Comments 41
Хочу предложить другую идею.
1) Найти все замкнутые контуры.
2) Для каждого контура рассмотреть область, которую он ограничивает, и посчитать ее центр масс и центральные моменты второго порядка.
3) По формулам с той же страницы на википедии можно посчитать числа Θ, λ1 и λ2. Две лямбды — это длины полуосей эллипса, а Θ — это угол поворота главной оси. Кроме того, центр масс (x, y) будет определять центр эллипса. Понятно, что числа Θ, λ1, λ2, x, y однозначно задают эллипс.
4) Далее нужно проверить, насколько контур действительно похож на эллипс. Можно, например, посмотреть сколько пикселей принадлежит эллипсу, но не принадлежит контуру, или наоборот. Есть некоторый простор для фантазии и экспериментов.
5) Если контур действительно похож на эллипс, добавляем его к результату.
Я бы рекомендовал вам для таких целей пользоваться библиотекой OpenCV. В ней есть все вам необходимое:
* Алгоритм Canny.
* Адаптивный порог
* Поиск замкнутых контуров
* Вычисление моментов дял контура
*… и многое другое. Полная документация доступна онлайн.
P.S.: 1 секунда на изображение 700x700 — многовато. Думаю, при грамотной реализации можно было бы выдавать как минимум 30 кадров в секунду даже на слабом компьютере.
1) Найти все замкнутые контуры.
2) Для каждого контура рассмотреть область, которую он ограничивает, и посчитать ее центр масс и центральные моменты второго порядка.
3) По формулам с той же страницы на википедии можно посчитать числа Θ, λ1 и λ2. Две лямбды — это длины полуосей эллипса, а Θ — это угол поворота главной оси. Кроме того, центр масс (x, y) будет определять центр эллипса. Понятно, что числа Θ, λ1, λ2, x, y однозначно задают эллипс.
4) Далее нужно проверить, насколько контур действительно похож на эллипс. Можно, например, посмотреть сколько пикселей принадлежит эллипсу, но не принадлежит контуру, или наоборот. Есть некоторый простор для фантазии и экспериментов.
5) Если контур действительно похож на эллипс, добавляем его к результату.
Я бы рекомендовал вам для таких целей пользоваться библиотекой OpenCV. В ней есть все вам необходимое:
* Алгоритм Canny.
* Адаптивный порог
* Поиск замкнутых контуров
* Вычисление моментов дял контура
*… и многое другое. Полная документация доступна онлайн.
P.S.: 1 секунда на изображение 700x700 — многовато. Думаю, при грамотной реализации можно было бы выдавать как минимум 30 кадров в секунду даже на слабом компьютере.
На данный момент передо мной стоит преграда: у меня не получается нормально работать с OpenCV через Java (именно на ней я всё и реализовывал). А вообще, надо попробовать сделать это на Python/Qt + OpenCV, потому что мне тоже кажется, что производительность хромает (а так гордо я выставил эту цифру, потому что изначально она у меня равнялась ~2800ms).
У меня у самого огромная куча идей по реализации, но я упираюсь в то, что более-менее владею только одним языком, к которому легко получается рисовать GUI. Нужно сделать вообще на C++/Qt, но это мне надо будет С++ учить, а я пока и в Java путаюсь.
У меня у самого огромная куча идей по реализации, но я упираюсь в то, что более-менее владею только одним языком, к которому легко получается рисовать GUI. Нужно сделать вообще на C++/Qt, но это мне надо будет С++ учить, а я пока и в Java путаюсь.
JavaCV и флаг вам в руки. Я так же как и вы рассуждал когда по одному проекту вдруг пришлось вспоминать C# и писать на нем с применением OpenCV. Решение — найти биндинг под C# (для оного EMGU показался самым адекватным) ну и вперед к победе…
JavaCV насколько я помню самый адекватный биндинг OpenCV. Необходимый вам функционал он поддерживает, так что… желаю удачи вобщем
JavaCV насколько я помню самый адекватный биндинг OpenCV. Необходимый вам функционал он поддерживает, так что… желаю удачи вобщем

А я-то думал, зачем Вы задавали вопрос (http://habrahabr.ru/qa/14837/) про скопления точек…
Опасно с рэндомом так вольготно поступать… Насчёт детектирования — могу попробовать переделать под эллипсы один забавный алгоритм и статейку сделать тут коротенькую(обычно я окружности этим алгоритмом выцепляю, но думаю что он применим при малых приближениях). Вроде на Хабре его не было. Если интересно — скиньте картинок 10 для тестов.

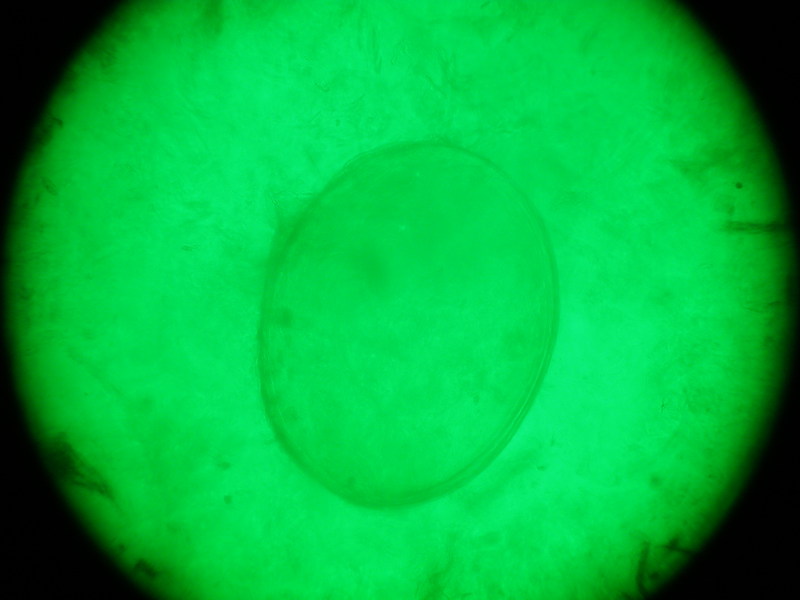
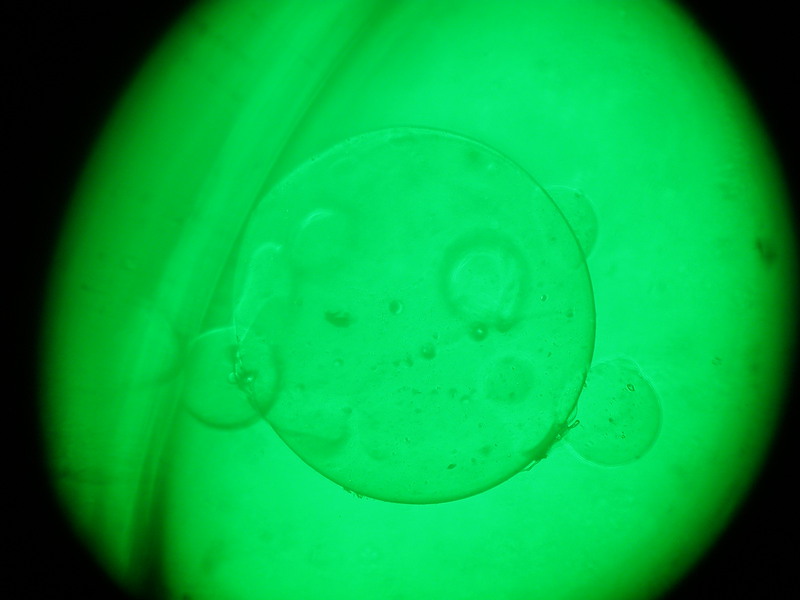
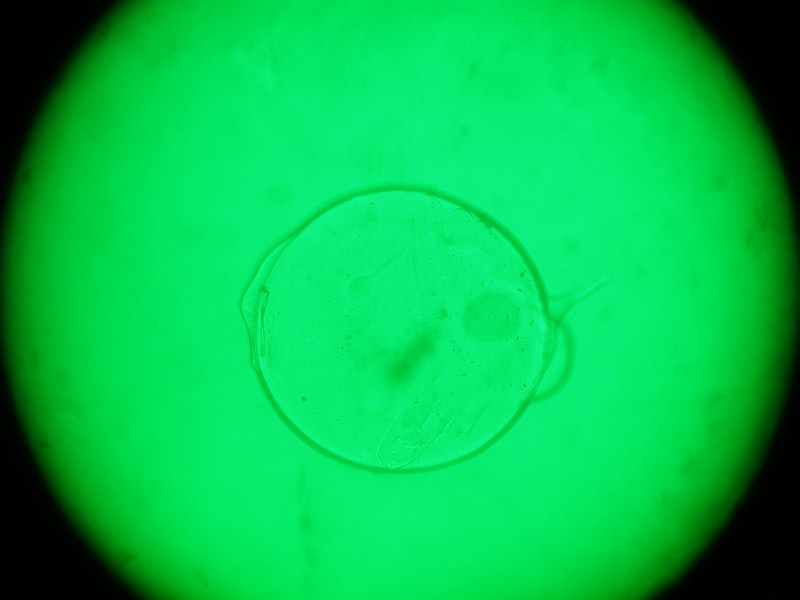
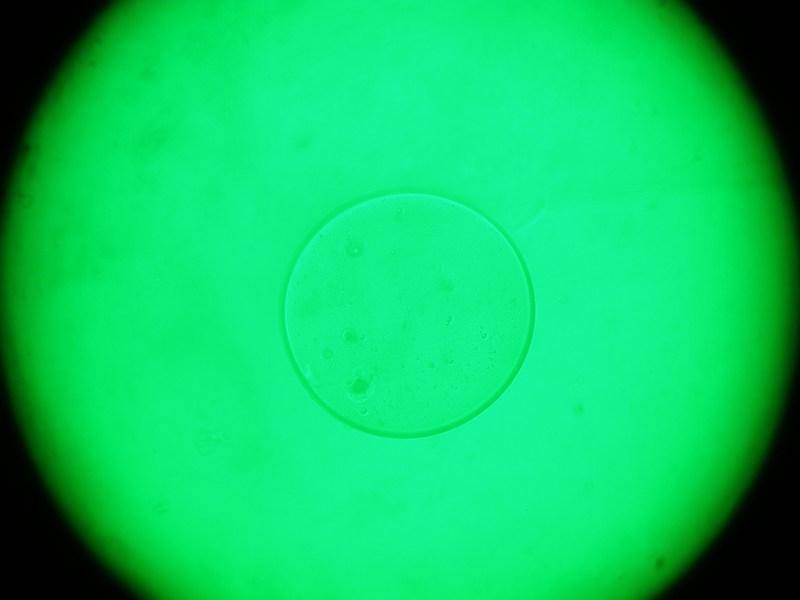


Я считаю, вы должны сделать проверку: после того, как вы нашли параметры эллипса, берете на нем 30 равномерно распределенных точек. Вокруг каждой точки формируется кружочек, и в нем (на исходном изображении) ищется линия (фрагмент эллипса, который будет фактически прямой линией) заданного направления. Если линия не найдена хотя бы в 3-5 точках, значит эллипс найден неверно.
Проверку наличия линии можно проводить таким образом: проводим 3 линии (там, где должна пройти граница и 2 параллельных сбоку от нее) и проверяем наличие контраста между ними (т.е по центру светлая неразрывная линия, с краев темные, или наоборот).
Алгоритмы отптического распознавания надо обязательно проверять независимой проверкой. Посмотрите, например, на результат алгоритма адаптивной бинаризации — он превратил читаемую картинку в кашу, и ваша поправка с яркостью — не более, чем костыль. Если таким алгоритмы не тестировать и перепроверять, они дают ошибки. Ваш алгоритм, на мой взгляд, при отсутствии подобных проверок, очень склонен к этому. что, например, будет, если подать на вход бледную картинку? Яркую? С 2 эллиплами? С половиной эллипса? С линиями? С шумом? Если речь идет о медицине или научной работе, необходимо высокое качество результата.
Вообще, бинаризация, на мой взгляд это плохо — надо просто работать хотя бы с градациями серого ( в идеале с 3 цветами, но там получается более сложно) — так как бинаризация теряет много информации и искажает изображения (попробуйте бинаризовать например мелкий сканированный шрифт — поймете, о чем я говорю — бинаризованное изображение букв часто не читается даже человеком, что уж говорить о примитивных алгоритмах).
Проверку наличия линии можно проводить таким образом: проводим 3 линии (там, где должна пройти граница и 2 параллельных сбоку от нее) и проверяем наличие контраста между ними (т.е по центру светлая неразрывная линия, с краев темные, или наоборот).
Алгоритмы отптического распознавания надо обязательно проверять независимой проверкой. Посмотрите, например, на результат алгоритма адаптивной бинаризации — он превратил читаемую картинку в кашу, и ваша поправка с яркостью — не более, чем костыль. Если таким алгоритмы не тестировать и перепроверять, они дают ошибки. Ваш алгоритм, на мой взгляд, при отсутствии подобных проверок, очень склонен к этому. что, например, будет, если подать на вход бледную картинку? Яркую? С 2 эллиплами? С половиной эллипса? С линиями? С шумом? Если речь идет о медицине или научной работе, необходимо высокое качество результата.
Вообще, бинаризация, на мой взгляд это плохо — надо просто работать хотя бы с градациями серого ( в идеале с 3 цветами, но там получается более сложно) — так как бинаризация теряет много информации и искажает изображения (попробуйте бинаризовать например мелкий сканированный шрифт — поймете, о чем я говорю — бинаризованное изображение букв часто не читается даже человеком, что уж говорить о примитивных алгоритмах).
Вот это самая развернутая критика из всех, что я пока слышал, спасибо!
Мне тоже не нравится, что я не придумал проверку, и пока спасаюсь тем, что провожу несколько (9 раз, потому что картинки идут с микроскопа с интервалом в 10 секунд, а время обработки одной — 1000мс) измерений одной и той же картинки. Если отклонения большие, то результат считается браком. Но это ведь тоже неправильно…
В данном случае я воспользовался тем, что с приборов картинка идет почти всегда с одинаковой яркостью, шумом и интенсивностью.
Если два эллипса, то определится, очевидно, самый большой из них (по физическим размерам), но заранее известно, что эллипс только один. Если их два — то нужно снимать два максимума с распыления координат.
В общем, тут полно размышлений и определенно есть над чем подумать — точно!
Мне тоже не нравится, что я не придумал проверку, и пока спасаюсь тем, что провожу несколько (9 раз, потому что картинки идут с микроскопа с интервалом в 10 секунд, а время обработки одной — 1000мс) измерений одной и той же картинки. Если отклонения большие, то результат считается браком. Но это ведь тоже неправильно…
В данном случае я воспользовался тем, что с приборов картинка идет почти всегда с одинаковой яркостью, шумом и интенсивностью.
Если два эллипса, то определится, очевидно, самый большой из них (по физическим размерам), но заранее известно, что эллипс только один. Если их два — то нужно снимать два максимума с распыления координат.
В общем, тут полно размышлений и определенно есть над чем подумать — точно!
На самом деле если взять ваш рандом и то что описано у egorinsk, то получится ни что иное как RANSAC. Метод проверки эллипса по определенным параметрам может быть сумма расстояний до ближайших черных точек (В MATLAB функция bwdist и еще несколько строк). У правильных параметров эта сумма будет максимальной.
Что касается нахождения центра по вашему методу, то надежней будет mean-shift algorithm.
Что касается нахождения центра по вашему методу, то надежней будет mean-shift algorithm.
А почему эллипс строится по 6 точкам? Уравнение ведь однородное. Для кривой второго порядка всегда хватало 5 точек, коэффициенты ищутся решением однородного уравнения. В качестве шестой точки есть смысл добавить точку, которая эллипсу заведомо не примнадлежит, и записать для нее F(x,y)=1 — тогда придется решать более привычное неоднородное уравнение. А если действительно нужен точный результат, то нужно брать все точки, лежащие вдоль линии приблизительно найденного эллипса (лучше бы с весами), и подать их на вход метода наименьших квадратов. Он позволит определить параметры с точностью до десятых долей пикселя (а то и точнее).
Извините, сейчас начал читать комментарии, и по-глупости начал снизу.
Оригинальное решение — своеобразная вариация преобразований Хафа.
Кстати, как вариант — для получения нулевых приближений — можно было бы использовать именно преобразования Хафа для выделения окружностей. В итоге получаем 3D-массив данных «координаты центра — радиус». Проекция массива на плоскость координат даст приблизительные положения центров эллипсов; положение максимумов вдоль координаты радиусов — приблизительные полуоси эллипса. А уточнить параметры можно было бы, разбив соответствующие этим параметрам контуры на 4 части: (-π/2, π/2), (3π/2, 5π/2), (π/2, 3π/2), (-3π/2, -π/2) и аппроксимируя методом наименьших квадратов.
Кстати, как вариант — для получения нулевых приближений — можно было бы использовать именно преобразования Хафа для выделения окружностей. В итоге получаем 3D-массив данных «координаты центра — радиус». Проекция массива на плоскость координат даст приблизительные положения центров эллипсов; положение максимумов вдоль координаты радиусов — приблизительные полуоси эллипса. А уточнить параметры можно было бы, разбив соответствующие этим параметрам контуры на 4 части: (-π/2, π/2), (3π/2, 5π/2), (π/2, 3π/2), (-3π/2, -π/2) и аппроксимируя методом наименьших квадратов.
Да, если считать в полярных координатах, можно за несколько итераций уточнить параметры эллипса.
Нет, мы получим, в лучшем случае яркие линии эволют эллипсов (четырехугольные «звездочки» — сжатые астроиды). Может быть, будут пики в фокусах. Но распознавать их и объединять в эллипсы — задачка не проще исходной.
Какого размера 3D массив обычно используют в этих преобразованиях?
Какого размера 3D массив обычно используют в этих преобразованиях?
Какого размера 3D массив обычно используют в этих преобразованиях?
В зависимости от желаемой точности: предварительные массивы можно строить с шагом, скажем, в 10 пикселей по всем направлениям. Тогда для картинки XxY пикселей получим (X/10)·(Y/10)·(sqrt(X^2+Y^2)/10) — всего порядка 22.5МБ для картинки 2Кх2К.
Вот только окружности/эллипсы, центры которых не лежат на изображении, а радиусы — больше диагонали изображения, мы так не определим.
Более точные (с шагом даже в 1 пиксель) преобразования Хафа уже для больших изображений на обычных компьютерах не построишь: памяти не хватит. Разве что сразу писать данные в файл, а затем вместо памяти работать с файлом (или делать mmap и надеяться, что ядро позаботится о «подчистке» неиспользуемых областей памяти).
Но это — вечная проблема методов обработки данных: либо метод не является требовательным к объему памяти, но сильно жрет вычислительные ресурсы, либо он работает довольно быстро, но требует уйму памяти.
Мне сейчас нужно искать центры шахматной доски 2*2 (повернута под неизвестным углом в 3D, известно только, что отношение яркостей черного и белого больше двойки). От обилия возможностей просто голова крУгом, и не знаю, с чего начать. То ли распознавать отрезки. То ли искать точку с нулевым градиентом и отрицательной гауссовой кривизной. То ли строить производные по x и y и искать — что? Полюсы комплекснозначной функции? В общем, весело :)
Размер картинки — примерно 10K*4K, размер участков, которые надо искать — от 15*15 :)
Для начала нужно будет определиться с положением доски на изображении, чтобы выделить область интереса как можно точнее (иначе оперативки просто не хватит).
В этом случае проще построить преобразования Хафа для поиска прямых, выделить границы между ячейками, а затем, составив простейшую систему уравнений, методом наименьших квадратов найти матрицу координатных преобразований.
Вот, кстати, пример: картинка с грубо выявленными прямыми («на глаз» щелкал по максимумам преобразования Хафа, если сделать хотя бы бикубическую аппроксимацию, получим более точно), ее преобразование Хафа и то же преобразование в 3D.
{kind=link}
{kind=link}
{kind=link}
Разбить картинку на перекрывающиеся фрагменты и искать прямые в каждом из них… Тоже вариант, спасибо.
Как насчет такой идеи:
Взять пиксель, посмотреть, в окружности, к примеру, 5 пикселей есть ли пиксели похожие по цвету. Если нет взять соседний пиксель (можно перепрыгнуть через 5 пикселей)
Если в окружности 5 пикселей есть похожие пиксели — найти границу группы пикселей.
Если эта группа — фрагмент нашей доски — по соседству мы найдем еще три граничащие группы однотонных пикселей. Если это просто фоновое пятно — аналогичных пятен рядом мы не найдем. Там где мы проверяли на окружность 5 пикс можно уже не искать — там заведомо ничего нет.
Затем нужно выявить форму этого пятна, очистив от посторонних шумов. Посмотреть, кругообразно ли оно или вытянуто. Если кругообразно — находим примерный центр, вычисляем расстояние до границы, увеличиваем его вдвое и смотрим какие пиксели лежат в этом удвоенном удалении от предпологаемого центра первой области. Если первую область мы нашли верно — на этом удвоенном расстоянии мы найдем центр следующей области, то есть довольно большое пятно однотонных пикселей. Опять находим их границу и сравниваем форму с первой. Если приблизительно подходит, проверяем, примыкают ли эти 2 области, затем ищем еще 2 области.
Если форма первой области скорее вытянута, чем кругообразна — значит соседняя шахматная область должна находить на одном из концов первой области. Проверяем на группу схожих пикселей оба конца, смотрим на форму, сравниваем с первой, ищем еще 2.
Взять пиксель, посмотреть, в окружности, к примеру, 5 пикселей есть ли пиксели похожие по цвету. Если нет взять соседний пиксель (можно перепрыгнуть через 5 пикселей)
Если в окружности 5 пикселей есть похожие пиксели — найти границу группы пикселей.
Если эта группа — фрагмент нашей доски — по соседству мы найдем еще три граничащие группы однотонных пикселей. Если это просто фоновое пятно — аналогичных пятен рядом мы не найдем. Там где мы проверяли на окружность 5 пикс можно уже не искать — там заведомо ничего нет.
Затем нужно выявить форму этого пятна, очистив от посторонних шумов. Посмотреть, кругообразно ли оно или вытянуто. Если кругообразно — находим примерный центр, вычисляем расстояние до границы, увеличиваем его вдвое и смотрим какие пиксели лежат в этом удвоенном удалении от предпологаемого центра первой области. Если первую область мы нашли верно — на этом удвоенном расстоянии мы найдем центр следующей области, то есть довольно большое пятно однотонных пикселей. Опять находим их границу и сравниваем форму с первой. Если приблизительно подходит, проверяем, примыкают ли эти 2 области, затем ищем еще 2 области.
Если форма первой области скорее вытянута, чем кругообразна — значит соседняя шахматная область должна находить на одном из концов первой области. Проверяем на группу схожих пикселей оба конца, смотрим на форму, сравниваем с первой, ищем еще 2.
Извините, сейчас начал просматривать комментарии, и по-глупости начал снизу.
С уравнением эллипса вы чего-то напутали. Эллипс задается пятью точками; шесть точек могут и не лежать на одном эллипсе (точнее — конике, кривой второго порядка). Коэффициенты ведь в уравнении берутся с точностью до пропорциональности. Поэтому находить надо не шесть коэффициентов, а пять — например свободный можно принять равным единице.
Поэтому мне интересно, как вы умудрились построить эллипс по шести точкам: подробности — в студию! :-)
Поэтому мне интересно, как вы умудрились построить эллипс по шести точкам: подробности — в студию! :-)
Строго говоря, эллипс задаётся вообще трёмя точками, но нам нужно абсолютное положение эллипса на картинке, потому что пользователь хочет видеть полученный результат. А иначе нам и угол поворота был бы не нужен. Но действительно, шестая точка нужна только для того, чтобы найти параметр F, который входит в выражения для нахождения координат центра.
Я обязательно распишу, как считались параметры уравнения кривой второго порядка в моём методе.
Я обязательно распишу, как считались параметры уравнения кривой второго порядка в моём методе.
Так, стоп. Что за бред? Пятью точками задаётся эллипс задаётся целиком, я вам ответственно как математик заявляю :-)
Все те абстрактные параметры, которые вы перечислили: абсолютное положение на картинке, угол поворота: они все получаются из тех шести коэффициентов, которые участвуют в уравнении кривой второго порядка. А шесть коэффициентов восстанавливаются по пяти точкам, а никак не по шести. А коэффициент F найти точно нельзя никак: если шестёрка (A, B, C, D, E, F) является коэффициентами эллипса, то и шестёрка (kA, kB, kC, kD, kE, kF) для любого ненулевого k тоже будет шестёркой коэффициентов эллипса.
Хотите аналогию? Прямая — кривая первого порядка — имеет уравнение Ax + By + C = 0. Однако для восстановления её коэффициентов нужно две, а не три точки, не так ли?
А восстановление коэффициентов по пяти точкам делается очень просто: выписывается система из пяти линейных уравнений, и находится её решение, например, методом Гаусса. Вы должны были делать как-то так.
Все те абстрактные параметры, которые вы перечислили: абсолютное положение на картинке, угол поворота: они все получаются из тех шести коэффициентов, которые участвуют в уравнении кривой второго порядка. А шесть коэффициентов восстанавливаются по пяти точкам, а никак не по шести. А коэффициент F найти точно нельзя никак: если шестёрка (A, B, C, D, E, F) является коэффициентами эллипса, то и шестёрка (kA, kB, kC, kD, kE, kF) для любого ненулевого k тоже будет шестёркой коэффициентов эллипса.
Хотите аналогию? Прямая — кривая первого порядка — имеет уравнение Ax + By + C = 0. Однако для восстановления её коэффициентов нужно две, а не три точки, не так ли?
А восстановление коэффициентов по пяти точкам делается очень просто: выписывается система из пяти линейных уравнений, и находится её решение, например, методом Гаусса. Вы должны были делать как-то так.
Метод Гаусса систему из пяти однородных уравнений над шестью неизвестными не решает. Его надо хорошо модифицировать, например, учитывая положение ступеньки в приведенной матрице. А проще посчитать пять миноров 5х5 — они сразу дадут коэффициенты. Шестью точками уравнение эллипса задается. Но только если пять из этих точек лежат на эллипсе, а шестая — не лежит.
А то, что шесть точек на эллипсе должны удовлетворять теореме Паскаля — да, есть такой факт…
А то, что шесть точек на эллипсе должны удовлетворять теореме Паскаля — да, есть такой факт…
Метод Гаусса систему из пяти однородных уравнений над шестью неизвестными не решает. Его надо хорошо модифицировать, например, учитывая положение ступеньки в приведенной матрице.
Я, когда говорил про метод Гаусса, имел в виду следующее. Ясно же из постановки задачи, что (0, 0) на эллипсе не лежит? Наверное, поэтому F != 0. Стало быть сделаем F равным 1 насильно и получим обычную систему из пяти неоднородных уравнений над пятью переменными, которая Гауссом решается на ура. Это эквивалентно подсчёту миноров 5 x 5.
Ну а по поводу того, сколько точек задают эллипс.
Шестью точками уравнение эллипса задается. Но только если пять из этих точек лежат на эллипсе, а шестая — не лежит.
Ну и какое же условие даёт шестая точка? То, что Ax^2 + Bxy + Cy^2 + Dx + Ey + F != 0? Казалось бы, оно бессмысленно — разве что проверить с помощью него коэффициенты.
Мы же говорим про количество точек n, такое что через любые n точек (общего положения) проходит единственная коника, не так ли? Я действительно не понимаю, как автор смог использовать шестую точку.
Фразы автора топика вида:
Если точки расположены слишком близко друг к другу, то через заданные шесть точек можно провести как минимум два эллипса с одинаковой достоверностью. Поэтому выбираемые шесть точек должны лежать как можно дальше друг от друга. Плюс, заведомо лежать на эллипсе.
радуют, но тем не менее выдают с головой, что в теме ему пока есть что поучить :-)
Ну и какое же условие даёт шестая точка? То, что Ax^2 + Bxy + Cy^2 + Dx + Ey + F != 0? Казалось бы, оно бессмысленно — разве что проверить с помощью него коэффициенты.
Да, имелось в виду условие Ax^2 + Bxy + Cy^2 + Dx + Ey + F = 1, которое можно использовать для нормировки. Про точку (0,0) есть сомнения: если мы выбираем точки случайно, то они вполне могут попасть на конику, проходящую через (0,0) — и при решении системы придется делить на 0. Лучше уж взять центр масс пяти точек. Но и для него нельзя гарантировать, что он вне кривой…
Да, имелось в виду условие Ax^2 + Bxy + Cy^2 + Dx + Ey + F = 1, которое можно использовать для нормировки. Про точку (0,0) есть сомнения: если мы выбираем точки случайно, то они вполне могут попасть на конику, проходящую через (0,0) — и при решении системы придется делить на 0. Лучше уж взять центр масс пяти точек. Но и для него нельзя гарантировать, что он вне кривой…
Тем не менее, вероятность этого события, как говорил один известный рунет-персонаж, крайне мала. Предполагается ведь, что точки всё-таки берутся с эллипса (по постановке задачи), а вот эллипс (0, 0) никак не заденет.
Я так подумал, то что вы сказали про пять миноров — это круто. Я бы, если бы писал, нормировал бы по свободному коэффициенту — а это может отрицательно сказаться на точности. Ваш метод гораздо в этом плане круче.
В общем, вопрос исчерпан.
Я так подумал, то что вы сказали про пять миноров — это круто. Я бы, если бы писал, нормировал бы по свободному коэффициенту — а это может отрицательно сказаться на точности. Ваш метод гораздо в этом плане круче.
В общем, вопрос исчерпан.
Какой интересный велосипед вместо RANSAC…
Почему вместо оперирования большим количеством центров не проверить где расположены эти 6 точек? Если по разные стороны от предполагаемого центра — значит это искомый эллипс, если с одной стороны — посмотреть что с контрастом на противоположной стороне предполагаемого эллипса (если в некотором радиусе от границы эллипса исключительно пиксели фона — эллипс ошибочен, а если в отдалении ± пиксель темных точек в разы больше чем, скажем, ± 5 пикселей — значит эллипс найден верно)
Ну или сразу для любой комбинации предполагаемых точек эллипса проверять еще 5 точек в случайной части эллипса? Эсли точки заведомо фоновые — ошибка, если часть из них могут быть границе эллипса — проверяем еще на, ну 50 точек. Прошла проверка — эллипс нашли
Насколько действенный вариант?
Ну или сразу для любой комбинации предполагаемых точек эллипса проверять еще 5 точек в случайной части эллипса? Эсли точки заведомо фоновые — ошибка, если часть из них могут быть границе эллипса — проверяем еще на, ну 50 точек. Прошла проверка — эллипс нашли
Насколько действенный вариант?
Sign up to leave a comment.
Детектирование эллиптических частиц на микрофотографии. Новый алгоритм поиска эллипсов на изображении