
На этот раз я бы хотел рассказать, как настроить сей сабж, в частности каждый отдельный компонент, что бы в итоге получить свое собственное, расширяемое, отказоустойчивое облако на базе OpenNebula. В данной статье я рассмотрю следующие моменты:
- Установка Ceph, распределенного хранилища. (Я буду описывать установку двухуровневого хранилища с кэширующим пулом из SSD-дисков)
- Установка MySQL, Galera кластера с мастер-мастер репликацией
- Установка софт-свича OpenvSwitch
- Установка непосредственно самой OpenNebula
- Настройка отказоустойчивого кластера
- Первоначальная конфигурация
Темы сами по себе очень интересные, так что даже если вас не интересует конечная цель, но интересует настройка какого-нибудь отдельного компонента. Милости прошу под кат.
Небольшое вступление
Итак, что же мы получим в итоге?
После прочтения данной стати вы сможете развернуть свое собственное гибкое, расширяемое и к тому же отказоустойчивое облако на базе OpenNebula. Что же значат эти слова? — Давайте разберем:
- Расширяемое — это значит, что вам не придется перестраивать ваше облако при расширении. В любой момент вы сможете расширить ваше место в облаке, всего лишь добавив дополнительные жесткие диски в пул ceph. Еще вы можете без проблем сконфигурировать новую ноду и ввести ее в кластер при желании.
- Гибкое — девиз OpenNebula так и звучит «Flexible Enterprise Cloud Made Simple». OpenNebula очень простая в освоении и к тому же очень гибкая система. Вам не составит труда разобраться с ней, а так же при необходимости написать для нее свой модуль, т.к. вся система построена так, что бы быть максимально простой и модульной.
- Отказоустойчивое — В случае выхода из строя жесткого диска, кластер сам перестроится так, что бы обеспечить необходимое количество реплик ваших данных. В случае выхода из строя одной ноды, вы не потеряете управление, а облако продолжит функционировать до устранения вами проблемы.

Что нам для этого надо?
- Я буду описывать установку на 3 ноды, но в вашем случае их может быть сколько угодно.
Вы так же можете установить OpenNebula на одну ноду, но в этом случае вы не сможете построить отказоустойчивый кластер, а вся ваша установка по этому руководству сведется лишь к установке самой OpenNebula, и например, OpenvSwitch.
Кстати, еще вы можете установить CentOS на ZFS, прочитав мою предыдущую статью (не для продакшена) и настроить OpenNebula на ZFS, используя написанный мной ZFS-драйвер
- Также, для функционирования Ceph, крайне желательна 10G сеть. В противном случае, вам не имеет смысла поднимать отдельный кэш-пул, так как скоростные характеристики вашей сети будут даже ниже, чем скорость записи на пул из одних только HDD.
- На всех нодах установлен CentOS 7.
- Также каждая нода содержит:
- 2SSD по 256GB — для кэш-пула
- 3HDD по 6TB — для основного пула
- Оперативной памяти, достаточной для функционирования Ceph (1GB ОЗУ на 1TB данных)
- Ну и ресурсы необходимые для самого облака, CPU и оперативная память, которые мы будем использовать для запуска виртуальных машин
- Еще хотел добавить, что установка и работа большинства компонентов требует отключенного SELINUX. Так что на всех трех нодах он отключен:
sed -i s/SELINUX=enforcing/SELINUX=disabled/g /etc/selinux/config setenforce 0
- На каждой ноде установлен EPEL-репозиторий:
yum install epel-release
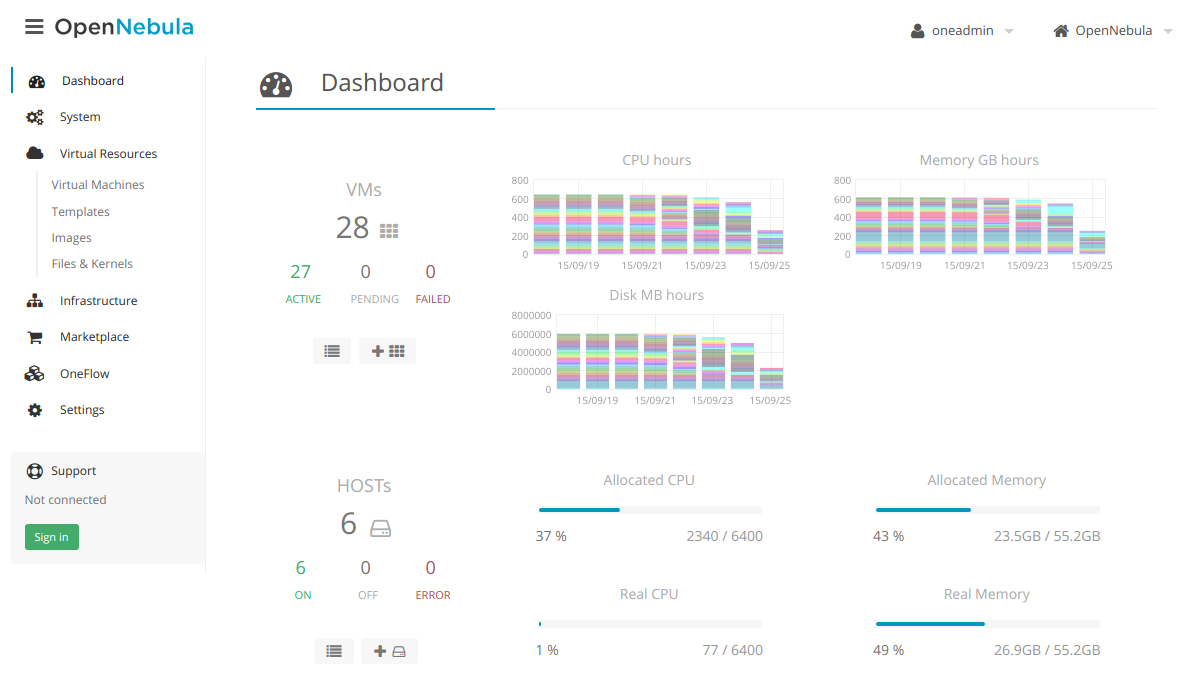
Схема кластера
Для понимания всего происходящего, вот примерная схема нашего будущего кластера:
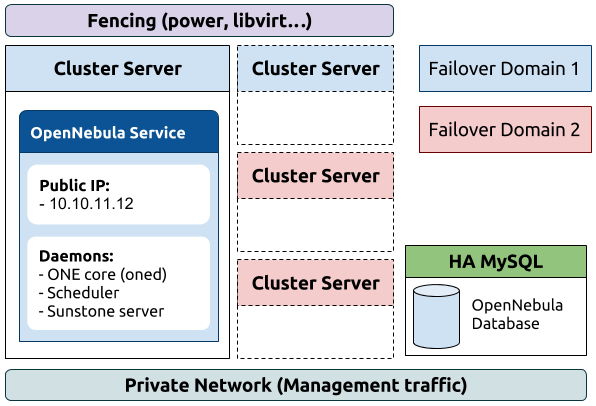
И табличка с характеристиками каждой ноды:
| Hostname | kvm1 | kvm2 | kvm3 |
|---|---|---|---|
| Network Interface | enp1 | enp1 | enp1 |
| IP address | 192.168.100.201 | 192.168.100.202 | 192.168.100.203 |
| HDD | sdb | sdb | sdb |
| HDD | sdc | sdc | sdc |
| HDD | sdd | sdd | sdd |
| SSD | sde | sde | sde |
| SSD | sdf | sdf | sdf |
Все, теперь можно приступать к настройке! И начнем мы пожалуй с построения хранилища.
Ceph
Про ceph на хабре уже не раз писали. Например teraflops довольно детально описал его устройство и базовые понятия в своей статье. Рекомендовано к прочтению.
Здесь же опишу настройку ceph для хранения блочных устройств RBD (RADOS Block Device) для наших виртуальных машин, а так же настройку кэш-пула для ускорения операций ввода-вывода в нем.
Итак мы имеем три ноды kvm1, kvm2, kvm3. Каждая из них имеет 2 SSD диска и 3 HDD. На этих дисках мы и поднимем два пула, один — основной на HDD, второй — кэширующий на SSD. В общей сложности у нас должно получиться что-то подобное:

Подготовка
Установка будет осуществляться с помощью ceph-deploy, а она подразумевает установку с так называемого админского сервера.
В качестве админского сервера может служить любой компьютер c установленным ceph-depoy и ssh-клиентом, в нашем случае таким сервером будет выступать одна из нод kvm1.
Нам необходимо на каждой ноде иметь пользователя ceph, а так же разрешить ему безпарольно ходить между нодами и выполнять любые команды через sudo так же без пароля.
На каждой ноде выполняем:
sudo useradd -d /home/ceph -m ceph sudo passwd ceph sudo echo "ceph ALL = (root) NOPASSWD:ALL" > /etc/sudoers.d/ceph sudo chmod 0440 /etc/sudoers.d/ceph
Заходим на kvm1.
Теперь сгенерируем ключ и скопируем его на остальные ноды
sudo ssh-keygen -f /home/ceph/.ssh/id_rsa sudo cat /home/ceph/.ssh/id_rsa.pub >> /home/ceph/.ssh/authorized_keys sudo chown -R ceph:users /home/ceph/.ssh for i in 2 3; do scp /home/ceph/.ssh/* ceph@kvm$i:/home/ceph/.ssh/ done
Установка
Добавляем ключ, установим репозиторий ceph и ceph-depoy из него:
sudo rpm --import 'https://download.ceph.com/keys/release.asc' sudo yum -y localinstall http://download.ceph.com/rpm/el7/noarch/ceph-release-1-1.el7.noarch.rpm sudo yum install -y ceph-deploy
Ок, теперь заходим за юзера ceph и создаем папку в которой мы будем хранить конфиги и ключи для ceph.
sudo su - ceph mkdir ceph-admin cd ceph-admin
Теперь установим ceph на все наши ноды:
ceph-deploy install kvm{1,2,3}
Теперь создадим кластер
ceph-deploy new kvm{1,2,3}
Создадим мониторы и получим ключи:
ceph-deploy mon create kvm{1,2,3} ceph-deploy gatherkeys kvm{1,2,3}
Теперь согласно нашей первоначальной схеме подготовим наши диски, и запустим OSD-демоны:
# Flush disks ceph-deploy disk zap kvm{1,2,3}:sd{b,c,d,e,f} # SSD-disks ceph-deploy osd create kvm{1,2,3}:sd{e,f} # HDD-disks ceph-deploy osd create kvm{1,2,3}:sd{b,c,d}
Посмотрим, что у нас получилось:
ceph osd tree
вывод
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -1 3.00000 root default -2 1.00000 host kvm1 0 1.00000 osd.0 up 1.00000 1.00000 1 1.00000 osd.1 up 1.00000 1.00000 6 1.00000 osd.6 up 1.00000 1.00000 7 1.00000 osd.7 up 1.00000 1.00000 8 1.00000 osd.8 up 1.00000 1.00000 -3 1.00000 host kvm2 2 1.00000 osd.2 up 1.00000 1.00000 3 1.00000 osd.3 up 1.00000 1.00000 9 1.00000 osd.9 up 1.00000 1.00000 10 1.00000 osd.10 up 1.00000 1.00000 11 1.00000 osd.11 up 1.00000 1.00000 -4 1.00000 host kvm3 4 1.00000 osd.4 up 1.00000 1.00000 5 1.00000 osd.5 up 1.00000 1.00000 12 1.00000 osd.12 up 1.00000 1.00000 13 1.00000 osd.13 up 1.00000 1.00000 14 1.00000 osd.14 up 1.00000 1.00000
Проверяем состояние кластера:
ceph -s
Настройка кэш-пула

Итак у нас есть полноценный ceph-кластер.
Давайте же настроим для него кэширующий пул, для начала нам надо отредактировать карты CRUSH что бы определить правила по которым у нас будут распределяться данные. Чтобы наш кэш-пул находился только на SSD-дисках, а основной пул только на HDD.
Для начала нам нужно запретить ceph обновлять карту автоматически, допишем в ceph.conf
osd_crush_update_on_start = false
И обновим его на наших нодах:
ceph-deploy admin kvm{1,2,3}
Сохраним нашу нынешнюю карту и переведем ее в текстовый формат:
ceph osd getcrushmap -o map.running crushtool -d map.running -o map.decompile
давайте приведем ее к такому виду:
map.decompile
# begin crush map tunable choose_local_tries 0 tunable choose_local_fallback_tries 0 tunable choose_total_tries 50 tunable chooseleaf_descend_once 1 tunable straw_calc_version 1 # devices device 0 osd.0 device 1 osd.1 device 2 osd.2 device 3 osd.3 device 4 osd.4 device 5 osd.5 device 6 osd.6 device 7 osd.7 device 8 osd.8 device 9 osd.9 device 10 osd.10 device 11 osd.11 device 12 osd.12 device 13 osd.13 device 14 osd.14 # types type 0 osd type 1 host type 2 chassis type 3 rack type 4 row type 5 pdu type 6 pod type 7 room type 8 datacenter type 9 region type 10 root # buckets host kvm1-ssd-cache { id -2 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item osd.0 weight 1.000 item osd.1 weight 1.000 } host kvm2-ssd-cache { id -3 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item osd.2 weight 1.000 item osd.3 weight 1.000 } host kvm3-ssd-cache { id -4 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item osd.4 weight 1.000 item osd.5 weight 1.000 } host kvm1-hdd { id -102 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item osd.6 weight 1.000 item osd.7 weight 1.000 item osd.8 weight 1.000 } host kvm2-hdd { id -103 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item osd.9 weight 1.000 item osd.10 weight 1.000 item osd.11 weight 1.000 } host kvm3-hdd { id -104 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item osd.12 weight 1.000 item osd.13 weight 1.000 item osd.14 weight 1.000 } root ssd-cache { id -1 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item kvm1-ssd-cache weight 1.000 item kvm2-ssd-cache weight 1.000 item kvm3-ssd-cache weight 1.000 } root hdd { id -100 # do not change unnecessarily # weight 0.000 alg straw hash 0 # rjenkins1 item kvm1-hdd weight 1.000 item kvm2-hdd weight 1.000 item kvm3-hdd weight 1.000 } # rules rule ssd-cache { ruleset 0 type replicated min_size 1 max_size 10 step take ssd-cache step chooseleaf firstn 0 type host step emit } rule hdd { ruleset 1 type replicated min_size 1 max_size 10 step take hdd step chooseleaf firstn 0 type host step emit }# end crush map
Можно заметить, что вместо одного root я сделал два, для hdd и ssd, тоже самое произошло с rule и каждым host.
При редактировании карты вручную будте предельно внимательны и не запутайтесь в id'шниках!
Теперь скомпилируем и назначим ее:
crushtool -c map.decompile -o map.new ceph osd setcrushmap -i map.new
Посмотрим, что у нас получилось:
ceph osd tree
вывод
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -100 3.00000 root hdd -102 1.00000 host kvm1-hdd 6 1.00000 osd.6 up 1.00000 1.00000 7 1.00000 osd.7 up 1.00000 1.00000 8 1.00000 osd.8 up 1.00000 1.00000 -103 1.00000 host kvm2-hdd 9 1.00000 osd.9 up 1.00000 1.00000 10 1.00000 osd.10 up 1.00000 1.00000 11 1.00000 osd.11 up 1.00000 1.00000 -104 1.00000 host kvm3-hdd 12 1.00000 osd.12 up 1.00000 1.00000 13 1.00000 osd.13 up 1.00000 1.00000 14 1.00000 osd.14 up 1.00000 1.00000 -1 3.00000 root ssd-cache -2 1.00000 host kvm1-ssd-cache 0 1.00000 osd.0 up 1.00000 1.00000 1 1.00000 osd.1 up 1.00000 1.00000 -3 1.00000 host kvm2-ssd-cache 2 1.00000 osd.2 up 1.00000 1.00000 3 1.00000 osd.3 up 1.00000 1.00000 -4 1.00000 host kvm3-ssd-cache 4 1.00000 osd.4 up 1.00000 1.00000 5 1.00000 osd.5 up 1.00000 1.00000
Теперь опишем нашу конфигурацию в конфиг ceph.conf, а в частности запишем данные о мониторах и osd.
У меня получился такой конфиг:
ceph.conf
[global] fsid = 586df1be-40c5-4389-99ab-342bd78566c3 mon_initial_members = kvm1, kvm2, kvm3 mon_host = 192.168.100.201,192.168.100.202,192.168.100.203 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx filestore_xattr_use_omap = true osd_crush_update_on_start = false [mon.kvm1] host = kvm1 mon_addr = 192.168.100.201:6789 mon-clock-drift-allowed = 0.5 [mon.kvm2] host = kvm2 mon_addr = 192.168.100.202:6789 mon-clock-drift-allowed = 0.5 [mon.kvm3] host = kvm3 mon_addr = 192.168.100.203:6789 mon-clock-drift-allowed = 0.5 [client.admin] keyring = /etc/ceph/ceph.client.admin.keyring [osd.0] host = kvm1 [osd.1] host = kvm1 [osd.2] host = kvm2 [osd.3] host = kvm2 [osd.4] host = kvm3 [osd.5] host = kvm3 [osd.6] host = kvm1 [osd.7] host = kvm1 [osd.8] host = kvm1 [osd.9] host = kvm2 [osd.10] host = kvm2 [osd.11] host = kvm2 [osd.12] host = kvm3 [osd.13] host = kvm3 [osd.14] host = kvm3
И раздадим его нашим хостам:
ceph-deploy admin kvm{1,2,3}
Проверяем состояние кластера:
ceph -s
Создание пулов
Для создания пулов, нам нужно посчитать правильное количество pg (Placment Group), они нужны для алгоритма CRUSH. Формула расчета такая:
и округление вверх, до ближайшей степени числа 2(OSDs * 100) Total PGs = ------------ Replicas
То есть в нашем случае, если мы планируем иметь только один пул на SSD и один пул на HDD с репликой 2, формула расчета получается следующая:
HDD pool pg = 9*100/2 = 450[округляем] = 512 SSD pool pg = 6*100/2 = 300[округляем] = 512
Если пулов на наш root планируется несколько, то полученное значение следует разделить на кол-во пулов
Создаем пулы, назначаем им size 2 — размер реплики, это значит что записанные в него данные будут дублироваться на разных дисках, и min_size 1 — минимальный размер реплики в момент записи, то есть сколько нужно сделать реплик в момент записи что бы «отпустить» операцию записи.
Пул one — понятное дело будет использоваться для хранения образов OpenNebulaceph osd pool create ssd-cache 512 ceph osd pool set ssd-cache min_size 1 ceph osd pool set ssd-cache size 2 ceph osd pool create one 512 ceph osd pool set one min_size 1 ceph osd pool set one size 2
Назначаем правила нашим пулам:
ceph osd pool set ssd-cache crush_ruleset 0 ceph osd pool set one crush_ruleset 1
Настраиваем что запись в пул one будет производиться через наш кэш-пул:
ceph osd tier add one ssd-cache ceph osd tier cache-mode ssd-cache writeback ceph osd tier set-overlay one ssd-cache
Ceph использует 2 основных операции очищения кэша:
- Flushing (промывка): агент определяет остывшие объекты и сбрасывает их в пул хранения
- Evicting (выселение): агент определяет неостывшие объекты и начиная с самых старых, сбрасывает их в пул хранения
Для определения «горячих» объектов используется так называемый Фильтр Блума.
Настраиваем параметры нашего кэша:
# Включаем фильтр bloom ceph osd pool set ssd-cache hit_set_type bloom # Сколько обращений к объекту что бы он считался горячим ceph osd pool set ssd-cache hit_set_count 4 # Сколько времени объект будет считаться горячим ceph osd pool set ssd-cache hit_set_period 1200
Так же настраиваем
# Сколько байтов должно заполниться прежде чем включится механизм очистки кэша ceph osd pool set ssd-cache target_max_bytes 200000000000 # Процент заполнения хранилища, при котором начинается операция промывания ceph osd pool set ssd-cache cache_target_dirty_ratio 0.4 # Процент заполнения хранилища, при котором начинается операция выселения ceph osd pool set ssd-cache cache_target_full_ratio 0.8 # Минимальное количество времени прежде чем объект будет промыт ceph osd pool set ssd-cache cache_min_flush_age 300 # Минимальное количество времени прежде чем объект будет выселен ceph osd pool set ssd-cache cache_min_evict_age 300
Ключи
Создадим пользователя one и сгенерируем для него ключ
ceph auth get-or-create client.oneadmin mon 'allow r' osd 'allow rw pool=ssd-cache' -o /etc/ceph/ceph.client.oneadmin.keyring
Так как он не будет писать напрямую в основной пул, выдадим ему права только на ssd-cache пул.
На этом настройку Ceph можно считать завершенной.
MariaDB Galera Cluster
Теперь настроим отказоустойчивую MySQL базу данных на наших нодах, в которой мы и будем хранить конфигурацию нашего дата центра.
MariaDB Galera Cluster — это MariaDB кластер с мастер-мастер репликацией использующий для синхронизации galera-библиотеку.
Плюс ко всему он довольно прост в настройке:
Установка
На всех нодах
Установим репозиторий:
cat << EOT > /etc/yum.repos.d/mariadb.repo [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/10.0/centos7-amd64 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1 EOT
И сам сервер:
yum install MariaDB-Galera-server MariaDB-client rsync galera
запустим демон, и произведем начальную установку:
service mysql start chkconfig mysql on mysql_secure_installation
Настраиваем кластер:
На каждой ноде создадим пользователя для репликации:
mysql -p GRANT USAGE ON *.* to sst_user@'%' IDENTIFIED BY 'PASS'; GRANT ALL PRIVILEGES on *.* to sst_user@'%'; FLUSH PRIVILEGES; exit service mysql stop
Приведем конфиг /etc/my.cnf к следующему виду:
Для kvm1:
cat << EOT > /etc/my.cnf collation-server = utf8_general_ci init-connect = 'SET NAMES utf8' character-set-server = utf8 binlog_format=ROW default-storage-engine=innodb innodb_autoinc_lock_mode=2 innodb_locks_unsafe_for_binlog=1 query_cache_size=0 query_cache_type=0 bind-address=0.0.0.0 datadir=/var/lib/mysql innodb_log_file_size=100M innodb_file_per_table innodb_flush_log_at_trx_commit=2 wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_address="gcomm://192.168.100.202,192.168.100.203" wsrep_cluster_name='galera_cluster' wsrep_node_address='192.168.100.201' # setup real node ip wsrep_node_name='kvm1' # setup real node name wsrep_sst_method=rsync wsrep_sst_auth=sst_user:PASS EOT
По аналогии с kvm1 запишем конфиги для остальных нод:
Для kvm2
cat << EOT > /etc/my.cnf collation-server = utf8_general_ci init-connect = 'SET NAMES utf8' character-set-server = utf8 binlog_format=ROW default-storage-engine=innodb innodb_autoinc_lock_mode=2 innodb_locks_unsafe_for_binlog=1 query_cache_size=0 query_cache_type=0 bind-address=0.0.0.0 datadir=/var/lib/mysql innodb_log_file_size=100M innodb_file_per_table innodb_flush_log_at_trx_commit=2 wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_address="gcomm://192.168.100.201,192.168.100.203" wsrep_cluster_name='galera_cluster' wsrep_node_address='192.168.100.202' # setup real node ip wsrep_node_name='kvm2' # setup real node name wsrep_sst_method=rsync wsrep_sst_auth=sst_user:PASS EOT
Для kvm3
cat << EOT > /etc/my.cnf collation-server = utf8_general_ci init-connect = 'SET NAMES utf8' character-set-server = utf8 binlog_format=ROW default-storage-engine=innodb innodb_autoinc_lock_mode=2 innodb_locks_unsafe_for_binlog=1 query_cache_size=0 query_cache_type=0 bind-address=0.0.0.0 datadir=/var/lib/mysql innodb_log_file_size=100M innodb_file_per_table innodb_flush_log_at_trx_commit=2 wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_address="gcomm://192.168.100.201,192.168.100.202" wsrep_cluster_name='galera_cluster' wsrep_node_address='192.168.100.203' # setup real node ip wsrep_node_name='kvm3' # setup real node name wsrep_sst_method=rsync wsrep_sst_auth=sst_user:PASS EOT
Готово, настало время запустить наш кластер, на первой ноде запускаем:
/etc/init.d/mysql start --wsrep-new-cluster
На остальных нодах:
/etc/init.d/mysql start
Проверим наш кластер, на каждой ноде запустим:
mysql -p SHOW STATUS LIKE 'wsrep%';
Пример вывода
+------------------------------+----------------------------------------------------------------+ | Variable_name | Value | +------------------------------+----------------------------------------------------------------+ | wsrep_local_state_uuid | 5b32cb2c-39df-11e5-b26b-6e85dd52910e | | wsrep_protocol_version | 7 | | wsrep_last_committed | 4200745 | | wsrep_replicated | 978815 | | wsrep_replicated_bytes | 4842987031 | | wsrep_repl_keys | 3294690 | | wsrep_repl_keys_bytes | 48870270 | | wsrep_repl_data_bytes | 4717590703 | | wsrep_repl_other_bytes | 0 | | wsrep_received | 7785 | | wsrep_received_bytes | 62814 | | wsrep_local_commits | 978814 | | wsrep_local_cert_failures | 0 | | wsrep_local_replays | 0 | | wsrep_local_send_queue | 0 | | wsrep_local_send_queue_max | 2 | | wsrep_local_send_queue_min | 0 | | wsrep_local_send_queue_avg | 0.002781 | | wsrep_local_recv_queue | 0 | | wsrep_local_recv_queue_max | 2 | | wsrep_local_recv_queue_min | 0 | | wsrep_local_recv_queue_avg | 0.002954 | | wsrep_local_cached_downto | 4174040 | | wsrep_flow_control_paused_ns | 0 | | wsrep_flow_control_paused | 0.000000 | | wsrep_flow_control_sent | 0 | | wsrep_flow_control_recv | 0 | | wsrep_cert_deps_distance | 40.254320 | | wsrep_apply_oooe | 0.004932 | | wsrep_apply_oool | 0.000000 | | wsrep_apply_window | 1.004932 | | wsrep_commit_oooe | 0.000000 | | wsrep_commit_oool | 0.000000 | | wsrep_commit_window | 1.000000 | | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | | wsrep_cert_index_size | 43 | | wsrep_causal_reads | 0 | | wsrep_cert_interval | 0.023937 | | wsrep_incoming_addresses | 192.168.100.202:3306,192.168.100.201:3306,192.168.100.203:3306 | | wsrep_evs_delayed | | | wsrep_evs_evict_list | | | wsrep_evs_repl_latency | 0/0/0/0/0 | | wsrep_evs_state | OPERATIONAL | | wsrep_gcomm_uuid | 91e4b4f9-62cc-11e5-9422-2b8fd270e336 | | wsrep_cluster_conf_id | 0 | | wsrep_cluster_size | 3 | | wsrep_cluster_state_uuid | 5b32cb2c-39df-11e5-b26b-6e85dd52910e | | wsrep_cluster_status | Primary | | wsrep_connected | ON | | wsrep_local_bf_aborts | 0 | | wsrep_local_index | 1 | | wsrep_provider_name | Galera | | wsrep_provider_vendor | Codership Oy <info@codership.com> | | wsrep_provider_version | 25.3.9(r3387) | | wsrep_ready | ON | | wsrep_thread_count | 2 | +------------------------------+----------------------------------------------------------------+
Вот и все. Просто – не правда ли?
Внимание: если все ваши ноды будут выключенны в одно и тоже время, MySQL не поднимется сам, вы должны будете выбрать наиболее актуальную ноду, и запустить демон с опцией --wsrep-new-cluster, чтобы остальные ноды смогли прореплицировать с нее информацию.
OpenvSwitch
Про OpenvSwitch ls1 написал классную статью, рекомендую к прочтению.
Установка
Так как OpenvSwitch нет в стандартных пакетах в CentOS
Инструкция по сборке вручную
Для начала установим все необходимые зависимости:
Для компиляции OpenvSwitch создадим пользователя ovs и залогинимся под ним, дальнейшие действия будем выполнять от его имени.
Скачаем исходники, по рекомендации n40lab отключим openvswitch-kmod, и скомпилируем их.
Создадим папку для конфигов
Установим полученный нами RPM-пакет
yum -y install wget openssl-devel gcc make python-devel openssl-devel kernel-devel graphviz kernel-debug-devel autoconf automake rpm-build redhat-rpm-config libtool
Для компиляции OpenvSwitch создадим пользователя ovs и залогинимся под ним, дальнейшие действия будем выполнять от его имени.
adduser ovs su - ovs
Скачаем исходники, по рекомендации n40lab отключим openvswitch-kmod, и скомпилируем их.
mkdir -p ~/rpmbuild/SOURCES wget http://openvswitch.org/releases/openvswitch-2.3.2.tar.gz cp openvswitch-2.3.2.tar.gz ~/rpmbuild/SOURCES/ tar xfz openvswitch-2.3.2.tar.gz sed 's/openvswitch-kmod, //g' openvswitch-2.3.2/rhel/openvswitch.spec > openvswitch-2.3.2/rhel/openvswitch_no_kmod.spec rpmbuild -bb --nocheck ~/openvswitch-2.3.2/rhel/openvswitch_no_kmod.spec exit
Создадим папку для конфигов
mkdir /etc/openvswitch
Установим полученный нами RPM-пакет
yum localinstall /home/ovs/rpmbuild/RPMS/x86_64/openvswitch-2.3.2-1.x86_64.rpm
В коментариях Dimonyga подсказал, что OpenvSwitch есть в репозитории RDO и собирать его не нужно
Давайте установим его оттуда:
yum install https://rdoproject.org/repos/rdo-release.rpm yum install openvswitch
Запустим демон:
systemctl start openvswitch.service chkconfig openvswitch on
Создание бриджа
Сейчас мы настроим сетевой бридж в который будут добавляться порты
ovs-vsctl add-br ovs-br0 ovs-vsctl add-port ovs-br0 enp1
Поправим конфиги наших интерфейсов для автозапуска:
/etc/sysconfig/network-scripts/ifcfg-enp1
DEVICE="enp1" NM_CONTROLLED="no" ONBOOT="yes" IPV6INIT=no TYPE="OVSPort" DEVICETYPE="OVSIntPort" OVS_BRIDGE=ovs-br0
/etc/sysconfig/network-scripts/ifcfg-ovs-br0
Для kvm1:
DEVICE="ovs-br0" NM_CONTROLLED="no" ONBOOT="yes" TYPE="OVSBridge" BOOTPROTO="static" IPADDR="192.168.100.201" NETMASK="255.255.255.0" GATEWAY="192.168.100.1" DNS1="192.168.100.1" HOTPLUG="no"
Для kvm2
DEVICE="ovs-br0" NM_CONTROLLED="no" ONBOOT="yes" TYPE="OVSBridge" BOOTPROTO="static" IPADDR="192.168.100.202" NETMASK="255.255.255.0" GATEWAY="192.168.100.1" DNS1="192.168.100.1" HOTPLUG="no"
Для kvm3
DEVICE="ovs-br0" NM_CONTROLLED="no" ONBOOT="yes" TYPE="OVSBridge" BOOTPROTO="static" IPADDR="192.168.100.203" NETMASK="255.255.255.0" GATEWAY="192.168.100.1" DNS1="192.168.100.1" HOTPLUG="no"
Перезапустим сеть, все должно завестись:
systemctl restart network
OpenNebula
Установка
Вот и пришло время установить OpenNebula
На всех нодах:
Установим репозиторий OpenNebula:
cat << EOT > /etc/yum.repos.d/opennebula.repo [opennebula] name=opennebula baseurl=http://downloads.opennebula.org/repo/4.14/CentOS/7/x86_64/ enabled=1 gpgcheck=0 EOT
Установим сервер OpenNebula, web-интерфейс к нему Sunstone и ноду
yum install -y opennebula-server opennebula-sunstone opennebula-node-kvm
Запустим интерактивный скрипт, который установит в нашу систему необходимые gems:
/usr/share/one/install_gems
Настройка нод
На каждой ноде у нас появился пользователь one, нужно разрешить ему безпарольно ходить между нодами и выполнять любые команды через sudo без пароля, так же как мы и делали с пользователем ceph.
На каждой ноде выполняем:
sudo passwd oneadmin sudo echo "%oneadmin ALL = (root) NOPASSWD:ALL" > /etc/sudoers.d/oneadmin sudo chmod 0440 /etc/sudoers.d/oneadmin
Запустим сервисы Libvirt и MessageBus:
systemctl start messagebus.service libvirtd.service systemctl enable messagebus.service libvirtd.service
Заходим на kvm1
Теперь сгенерируем ключ и скопируем его на остальные ноды:
sudo ssh-keygen -f /var/lib/one/.ssh/id_rsa sudo cat /var/lib/one/.ssh/id_rsa.pub >> /var/lib/one/.ssh/authorized_keys sudo chown -R oneadmin: /var/lib/one/.ssh for i in 2 3; do scp /var/lib/one/.ssh/* oneadmin@kvm$i:/var/lib/one/.ssh/ done
На каждой ноде выполняем:
Разрешим Sunstone слушать на любой IP, не только на локальный:
sed -i 's/host:\ 127\.0\.0\.1/host:\ 0\.0\.0\.0/g' /etc/one/sunstone-server.conf
Настройка БД
Заходим на kvm1.
Создадим базу данных для OpenNebula:
mysql -p create database opennebula; GRANT USAGE ON opennebula.* to oneadmin@'%' IDENTIFIED BY 'PASS'; GRANT ALL PRIVILEGES on opennebula.* to oneadmin@'%'; FLUSH PRIVILEGES;
Теперь перенесем базу данных из sqlite в mysql:
Скачаем скрипт sqlite3-to-mysql.py:
curl -O http://www.redmine.org/attachments/download/6239/sqlite3-to-mysql.py chmod +x sqlite3-to-mysql.py
Сконвертируем и запишем нашу базу:
sqlite3 /var/lib/one/one.db .dump | ./sqlite3-to-mysql.py > mysql.sql mysql -u oneadmin -pPASS < mysql.sql
Теперь скажем OpenNebula подключаться к нашей бд, поправим конфиг /etc/one/oned.conf:
Заменим
DB = [ backend = "sqlite" ]
на
DB = [ backend = "mysql", server = "localhost", port = 0, user = "oneadmin", passwd = "PASS", db_name = "opennebula" ]
Скопируем его на остальные ноды:
for i in 2 3; do scp /etc/one/oned.conf oneadmin@kvm$i:/etc/one/oned.conf done
Так же мы должны скопировать ключ авторизации oneadmin в кластере на остальные ноды, так как все управление кластером OpenNebula осуществляется именно под ним.
for i in 2 3; do scp /var/lib/one/.one/one_auth oneadmin@kvm$i:/var/lib/one/.one/one_auth done
Проверка
Теперь на каждой ноде попробуем запустить серивис OpenNebula и проверить работает он или нет:
Запускаем
systemctl start opennebula opennebula-sunstone
- Проверяем:
http://node:9869 - Проверяем логи на ошибки (
/var/log/one/oned.log /var/log/one/sched.log /var/log/one/sunstone.log).
Если все хорошо, выключаем:
systemctl stop opennebula opennebula-sunstone
Настройка отказоустойчивого кластера
Пришло время настроить HA-кластер OpenNebula
По непонятным причинам pcs конфликтует с OpenNebula. По этому мы будем использовать pacemaker, corosync and crmsh.
На всех нодах:
Отключим автозапуск демонов OpenNebula
systemctl disable opennebula opennebula-sunstone opennebula-novnc
Добавим репозиторий:
cat << EOT > /etc/yum.repos.d/network\:ha-clustering\:Stable.repo [network_ha-clustering_Stable] name=Stable High Availability/Clustering packages (CentOS_CentOS-7) type=rpm-md baseurl=http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/ gpgcheck=1 gpgkey=http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/repodata/repomd.xml.key enabled=1 EOT
Установим необходимые пакеты:
yum install corosync pacemaker crmsh resource-agents -y
На kvm1:
Отредактируем /etc/corosync/corosync.conf, приведем его к такому виду:
corosync.conf
totem { version: 2 crypto_cipher: none crypto_hash: none interface { ringnumber: 0 bindnetaddr: 192.168.100.0 mcastaddr: 226.94.1.1 mcastport: 4000 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } quorum { provider: corosync_votequorum } service { name: pacemaker ver: 1 } nodelist { node { ring0_addr: kvm1 nodeid: 1 } node { ring0_addr: kvm2 nodeid: 2 } node { ring0_addr: kvm3 nodeid: 3 } }
Сгенерируем ключи:
cd /etc/corosync corosync-keygen
Скопируем конфиг и ключи на остальные ноды:
for i in 2 3; do scp /etc/corosync/{corosync.conf,authkey} oneadmin@kvm$i:/etc/corosync ls done
И запустим HA-сервисы:
systemctl start pacemaker corosync systemctl enable pacemaker corosync
Проверим:
crm status
Вывод
Last updated: Mon Nov 16 15:02:03 2015 Last change: Fri Sep 25 16:36:31 2015 Stack: corosync Current DC: kvm1 (1) - partition with quorum Version: 1.1.12-a14efad 3 Nodes configured 0 Resources configured Online: [ kvm1 kvm2 kvm3 ]
Отключим STONITH (механизм добивания неисправной ноды)
crm configure property stonith-enabled=false
Если у вас всего две ноды отключите кворум, во избежании splitbrain-ситуации
crm configure property no-quorum-policy=stop
Теперь создадим ресурсы:
crm configure primitive ClusterIP ocf:heartbeat:IPaddr2 params ip="192.168.100.200" cidr_netmask="24" op monitor interval="30s" primitive opennebula_p systemd:opennebula \ op monitor interval=60s timeout=20s \ op start interval="0" timeout="120s" \ op stop interval="0" timeout="120s" primitive opennebula-sunstone_p systemd:opennebula-sunstone \ op monitor interval=60s timeout=20s \ op start interval="0" timeout="120s" \ op stop interval="0" timeout="120s" primitive opennebula-novnc_p systemd:opennebula-novnc \ op monitor interval=60s timeout=20s \ op start interval="0" timeout="120s" \ op stop interval="0" timeout="120s" group Opennebula_HA ClusterIP opennebula_p opennebula-sunstone_p opennebula-novnc_p exit
Этими действиями мы создали виртуальный IP (192.168.100.200), добавили три наших сервиса в HA-кластер и объединили их в группу Opennebula_HA.
Проверим:
crm status
Вывод
Last updated: Mon Nov 16 15:02:03 2015 Last change: Fri Sep 25 16:36:31 2015 Stack: corosync Current DC: kvm1 (1) - partition with quorum Version: 1.1.12-a14efad 3 Nodes configured 4 Resources configured Online: [ kvm1 kvm2 kvm3 ] Resource Group: Opennebula_HA ClusterIP (ocf::heartbeat:IPaddr2): Started kvm1 opennebula_p (systemd:opennebula): Started kvm1 opennebula-sunstone_p (systemd:opennebula-sunstone): Started kvm1 opennebula-novnc_p (systemd:opennebula-novnc): Started kvm1
Настройка OpenNebula
Установка завершена, осталось только добавить наши ноды, хранилище и виртуальные сети в кластер.
Веб интерфейс всегда будет доступен по адресу
http://192.168.100.200:9869логин: oneadmin
пароль в /var/lib/one/.one/one_auth
- Создайте кластер
- Добавьте ноды
- Добавьте вашу виртуальную сеть:
cat << EOT > ovs.net NAME="main" BRIDGE="ovs-br0" DNS="192.168.100.1" GATEWAY="192.168.100.1" NETWORK_ADDRESS="192.168.100.0" NETWORK_MASK="255.255.255.0" VLAN="NO" VLAN_ID="" EOT onevnet create ovs.net
- Добавьте ваше Ceph хранилище:
Сначала нужно сохранить ключ авторизации:
UUID=`uuidgen` cat > secret.xml <<EOT <secret ephemeral='no' private='no'> <uuid>$UUID</uuid> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret> EOT
Растиражируем его на наши ноды:
for i in 1 2 3; do virsh --connect=qemu+ssh://oneadmin@kvm$i/system secret-define secret.xml virsh --connect=qemu+ssh://oneadmin@kvm$i/system secret-set-value --secret $UUID --base64 $(cat /etc/ceph/ceph.client.oneadmin.keyring | grep -oP '[^ ]*==') done
Теперь доавим само хранилище:
cat << EOT > rbd.conf NAME = "cephds" DS_MAD = ceph TM_MAD = ceph DISK_TYPE = RBD POOL_NAME = one BRIDGE_LIST ="192.168.100.201 192.168.100.202 192.168.100.203" CEPH_HOST ="192.168.100.201:6789 192.168.100.202:6789 192.168.100.203:6789" CEPH_SECRET ="$UUID" CEPH_USER = oneadmin EOT onedatastore create rbd.conf
- Добавьте ноды, сети, ваши хранилища к созданному кластеру через веб-интерфейс
HA VM
Теперь, если хотите настроить High Availability(высокую доступность) для ваших виртуальных машин, следуя официальной документации просто добавьте в /etc/one/oned.conf
HOST_HOOK = [ name = "error", on = "ERROR", command = "ft/host_error.rb", arguments = "$ID -m -p 5", remote = "no" ]
И скопируйте его на остальные ноды:
for i in 2 3; do scp /etc/one/oned.conf oneadmin@kvm$i:/etc/one/oned.conf done
Источники
- Ceph Documentation
- OpenNebula Documentation
- Alexey Vyrodov — Installation of HA OpenNebula on CentOS 7 with Ceph as a datastore and IPoIB as backend network
- N40LAB — CentOS 7 – Installing Openvswitch 2.3.2 LTS
- Смовж Алексей — Настройка отказоустойчивого решения виртуализации Proxmox + Ceph
- Sébastien Han — Ceph: Mix SATA and SSD Within the Same Box
- Каран Сингх — Настройка производительности Ceph и эталонное тестирование
- Zhiqiang W. (Intel) — Ceph cache tiering introduction
PS: Прошу, если вы заметили какие-то недочеты или ошибки пишите мне в личные сообщения
