Существует несколько десятков файловых систем, все из них предоставляют пользовательские интерфейсы для хранения данных. Каждая из систем хороша по-своему. Однако, в наш век высоких нагрузок и петабайтов данных для обработки, оказалось довольно непросто подыскать то, что нужно, стоит лишь задуматься о распределенных данных, распределенных нагрузках, множественном монтировании rw и о прочих кластерных прелестях.
Задача: организовать распределенное файловое хранилище
— без самосборных ядер, модулей, патчей,
— с возможностью множественного монтирования в режиме rw,
— POSIX совместимость,
— отказоустойчивость,
— совместимость с уже использующимися технологиями,
— разумный overhead по I/O операциям по сравнению с локальными файловыми системами,
— простота конфигурации, обслуживания и администрирования.
В работе мы используем Proxmox и контейнерную виртуализацию OpenVZ. Это удобно, это летает, у этого решения больше плюсов, чем у аналогичных продуктов. По крайней мере для наших проектов и в наших реалиях.
Сам storage везде монтируется по FC.
У нас был успешный опыт использования данной файловой системы, решили сначала попробовать ее. Proxmox с недавнего времени перешел на редхатовское ядро, в нем поддержка ocfs2 выключена. Модуль в ядре есть, но на форумах openvz и proxmox не рекомендуют его задействовать. Мы попробовали и пересобрали ядро. Модуль версии 1.5.0, кластер из 4 железных машин на базе debian squeeze, proxmox 2.0beta3, ядро 2.6.32-6-pve. Для тестов использовался stress. Проблемы за несколько лет остались те же самые. Все завелось, настройка данной связки занимает полчаса от силы. Однако, под нагрузкой кластер может самопроизвольно развалиться, что ведет к тотальному kernel panic на всех серверах сразу. За сутки тестов машины перезагружались в общей сложности пять раз. Это лечится, но доводить такую систему до работоспособного состояния довольно тяжело. Пришлось также пересобирать ядро и включать ocfs2. Минус.
Хоть ядро и редхатовское, модуль по умолчанию включен, завестись мы и здесь так и не смогли. Все дело в proxmox, которые со второй версии придумали свой кластер с шахматами и поэтессами для хранения своих конфигов. Там cman, corosync и прочие пакеты из gfs2-tools, только все пересобранные специально для pve. Оснастка для gfs2, таким образом, из пакетов просто так не ставится, так как предлагает сначала снести весь proxmox, что мы сделать не могли. За три часа зависимости удалось победить, но все опять закончилось kernel panic. Попытка приспособить пакеты для proxmox для решения наших проблем успехом не увенчалась, после двух часов было принято решение отказаться от этой идеи.
Остановились пока на ней.
POSIX совместимая, высокая скорость работы, отличная масштабируемость, несколько смелых и интересных подходов в реализации.
Файловая система состоит из следующих компонентов:

1. Клиенты. Пользователи данных.
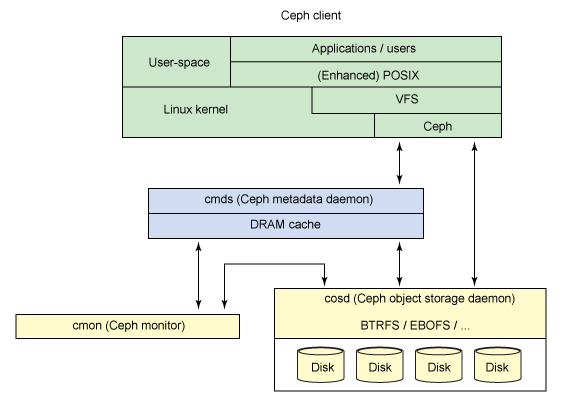
2. Сервера метаданных. Кэшируют и синхронизируют распределенные метаданные. С помощью метаданных клиент в любой промежуток времени знает, где находятся нужные ему данные. Также сервера метаданных выполняют распределение новых данных.
3. Кластер хранения объектов. Здесь в виде объектов хранятся как данные, так и метаданные.
4. Кластерные мониторы. Осуществляют мониторинг здоровья всей системы в целом.
Фактический файловый ввод/вывод происходит между клиентом и кластером хранения объектов. Таким образом, управление высокоуровневыми функциями POSIX (открытие, закрытие и переименование) осуществляется с помощью серверов метаданных, а управление обычными функциями POSIX (чтение и запись) осуществляется непосредственно через кластер хранения объектов.
Любых компонентов может быть несколько, в зависимости от стоящих перед администратором задач.
Файловая система может быть подключена как напрямую, с помощью модуля ядра, так через FUSE. С точки зрения пользователя, файловая система Ceph является прозрачной. Они просто имеют доступ к огромной системе хранения данных и не осведомлены об используемых для этого серверах метаданных, мониторах и отдельных устройствах, составляющих массивный пул системы хранения данных. Пользователи просто видят точку монтирования, в которой могут быть выполнены стандартные операции файлового ввода / вывода. С точки зрения администратора имеется возможность прозрачно расширить кластер, добавив сколько угодно необходимых компонентов, мониторов, хранилищ, серверов метаданных.
Разработчики гордо называют Ceph экосистемой.
GPFS, Lustre и прочие файловые системы, а также надстройки, мы не рассматривали в этот раз, они либо очень сложны в настройке, либо не развиваются, либо не подходят по заданию.
Конфигурация стандартная, все взято из Ceph wiki. В целом файловая система оставила приятные впечатления. Собран массив 2Тб, пополам из SAS и SATA дисков (экспорт блочных устройств по FC), партиции в ext3.
Ceph storage примонтирован внутрь 12-и виртуальных машин на 4 hardware nodes, осуществляется чтение-запись со всех точек монтирования. Четвертые сутки стресс-тестов проходят нормально, I/O выдается в среднем 75 мб/с. на запись по пику.
Мы пока не рассматривали остальные функции Ceph (а их осталось еще довольно много), также есть проблемы с FUSE. Но хотя разработчики предупреждают, что система экспериментальная, что ее не стоит использовать в production, мы считаем, что если очень хочется, то можно -_-
Прошу всех заинтересованных, а также всех сочувствующих, в личку. Тема очень интересная, ищем единомышленников, чтобы обсудить возникшие проблемы и найти способы их решения.
Ссылки:
— http://ru.wikipedia.org/wiki/Ceph
— сайт проекта
— краткий обзор, используемый при написании данной статьи
Задача: организовать распределенное файловое хранилище
— без самосборных ядер, модулей, патчей,
— с возможностью множественного монтирования в режиме rw,
— POSIX совместимость,
— отказоустойчивость,
— совместимость с уже использующимися технологиями,
— разумный overhead по I/O операциям по сравнению с локальными файловыми системами,
— простота конфигурации, обслуживания и администрирования.
В работе мы используем Proxmox и контейнерную виртуализацию OpenVZ. Это удобно, это летает, у этого решения больше плюсов, чем у аналогичных продуктов. По крайней мере для наших проектов и в наших реалиях.
Сам storage везде монтируется по FC.
OCFS2
У нас был успешный опыт использования данной файловой системы, решили сначала попробовать ее. Proxmox с недавнего времени перешел на редхатовское ядро, в нем поддержка ocfs2 выключена. Модуль в ядре есть, но на форумах openvz и proxmox не рекомендуют его задействовать. Мы попробовали и пересобрали ядро. Модуль версии 1.5.0, кластер из 4 железных машин на базе debian squeeze, proxmox 2.0beta3, ядро 2.6.32-6-pve. Для тестов использовался stress. Проблемы за несколько лет остались те же самые. Все завелось, настройка данной связки занимает полчаса от силы. Однако, под нагрузкой кластер может самопроизвольно развалиться, что ведет к тотальному kernel panic на всех серверах сразу. За сутки тестов машины перезагружались в общей сложности пять раз. Это лечится, но доводить такую систему до работоспособного состояния довольно тяжело. Пришлось также пересобирать ядро и включать ocfs2. Минус.
GFS2
Хоть ядро и редхатовское, модуль по умолчанию включен, завестись мы и здесь так и не смогли. Все дело в proxmox, которые со второй версии придумали свой кластер с шахматами и поэтессами для хранения своих конфигов. Там cman, corosync и прочие пакеты из gfs2-tools, только все пересобранные специально для pve. Оснастка для gfs2, таким образом, из пакетов просто так не ставится, так как предлагает сначала снести весь proxmox, что мы сделать не могли. За три часа зависимости удалось победить, но все опять закончилось kernel panic. Попытка приспособить пакеты для proxmox для решения наших проблем успехом не увенчалась, после двух часов было принято решение отказаться от этой идеи.
CEPH
Остановились пока на ней.
POSIX совместимая, высокая скорость работы, отличная масштабируемость, несколько смелых и интересных подходов в реализации.
Файловая система состоит из следующих компонентов:
1. Клиенты. Пользователи данных.
2. Сервера метаданных. Кэшируют и синхронизируют распределенные метаданные. С помощью метаданных клиент в любой промежуток времени знает, где находятся нужные ему данные. Также сервера метаданных выполняют распределение новых данных.
3. Кластер хранения объектов. Здесь в виде объектов хранятся как данные, так и метаданные.
4. Кластерные мониторы. Осуществляют мониторинг здоровья всей системы в целом.
Фактический файловый ввод/вывод происходит между клиентом и кластером хранения объектов. Таким образом, управление высокоуровневыми функциями POSIX (открытие, закрытие и переименование) осуществляется с помощью серверов метаданных, а управление обычными функциями POSIX (чтение и запись) осуществляется непосредственно через кластер хранения объектов.
Любых компонентов может быть несколько, в зависимости от стоящих перед администратором задач.
Файловая система может быть подключена как напрямую, с помощью модуля ядра, так через FUSE. С точки зрения пользователя, файловая система Ceph является прозрачной. Они просто имеют доступ к огромной системе хранения данных и не осведомлены об используемых для этого серверах метаданных, мониторах и отдельных устройствах, составляющих массивный пул системы хранения данных. Пользователи просто видят точку монтирования, в которой могут быть выполнены стандартные операции файлового ввода / вывода. С точки зрения администратора имеется возможность прозрачно расширить кластер, добавив сколько угодно необходимых компонентов, мониторов, хранилищ, серверов метаданных.
Разработчики гордо называют Ceph экосистемой.
GPFS, Lustre и прочие файловые системы, а также надстройки, мы не рассматривали в этот раз, они либо очень сложны в настройке, либо не развиваются, либо не подходят по заданию.
Конфигурация и тестирование
Конфигурация стандартная, все взято из Ceph wiki. В целом файловая система оставила приятные впечатления. Собран массив 2Тб, пополам из SAS и SATA дисков (экспорт блочных устройств по FC), партиции в ext3.
Ceph storage примонтирован внутрь 12-и виртуальных машин на 4 hardware nodes, осуществляется чтение-запись со всех точек монтирования. Четвертые сутки стресс-тестов проходят нормально, I/O выдается в среднем 75 мб/с. на запись по пику.
Мы пока не рассматривали остальные функции Ceph (а их осталось еще довольно много), также есть проблемы с FUSE. Но хотя разработчики предупреждают, что система экспериментальная, что ее не стоит использовать в production, мы считаем, что если очень хочется, то можно -_-
Прошу всех заинтересованных, а также всех сочувствующих, в личку. Тема очень интересная, ищем единомышленников, чтобы обсудить возникшие проблемы и найти способы их решения.
Ссылки:
— http://ru.wikipedia.org/wiki/Ceph
— сайт проекта
— краткий обзор, используемый при написании данной статьи
