Comments 98
Условие выхода в for некорректно, запятая это не && и, если побед в массиве нет, цикл не остановится никогда.
Добавил ссылки на описание с документации express.js, laravel, а так же на свое приблизительно объяснение.
Просто у термина middleware есть и другое, значительно более широко известное употребление, когда этим словом называют нечно (сервер или сервис), между backend и frontend, базой и web, ну и так далее. И там это не паттерн вообще.
Под паттерном я тут понимаю не паттерн проектирования, а просто какой-то повторяющийся кусок кода/повторяющаяся сигнатура. В данном случае под middleware я понимаю что-то вроде обертки, которая принимает функцию и возвращает новую с такой же сигнатурой, но с дополнительной логикой.
>обертки, которая принимает функцию и возвращает новую с такой же сигнатурой, но с дополнительной логикой.
Это просто функция высшего порядка, ничего больше. Как правило — просто композиция. И для этого тоже есть готовая куча терминов, уже, как правило из теории категорий.
Это просто функция высшего порядка, ничего больше.
Это один из видов функций высшего порядка. Отличительная от остальных особенностей — принимается параметром функция и возвращается функция с той же сигнатурой, как правило с вызовом параметра внутри.
А то определение, что вы написали — это и есть формулировка термина «функция высшего порядка». Один в один.
Функция высшего порядка может принимать на вход функции, а может не принимать, может возвращать функцию, а может не возвращать. Достаточно чего-то одного.
На входе всегда один редьсер. А вот с помощью операции композиции функций (не трандьюсеров) мы можем скомбинировать несколько, но мы можем сделать это и без нее по цеопчке t3(t2(t1(r)))
Очевидно, что Решение №2 следует записать в виде:
const result =
scores
.filter(({ my, others }) => my > others) // выбираем выигрышные
.slice(0, 2) // берем первые два
.map(({ gameID }) => gameID) // получаем их номер
чтобы убрать «лишний» полный проход для получения gameID.
</zanuda_mode>
А вот можно по-подробнее? Если сделать сперва .slice(0, 2), то мы получим первые две игры независимо от того, выигранные они или нет.
const result =
scores
.filter(({ my, others }) => my > others)
.map(({ gameID }) => gameID)
.slice(0, 2)
Если поменять местами map и slice, выигрыш будет. Но это все равно не самый оптимальный вариант. Реализация на базе композиции функций, описанная в статье, переберет лишь необходимое количество элементов.
const result = transduce(compose(
filter(({ my, others }) => my > others),
map(({ gameID }) => gameID),
take(2)
), append, [], scores)
Чисто внешне код отличается не сильно.
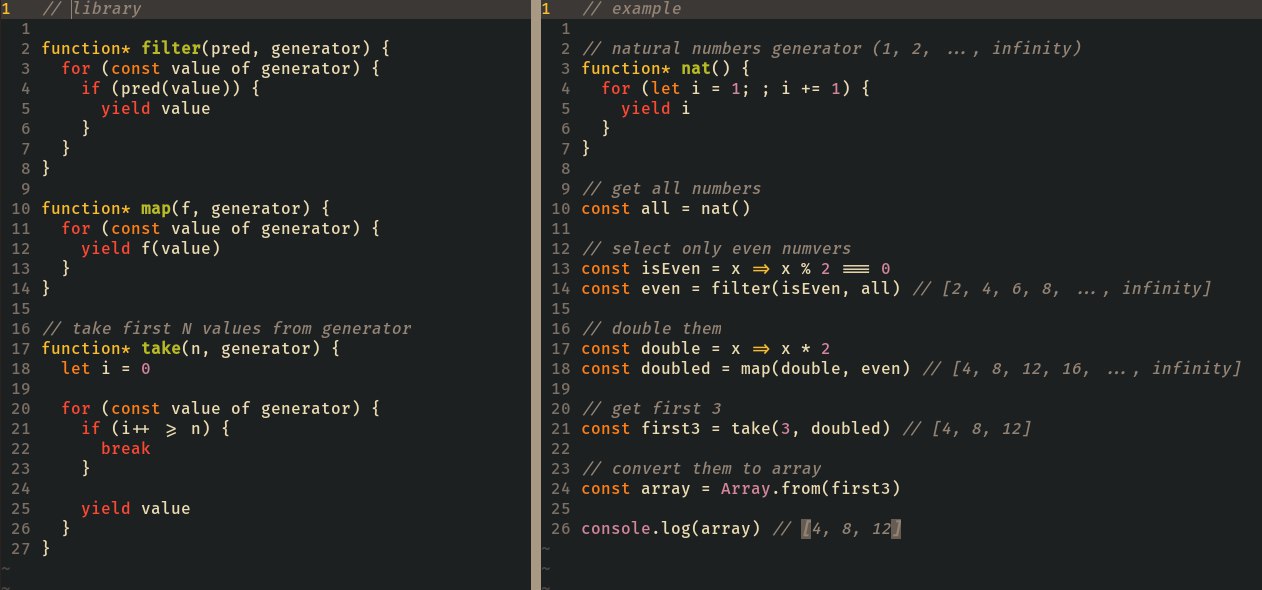
Да, так и есть. Я довольно долго работал с ленивыми коллекциями и генераторами, в результате чего привык сначала делать все операции (зачастую над бесконечным списком), а после чего брать нужное количество результатов.
Ещё бы. Если переписать это на Хаскеле (ленивость же!) — внезапно окажется, что тут фигурирует единственный тип сущностей: функция, делающая из одного ленивого списка другой. И генераторы — наиболее понятный аналог в некоторых языках...
Собственно, я переписывал это на хаскеле, но без нормальной реализации take.

Ужас какой. По моим представлениям — должно быть в точности решение 2.
Из-за ленивости на хаскеле действительно эти трансдьсеры не нужны (если не нужно переиспользовать трансформации) и на js такое действительно можно написать только через генераторы, вы правы.
x |> f = f x
main =
[1..]
|> filter even
|> map (* 2)
|> take 3
|> print -- [4, 8, 12]Несколько недель назад я такое тоже писал:
Касательно всех остальных решений – вполне согласем с вашим мнением
Увеличение уровня абстракции в данном случае помогает использовать трансдьюсеры со всеми сворачиваемыми типами (массивы, стримы в rxjs, множества, словари) независимо от того, реализовали ли они функции map/filter/take. Чисто теоретически, если бы трансдьюсеры бы встроили в js, то из всех библиотек типа rxjs/xstream все эти трансформации можно было бы выпилить, оставив только reduce, потому что универсальные трансдьюсеры будут работать однообразно везде.
В смысле зачем map reduce и другие в принципе? Так чтобы эти тупые циклы не писать. Они ведь написаны уже, пора кинуть их на свалку и не писать велосипед в каждом файле по нескольку раз. Плюс целиком эта функциональная конструкция получается более надежной, т. к. количество if/else меньше то меньше вероятность сделать ошибку.
К слову со своей колокольни: в scala можно у коллекций вызвать метод view — вернётся обёртка над коллекцией и операции типа map, filter и т.п. начнут работать лениво.
scores
.view // благодаря этой строчке появляется "ленивость"
.filter(x => x.my > x.others) // выбираем выигрышные
.map(_.gameId) // получаем их номер
.take(2) // берем первые двапричём результат — тоже view, "содержащий" 2 элемента и вычисляющий их в самый последний момент.
Возможно, Ваше решение тоже можно так реализовать, чтобы остальной код выглядел по-прежнему.
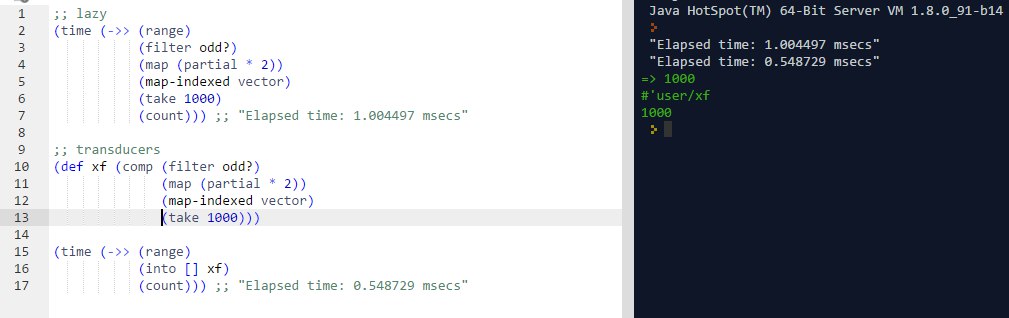
Да, можно, в js тоже есть библиотеки с ленивыми коллекциями, а в clojure все трансформации по умолчанию ленивы (но при этом ленивые трансформации проигрывают по скорости трансдьюсерам.
Но работа с трансформациями как с объектом первого класса — фишка трансдьюсеров, которая позволяет
а) переиспользовать их
б) использовать одни и те же трансдьсеры для любых типов данных, которые поддерживают свертки (Foldable), скажем, стримы в rxjs (те же самые трансдьюсеры будут прекрасно работать и там), а значит из этих библиотек можно было бы спокойно выпилить все трансформации, если бы трансдьюсеры были бы нативными и общеиспользуемыми (маловероятное будущее, но в clojure стремятся к этому)
scores
.Where(score => score.my > score.others)
.Select(score => score.gameID)
.Take(2);
_(scores)
.filter(({ my, others }) => my > others) // выбираем выигрышные
.map(({ gameID }) => gameID) // получаем их номер
.take(2)
.value()
Но главное, ваш пример выглядит так будто вы очень простой(чем проще – тем надежнее) и короткий код (пусть даже не оптимальный, хотя lodash это исправляет) который работает, заменили на какой-то «матан», который в придачу еще и длинее. Зачем?
Как я уже сказал, писать все эти трансдьюсеры с нуля не придется. Почти во всех своих проектах я использую ramda (как аналог lodash, только функциональный), который уже имеет реализацию трансдьюсеров (пример в статье есть). Мало того, трансдьюсеры — паттерн намного проще, чем ленивые вычисления (в lodash). Да и и сама ramda намного проще и немагичнее, чем lodash. Так же трансдьюсеры позволяют переиспользовать код, потому что позволяют работать с трансформациями как с объектом первого класса, а потом применять их.
Еще важно то, что трансдьюсеры работают где угодно, где есть reduce, то есть эти трансьдеюсеры будут работать что с lodash, что с ramda, что со стримами (при условии конечно, что они не зависят от реализации reduce, как функция take). Из этого следует вывод, что всякие xstream/rxjs можно было упросить, убрав оттуда filter/map/прочее и оставив только reduce.
Матана в трансдьюсерах нет, в статью я хотел вложить смысл, что это очень простой паттерн, который позволяет добится большой эффективности.
Ну и для сравнения с циклами: читать цепочку трансформация (будь то просто Array#map, или трансдьюсеры) проще, чем циклы с внутренней логикой, так как это декларативно.
>паттерн намного проще, чем ленивые вычисления (в lodash)
вас же не просят их имплементировать
>Да и и сама ramda намного проще и немагичнее, чем lodash
ни чем не обоснованое утверждение
>трансдьюсеры работают где угодно
это круто, но зачем? единственное здравое объяснение, которое приходит в голову – тестирование. Но это не проблема
>убрав оттуда filter/map/прочее и оставив только reduce.
я либо что-то не понимаю – либо вы что-то не договариваете.
возьмем простой кусок
const H = require('highland')
H(process.stdin)
.map(x => 'something' + b)
.pipe(process.stdout)
из вашего утверждения выходит что я .map(и любые другие преобразования) могу выразить через .reduce, но ведь .reduce возраващает нам результа когда «пройдет» по всей коллекции – а тут конца коллекции как бы нет.
Я не поленился и проверил:
const H = require('highland')
const xf = require('transducers-js').map(H.add('b'));
H(process.stdin)
.transduce(xf)
.pipe(process.stdout)
И что интересно – он работает абсолютно аналогично первому варианту. Я что-то не понимаю про reduce или вы плохо объяснили?
И самое главное: вы так и не объяснили – зачем все это? вы говорите: простой паттерн, который позволяет добится большой эффективности. Обоснуйте это утверждение,
пока что как в вашем примере так и в моем – мы эффективно увеличили количество строк кода и количество зависимостей
вас же не просят их имплементировать
они в понимании проще, чем ленивые коллекции, ведь это просто вызов функций по цепочке. Или вы к тому, что не обязательно понимать то, что используешь?
ни чем не обоснованое утверждение
да, это субъективное мнение после чтения исходного кода обеих библиотек
это круто, но зачем? единственное здравое объяснение, которое приходит в голову – тестирование. Но это не проблема
уменьшение повторения кода?
Про последний пункт насчет того, зачем это нужно: трансдьсеры частично решают ту же проблему, что и ленивые коллекции в lodash. Но решение через трансдьюсеры проще хотя бы потому, что тут больше нет довольно сложных ленивых коллекций, нет лишний преобразований с _ и value, нет методов, только функции, и это самый обычный reduce. Вроде как обосновал, нет? (простой паттерн — ведь это просто последовательное выполнение функций, большая эффективность — не выполняются лишние трансформации).
Ramda:
const result = into([], compose(
filter(({ my, others }) => my > others),
pluck("gameID"),
take(2),
), scores)Lodash:
_(scores)
.filter(({ my, others }) => my > others)
.map("gameID")
.take(2)
.value()Да, обычный цикл конечно проще, но обычный цикл еще и мутабелен, и императивен, ну а (субъективно) читать императивный код сложнее, чем декларативный.
Я мало что знаю про highload, но в xstream свертка вместо возвращения значение при завершении стрим возвращает новый, состоящий из результатов сверток после каждого элемента, то есть
------1-----1--2----1----1------
fold((acc, x) => acc + x, 3)
3-----4-----5--7----8----9------const map = fn => next => (acc, x) => next(acc, fn(x))
const filter = pred => next => (acc, x) => pred(x) ? next(acc, x) : acc
const compose = (f, g) => x => f(g(x))
const append = (arr, x) => arr.concat([x])
const isOdd = x => x % 2 === 1
const inc = x => x + 1
const double = x => x * 2
const xs = xstream.default
const button = document.querySelector("button")
const clicks$ = xs.create({
start(listener) {
button.addEventListener("click", () => listener.next())
},
stop() {
button.removeEventListener("click", next)
}
}).fold(inc, 0)
const doubledOdds$ = clicks$.fold(compose(
filter(isOdd),
map(double),
)(append), [])
doubledOdds$.addListener({
next(x) { console.log(x) }
}) // [2, 6, 10, ...]Исключетельно чертой трансдьюсеров является то, что они ничего не знают о контексте. Они не знают, как добавлять элемент в конец массива, поэтому вместо этого они делегируют это на оборачиваемый ими редьюсер.
Пока писал это, понял, что я недостаточно компетентен в этой области. Все, что могу сделать — дать ссылку на статью про трансдьюсеры от Рича Хикки — их создателя — https://clojure.org/reference/transducers. Там же есть ссылка на пост в блоге и видео.
На правах изврата:
const win = ({ my, others }) => my > others
const firstResult = scores.findIndex(win)
const secondResult = firstResult + 1 + scores.slice(firstResult + 1).findIndex(win)В реальном проекте я бы конечно использовал первый или второй вариант.
function archaeological(arr, {filter, map, take}) {
let acc = 0,
res = []
for (let i = 0; i < arr.length; i++) {
if (filter(arr[i])) {acc += 1; res.push(map(arr[i]))}
if (take(acc)) return res
}
}
const result = archaeological(scores, {
filter({my, others}) {return my > others},
take(x) {return x == 2},
map({gameID, my}) {return {gameID, my}} })
Немного смутила постановка задачи.
Необходимо найти номера первых двух выигранных мною игр
Я сначала подумал что имеются ввиду первые две игры в хронологическом порядке, а в статье это любые две игры.
Так же смущает наличие поля id у записей, которое намекает на то, что порядок записей в массиве может не совпадать с их хронологическим порядком, что опять же имеет смысл при иной трактовке задачи.
const take = n => next => (acc, x) => {
if (n > 0) {
acc = next(acc, x)
n -= 1
}
if (n <= 0) {
acc = reduced(acc)
}
return acc
}
Кажется такая реализация `take` не композится сама с собой. Если вызвать `take(1)(take(1))`, то результат будет обернут в Reduced дважды.
Как реализовать пустое перечисление, которое не вернет ни одно элемента?
const eof = next => (acc, x) => {
???
}
Работать со значением в самом трансдьюсере тоже становится не просто:
const last = next => (acc, x) => reduced(x);
const inc = next => (acc, x) => {
acc = next(acc, x);
// return acc + 1;
return acc instanceof Reduced ? reduced(acc.value + 1) : acc;
});
inc(last);Можно-ли как-то иначе реализовать протокол для трансдьюсеров, чтобы таких проблем не возникало?
Как реализовать пустое перечисление, которое не вернет ни одно элемента?
Нужно просто возвращать acc. reduce требует начальное состояние, именно ого и вернётся для пустого перечисления. При отстуствии начального состояния он берет первый элемент и при пустом массиве Array#reduce кидает исключение.
Должен заметить, что в посте я привел простую реализацию, когда как реально все немного сложнее. Трансдьюсер — это кортеж из трех функций с разным числом аргументов (имена фунцкий образные):
- init — не принимает аргументов и должна вернуть начальное состояние. Зачастую просто вызывает next, то есть делегирует init на следуюущий трансдьюсер.
- step — это то, что в статье — два аргумента: аккумулятор и элемент, возвращает аккумулятор
- result — принимает один аргумент — аккумулятор, срабатывает после завершения reduce.
Кажется такая реализацияtakeне композится сама с собой. Если вызватьtake(1)(take(1)), то результат будет обернут в Reduced дважды.
Да, это действительно так, спасибо за замечание. Кложурная версия вместо reduced использует ensure-reduced, которая работает как identity, если значение уже обернуто. Исправлю.
Работать со значением в самом трансдьюсере тоже становится не просто:
Да, это действительно проблема. Но проблема скорее в моей реализации функции reduce, можно попробовать придумать другой способ завершать её выполнение, но у меня идей нет. Можно сделать Reduced каким-нибудь прокси.
На более сложных и однотипных задачах оно может и прокатит. Но на примере из статьи — это маразм :)
Хотя бы укажите в самой статье, что не стоит использать все это чтобы просто выбрать два элемента из массива.
а) писать всё это не придется, все это уже реализовано в библиотеках для работы с данными (ramda, clojure.core)
б) использовать императивные циклы я в принципе не считаю хорошей идей, а трансдьюсеры будут намного быстрее, чем .map/.fiter на массивах с большим количеством данных. Ленивые коллекции (как в хаскеле, кложе, lo-dash) или трандьюсеры тут лучший вариант.
Но естественно использовать это для мелких задач поиска по массиву в 10 элементов — оверхед.
использовать императивные циклы я в принципе не считаю хорошей идей
Не завидую я пользователям вашего ПО.
К счастью, на языках, на которых я пишу, циклов в принципе нет (Clojure, для развлечения Elm и Haskell)
К счастью на языках, на которых пишите вы, практически никто не пишет ничего серьёзного, а то вызов функции это всё же не очень дёшево, особенно в рамках JS. А если учитывать, что в простенький цикл добавляется ещё 3 бесполезных вызова функций, то всё получается совсем не радужно если масштабировать задачу до сотен тысяч итераций.
Мне, если честно и самому нравятся функциональные решения, но(!) нужно понимать, что твоим кодом в первую очередь будут пользоваться и только во вторую — поддерживать. В связи с этим стоит всё же заменять все эти map(), reduce(), filter() и прочее на циклы во всех случаях, кроме тех, где это серьёзно ударит по читаемости и возможности повторно использовать код. Нет, не везде, но в JS точно.
Простенький оптимизатор заинлайнит вызовы функций в цикле. И если функциональные решения улучшают читаемость, то надо ставить их, пока профайлер не скажет, что тормозит или вот-вот начнёт тормозить из-за них.
В связи с этим стоит всё же заменять все эти map(), reduce(), filter() и прочее на циклы во всех случаях, кроме тех ...
Может всё-таки строго наоборот? Писать понятный удобный код пока не упрёшься в производительность. А вот уже затем профилирование и оптимизация. И скорее всего там не замена .map на for ;; будет, а что-нибудь уровня организации кода.
К тому же не стоит забывать, что js это интерпретируемый язык, в котором за кадром происходит очень много "магии", и все эти callback-и легко могут за-inline-иться.
Правда назвать вот такой вот код:
const result = reduce(
// Последовательно трансформируем редьюсер, применяя наши функции к
// редьюсеру, создавая тем самым цепочку редьюсеров.
filterWins(mapGameID(firstTwo(appendToResult))),
[],
scores,
)Понятным и красивым у меня язык не поворачивается. Та изначальная for-простыня была куда нагляднее:
const result = [];
for(const { gameID, my, others } of scores)
if(result.length === 2)
break;
else if(my > others)
result.push(gameID);На мой взгляд JS в текущем виде с текущими тенденциями сильно не хватает |>-оператора. Все эти композиции функций с оборачиванием всего написанного до этого скобочками изрядно раздражают. Их, в большинстве случаев, ещё и "из глубины" читать надо, а не слева-направо и сверху-вниз.
Касательно производительности. Тут мне кажется стоило бы избегать return arr.concat(el) и return Object.assign(obj, {...}) в reducer-ах в пользу мутабельных вариантов, т.к. разница может быть более чем тысячекратной (проверял на object.assign в reduce-цикле). Таки JS пока не Haskell :)
Вот небольшой пример про 2600-кратное ускорение. Проверил его на свежей сборке хрома:
mutable: 8.73486328125ms
reduce: 19150.360107421875msconst keys = []; for(let i = 0; i < 100000; i += 10) keys.push(i);
console.time('mutable');
const obj1 = {};
for(let key of keys) obj1[key] = key;
console.timeEnd('mutable');
console.time('reduce');
const obj2 = keys.reduce((o, key) => Object.assign({}, o, </b> [key]: key }), {});
console.timeEnd('reduce');
Результат:
mutable: 3.034ms
reduce: 21646.400ms
Исправленный код, в котором исправлена «опечатка»:
const keys = []; for(let i = 0; i < 100000; i += 10) keys.push(i);
console.time('mutable');
const obj1 = {};
for(let key of keys) obj1[key] = key;
console.timeEnd('mutable');
console.time('reduce');
const obj2 = keys.reduce((o, key) => Object.assign(o || {}, { [key]: key }), {});
console.timeEnd('reduce');
Результат:
mutable: 3.084ms
reduce: 11.763ms
Ускорение всего лишь в 4 раза, поэтому можно не отказываться от Object.assign, если кому-то с ним удобнее/нагляднее.
Почему так получилось?
Вот эта строка:
Object.assign({}, o, { [key]: key })Исправлена на такую:
Object.assign(o || {}, { [key]: key })Из документации:
Метод Object.assign() копирует из исходных объектов в целевой объект
Поэтому хоть первый вариант тоже корректный, но он заставляет бесконечно клонировать объект «o» в новый пустой (каждый раз который увеличивается в размерах), вместо того, чтобы просто добавить новый ключ в уже существующий «o».
А почему вы решили, что там опечатка? В этом то суть была. Иммутабельность во имя бога иммутабельности. Аналог .concat, но для объектов. Правда я предполагаю, что concat должен быть таки оптимизированным и на деле мутировать объект (либо иметь хитрую структуру, позволяющую ему иметь часть данных общими в разных переменных), пусть хоть и за кадром, а вот с Object.assign такой фокус не прокатил.
Клонировать внутренний объект 10000 раз, только лишь для того, чтобы в результате забрать финальный клон — с трудом верю, что это именно то, что вы хотели сделать.
Именно это и делал ваш код (хотя ваш вариант с for делает другое).
Но если опечатки нет, и это действительно была ваша цель, то что-то вы не то делаете, к производительности js это ни как не относится, и речи про 2600-кратное ускорение тем более не идет.
с трудом верю, что это именно то, что вы хотели сделать
Я понимаю, но нет, именно это я и хотел сделать. Это был наглядный пример того, что иммутабельность во имя иммутабельности, с полным игнорированием здравого смыслапринципов работы с памятью, идея изначально обречённая. Такое ещё может прокатить, если язык изначально заточен под такие задачи и имеет под капотом хитроумные оптимизации (аля Haskell).
Примерно также я думаю и про return arr.concat(el) в reduce-ах. Это выглядит несколько дико, не находите? Но упорно в каждой первой статье про reduce и иже с ним я вижу такие куски кода.
Касательно производительности. Тут мне кажется стоило бы избегать return arr.concat(el) и return Object.assign(obj, {...}) в reducer-ах в пользу мутабельных вариантов, т.к. разница может быть более чем тысячекратной (проверял на object.assign в reduce-цикле). ...2600-кратное ускорение.
И вы приводите пример кода, который специально делает много лишней работы (раз вы говорите что это не опечатка).
Потом я привожу исправленный код, и выясняется, что никаких проблем с производительностью нет, Object.assign прекрасно работает в reduce-цикле без потери производительности.
Правильный выход — использовать персистентные структуры данных.
@kana-desu, Насколько я понимаю, их в JS пока нет. Скажем персистентный hash-map. Да даже set. А на уровне языка их не воссоздать.
Да, скажем, ClojureScript вполне спокойно реализовал всякие персистентные иммутабельные типы типа векторов, списков, хэш-мапов, множеств на js. Все это прогоняется через google closure compiler и реакт-приложения с иммутабельным стейтом на кложовских типах данных работает быстрее, чем react + redux на pure js-объектах.
Моя вина, ок. В процитированной вами цитате я хотел указать Object.assign({}, obj, т.к. речь вёл про true иммутабельность и ФП, но поторопился. Правда я думал, что это очевидно. Но судя по хейтеру набежавшему на мои комментарии (lol), таки не очевидно. Ок поясню мысль детальнее: в рамках ФП большое значение имеет immutable значения. Reduce в ФП предполагает проброс в него чистой функции. В рамках чистой функции Object.assign(obj... это грубейшая ошибка. Но в рамках здравого смысла это практически единственный допустимый вариант в циклах приличной длины.
… так бы я написала, если бы то что вы написали имело смысл.
Какая разница с точки зрения иммутабельности в коде:
Object.assign({}, o, [key]: key }) (медленный вариант)
Object.assign(o || {}, [key]: key }) (быстрый вариант)
Если в обоих случаях «o» это внутренний объект reduce?
Вот ответ:
Код в обоих случаях делает одно и тоже, с одинаковой степенью иммутабельности, никакой разницы нет, только один искусственно тормозной, а второй очень быстрый.
Еще говорят, что у меня женская логика…
Наверняка найдется тот, кто поймет ваши хитросплетения мыслей, но у меня на это банально нет желания.
Какая разница с точки зрения иммутабельности в коде
Разница исключительно в подходе. Баланс между разумностью и фанатичностью. Мы с вами говорим об одном и том же, но разными словами. Даже выводы одни и те же.
Мы с вами говорим об одном и том же, но разными словами. Даже выводы одни и те же.Ну да, получается мы об «одном и том же», я привожу данные что падения производительности нет, а вы утверждаете что в 2600 раз медленнее. Ну да, видно что вывод один в один.
Maiami, предлагаю продолжить в личку.
Особенно на фоне того, что, как выяснилось позже, вы осмысленно их пытались ввести в заблуждение.
При этом совет про «профилирование» вполне себе разумный.
Поясню, я имел, и имею ввиду ровно следующее: Object.assign({}, o, diff это медленно, очень медленно. И в цикле так поступать нельзя. Примерно та же ситуация с arr.concat(...items) (но тут допускаю наличие оптимизаций). Отсюда вывод, если возникает желание расширять объект в reduce, то лучше либо мутировать объект напрямую, либо через тот же Object.assign, но задав ему первым аргументом сам объект. Таким образом мы нарушаем принцип иммутабельности, но это разумный компромисс, в особенности, учитывая то, что за пределами цельного вызова reduce ни один объект не модифицируется. Насколько я знаю, примерно также себя ведёт монада St в Haskell. Это совпадает с вашими словами? Да.
Изначально я поторопился и совершил опечатку вот тут, о чём покаялся вот тут. И заодно попытался яснее выразить свою мысль. Но наткнулся лишь на переход личности, пассаж о женской логике и вообще какой-то нездравный напор. Заодно и игнорирование лички. Ну ок, чтож поделать. Это же интернеты.
Если даже после ^ ничего непонятно, то поясню совсем уж тезисно:
Object.assign({},в цикле ― плохоarr.concat(newEl)в цикле, вероятно, тоже плохоObject.assign(el, diff— нормально- точечная мутабельность в функциональном JS — приемлемый компромисс
Надоело смотреть на то, как никто не хочет отвечать за свои слова «ой, я не то имел ввиду, ой, меня не так поняли, ой я говорил про сферическое фп в вакуме».
К слову, в lodash один из моих любимых методов — _.transform, это примерно то же, что и reduce, но с явным уклоном на мутабельность. Не требуется return. В таком случае там было бы
.transform((o, key) => { o[key] = key; }, {})К тому же он поддерживает break (return false).
Я честно говоря так и не понял, чем это лучше Iterable, который гораздо понятней и для реализации поддержки в коллекции, и для построения полностью ленивых трансформаций поверх такой ленивой последовательности — в т.ч. reduce.
Другими словами, у вас в качестве базовой операции выступает reduce, а также целая обвязка вокруг неё. Чем такой подход лучше простого поэлементного прохода по коллекции как базовой операции? Какие случаи можно (или значительно проще) записать на трансдьюсерах, но нельзя (значительно сложнее) на итераторах? Пока что я вижу, что трансдьюсеры:
- требуют нетривиальную логику во вспомогательном коде
- требуют более нетривиальной работы с пробросом состояния в рекурсивной манере
- применяются к коллекциям точно также через обёртки
Или весь вопрос исключительно в получении функционального иммутабельного ленивого аналога итераторов без ленивых коллекций?
Все-таки редьюсер это не совсем итератор. Это свертка, и у него в сигнатуре есть элемент коллекции и нечто, куда мы сворачиваем. Т.е. для простоты, текущая сумма, к которой прибавляется очередной элемент. Чем это лучше простого прохода — видимо тем, что это все-таки не совсем простой проход?
Что касается остального, то кратко ответ нет, это не совсем так. Нетривиальной логики там нет никакой, как впрочем и состояния. Его и в reduce нет, вообще говоря. Редьюсер это чистая функция.
Обертки? Тоже скорее нет, чем да. Одна из целей как раз состоит в том, чтобы применять к любому источнику, как скажем коллекции, так и к стриму, т.е. абстрагировать редьюсер (и композицию из них) от источника данных.
>Или весь вопрос исключительно в получении функционального иммутабельного ленивого аналога итераторов без ленивых коллекций?
Вообще на моей памяти трансдьюсеры появились в кложе, и все-таки не совсем для этого. Другое дело что в javascript все может быть иначе.
Собственно, вот оригинальный анонс: http://blog.cognitect.com/blog/2014/8/6/transducers-are-coming
Ух, теперь-то у нас все быстро (один проход и ровно до тех пор, пока мы не получим нужное количество элементов), но красиво ли?
JS коварен, тут не все так быстро как хотелось бы. Все в одном фор цикле будет пожалуй быстрее.
На мой взгляд трансдьюсеры ака преобразователи как оптимизация, основаны на reduce и если вы понимаете что есть данный оператор и как он работает то вы поймете что такое преобразователь и как он работает.
const result = []
for (let i = 0; i < scores.length && result.length < 2; i++) {
const { gameID, my, others } = scores[i]
if (my > others) {
result.push(gameID)
}
}
class Reduced {
constructor(value) {
this.value = value
}
}
const isReduced = value => value instanceof Reduced
const reduced = value => isReduced(value) ? value : new Reduced(value)
const reduce = (reducer, state, array) => {
if (isReduced(state)) {
return state.value
}
if (array.length === 0) {
return state
}
const [x, ...xs] = array
return reduce(reducer, reducer(state, x), xs)
}
const filter = pred => next => (acc, x) =>
pred(x) ? next(acc, x) : acc
const map = mapper => next => (acc, x) =>
next(acc, mapper(x))
const take = n => next => (acc, x) => {
if (n > 0) {
acc = next(acc, x)
n -= 1
}
if (n <= 0) {
acc = reduced(acc)
}
return acc
}
const append = (xs, x) =>
xs.concat([x])
const compose = (...fns) => x =>
fns.reduceRight((x, fn) => fn(x), x)
const transduce = (transducer, reducer, init, array) =>
reduce(transducer(reducer), init, array)
const firstTwoWins = compose(
filter(({ my, others }) => my > others),
map(({ gameID }) => gameID),
take(2)
)
const result = transduce(firstTwoWins, append, [], scores)
function takeFrom(arr, {filter, take, max}) {
let counter = 0,
result = []
for (let i = 0; i < arr.length; i++) {
if (filter(arr[i])) {counter++; result.push(arr[i][take])}
if (max && counter == max) return result
}
return result
}
const firstTwoWins = {
filter: ({my, others}) => my > others,
take : 'gameID',
max : 2
}
takeFrom(scores, firstTwoWins)
const win = ({my, others}) => my > others
const firstResult = scores.findIndex(win)
const secondResult = firstResult + 1 + scores.slice(firstResult + 1).findIndex(win)
const result =
scores
.filter(({ my, others }) => my > others)
.map(({ gameID }) => gameID)
.slice(0, 2)
элементов в массиве 10 100 100 000 1 000 000
императив 1 360 836 1 347 020 1 454 109 1 426 568
0 0 0 0
трансдюсер 361 359 63 541 47 5 (1 если элементы конечные)
0 0 28 247 (1 066 если элементы конечные)
обьекты 1 194 086 1 151 443 1 128 703 1 160 694
0 0 0 0
на правах изврата 904 147 809 852 1 436 139
0 0 1 5
повседневный 281 325 47 045 49 5
0 1 26 224
Трансдьюсеры — апгрейд для функциональных трансформаций. Но если они выполняют полный прогон в каждой трансформации, то трансдьюсеры только нужное число раз и не больше.
То есть разница между [1...100000].filter(..).map(..).take(5) и аналогичным решением на трансдьюсерах будет различаться на N порядков.
Name: Array methods
HZ: 4603.449432980031
Count: 241
Name: Transducers
HZ: 138288.02637186056
Count: 7398
Простой цикл не участвует, потому что он безнадежен?
Name: Array methods
HZ: 9575.634258372818
Count: 491
Name: Transducers
HZ: 133520.15607709397
Count: 6952
Name: For
HZ: 2598682.4299278776
Count: 134571code:
.add("For", () => {
const result = [];
for(const { my, others, gameID } of scores)
if(my > others)
{
result.push(gameID);
if(result.length >= 2)
break;
}
})Полная версия. Что-то уж сильно они разнятся, наверное я что-то напутал.
Нет, циклы заведомо быстрее и нет смысла с ними даже сравнивать)
Я процитирую себя же:
Трансдьюсеры — апгрейд для функциональных трансформаций
Циклы были заменены на трансформации, как более чистое, иммутабельное, функциональное, декларативное и т.д решение, но из-за этого пришлось пожертвовать производительностью. Трансформации были заменены на останавливаемую свертку (reduce + трансдюсеры для создания сложной логики), что сильно увеличило производительность.
В гисте ниже я выполнил пару оптимизаций:
- трансдьюсеры/редьюсеры хороши тем, что мы можем работать с транфсормацией как с объъектом, это их сильная сторона (реюзабельность), поэтому я вынес их (по сути как aot-компиляция, которая проводится для циклов).
- как тут советовали где-то выше в комментах, нет смысла делать concat, потому что стейт нигде больше не используется, адекватно будет заменить на push. Как оказалось, существенной роли это не сыграло, concat видимо как-то оптимизируется.
Name: Array methods
HZ: 4642.041341511592
Count: 240
Name: Transducer
HZ: 161841.1974395176
Count: 8669
Name: For
HZ: 786935.9631453991
Count: 40472Функциональные трансформации медленнее циклов на 3 порядка, но трандьюсеры быстрее их на два.
https://gist.github.com/kana-sama/d0d5eb8362dda32841cc58302fa1c191
Функциональные трансформации медленнее циклов на 3 порядка, но трандьюсеры быстрее их на два.
Если я правильно понял суть, то функ. трансформации медленнее трандьюсеров настолько, насколько душе угодно. Ведь основной принцип: не считать лишнее. Так что можно подобрать такой пример, что там и N порядков будет :)
Вы знаете, что такое трансдьюсеры