В данной статье я постарался раскрыть назначение VMware Virtual SAN, принципы её работы, требования, возможности и ограничения данной системы, основные рекомендации по её проектированию.
VMware Virtual SAN (далее vSAN) представляет собой распределенную программную СХД (SDS) для организации гипер-конвергентной инфраструктуры (HCI) на базе vSphere. vSAN встроен в гипервизор ESXi и не требует развертывание дополнительных сервисов и служебных ВМ. vSAN позволяет объединить локальные носители хостов в единый пул хранения, обеспечивающий заданный уровень отказоустойчивости и предоставляющий свое пространство для всех хостов и ВМ кластера. Таким образом, мы получаем централизованное хранилище, необходимое для раскрытия всех возможностей виртуализации (технологии vSphere), без необходимости внедрения и сопровождения выделенной (традиционной) СХД.
vSAN запускается на уровне кластера vSphere, достаточно запустить соответствующий сервис в управлении кластером и предоставить ему локальные носители хостов кластера – в ручном или автоматическом режиме. vSAN встроен в vSphere и жёстко привязан к ней, как самостоятельный продукт SDS, способный работать вне инфраструктуры VMware, существовать не может.
Аналогами и конкурентами vSAN являются: Nutanix DSF (распределенное хранилище Нутаникс), Dell EMC ScaleIO, Datacore Hyper-converged Virtual SAN, HPE StoreVirtual. Все эти решения совместимы ни только с VMware vSphere, но и с MS Hyper-V (некоторые и с KVM), они предполагают установку и запуск на каждом хосте HCI служебной ВМ, необходимой для функционирования SDS, в гипервизор они не встраиваются.
Важным свойством любой HCI, в т.ч. VMware vSphere+vSAN, является горизонтальная масштабируемость и модульность архитектуры. HCI строится и расширяется на базе идентичных серверных блоков (хостов или узлов), объединяющих вычислительные ресурсы, ресурсы хранения (локальные носители) и сетевые интерфейсы. Это может быть commodity-оборудование (серверы x86, в т.ч. брэндовые), поставляемое отдельно, либо уже готовые эплаенсы (например, Nutanix, vxRail, Simplivity). Комплексное ПО (например, vSphere+vSAN+средства_оркестровки_VMware) позволяет создать на базе этих блоков программно-определяемый ЦОД (SDDS), включающий среду виртуализации, SDN (программно-определяемая сеть), SDS, средства централизованного управления и автоматизации/оркестровки. Конечно, нельзя забывать про необходимость выделенного физического сетевого оборудования (коммутаторы), без которого невозможно взаимодействие между хостами HCI. При этом для организации сети целесообразно использовать leaf-spine архитектуру, оптимальную для ЦОД.
vSAN поднимается на уровне кластера хостов ESXi под управлением vCenter и предоставляет распределенное централизованное хранилище хостам данного кластера. Кластер vSAN может быть реализован в 2х вариантах:
• Гибридный – флэш-накопители используются в качестве кэша (cache layer), HDD обеспечивают основную ёмкость хранилища (capacity layer).
• All-flash — флэш-накопители используются на обоих уровнях: cache и capacity.
Расширение vSAN-кластера возможно путем добавления носителей в существующие хосты либо путем установки новых хостов в кластер. При этом необходимо учитывать, что кластер должен оставаться сбалансированным, это значит, что в идеале состав носителей в хостах (и сами хосты) должен быть идентичным. Допустимо, но не рекомендуется, включать в кластер хосты без носителей, участвующих в ёмкости vSAN, они также могут размещать свои ВМ на общем хранилище vSAN-кластера.
Сравнивая vSAN с традиционными внешними СХД следует отметить, что:
• vSAN не требует организации внешнего хранилища и выделенной сети хранения;
• vSAN не требует нарезки LUN-ов и файловых шар, презентования их хостам и связанной с этим настройки сетевого взаимодействия; после активации vSAN сразу становится доступной всем хостам кластера;
• передача данных vSAN осуществляется по собственному проприетарному протоколу; стандартные протоколы SAN/NAS (FC, iSCSI, NFS) для организации и работы vSAN не нужны;
• администрирование vSAN осуществляется только из консоли vSphere; отдельные средства администрирования или специальные плагины для vSphere не нужны;
• не нужен выделенный администратор СХД; настройка и сопровождение vSAN осуществляется администратором vSphere.
На каждом хосте кластера vSAN должно быть минимум по одному кэш-носителю и носителю данных (capacity или data disk). Данные носители внутри каждого хоста объединяются в одну или несколько дисковых групп. Каждая дисковая группа включает только один кэш-носитель и один или несколько носителей данных для постоянного хранения.
Носитель, отданный vSAN и добавленный в дисковую группу, утилизируется полностью, его нельзя использовать для других задач или в нескольких дисковых группах. Это касается как кэш-носителя, так и capacity дисков.
vSAN поддерживает только локальные носители, либо диски, подключенные по DAS. Включение в пул хранения vSAN хранилищ, подключенных по SAN/NAS, не поддерживается.
vSAN представляет собой объектное хранилище, данные в нем хранятся в виде «гибких» (flexible) контейнеров, называемых объектами. Объект хранит внутри себя данные или мета-данные, распределенные по кластеру. Ниже перечислены основные разновидности объектов vSAN (создаются отдельно для каждой ВМ):

Таким образом, данные каждой ВМ хранятся на vSAN в виде множества перечисленных выше объектов. В свою очередь каждый объект включает в себя множество компонентов, распределенных по кластеру в зависимости от выбранной политики хранения и объема данных.
Управление хранением данных на vSAN осуществляется с помощью механизма SPBM (Storage Policy Based Management), под воздействием которого находятся все хранилища vSphere начиная с версии 6. Политика хранения задает количество допустимых отказов (Number of failures to tolerate), метод обеспечения отказоустойчивости (репликация или erasure coding) и количество страйпов для объекта (Number of disk stripes per object). Заданное политикой количество страйпов определяет число носителей данных (capacity), по которым будет размазан объект.
Привязка политики к конкретной ВМ или её диску определяет количество компонентов объекта и их распределение по кластеру.
vSAN допускает изменение политики хранения для объектов на-горячую, без остановки работы ВМ. При этом в фоне запускаются процессы реконфигурации объектов.
При распределении объектов по кластеру vSAN контролирует, чтобы компоненты, относящиеся к разным репликам объекта и компоненты-свидетели (witness), разносились по разным узлам или доменам отказа (серверная стойка, корзина или площадка).
Свидетель (witness) – это служебный компонент, не содержащий полезных данных (только метаданные), его размер равен 2-4МБ. Он выполняет роль тайбрейкера при определении живых компонентов объекта в случае отказов.
Механизм вычисления кворума в vSAN работает следующим образом. Каждый компонент объекта получает определенное число голосов (votes) — 1 и более. Кворум достигается и объект считается «живым» если доступна его полная реплика и более половины его голосов.
Такой механизм вычисления кворума позволяет распределить компоненты объекта по кластеру таким образом, что в некоторых случаях можно обойтись без создания свидетеля. Например, при использовании RAID-5/6 или страйпинга на RAID-1.
После включения сервиса vSAN в кластере vSphere появляется одноименное хранилище (datastore), на весь кластер vSAN оно может быть только единственным. Благодаря механизму SPBM, описанному выше, в рамках единого хранилища vSAN каждая ВМ или её диск может получить необходимый её уровень сервиса (отказоустойчивость и производительность) путем привязки к нужной политике хранения.
vSAN datastore доступно всем хостам кластера, вне зависимости от наличия у хоста локальных носителей, включенных в vSAN. При этом хостам кластера могут быть доступны хранилища (datastore) других типов: VVol, VMFS, NFS.
vSAN datastore поддерживает Storage vMotion (горячая миграция дисков ВМ) с хранилищами VMFS/NFS.
В рамках одного сервера vCenter можно создавать несколько кластеров vSAN. Поддерживается Storage vMotion между кластерами vSAN. При этом каждый хост может быть участником только одного кластера vSAN.
vSAN совместима и поддерживает большинство технологий VMware, в т.ч. требующих общего хранилища, в частности: vMotion, Storage vMotion, HA, DRS, SRM, vSphere Replication, снапшоты, клоны, VADP, Horizon View.
vSAN не поддерживает: DPM, SIOC, SCSI reservations, RDM, VMFS.
Носители, контроллеры, а также драйверы и firmware должны быть сертифицированы под vSAN и отображаться в соответствующем листе совместимости VMware (секция Virtual SAN в VMware Compatibility Guide).
В качестве storage-контроллера может использоваться SAS/SATA HBA или RAID-контроллер, они должны функционировать в режиме passthrough (диски отдаются контроллером как есть, без создания raid-массива) или raid-0.
В качестве кэш-носителей могут использоваться SAS/SATA/PCIe –SSD и NVMe носители.
В качестве носителей данных могут использоваться SAS/SATA HDD для гибридной конфигурации и все перечисленные выше типы флэша (SAS/SATA/PCIe –SSD и NVMe) для all-flash конфигурации.
Объем памяти хоста определяется количеством и размером дисковых групп.
Минимальный объем ОЗУ хоста для участия в кластере vSAN — 8ГБ.
Минимальный объем ОЗУ хоста, необходимый для поддержки максимальной конфигурации дисковых групп (5 дисковых групп по 7 носителей данных), равен 32ГБ.
vSAN утилизирует порядка 10% ресурсов процессора.
Выделенный адаптер 1Гбит/с для гибридной конфигурации
Выделенный или совместно используемый адаптер 10Гбит/с для all-flash конфигурации
Необходимо разрешить трафик мультикаст в подсети vSAN
Для загрузки хостов с vSAN могут использоваться локальные USB или SD носители, а также SATADOM. Первые 2 типа носителей не сохраняют логи и трэйсы после перезагрузки, поскольку их запись осуществляется на RAM-диск, а последний сохраняет, поэтому рекомендуется использовать SATADOM-носители SLC-класса, обладающие большей живучестью и производительностью.
Максимум 64 хоста на кластер vSAN (и для гибрида и для all-flash)
Максимум 5 дисковых групп на хост
Максимум 7 capacity-носителей на дисковую группу
Не более 200 ВМ на хост и не более 6000 ВМ на кластер
Не более 9000 компонентов на хост
Максимальный размер диска ВМ – 62ТБ
Максимальное количество носителей в страйпе на объект – 12
Минимальное количество хостов кластера vSAN определяется числом допустимых отказов (параметр Number of failures to tolerate в политике хранения) и определяется по формуле: 2*number_of_failures_to_tolerate + 1.
При условии отработки 1 отказа vSAN допускает создание 2х- и 3х- узловых кластеров. Объект и его реплика размещаются на 2х хостах, на 3м размещается свидетель. При этом появляются следующие ограничения:
• при падении 1 хоста нет возможности ребилда данных для защиты от нового отказа;
• при переводе 1 хоста в режим обслуживания нет возможности миграции данных, данные оставшегося хоста на это время становятся незащищенными.
Это обусловлено тем, что ребилдить или мигрировать данные попросту некуда, нет дополнительного свободного хоста. Поэтому оптимально если в кластере vSAN используется от 4х хостов.
Правило 2*number_of_failures_to_tolerate + 1 применимо только при использовании Зеркалирования для обеспечения отказоустойчивости. При использовании Erasure Coding оно не работает, подробно это описано ниже в разделе «Обеспечение отказоустойчивости».
Для того, чтобы кластер vSAN был сбалансированным, аппаратная конфигурация хостов, в первую очередь это касается носителей и storage-контроллеров, должна быть идентичной.
Несбалансированный кластер (разная конфигурация дисковых групп хостов) поддерживается, но заставляет мириться со следующими недостатками:
• неоптимальная производительность кластера;
• неравномерная утилизация ёмкости хостов;
• отличия в процедурах сопровождения хостов.
Допускается размещение ВМ с сервером vCenter на vSAN датасторе, однако это приводит к рискам, связанным с управлением инфраструктурой при проблемах с vSAN.
Рекомендуется планировать размер кэша с запасом для возможности расширения capacity уровня.
В гибридной конфигурации 30% кэша выделяется на запись и 70% на чтение. All-flash конфигурация vSAN использует всю ёмкость кэш-носителей на запись, кэша на чтение не предусмотрено.
Рекомендуемый размер кэша должен быть не менее 10% от реальной ёмкости ВМ до репликации, т.е. учитывается полезное пространство, а не реально занятое (с учетом репликации).
В гибридной конфигурации дисковая группа будет утилизировать всю ёмкость установленного в неё флэш-носителя, при этом его максимальный объем не ограничен.
В all-flash конфигурации дисковая группа не может использовать более 600ГБ ёмкости установленного флэш-носителя, при этом оставшееся пространство не будет простаивать, поскольку кэшируемые данные будут записываться по всему объёму носителя циклически. В all-flash vSAN целесообразно использовать под кэш флэш-носители с большей скоростью и временем жизни по сравнению с capacity-носителями. Использование под кэш носителей объёмом более 600ГБ не повлияет на производительность, однако продлит срок службы данных носителей.
Такой подход к организации кэша в all-flash vSAN обусловлен тем, что флэш-capacity-носители и так быстрые, поэтому нет смысла кэшировать чтение. Выделение всей ёмкости кэша на запись, кроме её ускорения, позволяет продлить срок жизни capacity-уровня и снизить общую стоимость системы, поскольку для постоянного хранения можно использовать более дешевые носители, в то время как один более дорогой, производительный и живучий флэш-кэш будет защищать их от лишних операций записи.
Отказоустойчивость ВМ и соотношение объема полезного и занимаемого в общем пространства хранилища vSAN определяются двумя параметрами политики хранения:
• Number of failures to tolerate – количество допустимых отказов, определяет количество хостов кластера отказ которых сможет пережить ВМ.
• Failure tolerance method – метод обеспечения отказоустойчивости.
vSAN предлагает 2 метода обеспечения отказоустойчивости:
• RAID-1 (Mirroring) – полная репликация (зеркалирование) объекта с размещением реплик на разных хостах, аналог сетевого raid-1. Позволяет пережить кластеру до 3-х отказов (хостов, дисков, дисковых групп или сетевых проблем). Если Number of failures to tolerate = 1, то создается 1 реплика (2 экземпляра объекта), пространство, реально занимаемое ВМ или её диском на кластере, в 2 раза больше её полезной ёмкости. Если Number of failures to tolerate = 2, имеем 2 реплики (3 экземпляра), реально занимаемый объем в 3 раза больше полезного. Для Number of failures to tolerate = 3, имеем 3 реплики, занимаем пространство в 4 раза больше полезного. Данный метод отказоустойчивости неэффективно использует пространство, однако предоставляет максимальную производительность. Может использоваться для гибридной и all-flash конфигурации кластера. Минимально необходимое количество хостов 2-3 (для отработки 1 отказа), рекомендуемый минимум – 4 хоста, дает возможность ребилда при отказе.
• RAID-5/6 (Erasure Coding) – при размещении объектов производится вычисление блоков чётности, аналог сетевого raid-5 или -6. Поддерживается только all-flash конфигурация кластера. Позволяет кластеру отработать 1 (аналог raid-5) или 2 отказа (аналог raid-6). Минимальное количество хостов для отработки 1 отказа равно 4, для отработки 2-х отказов равно 6, рекомендуемые минимумы 5 и 7, соответственно, для возможности ребилда. Данный метод позволяет достичь значительной экономии пространства кластера по сравнению с RAID-1, однако приводит к потере производительности, которая может оказаться вполне приемлемой для многих задач, учитывая скорость all-flash. Так, в случае 4-х хостов и допуске 1 отказа полезное пространство, занимаемое объектом при использовании Erasure Coding, будет составлять 75% от его полного объема (для RAID-1 имеем 50% полезного пространства). В случае 6-ти хостов и допуске 2-х отказов полезное пространство, занимаемое объектом при использовании Erasure Coding, будет составлять 67% от его полного объема (для RAID-1 имеем 33% полезного пространства). Таким образом, RAID-5/6 в данных примерах оказывается эффективнее RAID-1 по использованию ёмкости кластера в 1,5 и 2 раза, соответственно.
Ниже представлено распределение данных на уровне компонент кластера vSAN при использовании RAID-5 и RAID-6. C1-С6 (первая строка) – компоненты объекта, A1-D4 (цветные блоки) – блоки данных, P1-Р4 и Q1-Q4 (серые блоки) – блоки четности.

vSAN позволяет по-разному обеспечивать отказоустойчивость для различных ВМ или их дисков. В рамках одного хранилища можно для критичных к производительности ВМ привязать политику с зеркалированием, а для менее критичных ВМ настроить Erasure Coding для экономии пространства. Таким образом, будет соблюдаться баланс между производительностью и эффективным использованием ёмкости.
Ниже приводится таблица с минимальным и рекомендуемым количеством хостов или доменов отказа для различных вариантов FTM/FTT:
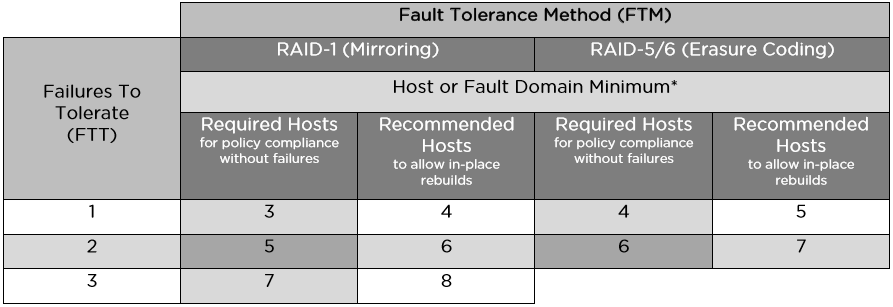
vSAN вводит понятие доменов отказа (fault domain) для защиты кластера от отказов на уровне серверных стоек или корзин, которые логически группируются в эти домены. Включение этого механизма приводит к распределению данных для обеспечения их отказоустойчивости не на уровне отдельных узлов, а на уровне доменов, что позволит пережить отказ целого домена – всех сгруппированных в нем узлов (например, серверной стойки), поскольку реплики объектов будут обязательно размещаться на узлах из разных доменов отказа.

Количество доменов отказа вычисляется по формуле: number of fault domains = 2 * number of failures to tolerate + 1. vSAN минимально требует 2 домена отказа, в каждом по 1 или несколько хостов, однако рекомендуемое количество равно 4, поскольку допускает возможность ребилда в случае отказа (2-3 домена не дают возможность ребилда, некуда). Таким образом, метод подсчета числа доменов отказа аналогичен, методу подсчета количества хостов для отработки нужного числа отказов.
В идеале в каждом домене отказа, должно быть одинаковое количество хостов, хосты должны иметь идентичную конфигурацию, пространство одного домена рекомендуется оставлять пустым для возможности ребилда (например, 4 домена с отработкой 1 отказа).
Механизм доменов отказа работает не только при Зеркалировании (RAID-1), но и для Erasure Coding, в этом случае каждый компонент объекта должен размещаться в разных доменах отказа и формула расчета числа доменов отказа меняется: минимум 4 домена для RAID-5 и 6 доменов для RAID-6 (аналогично расчету числа хостов для Erasure Coding).
Механизмы дедупликации и сжатия (ДиС) поддерживаются только в all-flash конфигурации и могут быть включены только на кластер vSAN в целом, выборочное включение для отдельных ВМ или дисков с помощью политик не поддерживается. Использовать только одну из этих технологий тоже не получится, только обе сразу.
Включении ДиС заставляет объекты автоматически страйпиться на все диски в дисковой группе, это позволяет избежать ребалансировки компонентов и выявлять совпадения блоков данных из разных компонент на каждом диске в дисковой группе. При этом сохраняется возможность задать старайпинг объектов вручную на уровне политик хранения, в т.ч. за пределы дисковой группы. При включении ДиС нецелесообразно на уровне политики резервировать пространство под объекты (параметр Object Space Reservation, толстые диски), поскольку это не даст прироста производительности и отрицательно скажется на экономии проcтранства.
ДиС производится после подтверждения операции записи. Дедупликация производится до выгрузки данных из кэша над одинаковыми блоками 4К внутри каждой дисковой группы, между дисковыми группами дедупликация не производится. После дедупликации и перед выгрузкой данных из кэша производится их компрессия: если реально сжать 4K до 2К или меньше, то компрессия производится, если нет, то блок остается несжатым, чтобы избежать неоправданных накладных расходов.
В дедуплицированном и сжатом виде данные находятся только на уровне хранения (capacity), это приблизительно 90% объема данных кластера. При этом накладные расходы на ДиС составляют порядка 5% общей ёмкости кластера (хранение метаданных, хэшей). В кэше данные находятся в обычном состоянии, поскольку запись в кэш осуществляется гораздо чаще, чем в постоянное хранилище, соответственно накладные расходы и деградация производительности от ДиС в кэше были бы значительно больше, чем бонус от оптимизации его относительно малой ёмкости.
Следует отметить наличие вопроса выбора между малым числом больших дисковых групп или множеством маленьких. На больших дисковых группах эффекта от ДиС будет больше (он делается внутри групп, а не между ними). У множества мелких дисковых групп кэш работает более эффективно (его пространство возрастает за счет увеличения общего числа кэш-носителей), будет больше доменов отказа, что будет ускорять ребилд при отказе 1 дисковой группы.
Пространство, занимаемое цепочками снапшотов, также оптимизируется за счет ДиС.
Параметр политики хранения Number of disk stripes per object задает количество отдельных capacity-носителей, по которым будут распределены компоненты одной реплики объекта (диска ВМ). Максимальное значение этого параметра, а значит максимальная длинна страйпа, которую поддерживает vSAN, равно 12, в этом случае реплика объекта распределяется на 12 носителей. Если заданная длина страйпа превышает число носителей дисковой группе, значит реплика объекта будет растянута на несколько дисковых групп (скорее всего внутри 1 хоста). Если заданная длина страйпа превышает число носителей хоста, значит реплика объекта будет растянута на несколько хостов (например, все носители 1 хоста и часть носителей другого).
По умолчанию, длина страйпа задается равной 1, это значит, что страйпинг не производится и реплика (при размере до 255ГБ) размещается на 1 носителе в виде 1 компоненты.
Теоретически страйпинг может дать прирост производительности за счет распараллеливания в/в, если носители на которые страйпится объект не перегружены. Страйпинг объекта на несколько дисковых групп, позволяет распараллелить нагрузку не только по capacity-носителям, но и утилизировать ресурсы кэш носителей вовлеченных дисковых групп. VMware рекомендует оставлять параметр «число страйпов на объект» равным 1, как задано по умолчанию, и не страйпить объекты, за исключением тех случаев, когда страйпинг допустим, необходим и реально позволит повысить производительность. В общем случае считается, что страйпинг ощутимого прироста производительности дать не сможет. В гибридных конфигурациях эффект от страйпинга может быть положительным, особенно при интенсивном чтении, когда возникают проблемы с попаданием в кэш. Потоковая запись также может быть ускорена за счет страйпинга, в т.ч. в all-flash конфигурации, поскольку могут утилизироваться несколько кэш-носителей и распараллеливается вытеснение данных на постоянные носители.
Следует учитывать, что страйпинг приводит к значительному росту количества компонент кластера. Это важно для кластеров с большим количеством ВМ и объектов, когда лимит компонент на кластер (9000) может быть исчерпан.
Необходимо учитывать, что максимальный размер 1 компонента объекта равен 255ГБ, это значит, что если объект имеет большой размер, его реплика будет автоматически разбита на число компонентов, кратное 255. В таком случае, независимо от политики страйпинга компоненты реплики будут разнесены по нескольким носителям, если их очень много (больше, чем носителей на хосте или в кластере, например, создаем диск 62ТБ), то на носитель может попасть по несколько компонент одного объекта.
При планировании размера хранилища кластера vSAN необходимо учитывать, что реально занимаемое пространство с учетом используемых методов отказоустойчивости (зеркало или EC) и количества допустимых отказов (от 1 до 3х) может значительно превышать полезную ёмкость кластера. Также необходимо учитывать воздействие методов оптимизации использования пространства (EC и ДиС).
Следует учитывать выделение пространства под swap-файлы (размер ОЗУ каждой ВМ) и хранение снапшотов.
При заполнении ёмкости vSAN на 80% начинается ребалансировка кластра – это фоновый процесс, перераспределяющий данные по кластеру и вызывающий значительную нагрузку, лучше не допускать его наступления. Порядка 1% пространства уходит при форматировании носителей кластера под файловую систему vSAN (VSAN-FS). Небольшая доля пространства уходит на метаданные ДиС (5%). Поэтому VMware рекомендует проектировать кластер vSAN с запасом ёмкости 30%, для того чтобы не доводить до ребалансировки.
vSAN рекомендует и поддерживает использование нескольких storage-контроллеров на одном хосте. Это позволяет увеличить производительность, ёмкость и отказоустойчивость на уровне отдельных узлов. При этом ни одна vSAN ready node не содержит более 1 storage-контроллера.
Рекомендуется выбирать контроллеры с максимально большой длиной очереди (не менее 256. Рекомендуется использовать контроллеры в режиме pass-through, когда диски напрямую презентуются гипервизору. vSAN поддерживает использование контроллеров в режиме raid-0, однако их применение приводит к дополнительным манипуляциям при сопровождении (например, при замене носителя). Внутренний кэш контроллера рекомендуется отключать, если невозможно, то настроить 100% на чтение; фирменные режимы акселерации контроллеров также необходимо отключать.
В случае отказа capacity-носителя его ребилд может быть произведен внутри той же дисковой группы или на другую группу (на том же хосте или на другом), это зависит от наличия свободного места.
Отказ кэш-носителя приводит к ребилду его дисковой группы целиком. Ребилд может быть произведен на тот же хост (если на нем есть еще дисковые группы и свободное место) или на другие хосты.
На случай отказа хоста для ребилда лучше предусмотреть как минимум 1 свободный хост, если нужно отработать несколько отказов, то и свободных хостов должно быть несколько.
Если компонент (диск или дисковый контроллер) деградировал (отказ компонента без возможности восстановления), то vSAN начинает его ребилдить немедленно.
Если компонент (потеря сети, отказ сетевой карты, отключение хоста, отключение диска) отсутствует (временное отключение с возможностью восстановления), то vSAN начинает его ребилдить отложенно (по умолчанию, через 60 мин).
Естественно, условием ребилда является наличие свободного места в кластере.
После отказа (носителя, дисковой группы, хоста, потери сети) vSAN останавливает в/в на 5-7 секунд пока оценивает доступность потерянного объекта. Если объект находится, то в/в возобновляется.
Если через 60 минут после отказа хоста или потери сети (начался ребилд), потерянный хост возвращается в строй (восстановлен или поднята сеть), vSAN сама определяет, что лучше (быстрее) сделать: доделать ребилд или синхронизировать вернувшийся хост.
По умолчанию vSAN осуществляет подсчёт контрольных сумм для контроля целостности объектов на уровне политик хранения. Вычисление контрольных сумм производится для каждого блока данных (4KB), их проверка осуществляется как фоновый процесс на операциях чтения и для данных, остающихся холодными в течении года (scrubber). Данный механизм позволяет выявлять повреждения данных по программным и аппаратным причинам, например, на уровне памяти и дисков.
При обнаружении несоответствия контрольной суммы vSAN автоматически восстанавливает поврежденные данные путем их перезаписи.
Вычисление контрольных сумм можно отключить на уровне политик хранения. Частоту запуска scrubber-а (проверка блоков к которым не было обращений) при желании можно изменить в дополнительных настройках (параметр VSAN.ObjectScrubsPerYear) и выполнять такую проверку чаще, чем 1 раз в год (хоть раз в неделю, но возникнет допнагрузка).
vSAN поддерживает nic-teaming с агрегированием портов и балансировкой нагрузки.
До версии 6.5 включительно vSAN требует поддержки мультикаст-трафика в своей сети. Если в одной подсети размещается несколько кластеров vSAN, необходимо назначить их хостам разные мультикаст-адреса, для разделения их трафика. Начиная с версии 6.6 vSAN не использует мультикаст.
При проектировании сети vSAN рекомендуется закладывать leaf-spine архитектуру.
vSAN поддерживает NIOC для выделения гарантированной полосы пропускания под свой трафик. NIOC может быть запущен только на distributed vSwitch, vSAN дает возможность их использования в любой редакции vSphere (они входят в лицензию vSAN).
vSAN поддерживает использование Jumbo-фреймов, однако VMware считает прирост производительности от их использования незначительным, поэтому даёт следующие рекомендации: если сеть их уже поддерживает – можно использовать, если нет, то для vSAN они совсем необязательны, можно обойтись без них.
Выше были описаны состав, структура и принципы размещения объектов и компонентов в кластере vSAN, методы обеспечения отказоустойчивости, использование политик хранения.
Теперь рассмотрим, как это работает на простом примере. В нашем распоряжении кластер vSAN из 4-х хостов в all-flash конфигурации. На рисунке ниже условно представлено, как в этом кластере будут размещаться 3 диска ВМ (вДиски).

вДиск-1 был привязан к политике хранения с отработкой 1 отказа (Failure To Tolerate (FTT) = 1) и использованием Erasure Coding (Fault Tolerance Method (FTM) = EC). Таким образом, объект вДиск-1 был распределен в системе в виде 4 компонент, по 1 на хост. Данные (data) вДиска внутри этих компонент записаны вместе с вычисленными значениями четностей (parity), фактически это сетевой RAID-5.
вДиск-2 и вДиск-3 были привязаны к политикам хранения с отработкой 1 отказа (FTT = 1) и зеркалированием (FTM = Mirror). Уточним, что вДиск-2 имеет полезный размер менее 255ГБ и для него задан размер страйпа по умолчанию (Number of disk stripes per object = 1). Поэтом объект вДиск-2 был размещен на кластере в виде 3х компонент на разных узлах: две зеркальные реплики и свидетель (witness).
вДиск-3, в данном случае, имеет полезный размер 500ГБ и для него задан размер страйпа по умолчанию. Поскольку 500ГБ больше 255ГБ, vSAN автоматически разбивает одну реплику объекта вДиск-3 на 2 компонента (Компонент1-1 и Компонент1-2) и кладет на Хост-1. Их реплики (Компонент2-1 и Компонент4-2) размещаются на хостах 2 и 4, соответственно. В данном случае свидетель отсутствует, поскольку алгоритм расчета кворума с использованием голосов позволяет без него обойтись. Необходимо отметить, что vSAN разместила вДиск-3 на пространстве кластера именно таким образом автоматически и на свое усмотрение, руками это задать не получится. С тем же успехом она могла разместить эти компоненты на узлах по-другому, например, одну реплику (Компонент1-1 и Компонент1-2) на Хост-4, вторую на Хост-1 (Компонент2-1) и Хост-3 (Компонент4-2). Либо могла выделить под реплики 2 хоста (2 компоненты на Хост-1 и 2 компоненты на Хост-3), а на третий разместить свидетеля (Хост-4), это уже 5 компонент, а не 4.
Конечно, автоматическое размещение объектов не является произвольным, vSAN руководствуется своими внутренними алгоритмами и старается равномерно утилизировать пространство и по возможности сократить количество компонент.
Размещение вДиск-2 тоже могло быть иным, общее условие – компоненты разных реплик и свидетель (если он есть) должны находиться на разных хостах, это условие отработки отказа. Так, если бы вДиск-2 имел размер чуть меньше 1,9ТБ, то каждая из его реплик состояла бы из 8 компонент (одна компонента не более 255ГБ). Такой объект можно было бы разместить на тех же 3х хостах (8 компонентов 1 реплики на Хосте-1, 8 компонентов 2 реплики на Хосте-2, свидетель на Хосте-3. Либо vSAN мог бы разместить его без свидетеля, распределив 16 компонентов обеих реплик по всем 4 хостам (без пересечения разных реплик на одном хосте)
Просто привожу таблицу из рекомендаций VMware:

vSAN поддерживает работу в режиме Stretched Cluster (растянутый кластер) с охватом 2х географически разнесенных площадок (сайтов), при этом общий пул хранения vSAN также распределяется между сайтами. Оба сайта являются активными, в случае выхода из строя одной из площадок, кластер использует хранилище и вычислительные мощности оставшегося сайта для возобновления работы рухнувших сервисов.
Подробное рассмотрение особенностей Stretched Cluster выходит за рамки данной публикации.
» Документация по vSAN 6.5 на VMware vSphere 6.5 Documentation Center
» Руководство по дизайну и масштабированию vSAN 6.2
» Руководство по дизайну сети vSAN 6.2
» Технологии оптимизации ёмкости vSAN 6.2
» Страйпинг в vSAN
» Блог VMware по vSAN
Концепция Virtual SAN
VMware Virtual SAN (далее vSAN) представляет собой распределенную программную СХД (SDS) для организации гипер-конвергентной инфраструктуры (HCI) на базе vSphere. vSAN встроен в гипервизор ESXi и не требует развертывание дополнительных сервисов и служебных ВМ. vSAN позволяет объединить локальные носители хостов в единый пул хранения, обеспечивающий заданный уровень отказоустойчивости и предоставляющий свое пространство для всех хостов и ВМ кластера. Таким образом, мы получаем централизованное хранилище, необходимое для раскрытия всех возможностей виртуализации (технологии vSphere), без необходимости внедрения и сопровождения выделенной (традиционной) СХД.
vSAN запускается на уровне кластера vSphere, достаточно запустить соответствующий сервис в управлении кластером и предоставить ему локальные носители хостов кластера – в ручном или автоматическом режиме. vSAN встроен в vSphere и жёстко привязан к ней, как самостоятельный продукт SDS, способный работать вне инфраструктуры VMware, существовать не может.
Аналогами и конкурентами vSAN являются: Nutanix DSF (распределенное хранилище Нутаникс), Dell EMC ScaleIO, Datacore Hyper-converged Virtual SAN, HPE StoreVirtual. Все эти решения совместимы ни только с VMware vSphere, но и с MS Hyper-V (некоторые и с KVM), они предполагают установку и запуск на каждом хосте HCI служебной ВМ, необходимой для функционирования SDS, в гипервизор они не встраиваются.
Важным свойством любой HCI, в т.ч. VMware vSphere+vSAN, является горизонтальная масштабируемость и модульность архитектуры. HCI строится и расширяется на базе идентичных серверных блоков (хостов или узлов), объединяющих вычислительные ресурсы, ресурсы хранения (локальные носители) и сетевые интерфейсы. Это может быть commodity-оборудование (серверы x86, в т.ч. брэндовые), поставляемое отдельно, либо уже готовые эплаенсы (например, Nutanix, vxRail, Simplivity). Комплексное ПО (например, vSphere+vSAN+средства_оркестровки_VMware) позволяет создать на базе этих блоков программно-определяемый ЦОД (SDDS), включающий среду виртуализации, SDN (программно-определяемая сеть), SDS, средства централизованного управления и автоматизации/оркестровки. Конечно, нельзя забывать про необходимость выделенного физического сетевого оборудования (коммутаторы), без которого невозможно взаимодействие между хостами HCI. При этом для организации сети целесообразно использовать leaf-spine архитектуру, оптимальную для ЦОД.
vSAN поднимается на уровне кластера хостов ESXi под управлением vCenter и предоставляет распределенное централизованное хранилище хостам данного кластера. Кластер vSAN может быть реализован в 2х вариантах:
• Гибридный – флэш-накопители используются в качестве кэша (cache layer), HDD обеспечивают основную ёмкость хранилища (capacity layer).
• All-flash — флэш-накопители используются на обоих уровнях: cache и capacity.
Расширение vSAN-кластера возможно путем добавления носителей в существующие хосты либо путем установки новых хостов в кластер. При этом необходимо учитывать, что кластер должен оставаться сбалансированным, это значит, что в идеале состав носителей в хостах (и сами хосты) должен быть идентичным. Допустимо, но не рекомендуется, включать в кластер хосты без носителей, участвующих в ёмкости vSAN, они также могут размещать свои ВМ на общем хранилище vSAN-кластера.
Сравнивая vSAN с традиционными внешними СХД следует отметить, что:
• vSAN не требует организации внешнего хранилища и выделенной сети хранения;
• vSAN не требует нарезки LUN-ов и файловых шар, презентования их хостам и связанной с этим настройки сетевого взаимодействия; после активации vSAN сразу становится доступной всем хостам кластера;
• передача данных vSAN осуществляется по собственному проприетарному протоколу; стандартные протоколы SAN/NAS (FC, iSCSI, NFS) для организации и работы vSAN не нужны;
• администрирование vSAN осуществляется только из консоли vSphere; отдельные средства администрирования или специальные плагины для vSphere не нужны;
• не нужен выделенный администратор СХД; настройка и сопровождение vSAN осуществляется администратором vSphere.
Носители и дисковые группы
На каждом хосте кластера vSAN должно быть минимум по одному кэш-носителю и носителю данных (capacity или data disk). Данные носители внутри каждого хоста объединяются в одну или несколько дисковых групп. Каждая дисковая группа включает только один кэш-носитель и один или несколько носителей данных для постоянного хранения.
Носитель, отданный vSAN и добавленный в дисковую группу, утилизируется полностью, его нельзя использовать для других задач или в нескольких дисковых группах. Это касается как кэш-носителя, так и capacity дисков.
vSAN поддерживает только локальные носители, либо диски, подключенные по DAS. Включение в пул хранения vSAN хранилищ, подключенных по SAN/NAS, не поддерживается.
Объектное хранилище
vSAN представляет собой объектное хранилище, данные в нем хранятся в виде «гибких» (flexible) контейнеров, называемых объектами. Объект хранит внутри себя данные или мета-данные, распределенные по кластеру. Ниже перечислены основные разновидности объектов vSAN (создаются отдельно для каждой ВМ):
Таким образом, данные каждой ВМ хранятся на vSAN в виде множества перечисленных выше объектов. В свою очередь каждый объект включает в себя множество компонентов, распределенных по кластеру в зависимости от выбранной политики хранения и объема данных.
Управление хранением данных на vSAN осуществляется с помощью механизма SPBM (Storage Policy Based Management), под воздействием которого находятся все хранилища vSphere начиная с версии 6. Политика хранения задает количество допустимых отказов (Number of failures to tolerate), метод обеспечения отказоустойчивости (репликация или erasure coding) и количество страйпов для объекта (Number of disk stripes per object). Заданное политикой количество страйпов определяет число носителей данных (capacity), по которым будет размазан объект.
Привязка политики к конкретной ВМ или её диску определяет количество компонентов объекта и их распределение по кластеру.
vSAN допускает изменение политики хранения для объектов на-горячую, без остановки работы ВМ. При этом в фоне запускаются процессы реконфигурации объектов.
При распределении объектов по кластеру vSAN контролирует, чтобы компоненты, относящиеся к разным репликам объекта и компоненты-свидетели (witness), разносились по разным узлам или доменам отказа (серверная стойка, корзина или площадка).
Witness и кворум
Свидетель (witness) – это служебный компонент, не содержащий полезных данных (только метаданные), его размер равен 2-4МБ. Он выполняет роль тайбрейкера при определении живых компонентов объекта в случае отказов.
Механизм вычисления кворума в vSAN работает следующим образом. Каждый компонент объекта получает определенное число голосов (votes) — 1 и более. Кворум достигается и объект считается «живым» если доступна его полная реплика и более половины его голосов.
Такой механизм вычисления кворума позволяет распределить компоненты объекта по кластеру таким образом, что в некоторых случаях можно обойтись без создания свидетеля. Например, при использовании RAID-5/6 или страйпинга на RAID-1.
Virtual SAN datastore
После включения сервиса vSAN в кластере vSphere появляется одноименное хранилище (datastore), на весь кластер vSAN оно может быть только единственным. Благодаря механизму SPBM, описанному выше, в рамках единого хранилища vSAN каждая ВМ или её диск может получить необходимый её уровень сервиса (отказоустойчивость и производительность) путем привязки к нужной политике хранения.
vSAN datastore доступно всем хостам кластера, вне зависимости от наличия у хоста локальных носителей, включенных в vSAN. При этом хостам кластера могут быть доступны хранилища (datastore) других типов: VVol, VMFS, NFS.
vSAN datastore поддерживает Storage vMotion (горячая миграция дисков ВМ) с хранилищами VMFS/NFS.
В рамках одного сервера vCenter можно создавать несколько кластеров vSAN. Поддерживается Storage vMotion между кластерами vSAN. При этом каждый хост может быть участником только одного кластера vSAN.
Совместимость vSAN с другими технологиями VMware
vSAN совместима и поддерживает большинство технологий VMware, в т.ч. требующих общего хранилища, в частности: vMotion, Storage vMotion, HA, DRS, SRM, vSphere Replication, снапшоты, клоны, VADP, Horizon View.
vSAN не поддерживает: DPM, SIOC, SCSI reservations, RDM, VMFS.
Аппаратные требования vSAN
Требования к устройствам хранения
Носители, контроллеры, а также драйверы и firmware должны быть сертифицированы под vSAN и отображаться в соответствующем листе совместимости VMware (секция Virtual SAN в VMware Compatibility Guide).
В качестве storage-контроллера может использоваться SAS/SATA HBA или RAID-контроллер, они должны функционировать в режиме passthrough (диски отдаются контроллером как есть, без создания raid-массива) или raid-0.
В качестве кэш-носителей могут использоваться SAS/SATA/PCIe –SSD и NVMe носители.
В качестве носителей данных могут использоваться SAS/SATA HDD для гибридной конфигурации и все перечисленные выше типы флэша (SAS/SATA/PCIe –SSD и NVMe) для all-flash конфигурации.
Требования к ОЗУ и ЦПУ
Объем памяти хоста определяется количеством и размером дисковых групп.
Минимальный объем ОЗУ хоста для участия в кластере vSAN — 8ГБ.
Минимальный объем ОЗУ хоста, необходимый для поддержки максимальной конфигурации дисковых групп (5 дисковых групп по 7 носителей данных), равен 32ГБ.
vSAN утилизирует порядка 10% ресурсов процессора.
Требования к сети
Выделенный адаптер 1Гбит/с для гибридной конфигурации
Выделенный или совместно используемый адаптер 10Гбит/с для all-flash конфигурации
Необходимо разрешить трафик мультикаст в подсети vSAN
Загрузочные носители
Для загрузки хостов с vSAN могут использоваться локальные USB или SD носители, а также SATADOM. Первые 2 типа носителей не сохраняют логи и трэйсы после перезагрузки, поскольку их запись осуществляется на RAM-диск, а последний сохраняет, поэтому рекомендуется использовать SATADOM-носители SLC-класса, обладающие большей живучестью и производительностью.
Конфигурационные максимумы vSAN 6.5
Максимум 64 хоста на кластер vSAN (и для гибрида и для all-flash)
Максимум 5 дисковых групп на хост
Максимум 7 capacity-носителей на дисковую группу
Не более 200 ВМ на хост и не более 6000 ВМ на кластер
Не более 9000 компонентов на хост
Максимальный размер диска ВМ – 62ТБ
Максимальное количество носителей в страйпе на объект – 12
Технологические особенности VMware Virtual SAN
Планирование состава кластера vSAN
Минимальное количество хостов кластера vSAN определяется числом допустимых отказов (параметр Number of failures to tolerate в политике хранения) и определяется по формуле: 2*number_of_failures_to_tolerate + 1.
При условии отработки 1 отказа vSAN допускает создание 2х- и 3х- узловых кластеров. Объект и его реплика размещаются на 2х хостах, на 3м размещается свидетель. При этом появляются следующие ограничения:
• при падении 1 хоста нет возможности ребилда данных для защиты от нового отказа;
• при переводе 1 хоста в режим обслуживания нет возможности миграции данных, данные оставшегося хоста на это время становятся незащищенными.
Это обусловлено тем, что ребилдить или мигрировать данные попросту некуда, нет дополнительного свободного хоста. Поэтому оптимально если в кластере vSAN используется от 4х хостов.
Правило 2*number_of_failures_to_tolerate + 1 применимо только при использовании Зеркалирования для обеспечения отказоустойчивости. При использовании Erasure Coding оно не работает, подробно это описано ниже в разделе «Обеспечение отказоустойчивости».
Для того, чтобы кластер vSAN был сбалансированным, аппаратная конфигурация хостов, в первую очередь это касается носителей и storage-контроллеров, должна быть идентичной.
Несбалансированный кластер (разная конфигурация дисковых групп хостов) поддерживается, но заставляет мириться со следующими недостатками:
• неоптимальная производительность кластера;
• неравномерная утилизация ёмкости хостов;
• отличия в процедурах сопровождения хостов.
Допускается размещение ВМ с сервером vCenter на vSAN датасторе, однако это приводит к рискам, связанным с управлением инфраструктурой при проблемах с vSAN.
Планирование кэша vSAN
Рекомендуется планировать размер кэша с запасом для возможности расширения capacity уровня.
В гибридной конфигурации 30% кэша выделяется на запись и 70% на чтение. All-flash конфигурация vSAN использует всю ёмкость кэш-носителей на запись, кэша на чтение не предусмотрено.
Рекомендуемый размер кэша должен быть не менее 10% от реальной ёмкости ВМ до репликации, т.е. учитывается полезное пространство, а не реально занятое (с учетом репликации).
В гибридной конфигурации дисковая группа будет утилизировать всю ёмкость установленного в неё флэш-носителя, при этом его максимальный объем не ограничен.
В all-flash конфигурации дисковая группа не может использовать более 600ГБ ёмкости установленного флэш-носителя, при этом оставшееся пространство не будет простаивать, поскольку кэшируемые данные будут записываться по всему объёму носителя циклически. В all-flash vSAN целесообразно использовать под кэш флэш-носители с большей скоростью и временем жизни по сравнению с capacity-носителями. Использование под кэш носителей объёмом более 600ГБ не повлияет на производительность, однако продлит срок службы данных носителей.
Такой подход к организации кэша в all-flash vSAN обусловлен тем, что флэш-capacity-носители и так быстрые, поэтому нет смысла кэшировать чтение. Выделение всей ёмкости кэша на запись, кроме её ускорения, позволяет продлить срок жизни capacity-уровня и снизить общую стоимость системы, поскольку для постоянного хранения можно использовать более дешевые носители, в то время как один более дорогой, производительный и живучий флэш-кэш будет защищать их от лишних операций записи.
Обеспечение отказоустойчивости
Отказоустойчивость ВМ и соотношение объема полезного и занимаемого в общем пространства хранилища vSAN определяются двумя параметрами политики хранения:
• Number of failures to tolerate – количество допустимых отказов, определяет количество хостов кластера отказ которых сможет пережить ВМ.
• Failure tolerance method – метод обеспечения отказоустойчивости.
vSAN предлагает 2 метода обеспечения отказоустойчивости:
• RAID-1 (Mirroring) – полная репликация (зеркалирование) объекта с размещением реплик на разных хостах, аналог сетевого raid-1. Позволяет пережить кластеру до 3-х отказов (хостов, дисков, дисковых групп или сетевых проблем). Если Number of failures to tolerate = 1, то создается 1 реплика (2 экземпляра объекта), пространство, реально занимаемое ВМ или её диском на кластере, в 2 раза больше её полезной ёмкости. Если Number of failures to tolerate = 2, имеем 2 реплики (3 экземпляра), реально занимаемый объем в 3 раза больше полезного. Для Number of failures to tolerate = 3, имеем 3 реплики, занимаем пространство в 4 раза больше полезного. Данный метод отказоустойчивости неэффективно использует пространство, однако предоставляет максимальную производительность. Может использоваться для гибридной и all-flash конфигурации кластера. Минимально необходимое количество хостов 2-3 (для отработки 1 отказа), рекомендуемый минимум – 4 хоста, дает возможность ребилда при отказе.
• RAID-5/6 (Erasure Coding) – при размещении объектов производится вычисление блоков чётности, аналог сетевого raid-5 или -6. Поддерживается только all-flash конфигурация кластера. Позволяет кластеру отработать 1 (аналог raid-5) или 2 отказа (аналог raid-6). Минимальное количество хостов для отработки 1 отказа равно 4, для отработки 2-х отказов равно 6, рекомендуемые минимумы 5 и 7, соответственно, для возможности ребилда. Данный метод позволяет достичь значительной экономии пространства кластера по сравнению с RAID-1, однако приводит к потере производительности, которая может оказаться вполне приемлемой для многих задач, учитывая скорость all-flash. Так, в случае 4-х хостов и допуске 1 отказа полезное пространство, занимаемое объектом при использовании Erasure Coding, будет составлять 75% от его полного объема (для RAID-1 имеем 50% полезного пространства). В случае 6-ти хостов и допуске 2-х отказов полезное пространство, занимаемое объектом при использовании Erasure Coding, будет составлять 67% от его полного объема (для RAID-1 имеем 33% полезного пространства). Таким образом, RAID-5/6 в данных примерах оказывается эффективнее RAID-1 по использованию ёмкости кластера в 1,5 и 2 раза, соответственно.
Ниже представлено распределение данных на уровне компонент кластера vSAN при использовании RAID-5 и RAID-6. C1-С6 (первая строка) – компоненты объекта, A1-D4 (цветные блоки) – блоки данных, P1-Р4 и Q1-Q4 (серые блоки) – блоки четности.
vSAN позволяет по-разному обеспечивать отказоустойчивость для различных ВМ или их дисков. В рамках одного хранилища можно для критичных к производительности ВМ привязать политику с зеркалированием, а для менее критичных ВМ настроить Erasure Coding для экономии пространства. Таким образом, будет соблюдаться баланс между производительностью и эффективным использованием ёмкости.
Ниже приводится таблица с минимальным и рекомендуемым количеством хостов или доменов отказа для различных вариантов FTM/FTT:
Домены отказа
vSAN вводит понятие доменов отказа (fault domain) для защиты кластера от отказов на уровне серверных стоек или корзин, которые логически группируются в эти домены. Включение этого механизма приводит к распределению данных для обеспечения их отказоустойчивости не на уровне отдельных узлов, а на уровне доменов, что позволит пережить отказ целого домена – всех сгруппированных в нем узлов (например, серверной стойки), поскольку реплики объектов будут обязательно размещаться на узлах из разных доменов отказа.
Количество доменов отказа вычисляется по формуле: number of fault domains = 2 * number of failures to tolerate + 1. vSAN минимально требует 2 домена отказа, в каждом по 1 или несколько хостов, однако рекомендуемое количество равно 4, поскольку допускает возможность ребилда в случае отказа (2-3 домена не дают возможность ребилда, некуда). Таким образом, метод подсчета числа доменов отказа аналогичен, методу подсчета количества хостов для отработки нужного числа отказов.
В идеале в каждом домене отказа, должно быть одинаковое количество хостов, хосты должны иметь идентичную конфигурацию, пространство одного домена рекомендуется оставлять пустым для возможности ребилда (например, 4 домена с отработкой 1 отказа).
Механизм доменов отказа работает не только при Зеркалировании (RAID-1), но и для Erasure Coding, в этом случае каждый компонент объекта должен размещаться в разных доменах отказа и формула расчета числа доменов отказа меняется: минимум 4 домена для RAID-5 и 6 доменов для RAID-6 (аналогично расчету числа хостов для Erasure Coding).
Дедупликация и сжатие
Механизмы дедупликации и сжатия (ДиС) поддерживаются только в all-flash конфигурации и могут быть включены только на кластер vSAN в целом, выборочное включение для отдельных ВМ или дисков с помощью политик не поддерживается. Использовать только одну из этих технологий тоже не получится, только обе сразу.
Включении ДиС заставляет объекты автоматически страйпиться на все диски в дисковой группе, это позволяет избежать ребалансировки компонентов и выявлять совпадения блоков данных из разных компонент на каждом диске в дисковой группе. При этом сохраняется возможность задать старайпинг объектов вручную на уровне политик хранения, в т.ч. за пределы дисковой группы. При включении ДиС нецелесообразно на уровне политики резервировать пространство под объекты (параметр Object Space Reservation, толстые диски), поскольку это не даст прироста производительности и отрицательно скажется на экономии проcтранства.
ДиС производится после подтверждения операции записи. Дедупликация производится до выгрузки данных из кэша над одинаковыми блоками 4К внутри каждой дисковой группы, между дисковыми группами дедупликация не производится. После дедупликации и перед выгрузкой данных из кэша производится их компрессия: если реально сжать 4K до 2К или меньше, то компрессия производится, если нет, то блок остается несжатым, чтобы избежать неоправданных накладных расходов.
В дедуплицированном и сжатом виде данные находятся только на уровне хранения (capacity), это приблизительно 90% объема данных кластера. При этом накладные расходы на ДиС составляют порядка 5% общей ёмкости кластера (хранение метаданных, хэшей). В кэше данные находятся в обычном состоянии, поскольку запись в кэш осуществляется гораздо чаще, чем в постоянное хранилище, соответственно накладные расходы и деградация производительности от ДиС в кэше были бы значительно больше, чем бонус от оптимизации его относительно малой ёмкости.
Следует отметить наличие вопроса выбора между малым числом больших дисковых групп или множеством маленьких. На больших дисковых группах эффекта от ДиС будет больше (он делается внутри групп, а не между ними). У множества мелких дисковых групп кэш работает более эффективно (его пространство возрастает за счет увеличения общего числа кэш-носителей), будет больше доменов отказа, что будет ускорять ребилд при отказе 1 дисковой группы.
Пространство, занимаемое цепочками снапшотов, также оптимизируется за счет ДиС.
Страйпинг объектов и количество компонент
Параметр политики хранения Number of disk stripes per object задает количество отдельных capacity-носителей, по которым будут распределены компоненты одной реплики объекта (диска ВМ). Максимальное значение этого параметра, а значит максимальная длинна страйпа, которую поддерживает vSAN, равно 12, в этом случае реплика объекта распределяется на 12 носителей. Если заданная длина страйпа превышает число носителей дисковой группе, значит реплика объекта будет растянута на несколько дисковых групп (скорее всего внутри 1 хоста). Если заданная длина страйпа превышает число носителей хоста, значит реплика объекта будет растянута на несколько хостов (например, все носители 1 хоста и часть носителей другого).
По умолчанию, длина страйпа задается равной 1, это значит, что страйпинг не производится и реплика (при размере до 255ГБ) размещается на 1 носителе в виде 1 компоненты.
Теоретически страйпинг может дать прирост производительности за счет распараллеливания в/в, если носители на которые страйпится объект не перегружены. Страйпинг объекта на несколько дисковых групп, позволяет распараллелить нагрузку не только по capacity-носителям, но и утилизировать ресурсы кэш носителей вовлеченных дисковых групп. VMware рекомендует оставлять параметр «число страйпов на объект» равным 1, как задано по умолчанию, и не страйпить объекты, за исключением тех случаев, когда страйпинг допустим, необходим и реально позволит повысить производительность. В общем случае считается, что страйпинг ощутимого прироста производительности дать не сможет. В гибридных конфигурациях эффект от страйпинга может быть положительным, особенно при интенсивном чтении, когда возникают проблемы с попаданием в кэш. Потоковая запись также может быть ускорена за счет страйпинга, в т.ч. в all-flash конфигурации, поскольку могут утилизироваться несколько кэш-носителей и распараллеливается вытеснение данных на постоянные носители.
Следует учитывать, что страйпинг приводит к значительному росту количества компонент кластера. Это важно для кластеров с большим количеством ВМ и объектов, когда лимит компонент на кластер (9000) может быть исчерпан.
Необходимо учитывать, что максимальный размер 1 компонента объекта равен 255ГБ, это значит, что если объект имеет большой размер, его реплика будет автоматически разбита на число компонентов, кратное 255. В таком случае, независимо от политики страйпинга компоненты реплики будут разнесены по нескольким носителям, если их очень много (больше, чем носителей на хосте или в кластере, например, создаем диск 62ТБ), то на носитель может попасть по несколько компонент одного объекта.
Планирование ёмкости кластера vSAN
При планировании размера хранилища кластера vSAN необходимо учитывать, что реально занимаемое пространство с учетом используемых методов отказоустойчивости (зеркало или EC) и количества допустимых отказов (от 1 до 3х) может значительно превышать полезную ёмкость кластера. Также необходимо учитывать воздействие методов оптимизации использования пространства (EC и ДиС).
Следует учитывать выделение пространства под swap-файлы (размер ОЗУ каждой ВМ) и хранение снапшотов.
При заполнении ёмкости vSAN на 80% начинается ребалансировка кластра – это фоновый процесс, перераспределяющий данные по кластеру и вызывающий значительную нагрузку, лучше не допускать его наступления. Порядка 1% пространства уходит при форматировании носителей кластера под файловую систему vSAN (VSAN-FS). Небольшая доля пространства уходит на метаданные ДиС (5%). Поэтому VMware рекомендует проектировать кластер vSAN с запасом ёмкости 30%, для того чтобы не доводить до ребалансировки.
Выбор storage-контроллера
vSAN рекомендует и поддерживает использование нескольких storage-контроллеров на одном хосте. Это позволяет увеличить производительность, ёмкость и отказоустойчивость на уровне отдельных узлов. При этом ни одна vSAN ready node не содержит более 1 storage-контроллера.
Рекомендуется выбирать контроллеры с максимально большой длиной очереди (не менее 256. Рекомендуется использовать контроллеры в режиме pass-through, когда диски напрямую презентуются гипервизору. vSAN поддерживает использование контроллеров в режиме raid-0, однако их применение приводит к дополнительным манипуляциям при сопровождении (например, при замене носителя). Внутренний кэш контроллера рекомендуется отключать, если невозможно, то настроить 100% на чтение; фирменные режимы акселерации контроллеров также необходимо отключать.
Отработка отказов
В случае отказа capacity-носителя его ребилд может быть произведен внутри той же дисковой группы или на другую группу (на том же хосте или на другом), это зависит от наличия свободного места.
Отказ кэш-носителя приводит к ребилду его дисковой группы целиком. Ребилд может быть произведен на тот же хост (если на нем есть еще дисковые группы и свободное место) или на другие хосты.
На случай отказа хоста для ребилда лучше предусмотреть как минимум 1 свободный хост, если нужно отработать несколько отказов, то и свободных хостов должно быть несколько.
Если компонент (диск или дисковый контроллер) деградировал (отказ компонента без возможности восстановления), то vSAN начинает его ребилдить немедленно.
Если компонент (потеря сети, отказ сетевой карты, отключение хоста, отключение диска) отсутствует (временное отключение с возможностью восстановления), то vSAN начинает его ребилдить отложенно (по умолчанию, через 60 мин).
Естественно, условием ребилда является наличие свободного места в кластере.
После отказа (носителя, дисковой группы, хоста, потери сети) vSAN останавливает в/в на 5-7 секунд пока оценивает доступность потерянного объекта. Если объект находится, то в/в возобновляется.
Если через 60 минут после отказа хоста или потери сети (начался ребилд), потерянный хост возвращается в строй (восстановлен или поднята сеть), vSAN сама определяет, что лучше (быстрее) сделать: доделать ребилд или синхронизировать вернувшийся хост.
Контрольные суммы
По умолчанию vSAN осуществляет подсчёт контрольных сумм для контроля целостности объектов на уровне политик хранения. Вычисление контрольных сумм производится для каждого блока данных (4KB), их проверка осуществляется как фоновый процесс на операциях чтения и для данных, остающихся холодными в течении года (scrubber). Данный механизм позволяет выявлять повреждения данных по программным и аппаратным причинам, например, на уровне памяти и дисков.
При обнаружении несоответствия контрольной суммы vSAN автоматически восстанавливает поврежденные данные путем их перезаписи.
Вычисление контрольных сумм можно отключить на уровне политик хранения. Частоту запуска scrubber-а (проверка блоков к которым не было обращений) при желании можно изменить в дополнительных настройках (параметр VSAN.ObjectScrubsPerYear) и выполнять такую проверку чаще, чем 1 раз в год (хоть раз в неделю, но возникнет допнагрузка).
Планирование сети vSAN
vSAN поддерживает nic-teaming с агрегированием портов и балансировкой нагрузки.
До версии 6.5 включительно vSAN требует поддержки мультикаст-трафика в своей сети. Если в одной подсети размещается несколько кластеров vSAN, необходимо назначить их хостам разные мультикаст-адреса, для разделения их трафика. Начиная с версии 6.6 vSAN не использует мультикаст.
При проектировании сети vSAN рекомендуется закладывать leaf-spine архитектуру.
vSAN поддерживает NIOC для выделения гарантированной полосы пропускания под свой трафик. NIOC может быть запущен только на distributed vSwitch, vSAN дает возможность их использования в любой редакции vSphere (они входят в лицензию vSAN).
vSAN поддерживает использование Jumbo-фреймов, однако VMware считает прирост производительности от их использования незначительным, поэтому даёт следующие рекомендации: если сеть их уже поддерживает – можно использовать, если нет, то для vSAN они совсем необязательны, можно обойтись без них.
Пример размещение объектов в кластере vSAN
Выше были описаны состав, структура и принципы размещения объектов и компонентов в кластере vSAN, методы обеспечения отказоустойчивости, использование политик хранения.
Теперь рассмотрим, как это работает на простом примере. В нашем распоряжении кластер vSAN из 4-х хостов в all-flash конфигурации. На рисунке ниже условно представлено, как в этом кластере будут размещаться 3 диска ВМ (вДиски).
вДиск-1 был привязан к политике хранения с отработкой 1 отказа (Failure To Tolerate (FTT) = 1) и использованием Erasure Coding (Fault Tolerance Method (FTM) = EC). Таким образом, объект вДиск-1 был распределен в системе в виде 4 компонент, по 1 на хост. Данные (data) вДиска внутри этих компонент записаны вместе с вычисленными значениями четностей (parity), фактически это сетевой RAID-5.
вДиск-2 и вДиск-3 были привязаны к политикам хранения с отработкой 1 отказа (FTT = 1) и зеркалированием (FTM = Mirror). Уточним, что вДиск-2 имеет полезный размер менее 255ГБ и для него задан размер страйпа по умолчанию (Number of disk stripes per object = 1). Поэтом объект вДиск-2 был размещен на кластере в виде 3х компонент на разных узлах: две зеркальные реплики и свидетель (witness).
вДиск-3, в данном случае, имеет полезный размер 500ГБ и для него задан размер страйпа по умолчанию. Поскольку 500ГБ больше 255ГБ, vSAN автоматически разбивает одну реплику объекта вДиск-3 на 2 компонента (Компонент1-1 и Компонент1-2) и кладет на Хост-1. Их реплики (Компонент2-1 и Компонент4-2) размещаются на хостах 2 и 4, соответственно. В данном случае свидетель отсутствует, поскольку алгоритм расчета кворума с использованием голосов позволяет без него обойтись. Необходимо отметить, что vSAN разместила вДиск-3 на пространстве кластера именно таким образом автоматически и на свое усмотрение, руками это задать не получится. С тем же успехом она могла разместить эти компоненты на узлах по-другому, например, одну реплику (Компонент1-1 и Компонент1-2) на Хост-4, вторую на Хост-1 (Компонент2-1) и Хост-3 (Компонент4-2). Либо могла выделить под реплики 2 хоста (2 компоненты на Хост-1 и 2 компоненты на Хост-3), а на третий разместить свидетеля (Хост-4), это уже 5 компонент, а не 4.
Конечно, автоматическое размещение объектов не является произвольным, vSAN руководствуется своими внутренними алгоритмами и старается равномерно утилизировать пространство и по возможности сократить количество компонент.
Размещение вДиск-2 тоже могло быть иным, общее условие – компоненты разных реплик и свидетель (если он есть) должны находиться на разных хостах, это условие отработки отказа. Так, если бы вДиск-2 имел размер чуть меньше 1,9ТБ, то каждая из его реплик состояла бы из 8 компонент (одна компонента не более 255ГБ). Такой объект можно было бы разместить на тех же 3х хостах (8 компонентов 1 реплики на Хосте-1, 8 компонентов 2 реплики на Хосте-2, свидетель на Хосте-3. Либо vSAN мог бы разместить его без свидетеля, распределив 16 компонентов обеих реплик по всем 4 хостам (без пересечения разных реплик на одном хосте)
Рекомендации по эффективному использованию пространства
Просто привожу таблицу из рекомендаций VMware:
Поддержка режима Stretched Cluster
vSAN поддерживает работу в режиме Stretched Cluster (растянутый кластер) с охватом 2х географически разнесенных площадок (сайтов), при этом общий пул хранения vSAN также распределяется между сайтами. Оба сайта являются активными, в случае выхода из строя одной из площадок, кластер использует хранилище и вычислительные мощности оставшегося сайта для возобновления работы рухнувших сервисов.
Подробное рассмотрение особенностей Stretched Cluster выходит за рамки данной публикации.
Список использованных источников (полезные ссылки)
» Документация по vSAN 6.5 на VMware vSphere 6.5 Documentation Center
» Руководство по дизайну и масштабированию vSAN 6.2
» Руководство по дизайну сети vSAN 6.2
» Технологии оптимизации ёмкости vSAN 6.2
» Страйпинг в vSAN
» Блог VMware по vSAN
