Приветствую, Хаброжители!
Сегодня речь пойдет о мире, о который большинство из вас не знает, но при этом там крутятся многие отличные инженеры-разработчики и большие деньги. Да, как ни странно, речь пойдет о Minecraft.
Minecraft — игра-песочница и на мультиплеер-серверах остро стоит проблема гриферства (от англ. griefing — вредительство), когда игроки рушат чужие постройки. На серверах с этой проблемой справляются по-разному. На публичных используют плагин на 'приват', на остальных же все строится на доверии.
Еще один из способов предотвратить гриферство — бан всех гриферов. И для того чтобы вычислить их, приходиться логгировать установку и удаление блоков. Собственно, о процессе создания такой лог-системы и пойдет речь дальше.
Выбор базы данных
Итак, вот у нас массив данных и хорошо бы его куда-то сохранять. Умные люди давно придумали БД. Лично у меня требования к БД были такие:
- Быстрая вставка
- Максимальное сжатие данных
- Возможность из Java без root-прав развертываться без лишних телодвижений
Последний пункт появился из-за того, что не на всех хостингах есть возможность получить root-доступ или установить какой-либо пакет. К тому же, не хотелось усложнять процедуру установки, а остановиться на "Кинул и забыл".
Базы данных, которые удовлетворяли бы всем критериям я не нашел, поэтому решил сделать свою мини-БД на Java.

Оптимизация места на жёстком диске
Основная проблема игры, как считают многие, — все её вычисления происходят в одном потоке. Это настоящая боль держателей серверов. Распараллелить изначально однопоточную архитектуру — надо постараться.

Поэтому само логгирование пришлось вынести в отдельный поток. А чтобы система не захлебнулась от Event'ов в очереди, добавить поддержку воркеров. Количество воркеров настраеваемое.
В итоге получилось так, что само событие перехватывается в главном тике, потом отправляется в поток, который занят тем, что распределяет задачи между воркерами. Там мы получаем файл, в который надо занести наше событие и передаем уже воркеру, который прикреплен к этому файлу. И сама операция IO происходит в воркере.
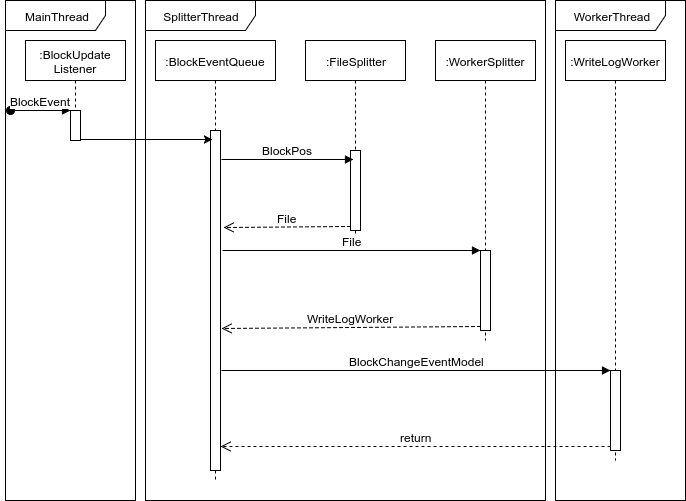
Оптимизация места на жёстком диске
Большое количество событий может привести к тому, что логи будут весить больше, чем сам мир. Этого нам допустить нельзя, поэтому будем думать.
Изначально строчка в логфайле выглядела так:
[2001-07-04T12:08:56.235-0700]Player PLACE <blockid> to 128,128,128
При беглом взгляде можно заметить, что 2001-07-04T12:08:56.235-0700 можно сократить до Timestamp, а PLACE или REMOVE на символ '+' и '-' соответственно. Ну и уберем нафиг 'to':
[123454678]Player + <blockid> 128,128,128
Не сложно заметить, что в логе будет часто повторятся nickname и blockid. Соответсвенно, их можно вынести в отдельный файл, а в лог писать только id
[123454678]1 + 1 128,128,128
В итоге я пришел к тому, что в строчке лога остались только числа и один символ. Мы сэкономим много места, если уберем разделители (пробелы) и числа будем записывать как байты, а не как символы. Сообственно, это привело меня к решению использовать байтовые логи.
Сама байтовая строка теперь выглядит так:
| Name | posX | posY | posZ | typeaction | playerid | blockid | timestamp |
|---|---|---|---|---|---|---|---|
| Field Length (bytes) | 4 byte | 4 byte | 4 byte | 1 byte ('0' for Remove, '1' for Insert) | 4 byte | 8 byte | 8 byte |
Итого мы имеем 35 байтов на строку фиксированно (1 байт для разделения строк).
Вначале был соблазн оставить 34 байта, но так как запись ведется в один файл, то в случае с фиксированной длинной, если побьется одна строка, весь файл станет нечитаемым.
Путь для логов: /{save}/{world/dimension}/*.bytelog
Структура строки для blockname to id:
| Name | id | blockname |
|---|---|---|
| Field Length (bytes) | 8 byte | 1 byte per symbols |
Итого: ~ 21 байтов на блок
Имя файла: blockmap.bytelog
Структура строки для nickname to id:
| Name | id | nickname |
|---|---|---|
| Field Length (bytes) | 4 byte | 1 byte per symbols |
Итого: ~ 10 байтов на игрока
Имя файла: nickmap.bytelog
Оптимизация памяти
Чтобы быстро маппить blockname и nickname в id пришлось держать содержимое обоих файлов в памяти. Java не может в HashMap хранить примитивные типы, поэтому каждый Integer будет стоить нам ~50 байт в памяти, что очень много.
Решить эту проблему нам поможет библиотека trove.
private final TObjectIntHashMap uuidToId = new TObjectIntHashMap();
Но каждый символ у нас занимает примерно 2 байта. Мы можем снизить потребления памяти с помощью самописного файла ASCIString, в котором символы хранятся в byte[], а не в char[].
Тестирование
В тестировании байтовой сериализации и десериализации ничего необычного нет, а вот для тестирования компонентов, к которым требовался многопоточный доступ пришлось использовать фреймворк от гугла Thread Weaver. Обычный тест с использованием этого фреймворка выглядит так:
public class NickMapperAsyncTest extends TestCase { private volatile NickMapper nickMapper; public void testNickMapper() { final AnnotatedTestRunner runner = new AnnotatedTestRunner(); runner.runTests(this.getClass(), NickMapper.class); } @ThreadedBefore public void before() throws IOException { nickMapper = new NickMapper(); } @ThreadedMain public void main() { nickMapper.getOrPutUser(new ASCIString("2")); nickMapper.getOrPutUser(new ASCIString("LionZXY")); nickMapper.getOrPutUser(new ASCIString("3")); } @ThreadedSecondary public void secondary() { nickMapper.getOrPutUser(new ASCIString("2")); nickMapper.getOrPutUser(new ASCIString("LionZXY")); nickMapper.getOrPutUser(new ASCIString("3")); } @ThreadedAfter public void after() { final int first = nickMapper.getOrPutUser(new ASCIString("LionZXY")); final int second = nickMapper.getOrPutUser(new ASCIString("2")); final int third = nickMapper.getOrPutUser(new ASCIString("3")); assertEquals(3, nickMapper.size()); assertEquals(Integer.MIN_VALUE + 3, Collections.max(Arrays.asList(first, second, third)).intValue()); } }
Фреймворк стучит из обоих потоков с разным порядком, что позволяет выловить самые противные баги в асинхронном коде.
Заключение
Пока по количеству скачиваний будет понятно стоит ли развивать дальше этот мод и идею. Из примерных планов на будущее:
- Добавить возможность удалять старые и неактуальные логи автоматически
- Добавить сжатие для файлов
Ссылки
@Config(modid = FastLogBlock.MODID) @Config.LangKey("fastlogblock.config.title") public class LogConfig { @Config.Comment("Enable handling event") public static boolean loggingEnable = true; @Config.Comment("Filepath from minecraft root folder to block log path") public static String logFolderPath = "blocklog"; @Config.Comment("Path to nickname mapper file from logFolderPath") public static String nickToIntFilePath = "nicktoid.bytelog"; @Config.Comment("Path to block mapper file from logFolderPath") public static String blockToLongFilePath = "blocktoid.bytelog"; public static HashConfig HASH_CONFIG = new HashConfig(); @Config.Comment("File splitter type. SINGLE for single-file strategy, BLOCKHASH for file=HASH(BlockPos) strategy") public static FileSplitterEnum fileSplitterType = FileSplitterEnum.BLOCKHASH; @Config.Comment("Utils information for migration") public static int logSchemeVersion = 1; @Config.Comment("Utils information for migration") public static int writeWorkersCount = 4; @Config.Comment("Regular expression for block change event ignore") public static String[] ignoreBlockNamesRegExp = new String[]{"<minecraft:tallgrass:*>"}; @Config.Comment("Permission level for show block log.") public static boolean onlyForOP = true; public static class HashConfig { @Config.Comment("Max logfile count") public final int fileCount = 16; @Config.Comment("Pattern for log filename. %d - file number. Default: part%d.bytelog") public final String fileNamePattern = "part%d.bytelog"; } @Mod.EventBusSubscriber(modid = FastLogBlock.MODID) private static class EventHandler { /** * Inject the new values and save to the config file when the config has been changed from the GUI. * * @param event The event */ @SubscribeEvent public static void onConfigChanged(final ConfigChangedEvent.OnConfigChangedEvent event) { if (event.getModID().equals(FastLogBlock.MODID)) { ConfigManager.sync(FastLogBlock.MODID, Config.Type.INSTANCE); } } } }
