
Доброго времени суток уважаемые хабравчане. Уже 3 года я работаю на проекте в котором мы используем Spring. Мне всегда было интересно разобраться с тем, как он устроен внутри. Я поискал статьи про внутреннее устройство Spring, но, к сожалению, ничего не нашел.
Всех, кого интересует внутреннее устройство Spring, прошу под кат.
На схеме изображены основные этапы поднятия ApplicationContext. В этом посте мы остановимся на каждом из этих этапов. Какой-то этап будет рассмотрен подробно, а какой-то будет описан в общих чертах.
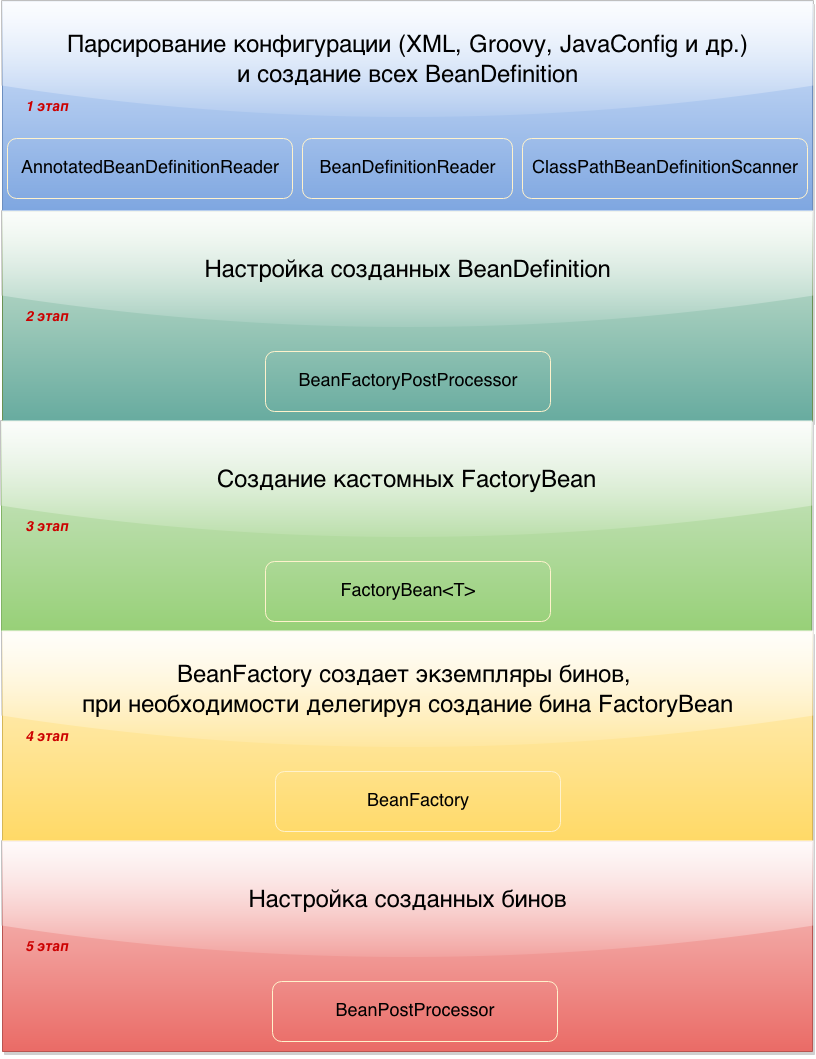
1. Парсирование конфигурации и создание BeanDefinition
После выхода четвертой версии спринга, у нас появилось четыре способа конфигурирования контекста:
- Xml конфигурация — ClassPathXmlApplicationContext(“context.xml”)
- Конфигурация через аннотации с указанием пакета для сканирования — AnnotationConfigApplicationContext(“package.name”)
- Конфигурация через аннотации с указанием класса (или массива классов) помеченного аннотацией @Configuration -AnnotationConfigApplicationContext(JavaConfig.class). Этот способ конфигурации называется — JavaConfig.
- Groovy конфигурация — GenericGroovyApplicationContext(“context.groovy”)
Про все четыре способа очень хорошо написано тут.
Цель первого этапа — это создание всех BeanDefinition. BeanDefinition — это специальный интерфейс, через который можно получить доступ к метаданным будущего бина. В зависимости от того, какая у вас конфигурация, будет использоваться тот или иной механизм парсирования конфигурации.
Xml конфигурация
Для Xml конфигурации используется класс — XmlBeanDefinitionReader, который реализует интерфейс BeanDefinitionReader. Тут все достаточно прозрачно. XmlBeanDefinitionReader получает InputStream и загружает Document через DefaultDocumentLoader. Далее обрабатывается каждый элемент документа и если он является бином, то создается BeanDefinition на основе заполненных данных (id, name, class, alias, init-method, destroy-method и др.). Каждый BeanDefinition помещается в Map. Map хранится в классе DefaultListableBeanFactory. В коде Map выглядит вот так.
/** Map of bean definition objects, keyed by bean name */ private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<String, BeanDefinition>(64);
Конфигурация через аннотации с указанием пакета для сканирования или JavaConfig
Конфигурация через аннотации с указанием пакета для сканирования или JavaConfig в корне отличается от конфигурации через xml. В обоих случаях используется класс AnnotationConfigApplicationContext.
new AnnotationConfigApplicationContext(JavaConfig.class);
или
new AnnotationConfigApplicationContext(“package.name”);
Если заглянуть во внутрь AnnotationConfigApplicationContext, то можно увидеть два поля.
private final AnnotatedBeanDefinitionReader reader; private final ClassPathBeanDefinitionScanner scanner;
ClassPathBeanDefinitionScanner сканирует указанный пакет на наличие классов помеченных аннотацией Component (или любой другой аннотацией которая включает в себя Component). Найденные классы парсируются и для них создаются BeanDefinition.
Чтобы сканирование было запущено, в конфигурации должен быть указан пакет для сканирования.
@ComponentScan({"package.name"})
или
<context:component-scan base-package="package.name"/>
AnnotatedBeanDefinitionReader работает в несколько этапов.
- Первый этап — это регистрация всех @Configuration для дальнейшего парсирования. Если в конфигурации используются Conditional, то будут зарегистрированы только те конфигурации, для которых Condition вернет true. Аннотация Conditional появилась в четвертой версии спринга. Она используется в случае, когда на момент поднятия контекста нужно решить, создавать бин/конфигурацию или нет. Причем решение принимает специальный класс, который обязан реализовать интерфейс Condition.
- Второй этап — это регистрация специального BeanFactoryPostProcessor, а именно BeanDefinitionRegistryPostProcessor, который при помощи класса ConfigurationClassParser парсирует JavaConfig и создает BeanDefinition.
Groovy конфигурация
Данная конфигурация очень похожа на конфигурацию через Xml, за исключением того, что в файле не XML, а Groovy. Чтением и парсированием groovy конфигурации занимается класс GroovyBeanDefinitionReader.
2. Настройка созданных BeanDefinition
После первого этапа у нас имеется Map, в котором хранятся BeanDefinition. Архитектура спринга построена таким образом, что у нас есть возможность повлиять на то, какими будут наши бины еще до их фактического создания, иначе говоря мы имеем доступ к метаданным класса. Для этого существует специальный интерфейс BeanFactoryPostProcessor, реализовав который, мы получаем доступ к созданным BeanDefinition и можем их изменять. В этом интерфейсе всего один метод.
public interface BeanFactoryPostProcessor { void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException; }
Метод postProcessBeanFactory принимает параметром ConfigurableListableBeanFactory. Данная фабрика содержит много полезных методов, в том числе getBeanDefinitionNames, через который мы можем получить все BeanDefinitionNames, а уже потом по конкретному имени получить BeanDefinition для дальнейшей обработки метаданных.
Давайте разберем одну из родных реализаций интерфейса BeanFactoryPostProcessor. Обычно, настройки подключения к базе данных выносятся в отдельный property файл, потом при помощи PropertySourcesPlaceholderConfigurer они загружаются и делается inject этих значений в нужное поле. Так как inject делается по ключу, то до создания экземпляра бина нужно заменить этот ключ на само значение из property файла. Эта замена происходит в классе, который реализует интерфейс BeanFactoryPostProcessor. Название этого класса — PropertySourcesPlaceholderConfigurer. Весь этот процесс можно увидеть на рисунке ниже.
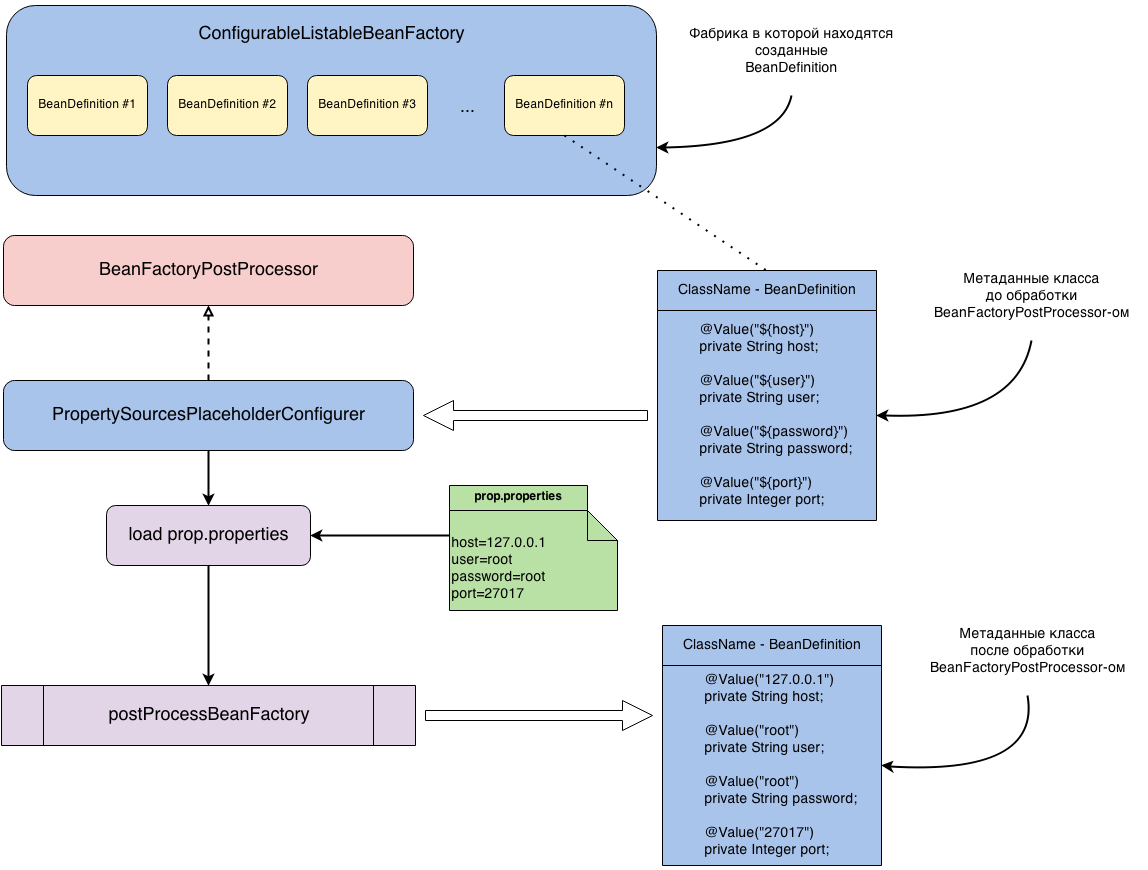
Давайте еще раз разберем что же у нас тут происходит. У нас имеется BeanDefinition для класса ClassName. Код класса приведен ниже.
@Component public class ClassName { @Value("${host}") private String host; @Value("${user}") private String user; @Value("${password}") private String password; @Value("${port}") private Integer port; }
Если PropertySourcesPlaceholderConfigurer не обработает этот BeanDefinition, то после создания экземпляра ClassName, в поле host проинжектится значение — "${host}" (в остальные поля проинжектятся соответствующие значения). Если PropertySourcesPlaceholderConfigurer все таки обработает этот BeanDefinition, то после обработки, метаданные этого класса будут выглядеть следующим образом.
@Component public class ClassName { @Value("127.0.0.1") private String host; @Value("root") private String user; @Value("root") private String password; @Value("27017") private Integer port; }
Соответственно в эти поля проинжектятся правильные значения.
Для того что бы PropertySourcesPlaceholderConfigurer был добавлен в цикл настройки созданных BeanDefinition, нужно сделать одно из следующих действий.
Для XML конфигурации.
<context:property-placeholder location="property.properties" />
Для JavaConfig.
@Configuration @PropertySource("classpath:property.properties") public class DevConfig { @Bean public static PropertySourcesPlaceholderConfigurer configurer() { return new PropertySourcesPlaceholderConfigurer(); } }
PropertySourcesPlaceholderConfigurer обязательно должен быть объявлен как static. Без static у вас все будет работать до тех пор, пока вы не попробуете использовать @ Value внутри класса @Configuration.
3. Создание кастомных FactoryBean
FactoryBean — это generic интерфейс, которому можно делегировать процесс создания бинов типа . В те времена, когда конфигурация была исключительно в xml, разработчикам был необходим механизм с помощью которого они бы могли управлять процессом создания бинов. Именно для этого и был сделан этот интерфейс. Для того что бы лучше понять проблему, приведу пример xml конфигурации.
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <bean id="redColor" scope="prototype" class="java.awt.Color"> <constructor-arg name="r" value="255" /> <constructor-arg name="g" value="0" /> <constructor-arg name="b" value="0" /> </bean> </beans>
На первый взгляд, тут все нормально и нет никаких проблем. А что делать если нужен другой цвет? Создать еще один бин? Не вопрос.
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <bean id="redColor" scope="prototype" class="java.awt.Color"> <constructor-arg name="r" value="255" /> <constructor-arg name="g" value="0" /> <constructor-arg name="b" value="0" /> </bean> <bean id="green" scope="prototype" class="java.awt.Color"> <constructor-arg name="r" value="0" /> <constructor-arg name="g" value="255" /> <constructor-arg name="b" value="0" /> </bean> </beans>
А что делать если я хочу каждый раз случайный цвет? Вот тут то и приходит на помощь интерфейс FactoryBean.
Создадим фабрику которая будет отвечать за создание всех бинов типа — Color.
package com.malahov.factorybean; import org.springframework.beans.factory.FactoryBean; import org.springframework.stereotype.Component; import java.awt.*; import java.util.Random; /** * User: malahov * Date: 18.04.14 * Time: 15:59 */ public class ColorFactory implements FactoryBean<Color> { @Override public Color getObject() throws Exception { Random random = new Random(); Color color = new Color(random.nextInt(255), random.nextInt(255), random.nextInt(255)); return color; } @Override public Class<?> getObjectType() { return Color.class; } @Override public boolean isSingleton() { return false; } }
Добавим ее в xml и удалим объявленные до этого бины типа — Color.
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <bean id="colorFactory" class="com.malahov.temp.ColorFactory"></bean> </beans>
Теперь создание бина типа Color.class будет делегироваться ColorFactory, у которого при каждом создании нового бина будет вызываться метод getObject.
Для тех кто пользуется JavaConfig, этот интерфейс будет абсолютно бесполезен.
4. Создание экземпляров бинов
Созданием экземпляров бинов занимается BeanFactory при этом, если нужно, делегирует это кастомным FactoryBean. Экземпляры бинов создаются на основе ранее созданных BeanDefinition.
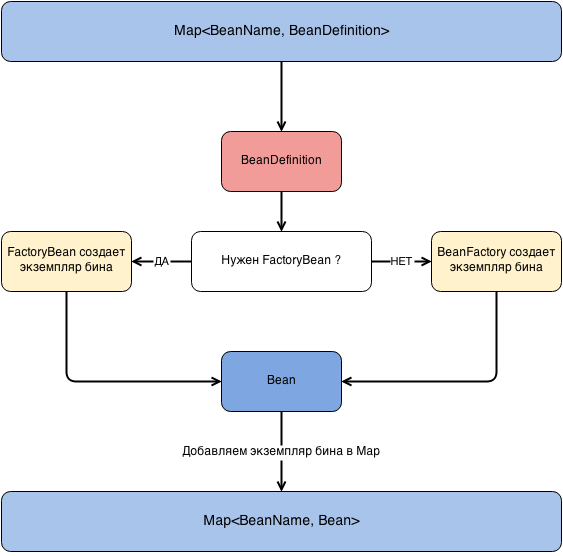
5. Настройка созданных бинов
Интерфейс BeanPostProcessor позволяет вклиниться в процесс настройки ваших бинов до того, как они попадут в контейнер. Интерфейс несет в себе несколько методов.
public interface BeanPostProcessor { Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException; Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException; }
Оба метода вызываются для каждого бина. У обоих методов параметры абсолютно одинаковые. Разница только в порядке их вызова. Первый вызывается до init-метода, второй, после. Важно понимать, что на данном этапе экземпляр бина уже создан и идет его донастройка. Тут есть два важных момента:
- Оба метода в итоге должны вернуть бин. Если в методе вы вернете null, то при получении этого бина из контекста вы получите null, а поскольку через бинпостпроцессор проходят все бины, после поднятия контекста, при запросе любого бина вы будете получать фиг, в смысле null.
- Если вы хотите сделать прокси над вашим объектом, то имейте ввиду, что это принято делать после вызова init метода, иначе говоря это нужно делать в методе postProcessAfterInitialization.
Процесс донастройки показан на рисунке ниже. Порядок в котором будут вызваны BeanPostProcessor не известен, но мы точно знаем что выполнены они будут последовательно.
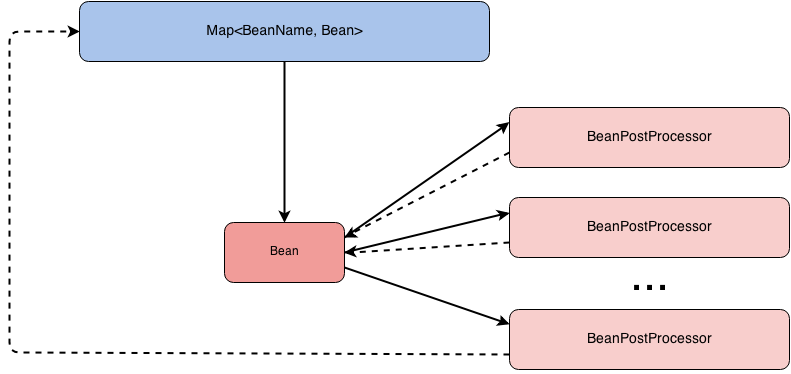
Для того, что бы лучше понять для чего это нужно, давайте разберемся на каком-нибудь примере.
При разработке больших проектов, как правило, команда делится на несколько групп. Например первая группа разработчиков занимается написанием инфраструктуры проекта, а вторая группа, используя наработки первой группы, занимается написанием бизнес логики. Допустим второй группе понадобился функционал, который позволит в их бины инжектить некоторые значения, например случайные числа.
На первом этапе будет создана аннотация, которой будут помечаться поля класса, в которые нужно проинжектить значение.
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) public @interface InjectRandomInt { int min() default 0; int max() default 10; }
По умолчанию, диапазон случайных числе будет от 0 до 10.
Затем, нужно создать обработчик этой аннотации, а именно реализацию BeanPostProcessor для обработки аннотации InjectRandomInt.
@Component public class InjectRandomIntBeanPostProcessor implements BeanPostProcessor { private static final Logger LOGGER = LoggerFactory.getLogger(InjectRandomIntBeanPostProcessor.class); @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { LOGGER.info("postProcessBeforeInitialization::beanName = {}, beanClass = {}", beanName, bean.getClass().getSimpleName()); Field[] fields = bean.getClass().getDeclaredFields(); for (Field field : fields) { if (field.isAnnotationPresent(InjectRandomInt.class)) { field.setAccessible(true); InjectRandomInt annotation = field.getAnnotation(InjectRandomInt.class); ReflectionUtils.setField(field, bean, getRandomIntInRange(annotation.min(), annotation.max())); } } return bean; } @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { return bean; } private int getRandomIntInRange(int min, int max) { return min + (int)(Math.random() * ((max - min) + 1)); } }
Код данного BeanPostProcessor достаточно прозрачен, поэтому мы не будем на нем останавливаться, но тут есть один важный момент.
BeanPostProcessor обязательно должен быть бином, поэтому мы его либо помечаем аннотацией Component, либо регестрируем его в xml конфигурации как обычный бин.
Первая группа разработчиков свою задачу выполнила. Теперь вторая группа может использовать эти наработки.
@Component @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) public class MyBean { @InjectRandomInt private int value1; @InjectRandomInt(min = 100, max = 200) private int value2; private int value3; @Override public String toString() { return "MyBean{" + "value1=" + value1 + ", value2=" + value2 + ", value3=" + value3 + '}'; } }
В итоге, все бины типа MyBean, получаемые из контекста, будут создаваться с уже проинициализированными полями value1 и value2. Также тут стоить отметить, этап на котором будет происходить инжект значений в эти поля будет зависеть от того какой @ Scope у вашего бина. SCOPE_SINGLETON — инициализация произойдет один раз на этапе поднятия контекста. SCOPE_PROTOTYPE — инициализация будет выполняться каждый раз по запросу. Причем во втором случае ваш бин будет проходить через все BeanPostProcessor-ы что может значительно ударить по производительности.
Полный код программы вы можете найти тут.
Хочу сказать отдельное спасибо EvgenyBorisov. Благодаря его курсу, я решился на написание этого поста.
Также советую посмотреть его доклад с JPoint 2014.
