Привет, Хабрачитатель!
Полнотекстовый поиск данных в InnoDB – это известная головная боль многих разработчиков под MySQL / InnoDB. Для тех, кто не в курсе дела я объясню. В типе таблиц MyISAM есть полноценный полнотекстовый поиск данных, однако сама таблица исторически имеет ограничения, которые являются принципиальными в отдельных проектах. В более «продвинутом» типе таблиц InnoDB полнотекстового поиска нет. Вот и приходится мириться бедным разработчикам либо с ограничениями MyISAM, либо с отсутствием поиска в InnoDB. Я хочу рассказать о том, какие есть способы организовать полноценный поиск в InnoDB без магии и исключительно штатными средствами. Также будет интересно сравнить скоростные характеристики каждого способа.
Для примера возьмем небольшую таблицу с 10000 записями.
В этой таблице мы храним данные пользователей сайта. На самом сайте есть форма поиска пользователей, в которую можно ввести произвольный запрос вида «Толстой Ясная Поляна». Для обработки такого запроса поиск должен осуществляться сразу по нескольким полям. Нам нужен поиск для полей login, name, surname, city, country. Запрос может быть как одиночным словом (имя или город) или же в виде набора слов, разделенных пробелом. Проблема в том, что нам необходимо искать этот набор слов сразу по нескольким полям, что сложно сделать в InnoDB без использования дополнительных функций.
Есть несколько относительно простых способов полнотекстового поиска данных в InnoDB:
Рассмотрим каждый из них подробнее.
Первый предлагаемый способ заключается в создании дополнительной таблицы в MyISAM. Как известно MyISAM достаточно неплохо поддерживает полнотекстовый поиск и это можно использовать. В эту дополнительную таблицу будут копироваться все данные из основной таблицы (users). Синхронизация будет обеспечиваться за счет триггеров. В новой таблице добавим поля login, name, surname, city, country. Таким образом, мы создадим «зеркало» основной таблицы, и работать будем с ним. Для возможности полнотекстового поиска добавим туда FULLTEXT индекс по всем 5 полям вместе:
Для синхронизации данных между основной таблицей и таблицей-«зеркалом» на users установим триггеры на запись, изменение и чтение:
Триггер на запись:
Триггер на изменение:
И простой триггер на удаление:
Поиск осуществляется с помощью следующего запроса:
Здесь поиск данных происходит в таблице search, результат сортируется по релевантности, и на выходе мы получаем соответствующие записи из таблицы users.
Главный плюс такого подхода — это гибкость поиска за счет добавления дополнительных индексов и составления новых комбинаций поиска (страна+город или логин + имя + фамилия). Таким образом, мы можем свободно формировать новые наборы для поиска и правила релевантности.
Минусы этого способа (как и всех способов с созданием «зеркала») – это избыточное хранение данных. Поэтому его целесообразно использовать при небольших объемах данных как в нашем примере.
Второй способ также заключается в создании зеркала данных, однако здесь мы будем хранить данные только в одном поле. В поставленной задаче поиск осуществляется сразу по группе полей и мы попробуем объединить их в одно текстовое поле, разделив пробелами. Таким образом, целому набору данных в таблице users будет соответствовать одно единственное поле. Создадим таблицу search с двумя полями id и text. Id – будет соответствовать id основной таблицы (users), text – это наши «кэшированные» данные.
Синхронизация также осуществляется с помощью триггеров:
Добавление:
Изменение:
Удаление:
Поисковый запрос выглядит так:
Этот способ не такой гибкий как предыдущий, однако как мы увидим дальше он выигрывает в скорости при большом числе разнообразных запросов.
Третий способ основан на создании списка «ключевых слов» — поисковых тегов. Ключевые слова – это поля в таблице users. Например, для пользователя с полями
Синхронизация данных осуществляется также за счет триггеров:
Создание:
Изменение:
Удаление:
Поисковый запрос:
Обратите внимание, что если раньше релевантность определялась встроенным механизмом поиска MyISAM, то в этом случае ее определяем сами. В результате поиска мы получили только те теги, которые соответствуют запросу. И чем больше тегов одного пользователя, тем выше он в выборке.
Приведенный пример имеет недостаток: при равном числе тегов у нескольких записей происходит естественная сортировка, что не всегда верно с точки зрения релевантности.
Однако у этого метода есть высокий потенциал для дальнейшего развития. Во-первых, мы можем добавить в сортировку
Четвертый способ суров и не использует MyISAM как предыдущие. В нем также нет дополнительных таблиц и триггеров. Мы будем просто искать по существующей таблице. Для начала нам необходимо проиндексировать все поля, в которых будет осуществляться поиск.
В InnoDB поиск можем осуществлять только с помощью оператора LIKE, но для его эффективной работы необходимо разбить запрос на слова, иначе запросы, состоящие из нескольких слов, останутся без результата. Для разбиения на слова и составления запроса напишем функцию:
Функция возвращает нам фрагмент сформированного поискового запроса, который просто нужно подставить и выполнить:
Также можно использовать временные таблицы, они дадут ощутимое удобство при обработке результатов запроса.
Существует ряд сторонних решений для полнотекстового поиска. Наиболее популярные платформы это Sphinx и проекты на базе Apache Lucene. Их использование лишено смысла при небольших объемах данных (таких как в нашем примере), а иногда просто невозможно в связи с ограничениями (хостер, злой админ, кривые руки и т. д.).
Сравним показанные способы полнотекстового поиска (кроме сторонних решений) на скорость выполнения типовых запросов. Сравнивать будем на примере выполнения 50 запросов различной сложности. Для этого напишем PHP-скрипт, который будет объективно подсчитывать среднюю скорость выполнения поиска каждым из приведенных методов. Для того чтобы приблизить измерения к реальным условиям проведем второе контрольное измерение, в котором будут использованы те же самые поисковые запросы. Здесь можно будет оценить, насколько хорошо в каждом методе используются кэширующие механизмы MySQL.
Сравнение скорости выполнения поисковых запросов в базе данных MySQL в таблице InnoDB различными методами:
Подробнее:
Как и ожидалось, прямой LIKE поиск в InnoDB оказался самым медленным и существенно проигрывает всем остальным. Конечно этот способ еще можно оптимизировать, однако это вряд ли даст существенный выигрыш в скорости.
Три оставшихся метода поиска показали себя примерно на одном уровне. Как показала практика, при большом количестве одинаковых запросов ощутимое преимущество дает использование ключевых слов (тегов) в MyISAM. При большом количестве разнообразных поисковых запросов выигрыш дает второй способ – создание кэшированного зеркала. Если какие-то поля сильно отличаются по размеру от других(содержимое статьи, текст новости), то эффективнее показывает себя первый способ — создание таблицы-зеркала.
Создание MyISAM зеркал стоит применять для небольших таблиц (10-50 тыс записей в таблице), если записей в таблице больше, и позволяют технические возможности используйте сторонние механизмы (Sphinx, Apache Lucene).
Полнотекстовый поиск данных в InnoDB – это известная головная боль многих разработчиков под MySQL / InnoDB. Для тех, кто не в курсе дела я объясню. В типе таблиц MyISAM есть полноценный полнотекстовый поиск данных, однако сама таблица исторически имеет ограничения, которые являются принципиальными в отдельных проектах. В более «продвинутом» типе таблиц InnoDB полнотекстового поиска нет. Вот и приходится мириться бедным разработчикам либо с ограничениями MyISAM, либо с отсутствием поиска в InnoDB. Я хочу рассказать о том, какие есть способы организовать полноценный поиск в InnoDB без магии и исключительно штатными средствами. Также будет интересно сравнить скоростные характеристики каждого способа.
Для примера возьмем небольшую таблицу с 10000 записями.
CREATE TABLE users(
id INT(11) NOT NULL AUTO_INCREMENT,
login VARCHAR(255) DEFAULT NULL,
`password` VARCHAR(255) DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
surname VARCHAR(255) DEFAULT NULL,
email VARCHAR(255) NOT NULL,
country VARCHAR(255) DEFAULT NULL,
city VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (id)
)
ENGINE = INNODB
В этой таблице мы храним данные пользователей сайта. На самом сайте есть форма поиска пользователей, в которую можно ввести произвольный запрос вида «Толстой Ясная Поляна». Для обработки такого запроса поиск должен осуществляться сразу по нескольким полям. Нам нужен поиск для полей login, name, surname, city, country. Запрос может быть как одиночным словом (имя или город) или же в виде набора слов, разделенных пробелом. Проблема в том, что нам необходимо искать этот набор слов сразу по нескольким полям, что сложно сделать в InnoDB без использования дополнительных функций.
Есть несколько относительно простых способов полнотекстового поиска данных в InnoDB:
- С помощью таблицы-«зеркала» в MyISAM
- С помощью таблицы-«зеркала» в MyISAM с кэшированными данными
- С помощью таблицы из ключевых слов в MyISAM
- Разбора запроса и прямой поиск в InnoDB
- Использование сторонних решений
Рассмотрим каждый из них подробнее.
С помощью таблицы-«зеркала» в MyISAM
Первый предлагаемый способ заключается в создании дополнительной таблицы в MyISAM. Как известно MyISAM достаточно неплохо поддерживает полнотекстовый поиск и это можно использовать. В эту дополнительную таблицу будут копироваться все данные из основной таблицы (users). Синхронизация будет обеспечиваться за счет триггеров. В новой таблице добавим поля login, name, surname, city, country. Таким образом, мы создадим «зеркало» основной таблицы, и работать будем с ним. Для возможности полнотекстового поиска добавим туда FULLTEXT индекс по всем 5 полям вместе:
CREATE TABLE search(
id INT(11) DEFAULT NULL,
login VARCHAR(255) DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
surname VARCHAR(255) DEFAULT NULL,
country VARCHAR(255) DEFAULT NULL,
city VARCHAR(255) DEFAULT NULL,
FULLTEXT INDEX IX_search (city, country, login, name, surname)
)
ENGINE = MYISAM
Для синхронизации данных между основной таблицей и таблицей-«зеркалом» на users установим триггеры на запись, изменение и чтение:
Триггер на запись:
CREATE
TRIGGER `insert`
AFTER INSERT
ON users
FOR EACH ROW
BEGIN
INSERT INTO search (`id`,`login`,`name`,`surname`,`country`,`city` ) VALUES(
NEW.`id`,
NEW.`login`,
NEW.`name`,
NEW.`surname`,
NEW.`country`,
NEW.`city`
);
END
Триггер на изменение:
CREATE
TRIGGER `update`
AFTER UPDATE
ON users
FOR EACH ROW
BEGIN
DELETE FROM `search` WHERE `id`= NEW.`id`;
INSERT INTO `search` (`id`,`login`,`name`,`surname`,`country`,`city` ) VALUES(
NEW.`id`,
NEW.`login`,
NEW.`name`,
NEW.`surname`,
NEW.`country`,
NEW.`city`
);
END
И простой триггер на удаление:
CREATE
TRIGGER `delete`
AFTER DELETE
ON users
FOR EACH ROW
BEGIN
DELETE FROM `search` WHERE `id`= OLD.`id`;
END
Поиск осуществляется с помощью следующего запроса:
SELECT `users`.* FROM `users`
INNER JOIN `search`
ON `search`.`id` = `users`.`id`
WHERE
MATCH(`search`.city, `search`.country, `search`.login, `search`.name, `search`.surname) AGAINST (' Владимир Тупин Санкт-Петербург ' IN BOOLEAN MODE) >0
ORDER BY MATCH(`search`.city, `search`.country, `search`.login, `search`.name, `search`.surname) AGAINST (' Владимир Тупин Санкт-Петербург ' IN BOOLEAN MODE) DESC
Здесь поиск данных происходит в таблице search, результат сортируется по релевантности, и на выходе мы получаем соответствующие записи из таблицы users.
Главный плюс такого подхода — это гибкость поиска за счет добавления дополнительных индексов и составления новых комбинаций поиска (страна+город или логин + имя + фамилия). Таким образом, мы можем свободно формировать новые наборы для поиска и правила релевантности.
Минусы этого способа (как и всех способов с созданием «зеркала») – это избыточное хранение данных. Поэтому его целесообразно использовать при небольших объемах данных как в нашем примере.
С помощью таблицы-«зеркала» в MyISAM с кэшированными данными
Второй способ также заключается в создании зеркала данных, однако здесь мы будем хранить данные только в одном поле. В поставленной задаче поиск осуществляется сразу по группе полей и мы попробуем объединить их в одно текстовое поле, разделив пробелами. Таким образом, целому набору данных в таблице users будет соответствовать одно единственное поле. Создадим таблицу search с двумя полями id и text. Id – будет соответствовать id основной таблицы (users), text – это наши «кэшированные» данные.
CREATE TABLE search(
id INT(11) DEFAULT NULL,
`text` TEXT DEFAULT NULL,
FULLTEXT INDEX IX_search_text (`text`)
)
ENGINE = MYISAM
Синхронизация также осуществляется с помощью триггеров:
Добавление:
CREATE
TRIGGER `insert`
AFTER INSERT
ON users
FOR EACH ROW
BEGIN
INSERT INTO search (`id`, `text`) VALUES(NEW.`id`,
LOWER(
CONCAT_WS(' ',
NEW.`name`,
NEW.`surname`,
NEW.`login`,
NEW.`country`,
NEW.`city`
)
)
);
END
Изменение:
CREATE
TRIGGER `update`
AFTER UPDATE
ON users
FOR EACH ROW
BEGIN
DELETE FROM search WHERE `id` = NEW.`id`;
INSERT INTO search (`id`, `text`) VALUES(NEW.`id`,
LOWER(
CONCAT_WS(' ',
NEW.`name`,
NEW.`surname`,
NEW.`login`,
NEW.`country`,
NEW.`city`
)
)
);
END CREATE
Удаление:
TRIGGER `delete`
AFTER DELETE
ON users
FOR EACH ROW
BEGIN
DELETE FROM search WHERE `id` = OLD.`id`;
END
Поисковый запрос выглядит так:
SELECT `users`.* FROM `users`
INNER JOIN `search`
ON `search`.`id` = `users`.`id`
WHERE
MATCH(`search`.`text`) AGAINST ('Владимир Тупин Санкт-Петербург' IN BOOLEAN MODE) >0
ORDER BY MATCH(`search`.`text`) AGAINST ('Владимир Тупин Санкт-Петербург' IN BOOLEAN MODE) DESC
Этот способ не такой гибкий как предыдущий, однако как мы увидим дальше он выигрывает в скорости при большом числе разнообразных запросов.
С помощью таблицы из ключевых слов в MyISAM
Третий способ основан на создании списка «ключевых слов» — поисковых тегов. Ключевые слова – это поля в таблице users. Например, для пользователя с полями
(id=2144; login= leo; name=Лев;surname=Толстой;city=’Ясная Поляна’;country=Россия;email=leo@tolstoy.ru;password=;) ключевыми словами будут («leo»; «Лев»; «Толстой»; «Ясная Поляна»; «Россия»). Все эти слова мы будем записывать в отдельную таблицу MyISAM, в которой будут два поля id и text. Id соответствует id основной таблицы (users). А text – это поле, в которое будут записываться ключевые слова-теги. Каждому пользователю из таблицы users будут соответствовать 5 записей в новой таблице search. Таким образом, мы получили таблицу тегов каждого пользователя.CREATE TABLE search(
id INT(11) DEFAULT NULL,
`text` VARCHAR(255) DEFAULT NULL,
FULLTEXT INDEX IX_search_text (`text`)
)
ENGINE = MYISAM
Синхронизация данных осуществляется также за счет триггеров:
Создание:
CREATE
TRIGGER `insert`
AFTER INSERT
ON users
FOR EACH ROW
BEGIN
INSERT INTO search (`id`,`text`) VALUES
(NEW.`id`, NEW.`login`),
(NEW.`id`, NEW.`name`),
(NEW.`id`, NEW.`surname`),
(NEW.`id`, NEW.`country`),
(NEW.`id`, NEW.`city`);
END
Изменение:
CREATE
TRIGGER `update`
AFTER UPDATE
ON users
FOR EACH ROW
BEGIN
DELETE FROM search WHERE `id` = NEW.`id`;
INSERT INTO search (`id`,`text`) VALUES
(NEW.`id`, NEW.`login`),
(NEW.`id`, NEW.`name`),
(NEW.`id`, NEW.`surname`),
(NEW.`id`, NEW.`country`),
(NEW.`id`, NEW.`city`);
END
Удаление:
CREATE
TRIGGER `delete`
AFTER DELETE
ON users
FOR EACH ROW
BEGIN
DELETE FROM search WHERE `id` = OLD.`id`;
END
Поисковый запрос:
SELECT `users`.* FROM `users`
INNER JOIN `search`
ON `search`.`id` = `users`.`id`
WHERE
MATCH(`search`.`text`) AGAINST(' Владимир Тупин Санкт-Петербург ' IN BOOLEAN MODE) > 0
GROUP BY `search`.`id`
ORDER BY COUNT(*) DESC
Обратите внимание, что если раньше релевантность определялась встроенным механизмом поиска MyISAM, то в этом случае ее определяем сами. В результате поиска мы получили только те теги, которые соответствуют запросу. И чем больше тегов одного пользователя, тем выше он в выборке.
Приведенный пример имеет недостаток: при равном числе тегов у нескольких записей происходит естественная сортировка, что не всегда верно с точки зрения релевантности.
Однако у этого метода есть высокий потенциал для дальнейшего развития. Во-первых, мы можем добавить в сортировку
ORDER BY сумму оценок релевантностей от запроса MATCH AGAINST. Тем самым указанный выше недостаток будет устранен. Во-вторых, мы можем добавить в эту таблицу дополнительное поле веса тега weight, и каждому полю основной таблицы поставить в соответствие значение этого веса. Таким образом, мы можем добавить сортировку с учетом значимости (веса) отдельных полей. Это дает нам возможность делать акцент на каких то полях без ухудшения качества поиска. Разбора запроса и прямой поиск в InnoDB
Четвертый способ суров и не использует MyISAM как предыдущие. В нем также нет дополнительных таблиц и триггеров. Мы будем просто искать по существующей таблице. Для начала нам необходимо проиндексировать все поля, в которых будет осуществляться поиск.
CREATE TABLE users(
id INT(11) NOT NULL,
login VARCHAR(255) DEFAULT NULL,
`password` VARCHAR(255) DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
surname VARCHAR(255) DEFAULT NULL,
email VARCHAR(255) NOT NULL,
country VARCHAR(255) DEFAULT NULL,
city VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (id),
INDEX city (city),
INDEX country (country),
INDEX email (email),
INDEX login (login),
INDEX name (name),
INDEX password (password),
INDEX surname (surname)
)
ENGINE = INNODB
В InnoDB поиск можем осуществлять только с помощью оператора LIKE, но для его эффективной работы необходимо разбить запрос на слова, иначе запросы, состоящие из нескольких слов, останутся без результата. Для разбиения на слова и составления запроса напишем функцию:
CREATE
FUNCTION search(str VARCHAR(255))
RETURNS varchar(255) CHARSET cp1251
BEGIN
DECLARE output VARCHAR(255) DEFAULT '';
DECLARE temp_str VARCHAR(255);
DECLARE first_part VARCHAR(255) DEFAULT "CONCAT_WS(' ',`name`,`surname`,`login`,`country`,`city`) LIKE '%";
DECLARE last_part VARCHAR(255) DEFAULT "%'";
WHILE LENGTH(str) != 0 DO
SET temp_str = SUBSTRING_INDEX (str, ' ', 1);
IF temp_str = str
THEN
SET str = '';
ELSE
SET str = SUBSTRING(str, LENGTH(temp_str) + 2);
END IF;
IF output != ''
THEN
SET output = CONCAT(output, ' OR ');
END IF;
SET output = CONCAT(output, first_part, temp_str, last_part);
END WHILE;
RETURN output;
END
Функция возвращает нам фрагмент сформированного поискового запроса, который просто нужно подставить и выполнить:
SET @WHERE = CONCAT('SELECT * FROM `users` WHERE ', search ('Хабра Хабрович'));
PREPARE prepared FROM @WHERE;
EXECUTE prepared;
Также можно использовать временные таблицы, они дадут ощутимое удобство при обработке результатов запроса.
Использование сторонних решений
Существует ряд сторонних решений для полнотекстового поиска. Наиболее популярные платформы это Sphinx и проекты на базе Apache Lucene. Их использование лишено смысла при небольших объемах данных (таких как в нашем примере), а иногда просто невозможно в связи с ограничениями (хостер, злой админ, кривые руки и т. д.).
Сравнение
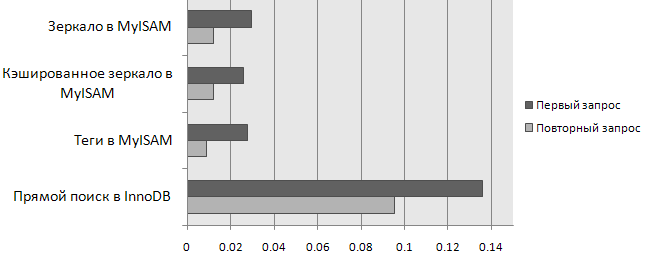
Сравним показанные способы полнотекстового поиска (кроме сторонних решений) на скорость выполнения типовых запросов. Сравнивать будем на примере выполнения 50 запросов различной сложности. Для этого напишем PHP-скрипт, который будет объективно подсчитывать среднюю скорость выполнения поиска каждым из приведенных методов. Для того чтобы приблизить измерения к реальным условиям проведем второе контрольное измерение, в котором будут использованы те же самые поисковые запросы. Здесь можно будет оценить, насколько хорошо в каждом методе используются кэширующие механизмы MySQL.
Сравнение скорости выполнения поисковых запросов в базе данных MySQL в таблице InnoDB различными методами:

Подробнее:
| Метод | Средняя скорость выполнения одного запроса (сек.) | Средняя скорость выполнения одного повторного запроса (сек.) |
| С помощью таблицы-«зеркала» в MyISAM | 0.029738 | 0.011974 |
| С помощью таблицы-«зеркала» в MyISAM с кэшированными данными | 0.025652 | 0.012027 |
| С помощью таблицы из ключевых слов в MyISAM | 0.027876 | 0.008866 |
| Разбора запроса и прямой поиск в InnoDB | 0.136091 | 0.09541 |
Как и ожидалось, прямой LIKE поиск в InnoDB оказался самым медленным и существенно проигрывает всем остальным. Конечно этот способ еще можно оптимизировать, однако это вряд ли даст существенный выигрыш в скорости.
Три оставшихся метода поиска показали себя примерно на одном уровне. Как показала практика, при большом количестве одинаковых запросов ощутимое преимущество дает использование ключевых слов (тегов) в MyISAM. При большом количестве разнообразных поисковых запросов выигрыш дает второй способ – создание кэшированного зеркала. Если какие-то поля сильно отличаются по размеру от других(содержимое статьи, текст новости), то эффективнее показывает себя первый способ — создание таблицы-зеркала.
Создание MyISAM зеркал стоит применять для небольших таблиц (10-50 тыс записей в таблице), если записей в таблице больше, и позволяют технические возможности используйте сторонние механизмы (Sphinx, Apache Lucene).
