Я работаю со встраиваемыми системами в течение нескольких лет: наша компания разрабатывает и производит бортовые компьютеры для автомобилей, зарядные устройства, и т.д.

Процессоры, используемые в наших продуктах — это, в основном, 16- и 32-битные микроконтроллеры Microchip, имеющие RAM от 8 до 32 кБ, и ROM от 128 до 512 кБ, без MMU. Иногда, для самых простых устройств, используются еще более скромные 8-битные чипы.
Очевидно, что у нас нет (разумных) шансов использовать ядро Linux. Так что нам нужна какая-нибудь RTOS (Real-Time Operating System). Находятся даже люди, которые не используют никаких ОС в микроконтроллерах, но я не считаю это хорошей практикой: если железо позволяет мне использовать ОС, я ее использую.
Несколько лет назад, когда мы переходили с 8-битников на более мощные 16-битные микроконтроллеры, мои коллеги, которые были гораздо более опытными, чем я, рекомендовали вытесняющюю RTOS TNKernel. Так что это — та ОС, которую я использовал в разных проектах в течение пары лет.
Не то, чтобы я был очень доволен ею: например, в ней нет таймеров. И она не позволяет потоку ждать сообщения сразу из нескольких очередей. И в ней нет программного контроля переполнения стека (это действительно напрягало). Но она работала, так что я продолжал ее использовать.
Просто чтобы убедиться, что мы с вами понимаем друг друга, я сделаю краткий обзор того, как работает вытесняющая ОС в принципе. Я извиняюсь, если вещи, которые я здесь излагаю, слишком тривиальны для читателя.
Микроконтроллеры «однопоточны»: они могут выполнять только одну инструкцию в каждый момент времени (конечно, существуют многоядерные процессоры, но сейчас речь не об этом). Чтобы запустить несколько потоков на одноядерном процессоре, нам нужно переключаться между потоками, так что пользователю кажется, что они выполняются параллельно.
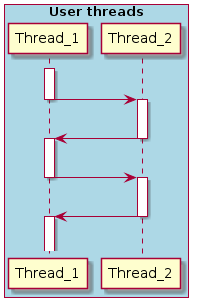
Это — то, для чего нужна ОС в первую очередь: она переключает управление между потоками. Как именно она это делает?
Микроконтроллер имеет набор регистров. Т.к. микроконтроллеры однопоточны, этот набор регистров принадлежит только одному потоку. Например, когда мы находим сумму двух чисел:
На самом деле происходит что-то вроде следующего (конечно, конкретная последовательность действий зависит от архитектуры, но в целом идея остается той же):
Тут 4 действия. Т.к. в вытесняющей ОС один поток может вытеснить другой поток в любой момент времени, то, конечно, это может произойти в середине этой последовательности. Представим, что другой поток вытесняет текущий после того, как в регистры V0 и V1 были загружены значения для суммирования. У нового потока есть свои дела и, следовательно, он использует эти регистры так, как ему нужно. Конечно, два потока не должны мешать друг другу, так что, когда первый поток опять получает управление, значения регистров V0 и V1 (и других) должны быть такими, какими они были до вытеснения.
Значит, когда мы переключаемся с потока A на поток B, в первую очередь мы должны куда-нибудь сохранить значения всех регистров потока А, затем восстановить значения всех регистров потока В. И только тогда поток В получает управление, и продолжает работать.
Так что более точная диаграмма переключения потоков будет выглядеть так:
Когда нужно переключиться с одного потока на другой, ядро получает управление, производит необходимые служебные действия (как минимум, сохраняет и восстанавливает значения регистров), и затем управление передается следующему потоку.
Куда именно сохраняются значения регистров для каждого потока? Очень часто, это — стек потока.
В современных ОС, (пользовательский) стек растет динамически благодаря MMU: чем больше потоку нужно, тем больше он получает (если ядро ему разрешит). Но микроконтрол��еры, с которыми я работаю, не имеют подобной роскоши: вся RAM отображена на адресное пространство статически. Так что каждый поток получает свою некоторую часть RAM, которая используется под стек; и если поток использует больше стека, чем ему было выделено, то это приводит к порче памяти и, следовательно, к некорректной работе. Фактически, пространство стека для каждого потока — это просто массив байт.
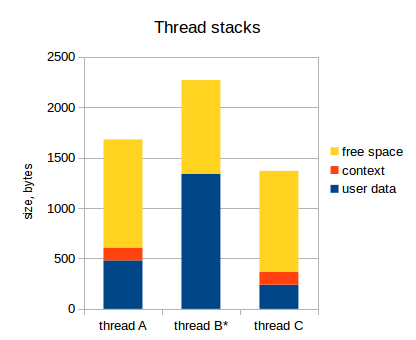
Когда мы решаем, сколько стека нужно каждому конкретному потоку, сначала мы просто прикидываем, сколько ему может понадобиться, и берем с некоторым запасом. Например, если это поток GUI с глубокой вложенностью, он может требовать несколько килобайт, но если это небольшой поток, обрабатывающий ввод пользователя, то нескольких сотен байт может быть достаточно.
Давайте предположим, что у нас есть три потока, и их потребление стека выглядит следующим образом:
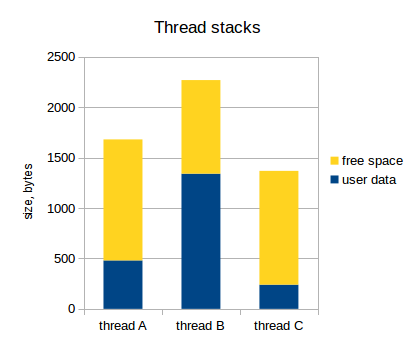
Как я уже указал, набор значений регистров для каждого потока сохраняются в стек этого потока. Этот набор значений регистров называют контекст потока. Следующая диаграмма отражает это (активный поток обозначен звездочкой):
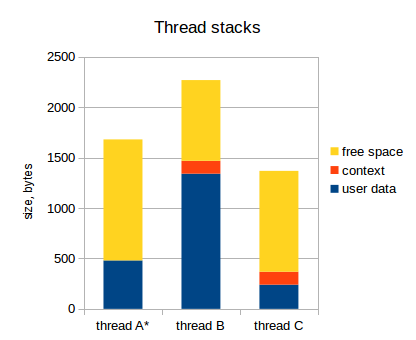
Заметьте, что у активного потока (thread A) контекст не сохранен в стек. Указатель стека в микроконтроллере указывает на вершину пользовательских данных потока А, и весь набор регистров микроконтроллера принадлежит потоку А (на самом деле, могут быть еще специальные р��гистры, не относящиеся к потоку, но это нас сейчас не интересует).
Когда ядро решает, что нужно переключить управление с потока А на поток В, оно делает следующее:
После этого, имеем следующее:
И поток В продолжает заниматься своими делами.
Мы пока не затрагивали очень важную тему: прерывания.
Прерывание — это когда выполняемый в данный момент поток приостанавливается (чаще всего, по причине внешнего события), процессор на какое-то время переключается на что-то другое (на обработку прерывания), и потом возвращается к прерванному потоку. Прерывание может быть сгенерировано в любой момент времени, и мы должны быть к этому готовы.
Микроконтроллеры, использующиеся для встраиваемых систем, обычно имеют достаточно много периферии: таймеры, приемо-передатчики (UART, SPI, CAN, и т.д.), АЦП, и т.д. Эта периферия может генерировать прерывания, когда наступает определенное событие: например, периферия UART может генерировать прерывание, когда принят новый байт, так что программа может сохранить его куда-нибудь. Таймеры генерируют прерывание по переполнению, так что программа может использовать это для каких-то периодических задач, и т.д.
Обработчик прерывания называют ISR (Interrupt Service Routine).
Прерывания могут иметь разные приоритеты: например, когда генерируется какое-то низкоприоритетное прерывание, выполняемый поток приостанавливается, и ISR получает управление. Теперь, если будет сгенерировано высокоприоритетное прерывание, то текущий ISR, опять же, приостанавливается, и ISR нового прерывания получает управление. Очевидно, когда он завершается, то первый ISR продолжает свою работу, и когда он тоже завершается, то, в итоге, управление передается обратно к прерванному потоку.
Есть короткие периоды времени, когда прерывания недопустимы: например, если мы обрабатываем какие-то данные, которые могут измениться в ISR. Если мы обрабатываем эти данные в несколько шагов, то прерывание может произойти в середине обработки и изменить данные. В итоге, поток обработает нецелостные данные, что приводит к некорректной работе программы.
Эти короткие периоды времени называют «критическими секциями»: когда мы входим в критическую секцию, мы запрещаем прерывания, и когда мы выходим из нее, то разрешаем прерывания обратно. То есть, если какое-то прерывание сгенерировано внутри критической секции, то ISR будет вызван только в момент выхода из нее (когда прерывания будут разрешены).
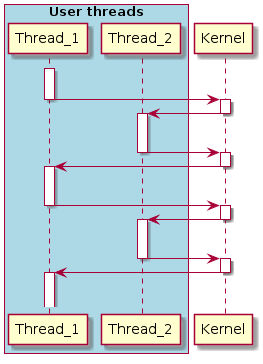
Очень интересный вопрос: куда сохранять стек ISR?
В целом, у нас есть два варианта:
Если мы используем стек прерванного потока, это выглядит следующим образом (в диаграмме ниже, поток В прерван):
Когда прерывание сгенерировано:
Это может работать достаточно быстро, но в контексте встраиваемых систем, где наши ресурсы очень ограничены, такой подход обладает существенным недостатком. Догадались, каким именно?
Помните, что прерывание может произойти в любой момент времени, так что, очевидно, мы не можем знать заранее, какой поток будет активен, когда прерывание произойдет. Так что, когда мы прикидываем размер стека для каждого потока, мы должны предположить, что все существующие прерывания могут произойти именно в этом потоке, с учетом их наихудшей вложенности. Это может значительно увеличить размер стеков для всех потоков: на 1 кБ легко, а может и больше (полностью зависит от приложения, конечно). Для примера, если в нашем приложении есть 7 потоков, то требуемый размер RAM для прерываний равен 1 * 7 = 7 кБ. Если наш микроконтроллер имеет только 32 кБ RAM (а это уже богатый микроконтроллер), то 7 кБ это 20%! Oh shi~.
Итого, стек каждого потока должен вмещать в себя следующее:
Хорошо, переходим к следующему варианту, когда мы используем отдельный стек для прерываний:
Теперь, 1 кБ для ISR из предыдущего примера должен быть выделен только один раз. Я считаю, что это гораздо более грамотный подход: во встраиваемых системах, RAM — очень дорогой ресурс.
После такого поверхностного обзора принципов работы RTOS, переходим дальше.
Как я указал в начале статьи, мы использовали TNKernel для наших разработок на 16- и 32-битных микроконтроллерах.
К сожалению, автор порта TNKernel для PIC32, Alex Borisov, использовал подход, когда прерывания используют стек прерванного потока. Это тратит кучу RAM впустую и не делает меня очень счастливым, но в остальном TNKernel выглядела хорошо: она компактная и быстрая, так что я продолжал ее использовать. Вплоть до дня X, когда я был очень удивлен, узнав, что на самом деле все гораздо хуже.
Я работал над очередным проектом: девайс, анализирующий аналоговый сигнал с автомобильной свечи, и позволяющий пользователю посмотреть некоторые параметры этого сигнала: длительности, амплитуды, и т.д. Поскольку сигнал меняется быстро, нам нужно его измерять достаточно часто: раз в 1 или 2 микросекунды.
Для этой задачи был выбран процессор Microchip семейства PIC32 (с ядром MIPS).
Задача не должна быть очень сложной, но в один прекрасный день у меня появились проблемы: иногда, когда устройство начинало измерения, программа падала в совершенно неожиданном месте. «Должно быть, дело в испорченной памяти» — подумал я, и очень расстроился, т.к. процесс поиска ошибок, связанных с порчей памяти, может быть долгим и совсем нетривиальным: как я уже говорил, никакого MMU нет, и вся RAM доступна всем потокам в системе, так что если один из потоков выходит из-под контроля и портит память другого потока, то проблема может проявляться очень далеко от фактического места с ошибкой.
Я уже говорил, что TNKernel не имеет программного контроля переполнения стека, так что, когда есть подозрение на порчу памяти, в первую очередь стоит проверить, не переполнен ли стек какого-нибудь потока. Когда поток создается, его стек инициализируется определенным значением (в TNKernel под PIC32, это просто
На MIPS, стек растет вниз, так что
Хорошо, это уже что-то. Но дело в том, что стек для этого потока был выделен с большим запасом: когда устройство работает нормально, используется только около 300 байт из 880! Должна быть какая-то дикая ошибка, которая так жестко переполняет стек.
Тогда я стал изучать память более тщательно, и стало ясно, что стек был заполнен повторяющимися паттернами. Смотрите: последовательность
И та же самая последовательность снова:
Адреса
Хмм, 34 слова… Это как раз размер контекста в MIPS! И тот же самый паттерн повторяется снова и снова. Так что, похоже, что контекст сохранен несколько раз подряд. Но… Как это может быть?!
К сожалению, чтобы разобраться во всем, мне потребовалось достаточно много времени. В первую очередь, я попробовал изучить сохраненный контекст более подробно: кроме прочего, там должен быть адрес в программной памяти, где прерванный поток должен возобновить работу позже. На PIC32, программная память отображена в регион от
Эта характерная последовательность из LW (Load Word) с адресов относительно SP (Stack Pointer) — процедура восстановления контекста. Теперь ясно, что поток был вытеснен в момент восстановления контекста из стека. Хорошо, это может произойти из-за прерывания, но почему так много раз подряд? У меня даже нет столько прерываний в системе.
До этого, я просто использовал TNKernel без четкого понимания того, как она работает, потому что она просто работала. Так что мне было даже в некоторой степени страшно лезть глубоко в ядро. Но на этот раз, мне пришлось.
Мы уже обсуждали процесс переключения контекста в общем, но сейчас, давайте освежим эту тему и добавим некоторые детали конкретной реализации (TNKernel).
Когда ядро решает переключить контекст с потока А на поток В, оно делает следующее:
Как видно, тут есть короткая критическая секция, пока ядро оперирует указателями на дескриптор потока и на вершину стека: иначе может произойти ситуация, когда прерывание будет сгенерировано между этими действиями, и нецелостность данных, конечно, приведет к некорректной работе.
В TNKernel под PIC32 есть два типа прерываний:
Сейчас нам интересны только Системные прерывания. И TNKernel имеет ограничение для этого типа прерываний: все Системные прерывания в приложении должны иметь одинаковый приоритет, так что эти прерывания не могут быть вложенными.
В качестве небольшого напоминания, вот что происходит, когда генерируется прерывание:
Теперь ISR активен, и использование стека выглядит следующим образом:

Как уже было сказано, этот подход значительно увеличивает требуемый размер стека для потоков: каждый поток должен быть достаточно большим, чтобы вместить следующее:
Необходимость умножать стек ISR на количество потоков — не самая приятная вещь, но, вообще говоря, с этим я был готов жить.
А что произойдет, если прерывание будет сгенерировано в процессе переключения контекста, т.е. пока контекст текущего потока сохраняется в стек или восстанавливается из стека?
Думаю, вы догадались: т.к. прерывания не запрещены в процессе сохранения/восстановления контекста, контекст будет сохранен дважды. Вот:

Так что, когда ядро решает переключиться с потока В на поток А, происходит вот что:
Получаем следующую картину:

Смотрите: контекст сохранен дважды в стеке потока В. На самом деле, это еще не катастрофа, если стек не переполнен, т.к. этот дважды сохраненный контекст будет дважды восстановлен, как только поток В получит управление. Например, предположим, что поток А уходит в ожидание чего-либо, и ядро переключает управление обратно на поток В:
Теперь мы, фактически, вернулись в тот момент, когда контекст сохранялся в стек потока В перед переключением на поток А. Так что мы просто продолжаем сохранять контекст:
После этого, поток В продолжает работать, как ни в чем не бывало:

Как видите, на самом деле, ничего не сломалось, но мы должны сделать важный вывод из этого исследования: наше предположение о том, что должен вмещать контекст каждого потока, было неверным. Как минимум, он должен вмещать два контекста, а не один.
Как помните, все системные прерывания в TNKernel должны иметь одинаковый приоритет, так что они не могут быть вложенными: значит, контекст не может быть сохранен больше двух раз.
Раз так, то итоговое заключение: стек каждого потока должен вмещать в себя следующее:
Ох… еще 136 байт для кадого потока. Опять же, умножаем на количество потоков: для 7 потоков это уже почти 1 килобайт: еще 3% от 32 кБ.
Ок. Хорошо. Я, возможно, был бы согласен и на такое положение дел, но наше итоговое заключение, на самом деле, не совсем итоговое. Все еще хуже.
Давайте изучим процесс сохранения двойного контекста глубже: даже после наших последних исследований, мы все еще не можем объяснить, как так получилось, что контекст сохранен в стеке потока много раз: ведь когда прерывание сгенерировано, то текущий уровень прерываний процессора повышен (до приоритета сгенерированного прерывания), и если произойдет еще одно системное прерывание, то оно будет обработано уже после того, как текущий ISR вернет управление.
Взглянем еще раз на эту диаграмму: ISR уже вернул управление, и мы переключились на поток А:
В этот момент, уровень прерываний процессора опять понижен, а контекст сохранен в стек потока В дважды.
Догадались, что дальше?
Правильно: когда мы переключаемся обратно на поток В, и пока ее контекст восстанавливается, может произойти еще одно прерывание. Рассмотрим:

Да, контекст сохранен в стек потока уже триж��ы. И, что хуже, это даже может быть то же самое прерывание: одно и то же прерывание может сохранить контекст в стеке потока несколько раз.
Так что, если вам настолько не повезет, что прерывание будет генерироваться периодически, и именно с той же частотой, с которой потоки будут переключаться туда-сюда, то контекст будет сохраняться в стеке потока снова и снова, что, в конечном итоге, приводит к переполнению стека.
Это явно не было учтено автором порта TNKernel под PIC32.
И именно это произошло с моим устройством, который измерял аналоговый сигнал: прерывание АЦП генерировалось именно с такой «удачной» частотой. Вот, что происходило:
Разумеется, это мой косяк, что прерывания по АЦП генерируются так часто, но поведение системы совершенно неприемлемо. Корректное поведение: мои потоки перестают получать управление (т.к. некогда) до тех пор, пока такая частая генерация прерываний не будет прекращена. Стек не должен быть заполнен кучей сохраненных контекстов, и когда прерывания перестанут генерироваться так часто, система спокойно продолжает свою работу.
И еще одно следствие: даже если у нас нет таких периодических прерываний, то все равно остается ненулевая вероятность того, что разные прерывания, существующие в приложении, произойдут именно в такие неудачные моменты, что контекст будет сохранен снова и снова. Встраиваемые системы часто рассчитаны на непрерывную работу в течение долгого времени (месяцы и годы): например, автомобильные сигнализации, бортовые компьютеры, и т.д. И если время работы устройства будет стремиться к бесконечности, то вероятность такого развития событий будет стремиться к единице. Рано или поздно, это происходит. Конечно, это неприемлемо, так что оставлять текущее положение вещей нельзя.
Хорошо: как минимум, теперь я знаю причину проблем. Следующий вопрос: как эту причину устранить?
Возможно, самый быстрый и грязный хак — просто запретить прерывания на период сохранения / восстановления контекста. Да, это устранит проблему, но это очень и очень плохое решение: критические секции должны быть как можно короче, и запрещать прерывания на такие долгие промежутки времени — вряд ли хорошая идея.
Гораздо более удачное решение — использовать отдельный стек для прерываний.
Существует другой порт TNKernel под PIC32 by Anders Montonen, и он использует отдельный стек для прерываний. Но этот порт не имеет некоторых удобных плюшек, присутствующих в порте Алекса Борисова: удобных Сишных макросов для объявления системных прерываний, сервисов для работы с системными тиками, и других.
Так что я решил его форкнуть и реализовать то, что мне нужно. Конечно, чтобы производить подобные изменения в ядре, мне нужно было хорошо понимать, как оно работает. И чем больше я изучал код TNKernel, тем меньше он мне нравился. TNKernel создает впечатление проекта, написанного на коленке: куча дублированного кода и нет никакой целостности.
Наиболее частый пример, встречающийся в ядре повсеместно — это код вроде следующего:
Если у нас есть несколько операторов
Теперь, нам не нужно помнить, что перед возвратом нужно обязательно разрешить прерывания. Пусть компилятор сделает за нас эту работу.
За последствиями далеко ходить не надо: вот функция из последней на данный момент TNKernel 2.7:
Смотрите: если в функцию переданы некорректные параметры, то возвращается
Оригинальный код TNKernel 2.7 содержит огромное количество дублирования кода. Очень много похожих вещей делаются в разных местах посредством простого копирования.
Если у нас есть несколько похожих сервисов (например, сервисы, отправляющие сообщение: из потока, из потока без ожидания, или из прерывания), то это три очень похожих функции, в которых отличаются 1-2 строчки, без каких-либо попыток обобщить вещи.
Переключения между состояниями потоков реализованы очень нецелостно. Например, когда нам нужно переместить поток из состояния Runnable в состояние Wait, недостаточно просто снять один флаг и поставить другой: нам также нужно убрать его из очереди на запуск, в которой поток состоял, потом, возможно, найти следующий поток на запуск, установить причину ожидания, добавить поток в очередь на ожидание (если нужно), установить таймаут (если нужно), и т.д. В TNKernel 2.7, нет общего механизма для этого, для каждого случая код написан «здесь и сейчас».
Тем временем, корректный способ реализовать эти вещи — это написать три функции для каждого состояния:
Теперь, когда нам нужно перевести поток из одного состояния в другое, нам обычно нужно просто вызвать две функции: одну для вывода потока из старого состояния, и другую для ввода ее в новое состояние. Просто и надежно.
Как следствие регулярного нарушения правила DRY, когда нам нужно что-то поменять, то нам нужно править код в нескольких местах. Нет нужды говорить, что это порочная практика.
Короче говоря, в TNKernel есть куча вещей, которые должны быть реализованы иначе.
Я решил отрефакторить его капитально. Чтобы убедиться, что я ничего не сломал, я начал реализовывать юнит-тесты для ядра. И очень скоро стало ясно, что TNKernel вообще не тестировалась: в самом ядре есть неприятные баги!
Для конкретной информации о найденных и исправленных багах, см. Why reimplement TNKernel.
В определенный момент стало ясно, что то, что я делаю, выходит далеко за рамки «рефакторинга»: я, фактически, переписывал почти все полностью. Плюс к этому, в API TNKernel есть некоторые вещи, которые меня давно напрягали, так что я слегка изменил API; а также есть вещи, которых мне не хватало, так что я их реализовал: таймеры, программный контроль переполнения стека, возможность ожидания сообщений из нескольких очередей, и т.д.
Я думал насчет названия довольно долго: мне хотелось обозначить прямую связь с TNKernel, но добавить что-то свежее и клевое. Так что первое название было: TNeoKernel.
Но, спустя некоторое время, оно само собой сократилось до лаконичного TNeo.
TNeo имеет стандартный для RTOS набор фич, плюс некоторые плюшки, которые есть не везде. Большинство возможностей опциональны, так что их можно отключить, тем самым сэкономив память и слегка увеличив производительность.
Проект размещен на GitHub: TNeo.
В данный момент, ядро портировано на следующие архитектуры:
Полная документация доступна в двух вариантах: html и pdf.
Конечно, очень сложно охватить реализацию всего ядра в одной статье; вместо этого, я постараюсь вспомнить, что было не ясно мне самому, и сфокусируюсь на этих вещах.
Но прежде всего, мы должны рассмотреть одну внутреннюю структуру: связанный список.
Связанный список — широко известная структура данных, и читатель, скорее всего, уже знаком с ней. Тем не менее, для полноты, давайте рассмотрим реализацию связанных списков в TNeo.
Связанные списки используются в TNeo повсеместно. Более конкретно, используется кольцевой двунаправленный связанный список. Структура на C выглядит следующим образом:
Она объявлена в файле src/core/tn_list.c.
Как видно, структура содержит указатели на экземпляры той же самой структуры: на предыдущий и на следующий элементы. Мы можем организовать цепочку таких структур, так что они будут связаны следующим образом:

Это здорово, но пользы от этого не очень много: мы бы хотели иметь какие-то полезные данные в каждом объекте, не так ли?
Решение — встроить
И мы хотим иметь возможность построить последовательность из экземпляров этой структуры. В первую очередь, встраиваем
Для этого примера, было бы логично поместить
Окей, и теперь создадим несколько экземпляров:
И теперь, еще один важный момент: создать сам список, который может быть как пустым, так и не пустым. Это просто экземпляр той же самой структуры
Когда список пустой, то оба его указателя на предыдущий и следующий элементы указывают на сам
Теперь мы можем организовать список следующим образом:

Он может быть создан с помощью кода вроде следующего:
Это отлично, но из вышеизложенного видно, что у нас по-прежнему есть список из
Для этого есть специальный макрос:
Так что имея указатель на
Теперь мы можем, например, обойти все элементы в списке
Этот код работает, но он несколько запутан и перегружен деталями реализации списка. Лучше иметь специальный макрос для обхода списков:
Тогда мы можем скрыть все детали и обойти список из наших экземпляров
В итоге, это довольно удобный способ создавать списки объектов. И, конечно, мы можем включить один и тот же объект в несколько списков: для этого структура должна иметь несколько встроенных экземпляров
После того, как я опубликовал ссылку на оригинальную статью (англ.) на Hacker News, один из читателей задал вопрос: почему связанные списки реализованы именно встраиванием
Вопрос интересный, так что я решил включить ответ в саму статью:
TNeo никогда не выделяет память из кучи: она оперирует только с объектами, указатели на которые переданы как параметры в тот или иной сервис ядра. И это, на самом деле, очень хорошо: часто, встраиваемые системы вообще не используют кучу, т.к. ее поведение недостаточно детерминировано.
Так что, например, когда задача переходит в ожидание мютекса, эта задача добавляется в список задач, ожидающих этот конкретный мютекс, и сложность этой операции O(1), т.е. она всегда выполняется за константное (и, кстати, небольшое) время.
Если же использовать подход с
Оба варианта неприемлемы. Поэтому используется вариант с встраиванием и, кстати, точно такой же подход используется в ядре Linux (см. книгу «Linux Kernel Development» by Robert Love). И почти все helper-макросы (для обхода списков) были взяты из ядра Linux, с небольшими изменениями: как минимум, мы не можем использовать GCC-специфичные расширения языка, вроде
Как уже было сказано, TNeo использует списки интенсивно:
Задачи, или потоки — это самая важная часть системы: в конце концов, это именно то, для чего РТОС вообще существуют. В контексте TNeo и других РТОС для сравнительно простых микроконтроллеров, задача — это подпрограмма, которая выполняется (как будто) параллельно с другими задачами.
Вообще говоря, я предпочитаю термин «поток» (thread), но TNKernel использует термин «задача» (task), так что, чтобы сохранить совместимость, TNeo также использует термин task. В этой статье, я использую оба термина в одинаковом смысле.
Каждая существущая задача в системе имеет свой собственный дескриптор:
Первый элемент дескриптора задачи — указатель на вершину стека задачи:
В ядре есть два указателя: на выполняемую в данный момент задачу, и на следующую задачу, которая должна быть запущена.
В src/core/internal/_tn_sys.h:
Как видно из комментариев, если они указывают на разные дескрипторы, то контекст должен быть переключен как можно скорее.
Задачи имеют разные приоритеты. Максимальное количество доступных приоритетов определяется размерностью процессорного слова: на 16-битных микроконтроллерах у нас есть 16 приоритетов, и на 32-битных — 32. Почему так — будет ясно позже, но, вообще говоря, для наших приложений мне никогда не было нужно больше, чем 5 или 6 приоритетов.
Для каждого приоритета существует связанный список готовых к запуску задач, которые имеют этот приоритет.
В src/core/internal/_tn_sys.h:
Где
И дескриптор задачи имеет экземпляр
В ядре также есть битовая маска (размером в одно слово), где каждый бит соответствует одному приоритету. Если бит установлен, то это означает, что в системе есть готовые к запуску задачи, имеющие соответствующий приоритет:
Так, когда ядру нужно определить, какой задаче необходимо передать управление, оно выполняет специфичную для архитектуры инструкцию find-first-set для
Конечно, когда задача входит или выходит из состояния Runnable (готова к запуску), она обслуживает соответствующий бит в
Вспомним, что когда задача в данный момент не запущена, ее контекст (значение всех регистров, плюс адрес в программной памяти, с которого задача должна продолжить выполнение) сохранен в ее стеке. И
Для каждой поддерживаемой ядром архитектуры (MIPS, ARM Cortex-M, и т.д.) есть определенная структура контеста, т.е. как именно все эти регистры располагаются в стеке. Когда задача только что создана и готовится к запуску, начало ее стека заполняется «инициализационным» контекстом, так что когда задача, наконец, получает управление, этот инициализационный контекст восстанавливается. Таким образом, каждая задача запускается в изолированном, чистом окружении.
Задача может находиться в одном из следующих состояний:
Когда задача выходит из какого-либо состояния или, наоборот, входит в него, есть определенный набор действий, которые необходимо выполнить. Например:
Дело в том, что когда задача, например, выходит из состояния Runnable, нам не нужно беспокоиться о новом состоянии, в которое задача перейдет: Wait? Suspended? Dormant? Это не имеет значения: в любом случае, мы всегда должны убрать ее из очереди на запуск, и выполнить остальные обязательные действия.
Простой и надежный способ реализовать это — написать три функции для каждого состояния:
Так что в файле src/core/tn_tasks.c у нас есть следующие функции:
И когда нам нужно перевести задачу из одного состояния в другое, это обычно сводится к следующему:
И мы можем быть уверены, что все внутренние дела будут улажены. Классно же?
Есть одна вещь, которая необходима задаче для выполнения: пространство для стека. Так что, прежде чем задача может быть создана, нам нужно выделить массив, который будет использоваться как стек этой задачи, и передать этот массив вместе с остальными вещами в
Ядро устанавливает вершину стека задачи на начало этого массива (или на конец — зависит от архитектуры), и помещает задачу в состояние Dormant. В данный момент, она еще не готова к запуску. Когда пользователь вызывает
Теперь планировщик позаботится об этой задаче, и запустит ее, когда будет нужно.
Давайте взглянем на то, как задачи запускаются.
Точная последовательность действий, необходимых для запуска задачи, конечно, зависит от архитектуры. Но, в качестве общего представления, ядро действует следующим образом:
Как именно ядро передает управление задаче — уже полностью зависит от архитектуры. Например, на MIPS, нужно сохранить program counter задачи в регистр EPC (Exception Program Counter), и выполнить инструкцию
Процесс, когда ядро приостанавливает выполнение текущей задачи и передает управление следующей задаче, называют «переключением контекста». Это процедура всегда выполняется в специальном ISR, имеющим низший приоритет. Так что, когда нужно переключить контекст, ядро устанавливает бит соответствующего прерывания. Если в данный момент выполняется пользовательская задача, то ISR, переключающий контекст, вызывается процессором тут же. Если же этот бит установлен из какого-то другого ISR (независимо от приоритета прерывания), то переключение контекста будет запущено позже: когда все выполняемые в данный момент ISR вернут управление.
Конечно, конкретное прерывание, использующееся для переключения контекста, зависит от архитектуры. Например, на PIC32 используется Core Software Interrupt 0. На ARM Cortex-M есть специальное исключение, предусмотренное для переключений контекста ОС:
Когда ISR ядра, переключающий контекст, вызывается, он делает следующее:
Переключение контекста происходит, когда какая-либо задача с более высоким приоритетом, чем текущая задача, становится готова к выполнению; или же когда текущая задача переходит в состояние Wait.
Например, предположим у нас есть две задачи: низкоприоритетная Transmitter и высокоприоритетрая Receiver. Receiver пытается получить сообщение из очереди, и т.к. очередь пуста, задача переходит в состояние Wait. Она больше недоступна для выполнения, так что ядро переходит к низкоприоритетной задаче Transmitter.

Как видно из диаграммы, когда низкоприоритетная задача Transmitter отправляет сообщение, вызвав сервис
Таким образом, система очень отзывчива: если вы устанавливаете правильные приоритеты задач, то события обрабатываются очень быстро.
В TNeo есть одна специальная задача: Idle. Она имеет самый низкий приоритет (пользовательские задачи не могут иметь такой низкий приоритет), и она всегда должна быть готова к запуску, так что
Приложение может реализовать коллбэк-функцию, которая будет вызываться из задачи Idle постоянно. Это может быть использовано для разных полезных целей:
Т.к. задача Idle должна всегда быть готова к запуску, запрещено вызывать из этого коллбэка любые сервисы ядра, которые могут перевести задачу в состояние Wait.
Ядро должно иметь представление о времени. Доступны две схемы: статический тик и динамический тик.
Статический тик — простейший способ реализовать таймауты: нам нужен какой-либо аппаратный таймер, который будет генерировать прерывания с определенной периодичностью. В этой статье, такой таймер будем называть системным таймером. Период этого таймера определяется пользователем (я всегда использовал 1 мс, но, конечно, можно установить произвольный период). В ISR этого таймера нам только нужно вызвать специальный сервис ядра:
Каждый раз, когда
Простейшая реализация таймеров может выглядеть следующим образом: у нас есть связанный список со всем активными таймерами, и на каждый системный тик мы проходим по всему списку таймеров, выполняя следующие действия для каждого таймера:
Этот подход обладает существенными недостатками:
Последний пункт, возможно, не так важен во встраиваемых системах, т.к. маловероятно, что кому-то потребуется такое большое количество таймеров; но первый пункт весьма значителен: нам точно хочется иметь возможность добавить (или перенастроить) таймер из таймерного коллбэка.
Так что в TNeo применен более хитрый подход. Основная идея взята из ядра Linux, но реализация значительно упрощена, поскольку: (1) встраиваемые системы имеют значительно меньше ресурсов, чем машины, для которых написан Linux, и (2) TNeo не нужно масштабироваться так же хорошо, как должен масштабироваться Linux. Вы можете прочитать про реализацию таймеров в Linux в книге Linux Device Drivers, 3rd edition:
Эта книга доступна всем желающим по ссылке: http://lwn.net/Kernel/LDD3/
Итак, переходим к реализации таймеров в TNeo.
У нас есть настраиваемое значение N, которое должно являться степенью двойки; типичные значения — 4, 8 или 16. И есть массив списков (т.н. tick-списков), этот массив состоит из N элементов. То есть, у нас есть N tick-списков.
Если таймер истекает через количество системных тиков от 1 до (N — 1), то этот таймер добавляется в один из этих tick-списков. Номер tick-списка вычисляется просто накладыванием соответствующей маски на таймаут (именно поэтому N должен быть степенью двойки). Если же таймер истекает позже, то он добавляется в «общий» (generic) список.
Маска, конечно, соответствует N: например, при N = 4, используется маска
Каждый N-й системный тик, ядро проходит по всем таймерам из «общего» списка, и для каждого таймера производит следующие действия:
А на каждый системный тик, мы проходимся по одному соответствующему tick-списку, и безусловно выполняем коллбэки всех таймеров из этого списка. Это решение более эффективно, чем простейшее, рассмотренное выше: мы должны пройти по всему списку таймеров только 1 раз в N тиков, в остальных же случаях просто безусловно «выстреливаем» все таймеры, список которых уже подготовлен ранее.
Внимательный читатель может задаться вопросом: почему мы используем только (N — 1) tick-списков, когда у нас вообще-то есть N списков? Это из-за того, что мы как раз хотим иметь возможность модифицировать таймеры из таймерных коллбэков. Если бы мы использовали N списков, и пользователь добавляет таймер с таймаутом, равным N, то новый таймер будет добавлен именно в тот список, который мы проходим в данный момент. Этого делать нельзя.
Если же мы используем (N — 1) списков, то мы гарантируем, что новый таймер не может быть добавлен в tick-список, который мы проходим в данный момент (кстати, таймер может быть убран из этого списка, но это не создаст проблем).
Хотя подобная реализация таймеров вполне приемлема для многих приложений, иногда она неидеальна: если устройство проводит большинство времени, ничего не делая, то вместо того, чтобы постоянно быть в режиме ожидания (с пониженным потреблением), MCU должен будет регулярно просыпаться, чтобы обработать системный тик и уйти в sleep обратно. Для этого, был реализован динамический тик.
Основная идея в том, чтобы избавиться от бесполезных вызовов
Для этого, ядро должно иметь возможность пообщаться с приложением:
Так что, когда режим динамический тик активен (
Для нормального функционирования, ядру нужно следующее:
Так что, перед стартом системы, приложение должно выделить массивы для стека задачи Idle и для прерываний, предоставить коллбэк задачи Idle (он может быть пустой), и предоставить специальный коллбэк, который должен создать как минимум одну (и обычно именно одну) пользовательскую задачу. Это — первая задача, которая будет запущена, и в моих приложениях я обычно называю ее
В
Ядро делает следующее:
После этого, система работает в обычном режиме: пользовательская задача получает управление и может делать все то, что может делать любая пользовательская задача. Обычно, она делает следующее:
Окей, кажется, я должен остановиться в какой-то момент: вряд ли у меня получится описать каждую деталь реализации в этой статье, которая уже, честно говоря, слишком большая.
Я постарался затронуть наиболее интересные темы, которые нужны для понимания картины в целом; для других тем, читатель легко сможет изучить исходный код, который я постарался сделать действительно хорошим и понятным. Исходники доступны: используйте их!
Если у вас есть любые вопросы, задавайте в комментариях.
Обычно, когда говорят о юнит-тестах, имеют в виду тесты, запускаемые на хост-машине. Но, к сожалению, компиляторы, используемые для встраиваемых систем, нередко содержат ошибки, так что я решил тестировать ядро прямо в железе. Таким образом, я могу быть уверен, что ядро 100% работает на моем устройстве.
Краткий обзор реализации тестов:
Есть высокоприоритетная задача «test director», которая создает себе «рабочие» задачи и различные объекты РТОС (очереди сообщений, мютексы, и т.д.), и затем говорит рабочим задачам, что им делать. Например:
После каждого шага, test director ждет, пока рабочие сделают свою работу, и затем проверяет, что все идет по плану: проверяет состояния задач, их приоритеты, последние возвращенные значения из сервисов ядра, различные свойства объектов, и т.д.
Подробный лог выводится в UART. Обычно, после каждого шага, выводится следующее:
Вот пример выводимого лога:
Если что-то идет не так, то будет не «as expected», а ошибка и подробности.
Я очень постарался смоделировать все возможные ситуации в рамках одной подсистемы (мютексы, очереди, и т.д.), включая ситуации с приостановленными задачами, удаленными задачами, удаленными объектами, и т.д. Это очень помогает поддерживать ядро действительно стабильным.
Окей, есть несколько причин.
Во-первых, мне не нравится их лицензия: по лицензии, FreeRTOS запрещено сравнивать с другими продуктами! Гляньте на последний параграф из FreeRTOS licence:
Насколько мне известно, они добавили это условие после очень старой дискуссии на форуме Microchip, где люди выложили графики сравнения нескольких ядер, и эти графики были не в пользу FreeRTOS. Автор FreeRTOS заявил, что измерения неверны, но, как ни забавно, не смог предоставить «правильные» измерения.
Так что, если я напишу ядро, которое оставит FreeRTOS позади в том или ином аспекте, я не смогу об этом написать. Может, я чего-то не понимаю, но, по-моему, ерунда какая-то. Мне не нравятся подобные вещи.
Кстати, несколько лет назад, когда мои коллеги рекомендовали TNKernel, они говорили, что TNKernel намного быстрее, чем FreeRTOS. После того, как я реализовал TNeo, то из любопытства я, конечно, произвел пару сравнений, но, к сожалению, не могу их опубликовать из-за лицензии FreeRTOS.
Во-вторых, ее исходный код мне тоже не нравится. Возможно, я просто слишком идеалист, но для меня, ядро реального времени — это, в некоторой степени, особый проект, и я хочу, чтобы он был настолько близок к идеалу, насколько возможно.
Да, сейчас самое время заценить код TNeo на GitHub и объяснить, почему он отстойный. Возможно, это поможет мне сделать ядро еще лучше!
В-третьих, я хотел иметь более или менее готовую замену TNKernel, чтобы я мог легко портировать существующие приложения на новое ядро. Принимая во внимание проблемы в TNKernel под микрочиповские микроконтроллеры, описанные в первой части статьи, у наших устройств всегда была вероятность неопределенного поведения.
И последнее, но не менее важное, работать над ядром — крайне увлекательное занятие!
Тем не менее, у FreeRTOS есть неоспоримое преимущество над (возможно) всеми остальными подобными продуктами: она портирована на огромное количество архитектур. К счастью, мне не нужно так много.
На данный момент, я портировал на TNeo все существующие приложения, которые раньше работали на TNKernel: бортовые компьютеры, зарядники, и т.д. Работает безупречно.
Я также представил ядро на ежегодном семинаре Microchip MASTERS 2014, начальник отдела разработки StarLine заинтересовался и попросил меня портировать ядро под архитектуру Cortex-M. Сейчас это уже давно готово, и ядро используется в их последних продуктах.
TNeo — тщательно протестированная вытесняющая РТОС для 16- и 32-битных микроконтроллеров с открытым исходным кодом.
Проект размещен на GitHub: TNeo.
В данный момент, ядро портировано на следующие архитектуры:
Полная документация доступна в двух вариантах: html и pdf.
Моя оригинальная статья на английском: How I ended up writing new real-time kernel. Т.к. автор оригинальной статьи — я сам, то, с вашего позволения, я не стал помещать эту статью в категорию «перевод».
Процессоры, используемые в наших продуктах — это, в основном, 16- и 32-битные микроконтроллеры Microchip, имеющие RAM от 8 до 32 кБ, и ROM от 128 до 512 кБ, без MMU. Иногда, для самых простых устройств, используются еще более скромные 8-битные чипы.
Очевидно, что у нас нет (разумных) шансов использовать ядро Linux. Так что нам нужна какая-нибудь RTOS (Real-Time Operating System). Находятся даже люди, которые не используют никаких ОС в микроконтроллерах, но я не считаю это хорошей практикой: если железо позволяет мне использовать ОС, я ее использую.
Несколько лет назад, когда мы переходили с 8-битников на более мощные 16-битные микроконтроллеры, мои коллеги, которые были гораздо более опытными, чем я, рекомендовали вытесняющюю RTOS TNKernel. Так что это — та ОС, которую я использовал в разных проектах в течение пары лет.
Не то, чтобы я был очень доволен ею: например, в ней нет таймеров. И она не позволяет потоку ждать сообщения сразу из нескольких очередей. И в ней нет программного контроля переполнения стека (это действительно напрягало). Но она работала, так что я продолжал ее использовать.
Как работает вытесняющая ОС
Просто чтобы убедиться, что мы с вами понимаем друг друга, я сделаю краткий обзор того, как работает вытесняющая ОС в принципе. Я извиняюсь, если вещи, которые я здесь излагаю, слишком тривиальны для читателя.
Запуск нескольких потоков
Микроконтроллеры «однопоточны»: они могут выполнять только одну инструкцию в каждый момент времени (конечно, существуют многоядерные процессоры, но сейчас речь не об этом). Чтобы запустить несколько потоков на одноядерном процессоре, нам нужно переключаться между потоками, так что пользователю кажется, что они выполняются параллельно.
Это — то, для чего нужна ОС в первую очередь: она переключает управление между потоками. Как именно она это делает?
Микроконтроллер имеет набор регистров. Т.к. микроконтроллеры однопоточны, этот набор регистров принадлежит только одному потоку. Например, когда мы находим сумму двух чисел:
//-- assume we have two ints: a and b int c = a + b;
На самом деле происходит что-то вроде следующего (конечно, конкретная последовательность действий зависит от архитектуры, но в целом идея остается той же):
# the MIPS disassembly: LW V0, -32744(GP) # загружаем значение переменной a из RAM в регистр V0 LW V1, -32740(GP) # загружаем значение переменной b из RAM в регистр V1 ADDU V0, V1, V0 # значения регистров V1 и V0 суммируются, результат сохраняется в V0 SW V0, -32496(GP) # сохраняем значение регистра V0 в RAM (по адресу переменной c)
Тут 4 действия. Т.к. в вытесняющей ОС один поток может вытеснить другой поток в любой момент времени, то, конечно, это может произойти в середине этой последовательности. Представим, что другой поток вытесняет текущий после того, как в регистры V0 и V1 были загружены значения для суммирования. У нового потока есть свои дела и, следовательно, он использует эти регистры так, как ему нужно. Конечно, два потока не должны мешать друг другу, так что, когда первый поток опять получает управление, значения регистров V0 и V1 (и других) должны быть такими, какими они были до вытеснения.
Значит, когда мы переключаемся с потока A на поток B, в первую очередь мы должны куда-нибудь сохранить значения всех регистров потока А, затем восстановить значения всех регистров потока В. И только тогда поток В получает управление, и продолжает работать.
Так что более точная диаграмма переключения потоков будет выглядеть так:
Когда нужно переключиться с одного потока на другой, ядро получает управление, производит необходимые служебные действия (как минимум, сохраняет и восстанавливает значения регистров), и затем управление передается следующему потоку.
Куда именно сохраняются значения регистров для каждого потока? Очень часто, это — стек потока.
Стек потока
В современных ОС, (пользовательский) стек растет динамически благодаря MMU: чем больше потоку нужно, тем больше он получает (если ядро ему разрешит). Но микроконтрол��еры, с которыми я работаю, не имеют подобной роскоши: вся RAM отображена на адресное пространство статически. Так что каждый поток получает свою некоторую часть RAM, которая используется под стек; и если поток использует больше стека, чем ему было выделено, то это приводит к порче памяти и, следовательно, к некорректной работе. Фактически, пространство стека для каждого потока — это просто массив байт.
Когда мы решаем, сколько стека нужно каждому конкретному потоку, сначала мы просто прикидываем, сколько ему может понадобиться, и берем с некоторым запасом. Например, если это поток GUI с глубокой вложенностью, он может требовать несколько килобайт, но если это небольшой поток, обрабатывающий ввод пользователя, то нескольких сотен байт может быть достаточно.
Давайте предположим, что у нас есть три потока, и их потребление стека выглядит следующим образом:
Как я уже указал, набор значений регистров для каждого потока сохраняются в стек этого потока. Этот набор значений регистров называют контекст потока. Следующая диаграмма отражает это (активный поток обозначен звездочкой):
Заметьте, что у активного потока (thread A) контекст не сохранен в стек. Указатель стека в микроконтроллере указывает на вершину пользовательских данных потока А, и весь набор регистров микроконтроллера принадлежит потоку А (на самом деле, могут быть еще специальные р��гистры, не относящиеся к потоку, но это нас сейчас не интересует).
Когда ядро решает, что нужно переключить управление с потока А на поток В, оно делает следующее:
- Сохраняет значения всех регистров в стек (то есть, в стек потока А);
- Переключает указатель стека на вершину стека потока В;
- Восстанавливает значения всех регистров из стека (то есть, из стека потока В).
После этого, имеем следующее:
И поток В продолжает заниматься своими делами.
Прерывания
Мы пока не затрагивали очень важную тему: прерывания.
Прерывание — это когда выполняемый в данный момент поток приостанавливается (чаще всего, по причине внешнего события), процессор на какое-то время переключается на что-то другое (на обработку прерывания), и потом возвращается к прерванному потоку. Прерывание может быть сгенерировано в любой момент времени, и мы должны быть к этому готовы.
Микроконтроллеры, использующиеся для встраиваемых систем, обычно имеют достаточно много периферии: таймеры, приемо-передатчики (UART, SPI, CAN, и т.д.), АЦП, и т.д. Эта периферия может генерировать прерывания, когда наступает определенное событие: например, периферия UART может генерировать прерывание, когда принят новый байт, так что программа может сохранить его куда-нибудь. Таймеры генерируют прерывание по переполнению, так что программа может использовать это для каких-то периодических задач, и т.д.
Обработчик прерывания называют ISR (Interrupt Service Routine).
Прерывания могут иметь разные приоритеты: например, когда генерируется какое-то низкоприоритетное прерывание, выполняемый поток приостанавливается, и ISR получает управление. Теперь, если будет сгенерировано высокоприоритетное прерывание, то текущий ISR, опять же, приостанавливается, и ISR нового прерывания получает управление. Очевидно, когда он завершается, то первый ISR продолжает свою работу, и когда он тоже завершается, то, в итоге, управление передается обратно к прерванному потоку.
Есть короткие периоды времени, когда прерывания недопустимы: например, если мы обрабатываем какие-то данные, которые могут измениться в ISR. Если мы обрабатываем эти данные в несколько шагов, то прерывание может произойти в середине обработки и изменить данные. В итоге, поток обработает нецелостные данные, что приводит к некорректной работе программы.
Эти короткие периоды времени называют «критическими секциями»: когда мы входим в критическую секцию, мы запрещаем прерывания, и когда мы выходим из нее, то разрешаем прерывания обратно. То есть, если какое-то прерывание сгенерировано внутри критической секции, то ISR будет вызван только в момент выхода из нее (когда прерывания будут разрешены).
Очень интересный вопрос: куда сохранять стек ISR?
Стек прерываний
В целом, у нас есть два варианта:
- Использовать стек потока, который был прерван;
- Использовать отдельный стек для прерываний.
Если мы используем стек прерванного потока, это выглядит следующим образом (в диаграмме ниже, поток В прерван):
Когда прерывание сгенерировано:
- Контекст текущего потока сохраняется в стек потока (так что, когда ISR завершается, мы можем сразу переключиться на другой поток);
- ISR делает свои дела (обрабатывает прерывание);
- Если нужно переключиться на другой поток, переключаемся (как минимум, модифицируем указатель стека);
- Контекст потока восстанавливается из стека;
- Поток продолжает свою работу.
Это может работать достаточно быстро, но в контексте встраиваемых систем, где наши ресурсы очень ограничены, такой подход обладает существенным недостатком. Догадались, каким именно?
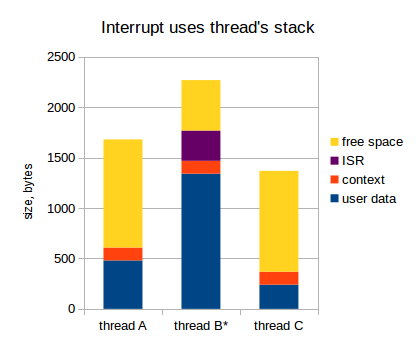
Помните, что прерывание может произойти в любой момент времени, так что, очевидно, мы не можем знать заранее, какой поток будет активен, когда прерывание произойдет. Так что, когда мы прикидываем размер стека для каждого потока, мы должны предположить, что все существующие прерывания могут произойти именно в этом потоке, с учетом их наихудшей вложенности. Это может значительно увеличить размер стеков для всех потоков: на 1 кБ легко, а может и больше (полностью зависит от приложения, конечно). Для примера, если в нашем приложении есть 7 потоков, то требуемый размер RAM для прерываний равен 1 * 7 = 7 кБ. Если наш микроконтроллер имеет только 32 кБ RAM (а это уже богатый микроконтроллер), то 7 кБ это 20%! Oh shi~.
Итого, стек каждого потока должен вмещать в себя следующее:
- Собственные данные потока;
- Контекст потока (значения всех регистров);
- Данные всех ISR с учетом наихудшей вложенности.
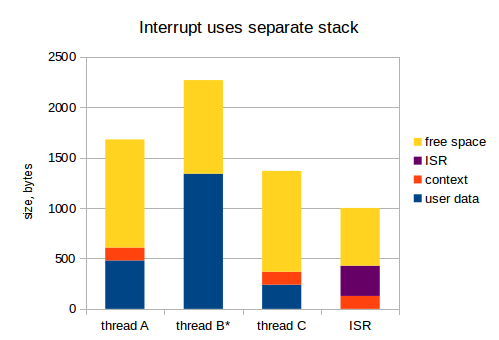
Хорошо, переходим к следующему варианту, когда мы используем отдельный стек для прерываний:
Теперь, 1 кБ для ISR из предыдущего примера должен быть выделен только один раз. Я считаю, что это гораздо более грамотный подход: во встраиваемых системах, RAM — очень дорогой ресурс.
После такого поверхностного обзора принципов работы RTOS, переходим дальше.
TNKernel
Как я указал в начале статьи, мы использовали TNKernel для наших разработок на 16- и 32-битных микроконтроллерах.
К сожалению, автор порта TNKernel для PIC32, Alex Borisov, использовал подход, когда прерывания используют стек прерванного потока. Это тратит кучу RAM впустую и не делает меня очень счастливым, но в остальном TNKernel выглядела хорошо: она компактная и быстрая, так что я продолжал ее использовать. Вплоть до дня X, когда я был очень удивлен, узнав, что на самом деле все гораздо хуже.
Фэйл TNKernel под PIC32
Я работал над очередным проектом: девайс, анализирующий аналоговый сигнал с автомобильной свечи, и позволяющий пользователю посмотреть некоторые параметры этого сигнала: длительности, амплитуды, и т.д. Поскольку сигнал меняется быстро, нам нужно его измерять достаточно часто: раз в 1 или 2 микросекунды.
Для этой задачи был выбран процессор Microchip семейства PIC32 (с ядром MIPS).
Задача не должна быть очень сложной, но в один прекрасный день у меня появились проблемы: иногда, когда устройство начинало измерения, программа падала в совершенно неожиданном месте. «Должно быть, дело в испорченной памяти» — подумал я, и очень расстроился, т.к. процесс поиска ошибок, связанных с порчей памяти, может быть долгим и совсем нетривиальным: как я уже говорил, никакого MMU нет, и вся RAM доступна всем потокам в системе, так что если один из потоков выходит из-под контроля и портит память другого потока, то проблема может проявляться очень далеко от фактического места с ошибкой.
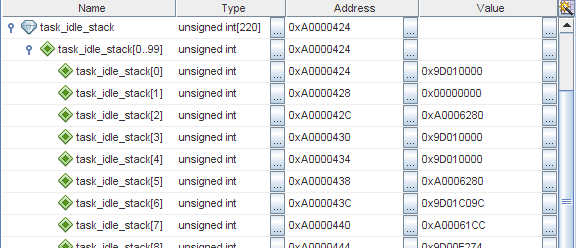
Я уже говорил, что TNKernel не имеет программного контроля переполнения стека, так что, когда есть подозрение на порчу памяти, в первую очередь стоит проверить, не переполнен ли стек какого-нибудь потока. Когда поток создается, его стек инициализируется определенным значением (в TNKernel под PIC32, это просто
0xffffffff), так что мы можем легко посмотреть, «испачкано» ли окончание стека. Я проверил, и действительно, стек потока idle явно переполнен:На MIPS, стек растет вниз, так что
task_idle_stack[0] — это последнее доступное слово в стеке потока idle.Хорошо, это уже что-то. Но дело в том, что стек для этого потока был выделен с большим запасом: когда устройство работает нормально, используется только около 300 байт из 880! Должна быть какая-то дикая ошибка, которая так жестко переполняет стек.
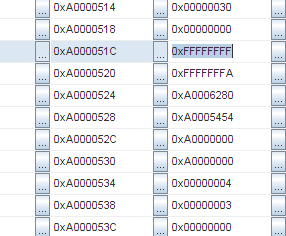
Тогда я стал изучать память более тщательно, и стало ясно, что стек был заполнен повторяющимися паттернами. Смотрите: последовательность
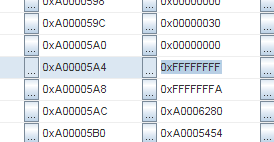
0xFFFFFFFF, 0xFFFFFFFA, 0xA0006280, 0xA0005454:И та же самая последовательность снова:
Адреса
0xA000051C и 0xA00005A4. Разница 136 байт. Поделим на 4 (размер слова), это 34 слова.Хмм, 34 слова… Это как раз размер контекста в MIPS! И тот же самый паттерн повторяется снова и снова. Так что, похоже, что контекст сохранен несколько раз подряд. Но… Как это может быть?!
К сожалению, чтобы разобраться во всем, мне потребовалось достаточно много времени. В первую очередь, я попробовал изучить сохраненный контекст более подробно: кроме прочего, там должен быть адрес в программной памяти, где прерванный поток должен возобновить работу позже. На PIC32, программная память отображена в регион от
0x9D000000 to 0x9D007FFF, так что эти адреса легко отличимы от остальных данных. Я взял эти адреса из сохраненого контекста: один из них был 0x9D012C28. Смотрим в дизассемблер:9D012C04 AD090000 SW T1, 0(T0) 9D012C08 8FA80008 LW T0, 8(SP) 9D012C0C 8FA9000C LW T1, 12(SP) 9D012C10 01000013 MTLO T0, 0 9D012C14 01200011 MTHI T1, 0 9D012C18 8FA10010 LW AT, 16(SP) 9D012C1C 8FA20014 LW V0, 20(SP) 9D012C20 8FA30018 LW V1, 24(SP) 9D012C24 8FA4001C LW A0, 28(SP) 9D012C28 8FA50020 LW A1, 32(SP) # <- вот он 9D012C2C 8FA60024 LW A2, 36(SP) 9D012C30 8FA70028 LW A3, 40(SP) 9D012C34 8FA8002C LW T0, 44(SP) 9D012C38 8FA90030 LW T1, 48(SP) 9D012C3C 8FAA0034 LW T2, 52(SP) 9D012C40 8FAB0038 LW T3, 56(SP) 9D012C44 8FAC003C LW T4, 60(SP) 9D012C48 8FAD0040 LW T5, 64(SP) 9D012C4C 8FAE0044 LW T6, 68(SP) 9D012C50 8FAF0048 LW T7, 72(SP) 9D012C54 8FB0004C LW S0, 76(SP) 9D012C58 8FB10050 LW S1, 80(SP) 9D012C5C 8FB20054 LW S2, 84(SP) 9D012C60 8FB30058 LW S3, 88(SP) 9D012C64 8FB4005C LW S4, 92(SP) 9D012C68 8FB50060 LW S5, 96(SP) 9D012C6C 8FB60064 LW S6, 100(SP) 9D012C70 8FB70068 LW S7, 104(SP) 9D012C74 8FB8006C LW T8, 108(SP) 9D012C78 8FB90070 LW T9, 112(SP) 9D012C7C 8FBA0074 LW K0, 116(SP) 9D012C80 8FBB0078 LW K1, 120(SP) 9D012C84 8FBC007C LW GP, 124(SP) 9D012C88 8FBE0080 LW S8, 128(SP) 9D012C8C 8FBF0084 LW RA, 132(SP) 9D012C90 41606000 DI ZERO 9D012C94 000000C0 EHB 9D012C98 8FBA0000 LW K0, 0(SP) 9D012C9C 8FBB0004 LW K1, 4(SP) 9D012CA0 409B7000 MTC0 K1, EPC
Эта характерная последовательность из LW (Load Word) с адресов относительно SP (Stack Pointer) — процедура восстановления контекста. Теперь ясно, что поток был вытеснен в момент восстановления контекста из стека. Хорошо, это может произойти из-за прерывания, но почему так много раз подряд? У меня даже нет столько прерываний в системе.
До этого, я просто использовал TNKernel без четкого понимания того, как она работает, потому что она просто работала. Так что мне было даже в некоторой степени страшно лезть глубоко в ядро. Но на этот раз, мне пришлось.
Переключение контекста в TNKernel под PIC32
Мы уже обсуждали процесс переключения контекста в общем, но сейчас, давайте освежим эту тему и добавим некоторые детали конкретной реализации (TNKernel).
Когда ядро решает переключить контекст с потока А на поток В, оно делает следующее:
- Сохраняет значения всех регистров в стек (то есть, в стек потока А);
- Запрещает прерывания;
- Переключает указатель стека на вершину стека потока В;
- Переключает указатель на дескриптор активного потока (на дескриптор потока В)
- Разрешает прерывания;
- Восстанавливает значения всех регистров из стека (то есть, из стека потока В).
Как видно, тут есть короткая критическая секция, пока ядро оперирует указателями на дескриптор потока и на вершину стека: иначе может произойти ситуация, когда прерывание будет сгенерировано между этими действиями, и нецелостность данных, конечно, приведет к некорректной работе.
Прерывания в TNKernel под PIC32
В TNKernel под PIC32 есть два типа прерываний:
- Системные прерывания: они могут вызывать сервисы ядра, которые могут привести к переключению контекста сразу после выполнения ISR. Когда такое прерывание вызывается, ядро сохраняет полный контекст в стек текущего потока
- Пользовательские прерывания: они не могут вызывать сервисы ядра. Ядро не производит никаких действий, когда генерируется такое прерывание.
Сейчас нам интересны только Системные прерывания. И TNKernel имеет ограничение для этого типа прерываний: все Системные прерывания в приложении должны иметь одинаковый приоритет, так что эти прерывания не могут быть вложенными.
В качестве небольшого напоминания, вот что происходит, когда генерируется прерывание:
- Контекст текущего потока сохраняется в стек потока;
- ISR получает управление.
Теперь ISR активен, и использование стека выглядит следующим образом:
Как уже было сказано, этот подход значительно увеличивает требуемый размер стека для потоков: каждый поток должен быть достаточно большим, чтобы вместить следующее:
- Собственные данные потока;
- Контекст потока (значения всех регистров);
- Данные всех ISR с учетом наихудшей вложенности.
Необходимость умножать стек ISR на количество потоков — не самая приятная вещь, но, вообще говоря, с этим я был готов жить.
Прерывание в момент переключения контекста
А что произойдет, если прерывание будет сгенерировано в процессе переключения контекста, т.е. пока контекст текущего потока сохраняется в стек или восстанавливается из стека?
Думаю, вы догадались: т.к. прерывания не запрещены в процессе сохранения/восстановления контекста, контекст будет сохранен дважды. Вот:
Так что, когда ядро решает переключиться с потока В на поток А, происходит вот что:
- Контекст сохраняется в стек потока В;
- В середине этого процесса происходит прерывание;
- В стеке потока В выделяется место для еще одного контекста, и контекст сохраняется туда
- ISR получает управление, делает свои дела и завершается
- Когда ISR завершается, ядро смотрит, какому потоку следует передать управление (это поток А: помните, мы хотели переключиться на поток А еще перед тем, как произошло прерывание)
- Запрещаем прерывания
- Переключаем указатель стека и указатель на дескриптор текущего потока
- Разрешаем прерывания
- Контекст восстанавливается из стека (т.е. с вершины стека задачи А)
Получаем следующую картину:
Смотрите: контекст сохранен дважды в стеке потока В. На самом деле, это еще не катастрофа, если стек не переполнен, т.к. этот дважды сохраненный контекст будет дважды восстановлен, как только поток В получит управление. Например, предположим, что поток А уходит в ожидание чего-либо, и ядро переключает управление обратно на поток В:
- Контекст сохраняется в стек потока А;
- Запрещаем прерывания, переключаем указатель стека, и т.д., разрешаем прерывания;
- Контекст восстанавливается из стека потока В.
Теперь мы, фактически, вернулись в тот момент, когда контекст сохранялся в стек потока В перед переключением на поток А. Так что мы просто продолжаем сохранять контекст:
- Завершаем сохранение контекста в стек потока В;
- Берем поток, который нужно активировать (на самом деле, он уже активирован: поток В);
- Восстанавливаем контекст обратно.
После этого, поток В продолжает работать, как ни в чем не бывало:
Как видите, на самом деле, ничего не сломалось, но мы должны сделать важный вывод из этого исследования: наше предположение о том, что должен вмещать контекст каждого потока, было неверным. Как минимум, он должен вмещать два контекста, а не один.
Как помните, все системные прерывания в TNKernel должны иметь одинаковый приоритет, так что они не могут быть вложенными: значит, контекст не может быть сохранен больше двух раз.
Раз так, то итоговое заключение: стек каждого потока должен вмещать в себя следующее:
- Собственные данные потока;
- Контекст потока (значения всех регистров);
- Второй контекст на случай, если прерывание произойдет в момент сохранения контекста;
- Данные всех ISR с учетом наихудшей вложенности.
Ох… еще 136 байт для кадого потока. Опять же, умножаем на количество потоков: для 7 потоков это уже почти 1 килобайт: еще 3% от 32 кБ.
Ок. Хорошо. Я, возможно, был бы согласен и на такое положение дел, но наше итоговое заключение, на самом деле, не совсем итоговое. Все еще хуже.
Копаем глубже
Давайте изучим процесс сохранения двойного контекста глубже: даже после наших последних исследований, мы все еще не можем объяснить, как так получилось, что контекст сохранен в стеке потока много раз: ведь когда прерывание сгенерировано, то текущий уровень прерываний процессора повышен (до приоритета сгенерированного прерывания), и если произойдет еще одно системное прерывание, то оно будет обработано уже после того, как текущий ISR вернет управление.
Взглянем еще раз на эту диаграмму: ISR уже вернул управление, и мы переключились на поток А:
В этот момент, уровень прерываний процессора опять понижен, а контекст сохранен в стек потока В дважды.
Догадались, что дальше?
Правильно: когда мы переключаемся обратно на поток В, и пока ее контекст восстанавливается, может произойти еще одно прерывание. Рассмотрим:
Да, контекст сохранен в стек потока уже триж��ы. И, что хуже, это даже может быть то же самое прерывание: одно и то же прерывание может сохранить контекст в стеке потока несколько раз.
Так что, если вам настолько не повезет, что прерывание будет генерироваться периодически, и именно с той же частотой, с которой потоки будут переключаться туда-сюда, то контекст будет сохраняться в стеке потока снова и снова, что, в конечном итоге, приводит к переполнению стека.
Это явно не было учтено автором порта TNKernel под PIC32.
И именно это произошло с моим устройством, который измерял аналоговый сигнал: прерывание АЦП генерировалось именно с такой «удачной» частотой. Вот, что происходило:
- Периферия АЦП завершает очередное измерение, и генерирует прерывание;
- Мой ISR вызывается, берет результат измерений, и отправляет сообщение в высокоприоритетный поток АЦП, который уже что-то делает с измеренным значением;
- Когда ISR завершается, ядро переключает управление на поток АЦП (т.к. его приоритет выше, чем приоритет прерванного потока);
- Поток АЦП быстро делает свою работу и переходит в ожидание следующего измерения;
- Ядро переключает управление на предыдущий поток, который был приостановлен из-за прерывания АЦП. И пока его контекст восстанавливается, происходит следующее прерывание по АЦП.
- Идем в пункт 2.
Разумеется, это мой косяк, что прерывания по АЦП генерируются так часто, но поведение системы совершенно неприемлемо. Корректное поведение: мои потоки перестают получать управление (т.к. некогда) до тех пор, пока такая частая генерация прерываний не будет прекращена. Стек не должен быть заполнен кучей сохраненных контекстов, и когда прерывания перестанут генерироваться так часто, система спокойно продолжает свою работу.
И еще одно следствие: даже если у нас нет таких периодических прерываний, то все равно остается ненулевая вероятность того, что разные прерывания, существующие в приложении, произойдут именно в такие неудачные моменты, что контекст будет сохранен снова и снова. Встраиваемые системы часто рассчитаны на непрерывную работу в течение долгого времени (месяцы и годы): например, автомобильные сигнализации, бортовые компьютеры, и т.д. И если время работы устройства будет стремиться к бесконечности, то вероятность такого развития событий будет стремиться к единице. Рано или поздно, это происходит. Конечно, это неприемлемо, так что оставлять текущее положение вещей нельзя.
Хорошо: как минимум, теперь я знаю причину проблем. Следующий вопрос: как эту причину устранить?
Возможно, самый быстрый и грязный хак — просто запретить прерывания на период сохранения / восстановления контекста. Да, это устранит проблему, но это очень и очень плохое решение: критические секции должны быть как можно короче, и запрещать прерывания на такие долгие промежутки времени — вряд ли хорошая идея.
Гораздо более удачное решение — использовать отдельный стек для прерываний.
Пытаемся улучшить TNKernel
Существует другой порт TNKernel под PIC32 by Anders Montonen, и он использует отдельный стек для прерываний. Но этот порт не имеет некоторых удобных плюшек, присутствующих в порте Алекса Борисова: удобных Сишных макросов для объявления системных прерываний, сервисов для работы с системными тиками, и других.
Так что я решил его форкнуть и реализовать то, что мне нужно. Конечно, чтобы производить подобные изменения в ядре, мне нужно было хорошо понимать, как оно работает. И чем больше я изучал код TNKernel, тем меньше он мне нравился. TNKernel создает впечатление проекта, написанного на коленке: куча дублированного кода и нет никакой целостности.
Примеры плохой реализации
Нарушение правила «Одна точка входа, одна точка выхода»
Наиболее частый пример, встречающийся в ядре повсеместно — это код вроде следующего:
int my_function(void) { tn_disable_interrupt(); //-- do something if (error()){ //-- do something tn_enable_interrupt(); return ERROR; } //-- do something tn_enable_interrupt(); return SUCCESS; }
Если у нас есть несколько операторов
return, а тем более, если нам нужно обязательно произвести какие-то действия перед возвратом, такой код — залог проблем. Гораздо лучше будет переписать его следующим образом:int my_function(void) { int rc = SUCCESS; tn_disable_interrupt(); if (error()){ rc = ERROR; } else { //-- so something } tn_enable_interrupt(); return rc; }
Теперь, нам не нужно помнить, что перед возвратом нужно обязательно разрешить прерывания. Пусть компилятор сделает за нас эту работу.
За последствиями далеко ходить не надо: вот функция из последней на данный момент TNKernel 2.7:
int tn_sys_tslice_ticks(int priority,int value) { TN_INTSAVE_DATA TN_CHECK_NON_INT_CONTEXT tn_disable_interrupt(); if(priority <= 0 || priority >= TN_NUM_PRIORITY-1 || value < 0 || value > MAX_TIME_SLICE) return TERR_WRONG_PARAM; tn_tslice_ticks[priority] = value; tn_enable_interrupt(); return TERR_NO_ERR; }
Смотрите: если в функцию переданы некорректные параметры, то возвращается
TERR_WRONG_PARAM, а прерывания остаются запрещенными. Если бы мы следовали правилу одна точка входа, одна точка выхода, то эта ошибка, скорее всего, не произошла бы.Нарушение принципа DRY
(don't repeat yourself)Оригинальный код TNKernel 2.7 содержит огромное количество дублирования кода. Очень много похожих вещей делаются в разных местах посредством простого копирования.
Если у нас есть несколько похожих сервисов (например, сервисы, отправляющие сообщение: из потока, из потока без ожидания, или из прерывания), то это три очень похожих функции, в которых отличаются 1-2 строчки, без каких-либо попыток обобщить вещи.
Переключения между состояниями потоков реализованы очень нецелостно. Например, когда нам нужно переместить поток из состояния Runnable в состояние Wait, недостаточно просто снять один флаг и поставить другой: нам также нужно убрать его из очереди на запуск, в которой поток состоял, потом, возможно, найти следующий поток на запуск, установить причину ожидания, добавить поток в очередь на ожидание (если нужно), установить таймаут (если нужно), и т.д. В TNKernel 2.7, нет общего механизма для этого, для каждого случая код написан «здесь и сейчас».
Тем временем, корректный способ реализовать эти вещи — это написать три функции для каждого состояния:
- Ввести поток в заданное состояние;
- Вывести поток из заданного состояния;
- Проверить, состоит ли поток в заданном состоянии.
Теперь, когда нам нужно перевести поток из одного состояния в другое, нам обычно нужно просто вызвать две функции: одну для вывода потока из старого состояния, и другую для ввода ее в новое состояние. Просто и надежно.
Как следствие регулярного нарушения правила DRY, когда нам нужно что-то поменять, то нам нужно править код в нескольких местах. Нет нужды говорить, что это порочная практика.
Короче говоря, в TNKernel есть куча вещей, которые должны быть реализованы иначе.
Я решил отрефакторить его капитально. Чтобы убедиться, что я ничего не сломал, я начал реализовывать юнит-тесты для ядра. И очень скоро стало ясно, что TNKernel вообще не тестировалась: в самом ядре есть неприятные баги!
Для конкретной информации о найденных и исправленных багах, см. Why reimplement TNKernel.
Встречайте: TNeo
В определенный момент стало ясно, что то, что я делаю, выходит далеко за рамки «рефакторинга»: я, фактически, переписывал почти все полностью. Плюс к этому, в API TNKernel есть некоторые вещи, которые меня давно напрягали, так что я слегка изменил API; а также есть вещи, которых мне не хватало, так что я их реализовал: таймеры, программный контроль переполнения стека, возможность ожидания сообщений из нескольких очередей, и т.д.
Я думал насчет названия довольно долго: мне хотелось обозначить прямую связь с TNKernel, но добавить что-то свежее и клевое. Так что первое название было: TNeoKernel.
Но, спустя некоторое время, оно само собой сократилось до лаконичного TNeo.
TNeo имеет стандартный для RTOS набор фич, плюс некоторые плюшки, которые есть не везде. Большинство возможностей опциональны, так что их можно отключить, тем самым сэкономив память и слегка увеличив производительность.
- Задачи, или потоки: самая основная возможность, для которой ядро вообще было написано;
- Мютексы: объекты для защиты разделяемых ресурсов:
- Рекурсивные мютексы: опционально, мютексы позволяют вложенную блокировку
- Определение взаимной блокировки (deadlock): если deadlock происходит, ядро может оповестить вас об этом, вызвав произвольную коллбэк-функцию
- Семафоры: объекты для синхронизации задач
- Блоки памяти фиксированного размера: простой и детерминированный менеджер памяти
- Группы флагов: объекты, содержащие биты событий, которые потоки могут ожидать, устанавливать и сбрасывать;
- Соединение групп флагов с другими объектами РТОС: очень полезная возможность соединить другие объекты РТОС с какой-либо группой флагов: например, когда потоку нужно ожидать сообщения сразу из нескольких очередей
- Очереди сообщений: FIFO буфер сообщений, которые потоки могут отправлять и принимать
- Таймеры: позволяют попросить ядро вызвать определенную функцию в будущем.
- Отдельный стек для прерываний: такой подход значительно экономит RAM
- Программный контроль переполнения стека: очень полезно, когда нет аппаратного контроля переполнения стека
- Динамический тик: если системе нечего делать, то можно не отвлекаться на периодическую обработку системных тиков
- Профайлер: позволяет узнать, сколько времени каждый из потоков выполнялся, максимальное время выполнения подряд, и другую информацию
Проект размещен на GitHub: TNeo.
В данный момент, ядро портировано на следующие архитектуры:
- ARM Cortex-M cores: Cortex-M0/M0+/M1/M3/M4/M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32MX/PIC24/dsPIC
Полная документация доступна в двух вариантах: html и pdf.
Реализация TNeo
Конечно, очень сложно охватить реализацию всего ядра в одной статье; вместо этого, я постараюсь вспомнить, что было не ясно мне самому, и сфокусируюсь на этих вещах.
Но прежде всего, мы должны рассмотреть одну внутреннюю структуру: связанный список.
Связанные списки
Связанный список — широко известная структура данных, и читатель, скорее всего, уже знаком с ней. Тем не менее, для полноты, давайте рассмотрим реализацию связанных списков в TNeo.
Связанные списки используются в TNeo повсеместно. Более конкретно, используется кольцевой двунаправленный связанный список. Структура на C выглядит следующим образом:
/** * Circular doubly linked list item, for internal kernel usage. */ struct TN_ListItem { /// /// pointer to previous item struct TN_ListItem *prev; /// /// pointer to next item struct TN_ListItem *next; };
Она объявлена в файле src/core/tn_list.c.
Как видно, структура содержит указатели на экземпляры той же самой структуры: на предыдущий и на следующий элементы. Мы можем организовать цепочку таких структур, так что они будут связаны следующим образом:
Это здорово, но пользы от этого не очень много: мы бы хотели иметь какие-то полезные данные в каждом объекте, не так ли?
Решение — встроить
struct TN_ListItem в другую структуру, экземпляры которой мы хотим связывать. Например, предположим, что у нас есть структура MyBlock:struct MyBlock { int field1; int field2; int field3; };
И мы хотим иметь возможность построить последовательность из экземпляров этой структуры. В первую очередь, встраиваем
struct TN_ListItem внутрь нее.Для этого примера, было бы логично поместить
struct TN_ListItem в начало struct MyBlock, но просто чтобы подчеркнуть, что struct TN_ListItem может быть в любом месте, не только в начале, давайте поместим ее в середину:struct MyBlock { int field1; int field2; //-- say, embed it here. struct TN_ListItem list_item; int field3; };
Окей, и теперь создадим несколько экземпляров:
//-- blocks to put in the list struct MyBlock block_first = { /* ... */ }; struct MyBlock block_second = { /* ... */ }; struct MyBlock block_third = { /* ... */ };
И теперь, еще один важный момент: создать сам список, который может быть как пустым, так и не пустым. Это просто экземпляр той же самой структуры
struct TN_ListItem, но не встроенный никуда://-- list head struct TN_ListItem my_blocks;
Когда список пустой, то оба его указателя на предыдущий и следующий элементы указывают на сам
my_blocks.Теперь мы можем организовать список следующим образом:
Он может быть создан с помощью кода вроде следующего:
//-- Конечно, было бы плохой идеей всегда создавать списки вот так, // вручную. Этот код просто для иллюстрации. my_blocks.next = &block_first.list_item; my_blocks.prev = &block_third.list_item; block_first.list_item.next = &block_second.list_item; block_first.list_item.prev = &my_blocks; block_second.list_item.next = &block_third.list_item; block_second.list_item.prev = &block_first.list_item; block_third.list_item.next = &my_blocks; block_third.list_item.prev = &block_second.list_item;
Это отлично, но из вышеизложенного видно, что у нас по-прежнему есть список из
TN_ListItem, а не из MyBlock. Но идея в том, что смещение от начала MyBlock до его list_item — одинаковое для всех экземпляров MyBlock. Так что, если у нас есть указатель на TN_ListItem, и мы знаем, что этот экземпляр встроен в MyBlock, то мы можем вычесть из указателя определенное смещение, и получим указатель на MyBlock.Для этого есть специальный макрос:
container_of() (определен в файле src/core/internal/_tn_sys.h):#if !defined(container_of) /* given a pointer @ptr to the field @member embedded into type (usually * struct) @type, return pointer to the embedding instance of @type. */ #define container_of(ptr, type, member) \ ((type *)((char *)(ptr)-(char *)(&((type *)0)->member))) #endif
Так что имея указатель на
TN_ListItem, мы получаем указатель на внешний MyBlock следующим образом:struct TN_ListItem *p_list_item = /* ... */; struct MyBlock *p_my_block = container_of(p_list_item, struct MyBlock, list_item);
Теперь мы можем, например, обойти все элементы в списке
my_blocks://-- loop cursor struct TN_ListItem *p_cur; //-- обходим все элементы в списке my_blocks for (p_cur = my_blocks.next; p_cur != &my_blocks; p_cur = p_cur->next) { struct MyBlock *p_cur_block = container_of(p_cur, struct MyBlock, list_item); //-- Сейчас, p_cur_block указывает на очередной экземпляр MyBlock }
Этот код работает, но он несколько запутан и перегружен деталями реализации списка. Лучше иметь специальный макрос для обхода списков:
_tn_list_for_each_entry(), определенный в файле src/core/internal/_tn_list.h.Тогда мы можем скрыть все детали и обойти список из наших экземпляров
MyBlock вот так:struct MyBlock *p_cur_block; _tn_list_for_each_entry( p_cur_block, struct MyBlock, &my_blocks, list_item ) { //-- Сейчас, p_cur_block указывает на очередной экземпляр MyBlock }
В итоге, это довольно удобный способ создавать списки объектов. И, конечно, мы можем включить один и тот же объект в несколько списков: для этого структура должна иметь несколько встроенных экземпляров
struct TN_ListItem: для каждого списка, в который планируется включать этот объект.После того, как я опубликовал ссылку на оригинальную статью (англ.) на Hacker News, один из читателей задал вопрос: почему связанные списки реализованы именно встраиванием
struct TN_ListItem в другие структуры, а не, например, вот так:struct TN_ListItem { TN_ListItem *prev; TN_ListItem *next; void *data; //-- указатель на любые полезные данные }
Вопрос интересный, так что я решил включить ответ в саму статью:
TNeo никогда не выделяет память из кучи: она оперирует только с объектами, указатели на которые переданы как параметры в тот или иной сервис ядра. И это, на самом деле, очень хорошо: часто, встраиваемые системы вообще не используют кучу, т.к. ее поведение недостаточно детерминировано.
Так что, например, когда задача переходит в ожидание мютекса, эта задача добавляется в список задач, ожидающих этот конкретный мютекс, и сложность этой операции O(1), т.е. она всегда выполняется за константное (и, кстати, небольшое) время.
Если же использовать подход с
void *data;, то у нас есть два варианта:- Когда добавляем новый объект в какой-нибудь список, ядро должно где-то выделить экземпляр
struct TN_ListItem(из кучи или, возможно, из какого-то пула объектов); - Клиентский код должен выделить
struct TN_ListItemсамостоятельно (любым способом) и передавать его в любой сервис ядра, которому это может понадобиться.
Оба варианта неприемлемы. Поэтому используется вариант с встраиванием и, кстати, точно такой же подход используется в ядре Linux (см. книгу «Linux Kernel Development» by Robert Love). И почти все helper-макросы (для обхода списков) были взяты из ядра Linux, с небольшими изменениями: как минимум, мы не можем использовать GCC-специфичные расширения языка, вроде
typeof(), т.к. TNeo должен компилироваться совсем не только GCC.Как уже было сказано, TNeo использует списки интенсивно:
- Есть общий список созданных задач в системе: иногда нужно обойти все созданные задачи (например, для генерации отчета профайлера)
- Когда задача готова к выполнению, она добавляется в очередь на запуск для ее приоритета (ниже это объясняется более подробно)
- Когда задача ждет сообщения из очереди, она добавляется в очередь задач, ожидающих сообщения из этой конкретной очереди
- И т.д.
Задачи (потоки)
Задачи, или потоки — это самая важная часть системы: в конце концов, это именно то, для чего РТОС вообще существуют. В контексте TNeo и других РТОС для сравнительно простых микроконтроллеров, задача — это подпрограмма, которая выполняется (как будто) параллельно с другими задачами.
Вообще говоря, я предпочитаю термин «поток» (thread), но TNKernel использует термин «задача» (task), так что, чтобы сохранить совместимость, TNeo также использует термин task. В этой статье, я использую оба термина в одинаковом смысле.
Каждая существущая задача в системе имеет свой собственный дескриптор:
struct TN_Task, объявленный в файле src/core/tn_tasks.h. Это довольно большая структура.Первый элемент дескриптора задачи — указатель на вершину стека задачи:
stack_cur_pt. Этот факт активно используется ассемблерными подпрограммами переключения контекста: имея указатель на дескриптор задачи, мы можем просто разадресовать его, и полученное значение будет указывать на вершину стека задачи. Довольно удобно.Текущая и следующая задачи
В ядре есть два указателя: на выполняемую в данный момент задачу, и на следующую задачу, которая должна быть запущена.
В src/core/internal/_tn_sys.h:
/// task that is running now extern struct TN_Task *_tn_curr_run_task; /// task that should run as soon as possible (if it isn't equal to /// _tn_curr_run_task, context switch is needed) extern struct TN_Task *_tn_next_task_to_run;
Как видно из комментариев, если они указывают на разные дескрипторы, то контекст должен быть переключен как можно скорее.
Приоритеты задач и очереди на запуск
Задачи имеют разные приоритеты. Максимальное количество доступных приоритетов определяется размерностью процессорного слова: на 16-битных микроконтроллерах у нас есть 16 приоритетов, и на 32-битных — 32. Почему так — будет ясно позже, но, вообще говоря, для наших приложений мне никогда не было нужно больше, чем 5 или 6 приоритетов.
Для каждого приоритета существует связанный список готовых к запуску задач, которые имеют этот приоритет.
В src/core/internal/_tn_sys.h:
/// list of all ready to run (TN_TASK_STATE_RUNNABLE) tasks extern struct TN_ListItem _tn_tasks_ready_list[TN_PRIORITIES_CNT];
Где
TN_PRIORITIES_CNT — конфигурируемое пользователем значение (конечно, оно не может быть больше максимального).И дескриптор задачи имеет экземпляр
struct TN_ListItem, который добавляется в один из этих списков задач:/** * Task */ struct TN_Task { /* ... */ /// queue is used to include task in ready/wait lists struct TN_ListItem task_queue; /* ... */ }
В ядре также есть битовая маска (размером в одно слово), где каждый бит соответствует одному приоритету. Если бит установлен, то это означает, что в системе есть готовые к запуску задачи, имеющие соответствующий приоритет:
/// bitmask of priorities with runnable tasks. /// lowest priority bit (1 << (TN_PRIORITIES_CNT - 1)) should always be set, /// since this priority is used by idle task which should be always runnable, /// by design. extern volatile unsigned int _tn_ready_to_run_bmp;
Так, когда ядру нужно определить, какой задаче необходимо передать управление, оно выполняет специфичную для архитектуры инструкцию find-first-set для
_tn_ready_to_run_bmp, и тут же получает максимальный приоритет из всех готовых к запуску задач. Затем, мы берем первую задачу из списка задач для соответствующего приоритета, и передаем ей управление.Конечно, когда задача входит или выходит из состояния Runnable (готова к запуску), она обслуживает соответствующий бит в
_tn_ready_to_run_bmp, это достаточно тривиально. В целом, все работает быстро.Контекст задачи
Вспомним, что когда задача в данный момент не запущена, ее контекст (значение всех регистров, плюс адрес в программной памяти, с которого задача должна продолжить выполнение) сохранен в ее стеке. И
stack_cur_ptr в дескрипторе задачи указывает именно на вершину этого сохраненного контекста.Для каждой поддерживаемой ядром архитектуры (MIPS, ARM Cortex-M, и т.д.) есть определенная структура контеста, т.е. как именно все эти регистры располагаются в стеке. Когда задача только что создана и готовится к запуску, начало ее стека заполняется «инициализационным» контекстом, так что когда задача, наконец, получает управление, этот инициализационный контекст восстанавливается. Таким образом, каждая задача запускается в изолированном, чистом окружении.
Состояния задач
Задача может находиться в одном из следующих состояний:
- Runnable: задача готова к запуску (это не означает, что задача фактически выполняется в данный момент)
- Wait: задача ждет чего-то (сообщения из очереди, мютекса, семафора, и т.д.)
- Suspended: задача был приостановлена другой задачей
- Wait + Suspended: задача была в состоянии Wait, после чего была приостановлена другой задачей
- Dormant: задача еще не была активирована после создания, или была уничтожена с помощью вызова
tn_task_terminate. Следующий раз, когда задача будет активирована, любое предыдущее ее состояние будет обнулено, и она будет запущена в чистом окружении
Когда задача выходит из какого-либо состояния или, наоборот, входит в него, есть определенный набор действий, которые необходимо выполнить. Например:
- Когда задача выходит из состояния Dormant, необходимо инициализировать ее стек, так что когда задача получит управление, она будет запущена в новом окружении
- Когда задача входит в состояние Runnable, нам нужно добавить ее в очередь на запуск для соответствующего приоритета и обслужить
_tn_ready_to_run_bmp, так что ядро рано или поздно передаст ей управление - Когда задача выходит из состояния Runnable, нужно убрать ее из очереди на запуск, опять-таки обслужить
_tn_ready_to_run_bmp, и если это была выполняемая в данный момент задача, то нужно определить другую задачу для выполнения - Когда задача входит в состояние Wait, мы добавляем ее в соответствующую очередь ожидания (если нужно), а также устанавливаем таймер, если таймаут был указан
- Когда задача выходит из состояния Wait, мы убираем ее из очереди ожидания (если она состояла в такой очереди), и сбрасываем таймер (если он был установлен)
- И т.д.
Дело в том, что когда задача, например, выходит из состояния Runnable, нам не нужно беспокоиться о новом состоянии, в которое задача перейдет: Wait? Suspended? Dormant? Это не имеет значения: в любом случае, мы всегда должны убрать ее из очереди на запуск, и выполнить остальные обязательные действия.
Простой и надежный способ реализовать это — написать три функции для каждого состояния:
- Ввести задачу в заданное состояние;
- Вывести задачу из заданного состояния;
- Проверить, состоит ли задача в заданном состоянии.
Так что в файле src/core/tn_tasks.c у нас есть следующие функции:
void _tn_task_set_runnable(struct TN_Task * task) { /* ... */ } void _tn_task_clear_runnable(struct TN_Task * task) { /* ... */ } void _tn_task_set_waiting( struct TN_Task *task, struct TN_ListItem *wait_que, enum TN_WaitReason wait_reason, TN_TickCnt timeout ) { /* ... */ } void _tn_task_clear_waiting(struct TN_Task *task, enum TN_RCode wait_rc) { /* ... */ } //-- etc.
И когда нам нужно перевести задачу из одного состояния в другое, это обычно сводится к следующему:
_tn_task_clear_dormant(task); _tn_task_set_runnable(task);
И мы можем быть уверены, что все внутренние дела будут улажены. Классно же?
Создание задач
Есть одна вещь, которая необходима задаче для выполнения: пространство для стека. Так что, прежде чем задача может быть создана, нам нужно выделить массив, который будет использоваться как стек этой задачи, и передать этот массив вместе с остальными вещами в
tn_task_create().Ядро устанавливает вершину стека задачи на начало этого массива (или на конец — зависит от архитектуры), и помещает задачу в состояние Dormant. В данный момент, она еще не готова к запуску. Когда пользователь вызывает
tn_task_activate() (или если флаг TN_TASK_CREATE_OPT_START был передан в tn_task_create()), ядро действует следующим образом:- Выводит задачу из состояния Dormant: как вы уже знаете, в этот момент стек задачи инициализируется чистым контекстом;
- Вводит задачу в состояние Runnable: как вы уже знаете, в этот момент задача помещается в конец соответствующей очереди на запуск.
Теперь планировщик позаботится об этой задаче, и запустит ее, когда будет нужно.
Давайте взглянем на то, как задачи запускаются.
Запуск задач
Точная последовательность действий, необходимых для запуска задачи, конечно, зависит от архитектуры. Но, в качестве общего представления, ядро действует следующим образом:
- Получает указатель стека из дескриптора задачи, на который указывает
_tn_next_task_to_run, и устанавливает как текущий указатель стека; - Выполняет
_tn_curr_run_task = _tn_next_task_to_run;; - Загружает значения всех регистров из стека, один за другим (помните, что указатель стека был только что установлен на вершину стека задачи). Кроме прочего, загружается также адрес в программной памяти, где задача должна быть возобновлена;
- Передает управление задаче.
Как именно ядро передает управление задаче — уже полностью зависит от архитектуры. Например, на MIPS, нужно сохранить program counter задачи в регистр EPC (Exception Program Counter), и выполнить инструкцию
eret (return from exception). То есть, ядро «обманывает» процессор, чтобы он вел себя так, будто возвращается из «обычного» прерывания. После выполнения eret, текущий PC (Program Counter) устанавливается в значение, сохраненное в EPC, и, фактически, задача продолжает выполнение.Переключение контекста
Процесс, когда ядро приостанавливает выполнение текущей задачи и передает управление следующей задаче, называют «переключением контекста». Это процедура всегда выполняется в специальном ISR, имеющим низший приоритет. Так что, когда нужно переключить контекст, ядро устанавливает бит соответствующего прерывания. Если в данный момент выполняется пользовательская задача, то ISR, переключающий контекст, вызывается процессором тут же. Если же этот бит установлен из какого-то другого ISR (независимо от приоритета прерывания), то переключение контекста будет запущено позже: когда все выполняемые в данный момент ISR вернут управление.
Конечно, конкретное прерывание, использующееся для переключения контекста, зависит от архитектуры. Например, на PIC32 используется Core Software Interrupt 0. На ARM Cortex-M есть специальное исключение, предусмотренное для переключений контекста ОС:
PendSV.Когда ISR ядра, переключающий контекст, вызывается, он делает следующее:
- Сохраняет значения всех регистров в стек текущей задачи, один за другим. Кроме прочего, сохраняется и адрес в программной памяти, на котором задача была прервана;
- Когда все регистры сохранены в стек, ядро сохраняет текущий указатель стека в дескриптор текущей задачи;
- Возможно, выполняет on-context-switch handler (он нужен для профайлера и для программного контроля переполнения стека, если любая из этих функций включена);
- Затем переходим к последовательности, указанной в предыдущей секции «Запуск задач».
Переключение контекста происходит, когда какая-либо задача с более высоким приоритетом, чем текущая задача, становится готова к выполнению; или же когда текущая задача переходит в состояние Wait.
Например, предположим у нас есть две задачи: низкоприоритетная Transmitter и высокоприоритетрая Receiver. Receiver пытается получить сообщение из очереди, и т.к. очередь пуста, задача переходит в состояние Wait. Она больше недоступна для выполнения, так что ядро переходит к низкоприоритетной задаче Transmitter.
Как видно из диаграммы, когда низкоприоритетная задача Transmitter отправляет сообщение, вызвав сервис
tn_queue_send(), эта задача вытесняется ядром в пользу высокоприоритетной Receiver незамедлительно. Так что, к моменту, когда tn_queue_send() возвращает управление в Transmitter, произошло уже много вещей:- Контекст переключается на Receiver;
- Receiver получает сообщение и обрабатывает его;
- Receiver пытается получить следующее сообщение, и переходит в состояние Wait;
- Контекст переключается обратно на Transmitter.
Таким образом, система очень отзывчива: если вы устанавливаете правильные приоритеты задач, то события обрабатываются очень быстро.
Задача Idle
В TNeo есть одна специальная задача: Idle. Она имеет самый низкий приоритет (пользовательские задачи не могут иметь такой низкий приоритет), и она всегда должна быть готова к запуску, так что
_tn_ready_to_run_bmp всегда имеет как минимум один установленный бит: бит для низшего приоритета задачи Idle. Очевидно, что ядро передает управление этой задаче тогда, когда нет никаких других готовых к запуску задач.Приложение может реализовать коллбэк-функцию, которая будет вызываться из задачи Idle постоянно. Это может быть использовано для разных полезных целей:
- MCU sleep. Когда системе нечего делать, часто имеет смысл перевести процессор в sleep, чтобы уменьшить потребление. Конечно, приложение должно настроить какое-то условие, по которому процессор должен выйти из sleep: чаще всего, это какое-нибудь прерывание;
- Вычисление загрузки системы. Простейшая реализация: просто увеличивать на единицу значение какой-нибудь переменной в бесконечном цикле. Чем быстрее изменяется значение — тем меньше нагрузка на систему.
Т.к. задача Idle должна всегда быть готова к запуску, запрещено вызывать из этого коллбэка любые сервисы ядра, которые могут перевести задачу в состояние Wait.
Таймеры
Ядро должно иметь представление о времени. Доступны две схемы: статический тик и динамический тик.
Статический тик
Статический тик — простейший способ реализовать таймауты: нам нужен какой-либо аппаратный таймер, который будет генерировать прерывания с определенной периодичностью. В этой статье, такой таймер будем называть системным таймером. Период этого таймера определяется пользователем (я всегда использовал 1 мс, но, конечно, можно установить произвольный период). В ISR этого таймера нам только нужно вызвать специальный сервис ядра:
//-- example for PIC32, hardware timer 5 interrupt: tn_p32_soft_isr(_TIMER_5_VECTOR) { INTClearFlag(INT_T5); tn_tick_int_processing(); }
Каждый раз, когда
tn_tick_int_processing() вызывается, мы говорим что произошел системный тик. Внутри этой функции, ядро проверяет, не пора ли вызвать коллбэк какого-нибудь таймера, и если пора, то вызывает его.Простейшая реализация таймеров может выглядеть следующим образом: у нас есть связанный список со всем активными таймерами, и на каждый системный тик мы проходим по всему списку таймеров, выполняя следующие действия для каждого таймера:
- Уменьшаем значение таймаута на 1;
- Если новое значение равняется нулю, то удаляем этот таймер из списка (т.е. делаем таймер неактивным), и запускаем коллбэк таймера.
Этот подход обладает существенными недостатками:
- Мы не можем управлять таймерами из коллбэков: если мы, например, добавим новый таймер, то список таймеров будет модифицирован. Но т.к. мы в данный момент уже проходим по этому списку, добавление элементов в него недопустимо;
- Этот подход довольно неэффективен при большом количестве активных таймеров: мы должны будем обработать каждый таймер при каждом системном тике.
Последний пункт, возможно, не так важен во встраиваемых системах, т.к. маловероятно, что кому-то потребуется такое большое количество таймеров; но первый пункт весьма значителен: нам точно хочется иметь возможность добавить (или перенастроить) таймер из таймерного коллбэка.
Так что в TNeo применен более хитрый подход. Основная идея взята из ядра Linux, но реализация значительно упрощена, поскольку: (1) встраиваемые системы имеют значительно меньше ресурсов, чем машины, для которых написан Linux, и (2) TNeo не нужно масштабироваться так же хорошо, как должен масштабироваться Linux. Вы можете прочитать про реализацию таймеров в Linux в книге Linux Device Drivers, 3rd edition:
- Time, Delays, and Deferred Work
- Kernel Timers
- The Implementation of Kernel Timers
- The Implementation of Kernel Timers
- Kernel Timers
Эта книга доступна всем желающим по ссылке: http://lwn.net/Kernel/LDD3/
Итак, переходим к реализации таймеров в TNeo.
У нас есть настраиваемое значение N, которое должно являться степенью двойки; типичные значения — 4, 8 или 16. И есть массив списков (т.н. tick-списков), этот массив состоит из N элементов. То есть, у нас есть N tick-списков.
Если таймер истекает через количество системных тиков от 1 до (N — 1), то этот таймер добавляется в один из этих tick-списков. Номер tick-списка вычисляется просто накладыванием соответствующей маски на таймаут (именно поэтому N должен быть степенью двойки). Если же таймер истекает позже, то он добавляется в «общий» (generic) список.
Маска, конечно, соответствует N: например, при N = 4, используется маска
0b0011; при N = 8, используется маска 0b0111, и т.д.Каждый N-й системный тик, ядро проходит по всем таймерам из «общего» списка, и для каждого таймера производит следующие действия:
- Таймаут уменьшается на N;
- Если результирующий таймаут меньше, чем N, то таймер перемещается в соответствующий tick-список.
А на каждый системный тик, мы проходимся по одному соответствующему tick-списку, и безусловно выполняем коллбэки всех таймеров из этого списка. Это решение более эффективно, чем простейшее, рассмотренное выше: мы должны пройти по всему списку таймеров только 1 раз в N тиков, в остальных же случаях просто безусловно «выстреливаем» все таймеры, список которых уже подготовлен ранее.
Внимательный читатель может задаться вопросом: почему мы используем только (N — 1) tick-списков, когда у нас вообще-то есть N списков? Это из-за того, что мы как раз хотим иметь возможность модифицировать таймеры из таймерных коллбэков. Если бы мы использовали N списков, и пользователь добавляет таймер с таймаутом, равным N, то новый таймер будет добавлен именно в тот список, который мы проходим в данный момент. Этого делать нельзя.
Если же мы используем (N — 1) списков, то мы гарантируем, что новый таймер не может быть добавлен в tick-список, который мы проходим в данный момент (кстати, таймер может быть убран из этого списка, но это не создаст проблем).
Хотя подобная реализация таймеров вполне приемлема для многих приложений, иногда она неидеальна: если устройство проводит большинство времени, ничего не делая, то вместо того, чтобы постоянно быть в режиме ожидания (с пониженным потреблением), MCU должен будет регулярно просыпаться, чтобы обработать системный тик и уйти в sleep обратно. Для этого, был реализован динамический тик.
Динамический тик
Основная идея в том, чтобы избавиться от бесполезных вызовов
tn_tick_int_processing(). Если ядро должно разбудить какую-то задачу через 100 системных тиков, то tn_tick_int_processing() должен быть вызван именно через 100 периодов системного тика (но внешние асинхронные события, конечно, могут произойти и изменить это).Для этого, ядро должно иметь возможность пообщаться с приложением:
- Чтобы запланировать следующий вызов
tn_tick_int_processing()через N тиков; - Чтобы спросить, сколько времени (т.е. получить текущий system ticks count).
Так что, когда режим динамический тик активен (
TN_DYNAMIC_TICK установлен в 1), приложение должно предоставить указатели на эти коллбэки при старте системы. Конечно, фактическая реализация этих коллбэков полностью зависит от типа MCU (даже на одинаковой архитектуре есть огромное количество разных MCU, которые имеют разную периферию, и т.д.), поэтому корректная реализация этих коллбэков лежит на приложении.Старт системы
Для нормального функционирования, ядру нужно следующее:
- Пространство для стека задачи Idle;
- Пространство для стека прерываний;
- Коллбэк для задачи Idle;
- Какая-нибудь пользовательская задача (задачи).
Так что, перед стартом системы, приложение должно выделить массивы для стека задачи Idle и для прерываний, предоставить коллбэк задачи Idle (он может быть пустой), и предоставить специальный коллбэк, который должен создать как минимум одну (и обычно именно одну) пользовательскую задачу. Это — первая задача, которая будет запущена, и в моих приложениях я обычно называю ее
task_init или task_conf. Очевидно, она выполняет инициализацию приложения.В
main(), приложение должно:- Запретить системные прерывания, вызвав
tn_arch_int_dis(); - Произвести основную инициализацию микроконтроллера: как минимум, настройки осциллятора;
- Настроить прерывание системного таймера (из ISR которого вызывается
tn_tick_int_processing()); - Вызвать
tn_sys_start(), предоставив всю необходимую информацию: указатели на массивы для стеков, их размеры, и коллбэк-функции.
Ядро делает следующее:
- Инициализирует очереди на запуск (массив списков
_tn_tasks_ready_list), и другие аспекты внутреннего состояния ядра; - Создает и активирует задачу Idle (после этого,
_tn_next_task_to_runуказывает на дескриптор задачи Idle) - Вызывает пользовательскую функцию, в которой первая пользовательская задача создается и активируется (после этого,
_tn_next_task_to_runуказывает на дескриптор самой высокоприоритетной пользовательской задачи); - Вызывает зависящую от архитектуры функцию
_tn_arch_sys_start(), которая инициализирует прерывание для переключения контекста, и производит первое переключение контекста в задачу, на дескриптор которой указывает_tn_next_task_to_run.
После этого, система работает в обычном режиме: пользовательская задача получает управление и может делать все то, что может делать любая пользовательская задача. Обычно, она делает следующее:
- Инициализирует различную периферию на плате (ЖК дисплеи, флешки, или что угодно);
- Инициализирует программные модули, используемые в приложении;
- Создает все остальные пользовательские задачи (т.к. все уже инициализировано, они теперь могут приступать к своей работе).
Больше деталей реализации
Окей, кажется, я должен остановиться в какой-то момент: вряд ли у меня получится описать каждую деталь реализации в этой статье, которая уже, честно говоря, слишком большая.
Я постарался затронуть наиболее интересные темы, которые нужны для понимания картины в целом; для других тем, читатель легко сможет изучить исходный код, который я постарался сделать действительно хорошим и понятным. Исходники доступны: используйте их!
Если у вас есть любые вопросы, задавайте в комментариях.
Юнит тесты
Обычно, когда говорят о юнит-тестах, имеют в виду тесты, запускаемые на хост-машине. Но, к сожалению, компиляторы, используемые для встраиваемых систем, нередко содержат ошибки, так что я решил тестировать ядро прямо в железе. Таким образом, я могу быть уверен, что ядро 100% работает на моем устройстве.
Краткий обзор реализации тестов:
Есть высокоприоритетная задача «test director», которая создает себе «рабочие» задачи и различные объекты РТОС (очереди сообщений, мютексы, и т.д.), и затем говорит рабочим задачам, что им делать. Например:
- Задача А, ты блокируешь мютекс М1
- Задача В, ты блокируешь мютекс М1
- Задача С, ты блокируешь мютекс М1
- Задача А, ты удаляешь мютекс М1
После каждого шага, test director ждет, пока рабочие сделают свою работу, и затем проверяет, что все идет по плану: проверяет состояния задач, их приоритеты, последние возвращенные значения из сервисов ядра, различные свойства объектов, и т.д.
Подробный лог выводится в UART. Обычно, после каждого шага, выводится следующее:
- Дословный комментарий;
- Test director пишет, что он делает;
- Каждая рабочая задача пишет, что она делает;
- Test director проверяет все и пишет отчет.
Вот пример выводимого лога:
//-- A locks M1 (line 404 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task A: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task A]: locking mutex (0xa0004c40).. [I]: [Task A]: mutex (0xa0004c40) locked [I]: [Task A]: waiting for command.. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=6 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- B tries to lock M1 -> B blocks, A has priority of B (line 413 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task B: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task B]: locking mutex (0xa0004c40).. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- C tries to lock M1 -> B blocks, A has priority of C (line 422 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task C: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task C]: locking mutex (0xa0004c40).. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- A deleted M1 -> B and C become runnable and have retval TN_RC_DELETED, A has its base priority (line 431 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task A: delete mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task A]: deleting mutex (0xa0004c40).. [I]: [Task C]: mutex (0xa0004c40) locking failed with err=-8 [I]: [Task C]: waiting for command.. [I]: [Task B]: mutex (0xa0004c40) locking failed with err=-8 [I]: [Task B]: waiting for command.. [I]: [Task A]: mutex (0xa0004c40) deleted [I]: [Task A]: waiting for command.. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=6 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_DELETED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_DELETED (as expected) [I]: * Mutex M1: holder=NONE (as expected), lock_cnt=0 (as expected), exists=no (as expected)
Если что-то идет не так, то будет не «as expected», а ошибка и подробности.
Я очень постарался смоделировать все возможные ситуации в рамках одной подсистемы (мютексы, очереди, и т.д.), включая ситуации с приостановленными задачами, удаленными задачами, удаленными объектами, и т.д. Это очень помогает поддерживать ядро действительно стабильным.
Заключительные слова
Почему бы просто не использовать FreeRTOS?
Окей, есть несколько причин.
Во-первых, мне не нравится их лицензия: по лицензии, FreeRTOS запрещено сравнивать с другими продуктами! Гляньте на последний параграф из FreeRTOS licence:
FreeRTOS may not be used for any competitive or comparative purpose, including the publication of any form of run time or compile time metric, without the express permission of Real Time Engineers Ltd. (this is the norm within the industry and is intended to ensure information accuracy).
Насколько мне известно, они добавили это условие после очень старой дискуссии на форуме Microchip, где люди выложили графики сравнения нескольких ядер, и эти графики были не в пользу FreeRTOS. Автор FreeRTOS заявил, что измерения неверны, но, как ни забавно, не смог предоставить «правильные» измерения.
Так что, если я напишу ядро, которое оставит FreeRTOS позади в том или ином аспекте, я не смогу об этом написать. Может, я чего-то не понимаю, но, по-моему, ерунда какая-то. Мне не нравятся подобные вещи.
Кстати, несколько лет назад, когда мои коллеги рекомендовали TNKernel, они говорили, что TNKernel намного быстрее, чем FreeRTOS. После того, как я реализовал TNeo, то из любопытства я, конечно, произвел пару сравнений, но, к сожалению, не могу их опубликовать из-за лицензии FreeRTOS.
Во-вторых, ее исходный код мне тоже не нравится. Возможно, я просто слишком идеалист, но для меня, ядро реального времени — это, в некоторой степени, особый проект, и я хочу, чтобы он был настолько близок к идеалу, насколько возможно.
Да, сейчас самое время заценить код TNeo на GitHub и объяснить, почему он отстойный. Возможно, это поможет мне сделать ядро еще лучше!
В-третьих, я хотел иметь более или менее готовую замену TNKernel, чтобы я мог легко портировать существующие приложения на новое ядро. Принимая во внимание проблемы в TNKernel под микрочиповские микроконтроллеры, описанные в первой части статьи, у наших устройств всегда была вероятность неопределенного поведения.
И последнее, но не менее важное, работать над ядром — крайне увлекательное занятие!
Тем не менее, у FreeRTOS есть неоспоримое преимущество над (возможно) всеми остальными подобными продуктами: она портирована на огромное количество архитектур. К счастью, мне не нужно так много.
Где TNeo используется?
На данный момент, я портировал на TNeo все существующие приложения, которые раньше работали на TNKernel: бортовые компьютеры, зарядники, и т.д. Работает безупречно.
Я также представил ядро на ежегодном семинаре Microchip MASTERS 2014, начальник отдела разработки StarLine заинтересовался и попросил меня портировать ядро под архитектуру Cortex-M. Сейчас это уже давно готово, и ядро используется в их последних продуктах.
Документация и исходники
TNeo — тщательно протестированная вытесняющая РТОС для 16- и 32-битных микроконтроллеров с открытым исходным кодом.
Проект размещен на GitHub: TNeo.
В данный момент, ядро портировано на следующие архитектуры:
- ARM Cortex-M cores: Cortex-M0/M0+/M1/M3/M4/M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32MX/PIC24/dsPIC
Полная документация доступна в двух вариантах: html и pdf.
Моя оригинальная статья на английском: How I ended up writing new real-time kernel. Т.к. автор оригинальной статьи — я сам, то, с вашего позволения, я не стал помещать эту статью в категорию «перевод».
