
Все уже много раз слышали про конкурс по машинному обучению от Билайн и даже читали статьи (раз, два). Теперь конкурс закончился, и так вышло, что первое место досталось мне. И хотя от предыдущих участников меня и отделяли всего сотые доли процента, я все же хотел бы рассказать, что же такого особенного сделал. На самом деле — ничего невероятного.
Подготовка данных
Говорят, что 80% времени аналитики данных проводят за подготовкой данных и предварительными модификациями и только 20% за непосредственно анализом. И оно так не спроста, так как «garbage in — garbage out». Процесс подготовки исходных данных можно разбить на несколько этапов, по которым я предлагаю пройтись.
Исправление выбросов
После внимательного изучения гистограмм становится ясно, что в данные закралось довольно много выбросов (outliers). Например, если вы видите, что 99.9% наблюдений переменной Х сконцентрированы на отрезке [0;1], а 0.01% наблюдений выбрасывает за сотню, то довольно логично сделать две вещи: во-первых ввести новую колонку для индикации странных событий, а во-вторых заменить выбросы чем-то разумным.
data["x8_strange"] = (data["x8"] < -3.0)*1 data.loc[data["x8"] < -3.0 , "x8"] = -3.0 data["x31_strange"] = (data["x31"] < 0.0)*1.0 data.loc[data["x31"] < 0.0, "x31"] = 0.0 data["x40_zero"] = (data["x40"] == 0.0)*1.0
Нормализация распределений
Вообще, работать с нормальными распределениями крайне приятно, так как многие статистические тесты завязаны на гипотезу о нормальности. Современных методов машинного обучения это касается в меньшей степени, но все равно привести данные к разумному виду важно. Особенно важно для методов, которые работают с расстояниями между точками (почти все алгоритмы кластеризации, классификатор k-соседей). В этой части подготовки данных я обошелся стандартным подходом: логарифмирую все, что распределено плотнее около нуля. Таким образом для каждой переменной подобрал трансформацию, которая давала более приятный вид. Ну а после этого шкалировал все в отрезок [0;1]
Текстовые переменные
Вообще, текстовые переменные — кладезь для data mining’а, но в исходных данных были только хэши, да и названия переменных были анонимизированы. Поэтому только стандартная рутина: заменить все редкие хэши на слово Rare (редкие = встречаются реже 0.5%), заменить все пропущенные данные на слово Missing и развернуть как бинарную переменную (так как многие методы, в том числе xgboost, не умеют в категориальные переменные).
data = pd.get_dummies(data, columns=["x2", "x3", "x4", "x11", "x15"]) for col in data.columns[data.dtypes == "object"]: data.loc[data[col].isnull(), col] = 'Missing' thr = 0.005 for col in data.columns[data.dtypes == "object"]: d = dict(data[col].value_counts(dropna=False)/len(data)) data[col] = data[col].apply(lambda x: 'Rare' if d[x] <= thr else x) d = dict(data['x0'].value_counts(dropna=False)/len(data)) data = pd.get_dummies(data, columns=data.columns[data.dtypes == "object"])
Feature engineering
Это то, за что мы все любим data science. Но все зашифровано, поэтому этот пункт придется опустить. Почти. После пристального изучения графиков, я заметил, что x55+x56+x57+x58+x59+x60 = 1, а значит это какие-то доли. Скажем, какой процент денег абонент тратит на СМС, звонки, интернет, etc. А значит особый интерес представляют те товарищи, у которых какая-либо из долей более 90% или менее 5%. Таким образом получаем 12 новых переменных.
thr_top = 0.9 thr_bottom = 0.05 for col in ["x55", "x56", "x57", "x58", "x59", "x60"]: data["mostly_"+col] = (data[col] >= thr_top)*1 data["no_"+col] = (data[col] <= thr_bottom)*1
Убираем NA
Тут все предельно просто: после того, как все распределения приведены к разумному виду, можно смело заменять NA-шки средним или медианой (теперь они почти совпадают). Я пробовал вообще выкинуть из обучающей выборки те строки, где более 60% переменных имеют значение NA, но добром это не кончилось.
Регрессия в качестве регрессора
Следующий шаг уже не такой банальный. Из распределения классов я предположил, что возрастные группы упорядочены, то есть 0<1…<6 или наоборот. А раз так, то можно не классифицировать, а строить регрессию. Она будет работать плохо, но зато её результат можно передать другим алгоритмам для обучения. Поэтому запускаем обычную линейную регрессию с функцией потерь huber и оптимизируем её через стохастический градиентный спуск.
from sklearn.linear_model import SGDRegressor sgd = SGDRegressor(loss='huber', n_iter=100) sgd.fit(train, target) test = np.hstack((test, sgd.predict(test)[None].T)) train = np.hstack((train, sgd.predict(train)[None].T))
Кластеризация
Вторая интересная мысль, которую я пробовал: кластеризация данных методом k-средних. Если в данных есть реальная структура (а в данных по абонентам она должна быть), то k-средних её почувствует. Сначала я взял k=7, потом добавил 3 и 15 (в два раза больше и в два раза меньше). Предсказания каждого из этих алгоритмов — номера кластеров для каждого образца. Так как эти номера не упорядочены, то оставить их числами нельзя, надо обязательно бинаризовать. Итого + 25 новых переменных.
from sklearn.cluster import KMeans k15 = KMeans(n_clusters=15, precompute_distances = True, n_jobs=-1) k15.fit(train) k7 = KMeans(n_clusters=7, precompute_distances = True, n_jobs=-1) k7.fit(train) k3 = KMeans(n_clusters=3, precompute_distances = True, n_jobs=-1) k3.fit(train) test = np.hstack((test, k15.predict(test)[None].T, k7.predict(test)[None].T, k3.predict(test)[None].T)) train = np.hstack((train, k15.predict(train)[None].T, k7.predict(train)[None].T, k3.predict(train)[None].T))
Обучение
Когда подготовка данных была завершена, встал вопрос, какой метод машинного обучения выбрать. В принципе, ответ на этот на этот вопрос давно известен.
На самом деле, помимо xgboost я пробовал метод k-соседей. Несмотря на то, что в пространствах высокой размерности он считается неэффективным, мне удалось добиться 75% (маленький шаг для человека и большой шаг для k-neighbors), считая расстояние не в обычном евклидовом пространстве (где переменные равноценны), а делая поправку на важность переменных, как показано в презентации.
Однако все это игрушки, и действительно хорошие результаты дала не нейросеть, не логистическая регрессия и не k-соседи, а то, что и ожидалось – xgboost. Позже, придя на защиту в Билайн, я узнал, что они также добились лучших результатов с помощью этой библиотеки. Для задач классификации она уже является чем-то типа «золотого стандарта».
«When in doubt – use xgboost»
Owen Zhang, top-2 on Kaggle.
Прежде чем начинать собственно бустить по-настоящему и получать отличные результаты, я решил посмотреть, насколько действительно важны все те колонки, которые были даны, и те, которые насоздавал я, развернув хэши и проведя кластеризацию методом К-средних. Для этого я провел легкий бустинг (не очень много деревьев), и построил столбцы, отсортированные по важности (по мнению xgboost).
gbm = xgb.XGBClassifier(silent=False, nthread=4, max_depth=10, n_estimators=800, subsample=0.5, learning_rate=0.03, seed=1337) gbm.fit(train, target) bst = gbm.booster() imps = bst.get_fscore()
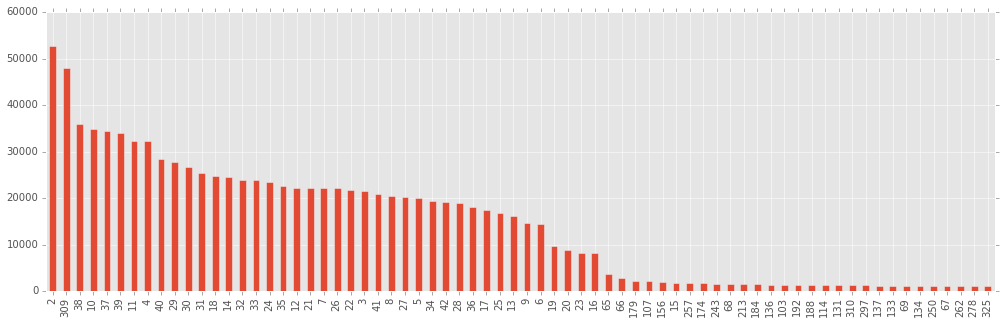
Мое мнение состоит в том, что те столбцы, важность которых оценена как “ничтожная” (а построена диаграмма только для самых важных 70 переменных из 335), содержат в себе больше шума, чем собственно полезных корреляций, и учиться по ним – себе вредить (i.e. переобучаться).
Интересно также заметить, что первая по важности переменная – x8, а вторая – результаты SGD-регрессии, добавленной мной. Те, кто пробовал участвовать в этом конкурсе, наверняка ломали голову, что за переменная x8, если она так хорошо разделяет классы. На защите в Билайне я не смог удержаться и не спросить, что же это было. Это был ВОЗРАСТ! Как мне объяснили, возраст, указанный в при покупке тарифа, и возраст, полученный в опросах, не всегда совпадают, так что да, участники действительно определяли возрастную группу в том числе и по возрасту.

Путем непродолжительных экспериментов я понял, что оставить 120 столбцов лучше, чем оставить 70 или оставить 170 (в первом случае, по всей видимости, все же выкидывается что-то полезное, во втором данные загрязнены чем-то бесполезным).
Теперь надо было бустить. Два параметра xgboost.XGBClassifier, заслуживающие наибольшего внимания – это eta (он же learning rate) и n_estimators (число деревьев). Остальные параметры не особо меняли результаты (поэтому я задал max_depth=8, subsample=0.5, а остальные параметры по умолчанию).
Между оптимальными значениями eta и n_estimators существует естественная зависимость – чем ниже eta (скорость обучения), тем больше деревьев необходимо, чтобы достичь максимальной точности. И мы действительно сталкиваемся здесь с оптимумом, после которого добавление дополнительных деревьев вызывает лишь переобучение, ухудшая точность на тестовой выборке. Например, для eta = 0.02 оптимальным будет примерно 800 деревьев:

Сначала я попробовал работать с средними eta (0.01-0.03) и увидел, что в зависимости от случайного состояния (seed) есть заметный разброс (например для 0.02 счет варьируется от 76.7 до 77.1), а также заметил, что этот разброс становится меньше при уменьшении eta. Стало понятно, что большие eta не подходят в принципе (как может быть хорошей модель, настолько зависимая от seed?).
Тогда я выбрал то eta, которое могу позволить себе на моем компьютере (не хотелось бы считать сутками). Это eta=0.006. Дальше необходимо было найти оптимальное число деревьев. Тем же способом, что показан выше, я установил, что для eta=0.006 подойдет 3400 деревьев. На всякий случай я попробовал два разных seed (важно было понять, велики ли флуктуации).
for seed in [202, 203]: gbm = xgb.XGBClassifier(silent=False, nthread=10, max_depth=8, n_estimators=3400, subsample=0.5, learning_rate=0.006, seed=seed) gbm.fit(trainclean, target) p = gbm.predict(testclean) filename = ("subs/sol3400x{1}x0006.csv".format(seed)) pd.DataFrame({'ID' : test_id, 'y': p}).to_csv(filename, index=False)
Каждый ансамбль на обычном core i7 считался по полтора часа. Вполне приемлемое время, когда конкурс проходит полтора месяца. Флуктуации на public leaderboard были невелики (для seed=202 получил 77.23%, для seed=203 77.17%). Отправил лучший из них, хотя весьма вероятно, что на private leaderboard другой был бы не хуже. Впрочем, мы уже не узнаем.
Теперь немного о самом конкурсе. Первое, что бросается в глаза тому, кто знаком с Kaggle – немного необычные правила сабмита. На Kaggle число самбишнов ограничено (в зависимости от конкурса, но как правило, не более 5 в день), здесь же сабмишны безлимитные, что позволило некоторым участникам отправлять результаты аж 600 раз. Кроме того, финальный сабмишн надо было выбрать один, а на Kaggle обычно разрешается выбрать любые два, и счет на private leaderboard считается по лучшему из них.
Еще одна необычная вещь – анонимизированные столбцы. С одной стороны, это практически лишает какой-либо возможности для feature design. С другой стороны, отчасти это и понятно: столбцы с реальными названиями дали бы мощное преимущество людям, разбирающимся в мобильной связи, а цель конкурса была явно не в этом.
