Когда-то управление автомобилем было почти искусством. Во времена славной классики (шестёрок и пятёрок) нужно было знать, как прочистить карбюратор, заменить топливный насос и что такое «подсос».
Когда-то компьютеры были большими и слово «debug» использовалось в самом прямом его смысле. Когда первые ПК начали входить в наши дома, было важно понимать, что такое северный и южный мост, как установить драйвер для видеоплаты, и какое значение поменять в системном реестре, чтобы таки запустить привередливую игру.
Сегодня хоть для личного использования, хоть для бизнеса, вы приходите в магазин, покупаете машину, нажимаете кнопку «ВКЛ» и начинаете пользоваться.
Да есть, нюансы — не пройдёт такой трюк с System p5 595 или Bagger 293 — нужны технические специалисты. Однако в базисе, даже для компании из нескольких филиалов — вы купили газельку, несколько ПК, обеспечили их выходом в Интернет — и можно работать.
Некоторое время назад у меня состоялся спор с человеком от сетей далёким. У него был резонный вопрос: почему нельзя автоматизировать создание и настройку корпоративных сетей небольшого размера. То есть почему он не может купить по одной железке в каждый свой филиал, нажать 5 кнопок на каждой и получить работающую стабильную сеть?
Вопрос был даже более глубокий и затрагивающий личные струны: зачем такой штат техподдержки (у компаний, провайдеров, вендоров). Разве нельзя в автоматическом режиме находить и исправлять бОльшую их часть?
Да, мне известны многие аргументы, которые тотчас всплывают в вашей голове. Такая постановка вопроса и мне сначала показалась утопической. И это логично, что сейчас это кажется невозможным в сфере связи — максимум в рамках одного домашнего маршрутизатора, но и там не всё гладко.
Однако вопрос не лишён рационального начала, и он завладел моим разумом на долгое время. Правда, я абстрагировался от корпоративных SOHO и SMB сетей и посвятил свои мысли сетям провайдерским.
С точки зрения нетехнического специалиста может казаться, что автоматическая настройка важнее и проще в реализации, чем поиск неисправностей. Но любому инженеру должно быть очевидно, что именно траблшутинг выкладывает дорожку из жёлтого кирпича — если мы не знаем, в чём может быть проблема, как мы можем пытаться что-то настроить?

В этой отправной статье под катом я хочу поделиться своими размышлениями на тему различных препятствий на пути к поставленной цели и способах их преодоления
На мой взгляд, первичная задача — это всё-таки научить оборудование автоматически находить проблемы и их причины. Именно об этом я и хотел бы поговорить в первую очередь сегодня.
Далее — научиться их исправлять. То есть зная, в чём причина проблемы, вполне можно решить её без участия человеков в большинстве случаев.
Как вырожденный случай исправления проблемы — настройка по шаблону. У нас есть LLD (Low Level Design — подробный дизайн сети) и на его основе Система Контроля настроит всё оборудование — от коммутаторов доступа до High-End маршрутизаторов в ядре сети: IP-адреса, VLAN, протоколы маршрутизации, политики QoS.
В принципе, в том или ином виде это есть уже сейчас — автонастройка по шаблону — не какая-то невидаль. Просто обычно речь всё-таки не о всей сети, а о каких-то гомогенных сегментах, например, коммутаторы доступа. Тут идёт жёсткая привязка к командному интерфейсу и, соответственно, производителю.
Сейчас это всё реализовано втупую — никакой проверки консистентности скрипт не делает — если в дизайне есть ошибка, она будет и на оборудовании. Есть, конечно, валидаторы конфигурации, но это ещё один «ручной» шаг.
Задача максимум амбициозна — автоматическая генерация топологии, IP-плана, таблиц коммутации и, собственно, настройка всего и вся. Максимум участия человека — утвердить дизайн, расставить оборудование и пробросить кабель.
Существует много систем, повышающих отказоустойчивость и понижающих потери/время простоя сервисов при проблеме на сети — IGP, VRRP, Graceful Restart capability, BFD, MPLS TE FRR и многое другое. Но всё это разрозненные куски. Их пытаются слепить в одно целое с переменным успехом, но от этого они не перестают быть разнородными сущностями.
Это напоминает вопрос окончательной теории в науке, согласно которой имеющиеся 4 типа взаимодействия имеют одинаковую природу. Это универсальная, единая теория, объясняющая всё просто и понятно. Но пока картина не складывается.
Вот красивая иллюстрация настроенной взаимосвязи между протоколами:
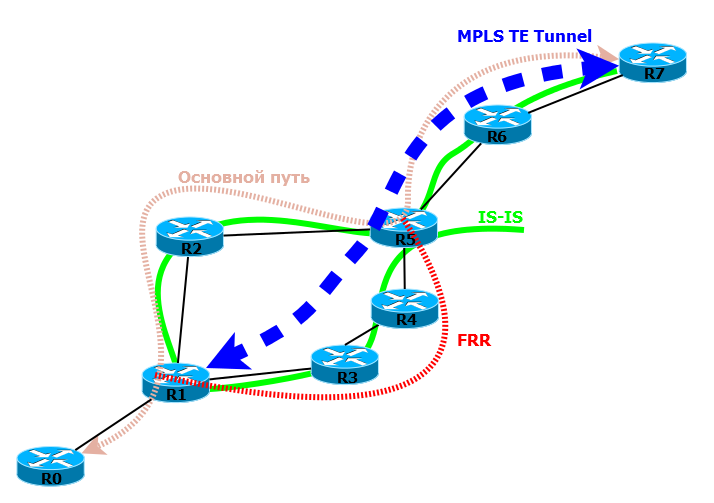
На такой сети запущен IS-IS, как протокол IGP. Поверх него работает MPLS TE с активированной функцией FRR.
R1 по BFD отслеживает статус R2 и статус TE-туннеля/LSP. Когда на R2 из-за ошибки ПО, перезагружается линейная плата, BFD на R1 мгновенно сообщает об этом всем процессам, которые должны быть в курсе. MPLS TE обращается к FRR и трафик перенаправляется на R3 по временному пути.
При этом на R1 благодаря функционалу GR сохраняются все маршруты R2, все соответствующие записи FIB и даже отношение соседства. В этот время R2 приходит в норму, плата подгружается, поднимаются интерфейсы. А на R1 уже всё готово и в кратчайшие сроки он готов передавать трафик снова на R2. В итоге сервисы возвращаются в своё прежнее русло — все довольны, все счастливы, никто из клиентов не почувствовал на себе кривую руку программиста.
Но представляете ли вы, какой объём конфигурации требуется для организации такого взаимодействия? А как часто конфигурация бывает некорректна, и резервирование отрабатывает совсем не так, как мы этого хотели? А что зачастую у инженеров может не хватить компетенции на настройку таких вещей, и многие корпоративные сети стоят с минимальной настройкой сервисов? Всё пока работает и слава богу! А что огромное количество проблем можно обнаружить на ранних этапах и предотвратить тот момент, когда это выльется в 3 часа простоя и потерю репутации?
Поэтому проведём некоторую классификацию проблем, чтобы понять, какие к ним нужны подходы.
Первый — проблемы, возникшие сейчас всилу обстоятельств — обрыв кабеля, сбой работы ПО или оборудования. Это по сути единственный на данный момент тип, с которым разработчики как-то борятся. Это то, что мы рассмотрели выше. У нас уже не один десяток протоколов, которые отслеживают состояние каналов и сервисов и могут на основе реальной ситуации перестраивать топологию. Но проблема в то, что, как я уже заметил, это всё элементы разных головоломок. Каждый протокол, каждый механизм настраивается индивидуально. И нужны недюжинные способности, чтобы охватить всё это целиком и иметь принципиальное понимание работы крупных сетей.
Ну хорошо, так или иначе, но мы с ними можем справляться — есть для этого средства. Какая здесь есть проблема, помимо собственно сложности? Объясню: после того, как всё случилось, мы либо ничего не заметили (50 мс на глазок не всегда), либо перебираем тонны логов и аварий, пытаясь установить причинно-следственную связь череды событий. А это, знаете ли, дело непростое, потому что поверхностных логов может не хватить, а подробные будут содержать огромное количество малоинформативных данных, например, падение LSP — по записи на каждую, процесс перезагрузки платы итд. Делать это нужно не на одной железке, а на всех по ходу движения трафика и часто даже тех, которые стоят в стороне. Нужно отделить зёрна от плевел — логи, связанные с аварией от тех, которые относятся к другим проблемам. И хорошо, если сеть моновендорная, а если у вас в качестве CE стоит DLink, PE — Huawei, P — cisco, a ASBR — Juniper… Ну что же, тут остаётся посочувствовать.
К чему я, собственно, веду. Логи — это хорошо, это прекрасно, они нужны. Но они не в удобочитаемом виде. Даже, если у вас правильная сеть, с настроенным NTP и SYSLOG-сервером, который позволяет просмотреть в действительно хронологическом порядке все аварии на всех устройствах, на поиск проблемы уйдёт масса времени.
При этом каждое устройство знает, что на нём произошло. Возвращаясь к последнему примеру, PE видит падение туннелей, VPN, перестроение IGP. Он может сообщить Системе Контроля в человеческом виде, что, мол, «В 16:20:12 01.01.2013 у меня упали все туннели и VPN'ы в таком-то направлении, через такой-то интерфейс. Кроме того, перестроилась схема маршрутизации. Что там произошло не уверен, но вот OSPF мне сообщил о пропадании линка между устройствами А и Б. Также о проблеме отчитался RSVP».
Промежуточный P, на котором выгорел SFP-модуль так и говорит: «В 16:20:12 01.01.2013 у меня был повреждён SFP-модуль в порту 1/1/1. Я всё проверил — аппаратная неисправность, нужна замена. По OSPF и RSVP разослал уведомление всем соседям».
Шутки шутками, конечно, но почему бы не разработать стандарт или какой-то протокол, который позволит на самом устройстве провести минимальный анализ и отправить однозначную информацию на Систему Контроля. Получив данные со всех устройств, скомпоновав их и проанализировав, Система Контроля может выдать вполне конкретное сообщение:
«В 16:20:12 на устройстве Б вышел из строя SFP-модуль в порту 1/1/1 (тут ссылочка на тип модуля, серийный номер, аптайм, средний уровень сигнала, количество ошибок на интерфейсе, причина выхода из строя). Это повлекло за собой падение следующих туннелей (список, со ссылками на параметры туннелей), VPN (список, со ссылками на параметры VPN). В 16:20:12 трафик был направлен через временный путь А-С-Е (ссылка на параметры пути: интерфейсы, метки MPLS, VPN итд.). В 16:20:14 был построен новый LSP А-Б»
Что это за проблемы? Ошибки на интерфейсах, которые пока под слабой нагрузкой, и они не дают о себе знать. Флаппинг интерфейсов или маршрутов на резервных линках, слишком лёгкие пароли, отсутствие ACL на VTY или на внешнем интерфейсе, большое количество широковещательных сообщений, поведение, похожее на атаки (обилие ARP, DHCP запросов), высокая утилизация ЦПУ каким-либо процессом, отсутствие чернодырых маршрутов (blackhole) при настроенной агрегации маршрутов.
Так или иначе сейчас многие такие ситуации отслеживаются и информационные сообщения пишутся в логи.Кто бы их отслеживал? Однако на такие вещи не обращают внимание, пока не вызовут на ковёр в связи с отсутствием связи у тысячи абонентов. И в автоматическом режиме оборудование не пытается найти причину или исправить ситуацию — в лучшем случае настроена отправка на SYSLOG-сервер.
Бывает, конечно, срабатывание чего-либо при определённых действиях — подавление широковещательных пакетов, если их число превышает определённый порог, например. Или отключение порта, на котором наблюдается флаппинг. Но это всё лечение симптомов — оборудование не пытается разобраться, в чём причина такого поведения.
Какие есть мысли по поводу данной ситуации? Разумеется, во-первых, это стандартизация логов и трапов. Стандартизация глобальная, на уровне комитетов. Все производители должны чётко придерживаться их, как, например, стандарта IP.
Да, это гигантский объём работы. Нужно предусмотреть все возможные ситуации и сообщения для всех протоколов. Но так или иначе её проделывает каждый вендор в отдельности, изобретая свои способы сообщить о проблеме. Так, может, лучше один раз собраться и договориться раз и навсегда? В конце концов Martini L2VPN тоже когда-то был личной разработкой Cisco.
Отсылать на систему контроля можно в таком виде, например:
«Message_Number.Parent_Message_Number.Device_ID. Date. Time/Time range.Alarm_ID.Optional parameters»
Message_Number — порядковый номер аварии в сети.
Parent_Message_Number — номер родительской аварии, которая повлекла за собой данную.
Device_ID — уникальный идентификатор устройства в сети.
Date — Дата аварии.
Time/Time range — Время возникновения аварии или период её длительности.
Alarm_ID — уникальный идентификатор аварии в стандарте.
Optional parameters — Дополнительные параметры, характерные для данной аварии.
Во-вторых, оборудование должно уметь само проводить минимальный анализ ситуации и логов. Оно должно знать где причина, где следствие и помимо детализированных логов отсылать также результаты анализа.
Например, если падение BFD, IGP и других протоколов было вызвано физическим отключением интерфейса, то он должен представить это в виде ветки зависимостей: падение порте повлекло за собой то-то и сё-то.
В-третьих, Интеллектуальная Система Контроля Работы Сети должна отразить аварии в человеческом виде.
Пусть после анализа на сервер мониторинга было отправлено стандартизированное сообщение, например:
Система Контроля разбирает данные сообщения на составляющие:
Авария №2374698214. Не является следствием чего-либо. Произошла на устройстве с ID 8422 29.10.2013. Длилась с 09:00:00 до 10:00:05. Универсальный идентификатор аварии 65843927456. Дополнительные параметры: GE0/0/0.
Авария №2374698219. Вызвана аварией «2374698214. Произошла на устройстве с ID 8422 29.10.2013. Длилась с 10:00:00 до 10:00:05. Универсальный идентификатор аварии 50. Дополнительные параметры: 90. 70. R2D2.
Авария №2374698220. Вызвана аварией „2374698214. Произошла на устройстве с ID 8422 29.10.2013 в 10:00:05. Универсальный идентификатор аварии 182. Дополнительные параметры: GE0/0/0. Abnormal Power flow. Power treshold is reached. Abnormal power timer is expired.
Далее он обращается в базу данных сетевых устройств и извлекает описание устройства с номером 8422.
В онлайн или в локальной копии глобальной БД аварий находит описание и значение аварии 65843927456 — аномально высокий поток силы. В качестве параметра — интерфейс-источник GE0/0/0.
50 — Высокая загрузка ЦПУ. Параметры: общая загрузка (90), самый нагружающий процесс (R2D2) и утилизация ЦПУ данным процессом (70).
182 — выключение интерфейса. В параметрах номер интерфейса и причина, по которой интерфейс бы выключен.
Далее Система Контроля формирует понятное и исчерпывающее сообщение:
“К коммутатору C3PO было подключено внешнее устройство к интерфейсу 10GE 0/0/0, генерировавшее аномально высокий поток силы в период с 09:00:00 до 10:00:05.
По этой причине процесс R2D2 утилизировал ЦПУ на 70% в период времени с 10:00 до 10:00:05. Порт был выключен в 10:00:05.
Abnormal Power flow. Power treshold is reached. Abnormal power timer is expired».
Не стоит, думаю, лишний раз говорить о том, что ничто не вечно, никто не идеален — интерфейсные карты выходят из строя, карты памяти обретают битые сектора, платы спонтанно перезагружаются, программисты внезапно исчезают.
Мне видится, что если проблема аппаратная и так или иначе решилась, оборудование однозначно может самостоятельно установить причину — потеря синхронизации, неисправность шины управления или мониторинга, выход из строя блока питания платы.
Одни проблемы имеют накопительный характер, другие внезапный, но, мне кажется, все их можно отследить. Даже, например, полное отключение линейной платы — управляющая плата даже в отсутствие основного питания должна суметь опросить плату и выявить проблему. Если не получается опросить, значит либо сам опрашиватель неисправен — легко проверить, либо плату на замену.
Опять же Система Контроля должна получить сообщение об этом:
«Линейная плата в слоту 4 потеряла синхронизацию с коммутационными фабриками из-за повреждения сетевого чипа L43F. Плату необходимо заменить». И тут же по ссылке сгенерированный шаблон на замену оборудования.
Тут всё просто. Либо у вендора есть хорошая база ПО, патчей и их описания со списком доступного функционала и решённых проблем, либо нет. Естественно, если нет, нам надо, чтобы да.
Система Контроля просто следит за всеми обновлениями и при необходимости загружает их и устанавливает.
Пожалуй, это самый сложный аспект. Тут огромное многообразие вариаций. Даже обычный IP вызовет бурю эмоций при попытке реализовать его автоматическую отладку.
Формализовать правила конфигурации, означает создать универсальный язык взаимодействия между Системой Контроля и оборудованием. Ну, нельзя же пытаться разгрести на одном сервере разрозненные данные от Juniper, Cisco, ZTE и Dlink. Нельзя создавать парсер, который будет подстраиваться под данные с разных устройств.
То есть будет необходима стандартизация как минимум хранения конфигурации и передачи её на Систему Контроля.
Как это видится мне: должен быть блок описания возможностей системы: что за тип (коммутатор, маршрутизатор, файрвол итд.), функционал (OSPF, MPLS, BGP). Дальше должны быть секции собственно конфигурации. Такая структура должна поддерживаться любым оборудованием от коммутатора доступа до VoIP шлюза в IMS-ядре.
Тогда с лёгкостью можно находить разнообразные неточности: неконсистентные настройки параметров на оппозитных устройствах (например, дискриминаторы BFD, уровни сетей IS-IS, соседи BGP, IP-адреса), совпадающие Router-ID, неактивированный PIM между двумя мультикастовыми маршрутизаторами итд.
Но, положа руку на сердце, — уже это вещи нетривиальные и реализуемые только должной стандартизации топологий или формализованного LLD (Low Level Design).
Примеры из реальной жизни для всего описанного выше я уже приводил в этой статье.
На мой взгляд в этой сфере (как и во многих других), сейчас огромное количество лишней работы и перерасход человеческих ресурсов.
Будем говорить о сетях операторского уровня, с SOHO и SMB совсем другие тонкости.
Возьмём для примера процедуру замены неисправной платы.
Сейчас она следующая (с некоторыми вариации для разных вендоров):
1) Плата вышла из строя, перезагрузилась или начала валить странными сообщениями. Заказчик видит в логах ошибки, аварии, но не может однозначно идентифицировать проблему.
2) Заказчик звонит на горячую линию поддержки вендора, описывает проблему на словах, либо заполняет стандартную форму. Предоставляет данные, логи, файлы, собранные рабским трудом или вовсе самостоятельно.
3) Оператор горячей линии открывает запрос назначает его на группу технических специалистов.
4) Ответственный группы назначает запрос инженеру.
5) Инженер анализирует данные и в итоге видит те же аварии. Подключается к оборудованию, проводит ряд тестов, собирает информацию.
6) Зачастую у инженера нет возможности установить истинную причину, и он не может по своей воле рекомендовать замену — эскалация запроса на следующий уровень.
7) В зависимости от компетенции инженеров более высокого уровня, запрос может путешествовать там какое-то время. До тех пор пока путём ввода определённых команд или анализа логов и диагностической информации согласно определённому алгоритму не будет установлена аппаратная неисправность.
8) По цепочке рекомендация доходит до ответственного инженера и далее до заказчика.
9) Затем следует процедура подтверждения закрытия запроса и различная бюрократия.
10) Заказчик открывает новый запрос на замену — снова заполняет форму, снова указывает проблему. Кол-центр переводит заявку на соответствующий отдел, назначаются ответственные и только потом фактически начинается процедура замены.
Это довольно пессимимстичный сценарий, но так или иначе вся эта процедура занимает продолжительно время и на неё необходимы усилия как минимум 4-5 людей — инженер заказчика, оператор кол-центра, Тимлид группы, инженер поддержки, инженеры более высоких уровней, сотрудники отдела запасных частей.
А ведь по сути — есть алгоритмы проверки физических параметров плат. Да их много, но не будем лукавить, их можно ввести в ПО или даже в аппаратную часть плат/шасси.
Оборудование само должно провести этот анализ, и в случае аппаратной проблемы Система Контроля должна выдать однозначную рекомендацию на замену (а, возможно, самостоятельно оформить заявку на замену — по шаблону же). Если ни одна известная аппаратная проблема не подтвердилась, Система Контроля должна предложить открыть запрос в ТП. А лучше опять же самостоятельно заполнить шаблон и зарегистрировать тикет — задача человека — подтвердить заявку.
Аналогично по очень многим другим вопросам.
Я не могу судить о разных вендорах, но часто бывают вопросы о том, какие версии ПО в данный момент актуальны, какие патчи должны быть установлены, какой функционал доступен в них.
Я считаю, что всем этим должна заниматься Система Контроля — подкачивать ПО, патчи, отслеживать текущие известные проблемы по оборудованию, устанавливать патчи, обновлять прошивки. Более подробно опишу в одной из следующих статей то, как я вижу работу такой системы.
Вопросы по конфигурации, неработоспособность каких-то сервисов? Часть таких вещей довольно очевидна и заключается либо в неправильном применении инструкций по настройке, либо несоответствии конфигураций на различных устройствах. Но такие ситуации инженер ТП легко отслеживает, вводя определённые команды. Разве не может то же самое сделать и Система Контроля? Проанализировать конфигурацию и понять проблему и даже исправить её?
Да, у многих инженеров и у меня в том числе есть весомый вопрос — а что тогда делать всем нам, если нас можно заменить автоматикой?
Спешу вас успокоить — мы все устареем, как трубочисты и барышни на коммутаторах.
На самом деле это вечный вопрос и повод для стычек. Куда делись кучеры с появлением автомобилей, куда делся огромный штат, обслуживающий первые ЭВМ с появлением компактных ПК?
Современный мир предлагает нам всё больше разнообразных рабочих мест. В конце концов можно устроиться топливным элементом для матрицы.
Но никуда не денется обслуживающий персонал и техническая поддержка — есть масса проблем, которые нельзя решить автоматически в силу тех или иных причин (например, административных). Эти и другие вопросы я рассмотрел в другой статье.
Сети надо проектировать, кабель надо прокладывать, за Системой Контроля следить, проблемы решать.
Просто нашу жизнь нужно сделать несколько более разумной.
Гораздо более важная проблема — поддержка вендоров.
Я полностью согласен с комментариями к статье на наг.ру, такая система, вместо со стандартами и суперпротоколами никому не нужна сейчас.
У вендоров есть свои NMS, которые они продают за большие деньги (огромные, надо сказать). Да и если будут такие стандарты, оборудование одного вендора можно просто менять на другого и никто этого не заметит. А оно им надо?
У крупных операторов (да и не очень крупных) часто есть самописные системы. Это и валидаторы конфигураций, и скрипты по автонастройке, и поверхностные анализаторы проблем.
Инженеры часто инертны и ленивы, либо наоборот гиперактивны и вручную ваяют тысячи строк, которые сгинут при форматировании винчестера следующим поколением админов.
Как бы то ни было, всё это не то. Совершенно не то.
После разговоров с коллегами я понял, что складывается неправильное понимание идеи — мол, я хочу предложить создание какой-то программной Системы Контроля, которая скриптами будет парсить логи, конфигурации и выдавать решение. При этом в ней будет 33 тысячи шаблонов для разных вендоров и разных версий ПО. И это чьё-то проприетарное решение, созданное волей одного предприимчивого человека.
НЕТ. Речь о вещах более масштабных — глобальная стандартизация системы сообщений между устройствами. Не Система Контроля должна заботиться о том, чтобы суметь распознать логи с Huawei, Cisco, Extreme, F5 и Juniper. Это само оборудование должно отсылать логи в строго определённом формате. Не кучка инертных скриптов по разным протоколам (FTP, TFTP, Telnet, SSH) должна собирать информацию о конфигурации, авариях, параметрах — это должна быть единая гибкая вендоронезависимая система.
Другая крайность — парадигма SDN. Это тоже другое. SDN — концентрирует в себе не только функции мониторинга — он забирает на себя практически все задачи оборудования, кроме собственно передачи данных — он принимает все решения о том, как передавать эти данные. Нет канала до мозга SDN — нет сети.
То, о чём веду речь я — всё та же гибкая сеть с самостоятельными устройствами, каждое из которых самодостаточно. А Система Контроля позволяет держать руку на пульсе — знать всё, что происходит в сети, заботиться обо всех проблемах при минимальном участии людей и предоставлять важную информацию в доступном виде.
P.S.
Я не претендую на полноту рассмотрения вопроса — моего уровня знаний явно не хватает, чтобы целиком его объять. Это лишь размышления.
Но я уверен, что это вектор развития сетевых технологий в плане обслуживания и поддержки. Через 50-80 лет всё изменится — сети будут охватывать не только компьютеры, планшетники и телефоны, в сети будет всё. Сплошная конвергенция — WiFi, фиксированные сети, 5G, 6G, телефония, видео, Интернет, M2M. Всё явно идёт не по пути упрощения и на традиционное обслуживание будет уходить всё больше и больше сил и средств.
Самое главное, что такие стандарты должны подойти вовремя. Сейчас не их время, но уже пора говорить об этом.
По ходу написания этой статьи, которая изначально планировалась вовсе как заметка, я пришёл к выводу, что тема для меня слишком интересная и будет ещё серия статей, посвящённых этой проблеме:
Когда-то компьютеры были большими и слово «debug» использовалось в самом прямом его смысле. Когда первые ПК начали входить в наши дома, было важно понимать, что такое северный и южный мост, как установить драйвер для видеоплаты, и какое значение поменять в системном реестре, чтобы таки запустить привередливую игру.
Сегодня хоть для личного использования, хоть для бизнеса, вы приходите в магазин, покупаете машину, нажимаете кнопку «ВКЛ» и начинаете пользоваться.
Да есть, нюансы — не пройдёт такой трюк с System p5 595 или Bagger 293 — нужны технические специалисты. Однако в базисе, даже для компании из нескольких филиалов — вы купили газельку, несколько ПК, обеспечили их выходом в Интернет — и можно работать.
Некоторое время назад у меня состоялся спор с человеком от сетей далёким. У него был резонный вопрос: почему нельзя автоматизировать создание и настройку корпоративных сетей небольшого размера. То есть почему он не может купить по одной железке в каждый свой филиал, нажать 5 кнопок на каждой и получить работающую стабильную сеть?
Вопрос был даже более глубокий и затрагивающий личные струны: зачем такой штат техподдержки (у компаний, провайдеров, вендоров). Разве нельзя в автоматическом режиме находить и исправлять бОльшую их часть?
Да, мне известны многие аргументы, которые тотчас всплывают в вашей голове. Такая постановка вопроса и мне сначала показалась утопической. И это логично, что сейчас это кажется невозможным в сфере связи — максимум в рамках одного домашнего маршрутизатора, но и там не всё гладко.
Однако вопрос не лишён рационального начала, и он завладел моим разумом на долгое время. Правда, я абстрагировался от корпоративных SOHO и SMB сетей и посвятил свои мысли сетям провайдерским.
С точки зрения нетехнического специалиста может казаться, что автоматическая настройка важнее и проще в реализации, чем поиск неисправностей. Но любому инженеру должно быть очевидно, что именно траблшутинг выкладывает дорожку из жёлтого кирпича — если мы не знаем, в чём может быть проблема, как мы можем пытаться что-то настроить?
В этой отправной статье под катом я хочу поделиться своими размышлениями на тему различных препятствий на пути к поставленной цели и способах их преодоления
На мой взгляд, первичная задача — это всё-таки научить оборудование автоматически находить проблемы и их причины. Именно об этом я и хотел бы поговорить в первую очередь сегодня.
Далее — научиться их исправлять. То есть зная, в чём причина проблемы, вполне можно решить её без участия человеков в большинстве случаев.
Как вырожденный случай исправления проблемы — настройка по шаблону. У нас есть LLD (Low Level Design — подробный дизайн сети) и на его основе Система Контроля настроит всё оборудование — от коммутаторов доступа до High-End маршрутизаторов в ядре сети: IP-адреса, VLAN, протоколы маршрутизации, политики QoS.
В принципе, в том или ином виде это есть уже сейчас — автонастройка по шаблону — не какая-то невидаль. Просто обычно речь всё-таки не о всей сети, а о каких-то гомогенных сегментах, например, коммутаторы доступа. Тут идёт жёсткая привязка к командному интерфейсу и, соответственно, производителю.
Сейчас это всё реализовано втупую — никакой проверки консистентности скрипт не делает — если в дизайне есть ошибка, она будет и на оборудовании. Есть, конечно, валидаторы конфигурации, но это ещё один «ручной» шаг.
Задача максимум амбициозна — автоматическая генерация топологии, IP-плана, таблиц коммутации и, собственно, настройка всего и вся. Максимум участия человека — утвердить дизайн, расставить оборудование и пробросить кабель.
Автоматический поиск неисправностей
Существует много систем, повышающих отказоустойчивость и понижающих потери/время простоя сервисов при проблеме на сети — IGP, VRRP, Graceful Restart capability, BFD, MPLS TE FRR и многое другое. Но всё это разрозненные куски. Их пытаются слепить в одно целое с переменным успехом, но от этого они не перестают быть разнородными сущностями.
Это напоминает вопрос окончательной теории в науке, согласно которой имеющиеся 4 типа взаимодействия имеют одинаковую природу. Это универсальная, единая теория, объясняющая всё просто и понятно. Но пока картина не складывается.
Вот красивая иллюстрация настроенной взаимосвязи между протоколами:
На такой сети запущен IS-IS, как протокол IGP. Поверх него работает MPLS TE с активированной функцией FRR.
R1 по BFD отслеживает статус R2 и статус TE-туннеля/LSP. Когда на R2 из-за ошибки ПО, перезагружается линейная плата, BFD на R1 мгновенно сообщает об этом всем процессам, которые должны быть в курсе. MPLS TE обращается к FRR и трафик перенаправляется на R3 по временному пути.
При этом на R1 благодаря функционалу GR сохраняются все маршруты R2, все соответствующие записи FIB и даже отношение соседства. В этот время R2 приходит в норму, плата подгружается, поднимаются интерфейсы. А на R1 уже всё готово и в кратчайшие сроки он готов передавать трафик снова на R2. В итоге сервисы возвращаются в своё прежнее русло — все довольны, все счастливы, никто из клиентов не почувствовал на себе кривую руку программиста.
Но представляете ли вы, какой объём конфигурации требуется для организации такого взаимодействия? А как часто конфигурация бывает некорректна, и резервирование отрабатывает совсем не так, как мы этого хотели? А что зачастую у инженеров может не хватить компетенции на настройку таких вещей, и многие корпоративные сети стоят с минимальной настройкой сервисов? Всё пока работает и слава богу! А что огромное количество проблем можно обнаружить на ранних этапах и предотвратить тот момент, когда это выльется в 3 часа простоя и потерю репутации?
Поэтому проведём некоторую классификацию проблем, чтобы понять, какие к ним нужны подходы.
- Критические ситуации реального времени
- Проблемы, которые имеются в данный момент, но не затрагивают сервисы
- Аппаратные проблемы
- Потенциальные проблемы ПО
- Некорректная конфигурация
1. Критические ситуации реального времени
Первый — проблемы, возникшие сейчас всилу обстоятельств — обрыв кабеля, сбой работы ПО или оборудования. Это по сути единственный на данный момент тип, с которым разработчики как-то борятся. Это то, что мы рассмотрели выше. У нас уже не один десяток протоколов, которые отслеживают состояние каналов и сервисов и могут на основе реальной ситуации перестраивать топологию. Но проблема в то, что, как я уже заметил, это всё элементы разных головоломок. Каждый протокол, каждый механизм настраивается индивидуально. И нужны недюжинные способности, чтобы охватить всё это целиком и иметь принципиальное понимание работы крупных сетей.
Ну хорошо, так или иначе, но мы с ними можем справляться — есть для этого средства. Какая здесь есть проблема, помимо собственно сложности? Объясню: после того, как всё случилось, мы либо ничего не заметили (50 мс на глазок не всегда), либо перебираем тонны логов и аварий, пытаясь установить причинно-следственную связь череды событий. А это, знаете ли, дело непростое, потому что поверхностных логов может не хватить, а подробные будут содержать огромное количество малоинформативных данных, например, падение LSP — по записи на каждую, процесс перезагрузки платы итд. Делать это нужно не на одной железке, а на всех по ходу движения трафика и часто даже тех, которые стоят в стороне. Нужно отделить зёрна от плевел — логи, связанные с аварией от тех, которые относятся к другим проблемам. И хорошо, если сеть моновендорная, а если у вас в качестве CE стоит DLink, PE — Huawei, P — cisco, a ASBR — Juniper… Ну что же, тут остаётся посочувствовать.
К чему я, собственно, веду. Логи — это хорошо, это прекрасно, они нужны. Но они не в удобочитаемом виде. Даже, если у вас правильная сеть, с настроенным NTP и SYSLOG-сервером, который позволяет просмотреть в действительно хронологическом порядке все аварии на всех устройствах, на поиск проблемы уйдёт масса времени.
При этом каждое устройство знает, что на нём произошло. Возвращаясь к последнему примеру, PE видит падение туннелей, VPN, перестроение IGP. Он может сообщить Системе Контроля в человеческом виде, что, мол, «В 16:20:12 01.01.2013 у меня упали все туннели и VPN'ы в таком-то направлении, через такой-то интерфейс. Кроме того, перестроилась схема маршрутизации. Что там произошло не уверен, но вот OSPF мне сообщил о пропадании линка между устройствами А и Б. Также о проблеме отчитался RSVP».
Промежуточный P, на котором выгорел SFP-модуль так и говорит: «В 16:20:12 01.01.2013 у меня был повреждён SFP-модуль в порту 1/1/1. Я всё проверил — аппаратная неисправность, нужна замена. По OSPF и RSVP разослал уведомление всем соседям».
Шутки шутками, конечно, но почему бы не разработать стандарт или какой-то протокол, который позволит на самом устройстве провести минимальный анализ и отправить однозначную информацию на Систему Контроля. Получив данные со всех устройств, скомпоновав их и проанализировав, Система Контроля может выдать вполне конкретное сообщение:
«В 16:20:12 на устройстве Б вышел из строя SFP-модуль в порту 1/1/1 (тут ссылочка на тип модуля, серийный номер, аптайм, средний уровень сигнала, количество ошибок на интерфейсе, причина выхода из строя). Это повлекло за собой падение следующих туннелей (список, со ссылками на параметры туннелей), VPN (список, со ссылками на параметры VPN). В 16:20:12 трафик был направлен через временный путь А-С-Е (ссылка на параметры пути: интерфейсы, метки MPLS, VPN итд.). В 16:20:14 был построен новый LSP А-Б»
2. Проблемы, которые имеются в данный момент, но не затрагивают сервисы
Что это за проблемы? Ошибки на интерфейсах, которые пока под слабой нагрузкой, и они не дают о себе знать. Флаппинг интерфейсов или маршрутов на резервных линках, слишком лёгкие пароли, отсутствие ACL на VTY или на внешнем интерфейсе, большое количество широковещательных сообщений, поведение, похожее на атаки (обилие ARP, DHCP запросов), высокая утилизация ЦПУ каким-либо процессом, отсутствие чернодырых маршрутов (blackhole) при настроенной агрегации маршрутов.
Так или иначе сейчас многие такие ситуации отслеживаются и информационные сообщения пишутся в логи.
Бывает, конечно, срабатывание чего-либо при определённых действиях — подавление широковещательных пакетов, если их число превышает определённый порог, например. Или отключение порта, на котором наблюдается флаппинг. Но это всё лечение симптомов — оборудование не пытается разобраться, в чём причина такого поведения.
Какие есть мысли по поводу данной ситуации? Разумеется, во-первых, это стандартизация логов и трапов. Стандартизация глобальная, на уровне комитетов. Все производители должны чётко придерживаться их, как, например, стандарта IP.
Да, это гигантский объём работы. Нужно предусмотреть все возможные ситуации и сообщения для всех протоколов. Но так или иначе её проделывает каждый вендор в отдельности, изобретая свои способы сообщить о проблеме. Так, может, лучше один раз собраться и договориться раз и навсегда? В конце концов Martini L2VPN тоже когда-то был личной разработкой Cisco.
Отсылать на систему контроля можно в таком виде, например:
«Message_Number.Parent_Message_Number.Device_ID. Date. Time/Time range.Alarm_ID.Optional parameters»
Message_Number — порядковый номер аварии в сети.
Parent_Message_Number — номер родительской аварии, которая повлекла за собой данную.
Device_ID — уникальный идентификатор устройства в сети.
Date — Дата аварии.
Time/Time range — Время возникновения аварии или период её длительности.
Alarm_ID — уникальный идентификатор аварии в стандарте.
Optional parameters — Дополнительные параметры, характерные для данной аварии.
Во-вторых, оборудование должно уметь само проводить минимальный анализ ситуации и логов. Оно должно знать где причина, где следствие и помимо детализированных логов отсылать также результаты анализа.
Например, если падение BFD, IGP и других протоколов было вызвано физическим отключением интерфейса, то он должен представить это в виде ветки зависимостей: падение порте повлекло за собой то-то и сё-то.
В-третьих, Интеллектуальная Система Контроля Работы Сети должна отразить аварии в человеческом виде.
Пусть после анализа на сервер мониторинга было отправлено стандартизированное сообщение, например:
«2374698214.0.8422. 29.10.2013 09:00:00-10:00:01.65843927456.GE0/0/0»
«2374698219.2374698214.8422. 29.10.2013 10:00:00-10:00:05. 50. 90. R2D2. 70»
«2374698220.2374698214.8422. 29.10.2013 10:00:01. 182. GE0/0/0. Abnormal Power flow. Power treshold is reached. Abnormal power timer is expired»
Система Контроля разбирает данные сообщения на составляющие:
Авария №2374698214. Не является следствием чего-либо. Произошла на устройстве с ID 8422 29.10.2013. Длилась с 09:00:00 до 10:00:05. Универсальный идентификатор аварии 65843927456. Дополнительные параметры: GE0/0/0.
Авария №2374698219. Вызвана аварией «2374698214. Произошла на устройстве с ID 8422 29.10.2013. Длилась с 10:00:00 до 10:00:05. Универсальный идентификатор аварии 50. Дополнительные параметры: 90. 70. R2D2.
Авария №2374698220. Вызвана аварией „2374698214. Произошла на устройстве с ID 8422 29.10.2013 в 10:00:05. Универсальный идентификатор аварии 182. Дополнительные параметры: GE0/0/0. Abnormal Power flow. Power treshold is reached. Abnormal power timer is expired.
Далее он обращается в базу данных сетевых устройств и извлекает описание устройства с номером 8422.
В онлайн или в локальной копии глобальной БД аварий находит описание и значение аварии 65843927456 — аномально высокий поток силы. В качестве параметра — интерфейс-источник GE0/0/0.
50 — Высокая загрузка ЦПУ. Параметры: общая загрузка (90), самый нагружающий процесс (R2D2) и утилизация ЦПУ данным процессом (70).
182 — выключение интерфейса. В параметрах номер интерфейса и причина, по которой интерфейс бы выключен.
Далее Система Контроля формирует понятное и исчерпывающее сообщение:
“К коммутатору C3PO было подключено внешнее устройство к интерфейсу 10GE 0/0/0, генерировавшее аномально высокий поток силы в период с 09:00:00 до 10:00:05.
По этой причине процесс R2D2 утилизировал ЦПУ на 70% в период времени с 10:00 до 10:00:05. Порт был выключен в 10:00:05.
Abnormal Power flow. Power treshold is reached. Abnormal power timer is expired».
3. Аппаратные проблемы
Не стоит, думаю, лишний раз говорить о том, что ничто не вечно, никто не идеален — интерфейсные карты выходят из строя, карты памяти обретают битые сектора, платы спонтанно перезагружаются, программисты внезапно исчезают.
Мне видится, что если проблема аппаратная и так или иначе решилась, оборудование однозначно может самостоятельно установить причину — потеря синхронизации, неисправность шины управления или мониторинга, выход из строя блока питания платы.
Одни проблемы имеют накопительный характер, другие внезапный, но, мне кажется, все их можно отследить. Даже, например, полное отключение линейной платы — управляющая плата даже в отсутствие основного питания должна суметь опросить плату и выявить проблему. Если не получается опросить, значит либо сам опрашиватель неисправен — легко проверить, либо плату на замену.
Опять же Система Контроля должна получить сообщение об этом:
«Линейная плата в слоту 4 потеряла синхронизацию с коммутационными фабриками из-за повреждения сетевого чипа L43F. Плату необходимо заменить». И тут же по ссылке сгенерированный шаблон на замену оборудования.
4. Потенциальные проблемы ПО
Тут всё просто. Либо у вендора есть хорошая база ПО, патчей и их описания со списком доступного функционала и решённых проблем, либо нет. Естественно, если нет, нам надо, чтобы да.
Система Контроля просто следит за всеми обновлениями и при необходимости загружает их и устанавливает.
5. Некорректная конфигурация
Пожалуй, это самый сложный аспект. Тут огромное многообразие вариаций. Даже обычный IP вызовет бурю эмоций при попытке реализовать его автоматическую отладку.
Формализовать правила конфигурации, означает создать универсальный язык взаимодействия между Системой Контроля и оборудованием. Ну, нельзя же пытаться разгрести на одном сервере разрозненные данные от Juniper, Cisco, ZTE и Dlink. Нельзя создавать парсер, который будет подстраиваться под данные с разных устройств.
То есть будет необходима стандартизация как минимум хранения конфигурации и передачи её на Систему Контроля.
Как это видится мне: должен быть блок описания возможностей системы: что за тип (коммутатор, маршрутизатор, файрвол итд.), функционал (OSPF, MPLS, BGP). Дальше должны быть секции собственно конфигурации. Такая структура должна поддерживаться любым оборудованием от коммутатора доступа до VoIP шлюза в IMS-ядре.
Тогда с лёгкостью можно находить разнообразные неточности: неконсистентные настройки параметров на оппозитных устройствах (например, дискриминаторы BFD, уровни сетей IS-IS, соседи BGP, IP-адреса), совпадающие Router-ID, неактивированный PIM между двумя мультикастовыми маршрутизаторами итд.
Но, положа руку на сердце, — уже это вещи нетривиальные и реализуемые только должной стандартизации топологий или формализованного LLD (Low Level Design).
Примеры из реальной жизни для всего описанного выше я уже приводил в этой статье.
Техподдержка
На мой взгляд в этой сфере (как и во многих других), сейчас огромное количество лишней работы и перерасход человеческих ресурсов.
Будем говорить о сетях операторского уровня, с SOHO и SMB совсем другие тонкости.
Возьмём для примера процедуру замены неисправной платы.
Сейчас она следующая (с некоторыми вариации для разных вендоров):
1) Плата вышла из строя, перезагрузилась или начала валить странными сообщениями. Заказчик видит в логах ошибки, аварии, но не может однозначно идентифицировать проблему.
2) Заказчик звонит на горячую линию поддержки вендора, описывает проблему на словах, либо заполняет стандартную форму. Предоставляет данные, логи, файлы, собранные рабским трудом или вовсе самостоятельно.
3) Оператор горячей линии открывает запрос назначает его на группу технических специалистов.
4) Ответственный группы назначает запрос инженеру.
5) Инженер анализирует данные и в итоге видит те же аварии. Подключается к оборудованию, проводит ряд тестов, собирает информацию.
6) Зачастую у инженера нет возможности установить истинную причину, и он не может по своей воле рекомендовать замену — эскалация запроса на следующий уровень.
7) В зависимости от компетенции инженеров более высокого уровня, запрос может путешествовать там какое-то время. До тех пор пока путём ввода определённых команд или анализа логов и диагностической информации согласно определённому алгоритму не будет установлена аппаратная неисправность.
8) По цепочке рекомендация доходит до ответственного инженера и далее до заказчика.
9) Затем следует процедура подтверждения закрытия запроса и различная бюрократия.
10) Заказчик открывает новый запрос на замену — снова заполняет форму, снова указывает проблему. Кол-центр переводит заявку на соответствующий отдел, назначаются ответственные и только потом фактически начинается процедура замены.
Это довольно пессимимстичный сценарий, но так или иначе вся эта процедура занимает продолжительно время и на неё необходимы усилия как минимум 4-5 людей — инженер заказчика, оператор кол-центра, Тимлид группы, инженер поддержки, инженеры более высоких уровней, сотрудники отдела запасных частей.
А ведь по сути — есть алгоритмы проверки физических параметров плат. Да их много, но не будем лукавить, их можно ввести в ПО или даже в аппаратную часть плат/шасси.
Оборудование само должно провести этот анализ, и в случае аппаратной проблемы Система Контроля должна выдать однозначную рекомендацию на замену (а, возможно, самостоятельно оформить заявку на замену — по шаблону же). Если ни одна известная аппаратная проблема не подтвердилась, Система Контроля должна предложить открыть запрос в ТП. А лучше опять же самостоятельно заполнить шаблон и зарегистрировать тикет — задача человека — подтвердить заявку.
Аналогично по очень многим другим вопросам.
Я не могу судить о разных вендорах, но часто бывают вопросы о том, какие версии ПО в данный момент актуальны, какие патчи должны быть установлены, какой функционал доступен в них.
Я считаю, что всем этим должна заниматься Система Контроля — подкачивать ПО, патчи, отслеживать текущие известные проблемы по оборудованию, устанавливать патчи, обновлять прошивки. Более подробно опишу в одной из следующих статей то, как я вижу работу такой системы.
Вопросы по конфигурации, неработоспособность каких-то сервисов? Часть таких вещей довольно очевидна и заключается либо в неправильном применении инструкций по настройке, либо несоответствии конфигураций на различных устройствах. Но такие ситуации инженер ТП легко отслеживает, вводя определённые команды. Разве не может то же самое сделать и Система Контроля? Проанализировать конфигурацию и понять проблему и даже исправить её?
Cоциально-психологические аспекты
Да, у многих инженеров и у меня в том числе есть весомый вопрос — а что тогда делать всем нам, если нас можно заменить автоматикой?
Спешу вас успокоить — мы все устареем, как трубочисты и барышни на коммутаторах.
На самом деле это вечный вопрос и повод для стычек. Куда делись кучеры с появлением автомобилей, куда делся огромный штат, обслуживающий первые ЭВМ с появлением компактных ПК?
Современный мир предлагает нам всё больше разнообразных рабочих мест. В конце концов можно устроиться топливным элементом для матрицы.
Но никуда не денется обслуживающий персонал и техническая поддержка — есть масса проблем, которые нельзя решить автоматически в силу тех или иных причин (например, административных). Эти и другие вопросы я рассмотрел в другой статье.
Сети надо проектировать, кабель надо прокладывать, за Системой Контроля следить, проблемы решать.
Просто нашу жизнь нужно сделать несколько более разумной.
Гораздо более важная проблема — поддержка вендоров.
Я полностью согласен с комментариями к статье на наг.ру, такая система, вместо со стандартами и суперпротоколами никому не нужна сейчас.
У вендоров есть свои NMS, которые они продают за большие деньги (огромные, надо сказать). Да и если будут такие стандарты, оборудование одного вендора можно просто менять на другого и никто этого не заметит. А оно им надо?
У крупных операторов (да и не очень крупных) часто есть самописные системы. Это и валидаторы конфигураций, и скрипты по автонастройке, и поверхностные анализаторы проблем.
Инженеры часто инертны и ленивы, либо наоборот гиперактивны и вручную ваяют тысячи строк, которые сгинут при форматировании винчестера следующим поколением админов.
Как бы то ни было, всё это не то. Совершенно не то.
После разговоров с коллегами я понял, что складывается неправильное понимание идеи — мол, я хочу предложить создание какой-то программной Системы Контроля, которая скриптами будет парсить логи, конфигурации и выдавать решение. При этом в ней будет 33 тысячи шаблонов для разных вендоров и разных версий ПО. И это чьё-то проприетарное решение, созданное волей одного предприимчивого человека.
НЕТ. Речь о вещах более масштабных — глобальная стандартизация системы сообщений между устройствами. Не Система Контроля должна заботиться о том, чтобы суметь распознать логи с Huawei, Cisco, Extreme, F5 и Juniper. Это само оборудование должно отсылать логи в строго определённом формате. Не кучка инертных скриптов по разным протоколам (FTP, TFTP, Telnet, SSH) должна собирать информацию о конфигурации, авариях, параметрах — это должна быть единая гибкая вендоронезависимая система.
Другая крайность — парадигма SDN. Это тоже другое. SDN — концентрирует в себе не только функции мониторинга — он забирает на себя практически все задачи оборудования, кроме собственно передачи данных — он принимает все решения о том, как передавать эти данные. Нет канала до мозга SDN — нет сети.
То, о чём веду речь я — всё та же гибкая сеть с самостоятельными устройствами, каждое из которых самодостаточно. А Система Контроля позволяет держать руку на пульсе — знать всё, что происходит в сети, заботиться обо всех проблемах при минимальном участии людей и предоставлять важную информацию в доступном виде.
P.S.
Я не претендую на полноту рассмотрения вопроса — моего уровня знаний явно не хватает, чтобы целиком его объять. Это лишь размышления.
Но я уверен, что это вектор развития сетевых технологий в плане обслуживания и поддержки. Через 50-80 лет всё изменится — сети будут охватывать не только компьютеры, планшетники и телефоны, в сети будет всё. Сплошная конвергенция — WiFi, фиксированные сети, 5G, 6G, телефония, видео, Интернет, M2M. Всё явно идёт не по пути упрощения и на традиционное обслуживание будет уходить всё больше и больше сил и средств.
Самое главное, что такие стандарты должны подойти вовремя. Сейчас не их время, но уже пора говорить об этом.
По ходу написания этой статьи, которая изначально планировалась вовсе как заметка, я пришёл к выводу, что тема для меня слишком интересная и будет ещё серия статей, посвящённых этой проблеме:
- Система Контроля. Возможности, принципы работы.
- Протоколы взаимодействия и взаимообмена служебной информацией между устройствами и Интеллектуальной Системой Контроля Работы.
- Обнаружение и устранение ошибок в конфигурации.
- Автоматизация настройки оборудования.
