Уже пару раз на Хабре возникали дискуссии на тему того, как сейчас работает распознавание номеров. Но статьи, где были бы показаны разные подходы к распознаванию номеров, на Хабре пока не было. Так что здесь попробуем разобраться, как все это работает. А потом, если статья вызовет интерес, продолжим и выложим работающую модель, которую можно будет поисследовать.

Один из ключевых параметров для создания системы распознавания — используемое железо для фотосъёмки. Чем мощнее и лучше система освещения, чем лучше камера, тем больше шансов распознать номер. Хороший инфракрасный (ИК) прожектор может просветить даже пыль и грязь, имеющуюся на номере, затмить все мешающие факторы. Думаю, кому-нибудь приходило аналогичное «письмо счастья», где кроме номера ничего не видно.

Чем лучше система съёмки — тем надежнее результат. Лучший алгоритм без хорошей системы съёмки бесполезен: всегда можно найти номер, который не распознается. Вот два совсем разных кадра:

В данной статье рассматривается именно программная часть, причём упор делается именно на случай, когда номер видно плохо и с искажениями (просто снят «с рук» любой камерой).
• Предварительный поиск номера – обнаружение области в которой содержится номер
• Нормализация номера – определение точных границ номера, нормализация констраста
• Распознавание текста – чтение всего что нашлось в нормализованном изображении
Это базовая структура. Конечно, в ситуации, когда номер линейно расположен и хорошо освещён, а у Вас в распоряжение отличный алгоритм распознавания текста, первые два пункта отпадут. В некоторых алгоритмах могут объединяться поиск номера и его нормализация.
Самый очевидный способ выделения номера – поиск прямоугольного контура. Работает только в ситуациях когда есть ясно читаемый контур, ничем не загороженный, с достаточно высоким разрешением и с ровной границей.


Производится фильтрация изображения для нахождения границ после чего производится выделение всех найденных контуров и их анализ . Почти все студенческие работы с обработкой изображений делаются именно таким образом. Примеров в инете полно . Работает плохо, но хоть как-то.
Куда интереснее, стабильнее и практичнее представляется подход , где от рамки анализируется только её часть. Выделяются контуры, после чего ищутся все вертикальные прямые. Для любых двух прямых, расположенных недалеко друг от друга, с небольшим сдвигом по оси y, с правильным отношением расстояния между ними к их длине, рассматривается гипотеза того, что номер располагается между ними. По сути, такой подход похож на упрощённый метод HOG .
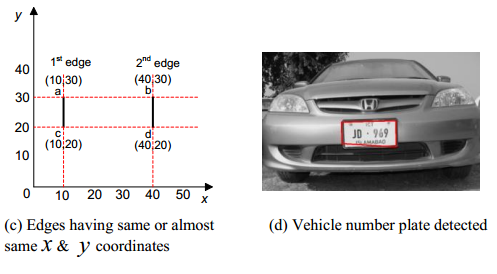
Одним из самых популярных методов подхода является анализ гистограмм изображения (1,2). Подход основывается на предположении, что частотная характеристика региона с номером отлична от частотной характеристики окрестности.


На изображении выделяются границы (выделение высокочастотных пространственных компонент изображения). Строится проекция изображения на ось y (иногда и на ось x). Максимум полученной проекции может совпасть с расположением номера.
У такого подхода есть существенный минус – машина по размеру должна быть сопоставима с размером кадра, т. к. фон может содержать надписи или другие детализированные объекты.
В чём минус всех предыдущих методов? В том, что на реальных, запачканных грязью номерах нет ни выраженных границ, ни выраженной статистики. Снизу приведено пару примеров таких номеров. И, надо сказать, для Москвы такие примеры не являются самыми плохими вариантами.


Лучшие методы, хотя и недостаточно часто используемые, это методы, опирающиеся на различные классификаторы. Например, хорошо работает обученный каскад Хаара. Эти методы позволяют анализировать область на предмет наличия в ней характерных для номера отношений, точек или градиентов. Наиболее красивым мне кажется метод, основанный на специально синтезированном преобразовании. Правда, я его не опробовал, но, на первый взгляд, должно устойчиво работать.
Такие методы позволяют находить не просто номер, а номер в сложных и нетипичных условиях. Тот же каскад Хаара для базы, собранной зимой в центре Москвы выдавал порядка 90% правильных обнаружений номера и 2-3% ложного захвата. Ни один алгоритм обнаружения границ или гистограмм не может выдать такое качество обнаружение по настолько плохим картинкам.
Многие методы в реальных алгоритмах прямо или косвенно опираются на наличие границ номера. Даже если границы не используются при детектировании номера, то могут использоваться в дальнейшем анализе.
Неожиданно, но для статистических алгоритмов сложным случаем может оказаться даже относительно чистый номер в хромированной (светлой) рамке на белой машине, так как оно встречается куда реже грязных номеров и может не встретиться достаточное количество раз при обучении.
Большинство указанных выше алгоритмов обнаруживают номер не точно и требуют дальнейшего уточнения его положения, а также улучшение качества снимка. Например, в данном случае требуется поворот и обрезка краёв:

Когда оставлена только окрестность номера, выделение границ начинает работать значительно лучше, так как все длинные горизонтальные прямые, которые удалось выделить — это и будут границы номера.
Самый простой фильтр, способный выделить такие прямые – преобразование Хафа:

Преобразование Хаффа позволяет очень быстро выделить две главных прямых и обрезать по ним изображение:

И лучше тем или иным способом улучшить контрастность получившегося изображения. Строго говоря, нужно усилить интересующую нас область пространственных частот:

После поворота имеем горизонтальный номер с неточно определёнными левыми и правыми краями. Точно отрезать лишнее теперь не обязательно, достаточно просто нарезать имеющиеся в номере буквы и работать при распознавании с ними.
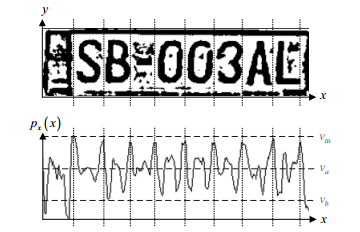
(На рисунке уже проведена операция бинаризации, т. е. использовано какое-то правило разделения пикселей на два класса. При разделении номера на символы эта операция вовсе не обязательна, а в дальнейшем может оказаться и вредной).
Теперь достаточно найти максимумы горизонтальной диаграммы, это и будут промежутки буквами. Особенно если мы ожидаем определенное количество знаков и расстояние между знаками будет примерно одинаковое, то разбиение на буквы по гистограмме сработает отлично.
Остаётся только вырезать имеющиеся буквы и перейти в процедуре их распознавания.
При значительном загрязнении номера периодические максимумы при разбиении на символы могут просто не проявиться, хотя сами символы могут быть визуально вполне читаемы.
Горизонтальные граница номера — не всегда хороший ориентир. Номера могут быть изогнуты штатно (Mercedes C-класса), могут быть бережно утоплены в неподходящее почти квадратное углубление для номера на американских машинах. А верхняя граница заднего номера просто часто прикрыта элементами кузова.
Естественно, учитывать все подобные проблемы — это и есть задача для серьезных систем распознавания номеров.
Задача распознавания текста или отдельных символов (optical character recognition, OCR) с одной стороны сложная, а с другой — вполне классическая. Существует множество алгоритмов её решения, некоторые из которых достигли совершенства. Но, с другой стороны, самых лучших алгоритмов в открытом доступе нет. Есть, конечно Tesseract OCR и несколько его аналогов, но эти алгоритмы не решают всех задач. В целом, методы распознавания текста можно разбить на два класса: структурные методы основанные на морфологии и анализе контура, имеющие дело с бинаризованным изображением, и растровые методы, основанные на анализе непосредственного изображения. При этом зачастую используется комбинация структурных и растровых методов
Во-первых, во всяком случая в России, в автомобильных номерах используется стандартный шрифт. Это просто подарок для автоматической системы распознавания знаков. 90% усилий в области OCR тратится на рукописный текст.
Во-вторых, грязь.
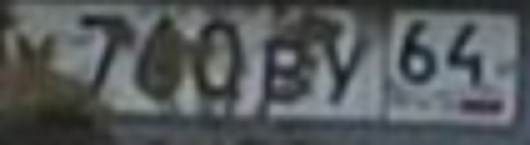
Вот тут то и приходится выбросить абсолютное большинство известных методов распознавания символов, особенно если по пути изображение бинаризуется для проверки связанности областей, разделения символов.
Это открытое программное обеспечение, выполняющее автоматическое распознавание как единичной буквы, так и сразу текста. Tesseract удобен тем, что есть для любых ОС, стабильно работает и легко обучаем. Но он очень плохо работает с замыленным, битым, грязным и деформированным текстом. Когда я попробовал сделать на нём распознавание номеров – от силы лишь 20-30% номеров из базы распознались правильно. Самые чистые и прямые. Хотя, конечно, и при использовании готовых библиотек что-то зависит от радиуса кривизны рук.
Очень простой для понимания метод распознавания символов, который, несмотря на свою примитивность, часто может побеждать не самые удачные реализации SVM или нейросетевых методов.
Работает он следующим образом:
1) предварительно записываем приличное количество изображений реальных символов уже корректно разбитые на классы своими глазами и руками
2) вводим меру расстояния между символами (если изображение бинаризованно, то операция XOR будет оптимальна)
3) затем, когда мы пытаемся распознать символ, поочередно рассчитываем дистанцию между ним и всеми символами в базе. Среди k ближайших соседей, возможно, будут представители различных классов. Естественно, представителей какого класса больше среди соседей, к тому классу стоит отнести распознаваемый символ.
В теории, если записать очень большую базу с примерами символов, снятых под разными углами, освещением, со всеми возможными потертостями, то K-nearest — это все, что нужно. Но тогда нужно очень быстро рассчитывать дистанцию между изображениями, а, значит, бинаризовать его и использовать XOR. Но тогда именно в случае с загрязненными или потертыми номерами будут проблемы. Бинаризация совершенно непредсказуемо изменяет символ.
У метода есть одно очень важное преимущество: он простой и прозрачный, а значит легко отлаживается и настраиваться на оптимальный результат. Во многих случаях очень важно понимать, как работает ваш алгоритм.
Часто методы, которые используются в распознавании изображений, построены на эмпирических подходах. Но никто не запрещает использовать математический аппарат теории вероятности, который был просто отполирован в задачах детектирования сигнала в радиолокационных системах. Шрифт на автомобильном номере нам известен, шум фотокамеры или пыль на номере можно с натяжкой назвать гауссовским. Существует некоторая неопределенность по расположению символа и его наклону, но эти параметры можно перебрать. Если мы оставляем изображение не бинаризованным, то нам еще неизвестна и амплитуда сигнала, т. е. яркость символа.
Очень не хочется вдаваться в строгое решение этой задачи в рамках статьи. По сути все-равно все сводится к операции расчета ковариации входного сигнала с гипотетическим (с учетом заданных смещений и поворотов):
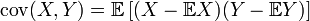
X – входной сигнал, Y – гипотеза. Обозначение E – математическое ожидание.
Если нужно выбрать из разных символов, то гипотезы по повороту и смещению строятся для каждого символа. Если мы точно знаем, что входное изображение содержит символ, то максимум ковариации по всем гипотезам определит символ, его смещение и наклон. Тут, конечно, встает проблема близости изображений различных символов («р» и «в», «о» и «с» и др.). Самое простое — ввести для каждого символа весовую матрицу коэффициентов.
Иногда такие методы называются «template-matching», что полностью отражает их суть. Задаем образцы — сравниваем входное изображение с образцами. Если есть какая-то неопределенность по параметрам, то, либо перебираем все возможные варианты, либо используем адаптивные подходы, правда тут уже знать и понимать математику придется.
Достоинства метода:
— предсказуемый и хорошо изученный результат, если шум хоть немного соответствует выбранной модели;
— если шрифт задан строго, как в нашем случае, то способен разглядеть сильно пыльный/грязный/потертый символ.
Недостатки:
— вычислительно весьма затратный.

Про искусственные нейросети на Хабре было уже написано очень много. Сейчас их принято разделять на два поколения:
— классические 2-3х-слойные нейросети, обучающиеся градиентными методами с обратным распространением ошибок (3х-слойная нейросеть изображена на рисунке);
— так называемые deep-learning нейросети и сверточные сети.
Второе поколение нейросетей уже последние лет 7 побеждают на разных соревнованиях по распознаванию изображений, выдавая результат несколько лучший, чем остальные методы.
Существует открытая база изображений рукописных цифр. Таблица результатов очень наглядно демонстрирует эволюцию различных методов, в том числе и алгоритмов на основе нейросетей.
Также стоит отдельно отметить, что для печатных шрифтов прекрасно работают простейшая однослойная или двухслойная (вопрос терминологии) сеть , которая по своей сути ничем не отличается от template-matching подходов.
Достоинства метода:
— при правильной настройке и обучении может работать лучше других известных методов;
— при большом обучающем массиве данных устойчив к искажения символов.
Недостатки:
— наиболее сложный для описанных методов;
— диагностика аномального поведения в многослойных сетях попросту невозможна.
В статье были рассмотрены базовые методы распознавания, их типичные глюки и ошибки. Возможно, это поможет вам сделать свой номер чуть более читаемым при поездках по городу, или наоборот.
Еще я надеюсь, что удалось показать полное отсутствие магии в задаче распознавания номеров. Все абсолютно понятно и интуитивно. Совершенно не страшная задача для курсовой работы студента по соответствующей специальности.
А еще через несколько дней ZlodeiBaal выложит небольшую распознавалку по номерам, по мотивам нашей работы над которой была написана эта статья. Ее можно будет мучить.
З.Ы. Все номера, которые приведены в статье — добыты из Гугла и Яндекса простыми запросами
1) ALGORITHMIC AND MATHEMATICAL PRINCIPLES OF AUTOMATIC NUMBER PLATE RECOGNITION SYSTEMS ONDREJ MARTINSKY – обзорная статья.
2) A Real-Time Mobile Vehicle License Plate Detection and Recognition Kuo-Ming Hung and Ching-Tang Hsieh –гистограммный подход при распознавании номеров
3) Robust License Plate Detection Using Covariance Descriptor in a Neural Network Framework Fatih Porikli, Tekin Kocak – нейросетевой подход при поиске номера
4) Automated Number Plate Recognition Using Hough Lines and Template Matching Saqib Rasheed, Asad Naeem and Omer Ishaq – поиск номеров через HOG-дескрипторы вертикальных линий
5) Survey of Methods for Character Recognition Suruchi G. Dedgaonkar, Anjali A. Chandavale, Ashok M. Sapkal – небольшая обзорная статья про распознавание буков и цифр
7) Учебное пособие «Основа теории обработки изображений», Крашенинников В. Р.
Софт VS Железо
Один из ключевых параметров для создания системы распознавания — используемое железо для фотосъёмки. Чем мощнее и лучше система освещения, чем лучше камера, тем больше шансов распознать номер. Хороший инфракрасный (ИК) прожектор может просветить даже пыль и грязь, имеющуюся на номере, затмить все мешающие факторы. Думаю, кому-нибудь приходило аналогичное «письмо счастья», где кроме номера ничего не видно.
Чем лучше система съёмки — тем надежнее результат. Лучший алгоритм без хорошей системы съёмки бесполезен: всегда можно найти номер, который не распознается. Вот два совсем разных кадра:
В данной статье рассматривается именно программная часть, причём упор делается именно на случай, когда номер видно плохо и с искажениями (просто снят «с рук» любой камерой).
Структура алгоритма
• Предварительный поиск номера – обнаружение области в которой содержится номер
• Нормализация номера – определение точных границ номера, нормализация констраста
• Распознавание текста – чтение всего что нашлось в нормализованном изображении
Это базовая структура. Конечно, в ситуации, когда номер линейно расположен и хорошо освещён, а у Вас в распоряжение отличный алгоритм распознавания текста, первые два пункта отпадут. В некоторых алгоритмах могут объединяться поиск номера и его нормализация.
Часть 1: алгоритмы предварительного поиска
Анализ границ и фигур, контурный анализ
Самый очевидный способ выделения номера – поиск прямоугольного контура. Работает только в ситуациях когда есть ясно читаемый контур, ничем не загороженный, с достаточно высоким разрешением и с ровной границей.
Производится фильтрация изображения для нахождения границ после чего производится выделение всех найденных контуров и их анализ . Почти все студенческие работы с обработкой изображений делаются именно таким образом. Примеров в инете полно . Работает плохо, но хоть как-то.
Анализ только части границ
Куда интереснее, стабильнее и практичнее представляется подход , где от рамки анализируется только её часть. Выделяются контуры, после чего ищутся все вертикальные прямые. Для любых двух прямых, расположенных недалеко друг от друга, с небольшим сдвигом по оси y, с правильным отношением расстояния между ними к их длине, рассматривается гипотеза того, что номер располагается между ними. По сути, такой подход похож на упрощённый метод HOG .
Гистограммный анализ регионов
Одним из самых популярных методов подхода является анализ гистограмм изображения (1,2). Подход основывается на предположении, что частотная характеристика региона с номером отлична от частотной характеристики окрестности.
На изображении выделяются границы (выделение высокочастотных пространственных компонент изображения). Строится проекция изображения на ось y (иногда и на ось x). Максимум полученной проекции может совпасть с расположением номера.
У такого подхода есть существенный минус – машина по размеру должна быть сопоставима с размером кадра, т. к. фон может содержать надписи или другие детализированные объекты.
Статистический анализ, классификаторы
В чём минус всех предыдущих методов? В том, что на реальных, запачканных грязью номерах нет ни выраженных границ, ни выраженной статистики. Снизу приведено пару примеров таких номеров. И, надо сказать, для Москвы такие примеры не являются самыми плохими вариантами.
Лучшие методы, хотя и недостаточно часто используемые, это методы, опирающиеся на различные классификаторы. Например, хорошо работает обученный каскад Хаара. Эти методы позволяют анализировать область на предмет наличия в ней характерных для номера отношений, точек или градиентов. Наиболее красивым мне кажется метод, основанный на специально синтезированном преобразовании. Правда, я его не опробовал, но, на первый взгляд, должно устойчиво работать.
Такие методы позволяют находить не просто номер, а номер в сложных и нетипичных условиях. Тот же каскад Хаара для базы, собранной зимой в центре Москвы выдавал порядка 90% правильных обнаружений номера и 2-3% ложного захвата. Ни один алгоритм обнаружения границ или гистограмм не может выдать такое качество обнаружение по настолько плохим картинкам.
Слабое место
Многие методы в реальных алгоритмах прямо или косвенно опираются на наличие границ номера. Даже если границы не используются при детектировании номера, то могут использоваться в дальнейшем анализе.
Неожиданно, но для статистических алгоритмов сложным случаем может оказаться даже относительно чистый номер в хромированной (светлой) рамке на белой машине, так как оно встречается куда реже грязных номеров и может не встретиться достаточное количество раз при обучении.
Часть 2: алгоритмы нормализации
Большинство указанных выше алгоритмов обнаруживают номер не точно и требуют дальнейшего уточнения его положения, а также улучшение качества снимка. Например, в данном случае требуется поворот и обрезка краёв:
Поворот номера в горизонтальную ориентацию
Когда оставлена только окрестность номера, выделение границ начинает работать значительно лучше, так как все длинные горизонтальные прямые, которые удалось выделить — это и будут границы номера.
Самый простой фильтр, способный выделить такие прямые – преобразование Хафа:
Преобразование Хаффа позволяет очень быстро выделить две главных прямых и обрезать по ним изображение:
Увеличение контраста
И лучше тем или иным способом улучшить контрастность получившегося изображения. Строго говоря, нужно усилить интересующую нас область пространственных частот:
Разбиение на буквы
После поворота имеем горизонтальный номер с неточно определёнными левыми и правыми краями. Точно отрезать лишнее теперь не обязательно, достаточно просто нарезать имеющиеся в номере буквы и работать при распознавании с ними.
(На рисунке уже проведена операция бинаризации, т. е. использовано какое-то правило разделения пикселей на два класса. При разделении номера на символы эта операция вовсе не обязательна, а в дальнейшем может оказаться и вредной).
Теперь достаточно найти максимумы горизонтальной диаграммы, это и будут промежутки буквами. Особенно если мы ожидаем определенное количество знаков и расстояние между знаками будет примерно одинаковое, то разбиение на буквы по гистограмме сработает отлично.
Остаётся только вырезать имеющиеся буквы и перейти в процедуре их распознавания.
Слабые места
При значительном загрязнении номера периодические максимумы при разбиении на символы могут просто не проявиться, хотя сами символы могут быть визуально вполне читаемы.
Горизонтальные граница номера — не всегда хороший ориентир. Номера могут быть изогнуты штатно (Mercedes C-класса), могут быть бережно утоплены в неподходящее почти квадратное углубление для номера на американских машинах. А верхняя граница заднего номера просто часто прикрыта элементами кузова.
Естественно, учитывать все подобные проблемы — это и есть задача для серьезных систем распознавания номеров.
Часть 3: алгоритмы распознавания символов
Задача распознавания текста или отдельных символов (optical character recognition, OCR) с одной стороны сложная, а с другой — вполне классическая. Существует множество алгоритмов её решения, некоторые из которых достигли совершенства. Но, с другой стороны, самых лучших алгоритмов в открытом доступе нет. Есть, конечно Tesseract OCR и несколько его аналогов, но эти алгоритмы не решают всех задач. В целом, методы распознавания текста можно разбить на два класса: структурные методы основанные на морфологии и анализе контура, имеющие дело с бинаризованным изображением, и растровые методы, основанные на анализе непосредственного изображения. При этом зачастую используется комбинация структурных и растровых методов
Отличия от стандартной задачи OCR
Во-первых, во всяком случая в России, в автомобильных номерах используется стандартный шрифт. Это просто подарок для автоматической системы распознавания знаков. 90% усилий в области OCR тратится на рукописный текст.
Во-вторых, грязь.
Вот тут то и приходится выбросить абсолютное большинство известных методов распознавания символов, особенно если по пути изображение бинаризуется для проверки связанности областей, разделения символов.
Tesseract OCR
Это открытое программное обеспечение, выполняющее автоматическое распознавание как единичной буквы, так и сразу текста. Tesseract удобен тем, что есть для любых ОС, стабильно работает и легко обучаем. Но он очень плохо работает с замыленным, битым, грязным и деформированным текстом. Когда я попробовал сделать на нём распознавание номеров – от силы лишь 20-30% номеров из базы распознались правильно. Самые чистые и прямые. Хотя, конечно, и при использовании готовых библиотек что-то зависит от радиуса кривизны рук.
K-nearest
Очень простой для понимания метод распознавания символов, который, несмотря на свою примитивность, часто может побеждать не самые удачные реализации SVM или нейросетевых методов.
Работает он следующим образом:
1) предварительно записываем приличное количество изображений реальных символов уже корректно разбитые на классы своими глазами и руками
2) вводим меру расстояния между символами (если изображение бинаризованно, то операция XOR будет оптимальна)
3) затем, когда мы пытаемся распознать символ, поочередно рассчитываем дистанцию между ним и всеми символами в базе. Среди k ближайших соседей, возможно, будут представители различных классов. Естественно, представителей какого класса больше среди соседей, к тому классу стоит отнести распознаваемый символ.
В теории, если записать очень большую базу с примерами символов, снятых под разными углами, освещением, со всеми возможными потертостями, то K-nearest — это все, что нужно. Но тогда нужно очень быстро рассчитывать дистанцию между изображениями, а, значит, бинаризовать его и использовать XOR. Но тогда именно в случае с загрязненными или потертыми номерами будут проблемы. Бинаризация совершенно непредсказуемо изменяет символ.
У метода есть одно очень важное преимущество: он простой и прозрачный, а значит легко отлаживается и настраиваться на оптимальный результат. Во многих случаях очень важно понимать, как работает ваш алгоритм.
Корреляционный
Часто методы, которые используются в распознавании изображений, построены на эмпирических подходах. Но никто не запрещает использовать математический аппарат теории вероятности, который был просто отполирован в задачах детектирования сигнала в радиолокационных системах. Шрифт на автомобильном номере нам известен, шум фотокамеры или пыль на номере можно с натяжкой назвать гауссовским. Существует некоторая неопределенность по расположению символа и его наклону, но эти параметры можно перебрать. Если мы оставляем изображение не бинаризованным, то нам еще неизвестна и амплитуда сигнала, т. е. яркость символа.
Очень не хочется вдаваться в строгое решение этой задачи в рамках статьи. По сути все-равно все сводится к операции расчета ковариации входного сигнала с гипотетическим (с учетом заданных смещений и поворотов):
X – входной сигнал, Y – гипотеза. Обозначение E – математическое ожидание.
Если нужно выбрать из разных символов, то гипотезы по повороту и смещению строятся для каждого символа. Если мы точно знаем, что входное изображение содержит символ, то максимум ковариации по всем гипотезам определит символ, его смещение и наклон. Тут, конечно, встает проблема близости изображений различных символов («р» и «в», «о» и «с» и др.). Самое простое — ввести для каждого символа весовую матрицу коэффициентов.
Иногда такие методы называются «template-matching», что полностью отражает их суть. Задаем образцы — сравниваем входное изображение с образцами. Если есть какая-то неопределенность по параметрам, то, либо перебираем все возможные варианты, либо используем адаптивные подходы, правда тут уже знать и понимать математику придется.
Достоинства метода:
— предсказуемый и хорошо изученный результат, если шум хоть немного соответствует выбранной модели;
— если шрифт задан строго, как в нашем случае, то способен разглядеть сильно пыльный/грязный/потертый символ.
Недостатки:
— вычислительно весьма затратный.
Нейросети
Про искусственные нейросети на Хабре было уже написано очень много. Сейчас их принято разделять на два поколения:
— классические 2-3х-слойные нейросети, обучающиеся градиентными методами с обратным распространением ошибок (3х-слойная нейросеть изображена на рисунке);
— так называемые deep-learning нейросети и сверточные сети.
Второе поколение нейросетей уже последние лет 7 побеждают на разных соревнованиях по распознаванию изображений, выдавая результат несколько лучший, чем остальные методы.
Существует открытая база изображений рукописных цифр. Таблица результатов очень наглядно демонстрирует эволюцию различных методов, в том числе и алгоритмов на основе нейросетей.
Также стоит отдельно отметить, что для печатных шрифтов прекрасно работают простейшая однослойная или двухслойная (вопрос терминологии) сеть , которая по своей сути ничем не отличается от template-matching подходов.
Достоинства метода:
— при правильной настройке и обучении может работать лучше других известных методов;
— при большом обучающем массиве данных устойчив к искажения символов.
Недостатки:
— наиболее сложный для описанных методов;
— диагностика аномального поведения в многослойных сетях попросту невозможна.
Заключение
В статье были рассмотрены базовые методы распознавания, их типичные глюки и ошибки. Возможно, это поможет вам сделать свой номер чуть более читаемым при поездках по городу, или наоборот.
Еще я надеюсь, что удалось показать полное отсутствие магии в задаче распознавания номеров. Все абсолютно понятно и интуитивно. Совершенно не страшная задача для курсовой работы студента по соответствующей специальности.
А еще через несколько дней ZlodeiBaal выложит небольшую распознавалку по номерам, по мотивам нашей работы над которой была написана эта статья. Ее можно будет мучить.
З.Ы. Все номера, которые приведены в статье — добыты из Гугла и Яндекса простыми запросами
Литература
1) ALGORITHMIC AND MATHEMATICAL PRINCIPLES OF AUTOMATIC NUMBER PLATE RECOGNITION SYSTEMS ONDREJ MARTINSKY – обзорная статья.
2) A Real-Time Mobile Vehicle License Plate Detection and Recognition Kuo-Ming Hung and Ching-Tang Hsieh –гистограммный подход при распознавании номеров
3) Robust License Plate Detection Using Covariance Descriptor in a Neural Network Framework Fatih Porikli, Tekin Kocak – нейросетевой подход при поиске номера
4) Automated Number Plate Recognition Using Hough Lines and Template Matching Saqib Rasheed, Asad Naeem and Omer Ishaq – поиск номеров через HOG-дескрипторы вертикальных линий
5) Survey of Methods for Character Recognition Suruchi G. Dedgaonkar, Anjali A. Chandavale, Ashok M. Sapkal – небольшая обзорная статья про распознавание буков и цифр
7) Учебное пособие «Основа теории обработки изображений», Крашенинников В. Р.
