Comments 57
Это работает только для заданных шрифтов. Например, цифра 4 может как иметь замкнутый контур, так и не иметь. Кто-то может использовать ЖКИ-шный 9-сегментный шрифт, а кто-то помещать в 0 точку или шрих…
Хотя сама идея интересна — и если её чуть-чуть развить (т.е. научить компьютер «понимать» особенности буквы), возможно, заработает.
Хотя сама идея интересна — и если её чуть-чуть развить (т.е. научить компьютер «понимать» особенности буквы), возможно, заработает.
Алгоритм немножко хромает. Частенько вместо цифры 7 — получаю цифру 1
habreffect.ru/files/641/e666ae9cd/zoomit.png
habreffect.ru/files/641/e666ae9cd/zoomit.png
Спасибо! Статья будет полезна, как одна из вводных статей по теме распознавания образов. Все просто, четко и ясно. Пытался что то похожее выдумывать (только более путаное — углы, вектора и т.п.), но при отладке (или обучении системы) терпения не хватало и начинал заново и еще более путанее ))
А можно соурс код?
Супер! Просто и со вкусом. Очень элегантное решение.
Может быть, у меня такая манера написания цифр, но для меня процент правильных ответов составил в районе 5-10%.
Если удаётся выделить цифру (букву) в таком виде, то с распознаванием уже проблем нет. Проблема как раз в зашумлениях и искажениях.
Помнится, тут описывали шикарнейший алгоритм распознавания символов с капчи —
1) убираем шум фильтром, изображение переводим в черно-белое, и находим прямоугольные области, с наибольшим количеством черных точек.
2) Возвращаем исходное изображение и «вырезаем» найденные области
3) Распознаем штук 50 символов самостоятельно и оставляем их в качестве контрольных
4 ) Отдаем все последующие символы в руки распознавалке, чтобы сравнивала с каждой из контрольных групп
1) убираем шум фильтром, изображение переводим в черно-белое, и находим прямоугольные области, с наибольшим количеством черных точек.
2) Возвращаем исходное изображение и «вырезаем» найденные области
3) Распознаем штук 50 символов самостоятельно и оставляем их в качестве контрольных
4 ) Отдаем все последующие символы в руки распознавалке, чтобы сравнивала с каждой из контрольных групп


Можно поподробнее про п.3?:
3. Для более высокой точности распознавания, исследуется топология. С помощью рекурсивной функции подсчитывается количество замкнутых областей.
Как подсчитать количество замкнутых областей?
3. Для более высокой точности распознавания, исследуется топология. С помощью рекурсивной функции подсчитывается количество замкнутых областей.
Как подсчитать количество замкнутых областей?
Волновым алгоритмом, скорее всего.
Вот вам почти рабочий код на Python. Закрашенные квардраты — pixel.type = «wall»
Вот вам почти рабочий код на Python. Закрашенные квардраты — pixel.type = «wall»
#Получаем ближайшие пиксели
def getNearestPixels(pixel):
return [near for near in image \
if abs(pixel.coords.x-near.coords.x)==1 or abs(pixel.coords.y-near.coords.y)==1
]
#Заменяем все соседние empty тоже на wavy и возвращаем количество изменений
def DoWave():
isChanged = False
wavy = [pixel for pixel i image if pixel.type is "wavy"]
for pixel in wavy:
for near in getNearestPixels(pixel.coords)
if near.type is empty:
near.type = "wavy"
isChanged = True
return isChanged
#Обходим все и считаем сколько раз вызван волновой алгоритм
counter = 0
for pixel in image:
empty = [pixel for pixel in image if pixel.type is "empty"]
if pixel is empty:
isImageChanged = True
pixel.type = "wavy";
while isImageChanged:
isImageChanged = doWave()
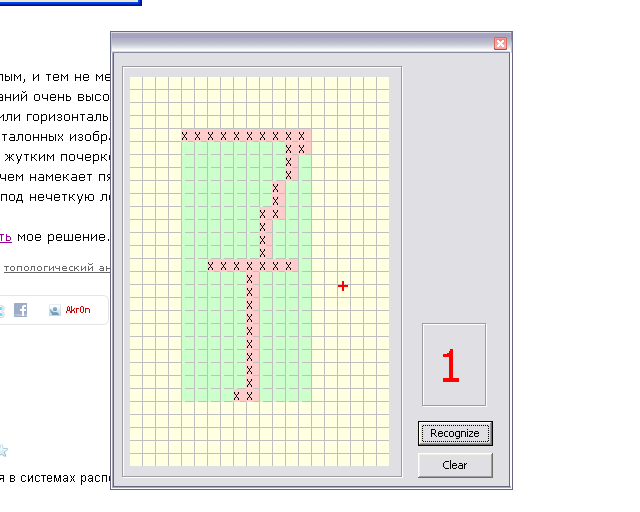
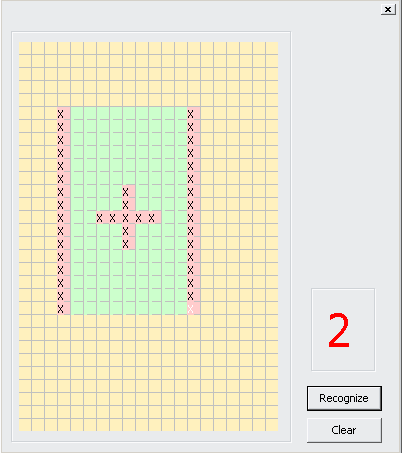
counter +=1Есть бага, если в цифре сделать пробел, т.е. не дорисовать один квадратик, то картинки по разному будут определяться, вот примеры:




это не баг, это фича.
хватит цыфири уродовать )
хватит цыфири уродовать )
моя третья картинка, где 9 определилась как 0 тоже фича? :)
Причем «девять» нарисована почти идеально (:
=)) Дело в том, что нужно обязательно замыкать 9, 6, 0 и 8. Причем даже отдельный пиксель уже считается отдельной замкнутой областью. Ну не делал я к алгоритму антивандальных примочек… каюсь…
<цитата написал=«автор»>Вообще имеются в виду только рукописные цифры.</цитата>
А по поводу девяток — нормально написаны, я не знаю что нужно быть за роботом, чтобы идеально, пиксель в пиксель писать под шаблон компьютерного шрифта :)
А по поводу девяток — нормально написаны, я не знаю что нужно быть за роботом, чтобы идеально, пиксель в пиксель писать под шаблон компьютерного шрифта :)
Поигравшись с программой в итоге сделал для себя вывод, что использование для рукописного текста врятли представляется возможным — программа заточена под один «шрифт» и к тому же почерк ловит только каллиграфический.
А задумка интересная. Желаю автору развить её дальше.
А задумка интересная. Желаю автору развить её дальше.
Поддерживаю. У нас в вузе например стало модным последнее время в качестве курсовых по программированию делать разные сайты, которые похожи один на один как две капли воды, и не представляют никакого интереса как в плане теоретическом, так и практическом. Ни для студента, ни для преподавателя. Сабж же — пример пусть и не на 100%, но успешной работы, к которой была приложена не только рука, но и голова. При желании ее можно развить в собственный движок распознавания образов. Кстати сравнение с образцом можно тоже добавить для случаев, когда статистика не однозначна.
Напомнило метод, совмещающий попиксельное сравнение и разбиение по областям. Имхо даёт результат лучше, даже для рукописного текста aimatrix.nm.ru/aimatrix/SimpleOCRAlgorithm.htm
>>Метод может показаться слишком тупым, и тем не менее он работает! Если не стоит задачи обмануть алгоритм, процент верных распознаваний очень высок.
Почему же тупой? Нормальный метод, хотя и требует некоторой доработки. А вот заявление про высокий процент распознаваний слишком оптимистичное :)
На сколько я могу судить, метод считает, что контур не замкнут, даже если разрыв в 1-2 точки, в результате вырастает процент ошибок.
Сам писал в студенческие годы нечто похожее.
За следующими дополнениями:
1) изображение «нормировалось», т.е. приводились к единому размеру и пропорциям
2) контуры замыкались, если разрыв в них мал относительно длины контура
3) статистика бралась не по четвертям, а по половинкам (верхней и нижней), четверти пробовал, но у меня как-то с ними хуже работало.
Почему же тупой? Нормальный метод, хотя и требует некоторой доработки. А вот заявление про высокий процент распознаваний слишком оптимистичное :)
На сколько я могу судить, метод считает, что контур не замкнут, даже если разрыв в 1-2 точки, в результате вырастает процент ошибок.
Сам писал в студенческие годы нечто похожее.
За следующими дополнениями:
1) изображение «нормировалось», т.е. приводились к единому размеру и пропорциям
2) контуры замыкались, если разрыв в них мал относительно длины контура
3) статистика бралась не по четвертям, а по половинкам (верхней и нижней), четверти пробовал, но у меня как-то с ними хуже работало.
Попробовал попробовал. =)
Мою девятку он тоже далеко не с первого раза понял.
Кстати, рисование точечками — это не совсем правильно. Если уж я держу зажатой мышку, то пробелов не должно появлятся. Лучше всего рисовать линиями пока мышка зажата.
Мою девятку он тоже далеко не с первого раза понял.
Кстати, рисование точечками — это не совсем правильно. Если уж я держу зажатой мышку, то пробелов не должно появлятся. Лучше всего рисовать линиями пока мышка зажата.


{kind=link}
Хардкодить таблицу некрасиво, лучше приделать какую-нибудь эвристику (хоть простейшую нейросеть) с пресетами. Тогда можно тренировать на разные шрифты/символы или хотя бы саму статистику иметь точнее.
Вообще, интересно, еще и топологию автоматизировать бы под любой набор символов да параметров всяких поболее, совсем хорошо было бы.
Вообще, интересно, еще и топологию автоматизировать бы под любой набор символов да параметров всяких поболее, совсем хорошо было бы.
Я когда-то реализовывал похожий алгоритм.
Ко всем параметрам определения можно добавить еще несколько:
1) количество прямых и их длительность. явно отделяет 1, 7, 5 от всего остального
2) количество и длинна «полукругов» (не замкнутых) — 2, 3, 5 от всего остального
3) количество соприкосновений с границей четверти. тоже очень четко отделяет 8, 6, 9, 0 от 1, 7,
4) количество несвязанных «кусков» в четверти. явно видно что у 2-ки в 3-й четверти их 2
… еще там с 5 шут было не помню уже, и работало достаточно неплохо.
Ко всем параметрам определения можно добавить еще несколько:
1) количество прямых и их длительность. явно отделяет 1, 7, 5 от всего остального
2) количество и длинна «полукругов» (не замкнутых) — 2, 3, 5 от всего остального
3) количество соприкосновений с границей четверти. тоже очень четко отделяет 8, 6, 9, 0 от 1, 7,
4) количество несвязанных «кусков» в четверти. явно видно что у 2-ки в 3-й четверти их 2
… еще там с 5 шут было не помню уже, и работало достаточно неплохо.
Yep!

p.s. Дадите исходники-то? Для исследовательских целей only.
p.s. Дадите исходники-то? Для исследовательских целей only.
:)
капризный тег попался…
gyazo.com/e5f1322c4764740f7c419e2e702d42bb.png
gyazo.com/e5f1322c4764740f7c419e2e702d42bb.png
{kind=link}
Про такой алгоритм известно очень давно. Для winmobile даже есть программа рукописного ввода на нём основанная:
softsearch.ru/programs/249-679-esperanto-download.shtml
Отличия: панель ввода делится на 9 зон и есть возможность определять буквы (с самообучением естессно).
softsearch.ru/programs/249-679-esperanto-download.shtml
Отличия: панель ввода делится на 9 зон и есть возможность определять буквы (с самообучением естессно).
Sign up to leave a comment.
Распознавание цифр с помощью простейшей статистики и анализа топологии