 Давным-давно, когда я был ещё наивным школьником, мне вдруг стало жутко любопытно: а каким же волшебным образом данные в архивах занимают меньше места? Оседлав свой верный диалап, я начал бороздить просторы Интернетов в поисках ответа, и нашёл множество статей с довольно подробным изложением интересующей меня информации. Но ни одна из них тогда не показалась мне простой для понимания — листинги кода казались китайской грамотой, а попытки понять необычную терминологию и разнообразные формулы не увенчивались успехом.
Давным-давно, когда я был ещё наивным школьником, мне вдруг стало жутко любопытно: а каким же волшебным образом данные в архивах занимают меньше места? Оседлав свой верный диалап, я начал бороздить просторы Интернетов в поисках ответа, и нашёл множество статей с довольно подробным изложением интересующей меня информации. Но ни одна из них тогда не показалась мне простой для понимания — листинги кода казались китайской грамотой, а попытки понять необычную терминологию и разнообразные формулы не увенчивались успехом.Поэтому целью данной статьи является дать представление о простейших алгоритмах сжатия тем, кому знания и опыт пока ещё не позволяют сходу понимать более профессиональную литературу, или же чей профиль и вовсе далёк от подобной тематики. Т.е. я «на пальцах» расскажу об одних из простейших алгоритмах и приведу примеры их реализации без километровых листингов кода.
Сразу предупрежу, что я не буду рассматривать подробности реализации процесса кодирования и такие нюансы, как эффективный поиск вхождений строки. Статья коснётся только самих алгоритмов и способов представления результата их работы.
RLE — компактность единообразия
Алгоритм RLE является, наверное, самым простейшим из всех: суть его заключается в кодировании повторов. Другими словами, мы берём последовательности одинаковых элементов, и «схлопываем» их в пары «количество/значение». Например, строка вида «AAAAAAAABCCCC» может быть преобразована в запись вроде «8×A, B, 4×C». Это, в общем-то, всё, что надо знать об алгоритме.
Пример реализации
Допустим, у нас имеется набор неких целочисленных коэффициентов, которые могут принимать значения от 0 до 255. Логичным образом мы пришли к выводу, что разумно хранить этот набор в виде массива байт:
unsigned char data[] = { 0, 0, 0, 0, 0, 0, 4, 2, 0, 4, 4, 4, 4, 4, 4, 4, 80, 80, 80, 80, 0, 2, 2, 2, 2, 255, 255, 255, 255, 255, 0, 0 };
Для многих гораздо привычней будет видеть эти данные в виде hex-дампа:
0000: 00 00 00 00 00 00 04 02 00 04 04 04 04 04 04 040010: 50 50 50 50 00 02 02 02 02 FF FF FF FF FF 00 00Подумав, мы решили, что хорошо бы для экономии места как-то сжимать такие наборы. Для этого мы проанализировали их и выявили закономерность: очень часто попадаются подпоследовательности, состоящие из одинаковых элементов. Конечно же, RLE для этого подойдёт как нельзя кстати!
Закодируем наши данные, используя свежеполученные знания: 6×0, 4, 2, 0, 7×4, 4×80, 0, 4×2, 5×255, 2×0.
Пришло время как-то представить наш результат в понятном компьютеру виде. Для этого, в потоке данных мы должны как-то отделять одиночные байты от кодируемых цепочек. Поскольку весь диапазон значений байта используется нашими данными, то просто так выделить какие-либо диапазоны значений под наши цели не удастся.
Есть как минимум два выхода из этой ситуации:
- В качестве индикатора сжатой цепочки выделить одно значение байта, а в случае коллизии с реальными данными экранировать их. Например, если использовать в «служебных» целях значение 255, то при встрече этого значения во входных данных мы вынуждены будем писать «255, 255» и после индикатора использовать максимум 254.
- Структурировать закодированные данные, указывая количество не только для повторяемых, но и последующих далее одиночных элементов. Тогда мы будем заранее знать, где какие данные.
Первый способ в нашем случае не кажется эффективным, поэтому, пожалуй, прибегнем ко второму.
Итак, теперь у нас имеется два вида последовательностей: цепочки одиночных элементов (вроде «4, 2, 0») и цепочки одинаковых элементов (вроде «0, 0, 0, 0, 0, 0»). Выделим в «служебных» байтах один бит под тип последовательности: 0 — одиночные элементы, 1 — одинаковые. Возьмём для этого, скажем, старший бит байта.
В оставшихся 7 битах мы будем хранить длины последовательностей, т.е. максимальная длина кодируемой последовательности — 127 байт. Мы могли бы выделить под служебные нужды, допустим, два байта, но в нашем случае такие длинные последовательности встречаются крайне редко, поэтому проще и экономичней просто разбивать их на более короткие.
Получается, в выходной поток мы будем писать сперва длину последовательности, а далее либо одно повторяемое значение, либо цепочку неповторяемых элементов указанной длины.
Первое, что должно броситься в глаза — при таком раскладе у нас есть парочка неиспользуемых значений. Не может быть последовательностей с нулевой длиной, поэтому мы можем увеличить максимальную длину до 128 байт, отнимая от длины единицу при кодировании и прибавляя при декодировании. Таким образом, мы можем кодировать длины от 1 до 128 вместо длин от 0 до 127.
Второе, что можно заметить — не бывает последовательностей одинаковых элементов единичной длины. Поэтому, от значения длины таких последовательностей при кодировании мы будем отнимать ещё единичку, увеличив тем самым их максимальную длину до 129 (максимальная длина цепочки одиночных элементов по-прежнему равна 128). Т.е. цепочки одинаковых элементов у нас могут иметь длину от 2 до 129.
Закодируем наши данные снова, но теперь уже и в понятном для компьютера виде. Будем записывать служебные байты как [T|L], где T — тип последовательности, а L — длина. Будем сразу учитывать, что длины мы записываем в изменённом виде: при T=0 отнимаем от L единицу, при T=1 — двойку.
[1|4], 0, [0|2], 4, 2, 0, [1|5], 4, [1|2], 80, [0|0], 0, [1|2], 2, [1|3], 255, [1|0], 0
Попробуем декодировать наш результат:
- [1|4]. T=1, значит следующий байт будет повторяться L+2 (4+2) раз: 0, 0, 0, 0, 0, 0.
- [0|2]. T=0, значит просто читаем L+1 (2+1) байт: 4, 2, 0.
- [1|5]. T=1, повторяем следующий байт 5+2 раз: 4, 4, 4, 4, 4, 4, 4.
- [1|2]. T=1, повторяем следующий байт 2+2 раз: 80, 80, 80, 80.
- [0|0]. T=0, читаем 0+1 байт: 0.
- [1|2]. T=1, повторяем байт 2+2 раз: 2, 2, 2, 2.
- [1|3]. T=1, повторяем байт 3+2 раз: 255, 255, 255, 255, 255.
- [1|0]. T=1, повторяем байт 0+2 раз: 0, 0.
А теперь последний шаг: сохраним полученный результат как массив байт. Например, пара [1|4], упакованная в байт, будет выглядеть вот так:
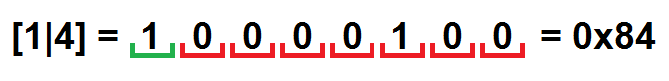
В итоге получаем следующее:
0000: 84 00 02 04 02 00 85 04 82 80 00 00 82 02 83 FF
0010: 80 00
Таким вот нехитрым образом на данном примере входных данных мы из 32 байт получили 18. Неплохой результат, особенно если учесть, что на более длинных цепочках он может оказаться гораздо лучше.
Возможные улучшения
Эффективность алгоритма зависит не только от собственно алгоритма, но и от способа его реализации. Поэтому, для разных данных можно разрабатывать разные вариации кодирования и представления закодированных данных. Например, при кодировании изображений можно сделать цепочки переменной длины: выделить один бит под индикацию длинной цепочки, и если он выставлен в единицу, то хранить длину и в следующем байте тоже. Так мы жертвуем длиной коротких цепочек (65 элементов вместо 129), но зато даём возможность всего тремя байтами закодировать цепочки длиною до 16385 элементов (214 + 2)!
Дополнительная эффективность может быть достигнута путём использования эвристических методов кодирования. Например, закодируем нашим способом следующую цепочку: «ABBA». Мы получим «[0|0], A, [1|0], B, [0|0], A» — т.е. 4 байта мы превратили в 6, раздули исходные данные аж в полтора раза! И чем больше таких коротких чередующихся разнотипных последовательностей, тем больше избыточных данных. Если это учесть, то можно было бы закодировать результат как «[0|3], A, B, B, A» — мы бы потратили всего один лишний байт.
LZ77 — краткость в повторении
LZ77 — один из наиболее простых и известных алгоритмов в семействе LZ. Назван так в честь своих создателей: Абрахама Лемпеля (Abraham Lempel) и Якоба Зива (Jacob Ziv). Цифры 77 в названии означают 1977 год, в котором была опубликована статья с описанием этого алгоритма.
Основная идея заключается в том, чтобы кодировать одинаковые последовательности элементов. Т.е., если во входных данных какая-то цепочка элементов встречается более одного раза, то все последующие её вхождения можно заменить «ссылками» на её первый экземпляр.
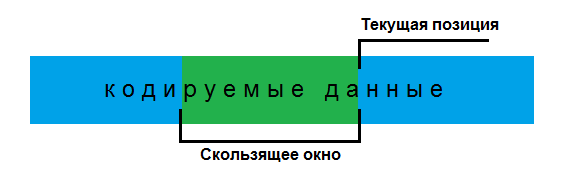
Как и остальные алгоритмы этого семейства, LZ77 использует словарь, в котором хранятся встречаемые ранее последовательности. Для этого он применяет принцип т.н. «скользящего окна»: области, всегда находящейся перед текущей позицией кодирования, в рамках которой мы можем адресовать ссылки. Это окно и является динамическим словарём для данного алгоритма — каждому элементу в нём соответствует два атрибута: позиция в окне и длина. Хотя в физическом смысле это просто участок памяти, который мы уже закодировали.
Пример реализации
Попробуем теперь что-нибудь закодировать. Сгенерируем для этого какую-нибудь подходящую строку (заранее извиняюсь за её нелепость):
«The compression and the decompression leave an impression. Hahahahaha!»
Вот как она будет выглядеть в памяти (кодировка ANSI):
0000: 54 68 65 20 63 6F 6D 70 72 65 73 73 69 6F 6E 20 The compression 0010: 61 6E 64 20 74 68 65 20 64 65 63 6F 6D 70 72 65 and the decompre0020: 73 73 69 6F 6E 20 6C 65 61 76 65 20 61 6E 20 69 ssion leave an i0030: 6D 70 72 65 73 73 69 6F 6E 2E 20 48 61 68 61 68 mpression. Hahah0040: 61 68 61 68 61 21 ahaha!Мы ещё не определились с размером окна, но условимся, что он больше размера кодируемой строки. Попробуем найти все повторяющиеся цепочки символов. Цепочкой будем считать последовательность символов длиной более единицы. Если цепочка входит в состав более длинной повторяющейся цепочки, будем её игнорировать.
«The compression and t[he ]de[compression ]leave[ an] i[mpression]. Hah[ahahaha]!»
Для пущей наглядности посмотрим на схему, где видны соответствия повторяемых последовательностей и их первых вхождений:

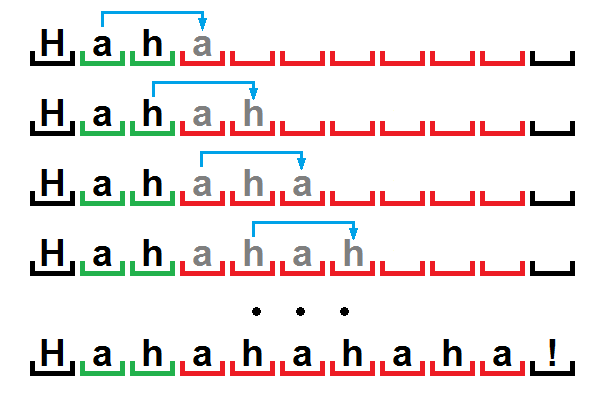
Пожалуй, единственным неясным моментом здесь будет последовательность «Hahahahaha!», ведь цепочке символов «ahahaha» соответствует короткая цепочка «ah». Но здесь нет ничего необычного, мы использовали кое-какой приём, позволяющий алгоритму иногда работать как описанный ранее RLE.
Дело в том, что при распаковке мы будем считывать из словаря указанное количество символов. А поскольку вся последовательность периодична, т.е. данные в ней повторяются с некоторым периодом, и символы первого периода будут находиться прямо перед позицией распаковки, то по ним мы можем воссоздать всю цепочку целиком, просто копируя символы предыдущего периода в следующий.
С этим разобрались. Теперь заменим найденные повторы на ссылки в словарь. Будем записывать ссылку в формате [P|L], где P — позиция первого вхождения цепочки в строке, L — её длина.
«The compression and t[22|3]de[5|12]leave[16|3] i[8|7]. Hah[61|7]!»
Но не стоит забывать, что мы имеем дело со скользящим окном. Для большего понимания, чтобы ссылки не зависели от размера окна, заменим абсолютные позиции на разницу между ними и текущей позицией кодирования.
«The compression and t[20|3]de[22|12]leave[28|3] i[42|7]. Hah[2|7]!»
Теперь нам достаточно отнять P от текущей позиции кодирования, чтобы получить абсолютную позицию в строке.
Пришло время определиться с размером окна и максимальной длиной кодируемой фразы. Поскольку мы имеем дело с текстом, редко когда в нём будут встречаться особо длинные повторяющиеся последовательности. Так что выделим под их длину, скажем, 4 бита — лимита на 15 символов за раз нам вполне хватит.
А вот от размера окна уже зависит, насколько глубоко мы будем искать одинаковые цепочки. Поскольку мы имеем дело с небольшими текстами, то в самый раз будет дополнить используемое нами количество бит до двух байт: будем адресовать ссылки в диапазоне из 4096 байт, используя для этого 12 бит.
По опыту с RLE мы знаем, что не всякие значения могут быть использованы. Очевидно, что ссылка может иметь минимальное значение 1, поэтому, чтобы адресовать назад в диапазоне 1..4096, мы должны при кодировании отнимать от ссылки единицу, а при декодировании прибавлять обратно. То же самое с длинами последовательностей: вместо 0..15 будем использовать диапазон 2..17, поскольку с нулевыми длинами мы не работаем, а отдельные символы последовательностями не являются.
Итак, представим наш закодированный текст с учётом этих поправок:
«The compression and t[19|1]de[21|10]leave[27|1] i[41|5]. Hah[1|5]!»
Теперь, опять же, нам надо как-то отделить сжатые цепочки от остальных данных. Самый распространённый способ — снова использовать структуру и прямо указывать, где сжатые данные, а где нет. Для этого мы разделим закодированные данные на группы по восемь элементов (символов или ссылок), а перед каждой из таких групп будем вставлять байт, где каждый бит соответствует типу элемента: 0 для символа и 1 для ссылки.
Разделяем на группы:
- «The comp»
- «ression »
- «and t[19|1]de»
- «[21|10]leave[27|1] »
- «i[41|5]. Hah[2|5]»
- «!»
Компонуем группы:
«{0,0,0,0,0,0,0,0}The comp{0,0,0,0,0,0,0,0}ression {0,0,0,0,0,1,0,0}and t[19|1]de{1,0,0,0,0,0,1,0}[21|10]leave[27|1] {0,1,0,0,0,0,0,1}i[41|5]. Hah[1|5]{0}!»
Таким образом, если при распаковке мы встречаем бит 0, то мы просто читаем символ в выходной поток, если же бит 1, мы читаем ссылку, а по ссылке читаем последовательность из словаря.
Теперь нам остаётся только сгруппировать результат в массив байтов. Условимся, что мы используем биты и байты в порядке от старшего к младшему. Посмотрим, как пакуются в байты ссылки на примере [19|1]:

В итоге наш сжатый поток будет выглядеть так:
0000: 00 54 68 65 20 63 6f 6d 70 00 72 65 73 73 69 6f #The comp#ressio
0010: 6e 20 04 61 6e 64 20 74 01 31 64 65 82 01 5a 6c n #and t##de###l
0020: 65 61 76 65 01 b1 20 41 69 02 97 2e 20 48 61 68 eave## #i##. Hah
0030: 00 15 00 21 00 00 00 00 00 00 00 00 00 00 00 00 ###!
Возможные улучшения
В принципе, здесь будет верно всё, что описывалось для RLE. В частности, для демонстрации пользы эвристического подхода при кодировании, рассмотрим следующий пример:
«The long goooooong. The loooooower bound.»
Найдём последовательности только для слова «loooooower»:
«The long goooooong. The [lo][ooooo]wer bound.»
Для кодирования такого результата нам понадобится четыре байта на ссылки. Однако, более экономично было бы сделать так:
«The long goooooong. The l[oooooo]wer bound.»
Тогда мы потратили бы на один байт меньше.
Вместо заключения
Несмотря на свою простоту и, казалось бы, не слишком уж большую эффективность, эти алгоритмы до сих пор широко применяются в разнообразных областях IT-сферы.
Их плюс — простота и быстродействие, а на их принципах и их комбинациях могут быть основаны более сложные и эффективные алгоритмы.
Надеюсь, изложенная таким образом суть этих алгоритмов поможет кому-нибудь разобраться в основах и начать смотреть в сторону более серьёзных вещей.
