Comments 167
Все бы хорошо, но визуально отличить лигатуру == от одинарного = довольно проблематично.
в js будет ещё хуже, там надо == от === отличать
а чем плохо использование символа ≡ для ===?
Можно сделать тройное равно для == и четверное для === :)
наверное только тем что количество знакомест разное. При удалении толи сразу весь ≡ удалять, толи сначала превращать его в ==, и наоборот, при вводе, внезапно два знакоместа превращаются в одно после печати третьего =. А длинное ≡≡≡ будет выглядеть непривычно.
А уж если попадется что-то вроде такого
то вообще пиши пропало. Мало того, что половина парсеров не понимает, что тут регуляка делится на ноль, ещё и лигатура будет неправильно намекать.
/0//0то вообще пиши пропало. Мало того, что половина парсеров не понимает, что тут регуляка делится на ноль, ещё и лигатура будет неправильно намекать.

лигатура же вдвое шире, чем одинарный =. Так что должно быть легко.
Сомневаюсь в этом. Вот пример:

Если строки у вас идут друг под другом, то да, отличить легко. Если у вас между этими строками будет одна пустая — уже сложнее. Следующий код, написанный этим шрифтом, будет тоже тяжел для восприятия:
А уж сколько интересных часов вас ждет в отладчике, если вы в условии вместо == поставите оператор присваивания.
Если строки у вас идут друг под другом, то да, отличить легко. Если у вас между этими строками будет одна пустая — уже сложнее. Следующий код, написанный этим шрифтом, будет тоже тяжел для восприятия:
a = b == c
А уж сколько интересных часов вас ждет в отладчике, если вы в условии вместо == поставите оператор присваивания.
Про Hasklig: Я был уверен, что перечёркнутый знак равенства это !=, а оказалось, что это /=. Незачёт.
В Fira Code вроде получше, но трудности с различием =, == и === остались.
В Fira Code вроде получше, но трудности с различием =, == и === остались.
И всё-таки, когда у '≠' я стираю один символ, и появляется '!', это как-то сбивает.
Учитывая, что в Haskell операция «не равно» пишется именно как
/=, не вижу проблемы.Об этом не знал. Тогда всё ок по данному параметру.
Проблема в том что в Haskell это комбинация «не равно», а во всех других языках — «разделить и присвоить». Поэтому я такую лигатуру делать не стал.
Логично. Но с другой стороны «направление мысли» с использованием лигатур ещё не обрело популярность, а уже споткнулось о подобную проблему.
Просто для разных языков нужны разные шрифты.
Или, если идти дальше, также как для обычных языков есть юникод, также и для программистских языков должен быть свой юникод по штуке на язык.
Или, если идти дальше, также как для обычных языков есть юникод, также и для программистских языков должен быть свой юникод по штуке на язык.
Если он будет «по штуке на язык», то какой в этом вообще смысл?
Юникод потому и юникод, что он один. Он записывает графические символы, а не их семантические особенности. Если лигатура <> выглядит одинаково в Haskell и SQL, то ей будет соответствовать один символ PROGRAMMING LIGATURE <>. Если же /= выглядит по-разному в Haskell и C++, то это будут два отдельных символа: PROGRAMMING LIGATURE /= (NEGATION) и PROGRAMMING LIGATURE /= (DIVISION).
Да, только в юникод не лигатуры заносятся, а символы., Т.е. будет просто символ Negation и символ Division with assignment.
Костыли.
Я уже как-то высказывал мысль, что идеальное решение нехватки спецсимволов (которое ощущается кстати во многих современных языках программирования) — это:
1. консорциуму Unicode нужно выбрать из всего множества символов 25 самых востребованных спецсимволов и назначить (продублировать) их на коды с 0x01 по 0x2F (исключая символы POSIX — пробел, табуляции, null, backspace и переносы строк). Т.е. по сути включить в ASCII. Ибо «управляющие коды для печатных устройств» это уже анахронизм.
2. производителям клавиатур нанести эти дополнительные символы на буквенные клавиши как дополнительные символы, которые можно ввести с каким-то сочетанием шифтовых клавиш.
Конечно будет какой-то переходный период, но зато потом — красота:)
Я уже как-то высказывал мысль, что идеальное решение нехватки спецсимволов (которое ощущается кстати во многих современных языках программирования) — это:
1. консорциуму Unicode нужно выбрать из всего множества символов 25 самых востребованных спецсимволов и назначить (продублировать) их на коды с 0x01 по 0x2F (исключая символы POSIX — пробел, табуляции, null, backspace и переносы строк). Т.е. по сути включить в ASCII. Ибо «управляющие коды для печатных устройств» это уже анахронизм.
2. производителям клавиатур нанести эти дополнительные символы на буквенные клавиши как дополнительные символы, которые можно ввести с каким-то сочетанием шифтовых клавиш.
Конечно будет какой-то переходный период, но зато потом — красота:)
Не стоит недооценивать живучесть «анахронизмов».
И специальные клавитуры для разработчиков. Красотень просто таки.
Это кстати совсем не бредовая мысль. Я бы хотел нажимать скобки и все символы из ряда шифт+цифра одной кнопкой а не комбинацией из двух. Как программисту, это бы мне кучу усилий сэкономило.
Не решает. Нужен еще один дополнительный ряд кнопок. На самом деле программисты это куча народу и если они за правильно сделанной ориентированной на них клавиатурой в очередь выстроятся, вот и бизнес готов. Люди вон страдают что в русской раскладке запятую приходится с шифтом набирать, а у программиста спецсимвол или скобка каждые пять букв встречаются. Если убрать из уравнения шифт, руки просто порхать начнут, и усталость раза в полтора снизится.
Это известно что emacs не для людей xrtc.net/f/pixen/emacs_user_at_work_by_earlcolour-d38aj2x.jpg
Угу, он для программистов в основном. Кстати, один из немногих редакторов, которые позволяют делать всё, не переключаясь на стрелки и мышку.
И, возвращаясь к теме топика, в нём есть prettify-symbols-mode.
И, возвращаясь к теме топика, в нём есть prettify-symbols-mode.
Есть раскладка «русская машинопись».
(а цифры с цифроблока набирать)
(а цифры с цифроблока набирать)
Я использую уже 2 года Logitech G510. Слева три блока по 6 программируемых клавиш. Можно делать отдельные профили для каждого приложения. Если и этого мало, вверху есть переключалка режимов М1 М2 М3. Соответственно в каждом хоткеи могут быть свои. На практике я ни разу с М1 не переключался.
Единственный минус — софт не позволяет перемешивать глобальные и локальные хоткеи. Т.е. нельзя сказать G1-G6 всегда вот это, а G7-G18 в зависимости от приложения. Если создается профиль для приложения, то глобальные хоткеи приходится копировать. Отчасти это компенсируется тем, что профили можно хранить в памяти самой клавиатуры, и будучи единожды настроенными они уже никогда не пропадут.
Единственный минус — софт не позволяет перемешивать глобальные и локальные хоткеи. Т.е. нельзя сказать G1-G6 всегда вот это, а G7-G18 в зависимости от приложения. Если создается профиль для приложения, то глобальные хоткеи приходится копировать. Отчасти это компенсируется тем, что профили можно хранить в памяти самой клавиатуры, и будучи единожды настроенными они уже никогда не пропадут.
Попробуйте клавиатуру полноформатную для кассовых аппаратов. Там есть пара рядов полностью программируемых клавиш…
можно ссылку как это примерно выглядит?
Сейчас в любой более-менее вменяемой геймерской клавиатуре есть возможность перепрограммировать любую клавишу. Но не хотелось бы жертвовать чем-то одним в угоду другого. А дополнительный ряд решает проблему, да. Только выглядит отстойно на тех примерах, что Вы скинули.
github.com/mudasobwa/huya-xkb/ — может быть, вам будет интересно. Привыкаешь месяц, потом радости вагон. Если не кодировать бухгалтерские ведомости.
ээ а как это работает?
Я почитал комментарии, уже увидел, что вы, судя по всему, на винде. Тогда, к сожалению, никак. Для *nix в первой строчке README — установочный скрипт.
Нет, я не спрашиваю как это установить, и нет, я не на винде. Мне интересно как это работает, а там ничего не написано про то что это и зачем: на каждой кнопке нарисовано по 4 символа, как выбирается какой из них будет вводиться? Нужно зажимать клавишу-модификатор?
А, ага, правый альт для третьего и AltGr+Shift для четвертого уровня. Нарисовать такую раскладку — небольшое достижение, я хотел лишь сказать, что 1) мысль набирать скобки и всякие «равно» в одно нажатие приходила не вам одному (я именно про то, что у меня все символы в первом регистре); 2) когда есть репозиторий, откуда оно раскатывается на любую машину в один копи-паст, уже не так страшно привыкать.
Т.е. в этой раскладке просто поменяны цифры и символы на них, цифра с шифтом, а символ без шифта. Возможно это не так уж плохо для программирования, в конце концов цифры не так часто нужны. Но дополнительный ряд это все равно лучше.
Еще закрывающие скобки все сдвинуты во второй регистр, IDE их почти везде сам закрывает. Цифры еще бывают на доп. клавиатуре. Дополнительный ряд сломает 10-пальцевый набор, мне кажется.
Хотя бы потому, что программисты занимаются не только программированием. Т.е. либо набирать цифры с шифтом везде, где они могут пригодиться ещё, либо сделать переключение «режимов», что ещё хуже. Хотя Num pad в данном случае может помочь.
Она ужасна тем, что ставится не отдельно, а патчит «default». Я не мастер в конфигурировании раскладок для Linux, но ведь есть способ добавлять её в качестве отдельной группы «xkb_symbols», не затирая намертво стандартную раскладку?
Спасибо хотя бы за то, что в папке /usr/share/X11/xkb/symbols остаётся резервная копия старой раскладки, чтобы её можно было восстановить.
Но, вообще, за идею спасибо. Я только недавно на Linux переехал и мне нужно было найти способ облегчить ввод некоторых символов (без того, чтобы заниматься пальцевой камасутрой с Compose key). Теперь хотя бы знаю, где можно вносить изменения в раскладку.
Спасибо хотя бы за то, что в папке /usr/share/X11/xkb/symbols остаётся резервная копия старой раскладки, чтобы её можно было восстановить.
Краткая инструкция для тех, кто хочет вернуть стандартную раскладку обратно
cd /usr/share/X11/xkb/symbols
sudo mv -f ru.orig ru
sudo rm /var/lib/xkb/*xkm 2>/dev/null
Но, вообще, за идею спасибо. Я только недавно на Linux переехал и мне нужно было найти способ облегчить ввод некоторых символов (без того, чтобы заниматься пальцевой камасутрой с Compose key). Теперь хотя бы знаю, где можно вносить изменения в раскладку.
Это сознательный выбор: мне нужен был oneliner для раскатки на новую машину. Было два варианта: патчить symbols, или патчить ru. Это же не туториал, это инструмент, сделанный для себя.
Ну, тут вам виднее. Единственное, я бы в инструкции предупреждал других пользователей, что затирается стандартная раскладка, если бы выкладывал подобную вещь в открытый доступ, и давал бы какую-нибудь информацию о том, как всё вернуть обратно.
Кстати, в install.sh (как и в мою краткую инструкцию) можно ещё добавить команду «setxkbmap» — прямо так, без параметров. Тогда изменения раскладки применятся сразу. Без этого, после установки вашей раскладки нужно либо перелогиниться/перезагрузиться, либо сделать какие-нибудь изменения в настройках клавиатуры, чтобы изменённая раскладка подгрузилась в память.
Кстати, в install.sh (как и в мою краткую инструкцию) можно ещё добавить команду «setxkbmap» — прямо так, без параметров. Тогда изменения раскладки применятся сразу. Без этого, после установки вашей раскладки нужно либо перелогиниться/перезагрузиться, либо сделать какие-нибудь изменения в настройках клавиатуры, чтобы изменённая раскладка подгрузилась в память.
Я не планировал «других пользователей» :)
setxkbmap нужен для вычистки какого-нибудь двухуровневого кэша, наверное, мне с ходу сложно себе представить, откуда после rm /var/lib/xkb/*xkm иксы возьмут старую раскладку. На убунту и генту, по крайней мере, никаких плясок не нужно.
setxkbmap нужен для вычистки какого-нибудь двухуровневого кэша, наверное, мне с ходу сложно себе представить, откуда после rm /var/lib/xkb/*xkm иксы возьмут старую раскладку. На убунту и генту, по крайней мере, никаких плясок не нужно.
сложно себе представить, откуда после rm /var/lib/xkb/*xkm иксы возьмут старую раскладку
Из оперативной памяти — наверняка. :)
В Kubuntu без setxkbmap изменения мгновенно не проявляются. Я прямо в окне консоли тестировал. Устанавливал вашу раскладку и тут же в консоли пытался вводить цифры в русской раскладке — вводились цифры. И только после setxkbmap начали вводиться знаки препинания вместо цифр, как и ожидалось от раскладки.
Я думаю, это всё не зависит от разновидности линуксов, это особенности X11. У вас без плясок работает, наверняка, потому, что вы не пробовали пользоваться раскладкой мгновенно после её установки, не отходя от кассы — когда ru или es раскладка уже есть в настройках на момент запуска install.sh. А так, если после install.sh компьютер перезагружался, или был релогин, или если в настройках клавиатуры сделано любое изменение или вообще, что угодно, дёргающее иксы, то всё, конечно же, нормально обновляется.
Но я могу и ошибаться. Всё же, я не так давно окончательно переехал на линукс, хотя и пользовался им эпизодически крайние лет 14-15. Так что, у меня хорошего понимания архитектуры ОС пока ещё нет. :)
Кхм. Я пробовал, конечно, пользоавться сразу, это же раскладка, а не агнрибёрдс. После установки нужно разок щелкнуть переключателем, на моих дистрибутивах он напрямую вызывает setxkbmap. Подозреваю, что в kubuntu переключатель раскладок вводит еще один уровень абстракции, коотрый и занимается кэшированием.
Не хочу рассказывать Вам про широкоиспользуемый telnet, но…
А ещё в эти управляющие символы входят перенос строки \n, любимый в windows возврат каретки \r, знак табуляции \t — это только то, что постоянно встречается любому пользователю, про стандартные терминальные escape, EOT, и прочие bell и backspace даже говорить не хочу (хоть и можно придумать какую-нибудь увлекательную систему, где они не должны быть вводимыми, а должны распознаваться и обрабатываться непосредственно средой).
А ещё в эти управляющие символы входят перенос строки \n, любимый в windows возврат каретки \r, знак табуляции \t — это только то, что постоянно встречается любому пользователю, про стандартные терминальные escape, EOT, и прочие bell и backspace даже говорить не хочу (хоть и можно придумать какую-нибудь увлекательную систему, где они не должны быть вводимыми, а должны распознаваться и обрабатываться непосредственно средой).
Я уточнил, что не все символы 0x00..0x2f, а только те которые не входят в набор POSIX. То есть все, исключая \0, \a, \b, \t, \n, \v, \f, \r.
По поводу телнета… текстовый файл в формате UTF8 тоже содержит коды 0x00 — 0x2f, и ничего.
По поводу телнета… текстовый файл в формате UTF8 тоже содержит коды 0x00 — 0x2f, и ничего.
В текстовой консоли используются все спецсимволы, им соответствуют сочетания клавиш от ctrl+A до ctrl+Z. telnet немного не в тему, он просто передаёт любые байты по сети, а их интерпретация уже осуществляется терминалом. А тут уже некорректен пример про utf-8, если в терминале выставлена соответствующая кодировка, то интерпретация происходит не на уровне отдельных байтов, а на уровне символов, состоящих из нескольких байтов (для utf-8 — от одного до шести вроде).
Да фигня, ASCII не надо менять — unicode уже достаточно хорошо поддерживается везде. Единственная проблема это удобно их вводить. Я использую типографскую раскладку, постоянно и очень естественно ввожу правильные кавычки, длинные тире, стрелки, никаких революций для этого не требуется. В языках кое-где можно сделать биндинги на юникодные символы (Хаскель их нативно понимает, в Clojure def/defmacro и вперед), но это украсит только мой личный код, даже коллег я не уверен что смогу уговорить.
На этом моменте я вставлю свою традиционную фразу о том, что пора бы забить на использование plain text для кода, а перейти на более богатый формат, способный хранить некое подобие AST. Тогда, во-первых, имеем профит с тулзами, которым нужно понимать структуру кода (хотя бы всякие diff/merge), а во-вторых, имеем отдельно модель-представление, т.е. рендерь как хочешь, никаких больше кровавых войн по поводу табов и пробелов или скобок на новой строке. Не говоря, конечно, о возможности вставить диаграмму прямо в коммент.
Грамотно спроектированный язык программирования (т.е. в том числе и с учетом быстрого парсинга для IDE) позволит все это получить и на plain text тоже. Ведь какая разница — plain text, xml, binary xml или что-то подобное — все равно это файл с набором байт. Грамотный plain text будет отличаться от «богатого формата» только тем, что в нем будет использоваться какое-то подмножество символов, а не все множество 0x00..0xFF. А иметь возможность открыть файлик в любом текстовом редакторе это весьма полезно (по крайней мере до тех пор, пока не получил распространение какой-то универсальный двоичный формат для представления произвольных иерархических данных).
В современных языках не хватает в первую очередь скобок — одни только шаблоны на угловых скобках всю красоту ломают. Поэтому такие мысли и возникают — добавить еще пару-тройку скобок, простейшие стрелки и возможно какие-то универсальные математические/типографские символы…
В современных языках не хватает в первую очередь скобок — одни только шаблоны на угловых скобках всю красоту ломают. Поэтому такие мысли и возникают — добавить еще пару-тройку скобок, простейшие стрелки и возможно какие-то универсальные математические/типографские символы…
Редактор в JetBrains MPS видели?
Добавлю, пожалуй, небольшое разъяснение. Вы сейчас рассматривали моё предложение с ортогональной точки зрения. Что-то в духе «зачем нам нужен docx, если он, как и plain text, всего лишь набор байтов? Давайте делать таблички ASCII-символами, а картинки не вставлять вовсе, потому что иметь возможность открыть файлик в любом текстовом редакторе — это весьма полезно».
Да я понял ваше предложение. Я и сам так думал когда-то.
В действительности написание программ в виде текста — это очень сильный стереотип, и разрушить его не так-то просто. Фактически, для этого нужно заново продумать самые фундаментальные вещи — так как даже элементарные операции типа copy и paste там будут (и должны) работать немного не так (а иногда и совсем не так). Программистам свойственно активно править код, нарушая при этом корректную структуру кода. Взяли и убрали закрывающую скобку… взяли и поставили открывающий комментарий, сидим и думаем где-бы его закрыть… В любом редакторе AST такое будет невозможно. То есть там в принципе будет невозможно сломать синтаксическое дерево, поэтому сам способ работы с кодом должен быть каким-то другим. А текстовые клавиатуры рассчитаны именно на ввод текста, а не узлов AST.
В действительности написание программ в виде текста — это очень сильный стереотип, и разрушить его не так-то просто. Фактически, для этого нужно заново продумать самые фундаментальные вещи — так как даже элементарные операции типа copy и paste там будут (и должны) работать немного не так (а иногда и совсем не так). Программистам свойственно активно править код, нарушая при этом корректную структуру кода. Взяли и убрали закрывающую скобку… взяли и поставили открывающий комментарий, сидим и думаем где-бы его закрыть… В любом редакторе AST такое будет невозможно. То есть там в принципе будет невозможно сломать синтаксическое дерево, поэтому сам способ работы с кодом должен быть каким-то другим. А текстовые клавиатуры рассчитаны именно на ввод текста, а не узлов AST.
Вы прямо markdown описали :) Ну, или любой другой язык разметки в plain text, например, *wiki.
Технически может это и нечто похоже. Похожее в том смысле, что в языках разметки можно вставить табличку или картинку, используя специальный синтаксис. Проблема в том, что если вы захотите встатить картинку в Markdown как-то так
но проипёте при этом, например, восклицательный знак, то документ становится невалидным в том смысле, что никакой картинки там уже не будет. А в том же MS Word это сделать (в похожем случае) достаточно сложно, если не невозможно.
Ну и нельзя не заметить, что Markdown — это просто текст. А с плейн-текстом есть следующая проблема: если вы пишете какой-то код, а потом, допустим, решаете переименовать функцию, вам нужно будет сделать это во всех местах. Да и diff будет выглядеть просто как одна строка, которую заменили другой строкой. Вы можете там точно так же ошибиться в принципе, как в примере выше. Или где-то в месте использования, допустим, можете забыть переименовать функцию. Если же хранить код в древовидном виде, близком к тому, в который код в plain-text преобразует компилятор, а также парсер IDE и прочие тулзы, то ваша функция фактически будет просто узлом в дереве с атрибутом «имя», а места использования этой функции — лишь ссылки на этот узел. Переименовали в одном месте — в остальных ничего менять не надо.
Выше NeoCode верно заметил, что в некоторых случаях такой подход повлечёт за собой необходимость избавиться от некоторых навыков работы и приобрести новые. Но я считаю, проблема решаема.

но проипёте при этом, например, восклицательный знак, то документ становится невалидным в том смысле, что никакой картинки там уже не будет. А в том же MS Word это сделать (в похожем случае) достаточно сложно, если не невозможно.
Ну и нельзя не заметить, что Markdown — это просто текст. А с плейн-текстом есть следующая проблема: если вы пишете какой-то код, а потом, допустим, решаете переименовать функцию, вам нужно будет сделать это во всех местах. Да и diff будет выглядеть просто как одна строка, которую заменили другой строкой. Вы можете там точно так же ошибиться в принципе, как в примере выше. Или где-то в месте использования, допустим, можете забыть переименовать функцию. Если же хранить код в древовидном виде, близком к тому, в который код в plain-text преобразует компилятор, а также парсер IDE и прочие тулзы, то ваша функция фактически будет просто узлом в дереве с атрибутом «имя», а места использования этой функции — лишь ссылки на этот узел. Переименовали в одном месте — в остальных ничего менять не надо.
Выше NeoCode верно заметил, что в некоторых случаях такой подход повлечёт за собой необходимость избавиться от некоторых навыков работы и приобрести новые. Но я считаю, проблема решаема.
Unicode везде есть, согласен; но я не случайно упомянул набор символов ASCII (который сейчас тоже является частью Unicode) — тут дело в том, чтобы символы были на всех клавиатурах мира; а поскольку ASCII есть везде, то логично включить их именно в ASCII, задействовав неиспользуемые коды. Кроме того, еще немало текстовых файлов создается и хранится именно в ASCII, и ничего плохого в этом нет.
Во-первых, даже 32-х символов явно не хватит для всех хотелок. Во-вторых не очень понятно зачем что-то впихивать в ASCII во времена победившего Unicode.
Ну так сложилось, что весь Unicode по факту делится на две части: символы, которые присутстуют на всех клавиатурах мира, и которые присутствуют только на части клавиатур. К первой группе относятся английские буквы, цифры и базовые символы из ASCII. Именно этот набор символов и принято использовать в языках программирования, по понятным причинам — чтобы разработчикам допустим из Европы не пришлось иметь дело с идентификаторами из китайских иероглифов.
То есть Unicode победил только в части внутрикомпьютерного представления информации; на клавиатурах для всего Unicode к сожалению просто нет места, поэтому там по-прежнему господствует ASCII, а Unicode представлен лишь частично и совершенно по-разному в зависимости от страны.
Отсюда и предложение с использованием незадействованных кодов… за счет своего расположения они ассоциированы с частью Unicode, доступной на клавиатурах всего мира (бывший ASCII).
То есть Unicode победил только в части внутрикомпьютерного представления информации; на клавиатурах для всего Unicode к сожалению просто нет места, поэтому там по-прежнему господствует ASCII, а Unicode представлен лишь частично и совершенно по-разному в зависимости от страны.
Отсюда и предложение с использованием незадействованных кодов… за счет своего расположения они ассоциированы с частью Unicode, доступной на клавиатурах всего мира (бывший ASCII).
Про Unicode на клавиатурах, конечно, согласен, но что-то я не пойму, где на клавиатуре кнопки для неиспользуемых символов ASCII?
Как вторые (третьи для локализованных клавиатур) символы на буквах. И букв по количеству как раз примерно сколько, сколько там неиспользуемых кодов, так что все сходится:)
Так если нужна специальная раскладка чтобы такие символы вводить, почему бы не забиндить туда нормальные юникодные символы которые _уже есть_, а не придумывать и двигать опять стандарт?
Возможно это чисто психологический момент, но однобайтовые символы (т.е. из той части unicode которая раньше была ascii) воспринимаются как более «фундаментальные» что-ли. Где-то в одной группе с латинскими буквами и цифрами, которые есть везде — на любой клавиатуре, в любом шрифте, в любой локализации, которые прочитаются гарантированно правильно из любого файла.
Соответственно, нужно выбрать из множества unicode 25 наиболее важных символов и забиндить. Можно было бы даже голосование в интернете устроить:)
И еще огромное количество файлов, в том числе и исходных кодов, существует в однобайтовой кодировке, и в этом нет ничего плохого.
Соответственно, нужно выбрать из множества unicode 25 наиболее важных символов и забиндить. Можно было бы даже голосование в интернете устроить:)
И еще огромное количество файлов, в том числе и исходных кодов, существует в однобайтовой кодировке, и в этом нет ничего плохого.
В любом языке полно составных знаков: ->, <=, ++, :=. По смыслу это один символ, но составленный из нескольких более простых. Мозгу требуются дополнительные усилия на то, чтобы считать и объединять такие конструкции на лету.
По-моему, проблема высосана из пальца. Никаких дополнительных усилий тренированному мозгу не требуется, чтобы заниматься иероглифическим чтением. Вот прямо сейчас вы читаете мой комментарий, не объединяя на лету буквы в слова, а воспринимая слова целиком как единое целое.
Отдельно стоит отметить, что хоть тут и нет проблемы затрудненного восприятия, возможно, для кого-то есть проблема эстетического характера, ведь составные операторы могут быть субъективно некрасивы.
Более того, в подтверждение, если в части слов убрать некоторые бквы (гласные, к примеру), текст всё равно будет прчтн и понят, и только при детальном рссмтрни можно заметить подвох. Вообще, имхо, программерский шрифт не должен изменять вид вводимого кода, а том количество WTF/min может сильно возрасти.
Объединение дефисов и угловых скобок продольной линией плохо смотрится…
Я вижу несколько проблем:
1. Набор лигатур для разных языков программирования будет разным.
2. Даже в одном языке программирования одно и то же сочетание символов может значить разные вещи. Например в C++ '>>' может быть как оператором сдвига, так и двумя закрывающими скобками в шаблонах, и в идеале должны отображаться по-разному. То есть без разбора языка тут не всегда можно обойтись.
1. Набор лигатур для разных языков программирования будет разным.
2. Даже в одном языке программирования одно и то же сочетание символов может значить разные вещи. Например в C++ '>>' может быть как оператором сдвига, так и двумя закрывающими скобками в шаблонах, и в идеале должны отображаться по-разному. То есть без разбора языка тут не всегда можно обойтись.
Ну я пока из принципиального наткнулся только на разное значение /= в Хаскелле и во всех остальных языках. Понятно что на J наверное на таком шрифте не попрограммируешь :)
Плюс, сами по себе лигатуры не навязывают никакой семантики. Как раньше >> выглядел одинаково в семантически разных контекстах, так и сейчас будет выглядеть одинаково.
Про закрывающие скобки в C++, вроде бы есть практика их специально разделять пробелом чтобы не смущать компилятор неоднозначностями?
Плюс, сами по себе лигатуры не навязывают никакой семантики. Как раньше >> выглядел одинаково в семантически разных контекстах, так и сейчас будет выглядеть одинаково.
Про закрывающие скобки в C++, вроде бы есть практика их специально разделять пробелом чтобы не смущать компилятор неоднозначностями?
1. Ну с ходу:
2. Использование >> в шаблонах было нелегальным в старых стандартах, но было разрешено в C++11.
a<-b
2. Использование >> в шаблонах было нелегальным в старых стандартах, но было разрешено в C++11.
Мне кажется, если не замахиваться на изменение символов, а просто сделать выравненные символы, то это было бы и функционально и эстетично. Слишком уж много неоднозначностей может вызвать.
Очень клевая штука. Думаю, станет популярной, когда появится поддержка Sublime Text и WebStorm. Я бы себе поставил.
Когда саблайм и идея научатся нормально показывать юникод, вы хотели сказать :)
А саблайм не умеет показывать нормально уникод? Нормально — это как?
Умеет. Лигатуры — это не юникод, это фишка open type font. В редакторах кода они как правило отключены за ненадобностью и чтобы fi в один символ не схлопывался (в некоторые моноширинные шрифты добавляют такую лигатуру).
Нормально, с моей точки зрения, это не так:
habrastorage.org/files/8a8/580/f86/8a8580f8674542b8925ee1f774dad8c8.png
habrastorage.org/files/8a8/580/f86/8a8580f8674542b8925ee1f774dad8c8.png
А вставьте этот текст сюда же, пожалуйста, хочу у себя посмотреть.
А, нашел, у меня это выглядит так:

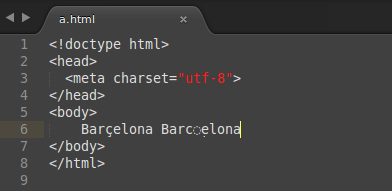
А вот это уже странно. Попробуйте шрифт поменять. Потому что у меня-то хоть объяснимо с точки зрения разработчиков редактора кода: «покажем комбинируемый символ отдельно». А у вас похоже на проблемы с комбинируемыми акутами в самом шрифте. ОС какая? Давайте все-таки текстами обменяемся: «Barçelona Barçelona». В первом слове ASCII-8, во втором — комбинируемая диакритика.
Второе слово вашего текста выглядит просто как Barcelona (неотличимо, без лишних пробелов или отступов), однако после c-таки нечто есть, при удалении 'c' стирается за 2 backspace. В названии же вкладки всё выглядит корректно.
ОС Windows, Sublime Text 3, Lucida Sans Unicode. Разные шрифты не помогают.
ОС Windows, Sublime Text 3, Lucida Sans Unicode. Разные шрифты не помогают.
А можешь выложить какие-то более живые примеры кода?
habrastorage.org/files/a29/609/56d/a2960956d5dd46279fa19f4956c219e9.png
habrastorage.org/files/a44/485/451/a4448545134b47559710471fd285a4fd.png
habrastorage.org/files/1e5/af4/713/1e5af4713a884ac1a6490f35379ee4ac.png
habrastorage.org/files/707/64f/b1c/70764fb1cc3a4014be69b3b845779ddd.png
habrastorage.org/files/2d2/55e/194/2d255e19481d4ad8bbe88702a40ad4b6.png
habrastorage.org/files/a44/485/451/a4448545134b47559710471fd285a4fd.png
habrastorage.org/files/1e5/af4/713/1e5af4713a884ac1a6490f35379ee4ac.png
habrastorage.org/files/707/64f/b1c/70764fb1cc3a4014be69b3b845779ddd.png
habrastorage.org/files/2d2/55e/194/2d255e19481d4ad8bbe88702a40ad4b6.png
Гигантское спасибо.
Единственный вопрос: вы Fira выбрали потому, что вам она нравится? Почему, к примеру, не Ubuntu Mono? У них какая-то неприятная лицензия?
Единственный вопрос: вы Fira выбрали потому, что вам она нравится? Почему, к примеру, не Ubuntu Mono? У них какая-то неприятная лицензия?
Ага, он у меня и до этого стоял рабочим шрифтом.
Эх, вот всегда в людях, создающих маленькие шедевры, не все идеально :)
Кстати да, как замутить такую фишку на своём шрифте? Какие программы для этого нужны + входной формат исходного шрифта?
Я думаю, идеально, как всегда, попросить исходники и работать в том же тулинге, что и автор шрифта. Я взял trial version RoboFont, им декомпилировал otf в ufo и в нем же рисовал лигатуры, прописал feature liga и экспортил обратно в otf. Я в шрифтах слабо разбираюсь, но как программист подозреваю что там куча информации могла потеряться в таком процессе реверс-инжиниринга. Мозилла выкладывает исходники Fira Mono в UFO, но я не смог ни одним редактором их открыть к сожалению.
В том же тулинге, что автор шрифта, с гарантией не удастся; я подозреваю, профессиональные инструменты стоят как крыло от боинга.
Интересно, можно ли как-то автоматизировать этот процесс. Если шрифт юникодный, то в нем ведь все эти стрелочки уже есть, нужно просто перенести их в лигатуры, добавив нужное количество пространства по бокам для выравнивания, так?
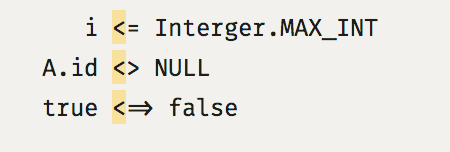
Если часть лигатуры совпадёт с поиском по коду (например, ищу! в блоке кода), что будет выделено?
Зависит от редактора, похоже. В LightTable поиск разбивает лигатуру, а простой selection нет:
habrastorage.org/files/b5f/ba2/b36/b5fba2b362904648b759c4c1e1360172.png
habrastorage.org/files/c24/0e1/27a/c240e127aab145e890dd86eb1c711eae.png
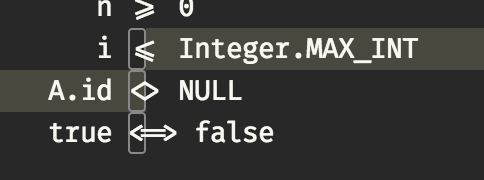
А в Atom ничего не портится:
habrastorage.org/files/737/7f7/4d7/7377f74d715349dfbec4e4a8e6fe1a32.png
habrastorage.org/files/b5f/ba2/b36/b5fba2b362904648b759c4c1e1360172.png
habrastorage.org/files/c24/0e1/27a/c240e127aab145e890dd86eb1c711eae.png
А в Atom ничего не портится:
habrastorage.org/files/737/7f7/4d7/7377f74d715349dfbec4e4a8e6fe1a32.png
Атом использует codebase хрома, а хром очень аккуратно относится к поиску по юникоду (даже слишком аккуратно). Например, поиск по этой странице «ℝ» найдет over9000 вхождений.
Так и LightTable тоже. Лигатуры с юникодом никак не связаны, они здесь все из ASCII состоят если что. Вопрос в том как отображать выделение, или найденные результаты. LightTable вставляет дополнительный span похоже и подкрашивает его цветом. На границе span-а понятно что лигатур не будет. А в atom просто рисуют поверх, наверное в доп. слое.
В VS тоже вроде все ок (лигатуры всегда рисуются, поиск подсвечивает найденную половину).
Есть мнение, что эти стрелочки, чёрточки и прочие закорючки вообще не улучшают понятность кода. Лучше использовать слова или хотя бы сокращения.
Я и обычные-то лигатуры типа «fi» считаю ерундой и непонятно они зачем нужны в компьютерный век, а тут ещё и специальные какие-то.
Я и обычные-то лигатуры типа «fi» считаю ерундой и непонятно они зачем нужны в компьютерный век, а тут ещё и специальные какие-то.
Очень спорное решение, явно все на этот шрифт не перейдут, учить новичков смысла нет, тех кто уже привык к текущему положению дел в большинстве случаев не перетащить. Да и совсем не понятно почему страдает читабельность кода в текущем виде. Программист личность аскетичная и его радует не новый вид символов, а качество программного кода.
А при чем тут общественное мнение, простите? Это шрифт в моем редакторе, почему он должен нравиться кому-то еще?
Есть ответное мнение, что хороший программист тяготеет к прекрасному. И прекрасное выражается не только в «красивом» коде, но и красивом UI, который они проектируют или которым пользуются сами.
Не туда ответил. Хотел на уровень выше.
Есть мнение, что я абсолютно с вами согласен; я как раз возражал тезису «явно все на этот шрифт не перейдут». Я-то сразу перешел.
К сожалению, лигатурами невозможно добиться всего, чего хотелось бы, ибо не хватает возможности задавать контекст.
Например, было бы (возможно не для всех) круто, если бы
C конъюнкцией и дизъюнкцией, допустим, тоже сложно. Можно заменять
Кстати, почему в Fira Code есть сочетание
Нет совершенства :(
Например, было бы (возможно не для всех) круто, если бы
! или not в логических выражениях заменялся на ¬. А в хаскеле с ним ещё и другая проблема. C конъюнкцией и дизъюнкцией, допустим, тоже сложно. Можно заменять
&& на ∧, а вот || в некоторых языках используется в list comprehensions, а не как logical or.Кстати, почему в Fira Code есть сочетание
/> для тегов, но нет </? Нет совершенства :(
Да… в C++ особенно весело будет «заменять && на ∧». Как прикажете отличать от ^?
Как два пальца: заменяем
^ на ⊕, и вуаля.Нет, Halt имел ввиду, что && в C++ используется также для обозначения rvalue references, и в таком качестве не должен ни на что заменяться.
Контекст и склеивание символов в лигатуры — это не проблемы лигатур. Если не считать шрифты абсолютным отображением байтов в памяти, то такой проблемы нет. На диске лежит
&&, парсер читает оператор-конъюнкции, редактор выдаёт глиф LOGICAL AND (U+2227), рендерер выбранного шрифта отображает ∧.Мне понравилось, как вводятся уникодные в Agda2, сделал аналогично в SublimeText в UnicodeMath. С учётом наличия в Haskell base-unicode-symbols и прагмы UnicodeSyntax, выходит удобно.
Вашим плагином я пользуюсь каждый рабочий день и очень благодарен. Но всё же это вставка юникодных символов, а тут меняется только отображение. Раньше пользовался vim-conceal для этого, но это третий тип решения и привязано к редактору…
Посоветуйте, пожалуйста, моноширный шрифт, имеющий различное написание кириллицы и латининицы. Очень хотелось бы видеть русские буквы, написанные случайно вместо латинских.
Любой шрифт, в котором кириллических букв попросту нет.
Это не совсем то, что нужно. Насколько я понимаю, в зависимости от редактора, будет отображаться либо первым попавшимся ему шрифтом, либо символ-заглушка (т.е. будет непонятно, что написано кириллицей). Хотелось бы просто комфортной работы (конкретно, в Visual Studio) и одновременного понимания, в каких местах используются русские буквы.
Сейчас в подобных случаях использую поиск по регулярному выражению [а-я] (VS очень удобно подсвечивает все найденные места), но для этого нужно делать дополнительные действия (т.е. выполнить поиск).
Сейчас в подобных случаях использую поиск по регулярному выражению [а-я] (VS очень удобно подсвечивает все найденные места), но для этого нужно делать дополнительные действия (т.е. выполнить поиск).
Не могу понять вот что: если в спецификации языка написано, что после вот таких символов ставится, скажем, набор знаков "::" или "-->", то зачем менять то, что написать в стандарте, на то, что захотелось левой пятке?
Я понимаю, что привычные в почти любом языке переменные i, j, k можно заменить на картинку смайлика (причем даже разный: скажем, переменную i целого типа — на смайлик «белый», а float — на «черный», но — зачем?.. Из буханки вот тоже многое можно сотворить…
Лигатуры — выход изящный, но уж очень он на любителя!
Я понимаю, что привычные в почти любом языке переменные i, j, k можно заменить на картинку смайлика (причем даже разный: скажем, переменную i целого типа — на смайлик «белый», а float — на «черный», но — зачем?.. Из буханки вот тоже многое можно сотворить…
Лигатуры — выход изящный, но уж очень он на любителя!
В Visual Studio у меня не работает :-(. Нужно создать на UserVoice предложение

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Что-то не фурычит. Вот Fira Code:

А вот Droid Sans Mono:

А вот Droid Sans Mono:
Так gVim же в списке No support. Откройте нормальным редактором
Эмм. Это вообще с каких пор это ненормальный редактор?! Низачот.
P.S. Если другие фонты работают, а Ваш — нет, проблемы, наверное в редакторе, да, так?
P.P.S. Если Вы не поняли, лигатуры работают. Но кодировка слетает.
P.S. Если другие фонты работают, а Ваш — нет, проблемы, наверное в редакторе, да, так?
P.P.S. Если Вы не поняли, лигатуры работают. Но кодировка слетает.
Ну да, проблема в редакторе, чему вы так удивляетесь? Поддержка лигатур — отдельная фича, она либо реализована, либо нет, либо реализована неправильно. Откройте страницу github.com/i-tu/Hasklig и прочитайте:
No support. Some editors have replaced standard font rendering engines with custom ones and don't support ligatures:
* gVim (output corrupted. A patch exists, but it has not been incorporated into mainstream gVim.)
No support. Some editors have replaced standard font rendering engines with custom ones and don't support ligatures:
* gVim (output corrupted. A patch exists, but it has not been incorporated into mainstream gVim.)
По смыслу это один символ, но составленный из нескольких более простых
Нет. Это один символ (единица информации), составленный из нескольких знаков (единица написания).
А статья отличная!
Хотя и не вижу (для себя) профита от шрифтов с лигатурами: код должен выглядеть так, как ты его символ за символом вводил, но за работу спасибо! Открыл для себя Fira Mono, добавил в свою коллекцию: htrd.su/wiki/zhurnal/2010-11-27_13.25_shrifty_dlja_koda
del
Оперделенно, нововведение заслуживает внимания — это настолько же лучше текущего положения вещей, насколько математическая формула записанная спецсимволами лучше жалкого ASCII-подобия. Ну и с лигатурами выход интересный.
В emacs есть пакет, который заменяет при отображении lambda в коде лисповых программ на соответствующую греческую букву (исходный код остаётся неизменным). Такой подход позволяет использовать в листингах на разных языках разные наборы замен.
>Мозгу требуются дополнительные усилия на то, чтобы считать и объединять такие конструкции на лету
А много дополнительных усилий мозгу требуется на то, чтобы считатьлигатуры буквы
Для выделения образа мозгу не требуется его графическая связность. Поэтому и токен
А много дополнительных усилий мозгу требуется на то, чтобы считать
Ы, Ё, Й? Опознать число 10?Для выделения образа мозгу не требуется его графическая связность. Поэтому и токен
>= или != мозг выделяет с такой же лёгкостью, как графически неразрывный символ. Вот отделять от окружающих символов пространством требуется для упрощения восприятия в любом случае. Поэтому a = 5, но не a=5.А на eclipse под виндой это как-то можно завести? Шрифт поставил, выбрал, но эклипсу это до фени.
Такому шрифту нужен конфигуратор, включать-выключать фичи
И чтобы каждый мог запилить свою фичу легко и просто
И чтобы каждый мог запилить свою фичу легко и просто
Это здорово, использовать ≤ ≥ ≠ вместо >= <= !=. Ну а остальное есть в Юникоде, для примера: ≪ ≫ ⩵ ⩶ ⇔ ⟺ ⬄ ⇒ ⇐. Осталось только сделать раскладку для клавиатур и научить языки программирования понимать эти символы.
Sign up to leave a comment.
Моноширинные шрифты с программистскими лигатурами