Цель статьи — познакомить широкую аудиторию с соревнованиями по анализу данных на Kaggle. Я расскажу о своем подходе к участию на примере Outbrain click prediction соревнования, в котором я принимал участие и занял 4ое место из 979 команд, закончив первым из выступающих в одиночку.
Для понимания материала желательны знания о машинном обучении, но не обязательны.
О себе — работаю в роли Data Scientist / Software Engineer в captify.co.uk. Это второе серьезное соревнование на Kaggle, предыдущий результат 24/2125, также соло. Машинным обучением занимаюсь около 5ти лет, программированием — 12. Linkedin profile.
Основной задачей машинного обучения, является построение моделей, способных предсказывать результат на основе входных данных, отличающихся от обозреваемых ранее. Например, мы хотим предсказывать стоимость акций конкретной компании через заданное время, учитывая текущую стоимость, динамику рынка и финансовые новости.
Здесь будущая стоимость акций будет предсказанием, а текущая стоимость, динамика и новости — входными данными.
Kaggle это прежде всего платформа для проведения соревнований по анализу данных и машинному обучению. Спектр задач абсолютно разный — классификация китов на виды, идентификация раковых опухолей, оценка стоимости недвижимости и тд. Компания организатор формирует проблему, предоставляет данные и спонсирует призовой фонд. На момент написания статьи активны 3 соревнования, общий призовой фонд 1.25M $ — список активных соревнований.
Мое последнее соревнование — Outbrain click prediction, задача — предсказать какую рекламу нажмет пользователь из показанных ему. Спонсор соревнования — компания Outbrain занимается промоушном различного контента, например блогов или новостей. Они размещают свои рекламные блоки на множестве разных ресуров, включая cnn.com, washingtonpost.com и другие. Так как компания которая получает деньги за клики пользователей, они заинтересованы показывать пользователям потенциально интересный им контент.
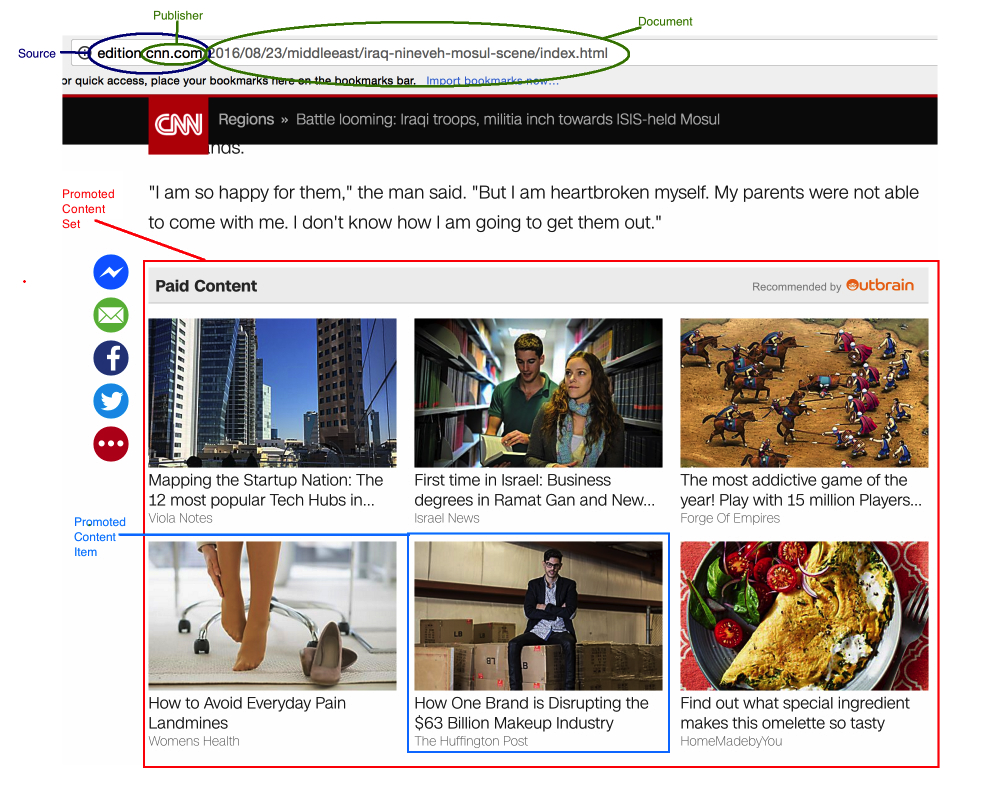
Формальное описание задачи — необходимо расположить показанную пользователю рекламу в данном блоке в ниспадающем порядке по вероятности нажатия на рекламу.
Количество предоставленных данных достаточно большое, например clicklog файл в районе 80ГБ. Точное описание входных данных можно получить на странице соревнования.
Предоставленные данные делятся на 2 части — те для которых участникам известно какой баннер нажмет пользователь (тренировочные данные), и данные для которых результат нужно предсказать — тестовые. При этом, Kaggle знает реальные результаты для тестовых данных.
Участники соревнования используют тренировочные данные для построения моделей, которые предсказывают результат для тестовых данных. В конце, эти предсказания загружаются обратно, где платформа, зная реальные результаты, показывает точность предсказаний.
Прежде всего, стоит разобраться с данными, которые доступны участникам соревнования. На странице Data как правило, есть описание структуры и семантики, а на странице Правил соревнования — описание, можно ли использовать внешние источники данных, и если да — стоит ли делится ими с остальными.
Первое что я обычно делаю — выкачиваю все данные и разбираюсь в структуре, зависимостях, с тем как они отвечают постановке задачи. Для этих целей удобно использовать Jupyter + Python. Строим различные графики, статистические метрики, смотрим на распределения данных — делаем все что поможет понять данные.
Например, построим распределение количества реклам в одном рекламном блоке:

Также, на Kaggle есть раздел Kernels, где код можно выполнять прямо в их ноутбуках и обычно находятся ребята, которые делают различные визуализации доступного датасета — так мы начинаем пользоваться чужими идеями.
Если есть вопросы к структуре, зависимостям или значениям данных — ответ можно поискать на форуме, а можно попробовать догадаться самому и получить преимущество над теми кто (еще) не догадался.
Также, часто в данных есть Утечки (Leaks) — зависимости, например временные, которые позволяют понять значение целевой переменной (предсказание) для подмножества поставленных задач.
Например, в Outbrain click prediction, из данных в клик-логе можно было понять что пользователь нажал на определенную рекламу. Информация о таких утечках может публиковаться на форуме, а может и использоваться участниками без огласки.
Когда с постановкой задачи и входными данными в целом все ясно, я начинаю сбор информации — чтение книг, изучение похожих соревнований, научных публикаций. Это замечательный период соревнования, когда удается в очень сжатые временные сроки, значительно расширить свои знания в решении задач подобных поставленной.
Изучая подобные соревнования, я пересматриваю его форум, где победители как правило описывают свои подходы + изучаю исходный код решений который доступен.
Чтение публикаций знакомит с лучшими на сейчас результатами и подходами. Тоже отлично когда можно найти изначальный или воссозданный исходный код.
Например, два последних соревнования по Click-Prediction, были выиграны одной и той же командой. Описание их решений + исходные коды + чтение форумов этих соревнований примерно дали представление о направлении с которого можно начинать работу.
Я всегда начинаю с инициализации репозитория контроля версий. Потерять важные куски кода можно даже в самом начале, очень неприятно его потом восстанавливать. Обычно использую Git + Bitbucket (бесплатные приватные репозитории)
Валидация, или тестирование предсказаний, это оценка их точности на основании выбранной метрики.
Например, в Outbrain click prediction нужно предсказать, на какую рекламу из показанных нажмет пользователь. Предоставленные данные делятся на две части:
Обучения моделей происходит на тренировочных данных, в надежде что точность на тестовых данных также улучшится, при этом предполагается что тестовые и тренировочные данные взяты из одной выборки.
В процессе обучения, часто происходит момент, когда точность относительно тренировочных данных растет, но относительно тестовых — начинает падать. Так происходит потому что мощность (Capacity) модели позволяет запомнить или подстроится под тестовый набор.

Это явление называется переобучение (overfit), как с ним бороться мы поговорим ниже, пока достаточно понять что проверять точность необходимо на данных, которые модель не видела.
Несмотря на то что Kaggle дает возможность оценить точность решения (относительно тестовых данных) загрузив его на сайт, такой подход оценки имеет ряд недостатков:
Хорошо бы иметь локальную систему оценки точности, что позволит:
Для этих целей отлично подойдет локальная (кросс) валидация. Идея проста — разделим тренировочный набор на тренировочный и валидационный и будем использовать валидационный для оценки точности, сравнения алгоритмов, но не для обучения.
Методов валидации есть много, также как и способов разделения данных, важно соблюдать несколько простых правил:
Проверить адекватность локальной валидации можно сравнив улучшение показанное локально с реальным улучшением, полученным после загрузки решения на Kaggle. Хорошо, когда изменения в локальной оценке дают представление о реальном улучшении.
Модель можно представить как черный ящик или функцию, которая на входе получает данные и возвращает результат. Результаты могут быть разного типа, наиболее часто используемые:
В Outbrain competition необходимо было ранжировать рекламу по вероятности нажатия пользователем на нее. Простой и действенный способ добится этого — использовать задачу классификации, предсказывать вероятность нажатия, и сортировать рекламу в блоке по выданным классификатором вероятностям:
Предсказания классификатора:
Формат, в котором принимаются решения задачи:
Оценочная метрика (evaluation metric) — функция, показывающая насколько точно предсказание соответствует реальным данным. Для каждого типа задачи, существует много метрик — например для регрессии часто используется основанная на разнице квадратов значений. В соревновании использовалась MEAP (Mean Average Precision) — метрика учитывающая не только количество правильных ответов, но и разницу в порядке сортировки.
Рассмотрим простейший алгоритм, когда мы считаем что скорее всего, пользователь нажмет на наиболее популярную рекламу — ту у которой соотношение количество нажатий / просмотров (Click-through Rate — CTR) максимальное. В данном случае, входными параметрами в модель у нас есть 2 значения — id рекламы и была ли реклама нажата. Особого машинного обучения здесь нет, обычная статистическая метрика.
Допустим, это наши тренировочные данные, пусть под displayId мы группируем рекламы, показанные одному пользователю в одном блоке:
Для формирования первого признака используем формулу adClicked = max adId sum(adId, clicked == 1) / sum(adId)
Входные значения удобно представлять в виде вектора для одного случая (часто называется feature vector), и матрицы для всего набора данных — обозначается X. Целевая переменная (в нашем случае Clicked) — y
Теперь, при формировании ответа, для каждого displayId, мы сортируем показанные рекламы по feature_1 и получим ответ в виде:
display_id,ad_id
1,2 1
2,1 3
Первое что нужно сделать, это проверить точность работы модели используя уже разработанный нами механизм валидации. Модель основанная на частоте со сглаживанием возвращает результат значительно лучше случайных предсказаний:
Можно расширить модель, и считать CTR исходя также из региона пользователя, а статистику считать для всех встречаемых комбинаций adId * country * state:
adClicked = max adId sum(adId, clicked == 1, country==displayCountry, state==displayState) / sum(adId)
Важно строить признаки для обучения только из тренировочного набора данных, исключая валидационный и тестовый наборы, иначе мы не сможем адекватно оценить точность работы модели. Если используется k-fold cross validation — строить такие признаки придется k раз.
Другой подход — генерировать признаки таким образом, чтобы уменьшить переобучение модели. Например, я добавлял статистики по частоте нажатий только для тех реклам, где количество просмотров N > 10 (значение подбирается во время валидации). Мотивация — если добавляем частоты где количество просмотров рекламы == 1, алгоритм с достаточной сложностью (например дерево решений) определит возможность этого признака однозначно предсказать ответ и может использовать только ее для предсказания, при этом понятно, что решение это будет достаточно наивным.
Весь процесс генерирования признаков из входных данных часто называется Feature Engineering, и часто является решающим фактором успешного соревнования, так как алгоритмы и мета-алгоритмы обучения моделей как правило общедоступны.
Я рассматривал несколько общих групп признаков, определяющих:
Рассмотрим каждую группу подробнее:
Используя тренировочный набор данных и лог просмотров страниц, можно выбрать много интересного о пользователе — какие рекламы\рекламные кампании нажимал а какие всегда игнорировал. Так как были предоставлена метаинформация о страницах на которую ведет реклама (landing page) можно выявить какие категории страниц или темы\сущности пользователю интересны — если landing page это sport.cnn, и пользователь читает новости спорта часто в это время дня или в этот день недели, это можно попробовать использовать как признак.
Такие и подобные признаки помогут позже найти пользователей с похожими предпочтениями и через них предсказать — нажмет ли пользователь на рекламу.
Отбор признаков я делал вручную — исходя из изменения точности оценки до\после добавления.
Здесь стоит начать с простого перечисления мета-информации о рекламе/landing-page|рекламной кампании + CTR подобные признаки исходя из гео-локации, времени дня, дня недели — например stateCTRCamp: частота нажатий на рекламную кампанию (объединяет рекламы) в каком-то штате
Под контекстом я понимаю как страницу на которой отображается реклама так и время показа + информация о пользователе: гео + тип устройства. Зная время, можно перечислить все рекламы и страницы, которые пользователь посетил\нажимал вчера\позавчера\за последний час. Можно определить контент, популярный на данный момент и тд.
country, state, platform, county, pageDocumentCategories, countryCTRAdv, campaignId, advertiserId, userDocsSeenFromLogYesterday, userClickedThisAdvertiserTimes, hourOfDay, userDocsClickedToday, lastAdvUserClicked
Общее количество признаков — около 120, абсолютное большинство — разработанные вручную, например userDocsSeenFromLogYesterday — документы из клик лога просмотренные пользователем вчера (относительно целевого показа рекламы). более расширенный (неполный) список в техническом описании решения на форуме соревнования.
Большинство из использованных признаков категоризационные — например country, и для превращения в бинарный признак используется one-hot-encoding. Некоторые числовые признаки также были превращены в бинарные посредством отнесениях к числовому интервалу, для сглаживания некоторых использовалась формула log(x+1).
Закодированные признаки, встречающиеся менее 10 раз, не учитывались. Общее число кодированных признаков > 5M, хеширование для уменьшения размерности не применялось.
Построим модель логистической регрессии, которая получает на вход простые числовые признаки — частоту нажатий в стране и штате:
countryAdCTR = sum(adId, clicked == 1, country == displayCountry) / sum(adId)
stateAdCTR = sum(adId, clicked == 1, state == displayState) / sum(adId)
Формула вероятности нажатия на рекламу будет:
y* = f(z), z = w1 * countryAdCTR + w2 * stateAdCTR, f(z) = 1 / (1 + e(-z))
f(z) — логистическая функция, возвращает значения в интервале [0:1]. Алгоритм обучения подбирает коэффициенты w1 и w2 таким образом, чтобы уменьшить разницу между y* и y — т.е. добится максимальной схожести предсказаний и реальных значений.
Добавим категаризационные признаки advertiser и view_page_domain в модель, предварительно конвертировав их в бинарные при помощи метода one-hot-encoding, пример:
Categorical:
One-hot-encoded:
Формула будет:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3*advertiser + w4*view_page_domain
Так как advertiser и view_page это вектор, то и w3 и w4 тоже будут векторами
В CTR prediction очень важно учитывать взаимодействия признаков например страница на которой показывается реклама и advertiser — вероятность нажать на рекламу Gucci на страницу Vogue совершенно другая чем на рекламу Adidas., модель можно дополнить взаимодействием между advertiser и view_page:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3*advertiser + w4*view_page_domain + w5*advertiser*view_page_domain
Мы уже знаем что advertiser и view_page это вектора, а значит размерность вектора w5 будет длина вектора advertiser * длина вектора view_page.
С этим связанно несколько проблем — во первый, это будет очень большой вектор — все возможные домены, на которых показывается реклама умноженные на количество всех возможных рекламодателей. Во вторых — он будет очень разреженным (sparse) и большинство значений никогда не примут значение 1 — большинство комбинаций мы никогда не встретим в реальной жизни.
FM прекрасно подходят для задач предсказания CTR, так как явно учитывают взаимодействие признаков, при этом решая проблему разреженности данных. Прекрасное описание можно найти в изначальной публикации, здесь я опишу основную идею — каждое значение признака получает целочисленный вектор длины k, а результат взаимодействия признаков — скалярное произведение (dot-product) векторов — формулу смотрите в публикации в разделе Model Equation.
Во время анализа лучших моделей я обнаружил что последние 2 соревнования по CTR prediction выигрывали ребята с моделью (ансамблем) Field-aware Factorization Machines (FFM). Это продолжение FM, но теперь признаки делятся на n fields — своего рода группы признаков, как например группа признаков состоящая из документов просмотренных ранее, группа других рекламных объявлений в этом рекламном блоке и тд. Теперь каждый признак представлен в виде n векторов размерностью k — имеет разное представление в каждой другой группе признаков, что позволяет более точно учитывать взаимодействие между группами признаков. Описание и детали также смотрите в публикации.
FFM очень подвержены переобучению, для борьбы с этим используется ранняя остановка — после каждой итерации улучшения модели, происходит оценка точности на валидационном наборе. Если точность падает — обучение прекращается. Я внес несколько изменений в код стандартной библиотеки, главное из которых — добавил оценка качества на основании метрики MEAP которая использовалась для подсчета результата на Kaggle, вместо стандартной logloss.
Одна из команд, которая заняла место в топ-3 также добавила возможность попарной оптимизации в FFM.
Для возможности ранней остановки при обучении целой модели, я делил случайным образом тренировочный набор в распределении 95/5 и использовал 5% как валидационный.
Финальный результат это простое средние результатов работы 5 моделей на разных случайных распределениях со слегка разными наборами признаков.
Такой метод смешивания результатов на подвыборках тренировочного набора называется bagging (bootstrap aggregation) и часто позволяет уменьшить разброс (variance), что улучшает результат. Также, обычно он хорошо работает для смешения результатов моделей градиентного бустинга (xgboost/lightGBM)
Модели основанные на градиентном бустинге, стабильно давали хуже результат (сравнимый с FM), попарная оптимизация ненамного улучшала картину. Также не сработала для меня генерация признаков для FFM на основании листьев деревьев от бустинга. Стек FFM → FFM или XGBOOST → FFM был стабильно хуже чем FFM на всем наборе данных.
Финальные результаты
Изначальное объединение файлов сделано при помощи Python, также я обычно использую Jupyter для целей исследования данных и анализа. Также отфильтровал клик-лог только для пользователей встречающихся в тренировочном\тестовом наборах, что позволило уменьшить его с 80 до 10GB.
Изначальный Feature engineering также был написан на Python, однако, учитывая огромное количество данных, а значит время необходимое на их обработку, я быстро перешел на Scala. Разница в скорости по примерной оценке составила около 40 раз.
Для быстрого итерирования и оценки улучшения точности, я использовал подмножество данных, примерно 1/10 от общего объема.
Это позволило получать результат примерно через 5-10 минут после запуска + модели помещались в памяти ноутбука.
Генерирование входных файлов для финальной модели занимает около 3х часов на 6-ти ядерной машине. Общий объем записанных файлов > 500GB. Примерное время обучения и предсказания составляло 10-12 часов, использование памяти — около 120GB.
Весь процесс автоматизирован при помощи скриптов.
БОльшая часть работы была проведена на ноутбуке Dell Alienware (32GB RAM). Последние несколько недель я также использовал рабочую станцию (i7-6800, 128GB RAM) и в последнюю неделю memory optimized x4large и x8large AWS машины, до 2х параллельно.
Статья посвящается моей дорогой жене, которой очень непросто переживать время когда муж находится дома, но в тоже время его нет.
Также спасибо Артему Заика за комментарии и рецензию.
С моей точки зрения, участие в соревнованиях на Kaggle и подобных это отличный способ ознакомится со способами решения реальных проблем используя реальные данные и оценивая свои решения против реальных конкурентов. Выступление на высоком уровне также часто требует выделения большого количества времени и сил, особенно с работой в полный день и личную жизнь никто не отменял, так что подобные соревнования можно рассматривать как соревнования также с самим собой — победить в первую очередь себя.
Для понимания материала желательны знания о машинном обучении, но не обязательны.
О себе — работаю в роли Data Scientist / Software Engineer в captify.co.uk. Это второе серьезное соревнование на Kaggle, предыдущий результат 24/2125, также соло. Машинным обучением занимаюсь около 5ти лет, программированием — 12. Linkedin profile.
О машинном обучении и платформе Kaggle
Основной задачей машинного обучения, является построение моделей, способных предсказывать результат на основе входных данных, отличающихся от обозреваемых ранее. Например, мы хотим предсказывать стоимость акций конкретной компании через заданное время, учитывая текущую стоимость, динамику рынка и финансовые новости.
Здесь будущая стоимость акций будет предсказанием, а текущая стоимость, динамика и новости — входными данными.
Kaggle это прежде всего платформа для проведения соревнований по анализу данных и машинному обучению. Спектр задач абсолютно разный — классификация китов на виды, идентификация раковых опухолей, оценка стоимости недвижимости и тд. Компания организатор формирует проблему, предоставляет данные и спонсирует призовой фонд. На момент написания статьи активны 3 соревнования, общий призовой фонд 1.25M $ — список активных соревнований.
Мое последнее соревнование — Outbrain click prediction, задача — предсказать какую рекламу нажмет пользователь из показанных ему. Спонсор соревнования — компания Outbrain занимается промоушном различного контента, например блогов или новостей. Они размещают свои рекламные блоки на множестве разных ресуров, включая cnn.com, washingtonpost.com и другие. Так как компания которая получает деньги за клики пользователей, они заинтересованы показывать пользователям потенциально интересный им контент.
Формальное описание задачи — необходимо расположить показанную пользователю рекламу в данном блоке в ниспадающем порядке по вероятности нажатия на рекламу.
Количество предоставленных данных достаточно большое, например clicklog файл в районе 80ГБ. Точное описание входных данных можно получить на странице соревнования.
Предоставленные данные делятся на 2 части — те для которых участникам известно какой баннер нажмет пользователь (тренировочные данные), и данные для которых результат нужно предсказать — тестовые. При этом, Kaggle знает реальные результаты для тестовых данных.
Участники соревнования используют тренировочные данные для построения моделей, которые предсказывают результат для тестовых данных. В конце, эти предсказания загружаются обратно, где платформа, зная реальные результаты, показывает точность предсказаний.
Общий план участия в соревнованиях
- Анализ задачи и доступных данных
- Поиск и изучение возможных вариантов решения
- Разработка локального механизма оценки точности
- Генерирование признаков (features) для модели
- Имплементация (если нет готового алгоритма) + построение модели
- Оценка точности
- Итерирование пунктов 4 — 6, добавление новых моделей (бОльшая часть времени)
- Ансамбль и стек моделей (опционально)
- Объединение в команды (опционально)
Начало работы
Входные данные
Прежде всего, стоит разобраться с данными, которые доступны участникам соревнования. На странице Data как правило, есть описание структуры и семантики, а на странице Правил соревнования — описание, можно ли использовать внешние источники данных, и если да — стоит ли делится ими с остальными.
Первое что я обычно делаю — выкачиваю все данные и разбираюсь в структуре, зависимостях, с тем как они отвечают постановке задачи. Для этих целей удобно использовать Jupyter + Python. Строим различные графики, статистические метрики, смотрим на распределения данных — делаем все что поможет понять данные.
Например, построим распределение количества реклам в одном рекламном блоке:
Также, на Kaggle есть раздел Kernels, где код можно выполнять прямо в их ноутбуках и обычно находятся ребята, которые делают различные визуализации доступного датасета — так мы начинаем пользоваться чужими идеями.
Если есть вопросы к структуре, зависимостям или значениям данных — ответ можно поискать на форуме, а можно попробовать догадаться самому и получить преимущество над теми кто (еще) не догадался.
Также, часто в данных есть Утечки (Leaks) — зависимости, например временные, которые позволяют понять значение целевой переменной (предсказание) для подмножества поставленных задач.
Например, в Outbrain click prediction, из данных в клик-логе можно было понять что пользователь нажал на определенную рекламу. Информация о таких утечках может публиковаться на форуме, а может и использоваться участниками без огласки.
Анализ подходов к решению задачи
Когда с постановкой задачи и входными данными в целом все ясно, я начинаю сбор информации — чтение книг, изучение похожих соревнований, научных публикаций. Это замечательный период соревнования, когда удается в очень сжатые временные сроки, значительно расширить свои знания в решении задач подобных поставленной.
Изучая подобные соревнования, я пересматриваю его форум, где победители как правило описывают свои подходы + изучаю исходный код решений который доступен.
Чтение публикаций знакомит с лучшими на сейчас результатами и подходами. Тоже отлично когда можно найти изначальный или воссозданный исходный код.
Например, два последних соревнования по Click-Prediction, были выиграны одной и той же командой. Описание их решений + исходные коды + чтение форумов этих соревнований примерно дали представление о направлении с которого можно начинать работу.
Первый код
Контроль версий
Я всегда начинаю с инициализации репозитория контроля версий. Потерять важные куски кода можно даже в самом начале, очень неприятно его потом восстанавливать. Обычно использую Git + Bitbucket (бесплатные приватные репозитории)
Локальная (кросс) валидация
Валидация, или тестирование предсказаний, это оценка их точности на основании выбранной метрики.
Например, в Outbrain click prediction нужно предсказать, на какую рекламу из показанных нажмет пользователь. Предоставленные данные делятся на две части:
| Тип данных |
ID нажатой рекламы для каждого показа |
| Тренировочные |
Известно всем |
| Тестовые |
Известно только организаторам соревнования |
Обучения моделей происходит на тренировочных данных, в надежде что точность на тестовых данных также улучшится, при этом предполагается что тестовые и тренировочные данные взяты из одной выборки.
В процессе обучения, часто происходит момент, когда точность относительно тренировочных данных растет, но относительно тестовых — начинает падать. Так происходит потому что мощность (Capacity) модели позволяет запомнить или подстроится под тестовый набор.
Это явление называется переобучение (overfit), как с ним бороться мы поговорим ниже, пока достаточно понять что проверять точность необходимо на данных, которые модель не видела.
Несмотря на то что Kaggle дает возможность оценить точность решения (относительно тестовых данных) загрузив его на сайт, такой подход оценки имеет ряд недостатков:
- Ограничение на количество загрузок решений в день. Часто 2-5
- Latency этого подхода — подсчет решений для тестового набора, запись в файл, загрузка файла
- Нетривиальность автоматизации
- Вероятность переобучения относительно тестовых данных
Хорошо бы иметь локальную систему оценки точности, что позволит:
- Быстро оценивать точность на основании выбранных метрик
- Автоматизировать перебор алгоритмов и/или гиперпараметров
- Сохранять результаты оценки вместе с другой информацией для последующего анализа
- Исключить переобучение относительно тестовой выборки
Для этих целей отлично подойдет локальная (кросс) валидация. Идея проста — разделим тренировочный набор на тренировочный и валидационный и будем использовать валидационный для оценки точности, сравнения алгоритмов, но не для обучения.
Методов валидации есть много, также как и способов разделения данных, важно соблюдать несколько простых правил:
- Разделение не должно изменяться во времени чтобы исключить влияние на результат. Для этого например, можно сохранить отдельно валидационный и тренировочный наборы, сохранить индексы строк или использовать стандартный random.seed
- Если у Вас есть признаки (features) которые строятся на всем наборе данных — например частота нажатий на конкретную рекламу в зависимости от времени, такие признаки должны быть подсчитаны только используя тренировочный набор, но не валидационный, таким образом, знание об ответе не будет «перетекать» в модель
- Если данные расположены в зависимости от времени — например в тестовом наборе будут данные из будущего, относительно тренировочного набора, необходимо соблюдать такое-же распределение и в разделении тренировочного/валидационного множества
Проверить адекватность локальной валидации можно сравнив улучшение показанное локально с реальным улучшением, полученным после загрузки решения на Kaggle. Хорошо, когда изменения в локальной оценке дают представление о реальном улучшении.
Строим модели
Введение
Модель можно представить как черный ящик или функцию, которая на входе получает данные и возвращает результат. Результаты могут быть разного типа, наиболее часто используемые:
| Тип модели |
Тип возвращаемого результата |
Пример |
| Регрессия |
Вещественное число |
Стоимость акции компании N через 1 минуту |
| Классификация |
Категория |
Платежеспособный / Неплатежеспособный заемщик |
В Outbrain competition необходимо было ранжировать рекламу по вероятности нажатия пользователем на нее. Простой и действенный способ добится этого — использовать задачу классификации, предсказывать вероятность нажатия, и сортировать рекламу в блоке по выданным классификатором вероятностям:
Предсказания классификатора:
| DisplayId |
AdId |
ClickProb |
| 5 |
55 |
0.001 |
| 5 |
56 |
0.03 |
| 5 |
57 |
0.05 |
| 5 |
58 |
0.002 |
Формат, в котором принимаются решения задачи:
| DisplayId |
AdIds |
| 5 |
57 56 58 55 |
Оценочная метрика (evaluation metric) — функция, показывающая насколько точно предсказание соответствует реальным данным. Для каждого типа задачи, существует много метрик — например для регрессии часто используется основанная на разнице квадратов значений. В соревновании использовалась MEAP (Mean Average Precision) — метрика учитывающая не только количество правильных ответов, но и разницу в порядке сортировки.
Входные параметры
Рассмотрим простейший алгоритм, когда мы считаем что скорее всего, пользователь нажмет на наиболее популярную рекламу — ту у которой соотношение количество нажатий / просмотров (Click-through Rate — CTR) максимальное. В данном случае, входными параметрами в модель у нас есть 2 значения — id рекламы и была ли реклама нажата. Особого машинного обучения здесь нет, обычная статистическая метрика.
Допустим, это наши тренировочные данные, пусть под displayId мы группируем рекламы, показанные одному пользователю в одном блоке:
| displayId |
adId |
clicked |
| 1 |
1 |
0 |
| 1 |
2 |
1 |
| 2 |
1 |
1 |
| 2 |
3 |
0 |
Для формирования первого признака используем формулу adClicked = max adId sum(adId, clicked == 1) / sum(adId)
Входные значения удобно представлять в виде вектора для одного случая (часто называется feature vector), и матрицы для всего набора данных — обозначается X. Целевая переменная (в нашем случае Clicked) — y
| displayId |
adId |
feature_1 |
| 1 |
1 |
0.5 |
| 1 |
2 |
1 |
| 2 |
1 |
0.5 |
| 2 |
3 |
0 |
Теперь, при формировании ответа, для каждого displayId, мы сортируем показанные рекламы по feature_1 и получим ответ в виде:
display_id,ad_id
1,2 1
2,1 3
Первое что нужно сделать, это проверить точность работы модели используя уже разработанный нами механизм валидации. Модель основанная на частоте со сглаживанием возвращает результат значительно лучше случайных предсказаний:
| Model name |
Result |
| Random guess |
0.47793 |
| Frequency with smoothing |
0.63380 |
Можно расширить модель, и считать CTR исходя также из региона пользователя, а статистику считать для всех встречаемых комбинаций adId * country * state:
| adId |
Country |
State |
clicked |
| 1 |
US |
CA |
0 |
| 2 |
US |
TX |
1 |
| 1 |
UK |
1 |
1 |
adClicked = max adId sum(adId, clicked == 1, country==displayCountry, state==displayState) / sum(adId)
Важно строить признаки для обучения только из тренировочного набора данных, исключая валидационный и тестовый наборы, иначе мы не сможем адекватно оценить точность работы модели. Если используется k-fold cross validation — строить такие признаки придется k раз.
Другой подход — генерировать признаки таким образом, чтобы уменьшить переобучение модели. Например, я добавлял статистики по частоте нажатий только для тех реклам, где количество просмотров N > 10 (значение подбирается во время валидации). Мотивация — если добавляем частоты где количество просмотров рекламы == 1, алгоритм с достаточной сложностью (например дерево решений) определит возможность этого признака однозначно предсказать ответ и может использовать только ее для предсказания, при этом понятно, что решение это будет достаточно наивным.
Весь процесс генерирования признаков из входных данных часто называется Feature Engineering, и часто является решающим фактором успешного соревнования, так как алгоритмы и мета-алгоритмы обучения моделей как правило общедоступны.
Outbrain competition features
Я рассматривал несколько общих групп признаков, определяющих:
- Пользователя — того кому показывается реклама
- Рекламодателя
- Контекст + Время
Рассмотрим каждую группу подробнее:
Пользовательские признаки
Используя тренировочный набор данных и лог просмотров страниц, можно выбрать много интересного о пользователе — какие рекламы\рекламные кампании нажимал а какие всегда игнорировал. Так как были предоставлена метаинформация о страницах на которую ведет реклама (landing page) можно выявить какие категории страниц или темы\сущности пользователю интересны — если landing page это sport.cnn, и пользователь читает новости спорта часто в это время дня или в этот день недели, это можно попробовать использовать как признак.
Такие и подобные признаки помогут позже найти пользователей с похожими предпочтениями и через них предсказать — нажмет ли пользователь на рекламу.
Отбор признаков я делал вручную — исходя из изменения точности оценки до\после добавления.
Признаки рекламодателя
Здесь стоит начать с простого перечисления мета-информации о рекламе/landing-page|рекламной кампании + CTR подобные признаки исходя из гео-локации, времени дня, дня недели — например stateCTRCamp: частота нажатий на рекламную кампанию (объединяет рекламы) в каком-то штате
Контекст
Под контекстом я понимаю как страницу на которой отображается реклама так и время показа + информация о пользователе: гео + тип устройства. Зная время, можно перечислить все рекламы и страницы, которые пользователь посетил\нажимал вчера\позавчера\за последний час. Можно определить контент, популярный на данный момент и тд.
Использованные признаки
country, state, platform, county, pageDocumentCategories, countryCTRAdv, campaignId, advertiserId, userDocsSeenFromLogYesterday, userClickedThisAdvertiserTimes, hourOfDay, userDocsClickedToday, lastAdvUserClicked
Общее количество признаков — около 120, абсолютное большинство — разработанные вручную, например userDocsSeenFromLogYesterday — документы из клик лога просмотренные пользователем вчера (относительно целевого показа рекламы). более расширенный (неполный) список в техническом описании решения на форуме соревнования.
Большинство из использованных признаков категоризационные — например country, и для превращения в бинарный признак используется one-hot-encoding. Некоторые числовые признаки также были превращены в бинарные посредством отнесениях к числовому интервалу, для сглаживания некоторых использовалась формула log(x+1).
Закодированные признаки, встречающиеся менее 10 раз, не учитывались. Общее число кодированных признаков > 5M, хеширование для уменьшения размерности не применялось.
Пример простейшей модели — логистическая регрессия
Построим модель логистической регрессии, которая получает на вход простые числовые признаки — частоту нажатий в стране и штате:
countryAdCTR = sum(adId, clicked == 1, country == displayCountry) / sum(adId)
stateAdCTR = sum(adId, clicked == 1, state == displayState) / sum(adId)
Формула вероятности нажатия на рекламу будет:
y* = f(z), z = w1 * countryAdCTR + w2 * stateAdCTR, f(z) = 1 / (1 + e(-z))
f(z) — логистическая функция, возвращает значения в интервале [0:1]. Алгоритм обучения подбирает коэффициенты w1 и w2 таким образом, чтобы уменьшить разницу между y* и y — т.е. добится максимальной схожести предсказаний и реальных значений.
Добавим категаризационные признаки advertiser и view_page_domain в модель, предварительно конвертировав их в бинарные при помощи метода one-hot-encoding, пример:
Categorical:
| Sample |
Advertiser |
| 1 |
Adidas |
| 2 |
Nike |
| 3 |
BMW |
One-hot-encoded:
| Sample |
IsAdidas |
IsNike |
IsBMW |
| 1 |
1 |
0 |
0 |
| 2 |
0 |
1 |
0 |
| 3 |
0 |
0 |
1 |
Формула будет:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3*advertiser + w4*view_page_domain
Так как advertiser и view_page это вектор, то и w3 и w4 тоже будут векторами
В CTR prediction очень важно учитывать взаимодействия признаков например страница на которой показывается реклама и advertiser — вероятность нажать на рекламу Gucci на страницу Vogue совершенно другая чем на рекламу Adidas., модель можно дополнить взаимодействием между advertiser и view_page:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3*advertiser + w4*view_page_domain + w5*advertiser*view_page_domain
Мы уже знаем что advertiser и view_page это вектора, а значит размерность вектора w5 будет длина вектора advertiser * длина вектора view_page.
С этим связанно несколько проблем — во первый, это будет очень большой вектор — все возможные домены, на которых показывается реклама умноженные на количество всех возможных рекламодателей. Во вторых — он будет очень разреженным (sparse) и большинство значений никогда не примут значение 1 — большинство комбинаций мы никогда не встретим в реальной жизни.
Factorization Machines (FM)
FM прекрасно подходят для задач предсказания CTR, так как явно учитывают взаимодействие признаков, при этом решая проблему разреженности данных. Прекрасное описание можно найти в изначальной публикации, здесь я опишу основную идею — каждое значение признака получает целочисленный вектор длины k, а результат взаимодействия признаков — скалярное произведение (dot-product) векторов — формулу смотрите в публикации в разделе Model Equation.
Outbrain competition model
Field-aware Factorization Machines (FFM)
Во время анализа лучших моделей я обнаружил что последние 2 соревнования по CTR prediction выигрывали ребята с моделью (ансамблем) Field-aware Factorization Machines (FFM). Это продолжение FM, но теперь признаки делятся на n fields — своего рода группы признаков, как например группа признаков состоящая из документов просмотренных ранее, группа других рекламных объявлений в этом рекламном блоке и тд. Теперь каждый признак представлен в виде n векторов размерностью k — имеет разное представление в каждой другой группе признаков, что позволяет более точно учитывать взаимодействие между группами признаков. Описание и детали также смотрите в публикации.
Обучение FFM
FFM очень подвержены переобучению, для борьбы с этим используется ранняя остановка — после каждой итерации улучшения модели, происходит оценка точности на валидационном наборе. Если точность падает — обучение прекращается. Я внес несколько изменений в код стандартной библиотеки, главное из которых — добавил оценка качества на основании метрики MEAP которая использовалась для подсчета результата на Kaggle, вместо стандартной logloss.
Одна из команд, которая заняла место в топ-3 также добавила возможность попарной оптимизации в FFM.
Для возможности ранней остановки при обучении целой модели, я делил случайным образом тренировочный набор в распределении 95/5 и использовал 5% как валидационный.
Финальный результат это простое средние результатов работы 5 моделей на разных случайных распределениях со слегка разными наборами признаков.
Такой метод смешивания результатов на подвыборках тренировочного набора называется bagging (bootstrap aggregation) и часто позволяет уменьшить разброс (variance), что улучшает результат. Также, обычно он хорошо работает для смешения результатов моделей градиентного бустинга (xgboost/lightGBM)
Что не сработало
Модели основанные на градиентном бустинге, стабильно давали хуже результат (сравнимый с FM), попарная оптимизация ненамного улучшала картину. Также не сработала для меня генерация признаков для FFM на основании листьев деревьев от бустинга. Стек FFM → FFM или XGBOOST → FFM был стабильно хуже чем FFM на всем наборе данных.
| Model name |
Result |
| My best single model result |
0.69665 |
| My best result (mix of 5 models) |
0.69778 |
| 1st place best result |
0.70145 |
Финальные результаты
Код, инфраструктура и железо
Код
Изначальное объединение файлов сделано при помощи Python, также я обычно использую Jupyter для целей исследования данных и анализа. Также отфильтровал клик-лог только для пользователей встречающихся в тренировочном\тестовом наборах, что позволило уменьшить его с 80 до 10GB.
Изначальный Feature engineering также был написан на Python, однако, учитывая огромное количество данных, а значит время необходимое на их обработку, я быстро перешел на Scala. Разница в скорости по примерной оценке составила около 40 раз.
Для быстрого итерирования и оценки улучшения точности, я использовал подмножество данных, примерно 1/10 от общего объема.
Это позволило получать результат примерно через 5-10 минут после запуска + модели помещались в памяти ноутбука.
Генерирование входных файлов для финальной модели занимает около 3х часов на 6-ти ядерной машине. Общий объем записанных файлов > 500GB. Примерное время обучения и предсказания составляло 10-12 часов, использование памяти — около 120GB.
Весь процесс автоматизирован при помощи скриптов.
Железо
БОльшая часть работы была проведена на ноутбуке Dell Alienware (32GB RAM). Последние несколько недель я также использовал рабочую станцию (i7-6800, 128GB RAM) и в последнюю неделю memory optimized x4large и x8large AWS машины, до 2х параллельно.
Благодарность
Статья посвящается моей дорогой жене, которой очень непросто переживать время когда муж находится дома, но в тоже время его нет.
Также спасибо Артему Заика за комментарии и рецензию.
Заключение
С моей точки зрения, участие в соревнованиях на Kaggle и подобных это отличный способ ознакомится со способами решения реальных проблем используя реальные данные и оценивая свои решения против реальных конкурентов. Выступление на высоком уровне также часто требует выделения большого количества времени и сил, особенно с работой в полный день и личную жизнь никто не отменял, так что подобные соревнования можно рассматривать как соревнования также с самим собой — победить в первую очередь себя.
