 Я уже писал статью на тематику любительского перевода, где пытался описать кухню этого процесса. Но, на мой взгляд, этот опыт оказался не совсем удачным. Ввиду большого количества подходов нереально описать всё, а чрезмерное обобщение сути не отражает. Поэтому я решил описать один конкретный случай, довольно показательный, на мой взгляд.
Я уже писал статью на тематику любительского перевода, где пытался описать кухню этого процесса. Но, на мой взгляд, этот опыт оказался не совсем удачным. Ввиду большого количества подходов нереально описать всё, а чрезмерное обобщение сути не отражает. Поэтому я решил описать один конкретный случай, довольно показательный, на мой взгляд. Честно говоря, речь идёт не совсем о последнем нашем переводе. Дело в том, что идея написать эту статью пришла ко мне, когда дело наше находилось в упадке и слово «последний» значило действительно нашу финальную работу на этой сцене. Но, применив к проекту профессиональный подход и опыт, полученный в результате реальной производственной практики, я понял, что с этим можно жить и твёрдо решил, что мы должны доделать ещё один перевод, которого от нас ждут с нетерпением уже более двух лет. Так что при текущих обстоятельствах это слово означает скорей «последний на момент написания статьи».
Речь пойдёт не об игре на PC, это было бы слишком скучно — ведь там нет той экзотики и романтики реверс-инжиниринга, которая присуща внутренностям консольных игр. Речь пойдёт об игре на Nintendo Wii.
Я заранее прошу прощения за чересчур раздутую статью и скучную вторую половину, но, как говорится, из песни слов не выкинешь.
Предыстория
 Всё началось где-то в 2010-м году, точной даты уже и не припомнить. Я, будучи ещё студентом, и Dangaard (автор понравившихся многим статей про диких гусей и Красную Шапочку) уже довольно давно занимались любительскими переводами: я писал инструментарий, а он переводил. И была у нас одна нехорошая привычка — начинать переводить любую понравившуюся игрушку, именно поэтому количество заброшенных проектов у нас довольно сильно превышает количество завершённых. Одной из любимых игровых серий у нас был и остаётся небезызвестный Metroid — двухмерная бродилка, основоположник жанра Metroidvania, и мне всегда хотелось посмотреть, насколько успешно этот жанр был перенесён в 3D в играх серии Metroid Prime, выходивших на Nintendo GameCube и Wii.
Всё началось где-то в 2010-м году, точной даты уже и не припомнить. Я, будучи ещё студентом, и Dangaard (автор понравившихся многим статей про диких гусей и Красную Шапочку) уже довольно давно занимались любительскими переводами: я писал инструментарий, а он переводил. И была у нас одна нехорошая привычка — начинать переводить любую понравившуюся игрушку, именно поэтому количество заброшенных проектов у нас довольно сильно превышает количество завершённых. Одной из любимых игровых серий у нас был и остаётся небезызвестный Metroid — двухмерная бродилка, основоположник жанра Metroidvania, и мне всегда хотелось посмотреть, насколько успешно этот жанр был перенесён в 3D в играх серии Metroid Prime, выходивших на Nintendo GameCube и Wii.И вот в какой-то момент я стал счастливым обладателем Wii, и, конечно же, сразу же решил удовлетворить своё любопытство. Не знаю почему, но по первым минутам геймплея первая часть Metroid Prime меня не особо впечатлила — видимо, сказалось непривычное управление, да и войти во вкус я не успел, т.к. скорей хотелось опробовать и другие игры. Однако, приняв во внимание тот факт, что первые две части были лишь портом с GameCube, в отличии от третьей, которая изначально выходила на Wii, я решил посмотреть и на неё. Перестал на неё смотреть я примерно часов через шесть, и был очень впечатлён количеством информации в игре — буквально каждый объект можно было просканировать, получив краткую информацию или даже целую статью.
Глаза загорелись идеей, а руки уже приступили к исполнению уже привычного обряда инициации — запуску верного инструментария. Так родился проект этого перевода.
К сожалению, я не могу поведать о трудностях перевода игровых текстов, так что рассмотрены будут преимущественно технические и организационные аспекты процесса.
В поисках ресурсов
Итак, первым делом надо было добраться до файлов игры с целью реверс-инжиниринга. Сделать это нужно было любым доступным путём, поэтому я уже вбивал в гугл соответствующий запрос. Первой под руку подвернулась программа WiiScrubber, предназначенная для забивания нулями неиспользуемых областей образа игрового диска, чтобы он затем лучше сжимался (точнее, ввиду его шифрованности, сжимался хоть как-то), заодно умеющая и их открывать. Стоит заметить, что эта программа сыграла свою роль в ходе проекта, но об этом чуть позже.
Открыв образ и осмотрев его содержимое, сперва я обратил внимание на файлы большого размера с расширением *.pak. Несомненно, они были первоочередными подозреваемыми на предмет хранения игровых ресурсов, и один из экземпляров уже подготавливался к препарированию в хекс-редакторе.
Скрытый скриншот
В начале файла был заметен примитивный заголовок, начинавшийся с записи вида:
struct PakHeader { uint32 unknown; // version? uint32 totalHeaderSize; uint64 unknown; // hash? };
Следующие полезные данные начинались со смещения 0x40, что дало основания сделать выводы о выравнивании данных по размеру блока 64 байта. Среди этих данных явно выделялись какие-то идентификаторы: STRG, RSHD и DATA. К гадалке ходить не пришлось — стало очевидно, что архив разбит на сегменты, или секции. После каждого идентификатором следовало значение, кратное 64-м — очевидных варианта было два: либо размер, либо смещение.
Скрытый скриншот

Поскольку следующий блок данных имел размер 0x800 байт, и это же значение следовало за идентификатором первого сегмента, то стало очевидно, что это всё-таки размеры.
struct SectionRecord { char name[4]; uint32 size; };
С секциями всё ясно, осталось определить их назначение. Тут на интуитивном уровне помогли идентификаторы — в голове аббревиатуры сами выстроились в слова «strings», «resource headers» и, как это ни странно, «data». Бегло всё пролистав и учитывая, что секция STRG в некоторых архивах пуста, я решил сначала ознакомиться с секцией RSHD.
Скрытый скриншот
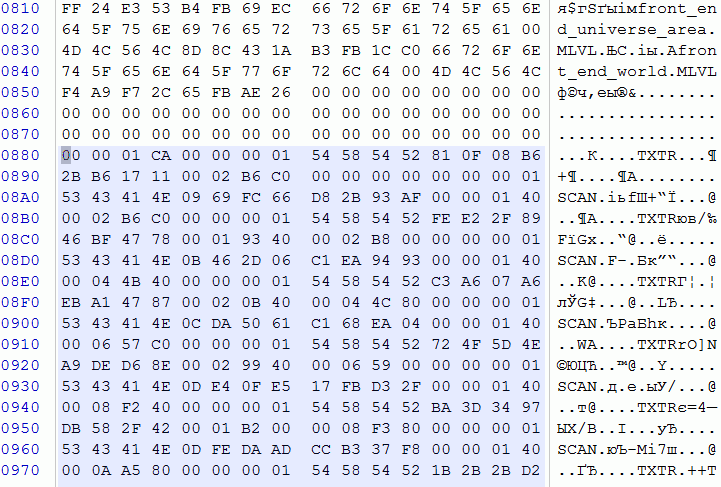
Опять же, вполне себе очевидно, что это секция представляет собой таблицу с информацией о хранимых в архиве файлах. В самом массиве данных просматривались идентификаторы — TXTR, SCAN, STRG и т.д., т.е. файлы имеют типизацию и это хорошо. Исходя из интуиции и структуры таблицы секций, я предположил, что первые 4 байта — это их количество. Чтобы в этом убедиться, я действовал стандартно: вычислил размер записи, посчитав расстояния между началами соседними идентификаторами (24 байта) и умножив на это самое значение (0x1CA). Получившееся значение (0x2AF0) я округлил до кратности 0x40, получив 2B00. Как и ожидалось, оно совпало с размером, указанным в таблице секций.
Теперь осталось разобрать формат самой записи о файле. С идентификатором всё ясно — он указывает на тип файла. Помимо него я ожидал найти как минимум какой-нибудь идентификатор самого файла, а так же его размер и смещение в архиве.
Скрытый скриншот

Путём визуального анализа я выявил некоторые закономерности. Первое число всегда равно 0 или 1, следовательно наиболее вероятно, что это булево значение. Учитывая, что это архив, вполне возможно, что это флаг сжатия. Далее шёл идентификатор, с которым я разобрался. За ним — 8 байт хаотичной информации, очень похожие на некий хеш и, похоже, и являющиеся идентификатором файла. Последними шли два значения: оба кратные 0x40, но последнее увеличивалось с количеством записей. Вывод напросился сам: размер и смещение файла. Поскольку смещение первого файла равно нулю, то ясно, что оно указано относительно начала сегмента.
Попрыгав по указанным смещениям и поприбавляя к ним размеры, я убедился в своих догадках и осталось только записать это в виде структурки:
struct FileRecord { uint32 packed; char type[4]; uint8 hash[8]; uint32 size; uint32 offset; };
Дальше меня интересовали сами данные файлов. Информация об их положении в архиве и размерах была известна, так что я по-быстрому набросал простой экстрактор и вынул содержимое одного из архивов как есть. Просмотрев пару файлов, я понял, что они действительно запакованы. Но я уже знал алгоритм — многолетний опыт подобной деятельности дал о себе знать, и хватило одного взгляда на окно хекс-редактора. Оставалось лишь убедиться в том, что опыт меня не обманывает, и я скормил один из файлов программке STUNS, отлично выявляющей некоторые распространённые алгоритмы сжатия. Я не ошибся, это был LZO.
Прежде, чем писать распаковщик, необходимо было не только определить алгоритм сжатия, но и разузнать структуру данных. Я взял один из таких файлов и начал его ковырять. Благодаря STUNS мне была известна позиция потока сжатых данных, но помимо него в запакованном файле присутствовала и другая информация.
Скрытый скриншот

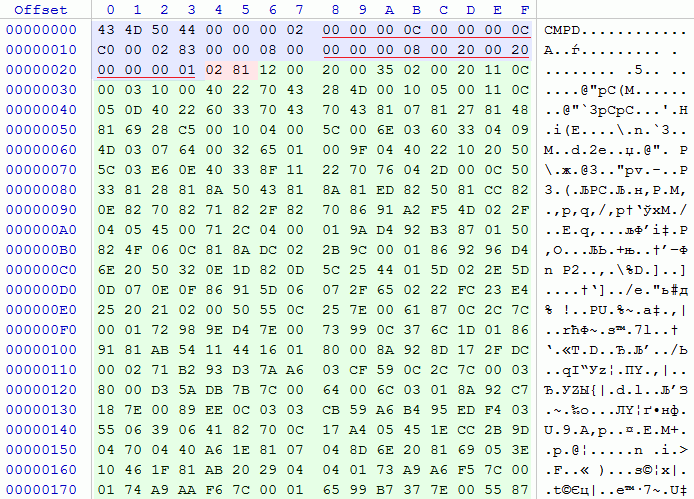
Прежде всего, было очевидно, что у всех таких файлов есть сигнатура — CMPD. За ней следовало значение, встречающееся в трёх вариантах — 1, 2, и очень редко — 3. Я решил, что это какой-то тип или версия формата, сперва не придав этому значения. Следующий байт хранил в себе неизвестное значение, а дальнейшие три — размер файла за вычетом 16. Это дало мне повод считать, что первые 16 байт файла являются заголовком. Поанализировав значения неизвестного байта я увидел, что часто различается лишь один-два бита, и решил, что это некие флаги. Далее следовали ещё четыре байта, равные размеру распакованного файла, выплюнутого мне STUNS'ом — выводы очевидны, это размер исходных данных.
16 байт подошли к концу, по данным STUNS ещё через два байта начинался уже сам сжатый поток. Я был уверен, это одна из классических схем: в двух байтах указывается размер порции данных, далее следует сама порция запакованных данных, и так до тех пор, пока поток не кончится. И действительно, значение этих двух байт совпадало с размером потока.
Обработав полученную информацию, я составил структуру заголовка.
struct CompressedFileHeader { char signature[4]; uint32 type; unsigned flags : 8; unsigned lzoSize : 24; uint32 dataSize; };
Теперь было ясно, как следует читать эти файлы, и я полез за старой доброй miniLZO. Благодаря своему мини-фреймворку и повсеместному использованию самодельных абстракций для потоков, реализация распаковки LZO-потока не заняла много ни времени, ни строк кода.
Показать код
while (streamSize > 0) { const uint16 chunkSize = input->readUInt16(); streamSize -= 2; input->read(inBuf, chunkSize); streamSize -= chunkSize; uint32 size = 0; lzo_decompress(inBuf, chunkSize, outBuf, &size); output->write(outBuf, size); }
Повысив свой примитивный экстрактор в звании до распоковщика, я сперва убедился, что верно понял назначение булевого поля в таблице файлов архива. Оказалось, что действительно, файлы, у которых оно имеет значение false, не подвергались запаковке. Успокоившись, я учёл это в коде, натравил программку на один из больших файлов и стал удовлетворённо смотреть на прогресс…
Но успешно завершить работу программе было не суждено. Попытка распаковать первый же TXTR-файл увенчалась крашем. Тут-то я и понял, что не даром присутствует какая-то версионность этих файлов. Открыв одну из сжатых текстур в хекс-редакторе, я принялся искать отличия.
Скрытый скриншот
Конечно же, в качестве типа тут уже была не единица. Первым делом бросилась в глаза разница в размере заголовка: он стал больше на 20 байт. При этом теперь в заголовке присутствовали два значения 12 и ещё 12 новых байт. У меня появилась одна догадка и я полез искать пример несжатой текстуры. Найдя таковую, я посмотрел на её начало и увидел, что оно очень похоже на те 12 байт, что вместе с прочим добавлены в заголовок.
Всё стало понятно: сжатые файлы такого типа позволяют считывать некоторое количество информации, не прибегая к распаковке — часть данных просто хранится в исходном виде прямо перед началом потока. В случае с текстурами незапакованным остался их заголовок, т.е. можно было без лишних вычислений узнать ширину, высоту и тип такой текстуры. Очень находчиво, стоит заметить. Но меня смущало то, что размер этих данных указан в двух экземплярах. Прошерстив все имеющиеся сжатые текстуры я не увидел ни одного иного варианта, и понял, что роли это не играет, но для себя предположил, что второе число — либо количество данных с учётом выравнивания на 4 байта, либо позиция, с которой следует начинать распаковывать выходной поток.
Я снова запустил распаковщик, и на этот раз он справился, но ввиду большого количества файлов это заняло довольно много времени. Тогда я добавил в него опцию выборочной распаковки, по типу файла, и начал прогонять по всем файлам. Я ожидал ещё одного краша, из-за ещё одного типа сжатых файлов, но оказалось, что ни один из интересующих файлов таким образом не запакован и я решил не тратить время на лишние исследования — впереди и так предстояло ещё много работы.
Итоговый вариант (псевдокод)
enum CompressedFileType { typeCommon = 1, typeTexture = 2, typeUnknown = 3 }; struct StreamHeader { unsigned flags : 8; unsigned lzo_size : 24; uint32 file_size; }; struct CompressedFileHeader { char signature[4]; uint32 type; if (commonHeader.type == typeTexture) { uint32 uncompressedChunkSize; uint32 uncompressedChunkSize2; // always equals to uncompressedChunkSize } StreamHeader streamHeader; if (commonHeader.type == typeTexture) { uint8 uncompressedData[uncompressedChunkSize]; } };
На этом осталось лишь разобраться с секцией STRG. Она начиналась со значения 0x4C, затем циклично чередовались данные: нуль-терминированная строка, идентификатор типа и хеш, присутствующий в таблице файлов. Конечно же, посчитав количество таких циклов, я получил 0x4C. Безусловно, это были имена некоторых файлов — видимо, для тех файлов, которые запрашиваются не по хешу, а по имени.
struct NameRecord { char name[]; // C-string char type[4]; uint8 hash[8]; };
По сути вся эта секция — сериализованное отображения хешей (или пар [хеш, тип]) на имя файла.
Теперь у меня был доступ ко всем необходимым ресурсам, и пришло время их исследовать.
В погоне за текстом
Далее необходимо было прежде всего извлечь текст, чтобы Dangaard начал его переводить, пока я продолжаю заниматься технической частью. Ещё перед тем, как я разобрался с архивами, я пытался найти признаки текста в файлах типа TXTR, но, как потом оказалось, TXTR не значит «text resource», а лишь производное от слова «texture». Конечно же, текст хранился в файлах типа STRG.
Я многого навидался, разбирая методики сериализации текстовых данных, поэтому, открывая один из таких файлов в хекс-редакторе, я был готов ко всему. И не зря, как оказалось, ведь случай выдался не тривиальный.
Скрытый скриншот

Мой взгляд сразу же привлекла строка «ENGLJAPNGERMFRENSPANITAL» — перечисление шести поддерживаемых игрой языков. По тексту во второй половине файла было видно, что в файле действительно имеются строки на всех этих языках. Всё, что следовало до идентификаторов языков, больно смахивало на заголовок, да и у других файлов картина была та же, поэтому я на этом и условился: первые 24 байта — заголовок.
Далее я начал сопоставлять известные мне факты со значениями этого заголовка. Например, было очевидно, что в файле хранятся данные двух строк для шести языков, поэтому семантика значений 6 и 2 вопросов не вызывала. Аналогично всё было очевидно с первыми четырьмя байтами: сигнатуры — обычное дело. Однако следующие 4 байта, хоть и казались безобидной версией формата ввиду отсутствия связи с какими-либо другими данными в файле, но после опыта со сжатыми файлами подозрения у меня всё-таки вызвали. Я на всякий случай просмотрел пару десятков файлов, и везде увидел ту же самую тройку, на этом успокоившись. Финишировали заголовок два нулевых значения, которые я списал на зарезервированные поля, довольно часто встречающиеся в бинарных форматах.
struct Header { uint32 signature; uint32 version; uint32 langCount; uint32 stringsCount; uint32 reserved1; uint32 reserved2; };
Со списком идентификаторов языков я разобрался. Далее, по логике, следовала таблица смещений строк, а затем и сами строки. Что же, надо это дело расковырять. Всего в файле шесть языков и две строки, но в таблице присутствует не 12, а 18 значений — значит для каждого языка присутствует ещё одно дополнительно значение, помимо смещений для двух строк.
По цикличному возрастанию значений видно, что смещения для каждого языка сгруппированы вместе, а не, например, чередуются вместе со смещениями других языков. Но каждой такой группе предшествует непонятное значение, а затем следуют смещения строк относительно начала первой строки. Сами строки хранятся подобно тому, как сделано в Delphi: сначала идёт длина строки, затем её данные. При этом строка нуль-терминирована. Возвращаясь к неизвестному значению, я не мог не проверить одну догадку и просуммировал длины всех строк первого языка. Да ведь это же и правда сумма длин строк языка! Теперь всё стало предельно ясно.
struct OffsetTable { uint32 totalStringsLength; uint32 stringOffsets[header.stringCount]; };
Скрытый скриншот

Настало время написать десериализатор. По тексту европейских языков было очевидно, что используется UTF-8. На тот момент я не очень давно перескочил с Delphi на C++, и из-за наличия на Delphi некоторых наработок, а также ввиду познаний в VCL и лишь поверхностного знания STL, часто грешил тем, что писал часть инструментария на Delphi. Поскольку на том же Delphi у меня имелась старая проверенная библиотечка для сериализации текста в читабельный и легко редактируемый формат, я решил и тут прибегнуть к этому приёму. К своему стыду, я хоть и старался прибегать к ООП и прочим благам цивилизованного кодописания, но часто грешил лапшевидным кодом, поэтому при написании этой статьи испытывал затруднения, вспоминая некоторые подробности.
В общем, необходимый для декодирования UTF-8 раздел документации WinApi был изучен, десериализатор был написан и после недолгой отладки опробован на препарируемом файле. Отлично, самое время извлечь игровой скрипт! Я извлёк из архивов все имеющиеся STRG-файлы и натравил на них десериализатор… Конечно, я ждал подвоха, и он был. Чего-то я не учёл, и вновь поймал краш.
Я открыл проблемный файл, и увидел, что погорячился, обозначив некоторые поля заголовка как зарезервированные.
Скрытый скриншот
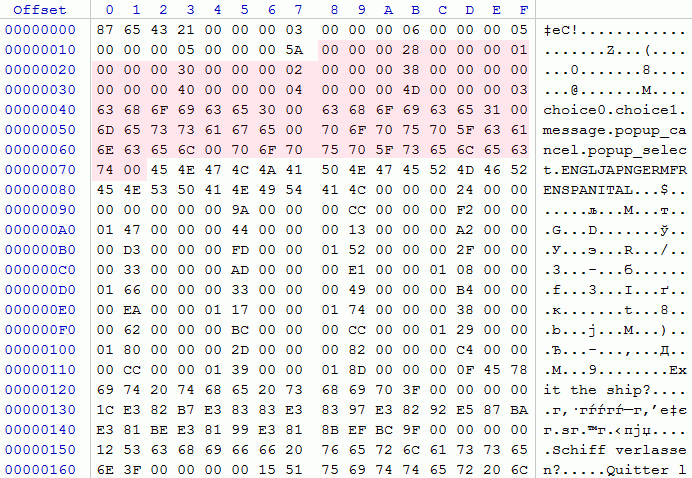
choice0, choice1… Да ведь это же идентификаторы строк! Значит, некоторым строкам могут назначаться такие вот идентификаторы, чтобы получать к ним доступ не по индексу, а по этим самым идентификаторам. Первое «зарезервированное» поле оказалось количеством этих самых идентификаторов, а затем следовал размер размещавшейся далее секции.
struct Header { uint32 signature; uint32 version; uint32 langCount; uint32 stringCount; uint32 idCount; uint32 idsSectionSize; };
В начале секции располагалась таблица, оказавшаяся немудрёным массивом смещений и индексов строк, для которых эти идентификаторы предназначены. За таблицей следовали сами идентификаторы в виде нуль-терминированных строк.
struct IdRecord { uint32 offset; uint32 index; };
Пришло время поправить десериализатор в соответствии с новыми данными и запустить процесс снова. На этот раз проблемные файлы проглотились без проблем и прогресс пошёл дальше. Я уже было готовился праздновать победу, но моё чувство удовлетворённости проделанной работой внезапно прервал ещё один краш… Ладно, не привыкать. Снова повторяю стандартную процедуру, открывая проблемный файл в хекс-редакторе.
Скрытый скриншот

Всё-таки я не ошибся с полем заголовка, хранящим версию формата. Но я и не думал, что остальные версии вообще используются игрой. Пришлось разбирать и эту версию, благо это было довольно просто.
Первые 16 байт заголовка оказались идентичны ранее исследованному формату. Затем сразу же следовала информация о языках, но немного в другом виде.
struct LangSectionRecord { char langId[4]; uint32 offset; uint32 size; };
А вот далее как раз и следовала последние 8 байт заголовка и секция идентификаторов в том же формате. Значит, и в том формате эти 8 байт не являлись частью заголовка.
Последними следовали секции с языковыми данными. В начале каждой секции находился список смещений строк. Сами строки на этот раз хранились в юникоде и были просто нуль-терминированы, без указания длины.
struct LangData { uint32 offsetTable[header.langCount]; uint32 size; };
Скрытый скриншот

Я добавил поддержку и этого формата и вновь запустил процесс десериализации… в последний раз. Теперь всё сработало гладко и на руках у меня был извлечённый игровой скрипт.
Шрифты
Тексты были отправлены Dangaard'у на ознакомление, и настала очередь шрифтов. Я ранее приметил парочку файлов с типом FONT, и у меня не осталось сомнений, что именно они хранят в себе шрифты.
Скрытый скриншот

Как правило, шрифты состоят из двух компонентов: растра и информации о том, как этот растр отображать. Но, просмотрев файл, я понял, что растра в нём нет. А это означает, что он должен хранится отдельно — например, в текстуре. Значит, надо было отыскать признаки какой-либо отсылки к растру.
Первым делом я начал визуально анализировать содержимое файла. В начале хорошо просматривалось имя шрифта — «Deface», а так же следующий за ним хеш. Я решил поискать файлы с таким хешем и действительно наткнулся на текстуру. Замечательно, растр теперь под рукой, но сперва следует разобраться с этим файлом.
Заголовок был мудрён, и я решил оставить его на потом. Чуть далее замеченных ранее имени шрифта и хеша текстуры виднелись данные, в которых прослеживалась некоторая периодичность. Присмотревшись повнимательней, я подобрал нужную ширину окна хекс-редактора и увидел, что это массив структур.
Скрытый скриншот

Судя по первому полю, где, без сомнения, хранились коды символов, это информация о глифах. Перед самим массивом классически находился его размер. Я начал искать в этом массиве структур характерные элементы, и первое, на что обратил внимание — это четыре явно различимых float-значения в стандартном формате IEEE 754. Различимы они, благодаря структуре формата, по наличию байт 3D, 3E, 3F и прочих похожих величин с интервалом в 4 байта — при большом скоплении чисел с плавающей запятой эту закономерность трудно не заметить. Сами значения колебались в диапазоне от 0 до 1 и стало очевидно, что это текстурные координаты. Семантику остальных значения, не видя текстуры, я определить не смог, поэтому принялся декодировать растр.
Отложив анализ структуры TXTR на потом, я решил просто обнаружить и обработать растр. В таких случаях я сперва всегда проверяю, является ли растр обыкновенным массивом цветов или индексов в случае изображения с индексированными цветами. И вот, открыв файл в тайловом редакторе и подобрав цветность, я увидел интересную картину.
Скрытый скриншот

Изображение было четырёхбитным, но очевидно, что картинки было две. Поскольку значения подобранной ширины и высоты нашлись в самом начале файла, т.е. по сути примерно так сама текстура выглядеть и должна, то за выводом далеко ходить не пришлось: в текстуре хитрым образом хранятся два слоя. Т.е. в каждом пикселе, вместо того, чтобы хранить четырёхбитное значение пикселя, хранятся два разных цвета — по одному на каждые два бита. Сами слои, соответственно, четырёхцветные.


Каждый слой являлся текстурным атласом — т.е. на нём находилось множество глифов, а в записях были указаны uv-координаты соответствующих символам глифов.
Для редакторов шрифтов у меня давно валялась заготовка на Delphi, доставшаяся ещё году в 2006-м от одного «коллеги». Я быстро набросал декодер растра и начал пытаться загрузить шрифт, по-разному интерпретируя поля в структурах глифов. Через несколько дней экспериментов я имел некоторое представление и даже вполне успешно загрузил шрифт.
Скрытый скриншот

Начиная конвертировать шрифты один за другим, я наткнулся на ещё один тип текстур. На этот раз в них хранилось целых четыре слоя вместо двух, но всё по тому же принципу. Разница была в том, что слои были не четырёхцветными, а бинарными.
В общем, картина постепенно прояснилась, и о глифах стало известно практически всё.
struct Rect { float left; float top; float right; float bottom; }; struct CharRecord { wchar_t code; Rect glyphRect; uint8 layerIndex; uint8 leftIdent; uint8 ident; uint8 rightIdent; uint8 glyphWidth; uint8 glyphHeight; uint8 baselineOffset; uint16 unknown; };
Скрытый скриншот

С этими знаниями стало реально разобрать и несправедливо забытый заголовок. Сопоставив известные мне факты, я так и не смог выяснить назначение большинства его полей, но это было и не важно, редактировать шрифт можно было и без них.
struct Header { uint32 maxCharWidth; uint32 fontHeight; uint32 unknown1; uint32 unknown2; uint32 unknown3; uint32 unknown4; uint16 unknown5; uint32 unknown6; char fontName[]; uint64 textureHash; uint32 textureColorCount; uint32 unknown7; };
Вроде бы всё, пора работать над сохранением шрифта, но тут я обратил внимание не странное дополнение, хранящееся в конце файла.
Скрытый скриншот

С некоторыми парами символов были сопоставленные некоторые значения, чаще всего 0, 1 и -1… Знатоки типографики наверняка уже догадались, о чём речь, но я тогда не сразу понял и даже поднял тему на тематическом форуме. Но вскоре я начал догадываться, и, погуглив, наткнулся на искомое определение… Да, это был кернинг в пикселах.
struct KerningRecord { wchar_t first; wchar_t second; int32 kerning; };
Все эти записи были отсортированы по возрастанию кодов символов. Теперь-то и назначение последнего поля в записи глифа стало известно — это был индекс первой записи кернинга для данного символа.
Теперь можно было заняться организацией сохранения такого шрифта. Я не стал рисковать и увеличивать размеры текстурных атласов, поэтому основной проблемой здесь было размещения всех глифов на ограниченной площади. Я спросил в теме про кернинг, не знает ли кто-нибудь незамысловатого алгоритма для этого, и в ответ мне дали ссылку на статью на gamedev.ru про упаковку карт освещения. Это было то, что нужно, и после реализации алгоритма шрифты можно было сохранять.
Но после изменения шрифтов оказалось, что даже с этим алгоритмом не так-то просто разместить все символы на имеющейся в распоряжении площади — часть глифов просто не влезала. Выход, впрочем, нашёлся сразу: я прикрутил оптимизацию, которая использовала одну и ту же часть текстуры для символов с одинаковыми глифами. Немного пошаманив, я устранил несущественные различия между некоторыми похожими символами кириллицы и латиницы, и они стали иметь общие глифы, благодаря чему шрифты начали успешно сохраняться.
Так очередной формат пал к моим пальцам, и на этом можно было вплотную заняться исследованием текстур.
Знакомство с текстурами
Игра не содержала большого количества текстур, нуждающихся в переводе, но на тот момент я этого не знал и работал с учётом худшего сценария. Немного покопавшись в извлечённых TXTR-файлах, я понял, что текстуры шрифтов — вырожденный случай, и большинство текстур не используют индексированные цвета.
Скрытый скриншот

Разобрать заголовок размером 12 байт не составило труда. Первое значения наверняка являлось номером типа текстуры, поскольку у текстур с индексированными цветами оно было иное. Далее следовали значения 640 и 480 — определённо очень знакомые числа, не так ли? В общем, в наличии разрешения в заголовке я и не сомневался, а вот назначение последнего значения не так очевидно. Но я готов был поклясться, что это количество mipmap-уровней, которые так часто встречаются в подобных случаях.
struct TextureHeader { uint32 type; uint16 width; uint16 height; uint32 mipmapCount; };
Заголовок был изучен, но основной проблемой являлось определение формата растра. К счастью, визуально подобная структура мне была весьма знакома — это определённо был алгоритм из семейства S3TC, многим знакомого по контейнерам DDS и алгоритмам DXTn. Форматы эти предназначены для использования сжатых текстур в видеопамяти и вроде как аппаратно поддерживается как Wii, так и Gamecube. Так что, несмотря на возникшие ассоциации с DirectX, ничего удивительного тут нет.
Определить конкретный алгоритм было несложно: все эти форматы имеют строго фиксированный коэффициент сжатия, и, исходя из соотношения размера исходного растра к сжатому в 8:1 (или 6:1 без учёта альфа-канала), это мог быть только DXT1. Пришло время лишь удостовериться в догадках, и я создал DDS-изображение этого же формата и разрешения, заменив растр заимствованным из текстуры. Но то, что я получил при открытии полученного файла, было не совсем осмысленным изображением…
Скрытое изображение

Настала пора пораскинуть мозгами. Раз на выходе получилось что-то отдалённо напоминающее изображение, было очевидно, что это всё же DXT1, но изменённый. На ум пришло два фактора, которые могли повлиять на формат: порядок байт и тайловая структура текстуры. Но, чтобы это проверить, мне необходимо было самому управлять процедурой декодирования, и для этой цели я начал искать какую-либо библиотеку.
К счастью, я вовремя наткнулся на замечательную библиотеку с открытым исходным кодом — NVIDIA Texture Tools (upd: переехала на github). Не без проблем, но я всё же смог приспособить её код для своих целей, и начал экспериментировать. Прежде всего, первая догадка оказалась верной, при том в ином порядке шли не байты, а целые слова, а также биты в них. После некоторых манипуляций с их перестановкой изображение приняло более адекватный вид.
Скрытое изображение

Я понял, что и насчёт тайловой структуры не ошибся. Но, учитывая, что DXT1 сам кодируется блоками 4x4, я был прав лишь отчасти: тут использовался некий свиззлинг тайлов, т.е. они были переставлены по некой матрице. Ну и, конечно же, изображение было перевёрнуто.
Мне было лень напрягать мозг и восстанавливать матрицу и я пошёл по давно накатанному пути — пытаться подбирать формулы для трансляции координат. Честно говоря, я не знаю, как у меня такое получалось, но я действовал по интуиции и ввиду наличия закономерностей в этой матрице, которые моё подсознание могло чувствовать без моего участия, это в конце концов прокатывало. И вот, наконец, я получил исходное изображение.
Скрытое изображение

Написать процедуру кодирования не составило проблемы — копипаст функции декодирования и, по сути, замена r-value на l-value сделали своё дело. На этом все основные форматы были разобраны и можно было вздохнуть чуточку свободней.
Первые пробы
Не терпелось поскорей что-нибудь уже опробовать в действии, и я начал думать о том, как бы обеспечить замену ресурсов в игре. Конечно, первым делом следовало подумать над перепаковкой архивов. Глупо было бы почём зря тратить процессорное время и прибегать к перепаковке неизменённых файлов, поэтому я начал писать функцию пересборки с запаковкой только необходимых данных.
Суть была такова: архив открывался и производилось итерирование по всем его файлам. На вход же подавался список директорий, где следовало искать их изменённые версии. Если таковая находилась, то она запаковывалась и записывалась в выходной файл, иначе же оригинальный запакованный файл копировался в неизменном виде.
Кстати, в процессе реализации данной функциональности я заметил занимательную вещь: мало того, что одни и те же файлы зачастую присутствовали в нескольких архивах, так они ещё нередко присутствовали во множественном числе и в рамках одного архива! Впрочем, я не удивился, ведь это легко объясняется — таким образом можно сократить количество движений головки привода над поверхностью диска. В поисках файла для чтения игра выбирает тот, что находится ближе всего по направлению движения головки, этим самым меньше изнашивая привод и быстрее производя загрузку. В иных играх, например, используется приём, когда все ресурсы уровня просто пакуются в отдельный архив, который потом в его рамках и используется. Конечно, это приводит к больших объёмов дублированию данных, но избыточным его назвать язык не повернётся, ведь всё более чем оправдано.
Когда необходимая функциональность была готова, я решил попытать счастья, скормив архив с изменёнными данными игре. Взяв ранее упомянутый WiiScrubber и пересобрав один из наименее весомых архивов, я попытался его заменить. Но меня ждало разочарование: размер оригинального файла был превышен. Уж чего мне хотелось меньше всего, так это заниматься проблемами пересборки образа, поэтому я начал искать обходные пути. И я их нашёл: решение оказалось аналогично тому, что я использовал в случае с шрифтами. Поскольку данные других языков меня не интересовали, я добавил в функцию пересборки возможность задать отображения одних файлов на другие. Т.е. если очередной обрабатываемый файл был помечен для отображения, то его содержимое никуда не писалось, а затрагивалась лишь его запись в таблице файлов — смещение и размер менялись на смещение и размер целевого файла. Таким образом, например, я «замапал» все варианты изображений начальных экранов на различных языках на один единственный — англоязычный, которому суждено было стать русскоязычным.
Я снова пересобрал архив, и на этот раз он поместился. И вот я совершил первый пробный запуск игры с изменёнными ресурсами… Не скажу, что всё получилось просто и без зависаний — то я не тот порядок байт использовал, то вообще забыл про порционность при запаковке в LZO, да и с шрифтами и текстом проблемы возникали, но в итоге всё было отлажено и игра наконец-то проглотила пересобранный архив без явных проблем. Ура, заработало: я увидел русский текст. Но это был далеко не конец пути, предстояло ещё многое сделать.
Организация процесса
Очень важно было наладить процесс перевода и создать хоть какую-то видимость цивилизованного подхода. В то время о системах контроля версий я знал лишь по наслышке, и мы решили использовать Dropbox, создав для проекта общую папку. Тем временем Dangaard закончил работу над первой версией глоссария, и пора было подумывать об автоматизации процесса вставки данных в игру.
Главной проблемой стала замена файлов в образе. Об использовании какого-либо скрипта, дёргающего внешние программы, не могло быть речи — таких программ с поддержкой командной строки мне известно не было, да и эстетически я бы не принял такой подход в отношении конкретно данной операции. Тем более, я с самого начала планировал создание исполняемого патча для образа, поэтому в любом случае пришлось бы прибегать к программной реализации такой возможности.
Что ж, раз так, то надо искать проект с открытым исходным кодом и наиболее близкими к необходимым возможностями. Сперва мой взгляд пал на Dolphin — замечательный и просто единственный существующий эмулятор Gamecube и Wii. Конечно, он умеет работать с образами, поэтому я выкачал его исходники и начал их изучать. Но архитектура оказалась довольно сложной, и я решил поискать альтернативы. Вдруг у меня возникла одна идея, и я вбил в гугле «WiiScrubber sources»… Бинго! Они существуют!
Надо сказать, это стало началом одного из самых сложных этапов в истории проекта. Если бы я это знал, я бы лучше сел и написал всё сам. Нет ничего хуже, чем адаптировать очень-очень узконаправленный код под свои нужды. Вот когда я на практике в полной мере ощутил всю важность и необходимость следования паттернам и блюдения культуры кода. Ведь мне буквально пришлось хирургическим путём вырезать функциональность из графического интерфейса. Код был написан с использованием MFC, и логика была интегрирована в GUI, где, к тому же, хранились некоторые данные — например, смещения файлов парсились из текстовых узлов TreeCtrl. Мне пришлось подменять сущности и писать фейковые классы контролов, чтобы всё хоть как-то собралось и заработало. Вкупе с и так не совсем чистым кодом это превратилось в кровавое месиво из костылей, грязных хаков и антипаттернов, которое рано или поздно пришлось бы разгребать.
Тем не менее, цель была достигнута. Код кровоточил, но свою задачу выполнял — я получил возможность программно заменять файлы в игре. Теперь надо было написать внутреннюю утилиту для быстрой вставки данных в игру. А поскольку пользоваться ей предстояло не только мне, надо было сделать её с простым и понятным графическим интерфейсом. Мне не очень-то хотелось разбираться со всяческими фреймворками или лезть в дебри MFC или WinApi, поэтому я решил вновь использовать свои познания в VCL. Я взял Borland C++ Builder 6.0 и начал писать.
 Надо сказать, положительных эмоций от этой IDE в процессе было получено мало. Уж не знаю, что тому виной, но без полной пересборки проекта каждый раз программа даже не запускалась. Плюс постоянные «шрёдингбаги» не давали локализовать место ошибки, в результате чего мне постоянно приходилось ревьюить весь тот ужас, что пришлось сотворить ранее. Пришлось и над кодом поработать, чтобы Borland смог его понять.
Надо сказать, положительных эмоций от этой IDE в процессе было получено мало. Уж не знаю, что тому виной, но без полной пересборки проекта каждый раз программа даже не запускалась. Плюс постоянные «шрёдингбаги» не давали локализовать место ошибки, в результате чего мне постоянно приходилось ревьюить весь тот ужас, что пришлось сотворить ранее. Пришлось и над кодом поработать, чтобы Borland смог его понять.Разобравшись с проблемами компиляции, я вернулся к проблемам функциональности. Чтобы процесс замены файлов был максимально быстрым и менее избыточным, надо было прикрутить возможность выбора конкретных файлов для замены. По содержимому архивов я определил, какой из них в какой локации используется, и создал список архивов с соответствующими пометками. Теперь, чтобы проверить текст в меню игры не нужно было прибегать к полной пересборке всего и вся.
Далее я набросал скрипт, который сериализовал ресурсы в игровые форматы и складывал их в папку, которая затем указывалась в качестве входной в разработанной только что программке. Теперь можно было в любой момент заменить ресурсы в игре, не прилагая излишних усилий.
Худо-бедно, но процесс «сборки» перевода был автоматизирован. Теперь надо было облегчить жизнь переводчику. Я заметил, что многие файлы с разными именами (точнее, хешами) имеют одинаковое содержимое, т.е. текст очень часто оказывался дублирован. Поэтому в выходных текстовых файлах я «схлопнул» все такие дубликаты в один, задав им композитные имена. А при сериализации просто получалась кучка файлов вместо одного.
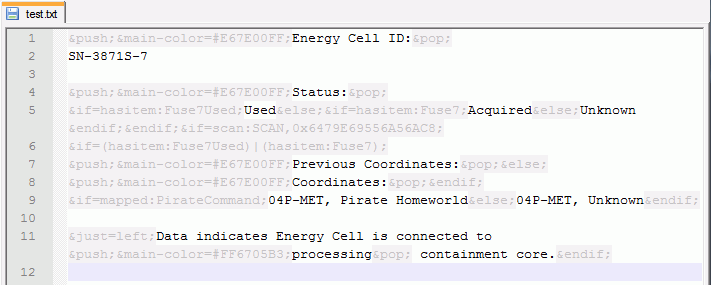
Затем я обратил внимание на обилие технических данных в тексте. Он был просто-напросто нечитабелен для человеческого глаза из-за огромного количества тегов.
Скрытый текст
&push;&main-color=#E67E00FF;Energy Cell ID:&pop;
SN-3871S-7
&push;&main-color=#E67E00FF;Status:&pop;
&if=hasitem:Fuse7Used;Used&else;&if=hasitem:Fuse7;Acquired&else;Unknown&endif;&endif;&if=scan:SCAN,0x6479E69556A56AC8;
&if=(hasitem:Fuse7Used)|(hasitem:Fuse7);
&push;&main-color=#E67E00FF;Previous Coordinates:&pop;&else;
&push;&main-color=#E67E00FF;Coordinates:&pop;&endif;
&if=mapped:PirateCommand;04P-MET, Pirate Homeworld&else;04P-MET, Unknown&endif;
&just=left;Data indicates Energy Cell is connected to &push;&main-color=#FF6705B3;processing&pop; containment core.&endif;
Благо такие проблемы приходилось решать и ранее, и я набросал xml-файл с описанием синтаксиса для Notepad++. Было очень кстати, что Dangaard переводил текст именно в нём, ведь Word и прочие текстовые комбайны со своей автозаменой и прочим способны доставить много проблем. После этих манипуляций воспринимать текст стало очень просто — проблема была решена.
Скрытый скриншот
Позже потребовалось ещё немного заморочиться с текстом. Dangaard обратился ко мне с просьбой — было невероятно нудно вести глоссарий имён локаций и повсеместно применять его в переводе, поэтому от меня требовалось автоматизировать этот процесс. Я набросал программку, которая считывала файл с глоссарием, парсила файлы с текстом и в случае, если строка полностью соответствовала элементу глоссария, производила её замену на переведённый вариант.
Перевод пошёл полным ходом и эстафету нагрузки перехватил Dangaard, переводя большие объёмы текста технического характера.
Мнимый финиш
Время шло, прогресс тоже не стоял на месте. И вот, в какой-то момент Dangaard рапортовал о завершении работы над переводом игрового журнала — самой сложной и объёмной части текста, ведь именно там находились описания практически всех игровых объектов и обширная коллекция мини-статей с их более подробным рассмотрением. Это несомненно означало перевес прогресса в сторону завершения перевода.
Примерно в этот момент я начал искать пути для создания маловесного исполняемого патча. Основная проблема состояла в том, чтобы найти средства для беспроблемной разработки GUI-приложения, сохраняя при этом малый размер и монолитность исполняемого файла, а также достойное оформление. В процессе я встретил много критики — многие считали, что в наше время не стоит уделять такое внимание размеру файла, да и вообще, лучше просто раздавать пропатченный образ через торренты. Но для меня это было делом принципа, ведь тот факт, что пользовательский интерфейс патча занимает больше памяти, чем сами данные патча, больно бил по моему чувству эстетики, так что это стало своего рода вызовом. К тому же, немаловажную роль играла юридическая сторона вопроса: я не хотел нарушать чьи-либо авторские права, распространяя нелегальную копию игры. По той же причине у меня даже лицензионный диск прикуплен.
Прошло ещё немного времени, и уже можно было предвкушать не такое уж и далёкое завершение работ. Изрядно устав от проекта, мы решили заранее объявить набор тестеров. Дело в том, что мы обнаружили кое-какую проблему: наш переведённый текст не всегда умещается в отведённое ему экранное место, и в связи с этим мы решили, что чем раньше мы начнём обнаруживать и исправлять такие места, тем лучше будет всем. Ведь чем больше времени проходило, тем меньше энтузиазма оставалось у нас в закромах.
Удручающе оказалось то, что на призыв откликнулся лишь один человек. Ничего не демотивирует так, как осознания того, что ваши труды не так уж и востребованы, и работа продолжилась с меньшим удовольствием. Ситуацию усугубляла необходимость рефакторинга проблемного кода для замены образов в игре, ведь если такое и годилось для внутреннего использования, то выпустить подобное в производство не позволяла совесть. Ещё одним стопорящим фактором оказалась необходимость создания патчера, удовлетворяющего требованиям.
Больше никто так и не откликнулся, и под весом обстоятельств дела наши пришли в упадок и всё встало, как это нередко бывает. Было множество попыток вернуть перевод в строй, но энтузиазма хватало ненадолго. Один раз, в грёзах об озвучке, я даже разобрал формат, в котором хранился звук речи — это был контейнеры одной из версий библиотеки FMOD. Однако полноценного звучания мне добиться не удалось, но дело не в сложности, а в отсутствии необходимости — я изначально знал, что хорошей озвучки на коленке не сделаешь.
Второе дыхание
С тех пор прошло два года. За это время я устроился на работу, закончил университет и получил много нового опыта по своей специальности. К сожалению, беззаботные времена прошли, и на свои увлечения после работы оставалось слишком мало времени и сил. Но всё это время совесть терзала мысль, что у нас есть незавершённые проекты, когда-то обещанные обществу. В голове витала мысль «надо», но как только доходило до дела, становилось ясно, что одной этой мысли мало. Dangaard периодически что-то понемногу переводил и тыкал в меня палочкой, что тоже заставляло меня беспокоиться.
В какой-то момент я вновь взглянул на свои наработки, и решил, что надо что-то менять. И я стал менять всё, пытаясь приводить всё в соответствии с требованиями к любому адекватному бизнес-процессу. Прежде всего реорганизация коснулась нашего метода согласования данных. Использовать Dropbox для этих целей никуда не годилось, и я стал смотреть в сторону систем контроля версий. Что бы там ни говорили, но мне нравится Subversion, поэтому я создал svn-репозиторий на одном из хостингов и начал переносить туда данные.
Сразу же всплыла проблема. Текст хранился в юникоде, поскольку Notepad++ не всегда корректно сохранял UTF-8, что периодически приводило к порче некоторых символов. Возможно, из-за наличия BOM SVN распознала файлы как бинарные, поэтому пришлось вручную устанавливать текстовый тип контента. После этих манипуляций текст был воспринят без проблем, но далее то и дело возникали проблемы — то утилиты сравнения версий не воспринимали юникод, то при возникновении конфликтов соответствующие текстовые метки прописывались в файлы как ANSI-текст. Но что-то менять было уже поздно, да и проблемы такого рода возникали не так часто, поэтому всё было оставлено как есть.
Как только миграция на SVN была завершена, я с удивлением заметил, что получил удовольствие от процесса. Работать с упорядоченными данными на более высоком уровне организации оказалось одним удовольствием по сравнению с предыдущим опытом, поэтому я решил на этом не останавливаться и обратил свой взор на инструментарий. Я решил, что надо переписать всё, что невозможно отрефакторить.
За полтора года опыта производственной практики я очень полюбил Qt, поэтому было решено его использовать и здесь. Тут же были созданы все необходимые проекты и работа закипела. Первое время я даже покрывал всё переписанное тестами, но потом мне это надоело и я решил акцентировать внимание на корректность выходных данных, а не на правильность работы кода.
Были переписаны все инструменты, за исключением редактора шрифтов и сериализатора текста — они работали и работали исправно, а нужды во внедрении куда-либо этой функциональности пока что не возникало. Через время руки дошли и до того кровавого месива, что мне пришлось породить для возможности замены файлов в образе. Через пару десятков коммитов этот код обрёл хоть какую-то форму, и я уже мог позволить себе использовать его для создания патчера. Следом и вставлялка данных была полностью переписана с использованием Qt вместо VCL.
Скрытый скриншот
Я решил, что и для патчера буду использовать Qt, и убил очень много времени, стараясь собрать его в статической конфигурации с минимальным размеров итоговых библиотек. Однако, хоть в системе сборки Qt и поддерживается «fine tuning», но на деле то ли руки у меня оказались кривыми, то ли эта возможность просто не работала.
Меня уже начали посещать мысли, а можно ли просто вырезать из библиотек ненужный мне код и данные? И я задал вопрос здесь, на Хабре. Надежды оправдались — меня спас MikhailEdoshin, рассказав, что в MSVC присутствуют флаги, позволяющие специальным образом компилировать код, и указывать линковщику, чтобы он вырезал неиспользуемые данные. После пробы этого метода я понял, что это отлично работает.
Я создал проект патчера и приступил к его разработке. Если два года назад я хотел увидеть в его качестве чего-то, напоминающего хакерскую поделку, то теперь это было желание видеть солидный инсталлятор, по-максимуму огораживающий авторов от потенциальных юридических проблем. Так что я взял QWizard и начал на его основе делать патчер в лучших традициях инсталлятора.
Скрытый скриншот

Вроде бы всё пошло хорошо, но вскоре возникла одна неприятная проблемка…
Неожиданное зависание
В какой-то момент игра стала просто зависать после главного меню. Это было ужасно, ведь до этого всё работало и причиной зависания могло быть что угодно. Замена архивов через WiiScrubber давала тот же самый эффект, так что винить конкретно патчер я не мог.
Много времени ушло на перебор возможных косячные файлов методом дихотомии, но в итоге оказалось, что раз на раз не приходится и при любом изменении игру вешает уже другой файл. И тут я решил проверить одну догадку, которая, в принципе, с самого начала держалась у меня в голове, но была отклонена как маловероятная.
Чтобы раскрыть суть, надо сперва немного поведать об устройстве диска Wii. В то время как обычный DVD-диск разбит на сектора размером 2048 байт, диск Wii разбит на кластеры по 0x8000 байт. Кластеры, в свою очередь, состоят из заголовка размером 0x400 байт и данных размером 0x7C00 байт. Сами кластеры собраны в подгруппы из восьми штук, которые затем собраны в группы из восьми подгрупп. Заголовок же кластера хранит в себе хеши, хеши хешей, и хеши хешей хешей… в общем, обо всём по порядку.
typedef uint8 Hash[20]; struct ClusterHeader { Hash h0[31]; uint8 padding0[20]; Hash h1[8]; uint8 padding1[32]; Hash h2[8]; uint8 padding2[32]; }; struct Cluster { ClusterHeader header; uint8 data[0x7C00]; };
Прежде всего, в заголовке хранится таблица из 31-го хеша SHA1, называемая H0. Она хранит в себе хеши каждого 1024-байтного блока данных в кластере.
Вторая таблица, H1, хранит в себе хеши таблиц H0 каждого кластера в подгруппе. Поскольку эта таблица имеется в заголовке у каждого кластера, то в рамках одной подгруппы у всех кластеров её содержимое одинаково.
Также существует таблица H2, которая хранит в себе хеши таблиц H1 всех подгрупп в группе. Поэтому она, в свою очередь, одинакова для всех кластеров в группе.
И, наконец, у каждого раздела на диске существует глобальная таблица хешей, которая хранит хеши таблиц H2 каждой группы кластеров. Эта таблица вместе с остальной заголовочной информацией раздела защищена цифровой подписью, что по цепочке де-факто защищает и таблицы остальных уровней, включая в итоге и сами данные кластеров. Они, к слову, при этом ещё и зашифрованы.
При любом изменении в образе необходимо пересчитать все хеши и заново подписать глобальную таблицу хешей. Но приватный ключ для подписи никому кроме Nintendo не известен, поэтому используется обходной путь, известный как signing bug.
Дело в том, что в прошивке Wii был обнаружен баг: при проверке цифровой подписи хеши сравнивались с помощью функции strncmp. Эта функция рассчитана на строки и имеет одну особенность: если в начале обоих сравниваемых цепочек данных присутствует нулевой байт, то они принимаются за пустые строки, и, как следствие, считаются равными. Поэтому для запуска на Wii модифицированного содержимого используется заранее подготовленная цифровая подпись, хеш которой начинается с нуля. Чтобы хеш контента тоже начинался с нуля, производится подгонка данных за счёт изменения зарезервированных полей.
Зная это, я написал функцию проверки, которая считала хеши и сравнивала их с указанными. И действительно — в определённый момент проверка завалилась из-за неверного хеша. Проблема с зависанием оказалась в том, что в исходниках WiiScrubber'а имелся баг, в результате которого в некоторых случаях не обновлялись хеши последнего обрабатываемого кластера. После устранения бага всё начало работать, чему я был очень рад.
Учитывая этот неприятный опыт, во внутренние сборки патчей я встроил обязательную проверку валидности образа и самих пересобранных архивов. В случае чего патч бы просто не применился.
Тестирование и релиз
Проблема с зависанием была устранена, процесс сборки патча был автоматизирован, перевод теперь действительно близился к завершению, и мы решили вновь набрать добровольцев для тестирования. На этот раз откликнулось достаточно людей, хотя в итоге действительно в тестировании участвовало только трое, включая меня. Я раздал патчи и процесс пошёл…
Перед этим я постарался предупредить большинство ошибок технического характера тем, что в процесс сборки патча добавил несколько тестов. Если они заваливались, патч просто не собирался.
Но проблемы всё равно лились рекой. Я еле успевал обрабатывать баг-репорты, как появлялись новые. При этом докладывалось не только об ошибках, но и о любых режущих ухо предложениях, поэтому тестирование в скором времени переросло в детальную переработку всего текста.
Оказалось, что проблема с невлезающим текстом имела гораздо больший масштаб, чем мы могли себе представить. Ввиду особенностей русского языка, перевод получался длиннее и просто не влезал на экран. Поэтому, стиснув зубы, я сел и написал редактор игрового скрипта с возможностью примерной визуализации текста.
Скрытый скриншот

Один из тестировщиков, человек под ником SonyLover, ранее был сопереводчиком в одном из наших проектов. Он предложил свою помощь в доведении перевода до конца, и мы вместе стали править буквально каждое предложение.
Тем временем обнаружилась одна неприятная проблема со шрифтами: одни символы казались выше других, что создавало эффект «скачущего» текста. Присмотревшись, я увидел это проблему и в оригинале, но там она была менее выражена и поэтому не столь заметна.
Скрытый скриншот

Причина оказалась проста и что-то подобное уже описывалось на Хабре: символы, прилегающие к краям текстуры, не подвергались интерполяции с прилегающей стороны, а поэтому выглядели чётче символов, находившихся дальше от края. Визуально это создавало эффект разницы в высоте символов. Впрочем, проблема была решена простым добавлением рамки из прозрачных пикселей, чтобы ни один символ более не прилегал к краям текстуры.
В таком темпе мы работали полтора месяца, шлифуя все неугодные моменты и споря по каждой мелочи. И вот, мы вплотную приблизились к релизу. Хоть в последний момент нам и пришлось прибегнуть к довольно глобальным изменениям вроде изменения парочки элементов глоссария или обнаружения непереведённых системных сообщений, вшитых в исполняемый файл игры, но сил их проверку уже не осталось.
И вот наконец для нас наступил торжественный день. 26 января 2013-го года я внёс последние правки, отбранчевался в репозиториях, собрал патч с релизной конфигурацией и объявил о релизе перевода. Сказать, что гора свалилась с моих плеч — ничего не сказать. Я, конечно, не почувствовал неописуемой радости, но зато у совести было на один повод меньше меня донимать.
Конечно, перевод не вышел идеальным — нет предела совершенству, и сразу же после релиза обнаружилась парочка неприятных, но не критичных моментов с форматированием текста. Но выпустить новую версию — дело пяти минут, поэтому это меня не сильно расстроило. Главное, что своей работой мы остались довольны, как и наша целевая аудитория.
Послесловие
Возвращаясь к заголовку, хочу немного рассказать о наших планах. Ещё недавно я был уверен, что больше не вернусь к переводческой деятельности, но, как видно, я ошибался. Потом я думал, что этот перевод уж наверняка станет для меня последним, но затем решил, что мы должны завершить ещё как минимум один долгострой, который уже два года ждут от нас сотни людей — перевод Silent Hill: Shattered Memories. А там будет видно, будет ли ещё лежать душа к любительским переводам. Всё-таки не зря очень многие, взрослея, уходят с этой сцены.
Честно говоря, мне перестало этого хватать для удовлетворения эстетических потребностей, как перестало хватать и времени с появлением других забот. Наверное, настала пора для чего-то большего. Например, исполнить мечту детства и юношества, занявшись разработкой игр. Кто знает, может когда-нибудь удастся выпустить свой собственный маленький шедевр.
На этом спасибо за внимание, моя история здесь оканчивается.
UPDATE: Исходники выложены на github.
