
Если ваш веб проект так или иначе будет связан с поиском и предоставлением пользователям некоторых данных, то перед вами наверняка встанет задача реализации строки поиска. При этом, если в проекте по какой-либо причине не удастся использовать технологии умных сервисов как Google или Яндекс, то поиск частично или полностью придется реализовать самостоятельно. Одной из подзадач наверняка будет реализация нечеткого поиска, ведь пользователи часто ошибаются и иногда не знают точных терминов, названий или имен.
В данной статье описывается возможная реализация нечеткого поиска, которая была применена для поиска на сайте edatuda.ru.
Задача
В рамках создания сервиса нашего по поиску ресторанов, кафе и баров возникла задача по реализации строки поиска, в которой пользователи могли бы указывать названия интересующих их заведений.
Задача ставилась следующим образом:
- Результаты поиска должны выводиться в процессе набора в выпадающем списке.
- Поиск должен учитывать возможные ошибки и опечатки пользователей (например mcdonalds так и хочется набрать как macdonalds).
- Для каждого заведения должна быть возможность задавать множество синонимов (например mcdonalds => макдак).
Визуальное представление пунктов 1-3:
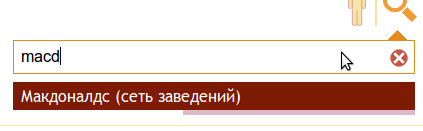
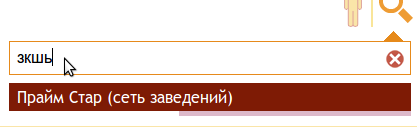
Таким образом, получив фразу запроса, скорее всего обрезанную, нужно выбрать из заранее собранного словаря наиболее близкие по написанию записи. По сути задача сводилась к исправлению опечаток, которое умеют выполнять современные поисковые системы. Одни из распространенных методов ее решения:
- Метод, основанный на построении n-граммного индекса.
Неплохой, простой и быстрый метод. - Метод, основанный на расстоянии редактирования.
Наверно, один из самых точных методов, который не учитывает контекст. - Объединение п.1 и п.2.
Для ускорения поиска на больших словарях имеет смысл сначала выбрать группу слов на основании n-граммного индекса с последующим применением п.2 (см. работу Цобеля и Дарта “Finding approximate matches in large lexicons”)
На хабре была хорошая статья, посвященная нечеткому поиску в тексте и словаре. В ней хорошо описаны п.1 и п. 2., в частности расстояния Левенштейна и Дамерау-Левенштейна с симпатичными картинками. Поэтому в данной статье подробного описания этих методов приводиться не будет.
Реализация поиска
В нашем случае словарь не такой большой (как например у поисковиков), порядка нескольких тысяч записей, поэтому мы решили использовать метод на основании расстояния редактирования без построения n-граммного индекса.
Обычные алгоритмы вычисления расстояния редактирования хорошо оценивают близость строк, но не используют никакой информации о символах (кроме их равенства или неравенства), такой как расстояние между клавишами соответствующих символам на клавиатуре или близость по звучанию.
Учет расстояния между клавишами может быть полезен так как при быстром наборе большое число ошибок происходит из-за промахов, при этом вероятность, что пользователь случайно нажал на соседнюю клавишу выше чем на более удаленную.
Учет фонетических правил тоже важен. Например, в случае с иностранными именами и названиями, пользователи часто не знают точного написания слов, но помнят их звучание.
В работе Цобеля и Дарта “Phonetic string matching: lessons from information retrieval” описывается метод сравнения строк объединяющий вычисление расстояния редактирования с набором фонетических правил (фраза “фонетические правила” не совсем корректна). Авторы выделили несколько фонетических групп, состоящих из символов, таких, чтобы “стоимость” замены символов одной группы при вычислении расстояния редактирования была ниже чем “стоимость“ замены символов не принадлежащих одной группе. Мы использовали эту идею.
В качестве базового алгоритма мы взяли алгоритм Вагнера-Фишера адаптированный для нахождения расстояния Дамерау-Левенштейна с несколькими модификациями:
- В базовом алгоритме “стоимость” всех операций равна 1. Мы задали, что “стоимость” операций вставки и удаления — 2, операции обмена — 1, а операции замены одного символа другим вычисляется следующим образом: если клавиши, соответствующие сравниваемым символам, расположены рядом на клавиатуре или сравниваемые символы принадлежат одной фонетической группе, то “стоимость” замены — 1, иначе 2.
- В качестве результата возвращается префиксное расстояние, т.е. минимальное расстояние между словом запроса и всеми префиксами слова из словаря. Это нужно, т.к. слова запроса, которые мы будем сравнивать со словарными формами, как правило, будут обрезаны. Т.е. мы можем сравнивать введенное пользователем “макд” со словарным “макдональдс” и получить большое расстояние (7 операций вставки), хотя “макдональдс” в данном случае очень точно соответствует запросу.
Фонетические группы мы взяли из упомянутой выше работы, с небольшими изменениями:
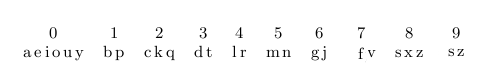
В исходной работе группы составлялись на основании звучания оригинальных английских слов, поэтому нет гарантии, что они будут показывать хороший результат на транслитерированном русском тексте. Мы сделали небольшие изменения (например убрали ‘p’ из оригинальной группы “fpv”) на основании собственных наблюдений.
Полученная реализация на c++:
{{{ class EditDistance { public: int DamerauLevenshtein(const std::string& user_str, const std::string& dict_str) { size_t user_sz = user_str.size(); size_t dict_sz = dict_str.size(); for (size_t i = 0; i <= user_sz; ++i) { trace_[i][0] = i << 1; } for (size_t j = 1; j <= dict_sz; ++j) { trace_[0][j] = j << 1; } for (size_t j = 1; j <= dict_sz; ++j) { for (size_t i = 1; i <= user_sz; ++i) { // Учтем вставки, удаления и замены int rcost = ReplaceCost(user_str[i - 1], dict_str[j - 1]); int dist0 = trace_[i - 1][j] + 2; int dist1 = trace_[i][j - 1] + 2; int dist2 = trace_[i - 1][j - 1] + rcost; trace_[i][j] = std::min(dist0, std::min(dist1, dist2)); // Учтем обмен if (i > 1 && j > 1 && user_str[i - 1] == dict_str[j - 2] && user_str[i - 2] == dict_str[j - 1]) { trace_[i][j] = std::min(trace_[i][j], trace_[i - 2][j - 2] + 1); } } } // Возьмем минимальное // префиксное расстояние int min_dist = trace_[user_sz][0]; for (size_t i = 1; i <= dict_sz; ++i) { if (trace_[user_sz][i] < min_dist) min_dist = trace_[user_sz][i]; } return min_dist; } private: const static size_t kMaxStrLength = 255; int trace_[kMaxStrLength + 1][kMaxStrLength + 1]; private: int ReplaceCost(unsigned char first, unsigned char second); } }}}
Учтем, что в коротких словах пользователи, как правило, делают не такие грубые ошибки, как в длинных. Для этого сделаем порог максимально допустимого расстояния между словами пропорциональным длине слова запроса.
{{{ const double kMaxDistGrad = 1 / 3.0; ... uint32_t dist = distance_.DamerauLevenshtein(word, dict_form); if (dist <= (word.size() * kMaxDistGrad)) { // ok } }}}
Индекс
Пусть исходные записи по заведениям имеют вид:
<мета данные: id,...><название заведения><синонимичные формы названия>
Тогда индекс можно представить следующим образом:

- places — мета данные по заведениям, которые являются результатом поиска.
- places_index — названия и их синонимичные формы, ссылающиеся на конкретные заведения; по сути это просто массив ссылок на places.
- words_index — слова, выделенные из всех форм; это что-то вроде инвертированного индекса вида: <слово><places_index0, places_index1,...>; в случае небольшого словаря его можно организовать в виде массива массивов.
Во время поиска нужно будет пройти по всему массиву words_index для каждого слова запроса пользователя. Если словарь слишком большой, то, предположив, что ошибки в первой букве довольно редкие, можно ограничиться формами, начинающимися на ту же букву, что и слово запроса.
Боремся за полноту
Для увеличения полноты найденных заведений мы применили еще пару идей.
- При наборе, пользователи часто забывают переключить раскладку клавиатуры, (часто можно увидеть запросы вида: “ghfqv”, “vfrljy”,..). Поэтому возникла идея в случае, если при обычном поиске не было найдено ни одного заведения, производить такой же поиск с запросом, сформированным из символов противоположной раскладки базового запроса.
- Многие заведения не имеют русских названий, но пользователи привыкли набирать их кириллицей. Для таких заведений как McDonalds, Starbucks и др. кириллические формы названий, очевидно, можно занести в словарь как синонимы. Но для некоторых, как например GQ Bar, не целесообразно порождать синонимы типа “GQ бар”, и при этом необходимо, чтобы заведение соответствовало запросу “бар”. Поэтому для кириллических запросов в дополнение к обычному формируется дополнительный транслитерированный запрос.
{{{ // Ищем базовую форму фразы FindPhrase(base_phrase, &suggested); // И ее транслитерированную форму // если она отличается от базовой. std::string trs_phrase = Transliterate(base_phrase); if (trs_phrase != base_phrase) FindPhrase(trs_phrase, &suggested); // Если не получилось ничего найти // попробуем найти фразу из символов // противоположной раскладки if (suggested.empty()) { std::string invert_phrase = InvertForm(base_phrase); FindPhrase(invert_phrase, &suggested); } }}}
Общая реализация
Вся логика индексирования и поиска реализовывалась в c++ демоне. Данные о заведениях периодически перечитываются из базы, индекс при этом полностью перестраивается. Общение с фронт-энд скриптами осуществляется по HTTP через GET запросы, результаты передаются в теле ответа в json формате. Получилась следующая схема:

В результате при ~2.5 тыс. уникальных слов время поиска в среднем составило ~8 мс.
Ссылки
- Сайт проекта. edatuda.ru
- Расстояние Левенштейна. ru.wikipedia.org/wiki/Расстояние_Левенштейна
- Расстояние Дамерау-Левенштейна. en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance
- Работа Цобеля и Дарта. “Finding approximate matches in large lexicons”. citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.14.3856&rep=rep1&type=pdf
- Работа Цобеля и Дарта. “Phonetic string matching: lessons from information retrieval” citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.18.2138&rep=rep1&type=pdf
