Comments 46
Культура использования статических анализаторов в России по странной причине находится в зачаточном состоянии. И чем больше проектов и статей на эту тему, тем лучше всем.
Для старта обсуждения — какой парсер используете? Чур в исходники не посылать! Хочется общаться с человеком, а не с github.
Спасибо за комментарий. Это анализатор байткода, а не анализатор исходного кода, поэтому нужен парсер байткода. Для построения модели по байткоду я пользуюсь Procyon Compiler Tools — весьма приятная штука. Есть баги, но автор их оперативно исправляет. Альтернативно думал попробовать FernFlower от JetBrains, но остановился на проционе.
У парсинга байткода есть существенные минусы: не всегда по байткоду можно восстановить, что было в оригинале. Иногда это критично для анализа: некоторые диагностики в анализаторе байткода в принципе невозможны. Это не только вещи вроде подозрительного форматирования, но и более сложные штуки. Например, такой код определённо подозрителен:
while(x > 0) {
... что-нибудь
return;
}Безусловный выход в конце цикла — повод задуматься. Но анализатор байткода не может этого увидеть, потому что компиляторы выдают тот же байткод, что и для этого вполне разумного кода:
if(x > 0) {
... что-нибудь
return;
}Так что, к сожалению, не всё можно сделать.
Плюсы в существенном упрощении настройки анализа. Если у вас есть скомпилированный jar или папка с .class-файлами, можно подать её анализатору на вход даже без всяких зависимостей. Подавляющую часть информации уже слинковал компилятор. Например, для любого вызова внешнего метода в .class-файле вы точно знаете его типы аргументов и возвращаемый тип, поэтому типы всех выражений можно выводить, даже не имея всех зависимостей.
Думаю, идеальный анализатор Java-кода должен сочетать и байт-код-анализ и анализ исходников (если они есть). Байт-код анализ пригодится для подгрузки скомпилированных библиотек и сбора статистики по ним. Например, важная информация: производит ли метод побочные эффекты. Есть очень много простых методов (геттеры, например), и не хочется при вызове любого из них сбрасывать весь контекст анализа. А так мы с помощью анализа байткода заглянули, что этот метод определён в библиотеке, нигде в дочерних классах не перегружен, и просто возвращает поле. Всё, после этого мы знаем, что вызов этого метода не испортит статически-выведенные факты о полях или каких-то объектах из кучи, и этим фактам можно и после вызова доверять.
Я тоже не знаю. В HuntBugs изначально заложен такой потенциал, но реализуется ли он когда-нибудь — неизвестно. Проект-то некоммерческий.
Раз уж пошла перепись разработчиков анализатора кода, то расскажу про PVS-Studio. Для C# кода мы анализируем именно исходники, а не байт-код. Наша мотивация была такой:
1. Мы считаем, что в исходнике больше информации, нежели в байт-коде.
2. Мы умеем работать с исходным кодом, так как есть опыт с C++,.
3. Мы делаем ставку на C# и бонус в виде легкой проверки других языков нам не очень актуален.
По этой причине решили работать именно с исходниками.
Ну да, адаптировать анализатор байткода к новому языку проще. По идее он может даже из коробки приносить пользу. Но, как я написал в статье, количество ложных сработок изначально будет неимоверно выше. Однако бывают не только новые языки, а всякие ещё инструментаторы, annotation-процессоры. Анализатор байткода получит уже реальный код после их работы, который может существенно отличаться от Java-исходника.
Добавлю и свое мнение: с помощью байт-кода не получится детектить такие вещи, как известный баг goto fail;, анализировать строки в комментариях, потому что информации о пробелах и комментариях, понятное дело, в байт-коде нет. Насколько помню, ваш анализатор PVS-Studio также способен анализировать такие вещи. Ну и как написали выше в комментариях, при компиляции теряется еще и другая информация, без которой также невозможно будет выявить определенные баги.
Зато с помощью байт-кода удобно проводить глубокий анализ, в котором анализируются связи между определением переменных и их использованием (потоки данных), проводится межпроцедурный анализ, и т.д. В нем нас по сути интересуют самые базовые вещи, характерные для существующих языков программирования, такие как последовательность, ветвления, циклы, вызовы методов.
Еще одним преимуществом анализа исходников, а не байт-кода, является то, что если исходники содержат какие-либо синтаксические или семантические ошибки, то байт-код извлечь не получится. А ситуации, в которых что-то не компилится, не ресолвится, не хватает файлов и т.п., могут возникать.
С goto fail не очень удачный пример. Но вот хороший пример с пробелами и забытыми фигурными скобочками из статьи про проверку FreeBSD:
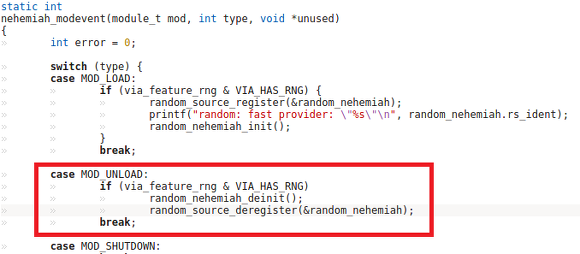
Кивание на немытую Россию тут совершенно неуместно. Уверен, если попробовать запустить huntBugs на кодовой базе заграничного Eclipse, он просто задымится и сломается от количества найденных багов
Если бы в Eclipse использовали анализаторы кода, наверное там было бы меньше ошибок.
Не очень понятно, почему вы сделали такое далекоидущее обобщение в комментариях к статье об IntelliJ, проекте, где (думаю не совру) о качестве кода и анализе думают больше, чем в 95% проектов "в мире".
Любой вменяемый джавист из используемых тулзов Вам выдаст сходу как минимум модный SonarQube. Или PMD, FindBugs, если он достаточно долго в этой отрасли. Проблема, думаю, не в России, а рискну предположить, что в отдельных сферах разработки.
По истории коммитов у вас они идут по несколько в день. Вы вечерами его дорабатывается помимо основной работы?
Честно говоря интересуют техники «совмещения» ибо у меня не всегда хватает сил/времени на свои проекты.
Иногда на работе удаётся немного пописать. Иногда дома. Главное не играть в игры и не смотреть фильмы, тогда куча времени на программинг появляется. Плюс я обычно думаю не за компом, а за компом только материализую мысли и отлаживаю их. Можно по дороге с работы домой придумать новый кусок кода достаточно детализированно, а дома его просто вбить из головы.
Во-первых, в него очень глубоко проник старый BCEL, который даже восьмую джаву с большим трудом поддерживает. Сам по себе BCEL — не сахар, а новый несовместим со старым. Если переходить на новый, всё равно изменится полностью всё API и придётся переписывать сторонние плагины. Во-вторых, там много геологических слоёв накопилось. Например, есть кусок, который использует ASM, в то время как основная часть использует BCEL. В этом можно запутаться сильно. В-третьих там огромный глобальный контекст. Куча всего хранится в статических полях, что усложняет интеграцию со сторонними инструментами, утяжеляет контроль за памятью и не даёт никакого шанса на нормальное распараллеливание. В-четвёртых, система приоритетов, которую не до конца вытеснила система рангов (у которой тоже есть проблемы) и сейчас они живут вместе, заставляя пользователей чесать репу при попытке понять, какой баг серьёзнее. В-пятых, способ обхода классов детекторами ведёт к повторным действиям и к неэффективному расходу памяти. Продолжать можно долго.
Но самое главное — FindBugs очень низкоуровневый. Практически любой анализатор говорит напрямую с байткодом, а не с какой-то более высокоуровневой моделью. Это сильно усложняет код, делая его stateful, и делает анализ менее устойчивым во многих случаях. Введёте промежуточную переменную и что-то поломается. Или, чтобы не поломалось, приходится кусок анализа засовывать прямо в OpcodeStack, что ещё более ужасно. Вон почитайте какой-нибудь класс детектора и увидите, как всё неудобно.
Не последняя проблема в том, что FindBugs по факту умирает. Из трёх коммитеров за последний год активность проявлял только я. В основном — мелкие фиксы и приём очевидных пулл-реквестов. Мне на себе тащить эту гору легаси неохота, приятнее начать новый проект.
Пулл-реквесты принимаются :-)
Хотя в findbugs меня всегда напрягало настаивать проект, указывая каталоги с исходниками и с зависимостями. С плагином я об этом забыл — в пару кликов можно проанализировать файл, модуль или весь проект и результаты смотреть в том же окне IDE.
Подключить его в качестве ещё одного механизма стат. проверки кода? Так оно не факт, что удастся корректно передать точное место потенциальной проблемы в коде (всё-таки байт-код может соответствовать разному коду). В общем случае точно можно будет получить только класс и метод в котором ошибка…
Подключить в качестве билд-степа? Так а мавен на что?
Есть какие-то ещё способы его заиспользовать?
Номера строк вытаскиваются из отладочной информации. Конкретную позицию в строке не покажет, но номер строки обычно неплохо определяется. В общем-то FindBugs-плагин же существует, это из той же оперы.
Интересно, а его за основу можно взять и «подменить» движок и заменить икноки?
Думаю, не всё так просто. У меня отличается концепция ранжирования, категоризации варнингов, генерации отчёта. Информация о прогрессе анализа по-другому передаётся. Ну и фильтров пока совсем нет. Можно отключить определённый варнинг целиком, но нельзя отключить, например, в конкретном классе. В FindBugs есть управление отключением детекторов, а я этого делать не хочу: отдельные детекторы — это деталь реализации, чтобы отключить детектор, надо просто отключить все варнинги, которые он умеет генерировать (детектор реально отключится, анализ может быстрее стать). В общем, отличий достаточно много, чтобы взять и переиспользовать. Плюс проект пока молодой и я не могу гарантировать стабильность API. Товарищ взялся писать плагин для Eclipse (вроде в минимальном виде уже работает, но я не пробовал). Если не забросит, на нём обкатаем API, тогда уже будет понятно, что с IDEA делать.
Warnings (0)
Окей…
А оно не умеет аггрегировать отчеты от подмодулей в Maven? Не очень удобно смотреть в каждом модуле, если модулей много.
Не умеет пока. Записал, чтобы не забыть, спасибо.
Статический анализатор HuntBugs: проверяем IntelliJ IDEA