Comments 238
Не знаю как без комментариев жить. Да и не понимаю тех, кто советует их не использовать вообще.
Даже когда пишешь, казалось бы, понятный код, всё равно порой бывают проблемы. Поэтому, не вижу ничего плохого в том, чтобы где-то в коде пояснить в комментариях те или иные моменты.
p.s. который уже по счёту пост про «комментировать или не комментировать» )
Даже когда пишешь, казалось бы, понятный код, всё равно порой бывают проблемы. Поэтому, не вижу ничего плохого в том, чтобы где-то в коде пояснить в комментариях те или иные моменты.
p.s. который уже по счёту пост про «комментировать или не комментировать» )
Сам всегда использую комментарии, ибо через год и самому будет довольно сложно разбираться в коде. Причем часто ловил себя на мысли: «Кто это (гуано|круть) написал? Ой, да это же я!»
Мы обходимся без комментариев кода, поясню как. В нашем соглашении по оформлению кода, четкие правила именования функций и переменных — нам этого вполне достаточно.
Я сталкивался с такими сложными алгоритмами, которые даже с понятными наименованиями переменных/методов оставались непонятными. Посему приветствую комментарии, которые поясняют не «что алгоритм делает» (это понятно и из наименований), а «как алгоритм это делает» или «почему именно так».
В этом случая я бы предпочёл отдельно описание алгоритма (в шапке файла или вообще в отдельном документе), а в коде всё равно обошёлся бы без комментариев.
Почему? Потому что если уж вы дошли до хитрого алгоритма, то, уж наверное, вы хотите что-то оптимизировать. И, скорее всего, у вас кроме довольно сложно алгоритма туда накручены ещё и какие-нибудь трюки с битовыми масками, etc. Мне проще сначала понять алгоритм описанный отдельно и не включающий в себя всех этих вещей, чем пытаться продраться одновременно через сложный алгоритм и его нетривиальную реализацию.
Почему? Потому что если уж вы дошли до хитрого алгоритма, то, уж наверное, вы хотите что-то оптимизировать. И, скорее всего, у вас кроме довольно сложно алгоритма туда накручены ещё и какие-нибудь трюки с битовыми масками, etc. Мне проще сначала понять алгоритм описанный отдельно и не включающий в себя всех этих вещей, чем пытаться продраться одновременно через сложный алгоритм и его нетривиальную реализацию.
В этом случая я бы предпочёл отдельно описание алгоритма (в шапке файла или вообще в отдельном документе), а в коде всё равно обошёлся бы без комментариев.Вы практически сформулировали концепцию javadoc'а — специальных комментариев в шапке метода, рассчитанных на машинную обработку;-).
т.е. если вы используете не совсем простой алгоритм (ситуации бывают разные), то вы его не коментируете и ожидаете что сами или другой программист позже его тоже знает и понимает? Правильное именование переменных и функций — хорошо, но, как показывает практика, не всегда достаточно
А что делать в ситуациях, когда, скрепя сердце, приходится применять абсолютно неочевидные хаки для обхода проблем в сторонних библиотеках? Вариант «отправить pull request разработчику и дождаться выхода следующей стабильной версии» подходит, увы, не всегда. Вынести хак в отдельную функцию и назвать её sacrificeAVirginAtMidnightOnTheNewMoonInTheHonorOfAzathothToFixThisStrangeCornerCaseInAngularJS(), чтобы сразу всё стало понятно?
Хороший вариант комментариев — javadoc, который позволяет понять, чего ожидать от функции/класса не напрягаясь с вниканием в код.
Нужно комментировать архитектуру, а не действия строк.
Комментарии нужны, но они должны описывать намерения кода или предупреждать о неявных подводных камнях. Если можно переписать код чтобы было понятно без них, то стоит это сделать.
Особенно бесят устаревшие комментарии элементарного кода которые только усложняют его понимание. Также комментарии с историей изменений, кто что и/или когда написал его.
Ну и как говориться:
Особенно бесят устаревшие комментарии элементарного кода которые только усложняют его понимание. Также комментарии с историей изменений, кто что и/или когда написал его.
Ну и как говориться:
“Don’t comment bad code—rewrite it.”
― Brian W. Kernighan, The Elements of Programming Style
Считаю, что из всей статьи нужно оставить только один абзац, в котором вы верно отметили, что комментарий прежде всего служит объяснением что происходит в коде и, самое главное, почему.
А комментарии в стиле «увеличиваем счетчик» — такая же крайность как и полное их отсутствие. В коде должен быть по меньшей мере один комментарий, где было бы написано зачем вы вообще решили написать весь этот код. :)
А комментарии в стиле «увеличиваем счетчик» — такая же крайность как и полное их отсутствие. В коде должен быть по меньшей мере один комментарий, где было бы написано зачем вы вообще решили написать весь этот код. :)
В ассемблерном коде такое не лишнее. Потому что там всё через регистры и очень быстро можно запутаться и перестать понимать что же мы сейчас увеличиваем на единицу. Я видел ассемблерный код с комментарием в каждой (!) строчке и это не выглядело излишеством.
Добавллю, что часто путают документацию и комментарии внутри кода (возможно из-за того, что оформляется как коментарии).
Дак вот документация, особенно для API, предназначенного для стороннних пользователей твоего кода просто жизненно необходима, так как даёт возможность быстрее разобраться в том, как использовать API.
Дак вот документация, особенно для API, предназначенного для стороннних пользователей твоего кода просто жизненно необходима, так как даёт возможность быстрее разобраться в том, как использовать API.
Подписываюсь под каждым словом!
Ещё от языка зависит. На некоторых код более понятен и читаем.
Пишу на Lua, комментариев пишу очень мало — только по делу — объясняю зачем и иногда поясняю что делает тот или иной кусок кода.
Практически не пишу комментарии вообще для кода, который написал только для себя. Практика показывает, что прекрасно разбираюсь в своём коде и через год.
Когда комментариев много, они действительно вредят.
Пишу на Lua, комментариев пишу очень мало — только по делу — объясняю зачем и иногда поясняю что делает тот или иной кусок кода.
Практически не пишу комментарии вообще для кода, который написал только для себя. Практика показывает, что прекрасно разбираюсь в своём коде и через год.
Когда комментариев много, они действительно вредят.
Вот пример кода, где без комментариев никак, значит они нужны.
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
hash = (hash << 6) + (hash << 16) - hash + c;
hash = fastMultiplicationBy65599(hash) + c
ИМХО, комментарий понятней, да и делать отдельную функцию имеет смысл только, если предполагается повторное использование, иначе это только увеличит количество кода — что плохо для читабельности.
>делать отдельную функцию имеет смысл только, если предполагается повторное использование
То есть, если функция имеет размер два экрана, то ее просто так разбивать на составляющие не нужно?
>что плохо для читабельности.
Хотите сказать мой код читается хуже?
То есть, если функция имеет размер два экрана, то ее просто так разбивать на составляющие не нужно?
>что плохо для читабельности.
Хотите сказать мой код читается хуже?
> То есть, если функция имеет размер два экрана, то ее просто так разбивать на составляющие не нужно?
Я про данный конкретный код говорю.
> Хотите сказать ваш код читается лучше моего?
Я же там сказал — ИМХО. Да, по моему личному мнению, версия с комментарием читается лучше.
Я про данный конкретный код говорю.
> Хотите сказать ваш код читается лучше моего?
Я же там сказал — ИМХО. Да, по моему личному мнению, версия с комментарием читается лучше.
Давайте будем откровенными.
Вот этот код нечитабелен:
Я понятия не имею что он делает и зачем. Я не знаю что такое c. Я не понял, вы подгоняли хэш, для какой то специфичной системы, у которой хэш имеет определенный формат или размер или что-то другое.
То, что вы добавили комментарий, не сделало код более читабельным. Это просто сноска, которая позволяет вам описать, что здесь происходит. Но код как был плохой, так и остался.
Вывод. Каждую часть перенести в функцию с нормальным описанием. Непонятные переменные в топку. Всю конструкцию прятать в функцию. Пока не получится что-то типа:
Другая, медленная функция получения хэша вам вяд ли понадобится.
Вот этот код нечитабелен:
hash = (hash << 6) + (hash << 16) - hash + c
Я понятия не имею что он делает и зачем. Я не знаю что такое c. Я не понял, вы подгоняли хэш, для какой то специфичной системы, у которой хэш имеет определенный формат или размер или что-то другое.
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
hash = (hash << 6) + (hash << 16) - hash + c;
То, что вы добавили комментарий, не сделало код более читабельным. Это просто сноска, которая позволяет вам описать, что здесь происходит. Но код как был плохой, так и остался.
Вывод. Каждую часть перенести в функцию с нормальным описанием. Непонятные переменные в топку. Всю конструкцию прятать в функцию. Пока не получится что-то типа:
hash = getHash();
getHash(){return leftShift(6)+ leftShift(16) - hash + wtfC;}
Другая, медленная функция получения хэша вам вяд ли понадобится.
Я надеюсь это сарказм?
Вы же не предлагаете создавать метод leftShift?
getHash — это _не_ нормальноеописаниеназвание.
По сути указанный фрагмент кода хэширует один входной символ. То есть это будет:
Вы же не предлагаете создавать метод leftShift?
getHash — это _не_ нормальное
По сути указанный фрагмент кода хэширует один входной символ. То есть это будет:
// вот тут можно написать что это полиномиальный хеш с множителем 65599 по естественному 32-битному модулю
class Hash {
// ...
public:
Hash() : hash_(0) { }
void update(C c) {
// а вот эту часть кода мы сейчас пытаемся сделать более читаемой
hash_ = (hash_ << 6) + (hash_ << 16) - hash_ + c;
}
uint32_t get() const { return hash_; }
private:
uint32_t hash_;
};
Что я сделал бы для повышения читабельности:
1) Тип параметра. Его нужно назвать более внятно. Желательно смысл+размерность, например CharUtf8
2) Название метода 'update' — это скорее recalculate или refresh
Но главное — сам класс. Он называется так, как будто является представлением хэша, а на самом деле это вычислитель хэша (по смыслу).
1) Тип параметра. Его нужно назвать более внятно. Желательно смысл+размерность, например CharUtf8
2) Название метода 'update' — это скорее recalculate или refresh
Но главное — сам класс. Он называется так, как будто является представлением хэша, а на самом деле это вычислитель хэша (по смыслу).
Ну вообще я бы тут подстраивался не столько под читаемость самого класса, а под читаемость кода, который будет этот класс использовать. Поэтому не зная где и как он будет использоваться — идеально не написать.
Что касается типов — они самому алгоритму вычисления хеша не нужны. Вот зачем хешу знать что это символы в кодировке utf-8? Он хеширует просто последовательность байт. Поэтому тип аргумента может быть целесообразно вынести в шаблонный параметр. Ну или захардкодить, сказав что принимаем на вход uint8_t. Тут неясно, может ли кому-то захотеться хешировать последовательность uint16_t, причем не побайтово, а поэлементно.
В принципе в параметры можно вынести и размер хеша (uint32_t), и может быть сам множитель.
Что касается интерфейса (имя функции update, а также что я не стал вводить класс HashBuilder()) — его я почерпнул из питоновского hashlib. Идея в том, что если я заранее не могу предсказать, как класс будет удобнее в использовании — можно посмотреть как это сделано в стандартных библиотеках. Даже если код не идеален — он будет по крайней мере привычен другим программистам.
Насчёт recalculate — не согласился бы — recalculate подразумевает что мы вычисляем весь хеш с нуля, в то время как тут мы проводим инкрементальное обновление.
refresh — я не настолько силён в английском, чтобы ощутить отличие этого слова от update, но сошлюсь на то что в hashlib этот метод называется update.
Можно переименовать в HashBuilder. Но на самом деле это будет hashes::Polynomial (или hashes::PolynomialBuilder — хотя это мне кажется уже лишним)
Что касается типов — они самому алгоритму вычисления хеша не нужны. Вот зачем хешу знать что это символы в кодировке utf-8? Он хеширует просто последовательность байт. Поэтому тип аргумента может быть целесообразно вынести в шаблонный параметр. Ну или захардкодить, сказав что принимаем на вход uint8_t. Тут неясно, может ли кому-то захотеться хешировать последовательность uint16_t, причем не побайтово, а поэлементно.
В принципе в параметры можно вынести и размер хеша (uint32_t), и может быть сам множитель.
Что касается интерфейса (имя функции update, а также что я не стал вводить класс HashBuilder()) — его я почерпнул из питоновского hashlib. Идея в том, что если я заранее не могу предсказать, как класс будет удобнее в использовании — можно посмотреть как это сделано в стандартных библиотеках. Даже если код не идеален — он будет по крайней мере привычен другим программистам.
Насчёт recalculate — не согласился бы — recalculate подразумевает что мы вычисляем весь хеш с нуля, в то время как тут мы проводим инкрементальное обновление.
refresh — я не настолько силён в английском, чтобы ощутить отличие этого слова от update, но сошлюсь на то что в hashlib этот метод называется update.
Можно переименовать в HashBuilder. Но на самом деле это будет hashes::Polynomial (или hashes::PolynomialBuilder — хотя это мне кажется уже лишним)
std::string s1 = "hello", s2="world";
std::cerr << Hash(s1.begin(), s1.end()).hexdigest() << std::endl;
std::cerr << Hash('x').hexdigest() << std::endl;
Hash h;
h.update(s1.begin(), s1.end());
h.update(s2.begin(), s2.end());
std::cerr << h.hexdigest() << std::endl;
Ну вообще я бы тут подстраивался не столько под читаемость самого класса, а под читаемость кода, который будет этот класс использовать.
В том-то и дело, что 1) это взаимосвязано 2) читаемость интерфейса у вас не слишком высока.
Поэтому не зная где и как он будет использоваться — идеально не написать.
Идеально не написать в принципе. Но можно написать так, чтобы потребитель знал, что ожидать исходя из названия.
Для меня лучшим примером читабельного API является QT — когда начинал писать на версии 3 практически не приходилось заглядывать в документацию чтобы понять что означают методы и их параметры.
Вот зачем хешу знать что это символы в кодировке utf-8? Он хеширует просто последовательность байт.
В таком случае зачем передавать в него какой-то C? Передавайте последовательность байт.
Что касается интерфейса (имя функции update, а также что я не стал вводить класс HashBuilder()) — его я почерпнул из питоновского hashlib.
Лучшее — враг хорошего. Что хорошо в питоновской hashlib — это то, что она есть и работает. Плохо написаный, но работающий код — лучше хорошо написаного и не работающего.
Опять же в python hashlib — все-таки читаемее чем то, что вы представили:
1) Название класса MD5 — гораздо читаемее чем Hash, потому что пользователю становится ясно чего ожидать от него. Hash — это хорошее имя для интерфейса, а не для имплементации.
2) Опять же в hashlib update — обновляет содержимое внутреннего члена — строки и такое имя метода оправдано, а вычисления происходят в digest или hexdigest — что опять же более ожидаемо. У вас же updade занимается вычислениями — имя метода вводит в заблуждение.
В таком случае зачем передавать в него какой-то C? Передавайте последовательность байт.
Ну случай если я захочу хешировать не последовательность байт, а последовательность двухбайтных чисел. В данном примере я не знал что именно автор хочет хешировать — байты, двухбайтные слова, четырехбайтные слова — поэтому не захотел привязываться к какому-то конкретному типо входных элементов.
2) Опять же в hashlib update — обновляет содержимое внутреннего члена — строки и такое имя метода оправдано, а вычисления происходят в digest или hexdigest — что опять же более ожидаемо. У вас же updade занимается вычислениями — имя метода вводит в заблуждение.
Ни в коем случае внутри hashlib.md5 строка не хранится — это свело бы на нет всю производительность (с тем же успехом можно было бы сделать md5 просто функцией, и принимать на вход уже сконкатенированную строку). Хеш вычисляется по мере поступления входных данных. Даже если бы у нас был 10-гигабайтный входной файл, можно было бы не имея такого количества оперативной памяти вычислить его хеш, читая его по кусочкам и вызывая update() много раз.
digest/hexdigest же просто возвращает внутреннее (уже посчитанное) состояние.
И как же имя метода вводит в заблуждение? Hash::update(data) — "_обновить_ значение хэша на основе новой порции данных".
1) Название класса MD5 — гораздо читаемее чем Hash, потому что пользователю становится ясно чего ожидать от него. Hash — это хорошее имя для интерфейса, а не для имплементации.
Ну тут не поспоришь. Как я писал выше, если это библиотека — то лучше назвать класс Polynomial и положить в неймспейс hashes. Но если это единственный алгоритм хеширования в своей области видимости, и другие не нужны — то можно назвать его просто Hash.
Аргумент в пользу такого именования приводил другой участник ниже
Но если в вашей системе, которая решает другую задачу, есть несколько методов получения хэша, то это плохо. Это гораздо хуже чем один метод, который просто возвращает хэш. Вам не нужно знать реализацию, вам нужен просто хэш. Имя метода GetHash идеально для этого.
Ну случай если я захочу хешировать не последовательность байт, а последовательность двухбайтных чисел.
И ваш код будет так же хорошо работать с двухбайтными числами? Может быть в таком случае этот самый поток чисел лучше всего будет назвать как-то более вменяемо чем 'C'?
Даже если бы у нас был 10-гигабайтный входной файл, можно было бы не имея такого количества оперативной памяти вычислить его хеш, читая его по кусочкам и вызывая update() много раз.
Верно. Но тогда update совсем не подходит. Имя в идеале не должно предполагать несколько толкований.
Примеры из других использований этого глагола наводят на мысль что тут старое должно быть обновлено новым. Вообще с учетом того, что у нас есть неявное состояние класса Hash — нам нужно знать его реализацию, чтобы понять как будет работать наш код с ним. Например мы получили параметром Hash, вызвали в нем update(«данные на которых мы хотим получить hash»), а в какой-то реализации нам прислали не новый объект, а какой-то уже попользованый и мы надолго засели в дебаггере, пока не отматерим создателя класса выяснив что он к тому же не сделал для нас reset() — зачем тогда вообще отдельный объект?
Но если это единственный алгоритм хеширования в своей области видимости, и другие не нужны — то можно назвать его просто Hash.
1) Вы никогда не знаете что с вашим кодом будет потом.
2) Работающий код всегда лучше чем неработающий, потому даже если вы назовете его class A и он будет работать — это уже хорошо.
3) Если вы все-таки хотите чтобы код был читаемым — лучше не делать в стиле «и так сойдет» для внутреннего потребления. Вам или кому-то другому придется разбираться в реализации класса через некоторое время, чтобы понять что за функцию хэширования вы там используете. Хорошо тут всего 2 строки, а если что-то сложнее типа SHA1?
Имя метода GetHash идеально для этого.
Если это просто метод, без параметра для указания алгоритма, то не удивляйтесь если вы увидите у себя в коде большого проекта его реализацию несколько раз.
И еще не удивляйтесь если у вас будут на одних и тех же данных пересчитывать одни и те же хэши по нескольку раз, просто потому, что никто не хочет разбираться одинаковые ли хэши возвращают 5 разных реализаций метода GetHash, потому будут считать для методов из библиотеки A методом A.GetHash, из библиотеки B — будет B.GetHash и т.д. — при этом это будут одинаковые значения.
И ваш код будет так же хорошо работать с двухбайтными числами?
Ага, будет.
Может быть в таком случае этот самый поток чисел лучше всего будет назвать как-то более вменяемо чем 'C'?
Какие-то предложения, как можно назвать число из входного потока? C — задумывалось как интутитивное сокращение для char, но не стал писать char, потому что захотел обобщить и на числа. Можно конечно назвать Element — но не думаю что намного понятнее станет.
Примеры из других использований этого глагола наводят на мысль что тут старое должно быть обновлено новым.
Это какие же примеры? Для замены обычно использую глаголы типа set/reset. Да и кому придёт в голову перезаписывать значение новым, если можно создать новый объект?
Вообще с учетом того, что у нас есть неявное состояние класса Hash — нам нужно знать его реализацию, чтобы понять как будет работать наш код с ним. Например мы получили параметром Hash, вызвали в нем update(«данные на которых мы хотим получить hash»), а в какой-то реализации нам прислали не новый объект, а какой-то уже попользованый и мы надолго засели в дебаггере, пока не отматерим создателя класса выяснив что он к тому же не сделал для нас reset() — зачем тогда вообще отдельный объект?
Справедливо. Таки можно неправильно понять что делает метод update. Предложите вариант лучше? add? append? Хотя для меня остается загадкой, зачем принимать параметром Hash, а затем делать ему update, предполагая что это полностью уничтожит его предыдущее состояние. Почему тогда не создать новый экземпляр в месте использования.
Ну и вообще у меня бы (неужели только у меня?) даже и мысли бы не возникло предположить что update перезаписывает состояние. Зачем вообще перезаписывать состояние? Если бы update вел себя так как вы ожидаете, то он должен был бы быть не методом, а конструктором. Или вообще свободной функцией calculateHash(), которая возвращает uint32_t. И никакой класс бы не понадобился.
1) Вы никогда не знаете что с вашим кодом будет потом.
2) Работающий код всегда лучше чем неработающий, потому даже если вы назовете его class A и он будет работать — это уже хорошо.
3) Если вы все-таки хотите чтобы код был читаемым — лучше не делать в стиле «и так сойдет» для внутреннего потребления. Вам или кому-то другому придется разбираться в реализации класса через некоторое время, чтобы понять что за функцию хэширования вы там используете. Хорошо тут всего 2 строки, а если что-то сложнее типа SHA1?
Для этого я написал в заголовке класса комментарий (один из немногих случаев, когда комментарий уместен), который описывает что за функция хеширования используется.
И да, имеет смысл этот хеш сразу назвать PolynomialHash.
Но этот класс — это _не_ продакшн код, и даже не пример для подражания. Я его написал за 5 минут, всего лишь ради того, чтобы продемонстрировать предыдущему комментатору возможный контекст той самой строки, с которой всё началось. Не ожидал что его тут так рьяно начнут ревьювить.
Хотя в целом я понял основную причину непонимания. Из-за шаблонизации вы оба подумали что C — это не один символ, а вся последовательность. Отсюда и неверное предположение что update вычисляет весь хеш с нуля, а не делает одну итерацию.
Это действие называется update и никак иначе.
Я надеюсь это сарказм?
Вы же не предлагаете создавать метод leftShift?
Вы же понимаете, что в зависимости от задачи может быть и соберусь. И зря вы так категоричны. :) К сожалению не знаю, во всех ли языках оператор << идентичен, но, если нет, я бы предпочел метод leftShift. Ну или не дай бог, я захочу логировать процесс получения хэша. Ну и т.д.
Опять таки, в зависимости от задачи, имя метода getHash может быть идеальным. Да, если вы делаете библиотеку, которая позволяет вычислять различные хэши, то название ужасное, не позволяет отделить одно от другой.
Но если в вашей системе, которая решает другую задачу, есть несколько методов получения хэша, то это плохо. Это гораздо хуже чем один метод, который просто возвращает хэш. Вам не нужно знать реализацию, вам нужен просто хэш. Имя метода GetHash идеально для этого.
Опять таки, тот коммент, который вы написали перед именем класса, это средства документирования. Я очень сильно за эти средства. Без них, я считаю что класс, метод не закончен.
Опять таки, что такое C, я категорически не понимаю. :)
Но если в вашей системе, которая решает другую задачу, есть несколько методов получения хэша, то это плохо. Это гораздо хуже чем один метод, который просто возвращает хэш. Вам не нужно знать реализацию, вам нужен просто хэш. Имя метода GetHash идеально для этого.
Я этим кодом хотел показать что строка, которую мы пытаемся упрощать — является _частью_ вычисления хеша. А именно обновлением хеша при поступлении на вход новых данных (тут нужно отметить что данный хеш умеет вычисляться поточно, не держа в памяти всю строку). Раз этот код — это часть алгоритма хеширования, то его выносить в функцию getHash() явно неуместно, т.к. по сути весь класс это и есть реализация функции getHash.
А как будет выглядеть код, который _использует_ это хеширование — я написал чуть выше. Для тех, кому не нужна возможность инкрементального обновления хеша — можно сделать и функцию, чтобы вместо
Hash(s1.begin(), s1.end()).get()
писать
getHash(s1.begin(), s1.end())
Хотя мне кажется такая функция будет уже излишеством.
За «C» простите, тут я просто не хотел привязываться к конкретному типу, поэтому написал толи псевдокод, толи неявно подразумевал это как шаблонный параметр. На самом деле C = char.
И резюмируя, ваш класс Hash ужасен. Что он делает я не понял. Обновляет какой то объект C? Хэш то вычисляется или нет? Если нет, почему класс называется хэш?
Выше ответил на критику.
Мало того что leftShift менее понятен чем '<<' так еще и работать будет медленней. Но даже это не главное. Он не принимает параметром hash, а значит либо добавил зависимостей либо вообще не работает.
Слушайте, но ведь пример абсолютно оторван от контекста. Утверждать что зависимостей прибавится или метод не будет работать не верно. Т.к. контекст не определен. Не Вы, не я не знаем что это за код и где он выполняется.
Я уже вообще пожалел, что написал что-то, т.к. написав все что угодно, можно интерпретировать как что-то, что является ошибкой, т.к. никакой конкретики в примере выше нет.
Ну и по поводу медленнее. Очень редко требуется оптимизировать, путем отказа от вызова метода. Даже чаще это явно лишнее. Отличный пример, это недавняя статья про Notepad++.
Я уже вообще пожалел, что написал что-то, т.к. написав все что угодно, можно интерпретировать как что-то, что является ошибкой, т.к. никакой конкретики в примере выше нет.
Ну и по поводу медленнее. Очень редко требуется оптимизировать, путем отказа от вызова метода. Даже чаще это явно лишнее. Отличный пример, это недавняя статья про Notepad++.
Мне проще понять
(65599 * hash), чем внимательно вчитаться и перевести с английского fastMultiplicationBy65599. В итоге, даже после того, как я переведу, я не буду точно уверен, что там имеется в виду, и, может, захочу еще посмотреть реализацию.Ещё неизвестно сколько придётся листать до объявления этой функции.
Используйте адекватные инструменты для разработки, и ничего не придется листать.
в теле fastMultiplicationBy65599, так и придется добавить коментарий:
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
fasterVersionOfHashMultipliedBy65599PlusC
но при этом большая возможность что в этот страшный fastMultiplicationBy65599 даже никто заходить не будет. функции кроме переиспользования кода нужны ещё чтоб уровень абстракции сохранять — а то идешь по бизнескейсу, а натыкаешся на хаки производительности.
В Java делают javadoc — специальный комментарий, из каких потом автоматически собирается документация к API. Вот там как раз описаниям алгоритмов самое место.
Если код не разобрать без навороченного IDE, то это не есть хорошо
А не нужно листать. Имя функции и её спецификация должны достаточно говорить о ней, чтобы уже можно было её использовать. А как функция реализована внутри не должно волновать при её использовании, это должно волновать только при её разработке или переработке. Иначе весь смысл концепции абстракции теряется.
и все таки, кто то же будет перерабатывать ее когда-нибудь.
Осознание этого факта должно заставлять программиста проверять исходный код функции, при её использовании?
Если есть переживания, за то правильно ли функционирует функция, то более верно будет использовать автоматическое тестирования функции перед запуском программы. Это позволит переложить беспокойство за корректность работы функции на автоматизированный механизм проверки и абстрагироваться от её реализации. А если тесты будет показывать что она работает неверно(например, слишком медленно), то тогда стоит заняться переработкой её реализации.
Если есть переживания, за то правильно ли функционирует функция, то более верно будет использовать автоматическое тестирования функции перед запуском программы. Это позволит переложить беспокойство за корректность работы функции на автоматизированный механизм проверки и абстрагироваться от её реализации. А если тесты будет показывать что она работает неверно(например, слишком медленно), то тогда стоит заняться переработкой её реализации.
1)когда/если её будут перерабатывать будет проще если функционал будет вынесен в отдельную функцию
2)до тех пор пока её будут перерабатывать код придется читать ещё десятку людей которые никак конкретно хитросплетениями хэшей не интересуются
2)до тех пор пока её будут перерабатывать код придется читать ещё десятку людей которые никак конкретно хитросплетениями хэшей не интересуются
Возможно у вас просто проблемы с английским.
hash = быстроеУмножениеНа65599(hash) + c
так лучше?
hash = быстроеУмножениеНа65599(hash) + c
так лучше?
> Возможно у вас просто проблемы с английским.
Средний английский (Intermediate или Upper Intermediate)
> так лучше?
ИМХО лучше, но все проблемы остались, мне все-равно проще понять
Средний английский (Intermediate или Upper Intermediate)
> так лучше?
ИМХО лучше, но все проблемы остались, мне все-равно проще понять
(65599 * hash)Не важно, оно и на русском читается хуже, чем (65599 * hash)
Понятно что хуже, но весь остальной код у вас выглядит точно также.
Или вы предлагаете у всего делать коментарии которые улучшают четабельность?
x = y.toLowerCase() // «ABC» -> «abc»
Или вы предлагаете у всего делать коментарии которые улучшают четабельность?
x = y.toLowerCase() // «ABC» -> «abc»
Был дан конкретный пример кода с поясняющим комментарием. Этот комментарий там абсолютно уместен, как мне кажется.
Есть два кода
x = y.toLowerCase()
hash = fastMultiplicationBy65599(hash) + c
Вы говорите, но для второго же будет понятнее 65599 * hash чем вызов функции. Я с этим согласен, но зачем в данном случае делать исключение? У вас большая часть кода состоит из вызова функции, которые нельзя проста так взять и из fastMultiplicationBy65599 превратить в 65599 * hash, поэтому думаю что единообразие лучше, и fastMultiplicationBy65599 не настолько хуже кода с комментарием что бы его здесь не использовать.
x = y.toLowerCase()
hash = fastMultiplicationBy65599(hash) + c
Вы говорите, но для второго же будет понятнее 65599 * hash чем вызов функции. Я с этим согласен, но зачем в данном случае делать исключение? У вас большая часть кода состоит из вызова функции, которые нельзя проста так взять и из fastMultiplicationBy65599 превратить в 65599 * hash, поэтому думаю что единообразие лучше, и fastMultiplicationBy65599 не настолько хуже кода с комментарием что бы его здесь не использовать.
ВамУдобнейРаспарситьВГоловеНазваниеФункцииЧтоБыПонятьЧтоОнаДелает();?
//Или таки удобнее прочитать комментарий?
//Или таки удобнее прочитать комментарий?
Я не спорю что 65599 * hash прочитать проще, чем fastMultiplicationBy65599(hash), но раз уже возникла необходимости в оптимизации, то в коде 65599 * hash уже не будет (хотя ниже пишут что компилятор сам умножение соптимизирует), придется писать комментарий. В итоге читать придется больше.
А мне проще прочитать
а ещё лучше
чем
При этом если я и полезу в реализацию fastMultiplication<>, то только ради интереса, как же оно там релизовано — и только первый раз. Чисто практически же названия функции будет достаточно чтобы понять что она делает и продолжить чтение.
А мне проще прочитать
hash = fastMultiplicationBy65599(hash) + c
а ещё лучше
hash = fastMultiplication<65599>(hash) + c
чем
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
hash = (hash << 6) + (hash << 16) - hash + c;
При этом если я и полезу в реализацию fastMultiplication<>, то только ради интереса, как же оно там релизовано — и только первый раз. Чисто практически же названия функции будет достаточно чтобы понять что она делает и продолжить чтение.
Я бы сказал что он работает медленнее чем то, что написано в комментарии. Это тот случай когда расходы на вызов функции не оправдаются.
На функцию можно и несколько тестов написать: чем не повторное использование?
Справедливости ради, хочу сказать, что ваш вариант намного лучше, чем если бы исходный код был бы оставлен вообще без комментариев.
На самом деле, имя функции должно пояснять, на кой, собственно, черт мы умножаем hash на 65599.
Кстати, надо уточнить на каком процессоре и каком компиляторе.
Но здесь комментарий уместен — что бы понять, на что код переписать при переходе на более современный компилятор или процессор.
Но здесь комментарий уместен — что бы понять, на что код переписать при переходе на более современный компилятор или процессор.
В случае с оптимизациями (конечно, более сложными, чем приведенная, хотя и тут применимо), есть интересная практика (кажется, в ffmpeg видел, но могу путать) просто оставлять рядом неоптимизированный код.
То есть, сначала пишем «в лоб», когда тесты проходят — оптимизируем. В случае проблем с оптимизированным вариантом всегда можно вернуть «тупой». Заодно и пояснение рядом.
#if 1 /* optimization */
hash = (hash << 6) + (hash << 16) - hash + c;
#else
hash = (65599 * hash) + c;
#endif
То есть, сначала пишем «в лоб», когда тесты проходят — оптимизируем. В случае проблем с оптимизированным вариантом всегда можно вернуть «тупой». Заодно и пояснение рядом.
Код с многочисленными препроцессорными вставками читается абсолютно ужасно, это я по опыту реальных проектов говорю. Особенно когда в погоне за оптимизацией начинают вставлять что-нибудь громоздкое и совсем нечитабельное типа ассемблерных вставок с SSE-кодом.
Заметно лучше иметь просто две версии класса с одним интерфейсом — одну «оптимизированную», другую нет, причем разнесенные по разным файлам.
Заметно лучше иметь просто две версии класса с одним интерфейсом — одну «оптимизированную», другую нет, причем разнесенные по разным файлам.
Кстати: никогда не делайте эту «оптимизацию», не раскладывайте умножение на сдвиги и сложения. На всех процессорах, выпущенных за последние 10 лет, это только замедляет код.
Вообще-то нигде не упоминалось, что это код под современный процессор. Вполне может быть микроконтроллер, в том числе без аппаратного умножения. Там компилятор может такого наворотить…
В оправдание можно сказать, что все современные компиляторы для беззнаковых целых умеют оптимизировать умножение сложением и сдвигами, если от этого есть выигрыш на конкретной платформе. Отсюда мораль — нужно по возможности использовать unsigned.
Умеют (сам проверял). Но в некоторых сложных выражениях могут облажаться.
Конечно такие выражения в коде — ещё бОльшее зло, чем любые комментарии…
Конечно такие выражения в коде — ещё бОльшее зло, чем любые комментарии…
оффтоп
Кстати, у меня был один такой оборот в коде, во время отладки на avr-gcc, который я родил глубокой ночью, переписал и забыл, а вот ассемблерный листинг оставил, так как он сильно меня удивил:
Собственно, в коде была тупейшая строка с битовыми масками и сдвигами переменных, никаких циклов и чего-то, похожего на задержку.
448: 80 91 71 00 lds r24, 0x0071
44c: 90 91 72 00 lds r25, 0x0072
450: 80 91 71 00 lds r24, 0x0071
454: 90 91 72 00 lds r25, 0x0072
458: 80 91 71 00 lds r24, 0x0071
45c: 90 91 72 00 lds r25, 0x0072
460: 80 91 71 00 lds r24, 0x0071
464: 90 91 72 00 lds r25, 0x0072Собственно, в коде была тупейшая строка с битовыми масками и сдвигами переменных, никаких циклов и чего-то, похожего на задержку.
Гхм… на каких платформах? Это будет неплохо работать на всех платформах, а умножение хорошо только на x86/64. На большинстве ARM скорее всего сдвиги-сложения быстрее будут. Да, и на x86 по причине суперскалярности тоже не факт — если уммножение выполняется за четыре такта или медленнее, то у сдвигов будет преимущество (и ещё вопрос все ли арифметические блоки в процессоре поддерживают умножение, что тоже может негативно отразиться).
А что это за магическое число такое?
Если это C или C++, рекомендую взглянуть на дизассемблированный листинг при включенной оптимизации: gcc оба варианта (со сдвигами и без) приводит к одному и тому же imul под core i3:
А вот если попросить под i386, то gcc сам выдаст серию сдвигов:
Сейчас подобные оптимизации вручную уже лучше не писать: оптимизация под современные процессоры имеет кучу нюансов, а большинство разработчиков почему-то до сих пор живут в каменном веке, когда не все компиляторы деление на два сдвигом заменять умели.
hash = (hash << 6) + (hash << 16) - hash + c;
//8048373: 69 d2 3f 00 01 00 imul $0x1003f,%edx,%edx
//..
//804837c: 01 d0 add %edx,%eax
А вот если попросить под i386, то gcc сам выдаст серию сдвигов:
hash = 65599U * hash + c;
// 8048368: 89 d3 mov %edx,%ebx
// 804836a: c1 e3 06 shl $0x6,%ebx
// 804836d: 89 d1 mov %edx,%ecx
// 804836f: c1 e1 10 shl $0x10,%ecx
// 8048372: 01 d9 add %ebx,%ecx
// 8048374: 29 d1 sub %edx,%ecx
// 8048376: 01 c8 add %ecx,%eax
Сейчас подобные оптимизации вручную уже лучше не писать: оптимизация под современные процессоры имеет кучу нюансов, а большинство разработчиков почему-то до сих пор живут в каменном веке, когда не все компиляторы деление на два сдвигом заменять умели.
Бытует мнение, что писать код не для человека, а для машины (в т.ч. и так, чтоб быстрее выполнялся, но при этом хуже читался) — само по себе есть ошибочный подход. Но по-моему оно слишком радикальное. В данном случае даже на мой взгляд с моей общей нелюбовью к комментариям тут этот комментарий уместен. Но лучше вынести в отдельный метод и написать специальный комментарий к нему (типа javadoc в java).
Конечно, же здесь нужен либо комментарий, либо отдельная функция. Но в большей части кода, например, веб- и бизнес-приложений без комментариев вполне можно обойтись. Я не верю, что большинству программистов каждый день приходится реализовывать какие-то нетривиальные алгоритмы.
P.S. Приведенная вами оптимизация имеет смысл далеко не на всех платформах. В частности, на x86 целочисленное умножение давно уже вычисляется за 3 такта, а в последних процессорах оптимизировано и деление.
P.S. Приведенная вами оптимизация имеет смысл далеко не на всех платформах. В частности, на x86 целочисленное умножение давно уже вычисляется за 3 такта, а в последних процессорах оптимизировано и деление.
Мы в команде придерживаемся мнения, что код должен читаться как книга. Главное не лениться называть понятно переменные, по минимуму использовать сокращения в названиях ну и инкапсуляцие «низкоуровневых» кусков кода. Конечно, комментарии периодически встречаются, но обычно это первый признак того, что с кодом что-то не так.
Допустим существует несколько вариантов решения задачи (А, Б, В, для простоты), допустим, я попробовал несколько, отладил, отпрофилировал и понял, что в данном случае лучше работает (быстре/меньше памяти жрет/etc) вариант Б, в то время как наиболее часто используемым является, например, вариант А. Если я не напишу об этом в комментарии, код может быть изменен другим разработчиком при рефакторинге, который не в курсе, почему я выбрал Б. Ну и тому кто будет делать ревью сразу все понятно будет.
Все, что вы пишите, правильно. Но подходит далеко не ко всем случаям. Например, если речь идет о гуе. Функциональные тесты могут быть пройдены и в данном кокретном месте использование того или иного варианта может быть не сильно критичным и городить бенчмарк тест излишне. Но когда речь идет о приложении целиком, выигрыш в 30мс тут, в 10мс там и т.д. сделают приложение в целом более отзывчивым.
Что-то знакомое для меня. Нас раньше учили, что любой человек открывший ваш код должен понять, что приблизительно он делает, даже если открывший в программировании 0. До сих пор стараюсь писать именно так.
У нас весь код проходит ревью, потому непонятный код в репозиторий не попадает. Комментариев очень мало.
Тут может быть такой подвох, мерило непонятности — люди, которые давно с этим кодом работают.
Для нового человека может быть нечто непонятно, и придётся ему задавать вопросы, отвлекать других. А если бы были комментарии…
Я не утверждаю, что у вас там всё именно так непонятно для новичка, просто описываю, как бывает.
Для нового человека может быть нечто непонятно, и придётся ему задавать вопросы, отвлекать других. А если бы были комментарии…
Я не утверждаю, что у вас там всё именно так непонятно для новичка, просто описываю, как бывает.
Золотые слова! Я вот буквально месяц на новом проекте и то что у меня вызывает столбняк тем кто давно на проекте предельно ясно. Часто один комментарий спас бы меня от нескольких часов исследований, а докблоки к свойствам и методам вообще бы сделали меня счастливым человеком))
Согласен, но выгоднее потратить немного времени, чтобы нового человека ввести в курс дела, чем постоянно тратить время на поддержание кода в виде, понятном для человека с улицы. Чтобы достичь последнего, комментариев недостаточно. Нужна подробная документация для домена, архитектуры, инфраструктуры. Не для каждого проекта это имеет смысл, я думаю.
Но ведь времени тратиться столько же. Может даже меньше. Проще ведь один раз описать метод, пусть даже для вас он и капитанский, чем объяснять для каждого новичка его тонкости
Можно сказать иначе. Каждый разработчик должен описывать каждый метод, чтобы новичок, который приходит раз в году, мог самостоятельно разобраться. (в реальности все равно не разберется без помощи соседа)
Почему один раз? Есть уверенность, что метод не будет рефакториться, перекраиваться и переписываться?
Так комментарии, которые поясняют переменную / строку кода в принципе никогда не были нужны. Комментариями либо поясняли, почему выбрали именно такое решение, либо описывали, что происходит в блоке кода (чтобы без его разбора, особенно, если он запутанный, можно было понять — чего автор хотел добиться, заодно проверить совпадение мысли и реализации...)
Лично я для себя придумал прием, чтобы писать более содержательные комментарии. Как правило, не пишу комментарии сразу при написании кода. Зато через некоторое время, когда просматриваю написанный код, если возникают малейшие запинки по поводу понимания что и зачем тут делается, пишу ответ в комментарии. Так больше шансов, что комментарий будет полезным, а не капитанским.
И кстати к некоторым книгам тоже пишут комментарии, даже если они написаны на естественном языке.
И кстати к некоторым книгам тоже пишут комментарии, даже если они написаны на естественном языке.
+100500, обычно дописываю комментарии после написания пары тройки методов, хотя я как раз сторонник максимально подробной документации. Если над проектом работает больше трех человек — то таковое необходимо. В данный момент приходится разбираться в ТАКОЙ каше Legacy-PHP кода, что скоро наверное мозг взорвется, а комментариев там минимум.
Комментировать строчки вида
не стоит конечно, лучше где-то выше сделать комментарий типа
тогда хоть будет понятно что в переменной хранится и для чего вообще она инкрементируется
Комментировать строчки вида
$i++;
не стоит конечно, лучше где-то выше сделать комментарий типа
$i=0; // взводим переменную для счетчика того-то
while (foobar) {
...
$i++;
...
}
тогда хоть будет понятно что в переменной хранится и для чего вообще она инкрементируется
В данном случае гораздо лучше именно переменную назвать адекватно :)
$itemCount, $beerBottles и т.д.
$itemCount, $beerBottles и т.д.
Это же классика. В 99% случаев $i — это переменная для счетчика
Если к имени счётчика требуется пояснение, то это плохое имя счётчика :) Ну я лично использую $i, $j, только если это индексы (массивов) и они инкрементируются строго на каждой итерации цикла.
Если счётчики вложенные, то перепутать
i с j, а потом выяснять, почему в некоторых случаях программа работает неправильно, — долгое и увлекательное занятие, правда, в общем, практически бесполезное…Это понятно, я же для примера из статьи написал :-)
Даже в случае называния $itemCount или $beerBottles лучше комментарий написать (в нашем случае по-русски), чем пытаться осмыслить латиницу. Опять же, в случае $i, писать буковок меньше :-)
Даже в случае называния $itemCount или $beerBottles лучше комментарий написать (в нашем случае по-русски), чем пытаться осмыслить латиницу. Опять же, в случае $i, писать буковок меньше :-)
> Опять же, в случае $i, писать буковок меньше
Так давайте все переменные и методы одной буковкой называть, чего уж там, будет супер компактный код. Правда, придется в комментариях пояснять для чего каждая буковка нужна, при чем желательно на двух языках, для англоязычных коллег.
Так давайте все переменные и методы одной буковкой называть, чего уж там, будет супер компактный код. Правда, придется в комментариях пояснять для чего каждая буковка нужна, при чем желательно на двух языках, для англоязычных коллег.
На трёх языках — ещё и для индийских суппортеров;-)
Коммент про Дональда Кнута, literate programming и системы WEB и CWEB
Комментарии в коде — это, как топор. Кто-то топором дом строит, а кто-то себе палец отрубает. Логика простая должна быть, если в этом месте комментарий будет полез и принесет пользу — пишем, если нет — не пишем.
Могу сказать на это вот что: когда на твоих плечах лежит разбор нескольких тысяч строк legacy-кода, упакованного в один файл — к комментариям относишься, как к мане небесной.
Или как к манне небесной.
А javadoc относится к таким комментариям? Потому что подобная штука однозначно нужна.
Кто не читал «Совершенный код», почитайте обязательно — не пожалеете. Там очень подробно разобран в том числе и вопрос комментирования программ.
32.3. Комментировать или не комментировать?
Комментарии легче написать плохо, а не хорошо, и комментирование иногда бывает скорее вредным,
чем полезным. Жаркие дискуссии по поводу достоинств комментирования часто напоминают
философские дебаты о моральных достоинствах, и это наводит меня на мысль о том, что, будь Сократ
программистом, между ним и его учениками могла бы произойти следующая беседа.
Комменто
Действующие лица:
ФРАСИМАХ Неопытный пурист теории, который верит всему, что читает.
КАЛЛИКЛ Закаленный в боях представитель старой школы — «настоящий» программист.
ГЛАВКОН Молодой, самоуверенный, энергичный программист.
ИСМЕНА Опытная разработчица, уставшая от громких обещаний и просто желающая найти
несколько работающих методик.
СОКРАТ Мудрый опытный программист.
Мизансцена:
Завершение ежедневного собрания группы
— Желает ли кто-то обсудить еще что-нибудь, прежде чем мы вернемся к работе? — спрашивает Сократ.
— Я хочу предложить стандарт комментирования для наших проектов, — говорит Фрасимах. —
Некоторые наши программисты почти не комментируют свой
код, а всем известно, что код без комментариев нечитаем.
— Ты, должно быть, еще менее опытен, чем я думал, — отвечает Калликл. — Комментарии — это
академическая панацея, и любому, кто писал реальные программы, известно, что комментарии
затрудняют чтение кода, а не облегчают. Естественный язык менее точен, чем Java или Visual
Basic, и страдает от избыточности, тогда как операторы языков программирования лаконичны и
попадают в самое яблочко. Если кто-то не может написать ясный код, разве ему удастся
написать ясные комментарии? Кроме того, комментарии устаревают при изменениях кода. Доверяя
устаревшим комментариям, ты сам себе роешь яму.
— Полностью согласен, — вступает в разговор Главкон. — Щедро прокомментированный код читать
труднее, потому что в этом случае читать приходится больше. Мало того, что я должен читать код,
так мне нужно читать еще и кучу комментариев!
— Подождите минутку, — вставляет свои две драхмы Исмена, ставя чашку кофе.
— Конечно, злоупотребление комментариями возможно, но хорошие комментарии ценятся на вес золота.
Мне приходилось сопровождать код как с комментариями, так и без них, и, будь у меня выбор, я бы
предпочла первый вариант. Не думаю, что нам нужен стандарт, заставляющий писать один
комментарий на каждые x строк кода, но побудить всех программистов комментировать код не
помешает.
— Если комментарии — пустая трата времени, почему все их используют, Калликл? — спрашивает Сократ.
— Или потому, что таково требование, или потому, что человек прочитал где-то о пользе
комментариев. Ни один программист, когда-либо задумавшийся об этом, не пришел к выводу, что
комментарии полезны.
— Исмена считает, что они полезны. Она уже три года сопровождает твой код без комментариев и чужой
код с комментариями. Ее мнение ты уже слышал. Что ты скажешь на это?
— Комментарии бесполезны, потому что они просто повторяют код в более многословной…
— Подожди, — прерывает Калликла Фрасимах. — Хорошие комментарии не повторяют код и не объясняют
его. Они поясняют его цель. Комментарии должны объяснять намерения программиста на более
высоком уровне абстракции, чем код.
— Верно, — соглашается Исмена. — Если я ищу фрагмент, который мне нужно изменить или исправить,
я просматриваю комментарии. Комментарии, повторяющие код, на самом деле бесполезны, потому что
все уже сказано в самом коде. Когда я читаю комментарии, я хочу, чтобы они напоминали оглавление
книги. Комментарии должны помочь мне найти нужный раздел, а после этого я начну читать
код. Гораздо быстрее прочитать одно предложение на обычном языке, чем анализировать 20 строк
кода на языке программирования.
Исмена наливает себе вторую чашку кофе.
— Мне кажется, что люди, отказывающиеся писать комментарии, (1) думают, что их код понятнее,
чем мог бы быть, (2) считают, что другие программисты гораздо сильнее интересуются их кодом,
чем есть на самом деле, (3) думают, что другие программисты умнее, чем есть на самом деле, (4)
ленятся или (5) боятся, что кто-то другой узнает, как работает их код.
— В этом смысле очень помогли бы обзоры кода, Сократ, — продолжает Исмена.
— Если кто-то утверждает, что комментарии писать не нужно, и получает во время обзора кучу
вопросов — если сразу несколько коллег спрашивают его: „Что происходит в этом фрагменте твоего
кода?“ — он начинает писать комментарии. Если программист не дойдет до этого сам, его руководитель
сможет заставить его писать комментарии.
— Я не утверждаю, Калликл, что ты ленишься или боишься, что кто-то другой поймет твой код. Я
работала с твоим кодом и могу сказать, что ты — один из лучших программистов компании. Но будь
чуточку добрее, а? Мне было бы легче сопровождать твой код, если бы ты писал комментарии.
— Но это пустая трата времени, — не сдается Калликл. — Код хорошего программиста должен быть
самодокументирующимся: все, что нужно знать другим программистам, должно быть в самом коде.
— Нет! — Фрасимах вскакивает со стула. — В коде и так уже есть все, что нужно знать компилятору!
С таким же успехом можно было бы сказать, что все, что нужно знать другим программистам, уже
есть в двоичном исполняемом файле! Если бы мы только были достаточно умны, чтобы уметь читать
его! Информации о том, что программист собирался сделать, в коде нет.
Фрасимах замечает, что вскочил с места, и садится.
— Сократ, это немыслимо. Почему мы спорим о важности комментариев? Во всех книгах, которые я
читал, говорится, что комментарии полезны и что на них не стоит экономить. Мы зря теряем время.
— Успокойся, Фрасимах. Спроси у Калликла, как давно он программирует.
— Действительно, как давно, Калликл?
— Ну, я начал с системы Акрополь IV где-то 15 лет назад. Думаю, что я стал свидетелем рождения и
гибели примерно десятка крупных приложений. А еще в десятке проектов я работал над крупными
компонентами. Две из этих систем включали более полумиллиона строк кода, так что я знаю, о чем
говорю. Комментарии совершенно бесполезны.
Сократ бросает взгляд на более молодого программиста.
— Как говорит Калликл, с комментариями действительно связано много проблем, и ты не поймешь это,
пока не приобретешь больше опыта. Если комментировать код неграмотно, комментарии не просто
бесполезны — они вредны.
— Они бесполезны, даже если комментировать код грамотно, — заявляет Калликл.
— Комментарии менее точны, чем язык программирования. Лично я думаю, что лучше вообще их не
писать.
— Постой, — говорит Сократ. — Исмена согласна с тем, что комментарии менее точны, но она
утверждает, что комментарии поднимают программиста на более высокий уровень абстракции, а все мы
знаем, что абстракция — один из самых эффективных инструментов, имеющихся в нашем распоряжении.
— Я с этим не согласен, — заявляет Главкон. — Нам следует концентрироваться не на комментариях,
а на читабельности кода. При рефакторинге большинство
моих комментариев исчезает. После рефакторинга мой код может включать 20 или 30 вызовов
методов, не нуждающихся в каких бы то ни было комментариях. Хороший программист способен
определять цель автора по самому коду; к тому же какой толк в чтении о чьей-то цели, если
известно, что код содержит ошибку?
Главкон умолкает, удовлетворенный своим вкладом в беседу. Калликл кивает.
— Похоже, вам никогда не приходилось изменять чужой код, — говорит Исмена. Калликл делает вид,
что его очень заинтересовали плитки на потолке.
— Почему бы вам не попробовать прочитать собственный код через шесть месяцев или год после его
написания? Вы можете развивать и навык чтения кода, и навык его комментирования. Никто не
заставляет вас выбирать что-то одно. Если вы читаете роман, вам, может, и не нужны названия
глав. Но при чтении технической книги вам, наверное, хотелось бы иметь возможность быстро найти
то, что вы ищете. Тогда мне не пришлось бы переходить в режим сверхсосредоточенности и читать
сотни строк кода для нахождения двух строк, которые я хочу изменить.
— Хорошо, я понимаю, что возможность быстрого просмотра кода была бы удобной, — говорит Главкон.
Он видел некоторые из программ Исмены, и они не оставили его равнодушным. — Но как быть с
другим утверждением Калликла — что комментарии устаревают по мере изменений кода? Я программирую
лишь пару лет, но даже я знаю, что никто не обновляет свои комментарии.
— Ну, и да, и нет, — говорит Исмена. — Если вы считаете комментарии неприкосновенными, а код
подозрительным, у вас серьезные проблемы. На самом деле несоответствие между комментарием и кодом
обычно говорит о том, что неверно и то, и другое. Если какие-то комментарии плохи, это не
означает, что само комментирование плохо. Пойду налью себе еще чашку кофе.
Исмена выходит из комнаты.
— Мое главное возражение против комментариев, — заявляет Калликл, — в том, что они тратят
ресурсы.
— Можете ли вы предложить способ минимизации времени написания комментариев? — спрашивает Сократ.
— Проектирование методов на псевдокоде, преобразование псевдокода в комментарии и написание
соответствующего им кода, — говорит Главкон.
— OK, это сработает, если комментарии не будут повторять код, — утверждает Калликл.
— Написание комментария заставляет вас лучше подумать над тем, что делает ваш код, — говорит
Исмена, возвращаясь с новой чашкой кофе. — Если комментарии писать трудно, это означает, что
код плох или вы недостаточно хорошо его понимаете. В обоих случаях вы должны поработать над
кодом еще, так что время, потраченное на его комментирование, не пропадает — оно указывает вам
на необходимую работу.
— Хорошо, — подводит итоги Сократ. — Не думаю, что у нас остались еще вопросы. Похоже, Исмена
сегодня была самой убедительной. Мы будем поощрять комментирование, но не будем относиться к
нему простодушно. Мы будем выполнять обзоры кода, чтобы все поняли, какие комментарии на самом
деле полезны. Если у вас возникнут проблемы с пониманием кода другого программиста, подскажите
ему, как он может его улучшить.
чем полезным. Жаркие дискуссии по поводу достоинств комментирования часто напоминают
философские дебаты о моральных достоинствах, и это наводит меня на мысль о том, что, будь Сократ
программистом, между ним и его учениками могла бы произойти следующая беседа.
Комменто
Действующие лица:
ФРАСИМАХ Неопытный пурист теории, который верит всему, что читает.
КАЛЛИКЛ Закаленный в боях представитель старой школы — «настоящий» программист.
ГЛАВКОН Молодой, самоуверенный, энергичный программист.
ИСМЕНА Опытная разработчица, уставшая от громких обещаний и просто желающая найти
несколько работающих методик.
СОКРАТ Мудрый опытный программист.
Мизансцена:
Завершение ежедневного собрания группы
— Желает ли кто-то обсудить еще что-нибудь, прежде чем мы вернемся к работе? — спрашивает Сократ.
— Я хочу предложить стандарт комментирования для наших проектов, — говорит Фрасимах. —
Некоторые наши программисты почти не комментируют свой
код, а всем известно, что код без комментариев нечитаем.
— Ты, должно быть, еще менее опытен, чем я думал, — отвечает Калликл. — Комментарии — это
академическая панацея, и любому, кто писал реальные программы, известно, что комментарии
затрудняют чтение кода, а не облегчают. Естественный язык менее точен, чем Java или Visual
Basic, и страдает от избыточности, тогда как операторы языков программирования лаконичны и
попадают в самое яблочко. Если кто-то не может написать ясный код, разве ему удастся
написать ясные комментарии? Кроме того, комментарии устаревают при изменениях кода. Доверяя
устаревшим комментариям, ты сам себе роешь яму.
— Полностью согласен, — вступает в разговор Главкон. — Щедро прокомментированный код читать
труднее, потому что в этом случае читать приходится больше. Мало того, что я должен читать код,
так мне нужно читать еще и кучу комментариев!
— Подождите минутку, — вставляет свои две драхмы Исмена, ставя чашку кофе.
— Конечно, злоупотребление комментариями возможно, но хорошие комментарии ценятся на вес золота.
Мне приходилось сопровождать код как с комментариями, так и без них, и, будь у меня выбор, я бы
предпочла первый вариант. Не думаю, что нам нужен стандарт, заставляющий писать один
комментарий на каждые x строк кода, но побудить всех программистов комментировать код не
помешает.
— Если комментарии — пустая трата времени, почему все их используют, Калликл? — спрашивает Сократ.
— Или потому, что таково требование, или потому, что человек прочитал где-то о пользе
комментариев. Ни один программист, когда-либо задумавшийся об этом, не пришел к выводу, что
комментарии полезны.
— Исмена считает, что они полезны. Она уже три года сопровождает твой код без комментариев и чужой
код с комментариями. Ее мнение ты уже слышал. Что ты скажешь на это?
— Комментарии бесполезны, потому что они просто повторяют код в более многословной…
— Подожди, — прерывает Калликла Фрасимах. — Хорошие комментарии не повторяют код и не объясняют
его. Они поясняют его цель. Комментарии должны объяснять намерения программиста на более
высоком уровне абстракции, чем код.
— Верно, — соглашается Исмена. — Если я ищу фрагмент, который мне нужно изменить или исправить,
я просматриваю комментарии. Комментарии, повторяющие код, на самом деле бесполезны, потому что
все уже сказано в самом коде. Когда я читаю комментарии, я хочу, чтобы они напоминали оглавление
книги. Комментарии должны помочь мне найти нужный раздел, а после этого я начну читать
код. Гораздо быстрее прочитать одно предложение на обычном языке, чем анализировать 20 строк
кода на языке программирования.
Исмена наливает себе вторую чашку кофе.
— Мне кажется, что люди, отказывающиеся писать комментарии, (1) думают, что их код понятнее,
чем мог бы быть, (2) считают, что другие программисты гораздо сильнее интересуются их кодом,
чем есть на самом деле, (3) думают, что другие программисты умнее, чем есть на самом деле, (4)
ленятся или (5) боятся, что кто-то другой узнает, как работает их код.
— В этом смысле очень помогли бы обзоры кода, Сократ, — продолжает Исмена.
— Если кто-то утверждает, что комментарии писать не нужно, и получает во время обзора кучу
вопросов — если сразу несколько коллег спрашивают его: „Что происходит в этом фрагменте твоего
кода?“ — он начинает писать комментарии. Если программист не дойдет до этого сам, его руководитель
сможет заставить его писать комментарии.
— Я не утверждаю, Калликл, что ты ленишься или боишься, что кто-то другой поймет твой код. Я
работала с твоим кодом и могу сказать, что ты — один из лучших программистов компании. Но будь
чуточку добрее, а? Мне было бы легче сопровождать твой код, если бы ты писал комментарии.
— Но это пустая трата времени, — не сдается Калликл. — Код хорошего программиста должен быть
самодокументирующимся: все, что нужно знать другим программистам, должно быть в самом коде.
— Нет! — Фрасимах вскакивает со стула. — В коде и так уже есть все, что нужно знать компилятору!
С таким же успехом можно было бы сказать, что все, что нужно знать другим программистам, уже
есть в двоичном исполняемом файле! Если бы мы только были достаточно умны, чтобы уметь читать
его! Информации о том, что программист собирался сделать, в коде нет.
Фрасимах замечает, что вскочил с места, и садится.
— Сократ, это немыслимо. Почему мы спорим о важности комментариев? Во всех книгах, которые я
читал, говорится, что комментарии полезны и что на них не стоит экономить. Мы зря теряем время.
— Успокойся, Фрасимах. Спроси у Калликла, как давно он программирует.
— Действительно, как давно, Калликл?
— Ну, я начал с системы Акрополь IV где-то 15 лет назад. Думаю, что я стал свидетелем рождения и
гибели примерно десятка крупных приложений. А еще в десятке проектов я работал над крупными
компонентами. Две из этих систем включали более полумиллиона строк кода, так что я знаю, о чем
говорю. Комментарии совершенно бесполезны.
Сократ бросает взгляд на более молодого программиста.
— Как говорит Калликл, с комментариями действительно связано много проблем, и ты не поймешь это,
пока не приобретешь больше опыта. Если комментировать код неграмотно, комментарии не просто
бесполезны — они вредны.
— Они бесполезны, даже если комментировать код грамотно, — заявляет Калликл.
— Комментарии менее точны, чем язык программирования. Лично я думаю, что лучше вообще их не
писать.
— Постой, — говорит Сократ. — Исмена согласна с тем, что комментарии менее точны, но она
утверждает, что комментарии поднимают программиста на более высокий уровень абстракции, а все мы
знаем, что абстракция — один из самых эффективных инструментов, имеющихся в нашем распоряжении.
— Я с этим не согласен, — заявляет Главкон. — Нам следует концентрироваться не на комментариях,
а на читабельности кода. При рефакторинге большинство
моих комментариев исчезает. После рефакторинга мой код может включать 20 или 30 вызовов
методов, не нуждающихся в каких бы то ни было комментариях. Хороший программист способен
определять цель автора по самому коду; к тому же какой толк в чтении о чьей-то цели, если
известно, что код содержит ошибку?
Главкон умолкает, удовлетворенный своим вкладом в беседу. Калликл кивает.
— Похоже, вам никогда не приходилось изменять чужой код, — говорит Исмена. Калликл делает вид,
что его очень заинтересовали плитки на потолке.
— Почему бы вам не попробовать прочитать собственный код через шесть месяцев или год после его
написания? Вы можете развивать и навык чтения кода, и навык его комментирования. Никто не
заставляет вас выбирать что-то одно. Если вы читаете роман, вам, может, и не нужны названия
глав. Но при чтении технической книги вам, наверное, хотелось бы иметь возможность быстро найти
то, что вы ищете. Тогда мне не пришлось бы переходить в режим сверхсосредоточенности и читать
сотни строк кода для нахождения двух строк, которые я хочу изменить.
— Хорошо, я понимаю, что возможность быстрого просмотра кода была бы удобной, — говорит Главкон.
Он видел некоторые из программ Исмены, и они не оставили его равнодушным. — Но как быть с
другим утверждением Калликла — что комментарии устаревают по мере изменений кода? Я программирую
лишь пару лет, но даже я знаю, что никто не обновляет свои комментарии.
— Ну, и да, и нет, — говорит Исмена. — Если вы считаете комментарии неприкосновенными, а код
подозрительным, у вас серьезные проблемы. На самом деле несоответствие между комментарием и кодом
обычно говорит о том, что неверно и то, и другое. Если какие-то комментарии плохи, это не
означает, что само комментирование плохо. Пойду налью себе еще чашку кофе.
Исмена выходит из комнаты.
— Мое главное возражение против комментариев, — заявляет Калликл, — в том, что они тратят
ресурсы.
— Можете ли вы предложить способ минимизации времени написания комментариев? — спрашивает Сократ.
— Проектирование методов на псевдокоде, преобразование псевдокода в комментарии и написание
соответствующего им кода, — говорит Главкон.
— OK, это сработает, если комментарии не будут повторять код, — утверждает Калликл.
— Написание комментария заставляет вас лучше подумать над тем, что делает ваш код, — говорит
Исмена, возвращаясь с новой чашкой кофе. — Если комментарии писать трудно, это означает, что
код плох или вы недостаточно хорошо его понимаете. В обоих случаях вы должны поработать над
кодом еще, так что время, потраченное на его комментирование, не пропадает — оно указывает вам
на необходимую работу.
— Хорошо, — подводит итоги Сократ. — Не думаю, что у нас остались еще вопросы. Похоже, Исмена
сегодня была самой убедительной. Мы будем поощрять комментирование, но не будем относиться к
нему простодушно. Мы будем выполнять обзоры кода, чтобы все поняли, какие комментарии на самом
деле полезны. Если у вас возникнут проблемы с пониманием кода другого программиста, подскажите
ему, как он может его улучшить.
Согласен с автором поста. Сам комментирую только тогда, когда код в силу некоторых причин не очевиден (используется какой-нибудь хак, например). В остальном — смотреть и читать здесь, очень полезно 2013.happydev.ru/report/10
Комментарии нужны. Для себя выделил два случая:
1) для описания назначения и вызовов функций, процедур, модулей. Т.е. хорошие комментарии — фактически спецификация программных интерфейсов. Если такие спецификации есть до кодинга, то достаточно скопировать их в «рыбы» модулей. Это идеал. В жизни недостижим. Обычно описание пишется после кодинга, но сути дела это не меняет.
2) для описания реально сложных алгоритмов (как правило математических моделей и методов). в этом случае комментарий описывает идею происходящего в программе. Когда таких мест много легко забыть, что хотел, как и зачем.
Все остальное — действительно не нужно, ибо вполне достаточно грамотных названий переменный, функций, модулей и т.д.
Детальное описание всего и вся для облегчения труда последователей делает жизнь легче им, а не мне, поэтому такое подробное комментирование следует оговаривать и ОПЛАЧИВАТЬ отдельно.
1) для описания назначения и вызовов функций, процедур, модулей. Т.е. хорошие комментарии — фактически спецификация программных интерфейсов. Если такие спецификации есть до кодинга, то достаточно скопировать их в «рыбы» модулей. Это идеал. В жизни недостижим. Обычно описание пишется после кодинга, но сути дела это не меняет.
2) для описания реально сложных алгоритмов (как правило математических моделей и методов). в этом случае комментарий описывает идею происходящего в программе. Когда таких мест много легко забыть, что хотел, как и зачем.
Все остальное — действительно не нужно, ибо вполне достаточно грамотных названий переменный, функций, модулей и т.д.
Детальное описание всего и вся для облегчения труда последователей делает жизнь легче им, а не мне, поэтому такое подробное комментирование следует оговаривать и ОПЛАЧИВАТЬ отдельно.
Что, в этом случае, меня может остановить от написания комментария, на который я потрачу, от силы, пару минут?
Например, необходимость переключить контекст с языка, на котором написан код, на естественный язык. Необходимость выразить конструкцию, связывающую десяток разнородных объектов программы, и существующую в данный момент в сознании, в виде слов. Пока начнешь её раскручивать и формулировать, легко будет забыть, что у неё было на противоположной стороне графа взаимосвязей. Особенно если слов не хватает и приходится сочинять новые формулировки для выражения того, для чего не выдумано языка… Не зря же говорят, что «мысль изречённая есть ложь». Пары минут тут может не хватить.
А вы прямо думаете на языке программирования? Поздравляю вас, вы робот.
Люди думают на естественном языке, так уж устроено сознание. Любая конкретная идея выражена на естественном языке. Мысль даже подуманная есть ложь, так как какие бы ни были в сознании образы, для осознания их приходится переводить в язык.
Недаром даже нет особых звуков для $, (, ) и прочих символов или особых синтаксических конструкций, которые есть в языке программирования. Есть разве что «перевод строки» или лучше «конец выражения», который отражается в понижении интонации.
Контекст всегда находится в естественном языке.
Люди думают на естественном языке, так уж устроено сознание. Любая конкретная идея выражена на естественном языке. Мысль даже подуманная есть ложь, так как какие бы ни были в сознании образы, для осознания их приходится переводить в язык.
Недаром даже нет особых звуков для $, (, ) и прочих символов или особых синтаксических конструкций, которые есть в языке программирования. Есть разве что «перевод строки» или лучше «конец выражения», который отражается в понижении интонации.
Контекст всегда находится в естественном языке.
Я думаю не на языке программирования. И не на естественном языке. А оперируя образами в сознании и связями между ними. Если бы для каждого понятия пришлось придумывать термин естественного языка, да ещё и проговаривать эти термины при любой операции над понятиями, то многие мысли додумать бы не удалось. Что-то воспринимается в визуальном виде, что-то в математических терминах, что-то в виде аналогий… Но язык — в лучшем случае, для формулировки окончательных результатов. И иногда язык программирования для этого подходит больше.
Комментарии пишу, но без фанатизма.
Комментирую в основном только блоки, чтобы было понятно что они делают. Что-то вроде
//Перебираем заявки, вошедшие в выбранный период и пересчитываем остатки
По крайней мере беглого взгляда на процедуру хватает, чтобы найти нужные места или «освежить» в памяти логику работы.
А остальную работу делает грамотное наименование переменных.
Комментирую в основном только блоки, чтобы было понятно что они делают. Что-то вроде
//Перебираем заявки, вошедшие в выбранный период и пересчитываем остатки
По крайней мере беглого взгляда на процедуру хватает, чтобы найти нужные места или «освежить» в памяти логику работы.
А остальную работу делает грамотное наименование переменных.
На днях наткнулся на свой старый-старый комментарий:
Вот иногда комментарии нужны для прекрасного чувства ностальжи по проведенным в офисе выходным перед новогодним релизом.
// здесь покоятся последние надежды на нормальный код в релизе 1.3.1
Вот иногда комментарии нужны для прекрасного чувства ностальжи по проведенным в офисе выходным перед новогодним релизом.
Давайте начистоту. Если
то и
тоже не получится.
С одной стороны, комментарии — зло, хотя и зло разной степени необходимости. Я сейчас сталкиваюсь с проблемой, что даже в экстремуме: устаревший ассемблерный код, тонны его, — комментарии помогают и путают примерно одинаково. Нет абсолютно никакой гарантии, что в коде слева от комментария происходит именно то, что в нем написано. Все критичное приходится проверять и перепроверять в коде. Комментарии сильно помогают в том, чтобы понять общую суть, помогают ориентироваться в тексте программы, помогают быстро пролистать много страниц по диагонали. Но в деталях на них полагаться нельзя, а детали как раз и важны в первую очередь.
Проблема в том, что есть множество инструментов для валидации и верификации кода. Есть статические и динамические анализаторы, есть профайлеры и отладчики, есть модульное, интеграционное, регрессионное тестирование. А вот комментарии верифицировать можно только вручную и только через ревью.
Можно, конечно, формализировать ревью. Взять, к примеру, методику Фагана, она правда тоже для кода, а не комментариев. Но она требует участия минимум трех участников на протяжении часа-полутора и позволяет инспектировать 200-300 строк за сессию. Это очень долго, дорого и никогда не применяется для комментариев. Вообще никогда. А вот документация, например, там где надо, в рамках формальной процедуры верифицируется.
И конечно же прозрачный идеоматичный код с говорящими именами и легкочитаемыми конструкциями лучше, чем грязный код с комментариями. И все-таки двадцать первый век на дворе, на современных языках можно писать много выразительнее, чем на алголе и ассемблере. И да, внезапный комментарий действительно говорит о том, что с кодом что-то не так.
Но с другой стороны, с кодом всегда что-то не так. Такая уж природа ПО. Считается, что хороший софт имеет плотность дефектов менее одного на тысячу строк кода. То есть даже при самых жестких V&V процедурах, никто и не ожидает, что программа будет безошибочной. Всего лишь дефектной в рамках дозволенного. Даже если процедура утверждает, что дефектов нет, это означает только то, что они не были найдены в рамках конкретной процедуры. Нулевая плотность дефектов — это не гарантия, а обещание.
Поэтому если кто-то думает, что может делать свой код лучше принципиально не пользуясь комментариями, это самообман. Код костыли содержит всегда, и лучше их явно обозначать комментариями, чем умалчивать.
Но и если кто-то думает, что может сделать свой код лучше комментируя все подряд без очевидной необходимости, это тоже самообман. Поддержка комментариев стократно сложнее поддержки кода, а внимания ей уделяется несравнимо меньше.
в реальной жизни, не всегда получается выдавать красивый и логичный код
то и
быть внимательным, и не забывать исправлять комментарии при исправлении кода
тоже не получится.
С одной стороны, комментарии — зло, хотя и зло разной степени необходимости. Я сейчас сталкиваюсь с проблемой, что даже в экстремуме: устаревший ассемблерный код, тонны его, — комментарии помогают и путают примерно одинаково. Нет абсолютно никакой гарантии, что в коде слева от комментария происходит именно то, что в нем написано. Все критичное приходится проверять и перепроверять в коде. Комментарии сильно помогают в том, чтобы понять общую суть, помогают ориентироваться в тексте программы, помогают быстро пролистать много страниц по диагонали. Но в деталях на них полагаться нельзя, а детали как раз и важны в первую очередь.
Проблема в том, что есть множество инструментов для валидации и верификации кода. Есть статические и динамические анализаторы, есть профайлеры и отладчики, есть модульное, интеграционное, регрессионное тестирование. А вот комментарии верифицировать можно только вручную и только через ревью.
Можно, конечно, формализировать ревью. Взять, к примеру, методику Фагана, она правда тоже для кода, а не комментариев. Но она требует участия минимум трех участников на протяжении часа-полутора и позволяет инспектировать 200-300 строк за сессию. Это очень долго, дорого и никогда не применяется для комментариев. Вообще никогда. А вот документация, например, там где надо, в рамках формальной процедуры верифицируется.
И конечно же прозрачный идеоматичный код с говорящими именами и легкочитаемыми конструкциями лучше, чем грязный код с комментариями. И все-таки двадцать первый век на дворе, на современных языках можно писать много выразительнее, чем на алголе и ассемблере. И да, внезапный комментарий действительно говорит о том, что с кодом что-то не так.
Но с другой стороны, с кодом всегда что-то не так. Такая уж природа ПО. Считается, что хороший софт имеет плотность дефектов менее одного на тысячу строк кода. То есть даже при самых жестких V&V процедурах, никто и не ожидает, что программа будет безошибочной. Всего лишь дефектной в рамках дозволенного. Даже если процедура утверждает, что дефектов нет, это означает только то, что они не были найдены в рамках конкретной процедуры. Нулевая плотность дефектов — это не гарантия, а обещание.
Поэтому если кто-то думает, что может делать свой код лучше принципиально не пользуясь комментариями, это самообман. Код костыли содержит всегда, и лучше их явно обозначать комментариями, чем умалчивать.
Но и если кто-то думает, что может сделать свой код лучше комментируя все подряд без очевидной необходимости, это тоже самообман. Поддержка комментариев стократно сложнее поддержки кода, а внимания ей уделяется несравнимо меньше.
Комментарии весьма уместны при описании различных интерфейсов и прототипов. Заголовки в header-файлах с кратким описанием содержимого и того зачем и как его применять, описания параметров функции и возможных исключений — все это вполне себе способствует читаемости и не случайно вменяемые IDE показывают соответствующие комментарии во всплывающих подсказках при автодополнении кода.
В остальном комментарии конечно свидетельствуют о проблемах в коде: идеальный код должен читаться как книга и описывать единственно возможное в данной ситуации действие :). Но этот идеал заведомо недостижим, реальный код так или иначе всегда содержит какое-то количество подводных камней, устранять которые стоит нерационально дорого. В подавляющем большинстве случаев люди, которые не пишут комментарии, эти камни никуда не убирают, а просто рассчитывают на то что другие программисты эти камни заметят. И вот их надо бы за такое бить по рукам.
В остальном комментарии конечно свидетельствуют о проблемах в коде: идеальный код должен читаться как книга и описывать единственно возможное в данной ситуации действие :). Но этот идеал заведомо недостижим, реальный код так или иначе всегда содержит какое-то количество подводных камней, устранять которые стоит нерационально дорого. В подавляющем большинстве случаев люди, которые не пишут комментарии, эти камни никуда не убирают, а просто рассчитывают на то что другие программисты эти камни заметят. И вот их надо бы за такое бить по рукам.
чистый код в комментариях не нуждается, он и так понятен
Понятие «чистый код» для всех разное. Я вот тоже думал 5 лет назад, что мой код «чистый».
Это неловкое чувство у каждого возникает, когда просматриваются старые проекты.
Есть вопрос немного другого толка. Почему комментарии написаны так, будто это диалог на уроке программирования?
Почему вместо «увеличиваем счётчик» не пишется «увеличение счётчика»?
Зачем нужна эта персонификация в комментариях кода?
Почему вместо «увеличиваем счётчик» не пишется «увеличение счётчика»?
Зачем нужна эта персонификация в комментариях кода?
А вы все еще пишете комментарии про увеличение счетчика? Тогда мы идем к вам :D
Персонификация зависит от человека, но на нее внимания не обращаешь.
А вот на комментарий об увеличении счетчика смотришь всегда с ухмылкой, не зависимо персонифицирован он или нет.
Персонификация зависит от человека, но на нее внимания не обращаешь.
А вот на комментарий об увеличении счетчика смотришь всегда с ухмылкой, не зависимо персонифицирован он или нет.
Если говорить про персонификацию комментариев, то не утверждают хорошо это или плохо. Просто интересно разобраться, в чём причины такой формы комментирования? Если это привычка, то откуда она появляется? Из школьных/институтских курсов программирования? Может существует некая популярная книга где активно используется такая форма комментариев? Или в некой популярной образцовой open source программе такие комментарии применяются?
Персонификация это забавный способ пообщаться с коллегой, который через пару лет будет ковыряться в твоем коде.
Сейчас порылся, попадаются забавные
Сейчас порылся, попадаются забавные
/**
* Метод выхода, посылаем далеко-далеко, отбираем печеньки,
* ломаем ножки, пусть ползёт как может. Злые мы, злые!
*/
public function Logout () {
...
}
Для того, чтобы язык в комментариях был больше похож на человеческую речь, а е на канцелярит.
Сравните, что проще понимать:
Или
Сравните, что проще понимать:
Онегин, добрый мой приятель,
Родился на брегах Невы,
Где, может быть, родились вы
Или блистали, мой читатель;
Или
Место рождения Онегина Е. расположено на берегах р.Нева, предположительно совпадает с местом рождения адресата данного текста
Проще второй вариант, приятнее первый вариант.
Тогда для Вас «персонификация» не нужна.
Я, да и многие мои знакомые, ппредпочитаем находиться и находимся в среде, где литературный русский распространён больше, чем канцелярит.
Я, да и многие мои знакомые, ппредпочитаем находиться и находимся в среде, где литературный русский распространён больше, чем канцелярит.
Согласен с высказавшимися выше, по большому счёту неважно в какой форме комментарий, если он хорошо выполняет свою функцию.
Но вопрос то не в этом, а в том откуда появилась такая тенденция? Например, понятно откуда появилась тенденция перехода на CamelCase, так как подобная запись позволяет делать более короткие идентификаторы при сохранении хорошей читаемости. А откуда появилась тенденция персонализировать комментарии пока не ясна.
Но судя по вашей версии, она появилась как противопоставление обезличенному тексту, позволяя его сделать более тёплым, ламповым и дружелюбным. Хорошая версия, но тогда почему персонифицированные комментарии так напоминают речь учителя программирования? Почему «увеличиваем счётчик», а не «увеличиваю счётчик»?
Но вопрос то не в этом, а в том откуда появилась такая тенденция? Например, понятно откуда появилась тенденция перехода на CamelCase, так как подобная запись позволяет делать более короткие идентификаторы при сохранении хорошей читаемости. А откуда появилась тенденция персонализировать комментарии пока не ясна.
Но судя по вашей версии, она появилась как противопоставление обезличенному тексту, позволяя его сделать более тёплым, ламповым и дружелюбным. Хорошая версия, но тогда почему персонифицированные комментарии так напоминают речь учителя программирования? Почему «увеличиваем счётчик», а не «увеличиваю счётчик»?
Просто у меня мания величия
Думаю, тот же вопрос можно задать кондуктору в автобусе, которая говорит «Передаем за проезд!», а не «Передавайте за проезд». Ответ лежит где-то в дебрях психологии, как мне кажется.
Передаём за проезд — это обращение к обезличенной толпе.
Передавайте за проезд — это обращение к конкретной группе лиц.
Так как приходиться работать со сплошным потоком людей, а не с некой стабильной группой лиц, то и выбирается соответствующее обращение.
Но версия про психологию мне нравиться, вполне вероятно.
Передавайте за проезд — это обращение к конкретной группе лиц.
Так как приходиться работать со сплошным потоком людей, а не с некой стабильной группой лиц, то и выбирается соответствующее обращение.
Но версия про психологию мне нравиться, вполне вероятно.
Это довольно древняя тенденция в научной литературе, особенно в математической (рассмотрим треугольник ABC...). Оттуда пришла и в комментарии к коду.
И да, мне так привычнее и приятнее.
И да, мне так привычнее и приятнее.
Да, это хорошая мысль. В основном это проявляется в учебниках, а их часто пишут педагоги основываясь на своей практике. Отсюда и подобная форма пояснений.
В научной литературе в основном, речь ведётся в виде доклада о проделанной работе. Что то вроде — при обработке полученных данных, выявлена тенденция усиливающаяся с увеличение числа итераций к группировке результатов вдоль линий предсказанных теоретическим путём(см. стр. 155), тем самым подтверждая…
В научной литературе в основном, речь ведётся в виде доклада о проделанной работе. Что то вроде — при обработке полученных данных, выявлена тенденция усиливающаяся с увеличение числа итераций к группировке результатов вдоль линий предсказанных теоретическим путём(см. стр. 155), тем самым подтверждая…
del
Особенно актуально на английском:
// Getting date
int GetDate();
На русском чуть менее бредово, но всего лишь чуть:
// Получаем дату
int GetDate();
Это конечно особый случай=)
// Getting date
int GetDate();
На русском чуть менее бредово, но всего лишь чуть:
// Получаем дату
int GetDate();
Это конечно особый случай=)
Одинаково бредово. Невозможно заниматься программированием и не знать английского на уровне get date.
Специально для вас: (до этого момента я не знал как будет ход поршня, а вы?)
//получить длину хода поршня
int GetPistonStrokeDistance()
//Get piston stroke distance
int GetPistonStrokeDistance()
//получить длину хода поршня
int GetPistonStrokeDistance()
//Get piston stroke distance
int GetPistonStrokeDistance()
Хорошие комментарии всегда отражают связь с бизнес-логикой. Т.е. они про уровень абстракции выше чем код, а значит, не являются избыточными и в целом — полезны. Особенно если логика сложная. Отвечают всегда на вопрос — «зачем?» Вопрос «как?» и так виден по коду, на него отвечать не нужно.
Другой сорт полезных комментариев — к магическим выражениям, типа регекспов. Где текстовое описание того что происходит является исходным требованием для магии, которую потом можно проверить на соответствие этому. Но такое встречается реже.
Третий сорт полезных комментариев — доки к методам и публичным апи. Они в принципе никогда лишними не бывают.
Другой сорт полезных комментариев — к магическим выражениям, типа регекспов. Где текстовое описание того что происходит является исходным требованием для магии, которую потом можно проверить на соответствие этому. Но такое встречается реже.
Третий сорт полезных комментариев — доки к методам и публичным апи. Они в принципе никогда лишними не бывают.
У нас в компании существует стандарт на комментарии — каждый публичный метод должен содержать docstrings с кратким описанием того, что он делает. Должны быть описаны параметры, их тип, что метод возвращает, какие исключения выбрасывает. Затем на основе всего этого генерируется документация. Плюс здорово помогает при автодополнении, сразу видно что метод делает, какие параметры принимает и что возвращает.
Так же комментируем особо сложные участки кода.
Так же комментируем особо сложные участки кода.
Язык python
Как-то так
Как-то так
def get_transaction_id(request):
"""Returns the current transaction id from the request
:param request: The current request object
:type request: django.http.request.HttpRequest
:return: The retrieved transaction identifier or None if not valid or not available
:rtype: int or None
"""
...
Хорошо.
А что насчёт инструментов, собирающих некие части документации прямо из комментариев к методам и классам в исходниках?
А что насчёт инструментов, собирающих некие части документации прямо из комментариев к методам и классам в исходниках?
В .NET достаточно XML-комментариев для всех внешних public классов и их public и protected методов.
Ну и изредка комментарии для сильно неочевидных кусочков кода, коих, естественно, должен быть минимум.
Ну и изредка комментарии для сильно неочевидных кусочков кода, коих, естественно, должен быть минимум.
Кстати, комментарии — действительно острая тема. Те, кто пишет про «самодокументирующийся код», похоже никогда не писали ничего длиннее shell/js скрипта на сотню строчек. Вот ряд наблюдений о «самодокументирующемся коде»:
- длинное имя переменной увеличивает длину строки, что приводит либо к избыточно длинным строкам, либо к разбиению длинной строки на более короткие; в любом случае код растет либо по горизонтали, либо по вертикали, а чем больше кода, тем дольше он читается
- то, что делает код и то, что автор кода хотел, чтобы код делал, не всегда одно и то же. Частично эта проблема решается юнит-тестами.
- без комментариев для оформления кода остаются только пустые строки + вынос даже однократно выполняющихся действий в отдельные функции. Чтение кода, изобилующего вызовами различных функций, замедляется по сравнению со старой доброй портянкой «копаем отсюда и до обеда».
- применение паттернов — никто не пишет настолько запутанный код, как программист, только что нашедший «единственно верный способ писать хороший код». В особо запущенных случаях даже комментарии могут не помочь разобраться в подобной мешанине.
- всегда проще прочитать документацию по библиотечным функциям, чем читать хидеры, чтобы вычленить из них публичный интерфейс, а затем реализацию этих методов, чтобы понять нюансы их применения
- комментарий обычно короче (и понятнее) кода — грамотно расставляя комментарии в коде ты экономишь время своих коллег и прочих людей, которым придется работать с твоим кодом
В статье не хватает примеров. Вот, Вы вставили в начало поста картинку:
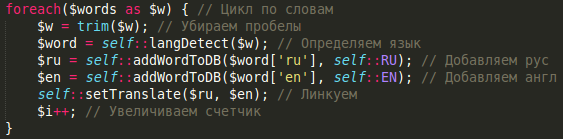
По Вашему мнению, здесь нужны комментарии или нет?
По Вашему мнению, здесь нужны комментарии или нет?
Мне кажется они не нужны. Точнее я уверен.
Код отвратительный.
Если порефакторить возможности нет, то можно было бы написать комментарии — это хоть как-то бы спасло ситуацию.
Но те комментарии, которые тут написаны — нисколько не помогают понять смутные места этого кода.
Если порефакторить возможности нет, то можно было бы написать комментарии — это хоть как-то бы спасло ситуацию.
Но те комментарии, которые тут написаны — нисколько не помогают понять смутные места этого кода.
Предложите Ваш вариант комментариев.
Не зная, что код должен был делать, я не могу написать поясняющие комментарии. Могу лишь написать вопросительные — типа как на код-ревью. В ответ от автора кода ожидал бы либо рефакторинга, чтобы вопрос отпал, либо (этот вариант хуже) пояснения в виде комментария.
foreach($words as $w) {
// почему здесь вообще делается trim? как-то не связано с остальной частью кода
$w = trim($w);
// langDetect - сомнительное название (detectLanguage?). В любом случае, исходя из названия функции я бы предположил что она вернёт "язык". Но тогда почему мы записываем результат в переменную с именем $word? Функция с именем langDetect принимает слово, и возвращает слово. Что она вообще делает?
$word = self::langDetect($w);
// внезапно узнаем что $word - это не слово, а какой-то dict? Всё равно непонятно какова семантика того что вернула langDetect. Может быть она получила слово и вернула его переводы на русский и английский? Тогда и функцию, и $word нужно переименовать. Кстати а почему захардкожены именно эти два языка? Других никогда не будет? Почему ключи в словаре это строки 'ru', 'en', а не self::RU, self::EN?
// Ок, а что делает addWordToDB - в принципе можно догадаться. Сохраняет пару слово-язык в базу, и возвращает какой-то уникальный идентификатор.
$ru = self::addWordToDB($word['ru'], self::RU);
$en = self::addWordToDB($word['en'], self::EN);
// Два глагола подряд - не могу перевести.
self::setTranslate($ru, $en);
$i++; // а это вообще что? В цикле нигде не используется. Выпилить, и заюзать array_length если мы хотим посчитать длину массива
}
Не зная, что код должен был делать, я не могу написать поясняющие комментарии.
Если бы Вы знали, что делает этот код, то комментарии, скорее всего, не понадобились бы.
Рассмотрим 2 варианта:
1. Человек знает код. Для него запись
$ru = self::addWordToDB($word['ru'], self::RU); имеет смысл. Значит, этот код не нуждается в комментариях.2. Человек не знает код. Чтобы незнакомый с кодом человек понимал значение
$ru = self::addWordToDB($word['ru'], self::RU); нужно комментировать все такие вызовы. Но это же бред. Возможно стоит прокомментировать сам метод addWordToDB? А он, оказывается, очень простой и понятен без комментариев. Тупик.А если этот код переписать более понятным способом? Тогда код станет понятен любому и комментарии станут не нужны.
Грубо говоря, есть 2 варианта:
1. Хороший код — комментарии не нужны.
2. Плохой код — комментарии не спасут.
Плюс есть еще специфика. Если человек не работал с базами данных, то для него весь SQL — арабская вязь. И он пойдет писать статью на Хабр «о важности комментариев», непонятно же ничего!
Тут все советуют «пиши не что происходит, а почему». Клевый совет! Пусть автор статьи попробует прокомментировать код с картинки в стиле «почему». Хотелось бы на это посмотреть.
ИМХО, комментарии необходимы только в случае хаков. Тогда они и в стиле «почему» будут и читающему код помогут.
Плохой код — комментарии не спасут.
Ну можно оптимистично предположить что код плохой временно (технический долг, или костыль для обхода бага компилятора/фреймворка). Тогда комментарии «сохранят» состояние мыслей (намерение) разработчика, и при дальнейшем рефакторинге позволят «войти в тему» и переписать код хорошо.
Хотя это я теоретизирую, на самом деле я видел только два варианта (как вы и описали):
1. Код хороший и комментарии не нужны
2. Код плохой, и нет шансов что его отрефакторят
Может полный вариант будет понятней?
Так понятнее.
В PHP конечно может быть своя специфика и стиль написания, но вот мое мнение:
В PHP конечно может быть своя специфика и стиль написания, но вот мое мнение:
/**
* Добавление слова // Не слова а целого словаря
*/
public static function add($words) // $dict. И в комментарии к функции написать в каком формате принимаем словарь (строки разделенные \n, в каждой строке два слова через пробел(ы?), какое из них русское, а какое - английское - определяется автоматически)
{
$words = explode("\n", $words); // lines? Хотя в контексте словарей можно и words назвать но на мой сторонний взгляд это путаница
$i = 0;
foreach($words as $w) { // as $line
$w = trim($w); // всё же я бы отдельной строкой сделал $words = map(trim, $words), в этом цикле trim неуместен. Хотя langDetect может сам trim сделать
$word = self::langDetect($w); // $translations = self::parseLine($line); // или не $translation а $words? или оставить $word?
$ru = self::addWordToDB($word['ru'], self::RU); // всё равно почему 'ru' захардкожено если есть константа?
$en = self::addWordToDB($word['en'], self::EN);
self::setTranslate($ru, $en); // addTranslation
$i++;
}
return $i; // зачем?
}
Не буду комментировать названия переменных и формулировку комментариев, ибо, как показала практика, сегодня, через 4 месяца месяца после написания этого кода, я легко в нем ориентируюсь.
Остальное, дело вкуса. Где вставлять трим? Плодить ли дополнительные переменные, если можно обойтись без них? Это все на усмотрение разработчика, лишь бы не влияло на читабельность. Учитывая что вы, увидев код впервые, и при этом не имея практики разработки на php, сразу разобрались, где можно и что можно было бы, на ваш взгляд, улучшить — читаемость у кода высокая.
Остальное, дело вкуса. Где вставлять трим? Плодить ли дополнительные переменные, если можно обойтись без них? Это все на усмотрение разработчика, лишь бы не влияло на читабельность. Учитывая что вы, увидев код впервые, и при этом не имея практики разработки на php, сразу разобрались, где можно и что можно было бы, на ваш взгляд, улучшить — читаемость у кода высокая.
Код читается легко и без комментов. При том, что последний раз я писал на PHP лет 10 назад.
Доки для методов — отлично.
Как мне кажется, даже комменты в функции langDetect не нужны.
Доки для методов — отлично.
Как мне кажется, даже комменты в функции langDetect не нужны.
Добрый день.
Не использую комментарии. Использую только возможности документирования (аля summary в C#). Всегда включаю ворнинги на отсутствие доки к функции/классу. Из комментов использую только подобия ToDo, что бы не забыть. Благо современные IDE позволяют собирать все эти ToDo и отображать отдельным списком, чем я и пользуюсь каждую неделю в пятницу утром, просматривая чего я еще не сделал.
Ни разу не было момента, когда комментарий был необходим. Всегда, когда коммент был необходим, приходилось заниматься рефакторингом, после которого, коммент был не нужен. Выводы очевидны.
Не использую комментарии. Использую только возможности документирования (аля summary в C#). Всегда включаю ворнинги на отсутствие доки к функции/классу. Из комментов использую только подобия ToDo, что бы не забыть. Благо современные IDE позволяют собирать все эти ToDo и отображать отдельным списком, чем я и пользуюсь каждую неделю в пятницу утром, просматривая чего я еще не сделал.
Ни разу не было момента, когда комментарий был необходим. Всегда, когда коммент был необходим, приходилось заниматься рефакторингом, после которого, коммент был не нужен. Выводы очевидны.
Всегда комментирую, что делает данный участок кода, если это не очевидно из алгоритма.
естественно, те комментарии, которые приведены на картинке — бред. Все идет от пережитков ГОСТ 80х, где комментарии должны занимать 30% кода.
естественно, те комментарии, которые приведены на картинке — бред. Все идет от пережитков ГОСТ 80х, где комментарии должны занимать 30% кода.
/**
* Запускается в основном потоке
*/
int
load_online(struct conn * conn ) {
…
}
/*
первый параметр всегда uid, по которому надо шардить, далее параметры для вывода
возвращает номер шарда, используется в sql_execute(const char* query , int shard_id);
*/
static int
sql_build(char* bufer, const char* template, uint64_t uid, ...) {
…
}
Комментирую комментарии холивара об комментировании.
Прочитав данную статью о комментариях и комментарии к ней о комментариях, хочу оставить комментарий:
То что в вашем коде нет комментариев ещё не означает что он хороший.
То что в вашем коде нет комментариев ещё не означает что он хороший.
Выскажусь осторожнее: необходимость писать комментарии (а не само их наличие) в программах на языке Java (про другие — например, shell/js скрипты — судить не берусь) является, по моему мнению, признаком низкого качества кода. Как, в прочем, и наличие пресловутых «методов длиннее 30 строк» и «методов с цикломатической сложностью больше 5». Есть ещё рефакторинг — в частности, выделение метода и переименование метода — чтоб разбить «спагетти» на несколько методов с говорящими названиями. Но на Java с её статической типизацией в этом плане лучше — 1) сигнатуры методов, содержащие в себе классы, несут дополнительную подсказку (хорошо подсвечиваются в IDE), 2) проще автоматизированный рефакторинг — не надо на каждую мелочь типа переименования или выделения метода писать тесты, есть гарантия, что, если код компилируется, то он будет работать так же как раньше.
В общем, по крайней мере на Java, и можно и следует писать так, чтоб комментарии были не нужны.
Иногда, правда, корпоративный стандарт требует наличия Javadoc'ов на каждом методе…
В общем, по крайней мере на Java, и можно и следует писать так, чтоб комментарии были не нужны.
Иногда, правда, корпоративный стандарт требует наличия Javadoc'ов на каждом методе…
Мораль:
Самое главное, если вы решили отказаться от ..., убедитесь, что причина… не в банальной лени.
Что такое лень?
Я вот на последнем проекте с большим трудом заставлял себя писать комментарии (требовались по стайл-гайду) по следующим причинам:
1) Если написать комментарий, который не несёт никакой информации, сверх того что уже есть в сигнатуре метода — то это bullshit
2) Если попытаться придумать комментарий, который добавит какую-то информацию сверх того что есть в сигнатуре метода — то это займёт значительное время, которое лучше бы потратить на рефакторинг.
С другой стороны рефакторинг иногда может занять значительное время — и если это лень (некогда) делать, то совесть заставляет хотя бы пометить подводный камень комментарием.
Я вот на последнем проекте с большим трудом заставлял себя писать комментарии (требовались по стайл-гайду) по следующим причинам:
1) Если написать комментарий, который не несёт никакой информации, сверх того что уже есть в сигнатуре метода — то это bullshit
2) Если попытаться придумать комментарий, который добавит какую-то информацию сверх того что есть в сигнатуре метода — то это займёт значительное время, которое лучше бы потратить на рефакторинг.
С другой стороны рефакторинг иногда может занять значительное время — и если это лень (некогда) делать, то совесть заставляет хотя бы пометить подводный камень комментарием.
Ну, подводные камни — это нечто другое, это надо откомментировать…
Да я про другое немножко. Очень многие вещи, которые имеют эффект не мгновенный, но в будущем (комментирование кода, TDD, чистка зубов и т.д.) и при этом представляют из себя некоторую рутину хочется взять и не делать.
Так вот прежде чем не делать имеет смысл убедиться, что вы понимаете смысл этого действа и отказываетесь от него не из-за лени, но сознательно.
Так вот прежде чем не делать имеет смысл убедиться, что вы понимаете смысл этого действа и отказываетесь от него не из-за лени, но сознательно.
По поводу устаревания комментариев
Действительно, есть такая проблема. В целом, вот как я вижу ее решение:
После редактирования кода, к которому есть комментарий, достаточно подсветить комментарий, чтобы разработчик обратил на него внимание и исправил при необходимости.
Можно интеллекта прибавить такой проверке, анализировать изменения кода и все такое, но суть в том, чтобы разработчик обратил внимание и перечитал комментарий, ведь как правило мы просто изменяем код, и переходим к другому куску.
Писал это команде идеи и решарпера, но они отказались имплементить эту фичу :(
Действительно, есть такая проблема. В целом, вот как я вижу ее решение:
После редактирования кода, к которому есть комментарий, достаточно подсветить комментарий, чтобы разработчик обратил на него внимание и исправил при необходимости.
Можно интеллекта прибавить такой проверке, анализировать изменения кода и все такое, но суть в том, чтобы разработчик обратил внимание и перечитал комментарий, ведь как правило мы просто изменяем код, и переходим к другому куску.
Писал это команде идеи и решарпера, но они отказались имплементить эту фичу :(
мне как то коменты программистов не сильно помогали но однажды чинил один сайт и там не работал календарь в коде шел комментарий
// эта промухаблядская штука перестала работать, заменил 1 на 2 и теперь ок
$i = 2;
оказалось там была проблемам с выкосоным годом
// эта промухаблядская штука перестала работать, заменил 1 на 2 и теперь ок
$i = 2;
оказалось там была проблемам с выкосоным годом
Иногда мне кажется, что компилятор игнорирует все мои комментарии
В первой, сырой версии, комментарии конечно же полезны.
После рефакторинга комментарии ни к чему. Замечу обратное — необходимость в комментариях скорее свидетельствует о необходимости в рефакторинге. Если дизайн кода настолько плох, что нуждается в пояснениях — очевидно, его можно улучшать.
Кстати, комментарии хороши на отдельных строчках — они так кроссIDEшнее сворачиваются.
После рефакторинга комментарии ни к чему. Замечу обратное — необходимость в комментариях скорее свидетельствует о необходимости в рефакторинге. Если дизайн кода настолько плох, что нуждается в пояснениях — очевидно, его можно улучшать.
Кстати, комментарии хороши на отдельных строчках — они так кроссIDEшнее сворачиваются.
Действительно острая тема. Мое мнение на этот счет такое:
Отсутствие комментариев в коде не показатель его качества.
Читаемость и понятность кода при отсутствии комментариев — свидетельствует о качественном коде.
Код писать надо так, чтобы потребность в комментариях была минимальной. Комментарии должны пояснять совсем не очевидные вещи и способствовать ускорению понимания кода.
Если код не читается, то он просто не читается. И это плохой код, требующий переработки.
Отсутствие комментариев в коде не показатель его качества.
Читаемость и понятность кода при отсутствии комментариев — свидетельствует о качественном коде.
Код писать надо так, чтобы потребность в комментариях была минимальной. Комментарии должны пояснять совсем не очевидные вещи и способствовать ускорению понимания кода.
Если код не читается, то он просто не читается. И это плохой код, требующий переработки.
Всем ярым любителям не писать никаких комментариев предлагаю взять любой большой, хорошо написанный проект, удалить из кода все комментарии, любезно оставленные разработчиками, а затем разобраться в нём. Можно попробовать начать с Numpy. :)
Бесполезные, неверные, запутывающие комментарии не нужны. Полезные комментарии нужны. О чём тут ещё спорить? Не понимаю. То же самое можно сказать про документацию в целом.
Бесполезные, неверные, запутывающие комментарии не нужны. Полезные комментарии нужны. О чём тут ещё спорить? Не понимаю. То же самое можно сказать про документацию в целом.
Открыв пару файлов и увидел ужасное наименование функций и полей. Тут да, комментарии нужны. Да, и может я, что-то не понял, но проект совсем не большой.
Проект нормальный по размеру. www.ohloh.net/p/numpy
Именование функций и полей такое, потому что проект пишут математики. Ну, сами понимаете. :)
Хорошо, вот какой-то кусочек кода. Переменные тут названы не лучшим образом, да и вообще… Как вы считаете, нужны комментарии или хватит описательных имён переменных и рефакторинга? Если считаете, что комментарии не нужны, скажите, почему так обрабатывается исключение LinAlgError, и что это означает в данном случае. Можете сказать, что делает данный код, просто прочитав его?
Именование функций и полей такое, потому что проект пишут математики. Ну, сами понимаете. :)
Хорошо, вот какой-то кусочек кода. Переменные тут названы не лучшим образом, да и вообще… Как вы считаете, нужны комментарии или хватит описательных имён переменных и рефакторинга? Если считаете, что комментарии не нужны, скажите, почему так обрабатывается исключение LinAlgError, и что это означает в данном случае. Можете сказать, что делает данный код, просто прочитав его?
Скрытый текст
def intersect_solve(self, i, j, x2=None, y2=None):
self_intersect = x2 is None
x1, y1 = self.__x, self.__y
xy1 = np.dstack((x1, y1)).squeeze()
xy2 = xy1
dxy1 = np.diff(xy1, axis=0)
if self_intersect:
x2, y2 = x1, y1
dxy2 = dxy1
is_nans = (np.isnan(np.sum(dxy1[i, :] + dxy2[j, :], axis=1)))
else:
xy2 = np.dstack((x2, y2)).squeeze()
dxy2 = np.diff(xy2, axis=0)
is_nans = np.isnan(np.sum(dxy1[i, :] + dxy2[j, :], axis=1))
remove = np.flatnonzero(is_nans)
i = np.delete(i, remove)
j = np.delete(j, remove)
n = i.size
t = np.zeros((4, n))
a = np.zeros((4, 4))
a[(0, 1, 2, 3), (2, 2, 3, 3)] = -1
b = -np.dstack((x1[i], x2[j], y1[i], y2[j])).squeeze().transpose()
if n == 1:
b = b.reshape((b.size, 1))
anomalous = np.zeros(n, dtype=np.bool)
eps = np.finfo(np.float64).eps
for k in xrange(0, n):
a[(0, 2), (0, 0)] = dxy1[i[k], :]
a[(1, 3), (1, 1)] = dxy2[j[k], :]
try:
t[:, k] = linalg.solve(a, b[:, k])
except linalg.LinAlgError:
if self_intersect:
t[:, k] = np.nan
else:
t[0, k] = np.nan
v = (dxy1[i[k], :], xy2[j[k], :] - xy1[i[k], :])
m = np.vstack(v).squeeze()
try:
cond = np.array(np.linalg.cond(m, p=1), ndmin=2)
anomalous[k] = (linalg.inv(cond).squeeze() < eps)
except linalg.LinAlgError:
anomalous[k] = True
if self_intersect:
anomalous = np.any(np.isnan(t), axis=0)
return i, j, t, anomalous
Не видя, что делает функция np.diff, понять трудно. Видно, что считаются пересечения каких-то двумерных отрезков или прямых (проверок на 0<=t[0,k]<=1 не видно), исключение отрабатывает случай параллельных отрезков (проверяет, лежат ли они на одной прямой?). Думаю, что если смотреть не только на эту функцию, но и слегка погулять по проекту, комментарии будут не нужны. И, конечно, надо хоть немного знать язык, на котором это написано: у меня 75% времени ушло на то, чтобы догадаться, что делает конструкция a[(0, 1, 2, 3), (2, 2, 3, 3)] = -1 и ей подобные. А что такое squeeze() и transpose(), я так и не понял.
Тут считается пересечение двух кривых на плоскости (или одной кривой с самой собой), заданных множеством координат точек. Всё верно, исключение отрабатывает в случае перекрытия отрезков.
Конечно нужно знать особенности языка. Но вы даже без знания языка поняли суть. Это говорит о вашем опыте и математическом бэкграунде. А новичок мог бы не разобраться без комментариев. :)
Конечно нужно знать особенности языка. Но вы даже без знания языка поняли суть. Это говорит о вашем опыте и математическом бэкграунде. А новичок мог бы не разобраться без комментариев. :)
Назвали ли бы, что-то типа
curve_intersection_solving, и даже новичку гадать не пришлось. Эта функция из одного проекта, с которым мне пришлось работать. Функция делает только часть работы в дебрях какого-то класса. Верхняя функция называется как-то подобно вашему предложению. Просто зачастую даже если известно, что делается и для чего, не всегда понятно почему это делается именно так, приходится разбираться. Особенно, когда надо оптимизировать производительность или найти закравшуюся ошибку. Комментарии в этом случае помогают, если они толковые, конечно.
По поводу «почему делается именно так» действительно много вопросов. Зачем ей передавать все пары отрезков, которые надо сравнивать? Неужели возникает ситуация, когда сравниваются какие-то выборочные пары, а не все отрезки фрагмента одной кривой со всеми отрезками фрагмента другой (фрагменты не обязательно непрерывные), или все пары различных отрезков фрагмента одной кривой? Зачем возвращать все пересечения всех пар касательных, если нужны только точки пересечения самих кривых? Почему бы не выбрасывать точки, лежащие за пределами одного или другого отрезка прямо в функции? Зачем для пересечения отрезков использовать линейную алгебру? Оно прекрасно ищется за 7 строчек безо всяких матриц.
Наверное, для обоснования такого выбора реализации комментарии были бы в самом деле полезны.
Наверное, для обоснования такого выбора реализации комментарии были бы в самом деле полезны.
Вот конкретный случай когда коментария лучше бы не было вообще.
В файле ResourceFontFileLoader.cpp
а в galaxy far far away ( ResourceFontFileLoader.h ) этот самый instance_ выглядит так:
Долго искал почему ресурс не освобождается. В коментах мечталось про «smart pointer» что я на веру и принял… То что это просто pointer выяснилось после какого-то количесва нервов и времени.
В файле ResourceFontFileLoader.cpp
// Smart pointer to singleton instance of the font file loader.
IDWriteFontFileLoader* ResourceFontFileLoader::instance_(
new(std::nothrow) ResourceFontFileLoader()
);
а в galaxy far far away ( ResourceFontFileLoader.h ) этот самый instance_ выглядит так:
static IDWriteFontFileLoader* instance_;
Долго искал почему ресурс не освобождается. В коментах мечталось про «smart pointer» что я на веру и принял… То что это просто pointer выяснилось после какого-то количесва нервов и времени.
«настоящие индейцы комментариев не пишут»
симметрично к
«настоящие индейцы документацию не читают»
симметрично к
«настоящие индейцы документацию не читают»
Наиболее ценный коментарий описывает то, чего в коде нет.
Для меня комментарии обязательны. Когда решаешь какую-то задачу, то тратишь время на её анализ, а комментарии помогают в будущем, когда понадобиться внести в задачу изменения/дополнения, сократить сложность повторного анализа. И очень удобно оставлять @ todo на будущее — а вдруг появятся свободные 10 минут или возможность между задачами ощущение победоносной паузы занять выполнением одного @ todo?
А по хорошему коду скажу так: часто испытываешь ощущение грамотно выполненной задачи; но это не сравнимо с тем, что испытываешь, когда имеешь возможность самого себя поймать на какой-то ошибке (от совсем простой до не удачного алгоритма). Бывает, что это происходит в момент написании комментария, и рождается @ todo. В общем, нет ничего совершенного. И надо уметь это признавать.
А по хорошему коду скажу так: часто испытываешь ощущение грамотно выполненной задачи; но это не сравнимо с тем, что испытываешь, когда имеешь возможность самого себя поймать на какой-то ошибке (от совсем простой до не удачного алгоритма). Бывает, что это происходит в момент написании комментария, и рождается @ todo. В общем, нет ничего совершенного. И надо уметь это признавать.
Мне кажется, что здесь важен момент необходимой достаточности. Так комментировать каждую строчку кода в 99,9% случаев не обязательно. Но и комменты, которые описывают важные части кода или определённую специфику не будут лишними.
Содержание комментария в коде — это свободная форма, поэтому жёстких требований к написанию комментариев нет. И они всегда остаются на усмотрение кодера.
Все комменты по делу? Иногда забавно встретить комментарий вида: «Если ты читаешь это сообщение, то ты в полной за*нице!..». А я в то время, как раз об этом и задумался :-)
Итог: не несущие полезной информации и излишние
комментарии в коде могут быть показателем плохого кода.
P.S. считаю, что в первую очередь, плохой код — это код, который не выполняет поставленную задачу.
Содержание комментария в коде — это свободная форма, поэтому жёстких требований к написанию комментариев нет. И они всегда остаются на усмотрение кодера.
Все комменты по делу? Иногда забавно встретить комментарий вида: «Если ты читаешь это сообщение, то ты в полной за*нице!..». А я в то время, как раз об этом и задумался :-)
Итог: не несущие полезной информации и излишние
комментарии в коде могут быть показателем плохого кода.
P.S. считаю, что в первую очередь, плохой код — это код, который не выполняет поставленную задачу.
Все хочется спросить у противников комментариев, как же поступать в подобных случаях?
//deprecated use methodB(...)
public void methodA(...)
Я бы постарался впихнуть туда код который будет генерировать compilation warning в месте которое пытается использовать deprecated код.
Стандартного портабельного решения там, правда, к сожалению нет.
Стандартного портабельного решения там, правда, к сожалению нет.
Добавить в метод код генерирующий compilation warning, но при этом не имеющим отношения к происходящему внутри метода… О_О отличное повышение читабельности кода.
Или вы же просто добавите что-то типа аннотации java (@deprecated) — но это же комментарий, а не код.
Или вы же просто добавите что-то типа аннотации java (@deprecated) — но это же комментарий, а не код.
Это же deprecated код, предполагается что он уже не поддерживается и должен быть в недалеком будущем выкинут — зачем заботиться о его читаемости? Меня куда больше волнует качество того кода который остается. Выдача предупреждения поможет оперативно выявить все места где используется deprecated метод и избежать появления новых.
Основная проблема — портируемость, так-то с читаемостью все не очень плохо получается. В vc++ например в объявление ф-и или класса просто добавляется __declspec(deprecated).
Основная проблема — портируемость, так-то с читаемостью все не очень плохо получается. В vc++ например в объявление ф-и или класса просто добавляется __declspec(deprecated).
Довольно интересная тема. Однако я для себя никаких правил по поводу комментариев никогда не вводил — просто пишу их там, где кусок кода сложен для понимания, или там, где это понимание может исчезнуть через недельку другую. Но вот когда работаешь не один — безусловно приходится единого стиля придерживаться.
Судя по тому, что вы отрыли такие кавычки, оформление текста вам должно быть небезразлично. Будьте последовательны и не используйте эти кавычки при написании текстов на русском языке.
Sign up to leave a comment.
Почему [не]нужно комментировать код