Часто на собеседованиях приходится спрашивать про функцию hashCode().
Я не буду здесь перечислять все свойства этой функции и ее связь с другой, не менее важной функцией equals(). Данная информация есть во всех учебниках по Java и я не вижу смысла ее здесь повторять. Мне бы хотелось остановиться лишь на одном свойстве: hashCode должен быть равномерно распределен на области значений функции. Я задумался: “А чем гарантировано равномерное распределение?”
Забегая вперед, скажу, что я пришел к довольно интересным выводам. Мне бы хотелось, чтобы меня поправили, если я где-то ошибся в рассуждениях.
Вначале я решил обратиться к Java документации на Object.hashCode(). Как каждый может убедиться, там нет информации, которая нас интересует. После этого я пошел к Гуру. Брюс Эккель написал 5 страниц, кивнул на Блоха (точнее списал у него), привел пример со строками, а в конце посоветовал использовать “полезные библиотеки”. Джошуа Блох поступил лучше: он предложил алгоритм вычисления, высказался о пользе простых чисел и… тоже привел пример. Я не могу не удержаться от цитирования:
Никто из авторов не удосужился провести анализ приведенного алгоритма и доказать его корректность.
1) Взять число, отличное от нуля, к примеру 17. Для удобства, назовем его p. Присвоить переменной result это начальное значение (result = p).
2) Для каждого поля вычислить hashCode c по некоторым правилам. Эти правила, нас сейчас не очень интересуют, они не влияют на результат. Для простоты будем работать с целыми числами (int) и будем принимать hashCode равным самому значению числа…
3) Скомбинировать result и полученный hashCode с: result = result * q + c, где q = 37, потому что, как мы помним, оно нечетное и простое.
4) Вернуть result.
Сначала сделаем несколько допущений:
1) Как уже сказано выше, будем работать с целыми числами.
2) Будем считать, что hashCode принимает значения от 0 до 232. То есть мы не будем работать с отрицательными значениями.
3) Будем считать, что переполнения при умножении и сложении не происходит. Будем использовать только небольшие исходные значения.
4) Будем считать, что данные, на основании которых строится hashCode распределены, равномерно.
Чтобы быть более конкретным, я стану рассматривать точки с целочисленными координатами (x, y) на плоскости в двухмерном пространстве, при условии, что x>= 0, y>=0.
Запишем hash функцию для точки P1 (x1, y1):
h — значение hash функции.
Теперь я хочу рассмотреть какую-нибудь другую точку P2(x2, y2) у которой будет такая же hash функция. То есть это как раз случай коллизии:
Вычтем из первого выражение второе:
Вынесем q в правую часть:
Если подобрать такие значения x1, x2, y1, y2, что выполнится полученное равенство, то эти координаты будут соответствовать значениям аргумента hash функции, при которой возникнет коллизия.
Можно предложить такой вариант:
То есть точки P(38, 1) и P(1, 2) имеют одинаковый hashCode… Я думал, что имея 4 миллиарда возможных значений для hash кода, можно было бы избежать коллизий хотя бы в квадрате 100x100!
Теперь рассмотрим случай n переменных, независимо изменяющихся от 0 до некоторого M. Хотелось бы найти максимальное значение M, такое, что хорошо написанная функция hashCode не имела бы коллизий на промежутке от 0 до M по всем n переменным. После недолгих раздумий, получаем значение для M:
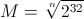
Для случая точек на плоскости M принимает значение 65536.
Похоже, что формула, приведенная Блохом, будет давать приемлемое распределение hash кодов для случая 8 и более переменных.
Рассмотрим теперь точки в трехмерном пространстве. Напишем небольшую программу, которая в тройном цикле перебирает точки от 0 до 100 (всего миллион точек) и считает количество коллизий. Код этой программы элементарный, поэтому не буду его здесь приводить. Интересен результат: я получил 901692 коллизий! То есть чуть более, чем 90%. Получается, что Блох, под видом hash функции, предложил функцию для получения коллизий?
Теперь попробуем построить хороший алгоритм для случая двух переменных (x1, y1). Чтобы равномерно раскидать значения x1 и y1 на числовой плоскости, воспользуемся умножением: умножим x1 на некоторое число p, а y1 — на q. Пока не будем накладывать на p и q никаких условий. Для получения значения hash функции, сложим эти произведения:
Воспользуемся приёмом, описанным выше: найдем x2, y2, такие, что значение hash функции выдаст коллизию.
Вычтем из первого равенства второе:
Если q взять равным 37, а p — 1, то получим формулу от Блоха.
Из последней формулы и из того факта, что мы работаем с целыми числами, следует:
1) Разность (x1-x2) пропорциональна q, разность (y2-y1) пропорциональна p.
2) Чем больше p и q, тем больше может быть расстояние между точками.
3) p и q должны быть взаимно простыми.
4) Имея верхнее ограничение на h=232, получаем, что каждое из произведений p*x1, q*y1 должны быть меньше, чем 232/2. Отсюда следует, что p и q должны быть меньше 32768. К примеру 32765 и 32767 Тут следует напомнить о нашем допущении: мы работаем только с положительными числами. Когда произойдет переполнение при сложении, мы окажемся в отрицательной части числовой оси. Предлагаю читателям поразмыслить над этим самостоятельно
Как писал Дональд Кнут в главе про генератор псевдослучайных последовательностей, если алгоритм выглядит сложно и запутанно, это еще не означает, что он работает правильно (недословное изложение).
Те кто используют реализацию hash функции от Джошуа Блоха, но имеют большое количество хешируемых переменных, могут спать спокойно. Так же могут не волноваться те, у кого различного рода Hash-коллекции не являются узким местом в производительности.
Если же вы бьетесь за производительность своего кода, учитываете все возможные мелочи, то вам, пожалуй, следует взглянуть на свои реализации hashCode() свежим взглядом. Учитывая, что хешируемые значения, могут быть не равномерно распределены для вашей конкретной бизнес области, вы сможете написать hash функцию с лучшим распределением hash кодов, чем любой сгенерированный вариант. Переписав hashCode(), вам, возможно, следует взглянуть на equals(): может быть вы сможете меньшим числом проверок вернуть значение false.
Спасибо тем, кто дочитал до конца.
Литература:
Bruce Eckel “Thinking in Java Third Edition”
Joshua Bloch “Effective Java: Programming Language Guide”
Я не буду здесь перечислять все свойства этой функции и ее связь с другой, не менее важной функцией equals(). Данная информация есть во всех учебниках по Java и я не вижу смысла ее здесь повторять. Мне бы хотелось остановиться лишь на одном свойстве: hashCode должен быть равномерно распределен на области значений функции. Я задумался: “А чем гарантировано равномерное распределение?”
Забегая вперед, скажу, что я пришел к довольно интересным выводам. Мне бы хотелось, чтобы меня поправили, если я где-то ошибся в рассуждениях.
Спросим у Гуру
Вначале я решил обратиться к Java документации на Object.hashCode(). Как каждый может убедиться, там нет информации, которая нас интересует. После этого я пошел к Гуру. Брюс Эккель написал 5 страниц, кивнул на Блоха (точнее списал у него), привел пример со строками, а в конце посоветовал использовать “полезные библиотеки”. Джошуа Блох поступил лучше: он предложил алгоритм вычисления, высказался о пользе простых чисел и… тоже привел пример. Я не могу не удержаться от цитирования:
The multiplier 37 was chosen because it is an odd prime. … The advantages of using a prime number are less clear, but it is traditional to use primes for this purpose.
Никто из авторов не удосужился провести анализ приведенного алгоритма и доказать его корректность.
Алгоритм (в вольном пересказе)
1) Взять число, отличное от нуля, к примеру 17. Для удобства, назовем его p. Присвоить переменной result это начальное значение (result = p).
2) Для каждого поля вычислить hashCode c по некоторым правилам. Эти правила, нас сейчас не очень интересуют, они не влияют на результат. Для простоты будем работать с целыми числами (int) и будем принимать hashCode равным самому значению числа…
3) Скомбинировать result и полученный hashCode с: result = result * q + c, где q = 37, потому что, как мы помним, оно нечетное и простое.
4) Вернуть result.
Анализ алгоритма
Сначала сделаем несколько допущений:
1) Как уже сказано выше, будем работать с целыми числами.
2) Будем считать, что hashCode принимает значения от 0 до 232. То есть мы не будем работать с отрицательными значениями.
3) Будем считать, что переполнения при умножении и сложении не происходит. Будем использовать только небольшие исходные значения.
4) Будем считать, что данные, на основании которых строится hashCode распределены, равномерно.
Чтобы быть более конкретным, я стану рассматривать точки с целочисленными координатами (x, y) на плоскости в двухмерном пространстве, при условии, что x>= 0, y>=0.
Запишем hash функцию для точки P1 (x1, y1):
(p*q + x1)*q + y1 = h
h — значение hash функции.
Теперь я хочу рассмотреть какую-нибудь другую точку P2(x2, y2) у которой будет такая же hash функция. То есть это как раз случай коллизии:
(p*q + x2)*q + y2 = h
Вычтем из первого выражение второе:
q(x1-x2) + y1 — y2 = 0 (Обратите внимание, что множитель, содержащий p пропал после вычитания)
Вынесем q в правую часть:
(x1 — x2) / (y2-y1) = q (понятно, что знаменатель должен быть отличен от нуля)
Если подобрать такие значения x1, x2, y1, y2, что выполнится полученное равенство, то эти координаты будут соответствовать значениям аргумента hash функции, при которой возникнет коллизия.
Можно предложить такой вариант:
x1 = 38
x2 = 1
y2= 2
y1 = 1
То есть точки P(38, 1) и P(1, 2) имеют одинаковый hashCode… Я думал, что имея 4 миллиарда возможных значений для hash кода, можно было бы избежать коллизий хотя бы в квадрате 100x100!
Теперь рассмотрим случай n переменных, независимо изменяющихся от 0 до некоторого M. Хотелось бы найти максимальное значение M, такое, что хорошо написанная функция hashCode не имела бы коллизий на промежутке от 0 до M по всем n переменным. После недолгих раздумий, получаем значение для M:
Для случая точек на плоскости M принимает значение 65536.
Похоже, что формула, приведенная Блохом, будет давать приемлемое распределение hash кодов для случая 8 и более переменных.
Рассмотрим теперь точки в трехмерном пространстве. Напишем небольшую программу, которая в тройном цикле перебирает точки от 0 до 100 (всего миллион точек) и считает количество коллизий. Код этой программы элементарный, поэтому не буду его здесь приводить. Интересен результат: я получил 901692 коллизий! То есть чуть более, чем 90%. Получается, что Блох, под видом hash функции, предложил функцию для получения коллизий?
Хороший hashCode для случая двух переменных
Теперь попробуем построить хороший алгоритм для случая двух переменных (x1, y1). Чтобы равномерно раскидать значения x1 и y1 на числовой плоскости, воспользуемся умножением: умножим x1 на некоторое число p, а y1 — на q. Пока не будем накладывать на p и q никаких условий. Для получения значения hash функции, сложим эти произведения:
p*x1+q*y1=h
Воспользуемся приёмом, описанным выше: найдем x2, y2, такие, что значение hash функции выдаст коллизию.
p*x2+q*y2=h
Вычтем из первого равенства второе:
p*(x1-x2) + q(y1-y2) = 0
или
(x1-x2)/(y2-y1)=q/p (при условии, что знаменатель не равен нулю)
Если q взять равным 37, а p — 1, то получим формулу от Блоха.
Из последней формулы и из того факта, что мы работаем с целыми числами, следует:
1) Разность (x1-x2) пропорциональна q, разность (y2-y1) пропорциональна p.
2) Чем больше p и q, тем больше может быть расстояние между точками.
3) p и q должны быть взаимно простыми.
4) Имея верхнее ограничение на h=232, получаем, что каждое из произведений p*x1, q*y1 должны быть меньше, чем 232/2. Отсюда следует, что p и q должны быть меньше 32768. К примеру 32765 и 32767 Тут следует напомнить о нашем допущении: мы работаем только с положительными числами. Когда произойдет переполнение при сложении, мы окажемся в отрицательной части числовой оси. Предлагаю читателям поразмыслить над этим самостоятельно
Выводы
Как писал Дональд Кнут в главе про генератор псевдослучайных последовательностей, если алгоритм выглядит сложно и запутанно, это еще не означает, что он работает правильно (недословное изложение).
Те кто используют реализацию hash функции от Джошуа Блоха, но имеют большое количество хешируемых переменных, могут спать спокойно. Так же могут не волноваться те, у кого различного рода Hash-коллекции не являются узким местом в производительности.
Если же вы бьетесь за производительность своего кода, учитываете все возможные мелочи, то вам, пожалуй, следует взглянуть на свои реализации hashCode() свежим взглядом. Учитывая, что хешируемые значения, могут быть не равномерно распределены для вашей конкретной бизнес области, вы сможете написать hash функцию с лучшим распределением hash кодов, чем любой сгенерированный вариант. Переписав hashCode(), вам, возможно, следует взглянуть на equals(): может быть вы сможете меньшим числом проверок вернуть значение false.
Спасибо тем, кто дочитал до конца.
Литература:
Bruce Eckel “Thinking in Java Third Edition”
Joshua Bloch “Effective Java: Programming Language Guide”
