Comments 58
Картинки красивые, но какова их практическая польза?
Вот взять две последние, зачем в предпоследней картинке 3D? Она от этого не становится более информативной, а вот использование горизонтальных линий сетки становится невозможным. Последняя с пузырьками какой-то сюрреализм, как можно визуально оценить где какой шарик, если предположить что они разного размера я не знаю.
Вот взять две последние, зачем в предпоследней картинке 3D? Она от этого не становится более информативной, а вот использование горизонтальных линий сетки становится невозможным. Последняя с пузырьками какой-то сюрреализм, как можно визуально оценить где какой шарик, если предположить что они разного размера я не знаю.
Картинки и подбирались по красоте: статья-то о красотах. Лично я тоже не люблю 3D-чарты там, где это снижает информативность, но пользователи их зачем-то хотят.
С другой стороны, вообще-то у нас есть всякие лейблы и прочее, что повышает читаемость — мы просто для статьи всё «лишнее» выпилили. Похоже, зря :)
С другой стороны, вообще-то у нас есть всякие лейблы и прочее, что повышает читаемость — мы просто для статьи всё «лишнее» выпилили. Похоже, зря :)
Сколько стоит ваша библиотека и какие преимущества перед Qt Data Visualization & Charts, которая интерактивна, кроссплатформенна и из коробки поддерживает анимационные переходы?
Ну во-первых, Qt Data Visualization & Charts зарелизили в 2014, мы в это время были уже глубоко и плотно в разработке. До этого был QWT, и он, мягко скажем, не фонтан.
Во-вторых, c Qt есть проблемы, если хочется зарелизить iOS-приложение с закрытыми исходниками. Аппстор требует, чтобы все использованные библиотеки лежали внутри в статике, а там с этим сложности: qt-project.org/wiki/Licensing-talk-about-mobile-platforms.
Во-третьих, как показывает практика, Qt не такой уж кроссплатформенный. Он великолепно подходит, когда надо что-то быстро сваять на коленке — но как только доходит дело до продакшена, его ненативность быстро начинает раздражать конечных пользователей.
В-четвёртых, у нас сделаны нативные оболочки для iOS и андроида (на Objective-C и Java), так что пользователь может не заморачиваться по поводу написания на С++.
Во-вторых, c Qt есть проблемы, если хочется зарелизить iOS-приложение с закрытыми исходниками. Аппстор требует, чтобы все использованные библиотеки лежали внутри в статике, а там с этим сложности: qt-project.org/wiki/Licensing-talk-about-mobile-platforms.
Во-третьих, как показывает практика, Qt не такой уж кроссплатформенный. Он великолепно подходит, когда надо что-то быстро сваять на коленке — но как только доходит дело до продакшена, его ненативность быстро начинает раздражать конечных пользователей.
В-четвёртых, у нас сделаны нативные оболочки для iOS и андроида (на Objective-C и Java), так что пользователь может не заморачиваться по поводу написания на С++.
а первый вопрос?;)
как только доходит дело до продакшена, его ненативность быстро начинает раздражать конечных пользователей.Постойте, но ту же мобильную версию 2gis разве не на Qt делают?
Насколько я понимаю, гис-движок там написан на С++ с использованием boost’а. Если из их мобильного приложения вычесть вкладку «Карта», то оставшийся объём пара студентов сможет написать за неделю на обычном UIKit. При этом не нужно будет платить Digia по 150$ в месяц за использование Qt. //Это оценочное суждение, сделанное на основе изучения вывода команды mcview Payload/GrymMobile.app/GrymMobile, и если кто-то точно знает, что я ошибаюсь — прошу меня поправить :-)
Для андроида — да, для iOS — нет. Внутренние части, как было правильно замечено, Qt не используют.
В аду для перфекционистов нету ни серы, ни огня, и лишь слегка несимметрично стоят щербатые котлы.
Извините за критику, но эта библиотека — совершенный провал с точки зрения научных графиков. Видимо, она никогда не задумывалась для графического представления информации? Судя по полировке пикселей это скорее художественные произведения по мотивам чисел пользователя, не более того.
Потому что иначе вы бы взяли в качестве вдохновения не MS Excel, а ggplot2 или что-нибудь аналогичное.
Хотя бы посмотрите www.informationisbeautiful.net, www.datavisualization.ch.
За предпоследний stacked chart вам должно быть очень стыдно. Он неплохо смотрится как иллюстрация, но абсолютно неинфоративен.
Информацию невозможно прочитать:
— трёхмерная проекция искажает оси и параллельные линии более не выглядят такими
— подписи нечитаемы, оси не подписаны
— трёхмерная толщина и проекция графика затрудняет чтение численных значений
Принятие решения на основе этого графика крайне затруднено — без таблицы с исходными числами он бесполезен.
Представленный 3d pie chart в виде пирамидки настолько ужасен, что я даже сохраню его к себе в коллекцию. Речь идёт даже не о затруднённом понимании данных или искажении восприятия (например, в статье Stephen Few наглядно разбираются все недостатки трёхмерных круговых диаграмм). Там тупо не видно данных!
Это наиболее яркий пример неудачного дизайна графиков, который мне встретился за все годы работы с научными данными. Браво! Победа с колоссальным отрывом.
Облако шариков я даже не рассматриваю в качестве графика. Там нет ровным счётом ничего кроме визуального мусора. Принятие решения или понимание ситуации невозможно в принципе.
Если я смею что-либо порекомендовать, я бы предложил начать с другого конца проблемы: с проектирования графиков. Вдруг окажется, что все эти трёхмерные представления только мешают основной цели? Тогда даже не придётся бороться с пикселями и жизнь станет намного приятнее =)
Потому что иначе вы бы взяли в качестве вдохновения не MS Excel, а ggplot2 или что-нибудь аналогичное.
Хотя бы посмотрите www.informationisbeautiful.net, www.datavisualization.ch.
За предпоследний stacked chart вам должно быть очень стыдно. Он неплохо смотрится как иллюстрация, но абсолютно неинфоративен.
Информацию невозможно прочитать:
— трёхмерная проекция искажает оси и параллельные линии более не выглядят такими
— подписи нечитаемы, оси не подписаны
— трёхмерная толщина и проекция графика затрудняет чтение численных значений
Принятие решения на основе этого графика крайне затруднено — без таблицы с исходными числами он бесполезен.
Представленный 3d pie chart в виде пирамидки настолько ужасен, что я даже сохраню его к себе в коллекцию. Речь идёт даже не о затруднённом понимании данных или искажении восприятия (например, в статье Stephen Few наглядно разбираются все недостатки трёхмерных круговых диаграмм). Там тупо не видно данных!
Это наиболее яркий пример неудачного дизайна графиков, который мне встретился за все годы работы с научными данными. Браво! Победа с колоссальным отрывом.
Облако шариков я даже не рассматриваю в качестве графика. Там нет ровным счётом ничего кроме визуального мусора. Принятие решения или понимание ситуации невозможно в принципе.
Если я смею что-либо порекомендовать, я бы предложил начать с другого конца проблемы: с проектирования графиков. Вдруг окажется, что все эти трёхмерные представления только мешают основной цели? Тогда даже не придётся бороться с пикселями и жизнь станет намного приятнее =)
Справедливости ради стоит отметить, что статья о рендеринге, а не о том, как строить информативные графики.
Спасибо за критику, но почти всё мимо.
Здесь иллюстрировались не научные данные, а возможности рендеринга, так что мы поотключали все милые сердцу подписи (они все включаются — и для данных, и для осей), выбрали ракурс понаряднее (всё трёхмерное можно вращать и масштабировать) и пообъёмнее (3d — это плюшка, а не единственно возможный вариант).
Мы прекрасно понимаем, что 3D в научных диаграммах не нужен, за редким исключением (типа спектрограммы линейного входа, как первая из 4-х картинок в конце — она ещё и обновляется в реальном времени) — но с всем вышеперечисленным технических трудностей при реализации не возникло :)
p.s. а за статью про паи спасибо, сложу в личную копилку аргументов :)
Здесь иллюстрировались не научные данные, а возможности рендеринга, так что мы поотключали все милые сердцу подписи (они все включаются — и для данных, и для осей), выбрали ракурс понаряднее (всё трёхмерное можно вращать и масштабировать) и пообъёмнее (3d — это плюшка, а не единственно возможный вариант).
Мы прекрасно понимаем, что 3D в научных диаграммах не нужен, за редким исключением (типа спектрограммы линейного входа, как первая из 4-х картинок в конце — она ещё и обновляется в реальном времени) — но с всем вышеперечисленным технических трудностей при реализации не возникло :)
p.s. а за статью про паи спасибо, сложу в личную копилку аргументов :)
Так а зачем решать проблемы, которых не должно возникать в принципе? =)
Есть какой-нибудь сайт с примерами диаграмм, построенных «по делу»?
Есть какой-нибудь сайт с примерами диаграмм, построенных «по делу»?
Научные диаграммы — это прекрасно. Их мы тоже с удовольствием рисуем. Но есть коммерческие заказчики, которым надо «вау-эффект» для презентаций, и они просили 3d, анимации, блестящие шарики и прочее.
Библиотека коммерческая, так что конкретные применения остаются за клиентами — мы-то делаем компонент, а не прикладные приложения. Есть демо-приложение (для iOS и мака), правда, там рандомные данные. Собственно, давайте данные — отрисуем :)
Из прикладного с реальными данными есть под рукой вот эти две: множественное выравнивание ДНК и спектрограмма звука. Последняя, кстати, в 3д лучше.


А что до невозникания проблем — так основные проблемы с точностью как раз касаются двумерных диаграмм. Четыре проблемы из шести про них.
Библиотека коммерческая, так что конкретные применения остаются за клиентами — мы-то делаем компонент, а не прикладные приложения. Есть демо-приложение (для iOS и мака), правда, там рандомные данные. Собственно, давайте данные — отрисуем :)
Из прикладного с реальными данными есть под рукой вот эти две: множественное выравнивание ДНК и спектрограмма звука. Последняя, кстати, в 3д лучше.
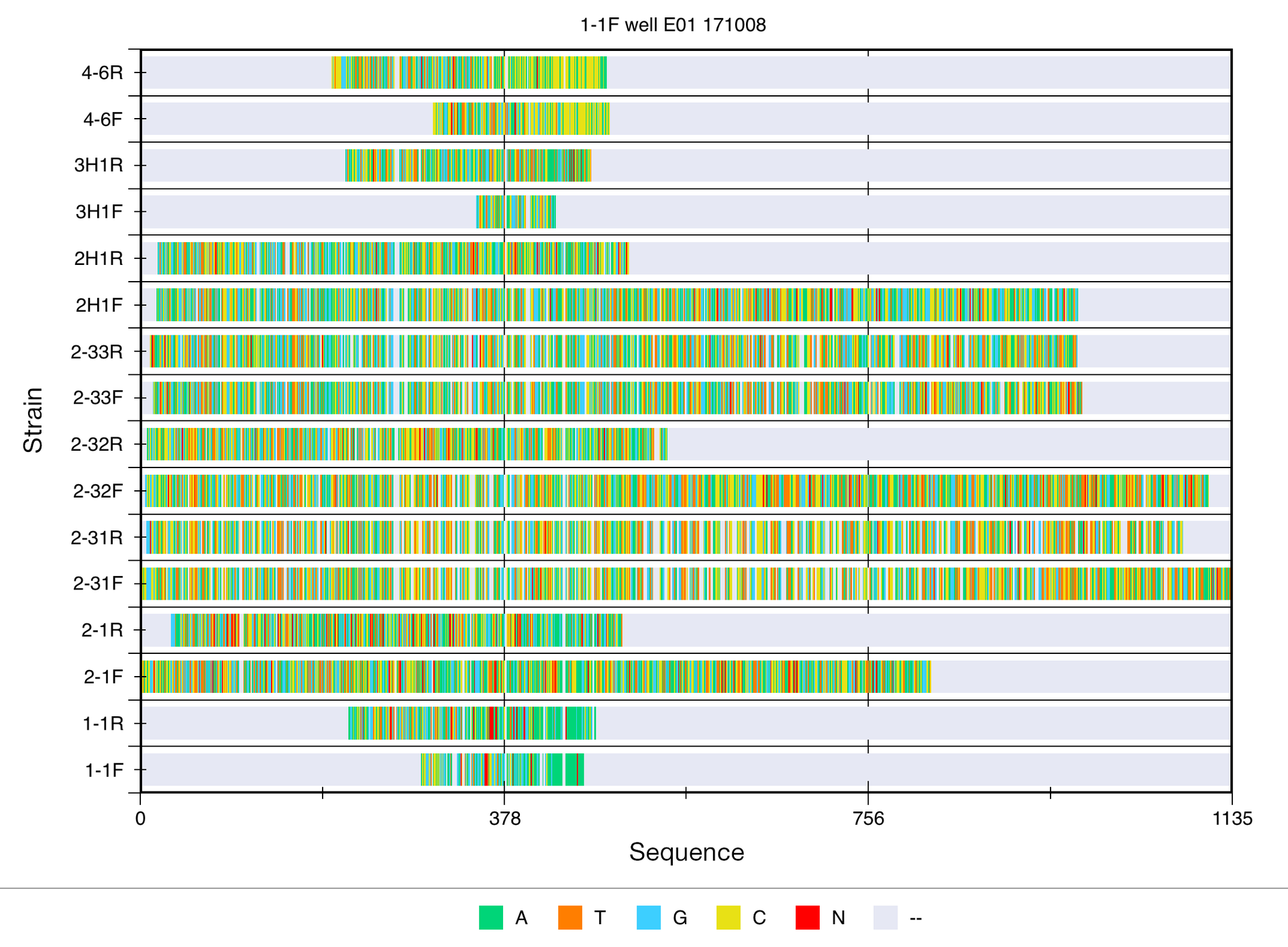

А что до невозникания проблем — так основные проблемы с точностью как раз касаются двумерных диаграмм. Четыре проблемы из шести про них.
свой визуализатор линий
Это называется тесселятор. Задачка осложняется тем, что сцену нужно динамически ретесселировать в зависимости от масштаба, иначе получите либо слишком угловатую кривую, либо низкую производительность. Всякие API типа Direct2D, WPF/Milcore и т.д. этим и занимаются. Софтверно это делать не лучшая идея, т.к. объем вычислений большой, а с аппаратной поддержкой будет много возни. В общем ИМХО оно того не стоит.
www.wolframalpha.com/input/?i=y%3Dx%5E2
Это если нужно быстро и просто получить красивый график.
Это если нужно быстро и просто получить красивый график.
а не проще работать через блиттер.???? как рейроалд тайкун. работает везде, проблемы те же. и решены.
Если вы про этот Blitter, то он предназначен для двумерной графики, а нам нужна и трёхмерная тоже. Кроме того, он же, вроде, чисто для спрайтов? На нём можно, например, динамически меняющиеся контуры рисовать? Или делать динамические эффекты освещения? Ну и насколько он на мобильных устройствах работает — тоже вопрос, надо проверять.
Проблема не в плохом OpenGL/DirectX. Проблема в том, что у вас нет опыта работы с плавающей точкой. Если бы вам в руки попал GDI+ — у вас бы были ровно те же проблемы, хотя рендерит он софтварно. А теперь подробнее по каждой проблеме.
Проблема 1: float и пиксельные соответствия
Очевидно, что вы делили отрезок на 5 частей следующим образом:
А то что вы подобрали там магию с 10000.0 — удалите, ибо это жжжесть.
Проблема 2: стыковка перпендикулярных линий
Помоему достаточно очевидная. Но причем тут аппаратно ускоренные линии? Вы пробовали на GDI рисовать линии в 2 пикселя толщиной? Будут те же проблемы.
Проблема 3: линии вообще
Да, линии вообще растеризуются очень неэффективно. И первое что нужно было сделать — написать код, строящий линии из треугольников. Просто функция, на вход подается ломаная — на выход — набор треугольников, строящий контур нужной толщины. Задача в пару десятков строк кода. Автоматически бы у вас исчезла проблема с углами (проблема 2).
Проблема 4: дырки между полигонами
Это практически 1 в 1 проблема #1. Вы прибавляете, прибавляете, и не заботитесь о том, что круг надо замкнуть. Решается добавлением одного условия. Если это последний элемент, то координаты нужно брать из первых вершин. Это не ГПУ погрешность растеризации, а ваша, CPU погрешность.
Проблема 5: особенности системного антиалиасинга
Вы просто не знаете как растеризуются линии. Между прочим в DirectX растеризация линий вообще стандартизирована, в OpenGL я подозреваю что тоже. В общих чертах как будет происходить растеризация. Допустим вы хотите нарисовать линию из (1;1) в (11;1). Вы ожидате что она нарисуется вот так:

Но ведь у нас флоат координаты. Начальные и конечные точки — это не центры пикселей. Это координаты линии. Т.е. реально линия находится вот тут:

И если у вас округление пойдет в большую сторону, то вы увидите линию там где надо. Если в меньшую, то увы, линия будет на пиксель выше. Но это не проблема погрешности, а проблема непонимания того, что работа идет в float пространстве, и пиксель — это квадрат. У нулевого пикселя координаты (0;0)(1;1) а центр в (0.5;0.5).
А теперь сюрприз. Что будет, если мы рисуем линию (1;1)(11;1) но со сглаживанием. Видите рисунок вверху? Линия покрывает половину пикселей вверху и половину пикселей внизу. Очевидно же, что после сглаживания она будет вот такой:

Ну а чтобы нарисовать то что мы и ожидаем — нужно сместить линию на половину её толщины (для однопиксельной на 0.5) вниз:

Тогда и сглаживание будет красивым, и «погрешностей растеризации» меньше. А еще где-то на хабре была статья, про выравнивание векторных изображений по пиксельной сетке. Очень рекомендую к прочтению.
Проблема 6: Многопоточность и экономия энергии
Хороший тон — рисовать только тогда, когда что-то реально изменилось. Рендериг средствами ГПУ — уже распаралеллен за вас, потому что GAPI функция возвращает управление сразу же, а отрисуется оно потом. Адекватный рендеринг будет требовать миллисекунды времени CPU. А для таких простых сцен как у вас и миллисекунды много. У меня есть ощущение, что ваш велосипед будет требовать много больше времени, чем нужно на рендер.
Проблема 1: float и пиксельные соответствия
Очевидно, что вы делили отрезок на 5 частей следующим образом:
partsize = fullsize/5.0;
xcoord = 0;
for (i=0; i<=5.0; i++)
{
//рисуем вертикальную линию в xcoord (но рисуем возможно со смещением, смотрите коммент к проблеме 5)
xcoord += partsize;
}
for (i=0; i<=5.0; i++)
{
xcoord = fullsize*i/5.0;
//рисуем вертикальную линию в xcoord
}
А то что вы подобрали там магию с 10000.0 — удалите, ибо это жжжесть.
Проблема 2: стыковка перпендикулярных линий
Помоему достаточно очевидная. Но причем тут аппаратно ускоренные линии? Вы пробовали на GDI рисовать линии в 2 пикселя толщиной? Будут те же проблемы.
Проблема 3: линии вообще
Да, линии вообще растеризуются очень неэффективно. И первое что нужно было сделать — написать код, строящий линии из треугольников. Просто функция, на вход подается ломаная — на выход — набор треугольников, строящий контур нужной толщины. Задача в пару десятков строк кода. Автоматически бы у вас исчезла проблема с углами (проблема 2).
Проблема 4: дырки между полигонами
Это практически 1 в 1 проблема #1. Вы прибавляете, прибавляете, и не заботитесь о том, что круг надо замкнуть. Решается добавлением одного условия. Если это последний элемент, то координаты нужно брать из первых вершин. Это не ГПУ погрешность растеризации, а ваша, CPU погрешность.
Проблема 5: особенности системного антиалиасинга
Вы просто не знаете как растеризуются линии. Между прочим в DirectX растеризация линий вообще стандартизирована, в OpenGL я подозреваю что тоже. В общих чертах как будет происходить растеризация. Допустим вы хотите нарисовать линию из (1;1) в (11;1). Вы ожидате что она нарисуется вот так:
Но ведь у нас флоат координаты. Начальные и конечные точки — это не центры пикселей. Это координаты линии. Т.е. реально линия находится вот тут:
И если у вас округление пойдет в большую сторону, то вы увидите линию там где надо. Если в меньшую, то увы, линия будет на пиксель выше. Но это не проблема погрешности, а проблема непонимания того, что работа идет в float пространстве, и пиксель — это квадрат. У нулевого пикселя координаты (0;0)(1;1) а центр в (0.5;0.5).
А теперь сюрприз. Что будет, если мы рисуем линию (1;1)(11;1) но со сглаживанием. Видите рисунок вверху? Линия покрывает половину пикселей вверху и половину пикселей внизу. Очевидно же, что после сглаживания она будет вот такой:
Ну а чтобы нарисовать то что мы и ожидаем — нужно сместить линию на половину её толщины (для однопиксельной на 0.5) вниз:
Тогда и сглаживание будет красивым, и «погрешностей растеризации» меньше. А еще где-то на хабре была статья, про выравнивание векторных изображений по пиксельной сетке. Очень рекомендую к прочтению.
Проблема 6: Многопоточность и экономия энергии
Хороший тон — рисовать только тогда, когда что-то реально изменилось. Рендериг средствами ГПУ — уже распаралеллен за вас, потому что GAPI функция возвращает управление сразу же, а отрисуется оно потом. Адекватный рендеринг будет требовать миллисекунды времени CPU. А для таких простых сцен как у вас и миллисекунды много. У меня есть ощущение, что ваш велосипед будет требовать много больше времени, чем нужно на рендер.
Решение проблемы 2 всё ж приведите, пожалуйста

Ой, в третьей приведено. Ручная тесселяция. А соседи тут говорят, вершинный шейдер надо.
Спасибо за развёрнутый комментарий! Да, теоретически-то Ваши доводы верны. Но есть нюансы.
По первой проблеме — вы как-то ловко пропустили тот момент, что при включении scissor test’а погрешность изменяется. Отрисовку сложной трёхмерной сцены, к сожалению, не получается свести к “xcoord = fullsize*i/5.0;”. График должен быть интерактивным, то есть должнен скроллиться и зумиться. Поэтому работа идёт в двух системах координат: сцены (где график, на неё действует масштаб и смещение, она ограничена scissor'ом) и экрана (где оси, она «статична», подвижны лишь риски на осях).
Для системы координат экрана используется матрица проекции, которую породил бы, например, вызов gluOrtho2D(0, screen_width, 0, screen_height).
Для двумерной сцены используется система координат, которую породил бы gluOrtho2D(-1, 1, -1, 1), чтобы по максимуму унифицировать случаи 2d и 3d графиков.
Чтобы риски на осях при скролле/зуме двигались вместе с графиком, мы вычисляем их координаты исходя из проекций соответствующих точек в системе координат сцены на систему координат экрана. Вот тут-то появляются те самые погрешности.
Дальше, про стыковку — ну да, такая проблема почти всюду. Но в условиях вышесказанного она иногда принимает весьма непредсказуемый характер, потому что сдвинуть что-то «на пиксель», когда оно подвержено довольно сложным многоступенчатым преобразованиям — не так-то просто.
Триангуляция линий — всё правильно. Но опять же нюанс, его вот уже тут озвучили: habrahabr.ru/post/230671/#comment_7810005
И проблема даже не в ретесселяции. Проблема в том, чтобы держать толщину линий одинаковой на разных масштабах контура. Не сказать, что это прямо так уж сложно, но сомнительно, что удастся уложиться в пару десятков строк кода :)
Про дырки между полигонами — там мы как раз ничего не прибавляем. И круг мы замыкаем (точнее, используем для начала следующего сектора координаты конца предыдущего). Тем не менее, такой вот спецэффект присутствует. Проблема в том, что у секторов есть ещё стенки (так как они могут выезжать из пирога и висеть рядом с ним). И вот то, что видно — это как раз не фон, а эта самая стенка, потому что в одном месте оказываются два стыкующихся полигона и один перпендикулярный им <картинка>. Погрешность растеризации вызывает как этот самый перпендикулярный полигон, который по идее скрыт стоящими рядом с ним, но из-за нехватки точности буфера глубины самый близкий к наблюдателю ряд точек проходит тест глубины и рисуется. Как избежать такой проблемы, мы пока что не придумали (очень не хочется костылить удаление стенки или же делать что-то с порядком вывода полигонов, потому что сейчас вся конструкция рисуется за один draw-call).
Про системный антиалиасинг Вы всё верно говорите и рисуете. Если в итоге у линии будут «правильные» координаты, она не размажется. Но проблема в том, что, как мы уже описали выше, «правильные» координаты организовать сложно (много промежуточных преобразований). Ну и артефакты — не самое страшное в системном антиалиасинге. Были бы они одни — мы б, может быть, смирились. Но вот его тормоза мы уже пережить не смогли :) А если писать свой антиалиасинг — так за компанию и от артефактов защититься решили.
Про многопоточность. Во-первых, да, мы рисуем только тогда, когда что-то изменилось. Во-вторых, рендеринг, конечно, распараллелен в плане SIMD. Но не в плане, например, загрузки данных. Те же glTexImage2D или glBufferData вполне себе синхронные. И не в плане всех остальных действий, которые производятся нами же по соседству (расчёт анимаций, применение преобразований и прочее). И вот в сумме все эти действия могут занимать довольно много времени, и их хочется производить где-то не там, где крутится обработка действий пользователя. Но главное даже не это (в большинстве случаев рендеринг действительно проходит быстро). Главное — это обратная ситуация: когда заблокирован main-thread, например, при обновлении данных. Или, ещё пример, на iOS, если на экране есть table view controller со включенной «пружинкой» и пользователь оттянул эту пружинку и держит, главный поток стоитс замиранием сердца ждёт, что же будет. И вот тут-то хотелось бы, чтобы анимация продолжала плавно проигрываться. Ну а велосипед наш работает довольно быстро — по крайней мере, поставленную задачу решает и обеспечивает удобный механизм анимаций.
По первой проблеме — вы как-то ловко пропустили тот момент, что при включении scissor test’а погрешность изменяется. Отрисовку сложной трёхмерной сцены, к сожалению, не получается свести к “xcoord = fullsize*i/5.0;”. График должен быть интерактивным, то есть должнен скроллиться и зумиться. Поэтому работа идёт в двух системах координат: сцены (где график, на неё действует масштаб и смещение, она ограничена scissor'ом) и экрана (где оси, она «статична», подвижны лишь риски на осях).
Для системы координат экрана используется матрица проекции, которую породил бы, например, вызов gluOrtho2D(0, screen_width, 0, screen_height).
Для двумерной сцены используется система координат, которую породил бы gluOrtho2D(-1, 1, -1, 1), чтобы по максимуму унифицировать случаи 2d и 3d графиков.
Чтобы риски на осях при скролле/зуме двигались вместе с графиком, мы вычисляем их координаты исходя из проекций соответствующих точек в системе координат сцены на систему координат экрана. Вот тут-то появляются те самые погрешности.
Дальше, про стыковку — ну да, такая проблема почти всюду. Но в условиях вышесказанного она иногда принимает весьма непредсказуемый характер, потому что сдвинуть что-то «на пиксель», когда оно подвержено довольно сложным многоступенчатым преобразованиям — не так-то просто.
Триангуляция линий — всё правильно. Но опять же нюанс, его вот уже тут озвучили: habrahabr.ru/post/230671/#comment_7810005
И проблема даже не в ретесселяции. Проблема в том, чтобы держать толщину линий одинаковой на разных масштабах контура. Не сказать, что это прямо так уж сложно, но сомнительно, что удастся уложиться в пару десятков строк кода :)
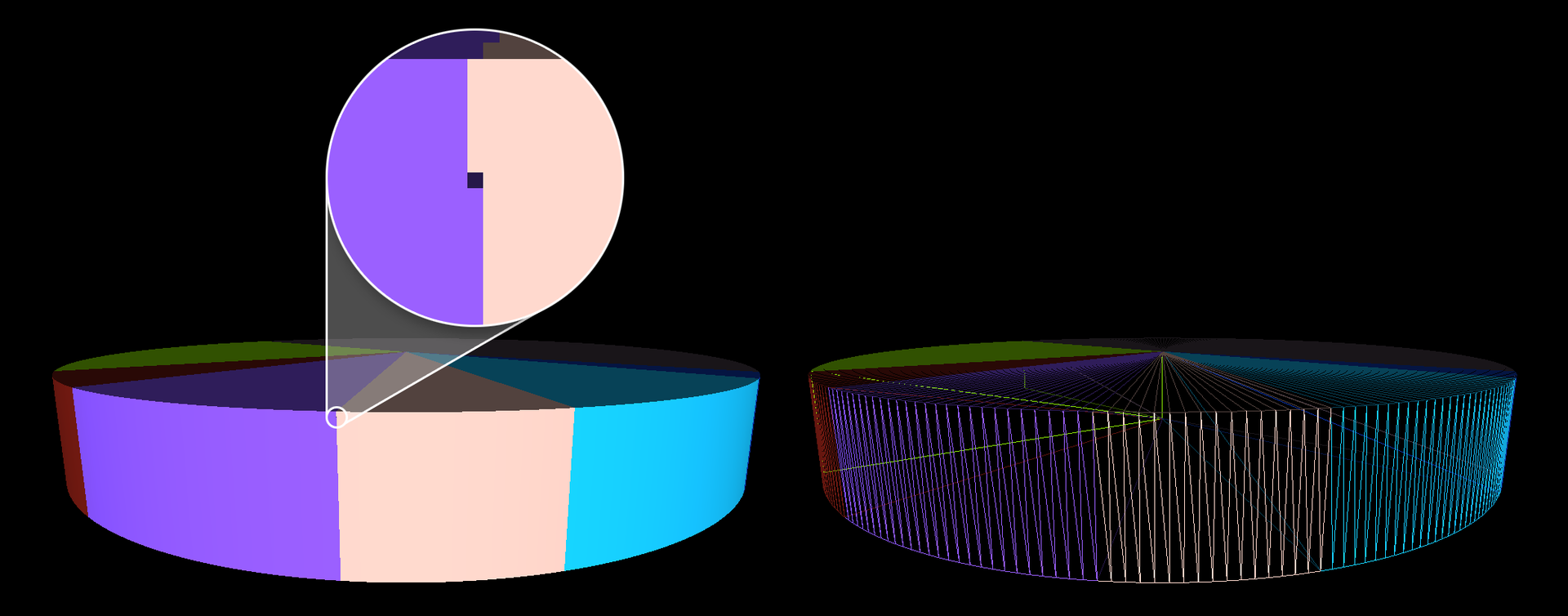
Про дырки между полигонами — там мы как раз ничего не прибавляем. И круг мы замыкаем (точнее, используем для начала следующего сектора координаты конца предыдущего). Тем не менее, такой вот спецэффект присутствует. Проблема в том, что у секторов есть ещё стенки (так как они могут выезжать из пирога и висеть рядом с ним). И вот то, что видно — это как раз не фон, а эта самая стенка, потому что в одном месте оказываются два стыкующихся полигона и один перпендикулярный им <картинка>. Погрешность растеризации вызывает как этот самый перпендикулярный полигон, который по идее скрыт стоящими рядом с ним, но из-за нехватки точности буфера глубины самый близкий к наблюдателю ряд точек проходит тест глубины и рисуется. Как избежать такой проблемы, мы пока что не придумали (очень не хочется костылить удаление стенки или же делать что-то с порядком вывода полигонов, потому что сейчас вся конструкция рисуется за один draw-call).
Про системный антиалиасинг Вы всё верно говорите и рисуете. Если в итоге у линии будут «правильные» координаты, она не размажется. Но проблема в том, что, как мы уже описали выше, «правильные» координаты организовать сложно (много промежуточных преобразований). Ну и артефакты — не самое страшное в системном антиалиасинге. Были бы они одни — мы б, может быть, смирились. Но вот его тормоза мы уже пережить не смогли :) А если писать свой антиалиасинг — так за компанию и от артефактов защититься решили.
Про многопоточность. Во-первых, да, мы рисуем только тогда, когда что-то изменилось. Во-вторых, рендеринг, конечно, распараллелен в плане SIMD. Но не в плане, например, загрузки данных. Те же glTexImage2D или glBufferData вполне себе синхронные. И не в плане всех остальных действий, которые производятся нами же по соседству (расчёт анимаций, применение преобразований и прочее). И вот в сумме все эти действия могут занимать довольно много времени, и их хочется производить где-то не там, где крутится обработка действий пользователя. Но главное даже не это (в большинстве случаев рендеринг действительно проходит быстро). Главное — это обратная ситуация: когда заблокирован main-thread, например, при обновлении данных. Или, ещё пример, на iOS, если на экране есть table view controller со включенной «пружинкой» и пользователь оттянул эту пружинку и держит, главный поток стоит
Пардон, потерялась картинка про дырки между полигонами:

По первой проблеме — вы как-то ловко пропустили тот момент, что при включении scissor test’а погрешность изменяется.Скроллинг и зумминг никак не связан с этим. В этом случае привязка к границам сетки должна дополнительно осуществляться в вершинном шейдере, а вершины должны иметь необходимую информацию о привязке.
График должен быть интерактивным, то есть должнен скроллиться и зумиться.
И проблема даже не в ретесселяции. Проблема в том, чтобы держать толщину линий одинаковой на разных масштабах контура. Не сказать, что это прямо так уж сложно, но сомнительно, что удастся уложиться в пару десятков строк кода :)Ну шейдер же. Вы думаете почему линии выкидывают из АПИ? Не гибко и держать код растеризации на пайплайне — неудобно.
Про дырки между полигонами — там мы как раз ничего не прибавляем. И круг мы замыкаем (точнее, используем для начала следующего сектора координаты конца предыдущего). Тем не менее, такой вот спецэффект присутствует.Увы, такого не может быть. Иначе во всех 3д моделях в играх были бы такие же дырки. :)
Проблема в том, что у секторов есть ещё стенки (так как они могут выезжать из пирога и висеть рядом с ним). И вот то, что видно — это как раз не фон, а эта самая стенка, потому что в одном месте оказываются два стыкующихся полигона и один перпендикулярный им <картинка>Ну во-первых я однозначно вижу фон (цвет нижележащего блина), а во-вторых — я вижу что у вас на той картинке, где эти самые блины — увеличение не из той области идет. Должно быть на 1 блин ниже. Ну и в-третьих — стенки должны тоже иметь общие координаты. Тогда не будет никакой погрешности в буфере глубины. Так что это целиком ваша погрешность, а не растеризации.
А если писать свой антиалиасинг — так за компанию и от артефактов защититься решили.Не заметил разницы между вашим антиалясингом и MSAA. Вы просто область для сравнения взяли удачную. И постпроцессовый антиалясинг (тот же FXAA например) — это полное фиаско для однопиксельных линий, идущих под углом.
Те же glTexImage2D или glBufferData вполне себе синхронные.То есть параллельность только для того, чтобы memcpy выполнялся в отдельном потоке? Хм…
Главное — это обратная ситуация: когда заблокирован main-thread, например, при обновлении данных.Так это вообще странное решение. Т.е. вместо того чтобы вынести обновление данных, которое блокирует main-thread — вы выносите рендеринг? При этом тред все равно заблокирован, пользователь не может ничего сделать, зато он может посмотреть как у него рендерится сцена, которая реально рендерится только когда что-то изменилось?
Или, ещё пример, на iOS, если на экране есть table view controller со включенной «пружинкой» и пользователь оттянул эту пружинку и держит, главный поток стоит с замиранием сердца ждёт, что же будет. И вот тут-то хотелось бы, чтобы анимация продолжала плавно проигрываться.Не работал с iOS, не могу ни подтвердить ни опровергнуть, но глядя на эти «проблемы» немного сомневаюсь что на iOS main thread блокируется наглухо (не приходят евенты ни таймеров, ни перерисовки)
Скроллинг и зумминг никак не связан с этим. В этом случае привязка к границам сетки должна дополнительно осуществляться в вершинном шейдере, а вершины должны иметь необходимую информацию о привязке.Поясните, что значит «привязка к сетке в вершинном шейдере» и какую такую информацию должны иметь вершины?
Ну шейдер же. Вы думаете почему линии выкидывают из АПИ? Не гибко и держать код растеризации на пайплайне — неудобно.Да, насчёт шейдера — да, сам по себе механизм не такой сложный. Но тут проблема не только в механизме, но ещё и в рефакторинге имеющегося кода.
Увы, такого не может быть. Иначе во всех 3д моделях в играх были бы такие же дырки. :)В играх стараются не допускать ситуации, которую мы показали тут: habrahabr.ru/post/230671/#comment_7811885
Мы тоже стараемся её избегать, но вот не всегда получается.
И это таки не фон, а стенка. На том скриншоте, что в статье, просто так совпало по цветам. Вот другой скриншот:

Ну и именно из-за того, что стенка имеет одни и те же координаты с боковинами, происходит ситуация «борьбы» в z-буфере, потому что на этапе растеризации у фрагментов разных полигонов оказывается одинаковая глубина. И из-за ограниченной точности z-буфера появляются места, где фрагменты проходят тест 50/50: часть от одного полигона, часть от другого. Вот, например, скриншот из Blender3D. Ситуация там несколько иная, там площадь перекрытия у полигонов большая. Но суть та же:

Не заметил разницы между вашим антиалясингом и MSAA. Вы просто область для сравнения взяли удачную. И постпроцессовый антиалясинг (тот же FXAA например) — это полное фиаско для однопиксельных линий, идущих под углом.Так во внешнем виде её особой и нет. Есть разница в производительности, потому что наш АА можно быстро отключить на период проигрывания анимации и включить обратно, когда картинка «устаканилась». Кроме того, у нас же не только постпроцессинговый, у нас гибрид SSAA и FXAA.
То есть параллельность только для того, чтобы memcpy выполнялся в отдельном потоке? Хм…Да, и плюс ещё обсчёт анимаций и все вспомогательные преобразования. Но ещё раз: это не главное, главное — обратная ситуация.
Так это вообще странное решение. Т.е. вместо того чтобы вынести обновление данных, которое блокирует main-thread — вы выносите рендеринг? При этом тред все равно заблокирован, пользователь не может ничего сделать, зато он может посмотреть как у него рендерится сцена, которая реально рендерится только когда что-то изменилось?В общем случае, действительно, обновление данных стоит выносить в отдельный поток. Но мы-то пишем компонент, который должен быть готов к разным ситуациям. И наличие плавных анимаций, не зависящих от нагруженности main thread-a — важный момент. «Когда что-то изменилось» включает в себя и воспроизведение анимаций, естественно.
Более того, подход разделения на main thread и rendering thread — это, мягко говоря, не наше изобретение, это best practice. Например, так работает Apple CoreAnimation.
Не работал с iOS, не могу ни подтвердить ни опровергнуть, но глядя на эти «проблемы» немного сомневаюсь что на iOS main thread блокируется наглухо (не приходят евенты ни таймеров, ни перерисовки)В описанной ситуации — наглухо.
Поясните, что значит «привязка к сетке в вершинном шейдере» и какую такую информацию должны иметь вершины?Например что вершину можно двигать вправо-влево/вверх-вниз на пол пикселя. И двигать как-то так:
coord.xy = round(coord.xy*0.5)*2.0;
Ну и именно из-за того, что стенка имеет одни и те же координаты с боковинами, происходит ситуация «борьбы» в z-буфере, потому что на этапе растеризации у фрагментов разных полигонов оказывается одинаковая глубина.Ок, но боковина почему у вас имеет другие координаты? Если бы она имела те же координаты — не было бы z-fiting-а. Вы мне сейчас рассказываете те вещи, которые я итак прекрасно знаю, т.к. я уже лет 8 работаю с DirectX и OpenGL. Есть кстати такая техника, называется Depth prepass. Это когда сцену сначала рисуют только в буфер глубины. Потом эту же сцену рисуют снова, но уже в колор буфер без записи в глубину но с тестом глубины glDepthFunc(GL_EQUAL). Если бы на этапе растеризации были бы погрешности — оно бы вообще через пиксель все рисовалось, и просто файтилось бы.
А то что вы привели пример с блендера — это да, погрешность на этапе интерполяции. Пиксель же у нас квадратный, и глубина для него считается в центре, а проекция — перспективная. Но у вас то другая ситуация. У вас стенка может иметь те же координаты, что и кольцо вокруг. Но у вас она имеет «свои» координаты. Так чот эта погрешность создана вами, на CPU.
Так во внешнем виде её особой и нет. Есть разница в производительности, потому что наш АА можно быстро отключить на период проигрывания анимации и включить обратно, когда картинка «устаканилась». Кроме того, у нас же не только постпроцессинговый, у нас гибрид SSAA и FXAA.У меня просто удивительно так совпало наверное. Сейчас пилю рендер, в нем есть рейтрейсинг, ну и из-за этого края, отрезанные рейтрейсингом не сглаживаются MSAA. Мне не досуг было думать, и я в качестве временного решения впихнул «гибрид» SSAA и FXAA. :) Вот так совпало, да. Потому что у меня однопиксельные линии есть (FXAA не подойдет), поэтому я делаю SSAA, линии становятся двухпиксельными, и я прохожу FXAA.
Но производительность SSAA ни в какие ворота не лезет, по сравнению с производительностью MSAA. Так что я не знаю откуда у вас там прирост. Но если оно действительно так, то это очень круто, и лучше бы вы поделились с сообществом этой технологией, чем постом выше.
Тоже когда-то грезил рендером в отдельном потоке. Но на практике оказалось — себе дороже. Отдельный поток нужен, если у тебя например тяжелая физика и относительно тяжелый рендер в одном потоке, и то только пожалуй для того, чтобы тяжелой физике было легче. Я в курсе что это не ваше изобретение, но в данном случае я не вижу уместности такому огромному велосипеду.
Например что вершину можно двигать вправо-влево/вверх-вниз на пол пикселя. И двигать как-то так:Если coord.xy в экранных координатах — да. Но у нас-то задача выровнять по пикселям и то, что в экранных, и то, что в координатах сцены (а там у нас изначальные значения от –1.0 до 1.0, и округление уведёт их в 0). Суть в том, что линии сетки существуют в пространстве графика, то есть в системе координат сцены. А риски на оси — в пространстве экрана, потому что они торчат за пределы области графика (а эту область мы ограничиваем scissor-ом). И тут важно не только, чтобы и те, и другие были выровнены по сетке пикселей, но и чтобы они совпадали пиксель в пиксель друг с другом (то есть чтобы риски были «продолжением» линий сетки).
coord.xy = round(coord.xy*0.5)*2.0;
Ок, но боковина почему у вас имеет другие координаты? Если бы она имела те же координаты — не было бы z-fiting-а. Вы мне сейчас рассказываете те вещи, которые я итак прекрасно знаю, т.к. я уже лет 8 работаю с DirectX и OpenGL. Есть кстати такая техника, называется Depth prepass. Это когда сцену сначала рисуют только в буфер глубины. Потом эту же сцену рисуют снова, но уже в колор буфер без записи в глубину но с тестом глубины glDepthFunc(GL_EQUAL). Если на этапе растеризации были бы погрешности — оно бы вообще через пиксель все рисовалось, и просто файтилось бы.Во-первых, координаты стенки именно что те же самые. А во-вторых, хорошо, что вам повезло так и не столкнуться с такой вот ситуацией, когда то, что вы называете погрешностью интерполяции, возникает на границе перпендикулярных полигонов. Но это же не значит, что так в принципе не бывает.
А то что вы привели пример с блендера — это да, погрешность на этапе интерполяции. Пиксель же у нас квадратный, и глубина для него считается в центре, а проекция — перспективная. Но у вас то другая ситуация. У вас стенка может иметь те же координаты, что и кольцо вокруг. Но у вас она имеет «свои» координаты. Так чот эта погрешность создана вами, на CPU.
У меня просто удивительно так совпало наверное. Сейчас пилю рендер, в нем есть рейтрейсинг, ну и из-за этого края, отрезанные рейтрейсингом не сглаживаются MSAA. Мне не досуг было думать, и я в качестве временного решения впихнул «гибрид» SSAA и FXAA. :) Вот так совпало, да. Потому что у меня однопиксельные линии есть (FXAA не подойдет), поэтому я делаю SSAA, линии становятся двухпиксельными, и я прохожу FXAA.По сути, основную идею вы сами озвучили: действительно, сначала делаем SSAA, затем поверх него FXAA. Общая производительность в целом получается такой же, как у MSAA, но выигрыш в том, что на периоды воспроизведения анимации мы отключаем антиалиасинг вообще. Поэтому у пользователя складывается ощущение плавности движений — но, конечно, ценой того, что пока сцена в движении, она не сглаживается.
Но производительность SSAA ни в какие ворота не лезет, по сравнению с производительностью MSAA. Так что я не знаю откуда у вас там прирост. Но если оно действительно так, то это очень круто, и лучше бы вы поделились с сообществом этой технологией, чем постом выше.
Насчёт производительности SSAA: по нашим замерам, производительность SSAA лишь чуть-чуть меньше, чем у MSAA, можно сказать, такая же. Но у нас нет рейтрейсинга, возможно, с ним ситуация поменяется. Вот, для примера, цифры одного из тестов: iPad3, сцена 1 600 000 треугольников, освещение по Фонгу (то есть рендеринг сам по себе простой). Без АА: 15 fps, MSAA: 5 fps, SSAA: 4.5 fps, FXAA: 8 fps, наш гибрид (когда он включен): 4.5 fps.
Тоже когда-то грезил рендером в отдельном потоке. Но на практике оказалось — себе дороже. Отдельный поток нужен, если у тебя например тяжелая физика и относительно тяжелый рендер в одном потоке, и то только пожалуй для того, чтобы тяжелой физике было легче. Я в курсе что это не ваше изобретение, но в данном случае я не вижу уместности такому огромному велосипеду.Ну да, мультитред — это сложно :) Но как раз тут это оказалось важно. Особенно для мобилок, которые, с одной стороны, довольно маломощные, с другой — во многих по два и больше ядер, так что два потока там хорошо уживаются и дают ощутимый для пользователя результат. Ну и велосипед — хотя, конечно, и не двадцать строчек кода — не такой уж и огромный :-)
Если coord.xy в экранных координатах — да. Но у нас-то задача выровнять по пикселям и то, что в экранных, и то, что в координатах сцены (а там у нас изначальные значения от –1.0 до 1.0, и округление уведёт их в 0). Суть в том, что линии сетки существуют в пространстве графика, то есть в системе координат сцены. А риски на оси — в пространстве экрана, потому что они торчат за пределы области графика (а эту область мы ограничиваем scissor-ом). И тут важно не только, чтобы и те, и другие были выровнены по сетке пикселей, но и чтобы они совпадали пиксель в пиксель друг с другом (то есть чтобы риски были «продолжением» линий сетки).Простите, но вы сейчас говорите чушь, которая только подтверждает, что никакого понимания процесса рендеринга, у вас нет. Как и понимания линейной алгебры. Выравнивать по пиксельной сетке нужно после умножения на матрицу проекции. После этого умножения получаются однородные координаты, эти однородные координаты нужно перевести в декарторвы координаты куба [-1;1] (coord.xy /= coord.w), по которому будет растеризация, эти координаты куба перевести в координаты пикселей [0;ViewPortSize] (coord.xy += 1.0; coord.xy *= ViewPortSize*0.5), выровнять по пиксельной сетке (coord.xy = round(coord.xy*0.5)*2.0), перевести все это дело обратно: ( coord.xy /= ViewPortSize*0.5; coord.xy -= 1.0; coord.xy *= coord.w).
На всякий случай предупреждаю, если вы сейчас скопируете этот код, и попытаетесь его использовать — далеко не все «заработает» как надо, потому что у вас изначально данные не выровнены как надо (см. объяснение в первом комментарии к однопиксельной линии. Если рядом будет двухпиксельная, а рисовать вы их будете по одним и тем же координатам, линии начнут ездить друг относительно друга, этого легко можно избежать, если немного подумать).
А прежде чем браться за такую работу, нужно как минимум изучить линейную алгебру и графический конвеер. И я не думаю мне пора заканчивать давать подобные примеры кода, потому что получаю ответы в духе: «я скопировал твою формулу, оно округлило все в 0, не работает».
Во-первых, координаты стенки именно что те же самые. А во-вторых, хорошо, что вам повезло так и не столкнуться с такой вот ситуацией, когда то, что вы называете погрешностью интерполяции, возникает на границе перпендикулярных полигонов. Но это же не значит, что так в принципе не бывает.Строим правильный меш, и так гарантирванно не бывает. Строим не правильный меш — бывает. Вы построили неправильный меш.
Без АА: 15 fps, MSAA: 5 fps, SSAA: 4.5 fps, FXAA: 8 fps, наш гибрид (когда он включен): 4.5 fps.Ну то есть не совпадает по производительности, как у вас в статье, а медленнее.
А еще по фразе
сцена 1 600 000 треугольниковпонятно, что вы не понимаете преимущество MSAA над SSAA, как и то, что при таком количестве геометрии MSAA запросто вырождается в SSAA.
Ну и MSAA так же можно включать и выключать на лету. Вы не разобрались как
p.s. А если смотреть на вашу разработку как на библиотеку для других разработчиков — я бы никогда не приобрел её после прочтения данного поста, в особенности глядя на все эти шаманства с 10000.0. Такая вот у вас своеобразная антиреклама получилась
Вы как-то очень легко рассуждаете о том, что мы знаем, а чего нет. Я же не говорю, например, что вы не знаете способы оптимизации и структурирования приложений, пока вы так упорно не соглашаетесь, что разделять рендеринг и main thread — это хороший тон.
Вы обвиняете нас в использовании «некрасивых костылей», а сами при этом предлагаете костыли едва ли не хуже. Да, после развёрнутого объяснения стало понятно, какой именно ужас вы имеете в виду. И да, этот ужас — при должном старании — тоже будет работать. При этом, однако, нагрузка ляжет на шейдер. Напоминаю, что мы ориентируемся на мобильные устройства, на которых дополнительные инструкции в коде шейдера крайне нежелательны. И лучше уж сделать костыли выравнивания один раз на меш, как у нас, чем повторять их на каждый кадр. Ваше решение, если его допилить как надо, имеет право на существование, но в этой конкретной ситуации не подходит.
Вы ставите диагноз по фотографии, утверждаете: «у вас неправильный меш», не потрудившись проверить подобную ситуацию, опираясь только на свой опыт — и, кстати, не потрудившись поинтересоваться опытом собеседника. Из-за этого беседа сводится к «я д’Артаньян, а вы — лоботрясы».
Насчёт понимания/непонимания преимущества MSAA над SSAA — при чём тут это вообще? Кроме того, по крайней мере на мобильных устройствах, падение производительности в три раза при MSAA — это довольно постоянная вещь, на сцене с меньшим количеством геометрии результат тот же.
Что касается производительности — да, наш способ медленнее MSAA. В итоге, пользователь получает на выходе 4.5 FPS против 5 FPS. Офигенно критичная разница. Ок, пускай так. Только наш АА выключается автоматом и быстро, а включать и выключать MSAA на лету можно, но это требует заметно больше времени. Особенно хватает нюансов с этим на андроиде. Да и не только там, на iOS тоже. У вас, видимо, какая-то специальная параллельная реальность, где ни отключение MSAA, ни отрисовка отдельных кадров не требуют времени, а мобильные устройства, вероятно, ничем не отличаются от десктопа. При этом вы сами сказали, что не работали с iOS — но утверждаете, что там всё есть, мы «просто не разобрались, как с ним работать».
Вообще, понятно что решать одну и ту же задачу (как, например, в нашем случае — отрисовка «опрятных» графиков) можно по-разному. В статье мы просто хотели показать, что иногда приходится запиливать некрасивые костыли во имя красивого результата.
Вы обвиняете нас в использовании «некрасивых костылей», а сами при этом предлагаете костыли едва ли не хуже. Да, после развёрнутого объяснения стало понятно, какой именно ужас вы имеете в виду. И да, этот ужас — при должном старании — тоже будет работать. При этом, однако, нагрузка ляжет на шейдер. Напоминаю, что мы ориентируемся на мобильные устройства, на которых дополнительные инструкции в коде шейдера крайне нежелательны. И лучше уж сделать костыли выравнивания один раз на меш, как у нас, чем повторять их на каждый кадр. Ваше решение, если его допилить как надо, имеет право на существование, но в этой конкретной ситуации не подходит.
Вы ставите диагноз по фотографии, утверждаете: «у вас неправильный меш», не потрудившись проверить подобную ситуацию, опираясь только на свой опыт — и, кстати, не потрудившись поинтересоваться опытом собеседника. Из-за этого беседа сводится к «я д’Артаньян, а вы — лоботрясы».
Насчёт понимания/непонимания преимущества MSAA над SSAA — при чём тут это вообще? Кроме того, по крайней мере на мобильных устройствах, падение производительности в три раза при MSAA — это довольно постоянная вещь, на сцене с меньшим количеством геометрии результат тот же.
Что касается производительности — да, наш способ медленнее MSAA. В итоге, пользователь получает на выходе 4.5 FPS против 5 FPS. Офигенно критичная разница. Ок, пускай так. Только наш АА выключается автоматом и быстро, а включать и выключать MSAA на лету можно, но это требует заметно больше времени. Особенно хватает нюансов с этим на андроиде. Да и не только там, на iOS тоже. У вас, видимо, какая-то специальная параллельная реальность, где ни отключение MSAA, ни отрисовка отдельных кадров не требуют времени, а мобильные устройства, вероятно, ничем не отличаются от десктопа. При этом вы сами сказали, что не работали с iOS — но утверждаете, что там всё есть, мы «просто не разобрались, как с ним работать».
Вообще, понятно что решать одну и ту же задачу (как, например, в нашем случае — отрисовка «опрятных» графиков) можно по-разному. В статье мы просто хотели показать, что иногда приходится запиливать некрасивые костыли во имя красивого результата.
Вы как-то очень легко рассуждаете о том, что мы знаем, а чего нет. Я же не говорю, например, что вы не знаете способы оптимизации и структурирования приложений, пока вы так упорно не соглашаетесь, что разделять рендеринг и main thread — это хороший тон.Даже если рендеринг просто делает glClear?
Вы обвиняете нас в использовании «некрасивых костылей», а сами при этом предлагаете костыли едва ли не хуже. Да, после развёрнутого объяснения стало понятно, какой именно ужас вы имеете в виду. И да, этот ужас — при должном старании — тоже будет работать.Это не ужас, и не костыли. Ваши 10000.0 легко расползутся в другом месте. И в данный момент они работают только для конкретно этой рамочки, и только для определенного круга разрешений. То что я предложил — гарантированно выравнивает все линии по пиксельной секте вне зависимости от разрешения, скроллинга, зума. Оно не будет показывать муть в подобных гридах:
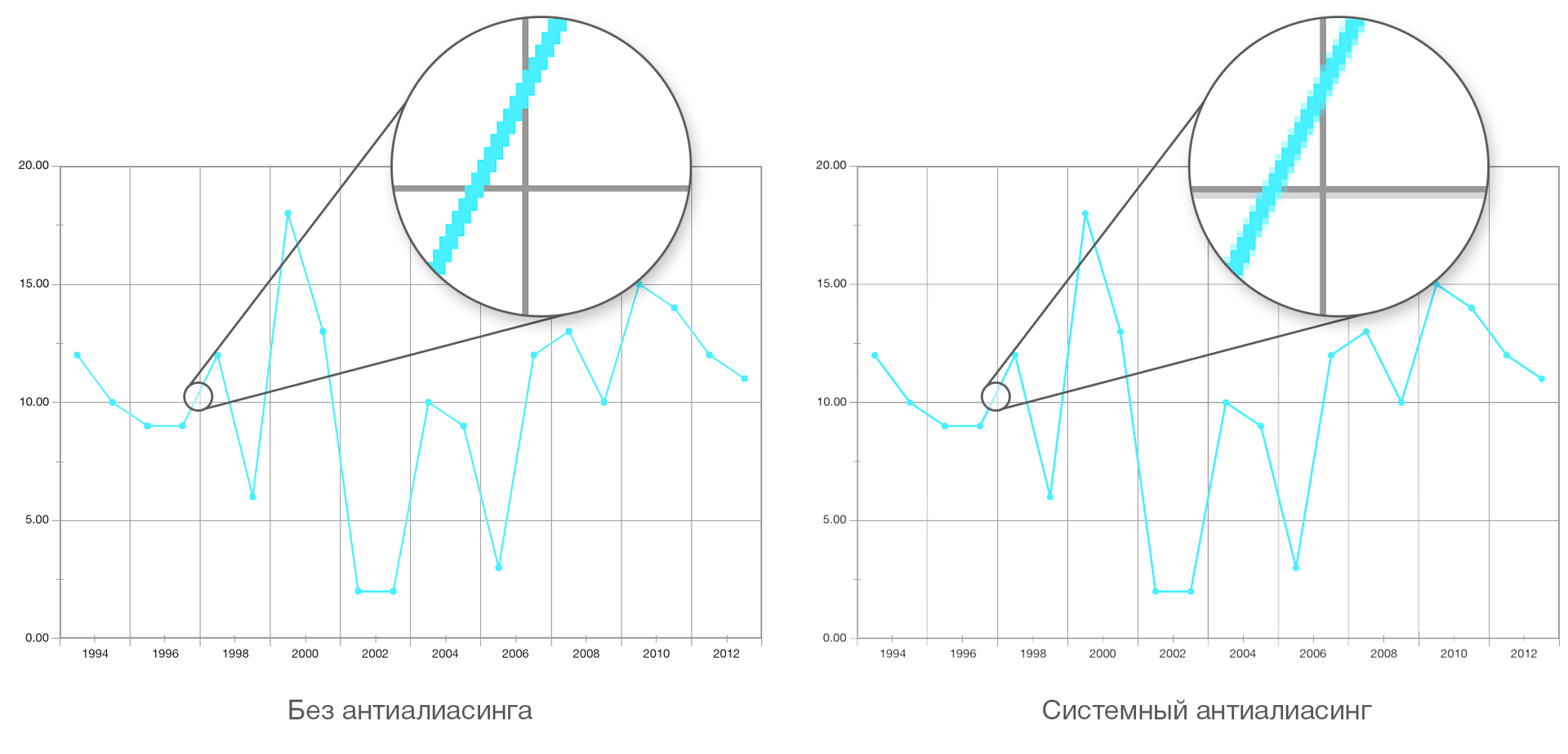 при использовании сглаживания, а вам, чтобы это побороть — придется для каждой линии грида подобрать свои N тысяч.
при использовании сглаживания, а вам, чтобы это побороть — придется для каждой линии грида подобрать свои N тысяч.Напоминаю, что мы ориентируемся на мобильные устройства, на которых дополнительные инструкции в коде шейдера крайне нежелательны.Вот этот аргумент особенно смешно звучит в контексте того, что вы используете GL_LINES. GL_LINES на порядок медленнее, чем те преобразования, которые я привел. Кроме того преобразования в координаты вьюпорта — необходимы для рисования линий через треугольники. Так что эти преобразования в любом случае делать.
Вы ставите диагноз по фотографии, утверждаете: «у вас неправильный меш», не потрудившись проверить подобную ситуацию, опираясь только на свой опыт — и, кстати, не потрудившись поинтересоваться опытом собеседника. Из-за этого беседа сводится к «я д’Артаньян, а вы — лоботрясы».В данном случае фотографии достаточно. Но вы же не верите, вам же доказательтсва надо, ведь так? Вот на скорую руку (но по факту убил полтора часа времени) набросал семпл:
 Невероятно! Ничего нигде не торчит. Но если бы я просто залил скриншот — никто бы мне не поверил. Поэтому вот демка в которой можно покрутить правой кнопкой мыши диаграмму, погенерировать новую, а так же залелеть внутрь, и убедиться что все стенки на месте.
Невероятно! Ничего нигде не торчит. Но если бы я просто залил скриншот — никто бы мне не поверил. Поэтому вот демка в которой можно покрутить правой кнопкой мыши диаграмму, погенерировать новую, а так же залелеть внутрь, и убедиться что все стенки на месте.Насчёт понимания/непонимания преимущества MSAA над SSAA — при чём тут это вообще? Кроме того, по крайней мере на мобильных устройствах, падение производительности в три раза при MSAA — это довольно постоянная вещь, на сцене с меньшим количеством геометрии результат тот же.
Что касается производительности — да, наш способ медленнее MSAA. В итоге, пользователь получает на выходе 4.5 FPS против 5 FPS. Офигенно критичная разница.Расскажите, как вы понимаете принцип работы MSAA, и объясните, почему в качестве теста производительности между SSAA и MSAA вы выбрали сцену с 1 600 000 треугольников?
Только наш АА выключается автоматом и быстро, а включать и выключать MSAA на лету можно, но это требует заметно больше времени. Особенно хватает нюансов с этим на андроиде. Да и не только там, на iOS тоже. У вас, видимо, какая-то специальная параллельная реальность, где ни отключение MSAA, ни отрисовка отдельных кадров не требуют времени, а мобильные устройства, вероятно, ничем не отличаются от десктопа.И расскажите, как вы видите включение/отключение MSAA, и в чем принципиальная разница включения/отключения MSAA от включения/отключения вашего SSAA?
В статье мы просто хотели показать, что иногда приходится запиливать некрасивые костыли во имя красивого результата.В статье вы показали, что вообще не умеете работать ни с плавающей точкой, ни линейной алгеброй. Из-за этого вы запилили некрасивые костыли, которые на самом деле никакой красивости не дали. Они просто там есть:

Даже если рендеринг просто делает glClear?Может быть, всё-таки стоит говорить о реальных вещах?
Расскажите, как вы понимаете принцип работы MSAA, и объясните, почему в качестве теста производительности между SSAA и MSAA вы выбрали сцену с 1 600 000 треугольников?
И расскажите, как вы видите включение/отключение MSAA, и в чем принципиальная разница включения/отключения MSAA от включения/отключения вашего SSAA?Да, чем больше геометрии, тем MSAA медленнее. Ну и что? Мы тестировали на пиковой нагрузке. Вот другая ситуация: iPad 1, 1000 треугольников, но довольно нагруженный шейдер отрисовки. MSAA даёт 14 fps, наш — 6 fps. Но при этом наш почти мгновенно выключается, так что все движения — на скорости 60 fps.
Включение/выключение MSAA на мобильных устройствах требует пересоздания рендербуферов. Кроме того, на разных платформах это будет делаться по-разному, что усложняет портирование. Наш механизм работает внутри движка, так что отключение оказывается удобнее. Ну и быстрее, так как нам не нужно изменять основной рендербуфер — что особенно актуально на андроидах, где пересоздание контекста может занимать до секунды (!).
Невероятно! Ничего нигде не торчит. Но если бы я просто залил скриншот — никто бы мне не поверил. Поэтому вот демка в которой можно покрутить правой кнопкой мыши диаграмму, погенерировать новую, а так же залелеть внутрь, и убедиться что все стенки на месте.Нда, отличная демка, порадовавшая нескучной надписью «Access violation at address 00000000» при запуске. Пришлось смотреть, что же мы делаем не так. Проблема оказалась в следующем: получили вы адреса gl*EXT функций, отлично. Но, видимо, вы так спешили, что написать проверку их на NULL уже не успели. Если в вашем OpenGL драйвере существует функция glNamedBufferDataEXT, это не значит, что она есть всегда и у всех. Конец немного предсказуем. Ладно, плохие драйверы, бывает. Запустим демку на свежем компьютере… запустилась, но показывает красивый чёрный экран. Что на этот раз? Не линкуются шейдеры…
Бог троицу любит, и на третьем компьютере она-таки запустилась. На первый взгляд всё в порядке, и торчащих пикселов не видно. Объясняется это просто: у вас используется 24-битный буфер глубины, у которого проблем с точностью практически не возникает. У нас в режиме совместимости со старыми девайсами используется 16-битный: спецификация OpenGL ES 2.0 не гарантирует, что более точный буфер глубины будет доступен. На iOS с этим всё в порядке, а вот на старых андроидах бывает, что и не бывает.
Но это только на первый взгляд. Вращаем барабан… и через пару десятков секунд выпадает сектор «приз»:
И снова:
и снова:
Оригиналы скриншотов: раз, два, три, четыре, пять, шесть.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Из-за этого вы запилили некрасивые костыли, которые на самом деле никакой красивости не дали. Они просто там естьВ размытости слов «Наш антиалиасинг» тоже наши костыли виноваты? Все претензии к habrastorage, пережавшему вот эту картинку. Вообще, там прекрасно видны волны вокруг прямых линий, уж можно было догадаться, что картинка пожата.
{kind=link}
Вы почему-то постоянно забываете о том, что библиотека используется и на мобильных девайсах (а по факту, в основном на них). Упорно твердите, что причина дырок между полигонами — «неправильный» меш, забывая о том, что не у всех есть такие красивые и глубокие буферы. Рассказывая об антиалиасинге, не вспоминаете о том, что старые андроиды по производительности ближе к нокии 3310, чем к iphone 5. Да даже ваша собственная демка для вашей собственной винды демонстрирует, что вы оперируете очень малым количеством ситуаций.
В статье вы показали, что вообще не умеете работать ни с плавающей точкой, ни линейной алгеброй.Прежде, чем разговаривать в таком тоне, нужно как минимум изучить линейную алгебру и графический конвеер (ц).
Вы, конечно, опытный теоретик, и очень убедительно учите всех жизни, но критерием истины по-прежнему остаётся практика. И эта самая практика прекрасно показала, чего стоят восемь лет вашего опыта.
Да, чем больше геометрии, тем MSAA медленнее. Ну и что? Мы тестировали на пиковой нагрузке. Вот другая ситуация: iPad 1, 1000 треугольников, но довольно нагруженный шейдер отрисовки. MSAA даёт 14 fps, наш — 6 fps. Но при этом наш почти мгновенно выключается, так что все движения — на скорости 60 fps.Ну то есть я вас убедил таки проверить на более реальных количествах данных, а не на абстрактных 1 600 000?
Включение/выключение MSAA на мобильных устройствах требует пересоздания рендербуферов. Кроме того, на разных платформах это будет делаться по-разному, что усложняет портирование. Наш механизм работает внутри движка, так что отключение оказывается удобнее. Ну и быстрее, так как нам не нужно изменять основной рендербуфер — что особенно актуально на андроидах, где пересоздание контекста может занимать до секунды (!).Вы уверены что не путаете рендербуфер с контекстом? Зачем рендербуфер пересоздавать? Почему нельзя хранить его, и просто не рисовать в него?
Нда, отличная демка, порадовавшая нескучной надписью «Access violation at address 00000000» при запуске. Пришлось смотреть, что же мы делаем не так. Проблема оказалась в следующем: получили вы адреса gl*EXT функций, отлично. Но, видимо, вы так спешили, что написать проверку их на NULL уже не успели. Если в вашем OpenGL драйвере существует функция glNamedBufferDataEXT, это не значит, что она есть всегда и у всех. Конец немного предсказуем. Ладно, плохие драйверы, бывает. Запустим демку на свежем компьютере… запустилась, но показывает красивый чёрный экран. Что на этот раз? Не линкуются шейдеры…Да, печально. Код создавался на базе другого, использующего OpenGL 3.3. Я понимаю, что вы с разбегу стали его тестить на всем всем всем, чтобы показать, насколько я некомпетентен, и что меня не хватило (после убитых полутора часов на диаграмму), на обработку того, что на девайсе не поддерживается GL3.3 и не поддерживаются никакие расширения, которые необходимы.
Бог троицу любит, и на третьем компьютере она-таки запустилась.Ну хорошо, в 2014 году вы нашли компьютер с поддержкой OGL3.3. и даже с установленными драйверами.
На первый взгляд всё в порядке, и торчащих пикселов не видно. Объясняется это просто: у вас используется 24-битный буфер глубины, у которого проблем с точностью практически не возникает.Ну да ну да. Вы убедили меня собрать демку с 16 битным буфером глубины. Найдете существенную разницу?
спецификация OpenGL ES 2.0 не гарантирует, что более точный буфер глубины будет доступен.А можно пруф? Очень интересно где спецификация гарантирует 16 битный буфер глубины? Потому что на десктопах ситуация ровно противоположная.
Вращаем барабан… и через пару десятков секунд выпадает сектор «приз»:Дада, а потом смотрим на мою диаграмму, смотрим на свою, считаем разницу в пикселях. 20 секунд кручения ради 1 пикселя, против десятков пикселей в каждом фрейме. Как вы объясните столь огромную разницу? Точность глубины? Вон демка на 16бит есть выше.
В размытости слов «Наш антиалиасинг» тоже наши костыли виноваты? Все претензии к habrastorage, пережавшему вот эту картинку. Вообще, там прекрасно видны волны вокруг прямых линий, уж можно было догадаться, что картинка пожата.Графический процессор дает некотролируемые погрешности. Хабрасторадж неконтролируемо пережимает картинки. Прям все против вас :)
Вы почему-то постоянно забываете о том, что библиотека используется и на мобильных девайсах (а по факту, в основном на них). Упорно твердите, что причина дырок между полигонами — «неправильный» меш, забывая о том, что не у всех есть такие красивые и глубокие буферы. Рассказывая об антиалиасинге, не вспоминаете о том, что старые андроиды по производительности ближе к нокии 3310, чем к iphone 5. Да даже ваша собственная демка для вашей собственной винды демонстрирует, что вы оперируете очень малым количеством ситуаций.Демка на меелкий буфер выше. А по поводу антиалясинга — это вообще класс. SSAA — последнее, что бы я стал делать даже на десктопах, не говоря уже про мобильники. Вы знаете как дать в пах производительности (1000 треугольников, MSAA даёт 14 fps, наш — 6 fps), но при этом кичитесь тем, что вам так важна эта производительность. Ну а моя демка оперирует малым количеством ситуаций, потому что это демка. Я итак убил на нее полтора часа. Еще полтора я на неё убивать не собираюсь, чтобы она запускалась на мыльницах.
Вы, конечно, опытный теоретик, и очень убедительно учите всех жизни, но критерием истины по-прежнему остаётся практика. И эта самая практика прекрасно показала, чего стоят восемь лет вашего опыта.Да, я восемь лет теоретизировал тут сидел, так все и было.
Прежде, чем разговаривать в таком тоне, нужно как минимум изучить линейную алгебру и графический конвеер (ц).Я уже просто понял, что вам все божья роса. Не вижу смысла продолжать данный диалог. Изначально цель была донести, что вам нужно изучать сабж, прежде чем такие статьи на хабре писать, а уж тем более продавать коммерческий продукт (хотя я знаю, и не такое продается). Цель не удалась, вы почему-то стали убеждать меня, что я не прав, вот и вышел такой тон. Но я надеюсь кто-то прочтет это, и не купит ваш продукт. Тогда от данной переписки будет хоть какая-то польза.
В недрах графического процессора возникают погрешности, которые проявляются в процессе растеризации, каждый раз по-разному. Отладить это практически невозможно, так как невозможно ни предсказать наличие погрешности, ни повлиять на механизм растеризации, в котором она возникает. (ц)
Но системный алгоритм сглаживания MSAA, доступный на любой современной платформе, имеет три серьёзных проблемы: 2. Затруднение мультиплатформенности (ц)
В общем меня совесть замучила. Извиняюсь за весь этот тон. Немного вышел из себя, т.к. по факту вижу «детские» ошибки при работе с рендером, а мне доказывают что я не прав. :)
Вы знаете как дать в пах производительности (1000 треугольников, MSAA даёт 14 fps, наш — 6 fps), но при этом кичитесь тем, что вам так важна эта производительность.
Вы правда не понимаете, что 6 fps это статическая сцена? Будь там хоть 1 fps, разницы никакой, это картинка. В момент, когда пользователь пальцем начинает неистово вращать что-то, их сглаживание быстро отключается и получается 60 fps в динамике?
Я то понимаю. Смотрите оригинальную статью:
Оба пункта мимо. А сглаживание отключается с такой же скоростью. Просто автор статьи не знает как.
1. Снижение производительности: по нашим наблюдениям, на мобилках она падает в среднем в три раза, и при воспроизведении анимации на сложных сценах появляются ощутимые лаги.
2. Затруднение мультиплатформенности (а мы за ней гоняемся): на разных платформах системный антиалиасинг включается по-разному, мы же пытаемся по максимуму унифицировать код.
Оба пункта мимо. А сглаживание отключается с такой же скоростью. Просто автор статьи не знает как.
Я не настоящий сварщик, надо сказать. К графике отношения не имею совершенно никакого, зато с 2009 года пишу под мобильники и мне кажется, вы игнорируете неприлично торчащий факт, что это библиотека для мобильных устройств.
Навскидку: OpenGL ES ≠ OpenGL. Более того, на разных операционных системах версии OpenGL ES могут оказаться неожиданно разными.
Даже если игнорировать эту неприятность, вы ведь знаете, что мобильные устройства это сложная среда? Например если вы пишете Android приложение, вам надо бриджить все вызовы к нативному коду через JNI? То есть чтобы отключить системное сглаживание надо сходить в JVM и вернуться обратно. На iOS ситуация другая, там всё проще немного, но судя по комментариям пацаны активно пилят поддержку как минимум Android, то есть таки да — отключается долго и по-разному на разных платформах почти наверняка. Я представления не имею, как это делается на Linux, Windows, Blackberry 10, Bada и прочих странных штуках, подозреваю что везде есть свои странности. Особенно учитывая, что гугление на тему разрядности буфера глубины на первой же странице выдаёт некий пост с таким приветствием:
По поводу снижения производительности я вообще не понял, даже если я, далёкий от графики вижу, что 60 fps это больше, чем 14 fps.
А если в целом, вы с лёгкостью можете поставить тут всех на место, просто рассказав, а как же надо всё это делать с примерами не для GL3.3, а для OpenGL ES, iOS и Android. Причём очень желательно для OpenGL ES 2.0 и 3.0. И чтоб портабельно. Что-то мне подсказывает, что уважаемый топикстартер всё же не в первый раз видит матчасть.
Навскидку: OpenGL ES ≠ OpenGL. Более того, на разных операционных системах версии OpenGL ES могут оказаться неожиданно разными.
Даже если игнорировать эту неприятность, вы ведь знаете, что мобильные устройства это сложная среда? Например если вы пишете Android приложение, вам надо бриджить все вызовы к нативному коду через JNI? То есть чтобы отключить системное сглаживание надо сходить в JVM и вернуться обратно. На iOS ситуация другая, там всё проще немного, но судя по комментариям пацаны активно пилят поддержку как минимум Android, то есть таки да — отключается долго и по-разному на разных платформах почти наверняка. Я представления не имею, как это делается на Linux, Windows, Blackberry 10, Bada и прочих странных штуках, подозреваю что везде есть свои странности. Особенно учитывая, что гугление на тему разрядности буфера глубины на первой же странице выдаёт некий пост с таким приветствием:
Well, welcome to OpenGL world. :)
I hope you will survive extension hell. :)
По поводу снижения производительности я вообще не понял, даже если я, далёкий от графики вижу, что 60 fps это больше, чем 14 fps.
А если в целом, вы с лёгкостью можете поставить тут всех на место, просто рассказав, а как же надо всё это делать с примерами не для GL3.3, а для OpenGL ES, iOS и Android. Причём очень желательно для OpenGL ES 2.0 и 3.0. И чтоб портабельно. Что-то мне подсказывает, что уважаемый топикстартер всё же не в первый раз видит матчасть.
То есть чтобы отключить системное сглаживание надо сходить в JVM и вернуться обратно.Т.к. автор статьи использует самопальный SSAA, то эмулирует он его через Framebuffer, и делает рендер в текстуру. Отключение такого SSAA — просто перестаем ренедерить в FBO, рендерим сразу в окно, это очень быстро. Но MSAA точно так же можно рендерить в FBO. И такой MSAA включается одинаково на всех платформах. В общем нет вообще никакой принципиальной разницы, кроме того, что нельзя напрямую постпроцессить такую текстуру.
Я прекрасно знаю, где в ОГЛ кроссплатформенный код, а где нет (ибо писал кроссплатформенный рендер под линуксы). Так что отключается и включается MSAA очень быстро, если использовать FBO (который итак используется для SSAA сейчас).
Особенно учитывая, что гугление на тему разрядности буфера глубины на первой же странице выдаёт некий пост с таким приветствиемНаиболее популярный буфер — это Depth24Stencil8. Я еще не встречал девайса, не поддерживающего такого буфера (исключая совсем раритетные карточки, типа S3 Virge GX2). А вот с 16-ти битными буферами даже на десктопах у меня были проблемы. Автор статьи кстати в комментариях утверждает:
У нас в режиме совместимости со старыми девайсами используется 16-битный: спецификация OpenGL ES 2.0 не гарантирует, что более точный буфер глубины будет доступен.и мне очень бы хотелось получить пруф.
не для GL3.3, а для OpenGL ES, iOS и Android. Причём очень желательно для OpenGL ES 2.0 и 3.0. И чтоб портабельно. Что-то мне подсказывает, что уважаемый топикстартер всё же не в первый раз видит матчасть.Ну причем тут вообще OpenGL ES то? Математика же одна и та же. Посмотрите на что больше всего жалуется автор. Что там, в ГПУ неконтролируемые погрешности. Мол вот у меня линии смазаны. Но линии надо просто привязывать по пиксельной сетке в вершинном шейдере. Вы думаете будет какая-то разница между GL3.3 и ES 2.0?
Или торчат перпендикулярные стенки из круговой диаграммы. Я вон выше набросал пример, и даже сделал его на 16-ти битном буфере глубины комментом ниже.
А утверждения что процессор пораждает некотролируемые погрешности — вообще абсурд. Это как бы если бы CPU вместо 2+2 иногда возвращал 3, а иногда 5.
Т.к. автор статьи использует самопальный SSAA, то эмулирует он его через Framebuffer, и делает рендер в текстуру. Отключение такого SSAA — просто перестаем ренедерить в FBO, рендерим сразу в окно, это очень быстро. Но MSAA точно так же можно рендерить в FBO. И такой MSAA включается одинаково на всех платформах. В общем нет вообще никакой принципиальной разницы, кроме того, что нельзя напрямую постпроцессить такую текстуру.
Я прекрасно знаю, где в ОГЛ кроссплатформенный код, а где нет (ибо писал кроссплатформенный рендер под линуксы). Так что отключается и включается MSAA очень быстро, если использовать FBO (который итак используется для SSAA сейчас).Android != GNU/Linux. Мобильное устройство != персональный компьютер. OpenGL != OpenGL ES. Каким образом вы собираетесь создать на ES 2.0 рендербуфер с поддержкой мультисемплинга?
и мне очень бы хотелось получить пруф.www.khronos.org/registry/gles/specs/3.0/es_spec_3.0.2.pdf, страницы 315, 316.
Каким образом вы собираетесь создать на ES 2.0 рендербуфер с поддержкой мультисемплинга?Посмотрел в спецификации ES2.0. Увы, да, там только через экстеншн. Начиная с ES3.0 — InCore.
Так же посмотрел ваш пруф. На самом деле надо приводить не этот пруф, а вот этот:
www.khronos.org/registry/gles/specs/2.0/es_full_spec_2.0.25.pdf стр 117. Но таки да, тут вы правы. Но посмотрите демку выше, с 16 битами. Там нет никакой проблемы с геометрией, как у вас. Т.е. 16 бит больше чем достаточно.
И да, в конексте ES 2.0 мультисемпловый рендер буфер можно создать только через экстеншн.
Сори, промазал веткой, удалено
Sign up to leave a comment.
Рендеринг диаграмм: не так просто, как кажется