — около 4000 нейронов, соответствующих различным сенонам. Эта нейросеть используется как акустическая модель в production-системе.
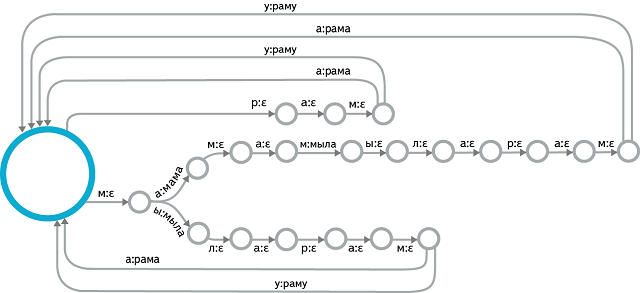
Рассмотрим подробнее процесс декодирования. Для задачи распознавания спонтанной речи с большим словарем подход, описанный в первой секции, неприменим. Необходима структура данных, соединяющая воедино все возможные предложения, которые может распознать система. Подходящей структурой является weighted finite-state transducer (WFST) — по сути, просто конечный автомат с выходной лентой и весами на ребрах. На входе этого автомата — сеноны, на выходе — слова. Процесс декодирования сводится к тому, чтобы выбрать лучший путь в этом автомате и предоставить выходную последовательность слов, соответствующую этому пути. При этом цена прохода по каждой дуге складывается из двух компонент. Первая компонента известна заранее и вычисляется на этапе сборки автомата. Она включает в себя стоимость произношения, перехода в данное состояние, оценку правдоподобия со стороны языковой модели. Вторая компонента вычисляется отдельно для конкретного фрейма: это акустический вес сенона, соответствующего входному символу рассматриваемой дуги. Декодирование происходит в реальном времени, поэтому исследуются не все возможные пути: специальные эвристики ограничивают набор гипотез наиболее вероятными.
Разумеется, наиболее интересная с технической точки зрения часть — это построение такого автомата. Эта задача решается в оффлайне. Чтобы перейти от простых HMM для каждой контекстно-зависимой фонемы к линейным автоматам для каждого слова, нам необходимо использовать словарь произношений. Создание такого словаря невозможно вручную, и здесь используются методы машинного обучения (а сама задача в научном сообществе называется Grapheme-To-Phoneme, или G2P). В свою очередь, слова «состыковываются» друг с другом в языковую модель, также представленную в виде конечного автомата. Центральной операцией здесь является композиция WFST, но также важны и различные методы оптимизации WFST по размеру и эффективности укладки в памяти.
Результат процесса декодирования — список гипотез, который может быть подвергнут дальнейшей обработке. К примеру, можно использовать более мощную языковую модель для переранжирования наиболее вероятных гипотез. Результирующий список возвращается пользователю, отсортированный по значению confidence — степени нашей уверенности в том, что распознавание прошло правильно. Нередко остается всего одна гипотеза, в этом случае приложение-клиент сразу переходит к выполнению голосовой команды.
В заключение коснемся вопроса о метриках качества систем распознавания речи. Наиболее популярна метрика Word Error Rate (и обратная ей Word Accuracy). По существу, она отражает долю неправильно распознанных слов. Чтобы рассчитать Word Error Rate для системы распознавания речи, используют размеченные вручную корпуса голосовых запросов, соответствующих тематике приложения, использующего распознавание речи.
Литература по теме:
1. Mohri, M., Pereira, F., & Riley, M. (2008). Speech recognition with weighted finite-state transducers. In Springer Handbook of Speech Processing (pp. 559-584). Springer Berlin Heidelberg.
2. Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A. R., Jaitly, N. et al. (2012). Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Processing Magazine, IEEE, 29(6), 82-97.
3. Jurafsky D., Martin J.H. (2008) Speech and language processing, 2nd edition. Prentice Hall.
