Comments 290
Это самый нелепый список придуманных проблем, которые я видел. Возмущаться тем, что тебе неудобны запятые в литералах и называть отсутствие встроенного дорогого копирования слайсов разных типов — плохим дизайном, попуская Пайка — это новый уровень Хабра?
Илья, я знаю, что ты ещё учишься в школе, но зачем так позориться? Даже зная твою любовь к троллингу, это как-то слишком топорно.
Илья, я знаю, что ты ещё учишься в школе, но зачем так позориться? Даже зная твою любовь к троллингу, это как-то слишком топорно.
numbers = append(numbers[:2], append([]int{3}, numbers[2:]...)...)
И это необходимый минимум, чтобы вставить элемент в массив. Ты все еще считаешь, что Go совершенен?
А кто сказал, что вставка элемента в середину непрерывного куска памяти — тривиальная задача?
Вот только непонятно, почему она должна быть такой же сложной в коде.
Ну потому что это 3 операции на самом деле, а не одна:
Но я согласен, можно было и сделать удобный метод вставки по позиции.
s = append(s, 0)
copy(s[i+1:], s[i:])
s[i] = x
Но я согласен, можно было и сделать удобный метод вставки по позиции.
Это технически три операции, а семантически — одна. Что мешало сделать
insert(numbers, i, v)?Тем, что городить новый keyword ради спорной нужности операции — это именно то, от чего в Go старались уйти.
К сожалению, вся остальная продемонстрированная работа со слайсами тоже не блещет.
Почему бы не сделать это в виде библиотечных функций, как это везде повсюду? Как же знаменитый code-reuse? Из языка вырезали так много, что приходится обратно все туда руками заталкивать. И это будет не стандартный API, а велосипед, который все и каждый делают заново. Это — плохо продуманный язык. Кто-то слишком фанател идеей о «спорной нужности операции».
Приведите три реальных примера, когда Вам нужно засовывать элементы в произвольное место в массиве/слайсе. Реальные кейсы только, пожалуйста. У меня, к примеру, за последние 2 года таких кейсов не было.
Поскольку вы утверждаете, что это крайне нужная операция, и авторы Го просто недостаточно умны, в отличие от школьников, чтобы понять это, это не должно составить труда.
Поскольку вы утверждаете, что это крайне нужная операция, и авторы Го просто недостаточно умны, в отличие от школьников, чтобы понять это, это не должно составить труда.
Добавление элемента в сортированный список.
Если нужен сортированный список — используйте linked list и сортируйте при вставке, слайсы тут причем?
Еще примеры? Реальные, из ежедневных проектов, которые вы пишете, желательно.
Еще примеры? Реальные, из ежедневных проектов, которые вы пишете, желательно.
Часть алгоритмов сортировки. Те же деревья (не все они состоят из связанных списков), многие производят манипуляции с массивом в памяти, потому что всё равно всё упрётся в диск. Опять же, связанный список требует дополнительное место на хранение указателя на следующий объект. Массив быстрее связанного списка на ряде задач, например, взятие элемента i в случае массива — операция со сложностью 1, а в случае списка 1-N.
Хорошо, котируется — специфические структуры данных. Вопрос — как часто вы пишете свои структуры данных? Сколько раз в неделю? В месяц? В году?
Сколько процентов от вашего основного кода занимает разработка своих структур данных? Оригинальный вопрос в силе — приведите 3 реальных последних примера из своего опыта этой «высокой нужной операции». Вопрос без подвоха.
Сколько процентов от вашего основного кода занимает разработка своих структур данных? Оригинальный вопрос в силе — приведите 3 реальных последних примера из своего опыта этой «высокой нужной операции». Вопрос без подвоха.
Я пишу на js, но вы правы, это действительно редкая операция, последний раз использовал вставку в середину массива примерно в апреле, когда реализовывал те самые b+tree для серверсайда.
> Вопрос — как часто вы пишете свои структуры данных?
простите, а вы на работе чем занимаетесь? То есть я не понимаю как вообще писать программы больше 1000 строк, не создавая структур данных.
простите, а вы на работе чем занимаетесь? То есть я не понимаю как вообще писать программы больше 1000 строк, не создавая структур данных.
старая изжеванная проблема — LinkedList vs ArrayList
Далеко не всегда связные списки хороши, к тому же в памяти гадят, а с учетом, что язык с со сборкой мусора…
Далеко не всегда связные списки хороши, к тому же в памяти гадят, а с учетом, что язык с со сборкой мусора…
Забавно, что за более чем десять лет программирования мне ни разу не приходилось использовать linked list ни в геймдеве, ни в контестах, вообще нигде, кроме как в примерах первого учебника по ООП. Уж насколько медленная эта структура, учитывая структуру кэша памяти! Кстати, рекомендую к прочтению «What every programmer should know about memory»
Разнообразные отсортированные очереди структур данных. Добавление должно происходить не в конец очереди, а в место, определенное каким-то полем структуры, например таймстампом.
Придумать кейс можно, безусловно. Тут у меня те же вопросы: почему именно слайс и как часто вы пишете свои очереди структур данных? Речь о компромиссах и приоритетах. И да, все еще хочу увидеть по три реальных примера этого «частого важного кейса» из реальной практики.
Я просто объединил свои частые кейсы. Реальные примеры, которыми я недавно занимался — очередь заявок на обработку оператором (заявки должны обрабатываться в сложном порядке, новая заявка далеко не всегда вставляется в конец очереди), очередь исполнения бизнес-транзакций по сущности (некоторые транзакции добавляются задним числом), очередь сообщений, пришедших на сокет, которые должны обрабатываться тоже не в порядке поступления. Трех достаточно?
Может пора задуматься над несколькими очередями с разными приоритетами вместо того, чтобы использовать очередь таким образом, что она перестают быть очередью?
Бывает логика приоритетов сложнее, чем в тривиальной priority queue. Взять, например, какой-нибудь deadline scheduling.
Очереди с разными приоритетами был второй этап развития после обычной очереди. В перспективе — очереди, динамически изменяющиеся, а не с определением места при вставке.
Да все понятно уже. Ваша бизнес логика давно переросла функционал слайсов, но вместо того чтобы это осознать и использовать другую структуру данных (связный список тут явно напрашивается) вы продолжаете есть кактус и утверждать, что использование слайсов для этой задачи оправданно и типично.
связный список тут явно напрашивается
Иногда можно уперется в память, т. к. в linked list хранятся указатели на предыдущий и следующий элементы.
И linked list не поддерживает случаный доступ ( привет, O(n) вместо O(1) )
Стоп, кажется, это уже было сказано здесь…
Да все понятно уже
То есть возможность упереться в память при увеличении размера слайса вас не заботит (а это хоть и временное, но двукратное увеличение!) и вы не видите в этом проблемы, а вот пара лишних указателей (или даже один — списки бывают еще и односвязными, что в случае очереди кажется более оптимальным) — это большая проблема?
Да и тут речь даже не в том, какой способ лучше. Речь о том, что необходимость таких изощренных манипуляций по определению не может быть простой и не является типичным примером использования. В случае необходимости конечно придется повозиться, но это жизнь, так сказать. Но в 99% случаев при правильном подходе нет необходимости вставлять элементы в середину слайса и в этих 99% случаев слайсы в Пщ очень удобны и лаконичны.
То есть возможность упереться в память при увеличении размера слайса вас не заботит (а это хоть и временное, но двукратное увеличение!)
Не знал, что такая реализация ( это получается vector из C++ ). Тогда замечание про память невалидно.
Такая проблема ArrayList'а есть, она известна, но на практике, бездумное использование ArrayList явно говорит о неверном дизайне. С другой стороны, раз выделив шматок памяти под слайс(с запасом, конечно), мы спокойно вставляем элемент в нужное место — происходит сдвиг элементов, без выделения памяти. Но когда нужен быстрый произвольный доступ — это вариант. Если же у нас миллион элементов в связном списке, то наложится и работа сборщика мусора и отсутствие произвольного доступа и тп.
Где-то лучше связный список, где-то массив, эта тема уже 100500 раз поднималась, и все достоинства и недостатки подходов давно известны. Уже не раз сталкивался с тем, что стараются избавиться от указателей и делать всё на массивах, ибо на но больших объемах сборщик мусора просто не дает нормально работать, что в C#, что в Go. Но спор то не об этом.
Где-то лучше связный список, где-то массив, эта тема уже 100500 раз поднималась, и все достоинства и недостатки подходов давно известны. Уже не раз сталкивался с тем, что стараются избавиться от указателей и делать всё на массивах, ибо на но больших объемах сборщик мусора просто не дает нормально работать, что в C#, что в Go. Но спор то не об этом.
У связных списков есть другое проблемное место (особенно в concurrent окружении), они сильна трешат prefetch кэша, что может приводить к потере 1-2 порядков. Исключение — это выделение блоками (или одним потоком), чтобы все аллоцированные элементы связного списка лежали последовательно и давали предсказуемый memory access pattern.
Хм, а почему для таких очередей не использовалась пирамида?
позаимствованный Oberon-Way не всегда единственно правильный.
А кто сказал, что это сложная задача? Даже на С она решается тривиально и я даже осмелюсь сказать, что получится читабельнее этого месива из скобок и точек. Это не говоря о том, что в современных языках это обычно входит в стандартную библиотеку.
И чем оно читаемее, чем код ниже?
a = append(a[:position], append([]T{x}, a[position:]...)...)
идеальный вариант ИМХО
a.insert(position, value);Подброшу-ка я дровишек: именно так и выглядит аналогичный код на Rust. :)
Написал на коленке вариант враппера для Go: play.golang.org/p/OgzWfYeB1V
Здесь нет проверок границ и многого другого, но все красиво обернуть при желании тут тоже можно.
Конечно другое дело, что все это ложится на плечи конечного программиста: либо писать реализацию самому, либо использовать готовые библиотеки.
Здесь нет проверок границ и многого другого, но все красиво обернуть при желании тут тоже можно.
Конечно другое дело, что все это ложится на плечи конечного программиста: либо писать реализацию самому, либо использовать готовые библиотеки.
Библиотека для вставки элемента в середину массива – это прекрасно! Сразу вспомнилось это:
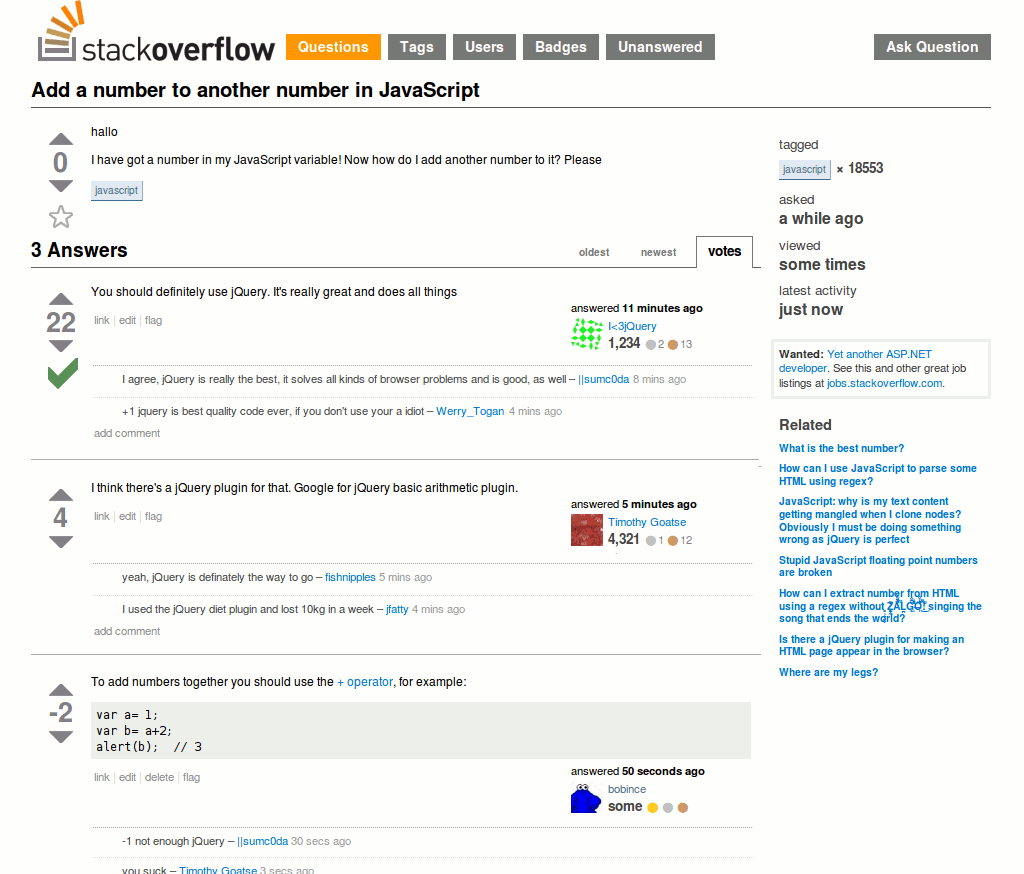
Угу…
Компилируется (еще бы), но при запуске (очевидно), выдает:
func main() {
d := []int{1,2,3,4}
s := NewHandySlice(d)
s.Insert(2, "abc")
fmt.Println(s.Values()[1].(int))
fmt.Println(s.Values()[2].(int))
}
Компилируется (еще бы), но при запуске (очевидно), выдает:
2 panic: interface conversion: interface is string, not int
Я же написал, что нету проверок никаких, это пример обертки.
Вы хотите production-ready код?
Вы хотите production-ready код?
Я хочу, чтобы проверки были compile-time, а не run-time. Это возможно?
В данном варианте нет.
Вот это и проблема. А будет ошибка на Insert или на приведении — уже не так важно.
Согласен. В С++ это можно было бы решить шаблонами. А вот в С точно так же only runtime checking.
А в некоторых языках просто есть дженерики.
Может и здесь скоро появится. «Некоторые» языки тоже не сразу их заимели.
То-то нам (почти) в каждом посте про Го дают ссылку на этот же документ как на объяснение, почему в Го дженериков не будет и это правильно.
Андрей Александреску обмолвился о generics в Go в одном из CppCast:
«It became the n-word of Go. Like you can't say 'generics' with 'Go', because everybody is gonna be offended in Go communitiy»
https://www.reddit.com/r/programming/comments/3qs888/cppcast_d_with_andrei_alexandrescu
Для тех, кто не знает, «n-word» — это эвфемизм слова «nigger» в США.
«It became the n-word of Go. Like you can't say 'generics' with 'Go', because everybody is gonna be offended in Go communitiy»
https://www.reddit.com/r/programming/comments/3qs888/cppcast_d_with_andrei_alexandrescu
Для тех, кто не знает, «n-word» — это эвфемизм слова «nigger» в США.
Тот факт, что мы активно обсуждаем операцию insert наталкивает меня на мысль о том, что видимо эти самые array в go являются growable (динамические). Если это так, то это мало чем отличается от векторов в C++ и Rust.
В каком языке векторы построены поверх array?
В каком языке векторы построены поверх array?
В java Vector — давно устаревшее говно мамонта. А актуальный ArrayList работает поверх массивов, с динамическим адаптивным расширением в зависимости от размера данных. В openjdk8 этот массив может быть либо пустым (константой), либо размером не менее 10 элементов. При небольших размерах он увеличивается с шагом в 50% от текущего размера.
Я не мыслю категориями «совершенен»/«не совершенен», это оставим школьникам. Вставка в произвольное место — это by design дорогая операция, вынуждающая двигать память, но 99% кейсов использования слайсов — это append. Это называется «компромисс», и все что касается дизайна языка — это всегда о компромиссах. То, что в слайсах в Go так неудобно делать произвольную вставку — создает стимул думать головой о том, какая структура данных больше подойдет, если нужно делать много быстрых произвольных вставок, а не вслепую ворочать память.
В любом случае, школьник тыкающий в Пайка и Томпсона, «объясняющий» им своим невежством, какой плохой они придумали дизайн — это мне непонятно.
В любом случае, школьник тыкающий в Пайка и Томпсона, «объясняющий» им своим невежством, какой плохой они придумали дизайн — это мне непонятно.
школьник тыкающий в Пайка и Томпсона, «объясняющий» им своим невежством, какой плохой они придумали дизайн — это мне непонятно
Ваня, ты наверное про нигилизм не слышал. Я не спорю, что Пайк и Томпсон крутые чуваки, но давай они хоть как-то будут объяснять свои решения. Удел разумного человека не идти на поводу у авторитетов, а делать соотв умозаключения, которые приведут его к истине.
Что вы заладили — «школьник», «школьник»… у вас школьник пирожок отобрал, что ли?
У вас судя по всему какой-то комплекс, на тему школьников, лол ;)
Как то возник вопрос «а как искать элемент в срезе?», возник ответ «перебором».
И вот что из этого вышло:
Ну, ты понял, да, когда надо будет писать программу, ты будешь не программой заниматься, а размышлять, а как же её написать в Go.
И вот что из этого вышло:
Пример поиска в срезе
Вывод
package main
import "fmt"
type IndexTeller interface {
Index (value interface{}) (pos int)
}
type MySlice []interface{}
func (s MySlice) Index(value interface{}) (pos int) {
for pos, e := range s {
if e == value {
return pos
}
}
return -1
}
func main() {
arr_i := MySlice{1, 2, 3, 4, 5}
arr_s := MySlice{"a", "b", "c", "d", "e"}
arr_m := MySlice{MySlice{1, 2, 3}, MySlice{"a", "b", "c"}}
var i int
i = arr_i.Index(2)
fmt.Println(i)
i = arr_s.Index("c")
fmt.Println(i)
i = arr_m.Index(MySlice{1, 2, 3})
fmt.Println(i)
}
Вывод
[guest@localhost go]$ go run t.go
1
2
panic: runtime error: comparing uncomparable type main.MySlice
goroutine 1 [running]:
main.MySlice.Index(0x18335f50, 0x2, 0x2, 0x80e5400, 0x183380a0, 0x0)
/home/guest/tmp/tests/misc/go/t.go:13 +0x90
main.main()
/home/guest/tmp/tests/misc/go/t.go:33 +0x89e
goroutine 2 [runnable]:
runtime.forcegchelper()
/usr/lib/golang/src/runtime/proc.go:90
runtime.goexit()
/usr/lib/golang/src/runtime/asm_386.s:2287 +0x1
goroutine 3 [runnable]:
runtime.bgsweep()
/usr/lib/golang/src/runtime/mgc0.go:82
runtime.goexit()
/usr/lib/golang/src/runtime/asm_386.s:2287 +0x1
goroutine 4 [runnable]:
runtime.runfinq()
/usr/lib/golang/src/runtime/malloc.go:712
runtime.goexit()
/usr/lib/golang/src/runtime/asm_386.s:2287 +0x1
exit status 2
[guest@localhost go]$
Ну, ты понял, да, когда надо будет писать программу, ты будешь не программой заниматься, а размышлять, а как же её написать в Go.
Меня больше всего поразило, что нельзя определить метод для этого. А еще кто-то недавно гнал на Ruby с его monkey-patching…
Я не совсем в теме, почему нельзя?
Дженериков нет. Этот метод придётся копипастить для каждого типа, используемого в массивах.
А что мешает использовать интерфейсы?
Необходимо определить операцию не над определённым типом, а над массивом таких типов, интерфейсы здесь причём?
есть способы с использованием стандартного пакета «reflect», но это конечно не очень круто, дженериков не хватает реально
Я об []interface.
Если существует такая частая необходимость вставки в вашей структуре данных, да еще со множеством различных типов, то почему не сделать тип-обертку над []interface{}
Если же планируется применять в паре типов, то сойдет и так:
Если существует такая частая необходимость вставки в вашей структуре данных, да еще со множеством различных типов, то почему не сделать тип-обертку над []interface{}
Как-то так
package main
import (
"fmt"
)
type arr []interface{}
func (a *arr) insert(pos int, x interface{}) {
*a = append((*a)[:pos], append([]interface{}{x}, (*a)[pos:]...)...)
}
func main() {
a := arr{1, 2, 3, 4, 5}
a.insert(2, 77)
fmt.Println(a)
// out: [1 2 77 3 4 5]
}
Если же планируется применять в паре типов, то сойдет и так:
func insert(a *[]int, pos int, x int) {
*a = append((*a)[:pos], append([]int{x}, (*a)[pos:]...)...)
}
Э… Всмысле нельзя? Т.е. вообще нельзя? А как жить, если надо? Можете для человека, который вообще не знает Go, коротко объяснить что именно нельзя и почему?
Ты ведь в курсе что можно оборачивать код который тебе не нравится в функции с более красивым дизайном? Го упрощен до невозможности, автор не ставил целью чтоб ты кончал когда пишешь на го, он упростил все действия, чтоб увеличить простоту и скорость, добавляя безопасности. Ты пишешь на голом языке, но избавлен от слежки за кодом постоянным. Со временем появятся и конструкции более менее универсальные, но сейчас цель у авторов отнюдь не идеальная красота кода, и они прямо об этом пишут.
Ты ведь в курсе что можно оборачивать код который тебе не нравится в функции с более красивым дизайном?
О, а как в Go обернуть в функцию код для вставки элемента в середину слайса произвольного типа (с сохранением типобезопасности, конечно)?
Функция не идеальна, но я без малого три дня как начал вникать в go, может более опытные могут сделать лучше? То же можно сделать и в обертке, которую я приводил выше, там был ваш вопрос о типизации.
func insert(s interface{}, pos int, x interface{}) {
switch a := s.(type) {
case *[]int:
*a = append((*a)[:pos], append([]int{x.(int)}, (*a)[pos:]...)...)
case *[]byte:
*a = append((*a)[:pos], append([]byte{x.(byte)}, (*a)[pos:]...)...)
case *[]string:
*a = append((*a)[:pos], append([]string{x.(string)}, (*a)[pos:]...)...)
// case ...
}
return
}
Во-первых, типобезопасность не сохранена — если я передам
Во-вторых, не будет работать для произвольного (неизвестного на момент написания функции) типа.
s одного типа, а x — другого, будет ошибка приведения.Во-вторых, не будет работать для произвольного (неизвестного на момент написания функции) типа.
В Go УЖЕ есть универсальная встроенная функция манипулирования слайсами, которая работает с любыми типами и с максимальной скоростью — append. И не нужно ничего изобретать, все уже изобретено и реализовано. Если вам не нравится синтаксис — это ни как не проблемы языка. Более того, так и задумано. Неужели вы считаете, что авторы оказались не способны привнести в синтаксис сахарку, если бы посчитали это необходимым? Я вас уверяю, смогли бы. Тот факт, что эта функция реализована именно таким образом говорит о том, что авторы языка считают именно такой синтаксис наиболее подходящим и я лично с ними в этом солидарен. Этот синтаксис показывает программисту, что операция которую он совершает, не простое присваивание, а ресурсоемкая задача. Нравится вам это или нет, но этот язык именно такой. Если он вам не подходит — не пишите на нем. Но не надо говорить, что язык плох из-за того, что он для вас недостаточно подслащен. Расслабьтесь и наслаждайтесь жизнью в сторонке от Go.
Спасибо за просвещение.
Теперь поднимитесь на пару уровней выше по ветке и посмотрите, на какой именно комментарий я отвечал.
Теперь поднимитесь на пару уровней выше по ветке и посмотрите, на какой именно комментарий я отвечал.
Этот синтаксис показывает программисту, что операция которую он совершает, не простое присваивание, а ресурсоемкая задача.
Ох е. И вы действительно в это верите? Есть другая причина — разработчики языка не продумали эту сторону, и мы имеем неоптимальное, некрасивое, неудобное решение. И ваши оправдания тому, что это нормально, выглядят нелепо. Ресурсоемкость задачи программисту должна говорить документация, но никак не монструозный синтаксис, который вообще никак с ресурсоемкостью не коррелирует и не связан. Есть плохой синтаксис и есть примитивная операция как то вставка в произвольное место массива. Это примитивная операция и не надо пытаться доказать обратно в надежде, что это сойдет за оправдание Go.
Расслабьтесь и наслаждайтесь жизнью в сторонке от Go.
А давайте вы лучше будете жить спокойнее в сторонке от тем, который так вас подрывают. Нравится — ок. Нам не нравится — извольте нам дать свободу для обсуждения. На любой язык ругаются и это позволяет сделать их лучше. На Страуструпа с плюсами жалуются — получаем новые стандарты. На команду C# жалуемся — получаем новые версии языка. Авось и до команды Go дойдет, что дизайн языка таки не блещет. В нем много хорошего, но достаточно проблемных мест, которые никак не подорвут его философию.
Точно, не заметил.
Задача слишком быстро начала обрастать дополнительными условиями) Началось все с «невозможности» обернуть код вставки выше в метод. Дальше понадобилась одна ф-я для нескольких типов, чтобы не «копипастить» метод, потом строгая типизация, далее произвольные типы и типобезопасность.
Думаю остановлюсь на варианте со строгой типизацией и возможностью реализации для каждого типа, для которого понадобится использование функции в приложении.
Задача слишком быстро начала обрастать дополнительными условиями) Началось все с «невозможности» обернуть код вставки выше в метод. Дальше понадобилась одна ф-я для нескольких типов, чтобы не «копипастить» метод, потом строгая типизация, далее произвольные типы и типобезопасность.
Думаю остановлюсь на варианте со строгой типизацией и возможностью реализации для каждого типа, для которого понадобится использование функции в приложении.
Отвечу Вашими же словами :)
У человека выше подгорело из-за синтаксиса
А не из-за того что в go нет шаблонов. Как бы тоже следите за цепью диалога, а потом свои несчастные 5 коп вставляйте.
Спасибо за просвещение.
Теперь поднимитесь на пару уровней выше по ветке и посмотрите, на какой именно комментарий я отвечал.
У человека выше подгорело из-за синтаксиса
И это необходимый минимум, чтобы вставить элемент в массив. Ты все еще считаешь, что Go совершенен?
А не из-за того что в go нет шаблонов. Как бы тоже следите за цепью диалога, а потом свои несчастные 5 коп вставляйте.
Вот прямо в исходном посте все про это написано: «А так как у нас нет никаких этих ваших дженериков, то написать красивую функцию insert(), которая будет прятать весь этот ужас просто не получится.»
Для меня это очень логичный ход мысли: уродливый синтаксис — написать что-нибудь, что его прячет — что, мне это писать для каждого типа?! Причем это не выдуманное, я по этой тропинке прыгал во времена .net 1, где напишешь какую-нибудь удобную мулечку, а потом ррраз — и вынужден ее повторять еще для пары разных типов.
(причем даже когда дженерики случились, тоже было больно, потому что операции сложения они, скажем, не покрывали, и приходилось отдельно прыгать)
Для меня это очень логичный ход мысли: уродливый синтаксис — написать что-нибудь, что его прячет — что, мне это писать для каждого типа?! Причем это не выдуманное, я по этой тропинке прыгал во времена .net 1, где напишешь какую-нибудь удобную мулечку, а потом ррраз — и вынужден ее повторять еще для пары разных типов.
(причем даже когда дженерики случились, тоже было больно, потому что операции сложения они, скажем, не покрывали, и приходилось отдельно прыгать)
Да, придется повторять, с этим то никто и не спорит, но я не пойму, почему не сказать прямо (я напомню я отвечал не напрямую посту, а комментарию) «меня бесит копипаст, не хочу повторять код». Вместо этого приводят просто длинный и уродливый кусок кода со словами «смотри какой уродливый код мне приходится писать?». Об этом речь а не о типе и невозможности написать универсальный для типа код.
Это самоподдерживающаяся аргументация. Копипасты приходится писать, потому что язык не позволяет сделать универсальное решение; универсальное решение нужно потому, что кусок кода, решающий задачу, уродлив. Выдерните любой пункт — остальная боль тоже пропадет, потому что можно будет одно за другим спрятать.
Нет, это называется вброс, или «непрямой аргумент». Когда автор специально искажает данные для пущего эффекта. Ибо прямые указания будут иметь меньший эффект. Если я скажу «не люблю копипастить, были бы дженерики тут», это все поддержат, ибо никто этого не любит, это очевидная проблема, и никто даже обсуждать это не будет, про нее все знают, но если я скажу «язык уродлив и не позволяет мне делать мои элегантные конструкции, которые давно уже есть в других языках». Вроде смысл тот же, но бомбить начинает у людей уже на много сильней. Я не приветствую такие провокационные фразы от других.
Если я скажу «не люблю копипастить, были бы дженерики тут», это все поддержат, ибо никто этого не любит, это очевидная проблема, и никто даже обсуждать это не будет, про нее все знают
Ох, я был бы рад, если бы это было так.
В том то и дело, в среде любителей го этот вопрос обсуждается больше всего, это очень наболевшая тема и все были бы счастливы если бы эта фича наконец-то появилась. Я даже не знаю кто может отрицать что в го этого не хватает. Как и адекватной модульной системы. Я очень сомневаюсь что адекватный человек, знающий GO будет спорить про эти две вещи.
Только вот я это читаю и просто диву даюсь — да это ж пересказ всего того мата, который был у меня, когда я начинал писать на Go. Простая примитивная программа из-за тех же слайсов и чехорды между [n]int и []int превращается в такое убожество, что страшно. Язык простой, да, но код на нем получается совсем не простой.
Во-первых, зачем же ограничиваться обсуждениями школьник/не школьник, давайте обсудим национальность и сексуальные предпочтения автора поста.
Во-вторых, это перевод.
В-третьих, если у языка с точки зрения программиста есть недостатки, почему бы ими не поделиться? Если это будет субъективная неприязнь данного программиста, статья сгинет в Лету, если многих это беспокоит, почему не обсудить? Спокойно и конструктивно. После ваших комментов возникат одна мысль — «Бомбануло».
Во-вторых, это перевод.
В-третьих, если у языка с точки зрения программиста есть недостатки, почему бы ими не поделиться? Если это будет субъективная неприязнь данного программиста, статья сгинет в Лету, если многих это беспокоит, почему не обсудить? Спокойно и конструктивно. После ваших комментов возникат одна мысль — «Бомбануло».
Судя по традиционному срачу в коментах, Go это новый JS
Ну окей, человеку не нравятся эти моменты языка, он это рассказал в своём блоге. Но зачем мне-то знать, что ему не нравится?
Прошу заметить как автор элегантно в первом предложении снял с себя ответственность под видом перевода. А перевод-то своего собственного поста :)
Решил покопаться ещё. Автор, опять же, сам лично разместил ссылку на реддите на свой же пост: www.reddit.com/r/programming/comments/3qjo3y/why_go_is_a_poorly_designed_language_from_a. И «обширность» обсуждения на реддите спровоцирована не статьёй, а ложными фактами, отсебятиной и враньём в цитатах Роба Пайка у автора (люди потрудились, поискали и выяснили, что он такого не говорил).
В общем, не стоит попадаться на грязные уловки автора и мнимый авторитет самого себя :)
В общем, не стоит попадаться на грязные уловки автора и мнимый авторитет самого себя :)
У меня в статье нет ни одной цитаты Пайка, о чем ты?
Первое предложение третьего абзаца в оригинальной английской статье. Пайк такого не говорил и даже не подразумевал.
Он говорил как-то так:
...And yet, with that long list of simplifications and missing pieces, Go is, I believe, more expressive than C or C++. Less can be more.
But you can't take out everything. You need building blocks such as an idea about how types behave, and syntax that works well in practice, and some ineffable thing that makes libraries interoperate well.
We also added some things that were not in C or C++, like slices and maps, composite literals, expressions at the top level of the file (which is a huge thing that mostly goes unremarked), reflection, garbage collection, and so on. Concurrency, too, naturally.
Ну смотри, там я действительно облажался — я не хотел цитаты, я хотел его несколько перефразировать. Там была ссылка на его статью, где он после списка вещей (огромного списка), которые они из Go убрали, говорит: «But you can't take out everything. You need building blocks such as an idea about how types behave, and syntax that works well in practice, and some ineffable thing that makes libraries interoperate well.»
Это кагбэ намекаэт, что он пытался убрать все по-максимуму, так что я не очень-то и соврал. С другой стороны — да, нехорошо получилось. Но ничего, я кавычки из оригинала убрал и заменил said на according to, спасибо за фидбэк.
Это кагбэ намекаэт, что он пытался убрать все по-максимуму, так что я не очень-то и соврал. С другой стороны — да, нехорошо получилось. Но ничего, я кавычки из оригинала убрал и заменил said на according to, спасибо за фидбэк.
Ооо, началось!

Стиль неуместный.
Простите, мистер зануда, я больше так не буду.
Зря вы считаете, что ваши фамильярные выпады на Пайка и закос под нейтив инглиш спикера в оригинале — это сколь нибудь оригинально или остроумно.
Нормальный стиль. Главное ведь не стиль, а чтобы информация усваивалась мозгом максимально быстро. Можно писать скучную документацию в официальном стиле, а можно вот так. Какой вариант усвоится лучше?
Для меня лично некоторым гарантом юзабельности Go является его использование в том же ВК (статьи были на Хабре). Но чему-то слишком разрекламированному у некоторых людей часто возникает отторжение. Да простит меня хабр, но именно так произошло, например, с фильмом «50 оттенков серого» — чрезмерная реклама и разочарование от обыденности. Статья — наглядный пример такой реакции.
Это может ничего не значить. Допустим, у меня есть нагруженный проект. И нужно поправить некий батлнек производительности, максимально оптимизировать. И предположим, что в силу сложившихся обстоятельств наилучшую производительнсть мне дает Brainfuck (обеспечивая необходимую стабильность и не порождая других проблем). Конечно же, я напишу это на нем. Но это не говорит ничего о юзабельности языка. Лишь о том, что у него есть свои сильные стороны и что ситуативно имеет смысл его использовать.
И это лишь один из вариантов, почему язык %language% используется в %project%.
И это лишь один из вариантов, почему язык %language% используется в %project%.
Во да, мы Go выбрали именно для тех задач, где он проявляет свои сильные стороны.
Лишь о том, что у него есть свои сильные стороны и что ситуативно имеет смысл его использовать
Ну да, значит язык применим на практике (пусть даже в определенном круге задач), то бишь юзабелен. Я особо ничего больше и не имел ввиду. Если не ошибаюсь, то как раз AterCattus рассказывал в презентации про то, как хорошо Go был применим для задачи, подчеркивая отсутствие желания переписывать всю логику сайта на этом языке. Полностью согласен.
Вообще считать ВК авторитетным глупо. Они не использовали ООП при написание такого большого, сложного по структуре и высоконагруженого проекта.
Если команда ВК смогла написать проект такого уровня без использования ООП, то я скорее задумаюсь о необходимости ООП, чем о их криворукости. Я никогда не работал с ВК кроме как пользователь, но мне он не показался бажным или неповоротливым.
мне он не показался бажным или неповоротливым.
<offtop>
Давненько вы им не пользовались :)
</offtop>
Пятая проблема надумана — я не слышал ни про один язык программирования, где были бы циклы foreach «по ссылке» (кроме, наверное, C++ — там я немного отстал от мейнстрима).
Аналогичный код на Swift не компилируется: «cannot pass immutable value to mutating operator: 'number' is a 'let' constant». Кажется, автор этого просит, а не циклов по ссылке.
Ха. Просто так не компилируется? Да кого это останавливало!
Никогда ещё каменты в интернете не отзывались мне так быстро: оказывается, умудрился неделю назад посадить баг именно на Swift и именно этим способом.
var numbers = [0, 1, 2, 3, 4]
for var number in numbers {
number++
}
print(numbers) // [0, 1, 2, 3, 4]
Никогда ещё каменты в интернете не отзывались мне так быстро: оказывается, умудрился неделю назад посадить баг именно на Swift и именно этим способом.
Хотел про это же написать, но автор (частично) прав, например если перебирать массив объектов (в питоне), то эти объекты можно будет изменять, в го они копируются, пример.
В питоне объекты всегда передаются по ссылке на них, в го — всегда копируются. Циклы тут ни при чем: play.golang.org/p/B5Zyjj1-R3
Но, кстати, приведённый wtf переводится на Python без потерь:
>>> numbers = [0,1,2,3,4]
>>> for number in numbers: number += 1
>>> numbers
[0, 1, 2, 3, 4]Потому что в питоне (и в некоторых других) простые типы как строки и числа копируются, а словари, массивы и т.п. передаются ссылкой (т.е. копируется ссылка на объект).
Нет. Всё ссылка на объект, а вот += может быть вызовом метода __iadd__, а может быть присваиванием этой ссылке нового значения, если у объекта не оказалось этого метода.
Вот, кстати, доказательство:
PS извиняюсь за минус, не сразу понял о чем вообще речь
a = 5
=> None
b = a
=> None
object.__repr__(a)
=> '<int object at 0x7fd04cc16700>'
object.__repr__(b)
=> '<int object at 0x7fd04cc16700>'
b += 1
=> None
object.__repr__(b)
=> '<int object at 0x7fd04cc16720>'
b
=> 6
a
=> 5
PS извиняюсь за минус, не сразу понял о чем вообще речь
Конкретно с мелкими int тут другая история. В классическом CPython целочисленные значения от -5 до 256 представляются ссылками на массив констант. Поэтому переменные с одинаковыми значениями в диапазоне [-5, 256] содержат одинаковые ссылки.
Для остальных целочисленных значений такое условие уже не выполняется:
Эта особенность поддерживается на уровне операций:
>>> 256 is 256
True
>>> a = 256
>>> b = 256
>>> a is b
True
Для остальных целочисленных значений такое условие уже не выполняется:
>>> 257 is 257
True
>>> a = 257
>>> b = 257
>>> a is b
False
Эта особенность поддерживается на уровне операций:
>>> a = 256
>>> b = 257
>>> a is b
False
>>> b -= 1
>>> a is b
True
В примере mayorovp ничего не изменится, если вы замените
a = 2 на a = 2.0. Данная оптимизация тут совершенно не причём: это иллюстрация к тому, что foo += bar есть foo = foo + bar, если у foo нет метода __iadd__ (в этом случае это будет foo.__iadd__(bar)). Ни у строк, ни у чисел в Python такого нет.Если вам нужен адрес объекта, то вместо
object.__repr__(obj) можно использовать id(obj): он быстрее печатается. Правда, не показывает тип, но здесь тип очевиден.PHP.
в D программист управляет типом цикла(который может быть и по ссылке и по значению):
foreach(ref x; y) {
…
}
foreach(x; y) {
…
}
foreach(ref x; y) {
…
}
foreach(x; y) {
…
}
я тут на сцене появляется PHP как пример «совершенного» языка программирования, где это возможно :)
P.S. опоздал с комментом про PHP
P.S. опоздал с комментом про PHP
Это можно сделать как минимум в C++ и D. Я уверен, что в доброй пачке других языков аналогичное поведение также возможно. Конкретно в данном случае автора смущает не то, нет циклов «по ссылке», а то, что это никак не освещенно в документации.
Довольно странно освещать в документации отсутствие некоторой фичи…
… но вполне нормально детально изобразить поведение цикла.
Никто не просит писать в документации по циклу «цикла по коллекции с передачей элемента по ссылке в Гоу нет», просят написать «цикл по коллекции в Гоу всегда передаёт элемент по значению».
У автора просто неудачный пример с int. Если взять что-то вида
И в подавляющем большинстве распространенных языков (C, C++, Java, Scala, Python, Ruby, JS, как минимум) поведение будет отличаться от Go, т. к. поле в структуре поменяет значение.
package main
import "fmt"
type A struct {
B string
}
func main() {
as := []A{{B: "asd"}, {B: "zxc"}}
for _, item := range as {
item.B = item.B + "!"
}
for _, item := range as {
fmt.Print(item.B) // asdzxc
}
fmt.Println()
for i, _ := range as {
as[i].B = as[i].B + "!"
}
for _, item := range as {
fmt.Print(item.B) // asd!zxc!
}
}И в подавляющем большинстве распространенных языков (C, C++, Java, Scala, Python, Ruby, JS, как минимум) поведение будет отличаться от Go, т. к. поле в структуре поменяет значение.
Perl5
Эта проблема приятно решена в PHP, например. Добавляешь & и все.
Почему бы так не сделать в Go, удобно же.
foreach ($arr as &$value) {
$value = $value * 2;
}
Почему бы так не сделать в Go, удобно же.
Один безымянный язык:
foreach (val) {
// this.link = &(val[this.key])
// string|uint this.key
// this.value = val[this.key]
}P.s. Я просто оставлю это здесь, раз наткнулся...
P.p.s. Причём обратите внимание, что this.link хранит указатель — то есть, мы получаем ещё и адрес оригинального значения, а не только доступ к нему...
Ещё не понятно почему нельзя было сделать нормальный(!) менеджер зависимостей, ведь есть куча успешных реализаций: npm(nodejs), cargo(rust), composer(php),…
Если бы хоть немного погуглили перед тем как писать коммент, то все нашлось бы
github.com/avelino/awesome-go#package-management
github.com/avelino/awesome-go#package-management
Много кому (в том числе и мне) нравится go-get, прямо очень-очень нравится. Но так как мейнтейнеры (в итом числе и я) иногда ломают пакеты это не очень класс. Хотелось бы, чтобы была возможность задавать зависимость не только по URL, но еще и по git тегу, как это делает labix.org/gopkg.in
Меня настолько заинтересовали слова «шапито» и «циркопляска», что я даже не поленился посмотреть, как оно в оригинале. Потом поискал, сколько раз эти слова употреблялись на хабре ранее. Много думал.
если заглянуть в спецификацию и прочитать, что «a:=42» — это сокращённая запись выражения «var a=42» то третий пример (со скрытыми переменными) перестанет быть таким уж неожиданным.
Да, это так. Автор же и написал, что по спеке это совершенно легитимная тема, но так как слева err, можно легко ошибиться и попасть вот в такую скополовушку. В принципе, это не критично и любой толковый гофер быстро прохавает тему, но все равно указывает на несссовершенство языка.
Этот пример вообще дико странный, потому что является наглядной демонстрации областей видимости.
В C++ все точно также, один в один. Если ты открываешь блок { }, то значит, определяешь новую область видимости, значит, если ты определяешь новую переменную — старая не перезапишется. В чем несовершенство языка, скажите мне, пожалуйста?
В C++ все точно также, один в один. Если ты открываешь блок { }, то значит, определяешь новую область видимости, значит, если ты определяешь новую переменную — старая не перезапишется. В чем несовершенство языка, скажите мне, пожалуйста?
Наверное все-таки в том, что определние новой переменной и присваивание нового значения визуально мало чем отличаются (привет опечаткам и долгому дебагу).
Вы кажется не осознали всю боль. Откройте пример play.golang.org/p/TNfS7eyYSf и сотрите фигурные скобки, которые задают новую область видимости.
Код скомпилируется, несмотря на повторное :=
А вот если еще объявить var err error перед этим, то получим уже
Код скомпилируется, несмотря на повторное :=
А вот если еще объявить var err error перед этим, то получим уже
no new variables on left side of :=
Окей, я осознал всю боль. Доработал пример, чтобы все стало еще больнее play.golang.org/p/U4Xm5dDf52
Вот этот пример прямо шикарный вышел.
Лишнее двоеточие в 24 строке. Оно же, поправленное: play.golang.org/p/T6_6naVdv6
В том-же D, shadowing запрещён, что, на мой взгляд, добро. — сам я не редко совершаю ошибки связанные с ним.
Пожалуй скажу немного.
Go действительно поначалу очень привлекает.
Меня привлек распиаренностью где бы то ни было, воплями о «языке нового поколения», сочетании (!) Си и паскалеобразного синтаксиса.
Действительно, операция ":=" выглядела для меня странно…
Как и объявления типов справа — показалось слишком громоздким.
Потом становится понятно что это просто очередная пустышка.
Давайте ка вспомним ту самую цепочку «инновационных языков» зарождавшихся по очереди в недрах Apple для замены Objective-C.
Припоминаете?
Неужели сейчас началась та же болезнь у немного другой компании?
Go действительно поначалу очень привлекает.
Меня привлек распиаренностью где бы то ни было, воплями о «языке нового поколения», сочетании (!) Си и паскалеобразного синтаксиса.
Действительно, операция ":=" выглядела для меня странно…
Как и объявления типов справа — показалось слишком громоздким.
Потом становится понятно что это просто очередная пустышка.
Давайте ка вспомним ту самую цепочку «инновационных языков» зарождавшихся по очереди в недрах Apple для замены Objective-C.
Припоминаете?
Неужели сейчас началась та же болезнь у немного другой компании?
объявление типов справа кажется громоздким, а слева вполне лаконичное? кол-во символов то одинаковое
Вот пример с Go:
А вот с C++:
У вас есть возможность посчитать символы и подтвердить свои слова.
var v6 *int
А вот с C++:
int* v6;
У вас есть возможность посчитать символы и подтвердить свои слова.
ну вы же сказали именно про типы, а не переменные
Пример на Go
Пример на C
По-моему, в плане громоздкости нет разницы. Может быть Вам непривычно, это да
Но с переменными вы правы, но это уже к синтаксису перменных, а не к типам
Пример на Go
func SomeFunc(i int) {}
type MyInteger int
Пример на C
void SomeFunc (int i) {}
typedef int MyInteger;
По-моему, в плане громоздкости нет разницы. Может быть Вам непривычно, это да
Но с переменными вы правы, но это уже к синтаксису перменных, а не к типам
Слово «var» добавляется.
Иногда говорят что так проще для парсера, потому что «var» — заранее известное ключевео слово, после которого может быть только объявление объектов; а «int» — имя типа, которое в общем случае может быть и пользовательским именем типа. В общем это правильно (для функций однозначно правильно иметь ключевое слово «func», «fn» и т.п. в начале), хотя при желании можно сохранить и оригинальный сишный синтаксис для переменных — так как переменные объявляются чаще всего, и для сохранения единообразия с объявлением полей структур.
Для этого нужно принять что любые конструкции вида «name1 name2» (два идентификатора подряд) это всегда объявление объекта name2 типа name1. Все остальные случаи сделать как-то по другому. В частности, запретить заключать объявляемые объекты в круглые скобки, как это возможно в С/С++.
Иногда говорят что так проще для парсера, потому что «var» — заранее известное ключевео слово, после которого может быть только объявление объектов; а «int» — имя типа, которое в общем случае может быть и пользовательским именем типа. В общем это правильно (для функций однозначно правильно иметь ключевое слово «func», «fn» и т.п. в начале), хотя при желании можно сохранить и оригинальный сишный синтаксис для переменных — так как переменные объявляются чаще всего, и для сохранения единообразия с объявлением полей структур.
Для этого нужно принять что любые конструкции вида «name1 name2» (два идентификатора подряд) это всегда объявление объекта name2 типа name1. Все остальные случаи сделать как-то по другому. В частности, запретить заключать объявляемые объекты в круглые скобки, как это возможно в С/С++.
Еще упрощает задачу программисту в поиске мест объявления переменных, всего-то var и :=
Нет, аргументы функций внутри самих функций это тоже объявление переменных. Но идея про легкость поиска мне понравилась. В известных мне IDE зачастую не хватает умного поиска — найти все места где переменная объявлена, где она читается, где изменяется и т.д. Аналогично с типами — где объявлен, где объявляются объекты этого типа, где наследование от этого типа…
Вот тут подробно написано: blog.golang.org/gos-declaration-syntax
Опрератор := сам по себе очень неплох (я восхитился лаконичности и красоте, а также тем как удачно вернули к жизни это старое доброе паскалевское сочетание символов), но реализация ИМХО не совсем правильная. Это оператор, а не замена инструкции объявления, поэтому у меня большие сомнения в выражениях вида a, b := foo(). Неясен статус запятой — это оператор или что? Какой у нее приоритет по отношению к оператору создания объекта? Сейчас как-то не модно стало точное описание всех синтаксических элементов языка, а жаль. Просто показывают кучку примеров — смотрите как просто писать программы — тяп ляп и готово! Вместо того чтобы дать исчерпывающий перечень всех групп синтаксических элементов, их смысл, состав и правила использования.
У него есть еще одна странность — он не работает внутри выражений. То есть x := (y:=a+b)*c не прокатит, а жаль, это было бы действительно по-хакерски.
У него есть еще одна странность — он не работает внутри выражений. То есть x := (y:=a+b)*c не прокатит, а жаль, это было бы действительно по-хакерски.
Кому то очень нравится Go?
Или я в чем то не прав?
Ответь мне, о ты, минусовавший!
Или я в чем то не прав?
Ответь мне, о ты, минусовавший!
Но понимаете ли, стоит убрать внутренний контекст (фигурные скобки) и код заработает ровно так, как мы ожидаем («after 42»). Интересно девки пляшут, не так ли?
А что не так, не могли бы вы пояснить? По мне приведенный код вполне очевидно работает…
На сколько я понимаю это чем-то похоже:
def test():
a=0
print "before: {}".format(a) #0
def up():
a = 1
print "insert: {}".format(a) #1
up()
print "after: {}".format(a) #0
Так что ничего не очевидного я тут не вижу
В твоем коде очевидно, что `a` — это новая переменная. В коде из топика используется :=, слева от которого новая переменная err. К тому же там контекст может быть еще слабее, чем вложенная функция — цикл или условие. Короче говоря, как-то не очень на руку «читабельному» языку.
Как минимум для джаваскриптеров не очевидно.
В JavaScript все проще, там если
Кстати, лично для меня, по сравнению с тем же Питоном, это гораздо удобнее.
var или (что еще лучше) let — значит новая переменная, если нет — берем из внешней области видимости. Ну т.е.function f() {
var a = 0;
var b = 1;
function g() {
var a = 2;
b = 3;
}
g();
console.log(a); // 0
console.log(b); // 3
}
Кстати, лично для меня, по сравнению с тем же Питоном, это гораздо удобнее.
вместо def up напишите if
а вообще тут дело в := и это то как он ведет себя согласно документации
другое дело, что программист, пишущий/читающий код, может ожидать от этого оператора немного другого
а вообще тут дело в := и это то как он ведет себя согласно документации
другое дело, что программист, пишущий/читающий код, может ожидать от этого оператора немного другого
Автор-переводчик, что вы наделали! В статье творится просто невероятная понжовщина, и это ещё плюсовики серьёзно не ворвались.
А статья любопытная. Из неё понял, что у Go есть определённое родство с Питоном (те же слайсы и механизм наследования в чём-то похожий).
Как убеждённый фанат плюсов, я, вроде бы, должен радоваться кривулькам конкурентов. Но скажу что думаю: Go просто относительно молодой язык, который ещё успеет отшлифоваться в процессе различных процессов.
А статья любопытная. Из неё понял, что у Go есть определённое родство с Питоном (те же слайсы и механизм наследования в чём-то похожий).
Как убеждённый фанат плюсов, я, вроде бы, должен радоваться кривулькам конкурентов. Но скажу что думаю: Go просто относительно молодой язык, который ещё успеет отшлифоваться в процессе различных процессов.
Go просто относительно молодой язык, который ещё успеет отшлифоваться в процессе различных процессов.
Довольно спорное утверждение. Понимаете, Пайк и компания ясно дали всем еще в прошлом году понять, что «язык стабилен и мы не планируем его менять». С каждым релизом языку уделяют все меньше и меньше внимания. Это не потому что он уже взрослый и достиг своего технологического апогея, а просто потому что Пайка все устраивает, а он вообще считает, что подстветка кода не нужна, а лучший редактор это acme
{kind=link}
Понимаете, Пайк и компания ясно дали всем еще в прошлом году понять, что «язык стабилен и мы не планируем его менять»
Если так, то печально. Неужели на Go уже есть достаточное количество написанного кода, чтобы говорить об откатанности его фич?
а он вообще считает, что подстветка кода не нужна, а лучший редактор это acme
М-да… А чем подсветка-то им не угодила?
Неужели на Go уже есть достаточное количество написанного кода, чтобы говорить об откатанности его фич?
По-моему сейчас вообще лучшее время, чтобы Go форкнуть и сделать язык без старперов.
А чем подсветка-то им не угодила?
Не знаю. Но скорее всего как обычно — отвлекает и нарушает читабельность кода.
Ну acme допустим имеет красивую идею, которой, впрочем, подсветка синтаксиса никак не мешает (не пересекается), и могла бы быть введена…
Ну, если только на слайсы смотреть, то они ещё в фортране были. ;) Причём синтаксис там в этом месте куда прямее — www.mathcs.emory.edu/~cheung/Courses/561/Syllabus/6-Fortran/array4.html
Ну, холливара по поводу «С++ vs Go» не развернулся в достаточной степени… И слава Богу!
П.С.: Хотя в статье-ответке на эту статью по поводу плюсов всё-таки развернулся срач. Вообще, нужно сделать мега-статью, в которой было бы максимально объективное сравнение языков по основным метрикам: скорость работы, лаконичность кода, выразительность (хотя выразительность это спорно), и.т.д.
П.С.: Хотя в статье-ответке на эту статью по поводу плюсов всё-таки развернулся срач. Вообще, нужно сделать мега-статью, в которой было бы максимально объективное сравнение языков по основным метрикам: скорость работы, лаконичность кода, выразительность (хотя выразительность это спорно), и.т.д.
Пункты 3 и 5 о чем вообще? Из опыта работы с другими языками программирования для меня это очевидное поведение. Просто для tucnak, исходя из его опыта, это непривычно.
Есть язык программирования (в данном случае GO), есть те, кому он нравится, есть те, кому не нравится. К чему устраивать тут дискуссии по поводу «это я напишу с трех строк» — «а я напишу это в одну строку». Каждый выбирает то, что ему нравится, к чему он привык.
Такие дискуссии очень интересны. Сравните хотя-бы количество комментариев к этой статье и к любой другой.
Мне как человеку интересующемуся дизайном языков программирования и разрабатывающему свой язык, интересно в особенности.
Мне как человеку интересующемуся дизайном языков программирования и разрабатывающему свой язык, интересно в особенности.
Я тоже пытаюсь написать свой язык программирования. Если можете вышлите спецификацию своего языка и комментарии на misha_shar53@mail.ru. Хотелось бы ознакомиться.
Давайте к нам, любителям изобретать языки программирования :-) t.me/lang_idioms
К тому, что Go интенсивно форсят, почём зря.
Почему зря? Из-за того, что его так форсят, постоянно появляется куча новых статей и обсуждений, из которых можно вынести много полезного.
Из-за того, что его так форсят, постоянно появляется куча новых статей и обсуждений
«Из-за того, что хлеб намазывают маслом, он становится покрыт маслом».
Нет, серьёзно, фраза так и выглядит.
Или вы думаете что он станет лучше только из-за того, что его будут больше обсуждать и придумают больше путей обхода недостатков дизайна и ограничений?
Есть те, кто к нему (и конкурентам) присматривается для решения в будущем каких-то задач и ещё окончательное решение не принял.
а какая подобные операции из примера 1 выглядели бы в Rust?
Как-то так:
fn main() {
let mut numbers = vec![1, 2, 3, 4, 5];
println!("{:?}", numbers);
println!("{:?}", &numbers[2..]);
println!("{:?}", &numbers[1..3]);
println!("{:?}", &numbers[0..numbers.len()-1]);
numbers.push(6);
println!("{:?}", numbers);
numbers.remove(2);
println!("{:?}", numbers);
numbers.insert(2, 3);
println!("{:?}", numbers);
let copiedNumbers = numbers.clone();
println!("{:?}", copiedNumbers);
}
>Какие дураки Rust придумывали… Другое дело Пайк и Томпсон, они-то знают, что вставка в непрерывный кусок памяти это сложная задача!
Какой «громкий» язык. Зачем везде этот восклицательный знак?
«!» вместо мата :) Если серьезно, так обозначаются макросы в Rust, мощная возможность для расширения языка и сокращения шаблонного кода. Вот тут можно почитать kgv.github.io/rust_book_ru/src/macros.html
Хочу ещё добавить, что разделение «массивов» на owned vectors, которые, собственно, являются владельцами куска памяти, и срезов, которые просто предоставляют окно в уже существующий кусок памяти (естественным образом вытекающее из концепций владения и заимствования), на мой взгляд, удобнее и понятнее в работе, чем модель, когда сами срезы владеют памятью, на которую указывают.
А ещё в расте можно итерировать элементы и по ссылке, и по значению, на выбор. Пример с итерацией по изменяемой ссылке:
let mut numbers = vec![1, 2, 3, 4, 5];
for number in &mut numbers {
*number += 1;
}
println!("{:?}", numbers);
Еще интересные мысли по слайсам. В D применяется специальный оператор $, который означает размер того массива, в контексте которого он применяется. То есть arr[$-1] это как раз последний элемент массива. Похоже чем-то на отрицательные индексы Питона, но пожалуй более строго… ведь индекс может получиться и в результате вычисления, вызова функции, и кто знает какой он там получится?
Звучит как очень правильное решение, которое можно спарировать фанбою Go—адепту «читабельности». Но ты не волнуйся, Ваня все равно выкатит что-то вроде того, что $ это большое зло и вводить его в язык это гигантская трагедия, лучше заниматься циркоплясками с длиной контейнера. А вообще я его в PHP видел этот знак, нам это точно не надо!
А ещё он в баше активно используется. Ещё перл на ум приходит.
Тут еще есть такой аспект: операторных символов в ASCII мало (а использовать Unicode непреемлемо по причине того, что символы должны гарантированно быть на стандартной клавиатуре в любой стране мира). Поэтому при разработке языка нужно расходовать операторные символы достаточно продуманно.
Более того, его можно оверлоадить dlang.org/operatoroverloading.html#dollar
И более гибко, например: list[ 0 , $ / 2 ] — половина массива.
> Мне особенно нравится это шапито с троеточиями…
Троеточие это вот: ⫶ (triple colon), «…» — многоточие.
Троеточие это вот: ⫶ (triple colon), «…» — многоточие.
> Да-да, явное лучше чем неявное, но все же?
Наверное проблема в том, что использование []FancyInt как []Stringy некорректно?
Иначе в Join можно было бы сделать
У массивов нет нетривиального subtyping-а про типу элемента, это вроде как общеизвестно.
Наверное проблема в том, что использование []FancyInt как []Stringy некорректно?
Иначе в Join можно было бы сделать
items[0] = new FancyRune;
У массивов нет нетривиального subtyping-а про типу элемента, это вроде как общеизвестно.
Мне нравится это бурное обсуждение.
Впрочем, как и все обсуждения Go.
Хомячки (и не только на картинках) бесятся.
Неплохо расслабляет после работы с C# кодом.
Впрочем, как и все обсуждения Go.
Хомячки (и не только на картинках) бесятся.
Неплохо расслабляет после работы с C# кодом.
Взглянув на код, сразу понял что язык мне никогда не понравится
Складывается впечатление, что автор статьи не вполне понимает, что при всех достоинствах и недостатках Go — это все же нишевый язык. У компании в какой-то момент остро встал вопрос — где брать высококласных разработчиков в требуемых количествах? Пока тебе требуется 1-2-5 — это сложно, но реализуемо. Если тебе требуется тысяча — это практически неразрешимая задача. В итоге Google пошел альтернативным путем — разработал язык на которой можно быстро (пере)обучить человека с минимальным бэкграундом и при этом не дать возможности этому новообученному специалисту простора для выстреливания в ногу.
Если вы рассчитываете на проект, который будет писаться в течении 10-15 лет, то вы должны понимать, что команда может смениться и даже не раз и вам нужно, чтобы код был прост и понятен, чтобы в нем не было немыслимых заковырок, определяемых не реальной потребностью реализовать именно так, а скорее мотивацией «зырьте как я могу».
Понимание всего этого позволяет взглянуть на язык несколько под другим углом.
Если вы рассчитываете на проект, который будет писаться в течении 10-15 лет, то вы должны понимать, что команда может смениться и даже не раз и вам нужно, чтобы код был прост и понятен, чтобы в нем не было немыслимых заковырок, определяемых не реальной потребностью реализовать именно так, а скорее мотивацией «зырьте как я могу».
Понимание всего этого позволяет взглянуть на язык несколько под другим углом.
Интересный взгляд, но возникает вопрос, хочешь ли ты сам вступить в ряды этих самых «тысяч» разработчиков.
Ответом на этот вопрос лично для меня является другой вопрос:
Хочешь ли ты быть крут за счет того, что умеешь на питоне извернуться так, что 90% других разработчиков этот код просто не поймут или ты хочешь быть крут потому, что разрабатываешь большой и клевый продукт которым будут пользоваться тысячи? Язык разработки — это большая, но все же часть продукта, который на выходе может быть плох или хорош, и определяется это не только тем, насколько удобно работать со слайсами.
consul, fleet, etcd — вот лишь малый список достойных вещей написанных на Go.
Хочешь ли ты быть крут за счет того, что умеешь на питоне извернуться так, что 90% других разработчиков этот код просто не поймут или ты хочешь быть крут потому, что разрабатываешь большой и клевый продукт которым будут пользоваться тысячи? Язык разработки — это большая, но все же часть продукта, который на выходе может быть плох или хорош, и определяется это не только тем, насколько удобно работать со слайсами.
consul, fleet, etcd — вот лишь малый список достойных вещей написанных на Go.
Странно, что вы Kubernetes не назвали или Docker )
Мне довольно трудно было бы «чувствовать себя крутым потому что разрабатываешь большой и клевый продукт, которым будут пользоватся тысячи», если делается все для того, чтобы я был не более чем легко заменяемым винтиком внутри системы. Как то мало остантся место для ощущения причасности, не находите? Это тоже самое, что пахать поле руками в толпе себе подобных весь день и чувствовать себя крутым от того, что спасаешь человечество от голодного вымирания. Нет, простите, я лучше научусь использовать комбайн.
Ну и да, у меня как-то и без Go не возникало трудностей «разрабатывать большой и клевый продукт, которым будут пользоватся тысячи» и получалось гораздо читабельне ем выглядит код на Go.
Ну и да, у меня как-то и без Go не возникало трудностей «разрабатывать большой и клевый продукт, которым будут пользоватся тысячи» и получалось гораздо читабельне ем выглядит код на Go.
Я хочу :-)
разработал язык на которой можно быстро (пере)обучить человека с минимальным бэкграундом и при этом не дать возможности этому новообученному специалисту простора для выстреливания в ногу.
нужно, чтобы код был прост и понятен, чтобы в нем не было немыслимых заковырок, определяемых не реальной потребностью реализовать именно так, а скорее мотивацией «зырьте как я могу».
Кажется, когда-то так появилась Java?
по пунктам:
1) по сути отсылка к отсутствию generics
2) может момент не самый очевидный для данного кода, но если понимать, что такое интерфейс (а это ссылка на что-то) то все логично
3) вы объявили новую переменную, то есть в момент написания этого кода вы допустили ошибку, это не проблема языка он сделал ровно то, что вы от него хотели.
4) есть подозрение, что не от хорошего кода желание такие касты делать.
5) что тут не очевидного, даже синтаксически, вы объявляете новые переменные, почему они должны быть другого типа чем у вас есть в массиве?
после этого вас уже откровенно начинает нести:
> Окей, но как только дело доходит до «читабельности», Роб Пайк решает, что надо ВНЕЗАПНО добавить запятые.
6) это синтаксис, в import и var нет в том месте запятых, а конструкции:
numbers := []int{
3, 5
4
}
явно выглядят куда хуже, кстати запятая в последнем элементе обязательна и проверяется при компиляции, так что пункт вообще не в кассу
7) кодогенерация запускается вручную, явно, отдельной командой.
то есть вместо того чтобы писать https://github.com/golang/net/blob/master/html/atom/gen.go можно сразу описать конструкцию которую можно запустить и сгенерировать новый файл table.go
В общем не сказать, что проблем нет, например если бы добавили опцию при которой можно отключить unused import стало бы чуть лучше, с generics кодогенерация спасает, но для стандартных контейнеров например это не очень классно хранить в каждом месте копию кода, а в реализации на интерфейсах нужно постоянно делать type assertion.
Плохо ещё, что аннотации есть только в структурах, а для типа например их нет.
По сути эти моменты уперлись в ту двухперстную простоту языка с которой он создавался и в 2.0 должен быть неких рефакторинг, но не факт что, что-то сильно поменяется
1) по сути отсылка к отсутствию generics
2) может момент не самый очевидный для данного кода, но если понимать, что такое интерфейс (а это ссылка на что-то) то все логично
3) вы объявили новую переменную, то есть в момент написания этого кода вы допустили ошибку, это не проблема языка он сделал ровно то, что вы от него хотели.
4) есть подозрение, что не от хорошего кода желание такие касты делать.
5) что тут не очевидного, даже синтаксически, вы объявляете новые переменные, почему они должны быть другого типа чем у вас есть в массиве?
после этого вас уже откровенно начинает нести:
> Окей, но как только дело доходит до «читабельности», Роб Пайк решает, что надо ВНЕЗАПНО добавить запятые.
6) это синтаксис, в import и var нет в том месте запятых, а конструкции:
numbers := []int{
3, 5
4
}
явно выглядят куда хуже, кстати запятая в последнем элементе обязательна и проверяется при компиляции, так что пункт вообще не в кассу
7) кодогенерация запускается вручную, явно, отдельной командой.
то есть вместо того чтобы писать https://github.com/golang/net/blob/master/html/atom/gen.go можно сразу описать конструкцию которую можно запустить и сгенерировать новый файл table.go
В общем не сказать, что проблем нет, например если бы добавили опцию при которой можно отключить unused import стало бы чуть лучше, с generics кодогенерация спасает, но для стандартных контейнеров например это не очень классно хранить в каждом месте копию кода, а в реализации на интерфейсах нужно постоянно делать type assertion.
Плохо ещё, что аннотации есть только в структурах, а для типа например их нет.
По сути эти моменты уперлись в ту двухперстную простоту языка с которой он создавался и в 2.0 должен быть неких рефакторинг, но не факт что, что-то сильно поменяется
Как хорошо, что божественный rust…
… не используется в production. ;)
почему?
Все известные мне люди, которым нравится Rust, и которых я спрашивал про production, говорили «нет». У меня даже появилось ощущение, что Rust красив только до тех пор, пока на нём не начинаешь писать что-то настоящее.
Но, конечно, это анекдот, в обоих смыслах.
Но, конечно, это анекдот, в обоих смыслах.
Я думаю ваши друзья отвечали «нет» в первую очередь потому, что еще некоторое время назад (до выхода версии 1.0) язык очень активно изменялся: обычная практика, когда правильный код не компилировался потому что у вас компилятор недельной давности (такого периода было достаточно, чтобы компилатор можно было считать устаревшим). Также, сразу после выхода 1.0, много важных вещей в стандартной библиотеке еще не было стабилизировано. Это добавляло ощущения нестабильности.
Но, к счастью, Rust уже дорос до 1.4, большинство API стабилизировано, новые библиотеки растут как на дрожжах и ничего не ломают. Конечно, это не значит, что всем стоит бросится писать на Rust, но если предположить, что код на Rust уже добрался до продакшена, то там у него точно будет все хорошо.
Но, к счастью, Rust уже дорос до 1.4, большинство API стабилизировано, новые библиотеки растут как на дрожжах и ничего не ломают. Конечно, это не значит, что всем стоит бросится писать на Rust, но если предположить, что код на Rust уже добрался до продакшена, то там у него точно будет все хорошо.
Библиотеки часто пока не так хороши, как сам язык, вроде батареек и много, но они еще сыроваты. Да и пока нет ничего вменяемого для UI. А язык, вроде бы, должен подходить для программирования UI.
Ну и в bare metal разработке тоже пока все сыро, хотя и выглядит крайне вкусно.
А еще пока нет нормальных средств интернационализации.
Ну и в bare metal разработке тоже пока все сыро, хотя и выглядит крайне вкусно.
А еще пока нет нормальных средств интернационализации.
Думаю просто потому что растаманы маленько торопятся с номерами версий. И еще никто не зарелизил на нем что-то типа докера. Но полагаю ждать уже осталось недолго.
И да, он действительно красив)
И да, он действительно красив)
// Чтобы скопировать слайс, ты должен будешь написать это:
//
copiedNumbers := make([]int, len(numbers))
copy(copiedNumbers, numbers)
copiedNumbers := numbers[:]
В Python работает так же, к слову.
не совсем (вернее это совсем не копирование): http://play.golang.org/p/b2hrKq5rem
об этом даже прямо в блоге написано: http://blog.golang.org/go-slices-usage-and-internals
> Slicing does not copy the slice's data. It creates a new slice value that points to the original array
об этом даже прямо в блоге написано: http://blog.golang.org/go-slices-usage-and-internals
> Slicing does not copy the slice's data. It creates a new slice value that points to the original array
// Интересный факт: отрицательные индексы не работают!
The omission of this feature (present in Python, for example) is deliberate
When performing arithmetic on slice indices it would be unfortunate if an erroneous negative result «just worked» as a reverse index. This leads to subtle bugs.
There are readability benefits to the status quo, also. It is clear that the Go expression s[:i] is creating a slice of s that is i bytes long. If i could be negative then the reader would need more context to understand the slice expression.
This is in keeping with Go's general philosophy of avoiding subtle syntactic tricks.
Про range вообще не понял, там же ясно стоит :=
Да, это объясняет почему так получается — но не объясняет зачем так сделано.
Это частный случай Zero value. Во всех остальных случаях оно очень удобно и эффективно.
Складывается ощущение, что автор не очень хорошо знает Go и имеет не так много опыта в разработке вообще. Но это ладно.
1) То что описано в реальном коде приходилось использовать от силы один раз. А частые операции со слайсами в Go куда понятнее и лаконичнее. В общем, если автору частно приходиться писать такой код, то может и не в языке дело.
«numbers[:-1]» — ну это просто Python головного мозга. Зачем требовать фич одного языка у другого, если другой намеренно хочет избежать опасных конструкций.
2) nil interface. Пункт с которым я соглашусь. Считаю это багом, который почему-то не хотят исправлять.
3) Ну сокрытие, ничего забавного — все очевидно. Если ты хороший разработчик — это не проблема. Причем одно забавное сокрытие в Go таки есть, но автор про него не знает, оно связано с именованными возвращаемыми значениями. Впрочем статические анализаторы на это обычно ругаются.
4) К сожалению передать []struct как []interface передать нельзя, было бы чуть удобнее, но откуда истерика по этому поводу?
5) foreach. Если вдумчиво читать стандарт языка, то все становится очевидным. Приводить в пример все остальные языки не имеет смысла, т.к. во многих из них нет понятия указателя. В данном случае это критично. Автор приводит в пример C++. Давайте смотреть ретроспективно — сколько прошло времени, чтобы в C++ вообще появился foreach?
6) unused imports — это наоборот то, что в Go прекрасно. Сначала раздражает строгость, но спустя некоторое время привыкаешь и испытываешь удовольствие от чистоты кода, в котором нет лишних неиспользуемых переменных и импортов. Это и полезно — по первым строчкам становится ясно что использует файл, а что нет. И авторы заморачивались не только на простоту, как думает автор, но и на скорость компиляции, лишние импорты при этом совершенно ни к чему. И многие конструкции в языке строги, подозреваю, отчасти и по этой причине.
7) Про кодогенерацию ничего не скажу, т.к. не приходилось использовать.
Итого, смотрим на эти пункты. Кто, откровенно может сказать, что эти пункты вообще что-то говорят про плохой дизайн языка?
Да, есть недочеты, но в C++ их куда больше, причем это не такие безобидные вещи — там с легкостью можно отстрелить себе обе ноги носовым платком.
Везде есть свои особенности и недостатки — идеала нет. Но, с моей точки зрения и опыта, это один из языков с лучшим дизайном, при этом минималистичным. Это не значит, что Go можно изучить за 2 недели. Нет, за 2 недели на нем можно научиться писать и если на этом остановиться, то будут появляться такие статьи. Чтобы изучить Go нужно хотя бы месяца 4 активной разработки и параллельного изучения особенностей и конструкций языка. Сладкий фрукт, да не каждый до него достает.
1) То что описано в реальном коде приходилось использовать от силы один раз. А частые операции со слайсами в Go куда понятнее и лаконичнее. В общем, если автору частно приходиться писать такой код, то может и не в языке дело.
«numbers[:-1]» — ну это просто Python головного мозга. Зачем требовать фич одного языка у другого, если другой намеренно хочет избежать опасных конструкций.
2) nil interface. Пункт с которым я соглашусь. Считаю это багом, который почему-то не хотят исправлять.
3) Ну сокрытие, ничего забавного — все очевидно. Если ты хороший разработчик — это не проблема. Причем одно забавное сокрытие в Go таки есть, но автор про него не знает, оно связано с именованными возвращаемыми значениями. Впрочем статические анализаторы на это обычно ругаются.
4) К сожалению передать []struct как []interface передать нельзя, было бы чуть удобнее, но откуда истерика по этому поводу?
5) foreach. Если вдумчиво читать стандарт языка, то все становится очевидным. Приводить в пример все остальные языки не имеет смысла, т.к. во многих из них нет понятия указателя. В данном случае это критично. Автор приводит в пример C++. Давайте смотреть ретроспективно — сколько прошло времени, чтобы в C++ вообще появился foreach?
6) unused imports — это наоборот то, что в Go прекрасно. Сначала раздражает строгость, но спустя некоторое время привыкаешь и испытываешь удовольствие от чистоты кода, в котором нет лишних неиспользуемых переменных и импортов. Это и полезно — по первым строчкам становится ясно что использует файл, а что нет. И авторы заморачивались не только на простоту, как думает автор, но и на скорость компиляции, лишние импорты при этом совершенно ни к чему. И многие конструкции в языке строги, подозреваю, отчасти и по этой причине.
7) Про кодогенерацию ничего не скажу, т.к. не приходилось использовать.
Итого, смотрим на эти пункты. Кто, откровенно может сказать, что эти пункты вообще что-то говорят про плохой дизайн языка?
Да, есть недочеты, но в C++ их куда больше, причем это не такие безобидные вещи — там с легкостью можно отстрелить себе обе ноги носовым платком.
Везде есть свои особенности и недостатки — идеала нет. Но, с моей точки зрения и опыта, это один из языков с лучшим дизайном, при этом минималистичным. Это не значит, что Go можно изучить за 2 недели. Нет, за 2 недели на нем можно научиться писать и если на этом остановиться, то будут появляться такие статьи. Чтобы изучить Go нужно хотя бы месяца 4 активной разработки и параллельного изучения особенностей и конструкций языка. Сладкий фрукт, да не каждый до него достает.
написать красивую функцию insert()
Возвращаясь в полусонном бреду, без всяких проверок… play.golang.org/p/22eNJO0Js3
Наконец-то пост ненависти про Go. А то все предыдущие статьи — один пиар и хомяк этот кривой на логотипах. Слишком форсят свой суперязычок. Хочется к его названию подписать «вно».
Интересы: «Assembler, Delphi, Интерфейсы». Конечно, у Delphi более ясное будущее чем у Go.
Хабраслив или тонкая игра в провокацию?
Хабраслив или тонкая игра в провокацию?
не, просто люблю комментировать спустя два дня, никто не заминусует, можно спокойно высказать мысли. Дельфи — паскаль, стоящий отдельным синтаксисом с зари времен, с ним рядом стоят бейсик, си-подобные языки. Это всё будет жить вечно, как и процессорные коды. А новомодное дмецо, которое по хорошему на одну ладонь положить, другой прихлопнуть и растереть — лезет сегодня из всех дыр. Каждый хочет урвать кусок пирога, выдвинуть свой суперпуперязык или новый синтаксис (с миллионом скобочек и двоеточий, «облегчающих» написание кода) на первое место чтоб школота неистово кодила на всем этом скопище манкиязычков. Я из движения хейтерства и сопротивления этому процессу.
А новомодное дмецо, которое по хорошему на одну ладонь положить, другой прихлопнуть и растереть — лезет сегодня из всех дыр
Д-р, простите, не узнал вас в гриме.

«Теперь весь мир стоит на краю, глядя вниз на чертово пекло. Все эти либералы, интеллектуалы, сладкоголосые болтуны. И отчего-то вдруг никто не знает, что сказать. Подо мной этот ужасный город, он вопит как скотобойня полная умственно отсталых детей, а ночь воняет блудом и нечистой совестью»
А если серьёзно — удачи. Всегда уважал фанатиков и верил что пусть даже окольными путями лишь фанатики могут принести какие-либо плоды. Злые ли, добрые будут эти плоды — другой вопрос. Но лишь одержимые движут мир.
Ох уж эти масоны.
Хотят поработить мир с помощью Go
Хотят поработить мир с помощью Go
> Причина №1. Манипуляции со слайсами просто отвратительны
Согласен
> Причина №2. Нулевые интерфейсы не всегда нулевые :)
Согласен, что это нелогично
> Причина №3. Забавное сокрытие переменных
Вообще не понял, почему автор ожидал 42 в последней строке. По-моему, поведение Go в этом случае верное.
> Причина №4. Ты не можешь передать []struct как []interface
Для начала хочется сказать, что тип rune для int32 вообще вызывает странное ощущение. Почему было не оставить просто int32, не понимаю?
А с самой причиной согласен в том контексте, что в Go (ну прям как в до боли знакомом php) нужно помнить про очередные подводные камни. Со временем к ним так привыкаешь, что даже и не воспринимаешь как проблему. Типа «да это же все знают!».
И да, если вспомнить про реализацию чего-то, подобного DI, с ожидаемыми параметрами с типами определенных интерфейсов, то причина выглядит серьёзной.
> Причина №5. Неочевидные циклы «по значению»
Ну смотря для кого неочевидные. Как по мне, отсутствие явного указателя передачи по ссылке уже говорит, что будет возвращено только значение.
> Причина №6. Сомнительная строгость компилятора
Согласен полностью, во время отладки бесит всё время комментировать и раскомментировать подключаемые библиотеки для отладки.
> Причина №7. Кодогенерация в Go это просто костыль
Согласен. Вообще против концепции генерации кода. Если язык не в состоянии предоставить удобные инструменты из коробки или с помощью фреймворков, то что-то в нём не так.
P.S.:
От себя добавлю ещё вот этот кейс, с которым я столкнулся при попытке написать первую простенькую программку на Golang, и который был сразу же заминусован на SO.
Согласен
> Причина №2. Нулевые интерфейсы не всегда нулевые :)
Согласен, что это нелогично
> Причина №3. Забавное сокрытие переменных
Вообще не понял, почему автор ожидал 42 в последней строке. По-моему, поведение Go в этом случае верное.
> Причина №4. Ты не можешь передать []struct как []interface
Для начала хочется сказать, что тип rune для int32 вообще вызывает странное ощущение. Почему было не оставить просто int32, не понимаю?
А с самой причиной согласен в том контексте, что в Go (ну прям как в до боли знакомом php) нужно помнить про очередные подводные камни. Со временем к ним так привыкаешь, что даже и не воспринимаешь как проблему. Типа «да это же все знают!».
И да, если вспомнить про реализацию чего-то, подобного DI, с ожидаемыми параметрами с типами определенных интерфейсов, то причина выглядит серьёзной.
> Причина №5. Неочевидные циклы «по значению»
Ну смотря для кого неочевидные. Как по мне, отсутствие явного указателя передачи по ссылке уже говорит, что будет возвращено только значение.
> Причина №6. Сомнительная строгость компилятора
Согласен полностью, во время отладки бесит всё время комментировать и раскомментировать подключаемые библиотеки для отладки.
> Причина №7. Кодогенерация в Go это просто костыль
Согласен. Вообще против концепции генерации кода. Если язык не в состоянии предоставить удобные инструменты из коробки или с помощью фреймворков, то что-то в нём не так.
P.S.:
От себя добавлю ещё вот этот кейс, с которым я столкнулся при попытке написать первую простенькую программку на Golang, и который был сразу же заминусован на SO.
Когда уже перестанут называть рейтинг -1 словом «заминусован»?..
Для начала хочется сказать, что тип rune для int32 вообще вызывает странное ощущение.
rune — это специальный тип данных для работы с Unicode. Формально это алиас на int32, но выделен в отдельный тип, так как представляет конкретную сущность — «букву», или же codepoint.
Вообще против концепции генерации кода.
habrahabr.ru/post/269887
Я прочитал статью. Честно, я все-равно воспринимаю это как костыль в коде. Не понимаю, почему нельзя было решить это через концепцию управления зависимостями, например? Почему не билдить все дополнительные библиотеки используя список зависимостей, собранный в управляющих файлах? Пусть это будет та же команда go generate. Какая ей технически разница, откуда читать информацию — из файла или из отдельного конфига? Ладно, если кому-то хочется держать всю информацию о зависимостях в самом файле, то с чего вдруг это указывается в комментарии да ещё и со странными требованиями в виде «не должно быть пробела после //»?
Нет, вы меня не убедили.
Нет, вы меня не убедили.
namespace, поправьте первую строку, указывающую на перевод, пожалуйста, чтоб читатель понимал, что ориганал тоже был написан вами.
я немного подумал и решил, что не хочу делиться с читателем этим скромным фактом.
Вам решать, но divan0 тогда прав, утверждая, что ваш пост «был выдан за перевод» (http://habrahabr.ru/post/269817/).
Sign up to leave a comment.
Почему Go — это плохо продуманный язык программирования