Знаете…
Я прямо сейчас реализую случайный лес на «Си с крестами». Уже показывает неплохие результаты, идёт настройка и доводка.
На одной из презентаций по случайному лесу была фотография… ну, обычного себе леса. Я и подумал: а почему он обычный, когда лучше было бы «пьяный лес»? Загуглил я картинки — и вместо северного «пьяного леса» увидел ваш калининградский «танцующий». Ну, классно, подумал, эта картинка даже больше походит на случайный лес! И тут вы появились…
По делу: а знаете, что индекс Джини можно пересчитывать инкрементально, так что проход по массиву в поисках оптимальной точки разбиения стоит O(n log n) времени?
Сортируем массив по возрастанию переменной. Поскольку случайные деревья и без того перетасовывают объекты, я использовал
struct Case
{
const double* input;
size_t target;
}
Пусть K — множество классов.
Критерий качества разбиения — sum[k in K] N[k less]² / N[less] + sum [k in K] N[k greater]² / N[greater], больше=лучше.
Держим такие числа: sum [k in K] N[k less]², N[k less] для всех k, и N[less]. Ну и то же самое для greater. Для начала высчитаем его для случая, когда все точки в greater.
Предположим, что одна точка из класса k перешла из greater в less. Тогда…
N(k less + 1)² = N(k less)² + 2N(k less) + 1. А значит, sum[k in K] N[k less]² := sum [k in K] N[k less]² + 2N[k less] + 1
С N[k less] всё понятно, N[k less] := N[k less] + 1
И, разумеется, N[less] := N[less] + 1
Статья великолепно описывает суть, но… я бы не советовал пользоваться «шустрой» реализацией приведенной по ссылке и вообще ее использовать. Код в стиле спагетти и шустростью там не пахнет… тонны ненужных циклов, которые можно свернуть добавлением пары строк без if в предыдущий цикл, либо в которых известно количество шагов, но используется do-while; неоправданное вычисление каждый раз arccos от двух мульти-пространственных векторов (норму векторов уж можно и сохранять, зачем лишний раз делать n*m операций когда можно просто n); читабельность в познавательных целях отсутствует напрочь.
круто, добавлю, тот код по ссылке действительно трудно понять -) но плз удали от туда папку бин и обж, почти у всех браузер или фаервол будет ругаться, что там икзешники, при скачивании зипа целиком
Простите, мне кажется, что вы ошибочно упомянули кросс-энтропию.
К тому же приведена формула энтропии.
Смысл кросс-энтропии в мере «похожести» распределений, она является аналогом (а точнее родственницей) дивергенции Кульбака-Лейблера.
дело трактовки, я не считаю это ошибкой, кросс-энтропия задается как
ничто не мешает мне подавать в формулу кросс-энтропии одинаковые распределения, да формально это выродится в информационную энтропию, но не перестанет быть и перекрестной энтропией, просто в случае p = q
например в книге An Introduction to Statistical Learning авторы в главе про деревья на странице 312 в формуле 8.7 называют
кросс-энтропией и не парятся по этому поводу
Дело в том, что кросс-энтропия как раз вводится для того, чтобы оценить ошибку, возникающую при замене одного распределения («истинного») на другое «подгоночное», как комплексная мера соответствия распределений.
И тогда если подать в два параметра кросс-энтропии одно и то же распределение, то её смысл исчезает.
Это всё равно, что вводить мерой отличия для коллинеарных векторов скалярное произведение.
Кросс-энтропия часто определяется как обычная энтропия с добавочкой КЛ дивергенции.
В случае одного и того же распределения КЛ дивергенция вообще становится бессмысленной и, разумеется, становится равной нулю.
Можно, конечно, поспорить (хотя с авторитетными уважаемыми авторами книги сложно), просто глаз режет, когда применяется не там.
Давайте я заберу слово «ошибочно» и вместо него скажем «нецелесообразно» :)
Спасибо за статью, особенно за обоснование bagging'а и декорреляции.
Также, пользуясь случаем немного попиарюсь :-) Раньше писал небольшую либу на JS и демку того, как работают деревья и лес принятия решений: habrahabr.ru/post/208952/


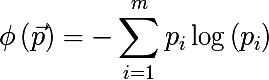
Модель Random Forest для классификации, реализация на c#