Comments 17
Глупый вопрос может быть, а почему не использовали кэширование запросов? или просто всю бд не засунули в тот же тарантул, где на lua написали бы скрипты для запросов
В старой архитектуре кэш был реализован на стороне сервера обработки. Там сконцентрированы все вычисления и работа с данными, поэтому там можно было кэшировать не просто ответы, но также результаты промежуточных вычислений. Но описанную в статье проблему этот кэш не решал, т.к. задержки возникали не доходя до него. Нужно было организовывать еще один кэш на стороне приложения или веб-сервера, но этого мы делать не стали, т.к. посчитали, что кэшировать в двух местах фактически одни и те же данные — достаточно дорого по ресурсам.
По поводу перехода на lua, если бы мы разрабатывали с нуля новый сервис, то у нас было бы больше вариантов для выбора архитектуры. Здесь же имел место рефакторинг унаследованного сервиса, у которого именно алгоритмическая часть, отвечающая за обработку данных, уже была оптимизирована (для этого в старой архитектуре вся эта обработка была оформлена в виде сервера на С++). Всю эту реализацию хотелось не переписывать заново, а аккуратно перенести в новую архитектуру.
По поводу перехода на lua, если бы мы разрабатывали с нуля новый сервис, то у нас было бы больше вариантов для выбора архитектуры. Здесь же имел место рефакторинг унаследованного сервиса, у которого именно алгоритмическая часть, отвечающая за обработку данных, уже была оптимизирована (для этого в старой архитектуре вся эта обработка была оформлена в виде сервера на С++). Всю эту реализацию хотелось не переписывать заново, а аккуратно перенести в новую архитектуру.
С++ имеет смысл использовать только если доказано, что приложение значительное время проводит вычисляя что-то процессором. Если команда top не показывает, что ваш процесс сервера приложений забирает хотя бы 10-20% процессорного времени, то значит ваш процесс большей частью что-то ждет, и смысла в С++ нет. Скорее всего минимизация количества компонентов (и TCP-коммуникаций между ними) и дала весь прирост скорости.
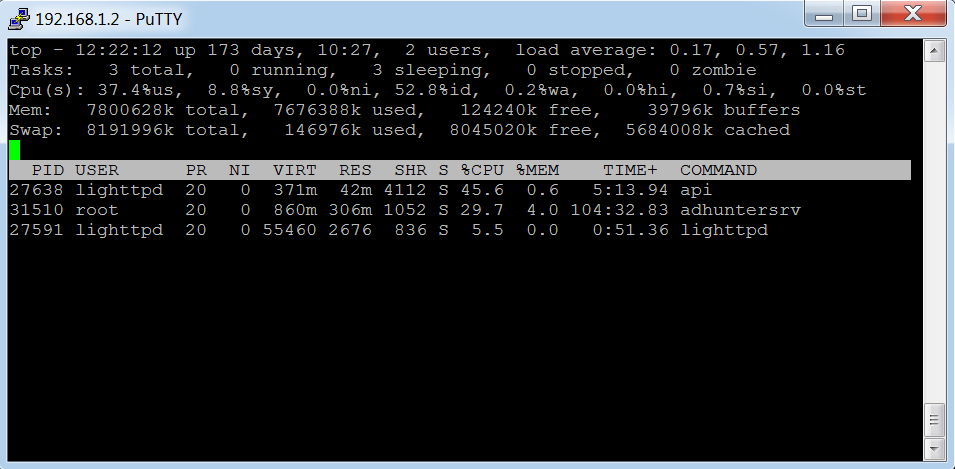
На скриншоте вывел загрузку процессора для приложения, сервера обработки и вебсервера при потоке запросов от одного пользователя.
Процесс «api» — это приложение, «lighttpd» — это вер-сервер.
Сервер обработки запущен от root, просьба не пинать за это, т.к. он запущен по-быстрому чисто для теста.
На картинке видно, что приложение отъедает 45,6% CPU.
Процесс «api» — это приложение, «lighttpd» — это вер-сервер.
Сервер обработки запущен от root, просьба не пинать за это, т.к. он запущен по-быстрому чисто для теста.
На картинке видно, что приложение отъедает 45,6% CPU.
«С++ имеет смысл использовать только если доказано, что приложение значительное время проводит вычисляя что-то процессором».
Не только. С/С++ абсолютно обосновано часто используется при написании веб-интерфейса для wifi-роутеров (да и наверное не только wifi; и наверное не только роутеров, а и вообще маленького сетевого железа, которое можно настраивать), потому, что это работает быстрее и занимает меньше места на несчастных 2/4/8 Мб флеш-памяти
Не только. С/С++ абсолютно обосновано часто используется при написании веб-интерфейса для wifi-роутеров (да и наверное не только wifi; и наверное не только роутеров, а и вообще маленького сетевого железа, которое можно настраивать), потому, что это работает быстрее и занимает меньше места на несчастных 2/4/8 Мб флеш-памяти
согл, преждевременная оптимизация,
но я бы 5 лет назад сделал бы так, как написано у автора.
но я бы 5 лет назад сделал бы так, как написано у автора.
Не рассматривали CAS? В качестве шаблонизатора используется тот же CTPP.
Как вариант, для того, чтобы увеличить допустимое время отклика от сервера, можно возвращать массивы подсказок также для возможных следующих букв, и использовать их на клиенте, пока от сервера не пришел следующий ответ.
Оптимизацию на стороне клиента можно делать независимо от серверной части, в том числе, и так, как вы предлагаете. Однако подсказки в этом случае будут менее адекватными. Дело в том, что всякий раз, когда пользователь вводит новый символ, вся введенная строка проходит полный цикл обработки на сервисе, который включает в себя ранжирование вариантов перед их выдачей. При ранжировании для каждого варианта оценивается вероятность того, что он будет полезным для пользователя. При ранжировании учитывается как информация, введенная пользователем к настоящему моменту, так и априорная информация об адресных объектах (их размер, популярность и пр.). Если на каком-то этапе ввода не отсылать строку на сервис, а брать варианты, которые вернул сервис ранее, то будет использоваться неадекватный результат ранжирования, полученный при вводе более короткой строки. Ну или придется реализовать повторное ранжирование на стороне клиента.
Ох уж этот дивный мир C++, всегда найдутся сто и одна отговорка, чтобы написать с нуля что-то, что уже есть, но слегка не устраивает)
И да, как уже написали выше, возвращайте не один слой подсказок, а несколько. Если конечно нет проблем с сетью.
И да, как уже написали выше, возвращайте не один слой подсказок, а несколько. Если конечно нет проблем с сетью.
Часто для этого используется БД. В нашем случае такой подход нивелировал бы всю оптимизацию, поэтому делается разделение между API-сессиями и GUI-сессиями. API-сессия запускается на каждом сервере независимо при получении от клиентского приложения первого запроса. Все изменения в аккаунте пользователя, которые происходят из-за активности API-сессии, реплицируются между серверами асинхронно. Проблемы, которые могут возникнуть в результате такой асинхронности, в каждом конкретном случае решаются отдельно. Например, на двух серверах пользовательский баланс может независимо дойти до нуля. В этом случае при репликации он на обоих серверах корректируется и становится отрицательным. Однако API-функции подсказок, которым посвящена данная статья, изменения в аккаунте не производят. Это открытая функций, по ней даже статистика не фиксируется, поэтому тут даже репликация между серверами не требуется.
Статья не имеет смысла без исходников. А как сделать похожий сервис, может рассказать почти любой разработчик с более чем трехлетним опытом работы. Лично я в ней не нашел для себя ничего нового, хотя активно нуждаюсь в подобном сервисе.
Sign up to leave a comment.
Оптимизация веб-сервиса подсказок для почтовых адресов и ФИО