GHC (Glasgow Haskell Compiler) — стандартный компилятор Хаскеля. GHC — один из самых крутых компиляторов в мире, но к сожалению без дополнительных телодвижений скомпилированные им программы по скорости больше напоминают интерпретируемые, т. е. работают очень медленно. Однако если раскрыть весь потенциал компилятора, Хаскель приближается по производительности к аналогичному коду на C.
В этой статье я обобщаю опыт выжимания максимума из GHC при создании dataflow-фреймворка Yarr.
Статья состоит из достаточно тривиальных по отдельности наблюдений, но, думаю, подойдет как памятка или старт в теме. Описываемые принципы — эмпирические, я не знаю внутреннего устройства GHC. Теорию компиляторов тоже не знаю, поэтому если для чего-то есть общепринятые термины, подсказывайте в комментариях.
Актуальная на данный момент версия GHC — 7.6.1.
Последнее замечание: на самом деле, с GHC «по умолчанию» все не так плохо, как описано в первом абзаце, хотя бы если просто компилировать с опцией
Можно выделить 2 основных направления оптимизаций, которые проводит GHC:
Они поддерживают друг друга, т. е. если структуры данных не расщепляются, то хуже и встраиваются функции, и наоборот. Поэтому бессмысленно следовать только паре нижеследующих советов, результата почти не будет.
В том числе Maybe, Either и списков, какими бы «стандартными» они не были. Причина очевидна — такие типы данных нельзя разложить на составляющие, потому что статически не известно, какая у них вообще структура.
Единственное исключение — типы-перечисления с несколькими конструкторами без параметров:
Если вдуматься, списки в Хаскеле — суть односвязные, которые практически не используются в императивных языках из-за своей медлительности. Так почему бы и в Хаскеле не использовать вместо них вектора (вместо стандартных строк — ByteString), едва ли уступающие спискам по удобству и возможностям. Для замены коротких списков в несколько элементов еще лучше подойдут вектора статически известной длины.
См. также: HaskellWiki — Performance/Data types.
Обычное, ленивое поле — это ссылка на замыкание, которое вернет значение поля. Строгое поле — ссылка на значение поля. Встроенное (unboxed) поле — само значение (если это тоже структура, то она целиком встраивается в родительскую). Встроенное поле получается добавлением к строгому директивы
Без 1-го варианта, как и в случае со списками, на самом вполне неплохо живется. В каждом случае делайте осознанный выбор в пользу 2 или 3 варианта. Поля по ссылке иногда эффективнее по памяти, быстрее при создании структур, проверках на равенство. Встроенные поля быстрее при чтении. Если чаще нужны встроенные поля (скорее всего), компилируйте с флагом
См. также: Haskell Style Guide/Dealing with laziness.
В примере структура
GHC не выносит вычисление структуры из «цикла»:
В машинном коде на каждой итерации будет переход по ссылке и чтение одних и тех же полей.
Однако если «подсказать» компилятору снаружи цикла, он не повторяет вычисления, уже проведенные где-то выше по АСД (абстрактному синтаксическому дереву):
Вместо написания кейсов вручную можно использовать обобщенный control flow из пакета deepseq.
Пример не очень удачный, потому что структура
Правило №1: добавляйте ко всем маленьким, часто (на рантайме) вызываемым, живущим далеко от корня АСД функциям директиву
Или, говоря по-умному, применяйте continuation passing style.
Преимущество замыканий перед структурами данных в том, что GHC гораздо положительнее настроен на их объединение и редукцию.
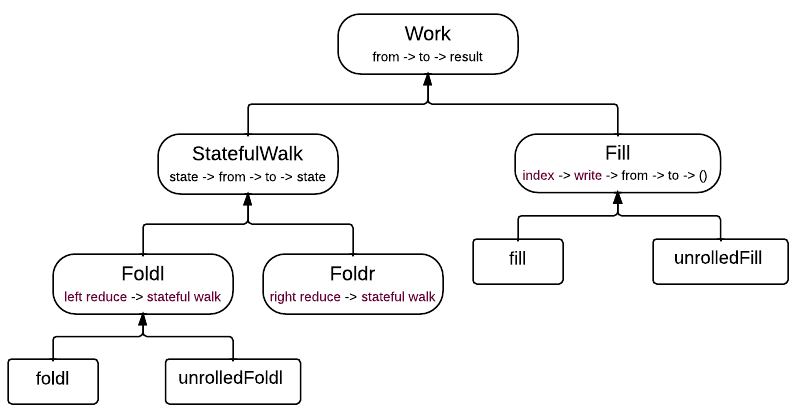
Например, в фреймворке Yarr я использую целую систему функций для параметризации вычислений вместо конфигурационных структур. На схеме изображена иерархия типов функций, стрелка «A → B» означает «B получается частичным применением из A», бордовым выделены аргументы, в свою очередь тоже являющиеся функциями:
Чтобы гарантировать, что частично примененная функция будет специализирована, в определении разбейте аргументы лямбдой:
Этот трюк описан в разделе INLINE pragma документации по GHC.
Вызов обобщенной функции (а-ля настоящий полиморфизм в императивных языках) не может быть заинлайнен по определению. Поэтому такие функции обязательно должны быть специализированы в месте вызова. Если GHC точно известен тип аргумента и сама обобщенная функция снабжена директивой
Если стоит цель получить производительную программу, очевидно, лучше ее подольше компилировать, чем исполнять. В Хаскеле есть множество механизмов переноса вычислений на этап компиляции.
В Yarr я использовал маркерные типы-индексы для статической двойной диспетчеризации, статическую арифметику (готовая арифметика и логика есть в библиотеке type-level) и некоторые другие вещи.
О
Сейчас за исключением редких случаев более быстрый машинный код генерирует бекенд LLVM:
Чтобы GHC не занимался гаданием на кофейной гуще и встраивал все, что скажут, Ben Lippmeier рекомендует использовать флаги
В этой статье я обобщаю опыт выжимания максимума из GHC при создании dataflow-фреймворка Yarr.
Статья состоит из достаточно тривиальных по отдельности наблюдений, но, думаю, подойдет как памятка или старт в теме. Описываемые принципы — эмпирические, я не знаю внутреннего устройства GHC. Теорию компиляторов тоже не знаю, поэтому если для чего-то есть общепринятые термины, подсказывайте в комментариях.
Актуальная на данный момент версия GHC — 7.6.1.
Последнее замечание: на самом деле, с GHC «по умолчанию» все не так плохо, как описано в первом абзаце, хотя бы если просто компилировать с опцией
-O2. Иногда компилятор делает быстрый машинный код и без подсказок программиста, но это зависит исключительно от положения звезд, бывает достаточно поправить в программе одну букву, чтобы GHC вдруг перестал понимать, как ее оптимизировать.Можно выделить 2 основных направления оптимизаций, которые проводит GHC:
- Расщепление типов данных на элементарные кусочки и преобразование функций для непосредственной работы с ними (см. Unboxed types and primitive operations)
- Встраивание (inline) и специализация функций
Они поддерживают друг друга, т. е. если структуры данных не расщепляются, то хуже и встраиваются функции, и наоборот. Поэтому бессмысленно следовать только паре нижеследующих советов, результата почти не будет.
Типы данных
Избегайте типов данных с несколькими конструкторами
В том числе Maybe, Either и списков, какими бы «стандартными» они не были. Причина очевидна — такие типы данных нельзя разложить на составляющие, потому что статически не известно, какая у них вообще структура.
Единственное исключение — типы-перечисления с несколькими конструкторами без параметров:
Bool, Ordering и т. д.Если вдуматься, списки в Хаскеле — суть односвязные, которые практически не используются в императивных языках из-за своей медлительности. Так почему бы и в Хаскеле не использовать вместо них вектора (вместо стандартных строк — ByteString), едва ли уступающие спискам по удобству и возможностям. Для замены коротких списков в несколько элементов еще лучше подойдут вектора статически известной длины.
См. также: HaskellWiki — Performance/Data types.
Объявляйте поля в структурах строгими, если точно не знаете, почему они должны быть ленивыми
Обычное, ленивое поле — это ссылка на замыкание, которое вернет значение поля. Строгое поле — ссылка на значение поля. Встроенное (unboxed) поле — само значение (если это тоже структура, то она целиком встраивается в родительскую). Встроенное поле получается добавлением к строгому директивы
{-# UNPACK #-}.Без 1-го варианта, как и в случае со списками, на самом вполне неплохо живется. В каждом случае делайте осознанный выбор в пользу 2 или 3 варианта. Поля по ссылке иногда эффективнее по памяти, быстрее при создании структур, проверках на равенство. Встроенные поля быстрее при чтении. Если чаще нужны встроенные поля (скорее всего), компилируйте с флагом
-funbox-strict-fields и добавляйте к «ссылочным» полям директиву {-# NOUNPACK #-}.См. также: Haskell Style Guide/Dealing with laziness.
Явно вычисляйте структуры перед многократным использованием
В примере структура
t много раз используется при отображении вектора:import Data.Vector as V ... data T = T !Int !Int fSum (T x y) = x + y ... -- t :: T V.map (+ (fSum t)) longVectorOfInts
GHC не выносит вычисление структуры из «цикла»:
-- Как примерно GHC скомпилирует последнюю строчку V.map (\x -> case t of (T y z) -> x + y + z) longVectorOfInts
В машинном коде на каждой итерации будет переход по ссылке и чтение одних и тех же полей.
Однако если «подсказать» компилятору снаружи цикла, он не повторяет вычисления, уже проведенные где-то выше по АСД (абстрактному синтаксическому дереву):
case t of (T x y) -> V.map (+ (fSum t)) longVectorOfInts -- GHC скомпилирует нормально: case t of (T x y) -> let s = x + y in V.map (\x -> x + s) longVectorOfInts
Вместо написания кейсов вручную можно использовать обобщенный control flow из пакета deepseq.
Пример не очень удачный, потому что структура
t используется один раз и можно просто выделить fSum t как переменную, но думаю суть приема ясна.Функции
Правило №1: добавляйте ко всем маленьким, часто (на рантайме) вызываемым, живущим далеко от корня АСД функциям директиву
INLINE. Если функции не встраиваются, советы из этого раздела становятся вредными.Больше функций, лямбд, каррирования!
Или, говоря по-умному, применяйте continuation passing style.
Преимущество замыканий перед структурами данных в том, что GHC гораздо положительнее настроен на их объединение и редукцию.
Например, в фреймворке Yarr я использую целую систему функций для параметризации вычислений вместо конфигурационных структур. На схеме изображена иерархия типов функций, стрелка «A → B» означает «B получается частичным применением из A», бордовым выделены аргументы, в свою очередь тоже являющиеся функциями:
Чтобы гарантировать, что частично примененная функция будет специализирована, в определении разбейте аргументы лямбдой:
f :: A -> B -> C {-# INLINE f #-} f a b = ... -- body where ... -- declarations --> f a \b -> let ... -- declarations in ... -- body
Этот трюк описан в разделе INLINE pragma документации по GHC.
Будьте осторожны с обобщенными функциями
Вызов обобщенной функции (а-ля настоящий полиморфизм в императивных языках) не может быть заинлайнен по определению. Поэтому такие функции обязательно должны быть специализированы в месте вызова. Если GHC точно известен тип аргумента и сама обобщенная функция снабжена директивой
INLINE, то он обычно делает это. При распространении обобщенности на несколько уровней функций — не специализирует.Поднимайте на уровень типов все, что можно
Если стоит цель получить производительную программу, очевидно, лучше ее подольше компилировать, чем исполнять. В Хаскеле есть множество механизмов переноса вычислений на этап компиляции.
В Yarr я использовал маркерные типы-индексы для статической двойной диспетчеризации, статическую арифметику (готовая арифметика и логика есть в библиотеке type-level) и некоторые другие вещи.
Флаги компиляции
-O2 — всегда.О
-funbox-strict-fields написано выше.Сейчас за исключением редких случаев более быстрый машинный код генерирует бекенд LLVM:
-fllvm -optlo-O3.Чтобы GHC не занимался гаданием на кофейной гуще и встраивал все, что скажут, Ben Lippmeier рекомендует использовать флаги
-funfolding-use-threshold1000 -funfolding-keeness-factor1000.