В последнее время реляционные СУБД немного потеснены системами с альтернативными моделями данных. Отчасти это вызвано задачами повышения производительности за счет упрощения структур хранения. С другой стороны, идут поиски путей расширения выразительных средств, в том числе за счет перехода к более богатым информационным моделям. Ведь многие поняли, что повышения уровня абстракции предметной области на один порядок дает расширение сферы применения продукта в десятки раз и возможность занять многие смежные ниши, порой увеличивая количество клиентов в сотни и тысячи раз.
Первая часть: http://habrahabr.ru/blogs/sql/119317/
Реляционная, иерархическая, сетевая, ключ-значение и др. СУБД определяют лишь модель данных, в выборе же информационной модели (не путать с моделью данных) мы более свободны. В любом случае, будет требоваться декомпозиция и отображение элементов информационной модели в модель данных.
Например, классическая информационная модель IDEF1X состоит из таких элементов: сущность, атрибут, связь один-к-одному, связь один-ко-многим, связь многие-ко-многим, категоризация (связь один-к-одному-из). А реляционная модель данных RDBMS имеет только: таблица, поле, связь один-ко-многим. Сущность отображается в одну или несколько таблиц, все типы связей представляются как один-ко-многим (другого типа в подавляющем большинстве RDBMS просто нет), категоризация вводится способом, который я описал в первой части статьи.
Что же мешает поднять уровень абстракции? В первую очередь то, что разработчики вынуждены выносить часть информационной модели в приложение. А значит — фиксировать эту часть модели, теряя в гибкости настройки под предметную область. Решение этой проблемы мне видится во введении динамически интерпретируемых метамоделей, используемых параллельно с реляционным или другим хранилищем. Метамодели уменьшают неопределенность в описании предметной области и позволяют убрать из приложений «места привязки» и избавиться от жесткой фиксации на специфике задач.
Я постарался собрать большинство компонентов информационного моделирования, необходимых при разработке прикладных приложений. В конце первой части была схема:
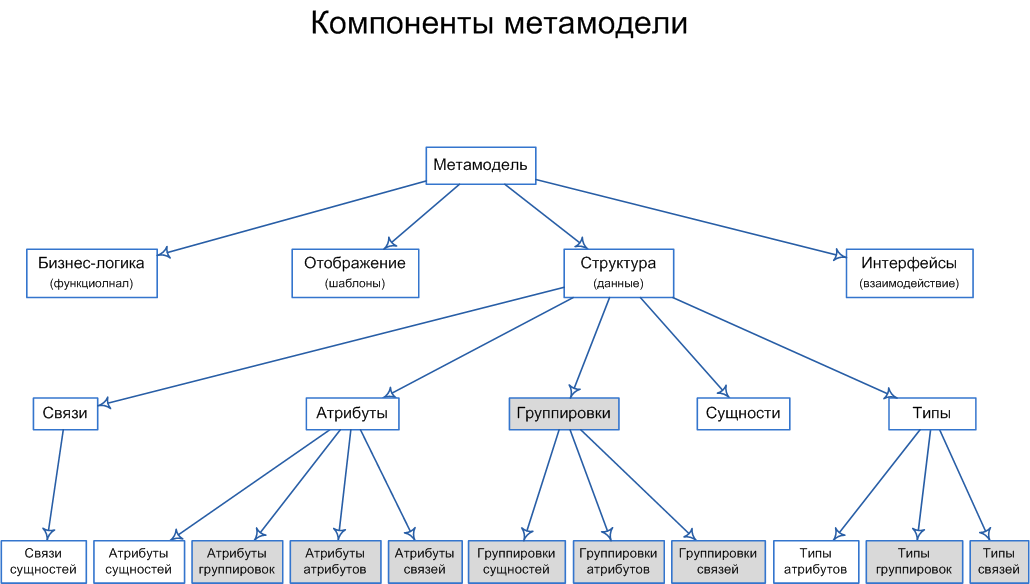
Теперь я объясню ее подробнее. В нижней строке схемы белым отмечены компоненты, присутствующие в реляционной молели данных, а серым — компоненты, требующие декомпозиции или метаописания для помещения в RDBMS. Рассмотрим их подробнее:
Группировки сущностей
Первое, чего часто не хватает — это возможность объединять сущности предметной области в группы.
Применение: сущности по своей природе могут быть не однородны, они относятся к разным уровням абстракции одной предметной области или же к разным предметным областям, обслуживаемым одной базой данных или же мы хотим выделить в предметной области несколько кластеров/зон.
Варианты решения: использование префиксов в именах таблиц, раскраска структур баз данных разными цветами, но чаще всего о группах «знает» непосредственно программное обеспечение, работающее с базой данных, группировки «зашиты» в код и модель без кода не полна.
Группировки атрибутов
Естественным, представляется группировка атрибутов сущностей в смысловые блоки, связанные функционально, семантически или относящиеся к разным аспектам моделирования сущностей.
Применение: например, бывает удобно сгруппировать поля, относящиеся к адресу (страна, город, улица, дом, индекс и т.д.) или два поля описывают один атрибут (как широта и долгота описывают атрибут «Координата»).
Варианты решения: введение префиксов в имена полей, перечисление полей по порядку, но в основном, этот аспект информационной модели «зашивается» в пользовательский интерфейс и мы видим, что модель не полна без интерфейса.
Группировки связей
Связи между таблицами не всегда именованы, поэтому группировка связей по именам практически не встречается, но есть задачи, к которых она крайне необходима.
Применение: пример #1 — люди перелинковыны многие-ко-многим через перекрестную таблицу и нам нужно выделить часть связей как «родственные», а часть как «дружественные» или «рабочие». Есть еще один распространенный случай (пример #2) группировок, когда есть несколько перекрестных таблиц многие-ко-многим, и нам нужно сгруппировать владельцев транспортных средств, владельцев недвижимости и владельцев домашних животных в несколько групп: бывшие владельцы, текущие владельцы и лица оспаривающие владение.
Варианты решения: для случая #1 — просто вводится флаг в перекрестной таблице или добавляется справочник групп связей. Для случая #2 — вводить одинаковые флаги и справочники для разных таблиц конечно можно, но хотелось бы потом одним запросом выбирать всех «текущих владельцев». Для этого мы можем применить абстрактную «свертку», как описано в первой части.
Атрибуты и типы группировок
Каждая из перечисленных выше группировок может иметь свои атрибуты и типы, это кажется вполне естественным. И для разных группировок имеется множество примеров и средств реализации.
Атрибуты связей
Связи между сущностями далеко не однородны, и уж точно не бинарны. Нам может потребоваться прикрепить к связям дату установления, силу связи или коэффициент доверия к информации, источник информации или пользователя (владельца связи) и другие атрибуты.
Применение: например, связь между специалистом и должностью может содержать дату вступления на должности и назначенный оклад.
Варианты решения: Для описания атрибутов связей мы обычно используем поля таблиц, описывающих сами сущности или поля таблиц-связок. То есть, уже приложение будет «знать» и «отличать» по имени поля, где атрибут сущности, а где атрибут связи.
Атрибуты атрибутов
Такая себе тавтология, но не такой уж и бред, если подумать, то во многих предметных областях атрибут сущности может иметь целый ряд собственных атрибутов.
Применение: например, показание датчика может быть дополнено оценкой погрешности, единицами изменения, временем снятия показаний, ссылкой на сотрудника, проводившего изменение или вносившего данные в систему.
Варианты решения: обычно делают просто два, три или более полей в одной таблице, а на уровне пользовательского интерфейса или приложения уже подразумевается, что одно поле является атрибутом другого.
Типы связей
Самым важным, на мой взгляд, компонентом информационной модели является тип связи между сущностями. Именно эта характеристика чаще всего «зашита» в приложение и пользовательский интерфейс, а иногда она вообще ни где не определена в явном виде и обрабатывается непосредственно пользователем, отнимая его внимание.
Применение: выделим несколько типов (далеко не полный список): один-к-одному, многие-ко-многим, связь со справочником, связь типа «Master-Detail», связь типа «контейнер» и т.д.
Варианты решения: связь со справочником может реализоваться в пользовательском интерфейсе в виде комбо-бокса или авто-инкрементного поля ввода; Master-Detail может быть реализована всплывающими окнами, несколькими гридами, древовидным гридом или комбо-боксом и гридом и еще многими способами. В зависимости от того, «какой» именно это «Master-Detail», например, можно выводить сгруппированный по датам лог, приобретенные товары или слабые связи — например, данные о поселении людей в номерах гостиницы. Если мы сравним связь между «гостиницей» и «номерами» со связью «номеров» с «постояльцами», то заметим, что номера являются неотъемлемой частью гостиницы, а вот с постояльцами связь более «мягкая», хотя и то и то можно назвать «Master-Detail». Вообще о классификации связей можно написать отдельную статью с приведением примеров структур баз данных и экранов приложений.
Таким образом, мы имеем целый ряд элементов информационной модели, которые помещаются в приложения, интерфейсы, шаблоны, по сути являясь частью модели. Вот для отделения их от чисто программных и системных решений и необходим слой метамодели. СУБД при этом используется как физическое хранилище двух уровней абстракции, как данных, так и метамодели. Динамическая интерпретация метамодели во время выполнения приложения позволяет связать несколько уровней абстракции в одно целое.
В третьей части, я планирую рассмотреть примеры применения метамодели в прикладных задачах.
Спасибо за внимание.
Первая часть: http://habrahabr.ru/blogs/sql/119317/
Реляционная, иерархическая, сетевая, ключ-значение и др. СУБД определяют лишь модель данных, в выборе же информационной модели (не путать с моделью данных) мы более свободны. В любом случае, будет требоваться декомпозиция и отображение элементов информационной модели в модель данных.
Например, классическая информационная модель IDEF1X состоит из таких элементов: сущность, атрибут, связь один-к-одному, связь один-ко-многим, связь многие-ко-многим, категоризация (связь один-к-одному-из). А реляционная модель данных RDBMS имеет только: таблица, поле, связь один-ко-многим. Сущность отображается в одну или несколько таблиц, все типы связей представляются как один-ко-многим (другого типа в подавляющем большинстве RDBMS просто нет), категоризация вводится способом, который я описал в первой части статьи.
Что же мешает поднять уровень абстракции? В первую очередь то, что разработчики вынуждены выносить часть информационной модели в приложение. А значит — фиксировать эту часть модели, теряя в гибкости настройки под предметную область. Решение этой проблемы мне видится во введении динамически интерпретируемых метамоделей, используемых параллельно с реляционным или другим хранилищем. Метамодели уменьшают неопределенность в описании предметной области и позволяют убрать из приложений «места привязки» и избавиться от жесткой фиксации на специфике задач.
Я постарался собрать большинство компонентов информационного моделирования, необходимых при разработке прикладных приложений. В конце первой части была схема:
Теперь я объясню ее подробнее. В нижней строке схемы белым отмечены компоненты, присутствующие в реляционной молели данных, а серым — компоненты, требующие декомпозиции или метаописания для помещения в RDBMS. Рассмотрим их подробнее:
Группировки сущностей
Первое, чего часто не хватает — это возможность объединять сущности предметной области в группы.
Применение: сущности по своей природе могут быть не однородны, они относятся к разным уровням абстракции одной предметной области или же к разным предметным областям, обслуживаемым одной базой данных или же мы хотим выделить в предметной области несколько кластеров/зон.
Варианты решения: использование префиксов в именах таблиц, раскраска структур баз данных разными цветами, но чаще всего о группах «знает» непосредственно программное обеспечение, работающее с базой данных, группировки «зашиты» в код и модель без кода не полна.
Группировки атрибутов
Естественным, представляется группировка атрибутов сущностей в смысловые блоки, связанные функционально, семантически или относящиеся к разным аспектам моделирования сущностей.
Применение: например, бывает удобно сгруппировать поля, относящиеся к адресу (страна, город, улица, дом, индекс и т.д.) или два поля описывают один атрибут (как широта и долгота описывают атрибут «Координата»).
Варианты решения: введение префиксов в имена полей, перечисление полей по порядку, но в основном, этот аспект информационной модели «зашивается» в пользовательский интерфейс и мы видим, что модель не полна без интерфейса.
Группировки связей
Связи между таблицами не всегда именованы, поэтому группировка связей по именам практически не встречается, но есть задачи, к которых она крайне необходима.
Применение: пример #1 — люди перелинковыны многие-ко-многим через перекрестную таблицу и нам нужно выделить часть связей как «родственные», а часть как «дружественные» или «рабочие». Есть еще один распространенный случай (пример #2) группировок, когда есть несколько перекрестных таблиц многие-ко-многим, и нам нужно сгруппировать владельцев транспортных средств, владельцев недвижимости и владельцев домашних животных в несколько групп: бывшие владельцы, текущие владельцы и лица оспаривающие владение.
Варианты решения: для случая #1 — просто вводится флаг в перекрестной таблице или добавляется справочник групп связей. Для случая #2 — вводить одинаковые флаги и справочники для разных таблиц конечно можно, но хотелось бы потом одним запросом выбирать всех «текущих владельцев». Для этого мы можем применить абстрактную «свертку», как описано в первой части.
Атрибуты и типы группировок
Каждая из перечисленных выше группировок может иметь свои атрибуты и типы, это кажется вполне естественным. И для разных группировок имеется множество примеров и средств реализации.
Атрибуты связей
Связи между сущностями далеко не однородны, и уж точно не бинарны. Нам может потребоваться прикрепить к связям дату установления, силу связи или коэффициент доверия к информации, источник информации или пользователя (владельца связи) и другие атрибуты.
Применение: например, связь между специалистом и должностью может содержать дату вступления на должности и назначенный оклад.
Варианты решения: Для описания атрибутов связей мы обычно используем поля таблиц, описывающих сами сущности или поля таблиц-связок. То есть, уже приложение будет «знать» и «отличать» по имени поля, где атрибут сущности, а где атрибут связи.
Атрибуты атрибутов
Такая себе тавтология, но не такой уж и бред, если подумать, то во многих предметных областях атрибут сущности может иметь целый ряд собственных атрибутов.
Применение: например, показание датчика может быть дополнено оценкой погрешности, единицами изменения, временем снятия показаний, ссылкой на сотрудника, проводившего изменение или вносившего данные в систему.
Варианты решения: обычно делают просто два, три или более полей в одной таблице, а на уровне пользовательского интерфейса или приложения уже подразумевается, что одно поле является атрибутом другого.
Типы связей
Самым важным, на мой взгляд, компонентом информационной модели является тип связи между сущностями. Именно эта характеристика чаще всего «зашита» в приложение и пользовательский интерфейс, а иногда она вообще ни где не определена в явном виде и обрабатывается непосредственно пользователем, отнимая его внимание.
Применение: выделим несколько типов (далеко не полный список): один-к-одному, многие-ко-многим, связь со справочником, связь типа «Master-Detail», связь типа «контейнер» и т.д.
Варианты решения: связь со справочником может реализоваться в пользовательском интерфейсе в виде комбо-бокса или авто-инкрементного поля ввода; Master-Detail может быть реализована всплывающими окнами, несколькими гридами, древовидным гридом или комбо-боксом и гридом и еще многими способами. В зависимости от того, «какой» именно это «Master-Detail», например, можно выводить сгруппированный по датам лог, приобретенные товары или слабые связи — например, данные о поселении людей в номерах гостиницы. Если мы сравним связь между «гостиницей» и «номерами» со связью «номеров» с «постояльцами», то заметим, что номера являются неотъемлемой частью гостиницы, а вот с постояльцами связь более «мягкая», хотя и то и то можно назвать «Master-Detail». Вообще о классификации связей можно написать отдельную статью с приведением примеров структур баз данных и экранов приложений.
Таким образом, мы имеем целый ряд элементов информационной модели, которые помещаются в приложения, интерфейсы, шаблоны, по сути являясь частью модели. Вот для отделения их от чисто программных и системных решений и необходим слой метамодели. СУБД при этом используется как физическое хранилище двух уровней абстракции, как данных, так и метамодели. Динамическая интерпретация метамодели во время выполнения приложения позволяет связать несколько уровней абстракции в одно целое.
В третьей части, я планирую рассмотреть примеры применения метамодели в прикладных задачах.
Спасибо за внимание.
