Miguel Grinberg
Эта статья является переводом четвертой части нового издания учебника Мигеля Гринберга. Прежний перевод давно утратил свою актуальность.
Это четвертый выпуск серии Flask Mega-Tutorial, в котором я расскажу вам, как работать с базами данных.
Для справки ниже приведен список статей этой серии.
- Глава 1: Привет, мир!
- Глава 2: Шаблоны
- Глава 3: Веб-формы
- Глава 4: База данных (Эта статья)
- Глава 5: Пользовательские логины
- Глава 6: Страница профиля и аватары
- Глава 7: Обработка ошибок
- Глава 8: Подписчики, контакты и друзья
- Глава 9: Разбивка на страницы
- Глава 10: Поддержка электронной почты
- Глава 11: Реконструкция
- Глава 12: Дата и время
- Глава 13: I18n и L10n
- Глава 14: Ajax
- Глава 15: Улучшение структуры приложения
- Глава 16: Полнотекстовый поиск
- Глава 17: Развертывание в Linux
- Глава 18: Развертывание на Heroku
- Глава 19: Развертывание на Docker контейнерах
- Глава 20: Магия JavaScript
- Глава 21: Уведомления пользователей
- Глава 22: Фоновые задачи
- Глава 23: Интерфейсы прикладного программирования (API)
Примечание 1: Если вы ищете старые версии данного курса, это здесь.
Примечание 2: Если вдруг Вы хотели бы выступить в поддержку моей(Мигеля) работы в этом блоге, или просто не имеете терпения дожидаться неделю статьи, я (Мигель Гринберг)предлагаю полную версию данного руководства упакованную электронную книгу или видео. Для получения более подробной информации посетите learn.miguelgrinberg.com.
Тема этой главы чрезвычайно важна. Для большинства приложений необходимо поддерживать постоянные данные, которые могут быть эффективно извлечены, и это именно то, для чего создаются базы данных.
Ссылки GitHub для этой главы: Browse, Zip, Diff.
Базы данных в Flask
Поскольку я уверен, что вы уже слышали, Flask не поддерживает базы данных изначально. Это одна из многих областей, в которых Flask намеренно не самодостаточен, и это здорово, потому что у вас есть свобода выбора базы данных, которая наилучшим образом подходит для вашего приложения, вместо того, чтобы быть вынужденным адаптироваться к одному.
В Python есть большой выбор для баз данных, многие из которых интегрируются с Flask приложением. Базы данных можно разделить на две большие группы: те, которые соответствуют реляционной модели, и те, которые этого не делают. Последняя группа часто называется NoSQL, что указывает на то, что они не реализуют популярный язык реляционных запросов SQL. Хотя в обеих группах есть отличные продукты для баз данных, я считаю, что реляционные базы данных лучше подходят для приложений, которые имеют структурированные данные, такие как списки пользователей, сообщения в блогах и т.д., В то время как базы данных NoSQL имеют тенденцию быть лучше для данных, которые имеют менее определенную структуру. Это приложение, как и большинство других, может быть реализовано с использованием любого типа базы данных, но по указанным выше причинам я собираюсь работать с реляционной базой данных.
В главе 3 я показал вам первое расширение Flask. В этой главе я собираюсь использовать еще два. Первым является Flask-SQLAlchemy, расширение, которое обеспечивает Flask-дружественную оболочку к популярному пакету SQLAlchemy, который является Object Relational Mapper или ORM. ORM позволяют приложениям управлять базой данных с использованием объектов высокого уровня, таких как классы, объекты и методы, а не таблицы и SQL. Задача ORM — перевести операции высокого уровня в команды базы данных.
Самое приятное в SQLAlchemy заключается в том, что это ORM не для одного, а для многих реляционных баз данных. SQLAlchemy поддерживает длинный список движков баз данных, включая популярные MySQL, PostgreSQL и SQLite. Это очень сильно, потому что вы можете сделать свою разработку с помощью простой базы данных SQLite, которая не требует сервера, а затем, когда придет время развертывать приложение на производственном сервере, вы можете выбрать более надежный сервер MySQL или PostgreSQL, не измененяя вашего приложения.
Чтобы установить Flask-SQLAlchemy в виртуальную среду, убедитесь, что вы активировали ее сначала, а затем запустите:
(venv) $ pip install flask-sqlalchemy
Миграция баз данных
Большинство учебных пособий по базе данных, которые я видел, охватывают создание и использование базы данных, но не позволяют адекватно решить проблему создания обновлений существующей базы данных по мере того, как приложение нуждается в изменении или увеличении. Это сложно, потому что реляционные базы данных сосредоточены вокруг структурированных данных, поэтому при изменении структуры данные, которые уже находятся в базе данных, необходимо перенести в модифицированную структуру.
Второе расширение, которое я собираюсь представить в этой главе, Flask-Migrate, который фактически созданный вашим покорным слугой. Это расширение является Flask-оберткой для Alembic, основой для миграции базы данных SQLAlchemy. Работа с миграциями баз данных добавляет немного работы вначале, но это небольшая цена, чтобы заплатить за надежный способ внесения изменений в вашу базу данных в будущем.
Процесс установки для Flask-Migrate аналогичен другим расширениям, которые вы видели:
(venv) $ pip install flask-migrate
Конфигурация Flask-SQLAlchemy
Во время разработки я собираюсь использовать базу данных SQLite. Базы данных SQLite являются наиболее удобным выбором для разработки небольших приложений, иногда даже не очень маленьких, так как каждая база данных хранится в одном файле на диске и нет необходимости запускать сервер баз данных, как MySQL и PostgreSQL.
У нас есть два новых элемента конфигурации для добавления в файл конфигурации:
config.py
import os basedir = os.path.abspath(os.path.dirname(__file__)) class Config(object): # ... SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL') or \ 'sqlite:///' + os.path.join(basedir, 'app.db') SQLALCHEMY_TRACK_MODIFICATIONS = False
Расширение Flask-SQLAlchemy принимает местоположение базы данных приложения из переменной конфигурации SQLALCHEMY_DATABASE_URI. Как вы помните из главы 3, в целом рекомендуется установить конфигурацию из переменных среды и предоставить резервное значение, когда среда не определяет переменную. В этом случае я беру URL-адрес базы данных из переменной среды DATABASE_URL, и если это не определено, я настраиваю базу данных с именем app.db, расположенную в основном каталоге приложения, которая хранится в переменной basedir.
Параметр конфигурации SQLALCHEMY_TRACK_MODIFICATIONS установлен в значение False, чтобы отключить функцию Flask-SQLAlchemy, которая мне не нужна, которая должна сигнализировать приложению каждый раз, когда в базе данных должно быть внесено изменение.
База данных будет представлена в приложении, как database instance. Механизм миграции базы данных также будет иметь экземпляр. Это объекты, которые необходимо создать после приложения, в файле app/__ init__.py:
from flask import Flask from config import Config from flask_sqlalchemy import SQLAlchemy from flask_migrate import Migrate app = Flask(__name__) app.config.from_object(Config) db = SQLAlchemy(app) migrate = Migrate(app, db) from app import routes, models
Я внес три изменения в скрипт init. Во-первых, я добавил объект db, который представляет базу данных. Затем я добавил еще один объект, который представляет механизм миграции. Надеюсь, вы увидите образец работы с расширениями Flask. Большинство расширений инициализируются как эти два. Наконец, я импортирую новый модуль под названием models внизу. Этот модуль определит структуру базы данных.
Модели баз данных
Данные, которые будут храниться в базе данных, будут представлены набором классов, обычно называемых моделями баз данных. Уровень ORM в SQLAlchemy будет выполнять переводы, необходимые для сопоставления объектов, созданных из этих классов, в строки в соответствующих таблицах базы данных.
Начнем с создания модели, представляющей пользователей. Используя инструмент WWW SQL Designer, я сделал следующую диаграмму для представления данных, которые мы хотим использовать в таблице users:
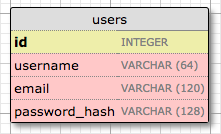
Поле id обычно используется во всех моделях и используется как первичный ключ. Каждому пользователю в базе данных будет присвоено уникальное значение идентификатора, сохраненное в этом поле. Первичные ключи в большинстве случаев автоматически назначаются базой данных, поэтому мне просто нужно указать поле id, помеченное как первичный ключ.
Поля username, email и password_hash определяются как строки (или VARCHAR на жаргоне базы данных), а их максимальная длина указывается так, чтобы база данных могла оптимизировать использование пространства. Хотя поля username и email не требуют пояснений, поля password_hash заслуживают внимания. Я хочу убедиться, что приложение, которое я создаю, использует лучшие рекомендации по безопасности, и по этой причине я не буду хранить пароли пользователей в базе данных. Проблема с хранением паролей заключается в том, что если база данных когда-либо становится скомпрометированной, злоумышленники будут иметь доступ к паролям, и это может быть разрушительным для пользователей. Вместо того, чтобы писать пароли напрямую, я собираюсь написать хэши паролей (password hashes), которые значительно улучшают безопасность. Это будет тема другой главы, так что не беспокойтесь об этом сейчас.
Итак, теперь, когда я знаю, что мне нужно для таблицы моих пользователей, я могу перевести это в код в новом модуле app/models.py:
from app import db class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), index=True, unique=True) email = db.Column(db.String(120), index=True, unique=True) password_hash = db.Column(db.String(128)) def __repr__(self): return '<User {}>'.format(self.username)
Созданный выше класс User наследует от db.Model, базового класса для всех моделей из Flask-SQLAlchemy. Этот класс определяет несколько полей как переменные класса. Поля создаются как экземпляры класса db.Column, который принимает тип поля в качестве аргумента, плюс другие необязательные аргументы, которые, например, позволяют мне указать, какие поля уникальны и индексированы, что важно для эффективного поиска базы данных ,
Метод __repr__ сообщает Python, как печатать объекты этого класса, что будет полезно для отладки. Вы можете увидеть метод __repr __() в действии в сеансе интерпретатора Python ниже:
>>> from app.models import User >>> u = User(username='susan', email='susan@example.com') >>> u <User susan>
Создание миграции репозитория
Класс модели, созданный в предыдущем разделе, определяет исходную структуру (или схему) базы данных для этого приложения. Но по мере того, как приложение продолжает расти, потребуется изменить структуру, которая, скорее всего, добавит новые сущности, но иногда также может изменять или удалять элементы. Alembic (инфраструктура миграции, используемая Flask-Migrate) сделает эти изменения схемы таким образом, чтобы не требовалось воссоздавать базу данных с нуля.
Чтобы выполнить эту, казалось бы, сложную задачу, Alembic поддерживает репозиторий миграции, который является каталогом, в котором хранится его сценарии миграции. Каждый раз, когда в схему базы данных вносится изменение, в репозиторий добавляется сценарий миграции с подробными сведениями об изменении. Чтобы применить миграции к базе данных, эти сценарии миграции выполняются в той последовательности, в которой они были созданы.
Flask-Migrate выдает свои команды через flask команду. Вы уже видели flask run, который является подчиненной командой, которая является родной для Flask. Подкоманда flask db добавляется Flask-Migrate для управления всем, что связано с миграцией базы данных. Итак, давайте создадим репозиторий миграции для microblog, запустивflask db init:
(venv) $ flask db init Creating directory /home/miguel/microblog/migrations ... done Creating directory /home/miguel/microblog/migrations/versions ... done Generating /home/miguel/microblog/migrations/alembic.ini ... done Generating /home/miguel/microblog/migrations/env.py ... done Generating /home/miguel/microblog/migrations/README ... done Generating /home/miguel/microblog/migrations/script.py.mako ... done Please edit configuration/connection/logging settings in '/home/miguel/microblog/migrations/alembic.ini' before proceeding.
Помните, что flask команда полагается на переменную среды FLASK_APP, чтобы знать, где расположено приложение Flask. Для этого приложения вы хотите установить FLASK_APP=microblog.py, как описано в главе 1.
После запуска этой команды вы найдете новый каталог migrations, в котором есть несколько файлов и подкаталог версий. Все эти файлы теперь должны рассматриваться как часть вашего проекта и, их необходимо добавить в систему управления версиями.
Первая миграция базы данных
При наличии репозитория миграции настало время создать первую миграцию базы данных, которая будет включать таблицу Users, сопоставляемую с моделью пользовательской базы данных. Существует два способа создания миграции базы данных: вручную или автоматически. Для автоматического создания миграции Alembic сравнивает схему базы данных, определенную моделями баз данных, с фактической схемой базы данных, используемой в настоящее время в базе данных. Затем он заполняет сценарий переноса изменениями, необходимыми для того, чтобы схема базы данных соответствовала моделям приложений. В этом случае, поскольку нет предыдущей базы данных, автоматический перенос добавит всю User модель в сценарий переноса. flask db migrate Подкоманда переноса DB генерирует эти автоматические миграции:
(venv) $ flask db migrate -m "users table" INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'user' INFO [alembic.autogenerate.compare] Detected added index 'ix_user_email' on '['email']' INFO [alembic.autogenerate.compare] Detected added index 'ix_user_username' on '['username']' Generating /home/miguel/microblog/migrations/versions/e517276bb1c2_users_table.py ... done
Вывод команды дает вам представление о том, что Alembic включен в миграцию. Первые две строки являются информационными и их обычно можно игнорировать. Затем он говорит, что нашел таблицу 'user' и два индекса '['email']' и '['username']'. Затем он сообщает вам, где он написал сценарий миграции. Код e517276bb1c2 — это автоматически созданный уникальный код для миграции (он будет другим для вас). Комментарий, заданный с параметром -m, является необязательным, он добавляет короткий описательный текст в перенос.
Сгенерированный сценарий миграции теперь является частью вашего проекта и должен быть включен в систему управления версиями. Вы можете просмотреть сценарий, если вам интересно посмотреть, как он выглядит. Вы обнаружите, что у него есть две функции: upgrade() и downgrade(). Функция upgrade() применяет миграцию, а функция downgrade() удаляет ее. Это позволяет Alembic переносить базу данных в любую точку истории, даже в более старые версии, используя путь понижения.
Команда flask db migrate не вносит никаких изменений в базу данных, она просто создает сценарий миграции. Чтобы применить изменения в базе данных, необходимо использовать команду flask db upgrade.
(venv) $ flask db upgrade INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.runtime.migration] Running upgrade -> e517276bb1c2, users table
Поскольку это приложение использует SQLite, команда Upgrade обнаружит, что база данных не существует и создаст ее (вы заметите, что файл с именем app.db будет добавлен после завершения этой команды, то есть базы данных SQLite). При работе с серверами баз данных, такими как MySQL и PostgreSQL, перед запуском обновления необходимо создать базу данных на сервере базы данных.
Процесс обновления базы данных и откатка изменений Upgrade и Downgrade
На данный момент приложение находится в зачаточном состоянии, но это не помешает обсудить, что будет в стратегии миграции базы данных в будущем. Представьте, что у вас есть приложение на вашей машине разработки, а также есть копия, развернутая на производственный сервер, который находится в сети и используется.
Предположим, что для следующей версии вашего приложения вам нужно внести изменения в свои модели, например, нужно добавить новую таблицу. Без миграции вам нужно будет выяснить, как изменить схему вашей базы данных, как на локальном хосте, так и на вашем сервере, и это может быть большой проблемой.
Но с поддержкой миграции базы данных, после изменения моделей в приложении вы создаете новый сценарий миграции ( flask db migrate ), вы, вероятно, просмотрите его, чтобы убедиться, что автоматическое создание сделало правильные вещи, а затем примените изменения в базе данных разработки ( flask db upgrade ). Вы добавите сценарий миграции в систему управления версиями и зафиксируете его.
Когда вы будете готовы выпустить новую версию приложения на свой production сервер, все, что вам нужно сделать, это захватить обновленную версию приложения, которая будет включать в себя новый сценарий миграции и запустить flask db upgrade. Alembic обнаружит, что база данных не обновлена до последней редакции, и выполнит все новые сценарии миграции, созданные после предыдущего выпуска.
Как я упоминал ранее, у вас также есть команда flask db downgrade, которая отменяет последнюю миграции. Хотя вам вряд ли понадобится этот вариант в момент рабочей эксплуатации, Вы можете найти его очень полезным во время разработки. Возможно, вы сгенерировали сценарий миграции и применили его, только чтобы обнаружить, что внесенные изменения не совсем то, что вам нужно. В этом случае можно понизить рейтинг базы данных, удалить сценарий миграции, а затем создать новый, чтобы заменить его.
Связи базы данных
Реляционные базы данных хороши в хранении связей между элементами данных. Рассмотрим случай, когда пользователь пишет сообщение в блоге. Пользователь будет иметь запись в таблице пользователей, и сообщение будет иметь запись в таблице сообщений. Самый эффективный способ записать кто написал данное сообщение, — связать две записи.
После того, как установлена связь между пользователем и постом, есть два типа запросов, которые нам могут понадобиться. Самый тривиальный, когда у вас есть пост и нужно знать кто из пользователей его написал. Чуть более сложный вопрос является обратным этому. Если у вас есть пользователь, то вам может понадобиться получить все написанные им записи. Flask-SQLAlchemy поможет нам с обоими типами запросов.
Расширим нашу базу для хранения постов, чтобы мы могли увидеть связи в действии. Для этого мы вернемся к нашему инструменту дизайна БД и создадим таблицу записей:
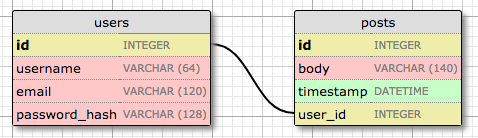
Таблица Сообщений будет иметь необходимый идентификатор, текст сообщения и метку времени. Но в дополнение к этим ожидаемым полям я добавляю поле user_id, которое связывает сообщение с его автором. Вы видели, что у всех пользователей есть первичный ключ id, который уникален. Способ связать запись блога с пользователем, который ее создал, — добавить ссылку на идентификатор пользователя, и это именно то, что является полем user_id. Это поле user_id называется внешним ключом (англ. foreign key). На приведенной выше схеме базы данных внешние ключи отображаются как связь между полем и полем id таблицы, на которую он ссылается. Такого рода отношения называется один ко многим, потому что "один" пользователь пишет "много" Сообщений.
Измененный app/models.py показан ниже:
from datetime import datetime from app import db class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), index=True, unique=True) email = db.Column(db.String(120), index=True, unique=True) password_hash = db.Column(db.String(128)) posts = db.relationship('Post', backref='author', lazy='dynamic') def __repr__(self): return '<User {}>'.format(self.username) class Post(db.Model): id = db.Column(db.Integer, primary_key=True) body = db.Column(db.String(140)) timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow) user_id = db.Column(db.Integer, db.ForeignKey('user.id')) def __repr__(self): return '<Post {}>'.format(self.body)
Новый класс Post будет представлять записи в блогах, написанные пользователями. Поле timestamp будет проиндексировано, что полезно, если вы хотите получить сообщения в хронологическом порядке. Я также добавил аргумент по умолчанию и передал функцию datetime.utcnow. Когда вы передаете функцию по умолчанию, SQLAlchemy установит для поля значение вызова этой функции (обратите внимание, что я не включил () после utcnow, поэтому я передаю саму эту функцию, а не результат ее вызова ). В общем, это позволит работать с датами и временем UTC в серверном приложении. Это гарантирует, что вы используете единые временные метки независимо от того, где находятся пользователи. Эти временные метки будут преобразованы в локальное время пользователя, когда они будут отображаться.
Поле user_id было инициализировано как внешний ключ для user.id, что означает, что оно ссылается на значение id из таблицы users. В этой ссылке user — это имя таблицы базы данных, которую Flask-SQLAlchemy автоматически устанавливает как имя класса модели, преобразованного в нижний регистр. Класс User имеет новое поле сообщений, которое инициализируется db.relationship. Это не фактическое поле базы данных, а высокоуровневое представление о взаимоотношениях между users и posts, и по этой причине оно не находится в диаграмме базы данных. Для отношения «один ко многим» поле db.relationship обычно определяется на стороне «один» и используется как удобный способ получить доступ к «многим». Так, например, если у меня есть пользователь, хранящийся в u, выражение u.posts будет запускать запрос базы данных, который возвращает все записи, написанные этим пользователем. Первый аргумент db.relationship указывает класс, который представляет сторону отношения «много». Аргумент backref определяет имя поля, которое будет добавлено к объектам класса «много», который указывает на объект «один». Это добавит выражение post.author, которое вернет автора сообщения. Аргумент lazy определяет, как будет выполняться запрос базы данных для связи, о чем я расскажу позже. Не беспокойтесь, если эти детали не имеют для вас смысла, я покажу примеры в конце этой статьи.
Поскольку у меня есть обновления для моделей приложений, необходимо создать новую миграцию базы данных:
(venv) $ flask db migrate -m "posts table" INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'post' INFO [alembic.autogenerate.compare] Detected added index 'ix_post_timestamp' on '['timestamp']' Generating /home/miguel/microblog/migrations/versions/780739b227a7_posts_table.py ... done
И миграция должна быть применена к базе данных:
(venv) $ flask db upgrade INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.runtime.migration] Running upgrade e517276bb1c2 -> 780739b227a7, posts table
Если проект хранится в системе управления версиями, не забудьте добавить в него новый сценарий миграции.
Время запуска
Я заставил вас пройти через долгий процесс создания базы данных, но я еще не показал вам, как все работает. Поскольку приложение еще не имеет логики базы данных, давайте поиграемся с базой данных в интерпретаторе Python, чтобы ознакомиться с ним. Итак, продолжайте и запустите Python. Перед запуском интерпретатора убедитесь, что ваша виртуальная среда активирована.
В командной строке Python давайте импортируем экземпляр базы данных и модели:
>>> from app import db >>> from app.models import User, Post
Начните с создания нового пользователя:
>>> u = User(username='john', email='john@example.com') >>> db.session.add(u) >>> db.session.commit()
Изменения в базе данных выполняются в контексте сеанса, к которому можно получить доступ как db.session. Множество изменений можно накапливать в сеансе, и как только все изменения были зарегистрированы, вы можете выпустить один файл db.session.commit(), который записывает все изменения атомарно. Если в любое время во время работы над сеансом произошла ошибка, вызов db.session.rollback()отменяет сеанс и удаляет любые изменения, сохраненные в нем. Важно помнить, что изменения записываются только в базу данных при вызове db.session.commit(). Сеансы гарантируют, что база данных никогда не останется в несогласованном состоянии.
Давайте добавим другого пользователя:
>>> u = User(username='susan', email='susan@example.com') >>> db.session.add(u) >>> db.session.commit()
База данных может ответить на запрос, возвращающий всех пользователей:
>>> users = User.query.all() >>> users [<User john>, <User susan>] >>> for u in users: ... print(u.id, u.username) ... 1 john 2 susan
Все модели имеют атрибут запроса, который является точкой входа для запуска запросов к базе данных. Самый основной запрос — тот, который возвращает все элементы этого класса, который называется all(). Обратите внимание, что при добавлении этих пользователей поля id автоматически устанавливались в 1 и 2.
Вот еще один способ. Если вы знаете идентификатор пользователя, вы можете получить результат следующим образом:
>>> u = User.query.get(1) >>> u <User john>
Теперь добавим сообщение в блоге:
>>> u = User.query.get(1) >>> p = Post(body='my first post!', author=u) >>> db.session.add(p) >>> db.session.commit()
Мне не нужно было устанавливать значение для поля timestamp, потому что это поле имеет значение по умолчанию, которое вы можете увидеть в определении модели. А как насчет поля user_id? Напомню, что отношение db.relationship, которое я создал в классе User, добавляет атрибут posts для пользователей, а также атрибут автора для сообщений. Я назначаю автора сообщению, используя виртуальное поле автора, вместо того, чтобы иметь дело с идентификаторами пользователей. SQLAlchemy отлично подходит в этом отношении, поскольку обеспечивает абстракцию высокого уровня над отношениями и внешними ключами.
В завершении, давайте рассмотрим еще несколько запросов к базе данных:
>>> # get all posts written by a user >>> u = User.query.get(1) >>> u <User john> >>> posts = u.posts.all() >>> posts [<Post my first post!>] >>> # same, but with a user that has no posts >>> u = User.query.get(2) >>> u <User susan> >>> u.posts.all() [] >>> # print post author and body for all posts >>> posts = Post.query.all() >>> for p in posts: ... print(p.id, p.author.username, p.body) ... 1 john my first post! # get all users in reverse alphabetical order >>> User.query.order_by(User.username.desc()).all() [<User susan>, <User john>]
Документация по Flask-SQLAlchemy-это лучшее место, чтобы узнать о многих вариантах, доступных для запроса к базе данных.
Для завершения этого раздела, давайте сотрем тест пользователей и сообщений, созданных выше, так что бы база данных стала чистой и готовой к следующей главе:
>>> users = User.query.all() >>> for u in users: ... db.session.delete(u) ... >>> posts = Post.query.all() >>> for p in posts: ... db.session.delete(p) ... >>> db.session.commit()
shell context или лекарство от геморроя
Помните, что вы делали в начале предыдущего раздела, сразу после запуска интерпретатора Python? Первое, что вы сделали, это запустили некоторые операции импорта:
>>> from app import db >>> from app.models import User, Post
В то время как вы работаете над своим приложением, вам нужно будет очень часто тестировать функционал в оболочке Python, поэтому повторять вышеуказанный импорт каждый раз будет утомительно. Команда flask shell — еще один очень полезный инструмент в командной оболочке команд. shell — это второе "ядро", реализующее flask, после запуска. Цель этой команды-запустить интерпретатор Python в контексте приложения. Что это значит? Рассмотрим следующий пример:
(venv) $ python >>> app Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'app' is not defined >>> (venv) $ flask shell >>> app <Flask 'app'>
При регулярном сеансе интерпретатора имя app неизвестно, если явно не импортировано, но при использовании flask shell команда предварительно импортирует экземпляр приложения. Прикол flask shell заключается не в том, что предварительно импортирует приложение, а в том, что вы можете настроить «shell context», который представляет собой список других имен для предварительного импорта.
Следующая функция в microblog.py создает контекст оболочки, который добавляет экземпляр и модели базы данных в сеанс оболочки:
from app import app, db from app.models import User, Post @app.shell_context_processor def make_shell_context(): return {'db': db, 'User': User, 'Post': Post}
Декоратор app.shell_context_processor регистрирует функцию как функцию контекста оболочки. Когда запускается команда flask shell, она будет вызывать эту функцию и регистрировать элементы, возвращаемые ею в сеансе оболочки. Причина, по которой функция возвращает словарь, а не список, заключается в том, что для каждого элемента вы также должны указывать имя, под которым оно будет ссылаться в оболочке, которое задается индексами словаря.
После того, как вы добавите функцию обработчика flask shell, вы можете работать с объектами базы данных, не импортируя их:
(venv) $ flask shell >>> db <SQLAlchemy engine=sqlite:////Users/migu7781/Documents/dev/flask/microblog2/app.db> >>> User <class 'app.models.User'> >>> Post <class 'app.models.Post'>
