Сетевой стек Linux по умолчанию замечательно работает на десктопах. На серверах с нагрузкой чуть выше средней уже приходится разбираться как всё нужно правильно настраивать. На моей текущей работе этим приходится заниматься едва ли не в промышленных масштабах, так что без автоматизации никуда – объяснять каждому коллеге что и как устроено долго, а заставлять людей читать ≈300 страниц английского текста, перемешанного с кодом на C… Можно и нужно, но результаты будут не через час и не через день. Поэтому я попробовал накидать набор утилит для тюнинга сетевого стека и руководство по их использованию, не уходящее в специфические детали определённых задач, которое при этом остаётся достаточно компактным для того, чтобы его можно было прочитать меньше чем за час и вынести из него хоть какую-то пользу.
Чего нужно добиться?
Главная задача при тюнинге сетевого стека (не важно, какую роль выполняет сервер — роутер, анализатор трафика, веб-сервер, принимающий большие объёмы трафика) – равномерно распределить нагрузку по обработке пакетов между ядрами процессора. Желательно с учётом принадлежности CPU и сетевой карты к одной NUMA-ноде, а также не создавая при этом лишних перекидываний пакета между ядрами.
Перед главной задачей, выполняется первостепенная задача — подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Рекомендации по подбору железа
- Двухпроцессорный сервер не будет полезен, если трафик приходит только на одну сетевую карту.
- Отдельные NUMA-ноды не будут полезны, если трафик приходит в порты одной сетевой карты.
- Нет смысла покупать сервер с числом ядер большим, чем суммарное число очередей сетевых карт.
- В случае с сетевыми картами с одной очередью распределить нагрузку между ядрами можно с помощью RPS, но потери при копировании пакетов в память это не устранит.
- Hyper-Threading не приносит пользы и выключается в BIOS (тем более в Skylake и Kaby Lake с ним проблемы)
- Выбирайте процессор с частотой ядер не менее 2.5GHz и большим объёмом L3 и остальных кэшей.
- Используйте DDR4-память.
- Выбирайте сетевые карты, поддерживающие размер RX-буферов до 2048 и более.
Таким образом, если дано 2+ источника объёма трафика больше 2 Гбит/сек, то стоит задуматься о сервере с числом процессоров и NUMA-нод, а также числу сетевых карт (не портов), равных числу этих источников.
"Господи, я не хочу в этом разбираться!"
И не нужно. Я уже разобрался и, чтобы не тратить время на то, чтобы объяснять это коллегам, написал набор утилит — netutils-linux. Написаны на Python, проверены на версиях 2.6, 2.7, 3.4, 3.6.
network-top
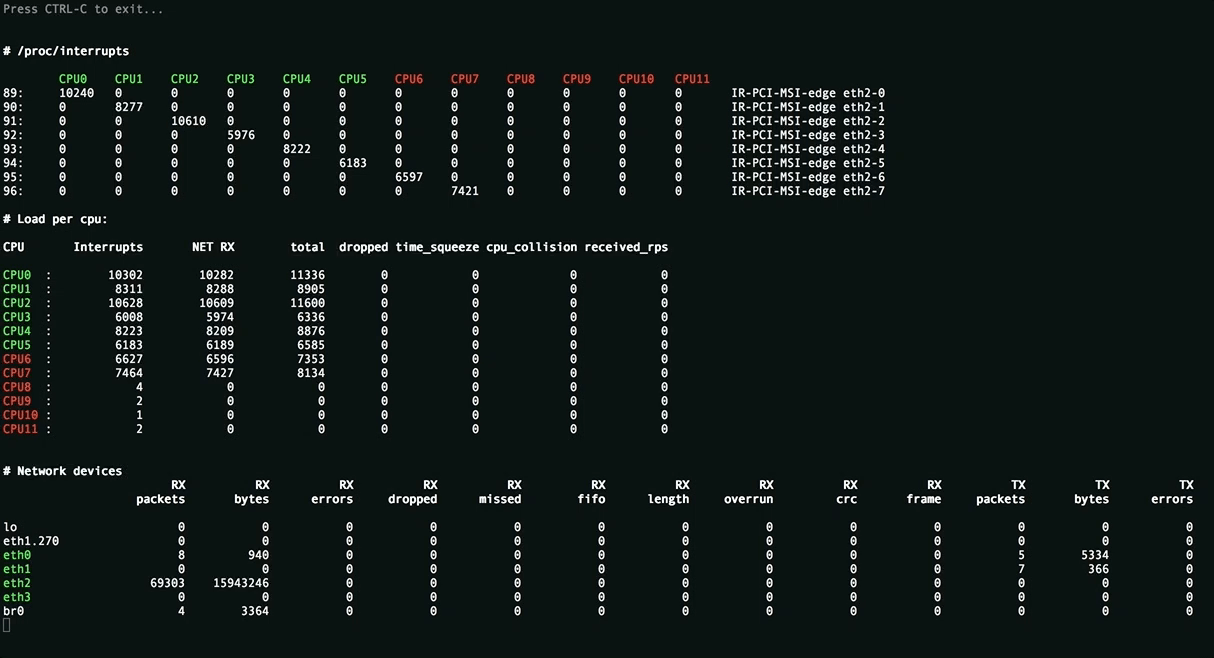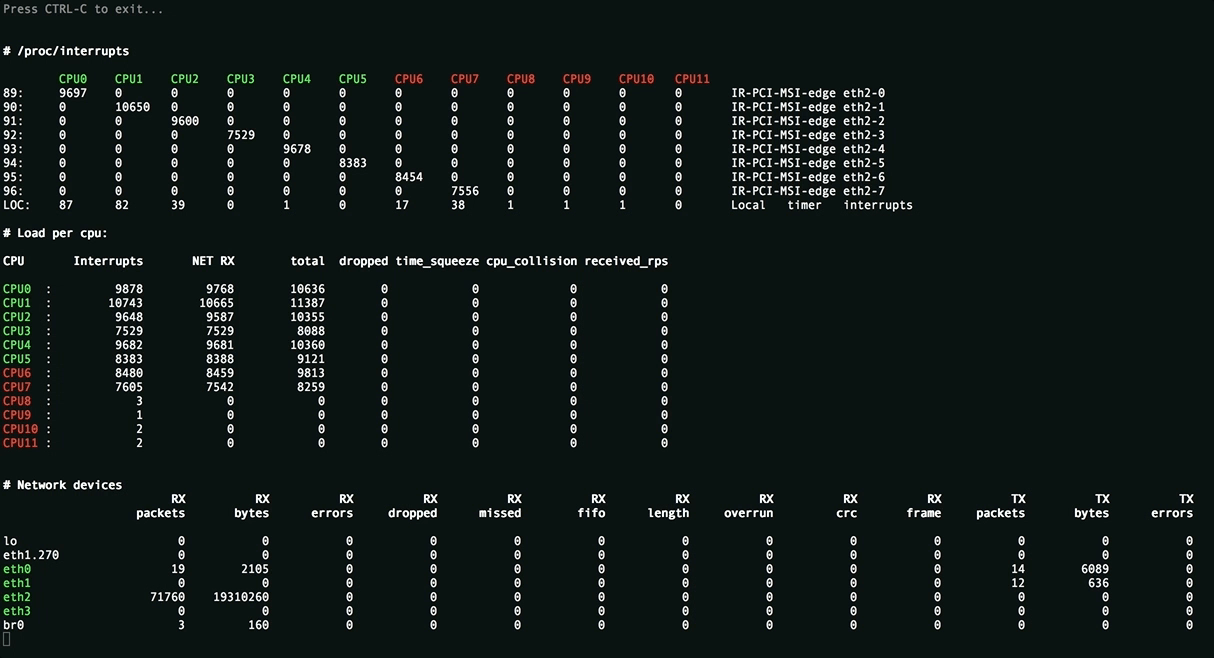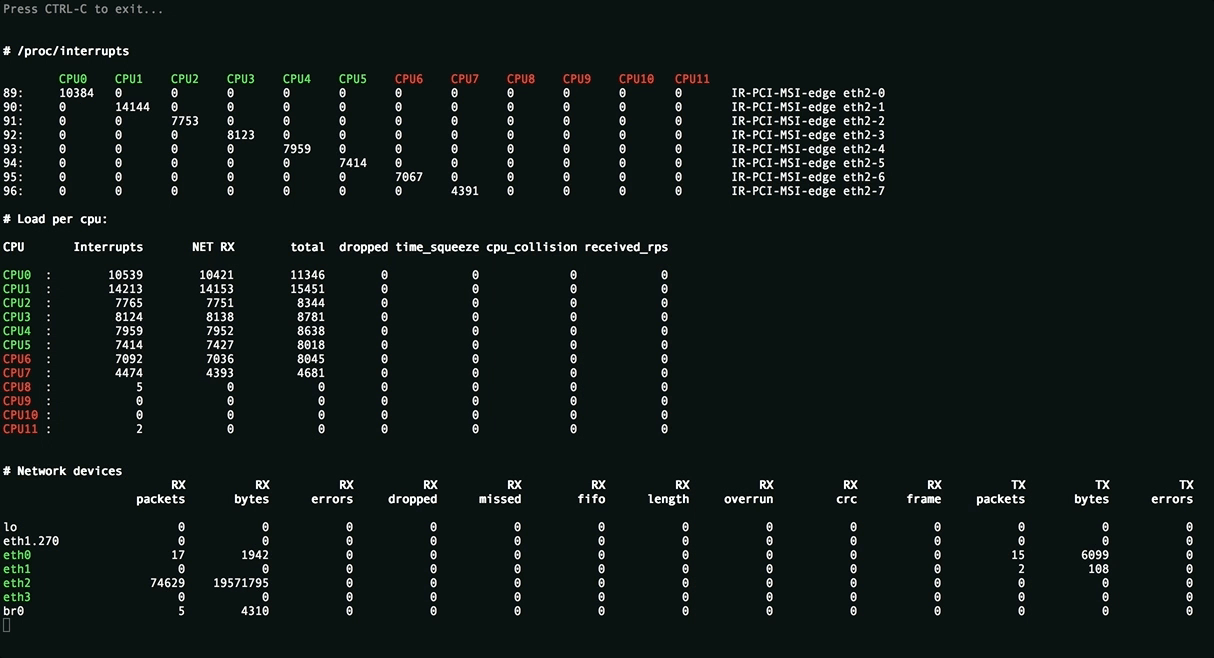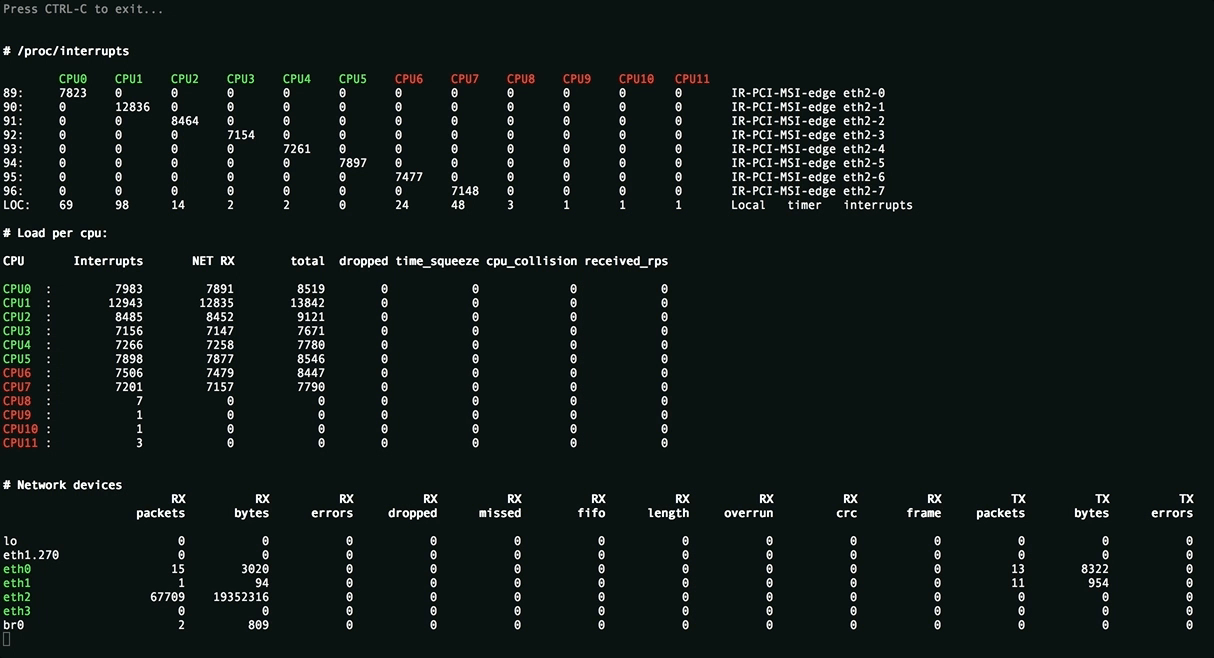
Эта утилита нужна для оценки применённых настроек и отображает равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора) на ресурсы сервера, всевозможные ошибки обработки пакетов. Значения, превышающие пороговые подсвечиваются.
rss-ladder
# rss-ladder eth1 0 - distributing interrupts of eth1 (-TxRx) on socket 0:" - eth1: irq 67 eth1-TxRx-0 -> 0 - eth1: irq 68 eth1-TxRx-1 -> 1 - eth1: irq 69 eth1-TxRx-2 -> 2 - eth1: irq 70 eth1-TxRx-3 -> 3 - eth1: irq 71 eth1-TxRx-4 -> 8 - eth1: irq 72 eth1-TxRx-5 -> 9 - eth1: irq 73 eth1-TxRx-6 -> 10 - eth1: irq 74 eth1-TxRx-7 -> 11
Эта утилита распределяет прерывания сетевой карты на ядра выбранного физического процессора (по умолчанию на нулевой).
autorps
# autorps eth0 Using mask 'fc0' for eth0-rx-0.
Эта утилита позволяет настроить распределение обработки пакетов между ядрами выбранного физического процессора (по умолчанию на нулевой). Если вы используете RSS, скорее всего вам эта утилита не потребуется. Типичный сценарий использования — многоядерный процессор и сетевые карты с одной очередью.
server-info
# server-info rate cpu: BogoMIPS: 7 CPU MHz: 7 CPU(s): 1 Core(s) per socket: 1 L3 cache: 1 Socket(s): 10 Thread(s) per core: 10 Vendor ID: 10 disk: vda: size: 1 type: 1 memory: MemTotal: 1 SwapTotal: 10 net: eth1: buffers: cur: 5 max: 10 driver: 1 queues: 1 system: Hypervisor vendor: 1 Virtualization type: 1
Данная утилита позволяет сделать две вещи:
server-info show: посмотреть, что за железо вообще установлено на сервере. В целом похоже на велосипед, повторяющийlshw, но с акцентом на интересующие нас параметры.server-info rate: найти узкие места в аппаратном обеспечении сервера. В целом похоже на индекс производительности Windows, но опять же с акцентом на интересующие нас параметры. Оценка производится по шкале от 1 до 10.
Прочие утилиты
rx-buffers-increaseавтоматически увеличивает буфер выбранной сетевой карты до оптимального значения.maximize-cpu-freqотключает плавающую частоту процессора. Энергопотребление будет повышенным, но это не ноутбук без зарядного устройства, а сервер, который обрабатывает гигабиты трафика.
Господи, я хочу в этом разбираться!
Прочитайте статьи про:
Эти статьи вдохновили меня на написание этих утилит .
Также хорошую статью написали в блоге одноклассников 2 года назад.
Обычные кейсы
Но руководство по запуску утилит само по себе мало что говорит о том, как именно их нужно применять в зависимости от ситуации. Приведём несколько примеров.
Пример 1. Максимально простой.
Дано:
- один процессор с 4 ядрами
- одна 1 Гбит/сек сетевая карта (eth0) с 4 combined очередями
- входящий объём трафика 600 Мбит/сек, исходящего нет.
- все очереди висят на CPU0, суммарно на нём ≈55000 прерываний и 350000 пакетов в секунду, из них около 200 пакетов/сек теряются сетевой картой. Остальные 3 ядра простаивают
Решение:
- распределяем очереди между ядрами командой
rss-ladder eth0 - увеличиваем ей буфер командой
rx-buffers-increase eth0
Пример 2. Чуть сложнее.
Дано:
- два процессора с 8 ядрами
- две NUMA-ноды
- Две двухпортовые 10 Гбит/сек сетевые карты (eth0, eth1, eth2, eth3), у каждого порта 16 очередей, все привязаны к node0, входящий объём трафика: 3 Гбит/сек на каждую
- 1 х 1 Гбит/сек сетевая карта, 4 очереди, привязана к node0, исходящий объём трафика: 100 Мбит/сек.
Решение:
1 Переткнуть одну из 10 Гбит/сек сетевых карт в другой PCI-слот, привязанный к NUMA node1.
2 Уменьшить число combined очередей для 10гбитных портов до числа ядер одного физического процессора:
for dev in eth0 eth1 eth2 eth3; do ethtool -L $dev combined 8 done
3 Распределить прерывания портов eth0, eth1 на ядра процессора, попадающие в NUMA node0, а портов eth2, eth3 на ядра процессора, попадающие в NUMA node1:
rss-ladder eth0 0 rss-ladder eth1 0 rss-ladder eth2 1 rss-ladder eth3 1
4 Увеличить eth0, eth1, eth2, eth3 RX-буферы:
for dev in eth0 eth1 eth2 eth3; do rx-buffers-increase $dev done
Необычные кейсы
Не всегда всё идёт идеально:
- Встречались сетевые карты, теряющие пакеты (missed) в случае использования RSS на несколько ядер в одной NUMA-ноде. Решение странное, но рабочее — 6 RX-очередей привязаны к CPU0, в rps_cpus каждой очереди записана маска процессоров 111110, потери пропали.
- Встречались сетевые карты mellanox и intel (X710) продолжающие работать при прекратившемся росте счётчиков прерываний. Трафик в tcpdump имелся, нагрузка, создаваемая сетевыми картами висела на CPU0. Нормальная работа восстановилась после включения и выключения RPS. Почему — неизвестно.
- Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) "пропадают" из списка сетевых карт. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning'и. Помогает флаг
unsupported_sfp=1,1при загрузке модуля ixgbe. По хорошему, однако, стоит купить supported sfp. - Некоторые драйверы сетевых карт подстраивают число очередей только под равные степени двойки значения (что обидно на 6-ядерных процессорах).
Update: после публикации автор осознал, что люди используют не только RHEL-based дистрибутивы для сетевых задач, а тесты в debian на наборах данных, собранных в RHEL-based системах, не отлавливают кучу багов. Большое спасибо всем сообщившим о том, что что-то не работает в Ubuntu/Debian/Altlinux! Все баги исправлены в релизе 2.0.10
Update2. в комментариях упомянули то, что RPS всё же часто бывает полезен людям и я его недооцениваю. В принципе это так, поэтому в релизе 2.2.0 появилась значительно улучшенная версия утилиты autorps.
Update3: Релиз 2.5.0
